
Human Activity Recognition Based on Deep Learning Regardless of Sensor Orientation


Abstract
:1. Introduction
2. Related Works
3. Methodology
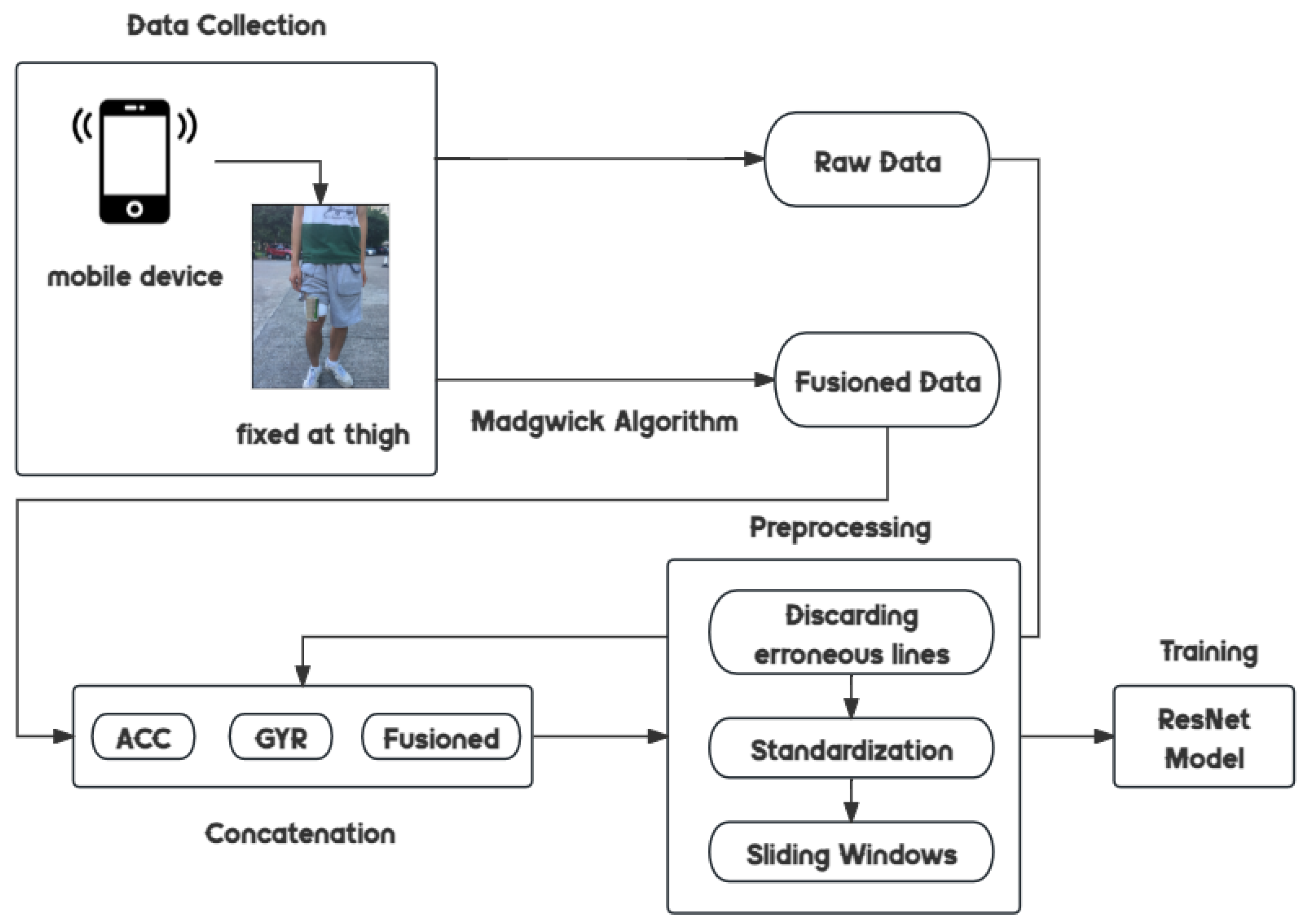
3.1. Datasets
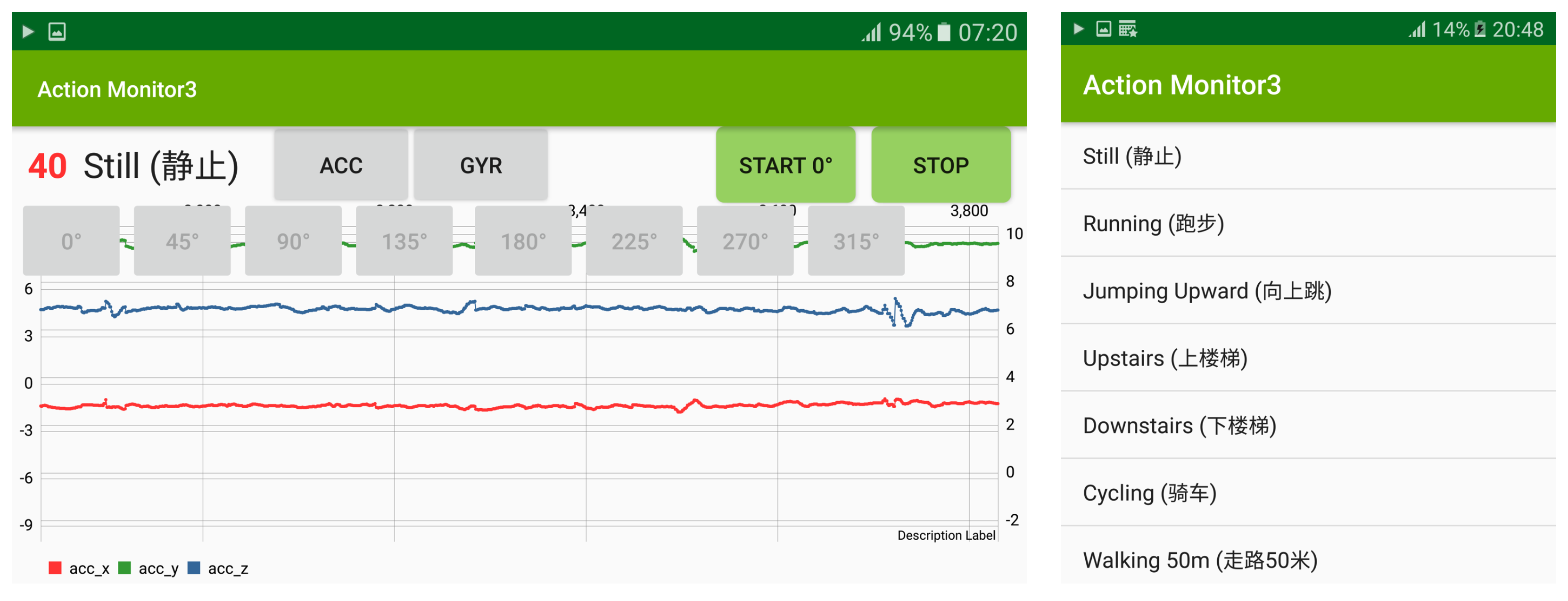
3.1.1. Our Dataset
3.1.2. WISDM [14]
3.1.3. UCI HAR [17]
3.2. Madgwick Algorithm
- a.
- Calculate the attitude update time step (), which depends on the update frequency of the attitude fusion.
- b.
- Update the orientation quaternion based on gyroscope measurements:where ⊗ denotes quaternion multiplication and , , represent the gyroscope’s 3-axial measurements.
- c.
- Correct the orientation quaternion using accelerometer and magnetometer measurements.
- d.
