1. Introduction
With the rapid development of renewable energy recently, renewable generation will be extensively utilized in the smart grid of the near future to mitigate environmental pollution and promote sustainable development. However, owing to the stochastic volatility and intermittency of renewable energy, the integration of renewable energy sources would possibly exacerbate the uncertainty of power systems, which brings a series of new challenges to transmission network expansion planning (TNEP). Hence, it is necessary to present an economic and robust TNEP method to deal with renewable energy integration in the smart grid.
In the literature, there have been several studies on the TNEP problem under uncertainty by adopting mathematical optimization methods. For instance, [
1] employed methods of stochastic programming and probabilistic constraints for generation and transmission expansion planning with consideration of uncertainties in power system operation. In [
2], a chance-constrained programming method was proposed to deal with uncertain load and wind power in TNEP. However, the stochastic optimization generally requires the accurate probability density function (PDF) of each uncertain parameter as well as the deterministic form of constraints associated with uncertainties, which are difficult to achieve in practice. Apart from stochastic optimization, robust optimization has also been widely discussed in TNEP. Since robust optimization only requires the lower and upper bounds of uncertain parameters, uncertainties such as load demand, renewable generation, and transmission investment cost [
3,
4] can be easily considered in TNEP through a robust model. Nevertheless, the robust TNEP method also has the issue of over-conservatism and may lead to uneconomic solutions.
Recently several researchers have employed the multi-scenario method in TNEP, which considers uncertainties by multiple scenarios. The works by [
5,
6] adopted a scenario-generation method to deal with uncertain generation dispatch. [
7] applied the Monte Carlo simulation (MCS) to simulate the uncertainties of outages and load forecasting in the coordinated generation-transmission expansion planning. In addition, the robust TNEP design based on extreme scenarios was adopted by [
8,
9] to improve the robustness of planning schemes. Nevertheless, the above multi-scenario methods still have limitations, as they tend to generate a large number of scenarios to achieve accurate simulation of uncertainties, which may cause a heavy computational burden.
With the integration of large-scale renewable energy, the penetration level of renewable generation is generally high in the smart grid. Under such circumstances, the traditional TNEP methods, which cater for rated renewable power output, may lead to low utilization rates of transmission lines and poor economic efficiency [
10]. In addition, since the power output of spatially dispersed renewable power plants tends to be strongly correlated in many geographical regions [
11], the assumption that each renewable power plant is independent is no longer applicable. Recently several studies have emphasized the necessity of considering spatio-temporal correlation among renewable energy sources in various fields of the power system, such as wind power forecasting [
11], power market [
12],
etc. Accordingly, the spatial correlation among different renewable power plants also needs to be considered in TNEP to improve the simulation accuracy of uncertain renewable generation.
Although much research has been devoted to the TNEP problem under uncertainty, few studies have investigated the impact of the peak distribution characteristics of renewable generation on the economic efficiency of TNEP. Hence, the purpose of this paper is to provide economic and flexible planning schemes considering uncertainty. A novel scenario-generation method based on clustering analysis is proposed first to handle uncertain factors. In contrast with the scenario-generation methods discussed above, the proposed method only requires the raw information of uncertain factors, and is capable of controlling the number of scenarios to an acceptable range. More importantly, it can spontaneously take into account the correlation among uncertain factors when generating typical scenarios, thus improving the accuracy of uncertainty simulation. Furthermore, on the basis of the typical scenarios, this paper presents a multi-scenario, multi-objective TNEP model with consideration of uncertain renewable generation and load demand. In order to achieve the balance between economic efficiency and robustness of TNEP, the curtailment of renewable generation is considered as one of the optimization objectives. A modified NSGA-II algorithm is then employed to obtain a set of Pareto optimal planning schemes with different levels of investment costs and renewable generation curtailments. In consequence, decision makers are allowed to make an effective choice according to the Pareto optimal front. For validation, the proposed TNEP method is tested on the modified IEEE RTS-24 system. The numerical results show that the proposed method can provide planning schemes superior to those from conventional TNEP methods.
2. Uncertainty Processing Based on Clustering Technique
It has been discussed above that an effective set of scenarios can be employed to guide the TNEP design of a smart grid under uncertainty. Obviously, the accuracy of uncertainty simulation has a direct effect on the validity of planning results, and the number of scenarios is also related to the computational efficiency of TNEP problem solving. When dealing with large uncertainties, the conventional scenario-generation methods can hardly guarantee simulation accuracy while controlling the scenarios’ number within an acceptable range. In addition, the difficulty of uncertainty simulation in the smart grid is also significantly increased due to the large-scale utilization of renewable energy. Therefore, an effective scenario-generation method is of great importance.
Since it is one of the major characteristics of a smart grid to have massive amounts of data collected from various measuring devices [
13], this paper proposes a novel scenario-generation method based on clustering analysis to cope with the uncertainty in the form of large datasets. As one of the most commonly used data mining techniques, clustering analysis has been proven to be effective to recognize the accurate distribution characteristics of large datasets [
14]. In this paper, the power dataset to be clustered consists of the raw data for each uncertain factor, such as hourly data of wind power, photovoltaic power, load demand,
etc. Through the clustering analysis, the power dataset can be clustered into several clusters where data samples belonging to the same cluster have similar values of renewable power output and load demand. This means that each cluster can represent a typical combination of renewable power output and load demand, while the correlation among the uncertain factors is considered intuitively. Therefore, a scenario set, which contains the typical combinations of renewable power output and load demand, can be selected from the clusters by data sampling.
This paper proposes a novel hybrid clustering method that thoroughly investigates the inherent characteristics of the TNEP problem. Moreover, an effective strategy for scenario selection is applied to ensure the typicality of the selected scenario set. The specific procedures are described in the following subsections.
2.1. Identification of the Number of Typical Combinations of Renewable Power Output and Load Demand
For the power dataset, each data sample represents a deterministic combination of renewable power output and load demand, while an effective scenario set should contain all the typical combinations. Since data samples belonging to the same cluster have similar values of renewable power output and load demand, each cluster can be considered as a specific data subset representing a typical combination. Thus the optimal cluster number for a power dataset, which corresponds to the number of typical combinations, needs to be identified first.
This section employs an iterative graph partitioning method to obtain the optimal cluster number [
15]. This method approaches the problem with two kinds of matrix forms: the observation matrix and the judgement matrix. Suppose the dataset
x with
n data samples has been already clustered into
h clusters, then an
n×
n observation matrix
MO is given by:
The observation matrix
MO represents the clustering relationships among all the data samples under a defined cluster number. Obviously, a single observation matrix can hardly reveal the accurate clustering distribution of a complex dataset, especially when the optimal cluster number is unknown. Thus it is essential to compute the observation matrices with different cluster numbers to obtain more clustering information. Suppose there is an observation matrix set with the total number
c of clusters ranging from 2 to
k, the judgement matrix
MJ is defined as follows to extract the key information:
where
is the observation matrix with the cluster number set to
c. It can be observed that the judgement matrix
MJ integrates the clustering relationships among data samples under different cluster numbers. The value of each matrix element indicates the similarity degree between the corresponding data samples; for example, a large value of
means a high similarity degree between
xi and
xj, and in that case there will be a high probability that
xi and
xj are grouped into the same cluster.
On the basis of the above two kinds of matrix forms, the steps of the identification method are given in brief below [
15]:
- (a)
Employ the partitioning clustering algorithm to cluster the power dataset iteratively with the cluster number ranging from 2 to k, then obtain the observation matrix set according to Equation (1).
- (b)