- Normalize the orientation quaternion q to ensure that it has a unit length of
3.3. Madgwick Algorithm Using Gradient Descent
3.4. Sensor Data Fusion
| Algorithm 1 Pseudocode for transforming accelerometer data into inertial acceleration. |
|
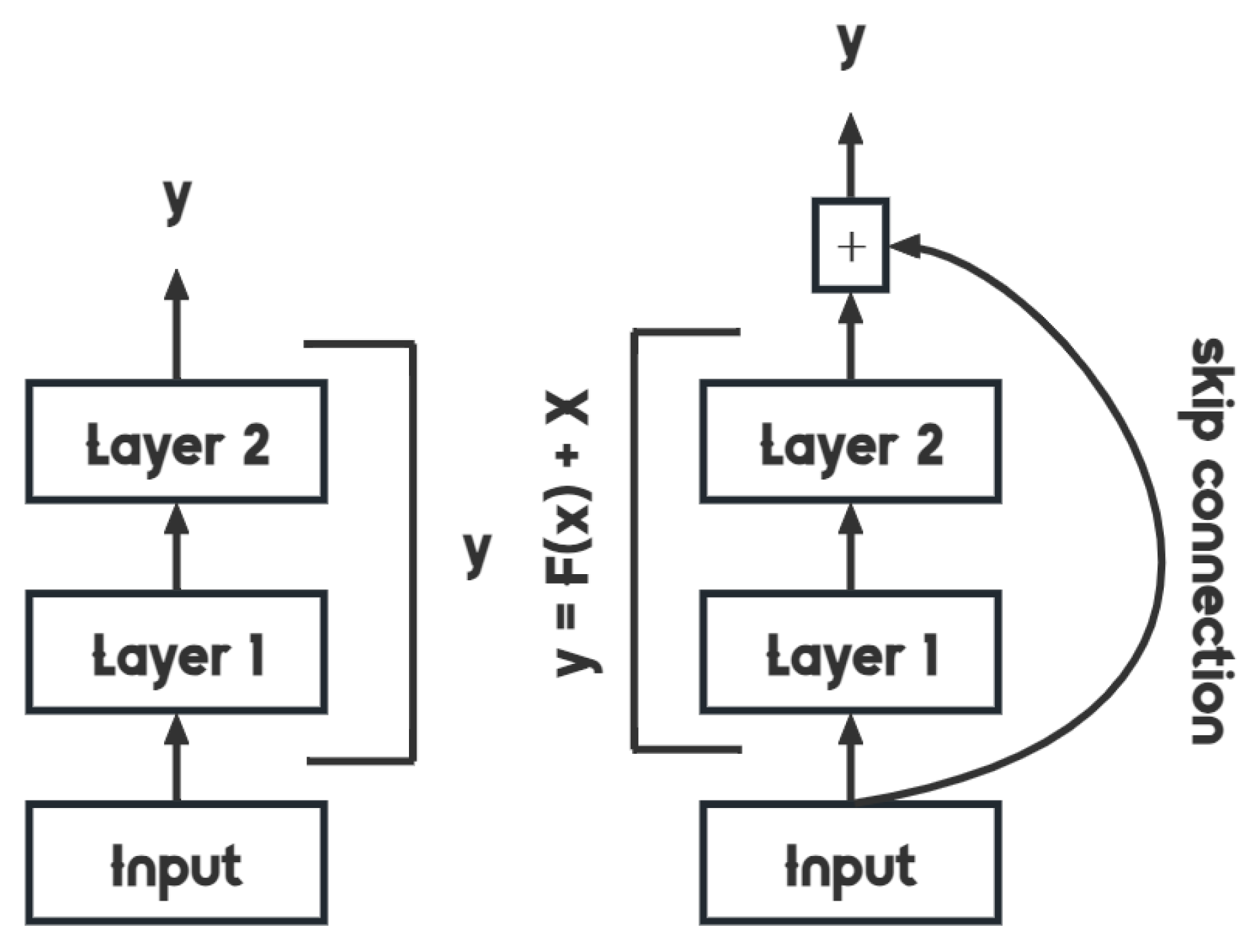
3.5. Optimized ResNet-34
4. Experimental Setup, Results, and Analysis
4.1. Stability Testing
4.2. Deep Learning Baseline Analysis
4.3. User-Independent Analysis
4.4. Analysis on Publicly Available Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Nguyen, L.N.N.; Rodríguez-Martín, D.; Català, A.; Pérez-López, C.; Samà, A.; Cavallaro, A. Basketball activity recognition using wearable inertial measurement units. In Proceedings of the XVI International Conference on Human Computer Interaction, New York, NY, USA, 7–9 September 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Al-Nawashi, M.; Al-Hazaimeh, O.M.; Saraee, M. A novel framework for intelligent surveillance system based on abnormal human activity detection in academic environments. Neural Comput. Appl. 2017, 28, 565–572. [Google Scholar] [CrossRef] [PubMed]
- Bloom, V.; Makris, D.; Argyriou, V. G3D: A gaming action dataset and real time action recognition evaluation framework. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16 July 2012; pp. 7–12. [Google Scholar] [CrossRef]
- Capela, N.; Lemaire, E.; Baddour, N.; Rudolf, M.; Goljar, N.; Burger, H. Evaluation of a smartphone human activity recognition application with able-bodied and stroke participants. J. Neuroeng. Rehabil. 2016, 13, 5. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. Acm Comput. Surv. (Csur) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Romaissa, B.D. Vision-Based Human Activity Recognition: A Survey-Multimedia Tools and Applications; SpringerLink; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Singh, T.; Vishwakarma, D.K. A deeply coupled ConvNet for human activity recognition using dynamic and RGB images. Neural Comput. Appl. 2021, 33, 469–485. [Google Scholar] [CrossRef]
- Mata, O.; Méndez, J.I.; Ponce, P.; Peffer, T.; Meier, A.; Molina, A. Energy savings in buildings based on image depth sensors for human activity recognition. Energies 2023, 16, 1078. [Google Scholar] [CrossRef]
- Franco, A.; Magnani, A.; Maio, D. A multimodal approach for human activity recognition based on skeleton and RGB data. Pattern Recognit. Lett. 2020, 131, 293–299. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor data acquisition and multimodal sensor fusion for human activity recognition using deep learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef] [PubMed]
- Noori, F.M.; Riegler, M.; Uddin, M.Z.; Torresen, J. Human activity recognition from multiple sensors data using multi-fusion representations and CNNs. Acm Trans. Multimed. Comput. Commun. Appl. (Tomm) 2020, 16, 1–19. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. Acm Sigkdd Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Nan, Y.; Lovell, N.H.; Redmond, S.J.; Wang, K.; Delbaere, K.; van Schooten, K.S. Deep learning for activity recognition in older people using a pocket-worn smartphone. Sensors 2020, 20, 7195. [Google Scholar] [CrossRef]
- Maurer, U.; Smailagic, A.; Siewiorek, D.; Deisher, M. Activity recognition and monitoring using multiple sensors on different body positions. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks (BSN’06), Cambridge, MA, USA, 3–5 April 2006; pp. 4–116. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the Esann, Bruges, Belgium, 24–26 April 2013; Volume 3, p. 3. [Google Scholar]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef]
- Morales, J.; Akopian, D.; Agaian, S. Human activity recognition by smartphones regardless of device orientation. In Proceedings of the Mobile Devices and Multimedia: Enabling Technologies, Algorithms, and Applications 2014, San Francisco, CA, USA, 2 February 2014; Volume 9030, pp. 134–145. [Google Scholar] [CrossRef]
- Ito, C.; Cao, X.; Shuzo, M.; Maeda, E. Application of CNN for human activity recognition with FFT spectrogram of acceleration and gyro sensors. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, New York, NY, USA, 8 October 2018; pp. 1503–1510. [Google Scholar] [CrossRef]
- Fang, J.; Qin, J. Advances in atomic gyroscopes: A view from inertial navigation applications. Sensors 2012, 12, 6331–6346. [Google Scholar] [CrossRef]
- Desai, P.R.; Desai, P.N.; Ajmera, K.D.; Mehta, K. A review paper on oculus rift-a virtual reality headset. arXiv 2014, arXiv:1408.1173. [Google Scholar] [CrossRef]
- Chung, H.Y.; Hou, C.C.; Chen, Y.S. Indoor intelligent mobile robot localization using fuzzy compensation and Kalman filter to fuse the data of gyroscope and magnetometer. IEEE Trans. Ind. Electron. 2015, 62, 6436–6447. [Google Scholar] [CrossRef]
- Madgwick, S.O.; Harrison, A.J.; Vaidyanathan, R. Estimation of IMU and MARG orientation using a gradient descent algorithm. In Proceedings of the 2011 IEEE International Conference on Rehabilitation Robotics, Zurich, Switzerland, 11 August 2011; pp. 1–7. [Google Scholar] [CrossRef]
- Choukroun, D.; Bar-Itzhack, I.Y.; Oshman, Y. Novel quaternion Kalman filter. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 174–190. [Google Scholar] [CrossRef]
- Spinsante, S.; Angelici, A.; Lundström, J.; Espinilla, M.; Cleland, I.; Nugent, C. A mobile application for easy design and testing of algorithms to monitor physical activity in the workplace. Mob. Inf. Syst. 2016, 2016, 5126816. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, D.; Gravina, R.; Fortino, G.; Jiang, Y.; Tang, K. Kernel fusion based extreme learning machine for cross-location activity recognition. Inf. Fusion 2017, 37, 1–9. [Google Scholar] [CrossRef]
- Sun, Z.; Ye, J.; Wang, T.; Huang, S.; Luo, J. Behavioral feature recognition of multi-task compressed sensing with fusion relevance in the Internet of Things environment. Comput. Commun. 2020, 157, 381–393. [Google Scholar] [CrossRef]
- Janidarmian, M.; Roshan Fekr, A.; Radecka, K.; Zilic, Z. A comprehensive analysis on wearable acceleration sensors in human activity recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Alo, U.R.; Mujtaba, G. Analysis of multi-sensor fusion for mobile and wearable sensor based human activity recognition. In Proceedings of the International Conference on Data Processing and Applications, New York, NY, USA, 12 May 2018; pp. 22–26. [Google Scholar] [CrossRef]
- Saha, J.; Chowdhury, C.; Roy Chowdhury, I.; Biswas, S.; Aslam, N. An ensemble of condition based classifiers for device independent detailed human activity recognition using smartphones. Information 2018, 9, 94. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed]
- Dara, S.; Tumma, P. Feature extraction by using deep learning: A survey. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 1795–1801. [Google Scholar] [CrossRef]
- Sadouk, L. CNN approaches for time series classification. In Time Series Analysis-Data, Methods, and Applications; IntechOpen: London, UK, 2019; Volume 5, pp. 57–78. [Google Scholar]
- Cho, H.; Yoon, S.M. Divide and conquer-based 1D CNN human activity recognition using test data sharpening. Sensors 2018, 18, 1055. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (bigcomp), Jeju, Republic of Korea, 13–16 February 2017; pp. 131–134. [Google Scholar] [CrossRef]
- Xi, R.; Hou, M.; Fu, M.; Qu, H.; Liu, D. Deep dilated convolution on multimodality time series for human activity recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Shu, X.; Yang, J.; Yan, R.; Song, Y. Expansion-squeeze-excitation fusion network for elderly activity recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5281–5292. [Google Scholar] [CrossRef]
- Ronald, M.; Poulose, A.; Han, D.S. iSPLInception: An inception-ResNet deep learning architecture for human activity recognition. IEEE Access 2021, 9, 68985–69001. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A.; Sitthithakerngkiet, K.; Youplao, P.; Yupapin, P. Resnet-se: Channel attention-based deep residual network for complex activity recognition using wrist-worn wearable sensors. IEEE Access 2022, 10, 51142–51154. [Google Scholar] [CrossRef]
- Yan, Z.; Younes, R.; Forsyth, J. ResNet-Like CNN Architecture and Saliency Map for Human Activity Recognition. In Proceedings of the International Conference on Mobile Computing, Applications, and Services, Cham, Switzerland, 24 March 2022; Volume 434, pp. 129–143. [Google Scholar] [CrossRef]
- Cavallo, A.; Cirillo, A.; Cirillo, P.; De Maria, G.; Falco, P.; Natale, C.; Pirozzi, S. Experimental comparison of sensor fusion algorithms for attitude estimation. Ifac Proc. Vol. 2014, 47, 7585–7591. [Google Scholar] [CrossRef]
- Wilson, S.; Eberle, H.; Hayashi, Y.; Madgwick, S.O.; McGregor, A.; Jing, X.; Vaidyanathan, R. Formulation of a new gradient descent MARG orientation algorithm: Case study on robot teleoperation. Mech. Syst. Signal Process. 2019, 130, 183–200. [Google Scholar] [CrossRef]
- Zmitri, M.; Fourati, H.; Vuillerme, N. Human activities and postures recognition: From inertial measurements to quaternion-based approaches. Sensors 2019, 19, 4058. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Koonce, B. ResNet 34. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 51–61. ISBN 978–1–4842–6168–2. [Google Scholar] [CrossRef]
- Parvat, A.; Chavan, J.; Kadam, S.; Dev, S.; Pathak, V. A survey of deep-learning frameworks. In Proceedings of the 2017 International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2017; pp. 1–7. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Our Dataset | WISDM | UCI HAR | |
|---|---|---|---|
| Sample rate (Hz) | 200 | 20 | 50 |
| Subjects | 31 | 29 | 30 |
| Catagories | 7 | 6 | 6 |
| Window size | 300 | 80 | 256 |
| Stride | 150 | 40 | 128 |
| Overlap rate (%) | 50 | 50 | 50 |
| Layer Name | 34-Layer | Output Size |
|---|---|---|
| conv1 | ||
| conv2_x | max pool, stride 2 | |
| conv3_x | ||
| conv4_x | ||
| conv5_x | ||
| average pooling, flatten, 64d fully connected , dropout | ||
| softmax |
| ACC_0 | ACC_All | 6D | 3D | 9D | |
|---|---|---|---|---|---|
| MLP | 86.93 | 82.42 | 87.49 | 80.12 | 86.57 |
| CNN-2D | 91.25 | 89.62 | 86.33 | 90.60 | 92.25 |
| ResNet-34 | 92.08 | 91.14 | 92.31 | 96.52 | 96.58 |
| Optimized ResNet-34 | 95.83 | 96.24 | 96.25 | 96.16 | 97.13 |
| ACC_0 | ACC_ALL | 6D | 3D | 9D | |
|---|---|---|---|---|---|
| MLP | 86.89 | 84.04 | 88.35 | 80.68 | 88.19 |
| CNN-2D | 91.26 | 91.02 | 90.39 | 89.42 | 86.16 |
| ResNet-34 | 89.01 | 92.53 | 92.51 | 94.04 | 92.73 |
| Optimized ResNet-34 | 89.83 | 94.27 | 94.40 | 94.22 | 95.65 |
| ResNet-34 | Optimized ResNet-34 | |
|---|---|---|
| Accuracy | 92.73% | 95.65% |
| Loss | 0.6749 | 0.5254 |
| Precision | 0.9343 | 0.9587 |
| Recall | 0.9273 | 0.9565 |
| F1 Score | 0.9281 | 0.9568 |
| Training Time | 10636 | 12798s |
| WISDM | UCI HAR | UCI HAR (6D) | UCI HAR (12D) | |
|---|---|---|---|---|
| MLP | 87.30 | 87.41 | 74.65 | 75.60 |
| CNN-2D | 94.23 | 88.09 | 78.25 | 90.60 |
| ResNet-34 | 95.34 | 90.34 | 89.48 | 91.89 |
| Optimized ResNet-34 | 96.33 | 90.80 | 87.13 | 92.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Sun, Y.; Zhang, Z. Human Activity Recognition Based on Deep Learning Regardless of Sensor Orientation. Appl. Sci. 2024, 14, 3637. https://doi.org/10.3390/app14093637
He Z, Sun Y, Zhang Z. Human Activity Recognition Based on Deep Learning Regardless of Sensor Orientation. Applied Sciences. 2024; 14(9):3637. https://doi.org/10.3390/app14093637
Chicago/Turabian StyleHe, Zhenyu, Yulin Sun, and Zhen Zhang. 2024. "Human Activity Recognition Based on Deep Learning Regardless of Sensor Orientation" Applied Sciences 14, no. 9: 3637. https://doi.org/10.3390/app14093637
APA StyleHe, Z., Sun, Y., & Zhang, Z. (2024). Human Activity Recognition Based on Deep Learning Regardless of Sensor Orientation. Applied Sciences, 14(9), 3637. https://doi.org/10.3390/app14093637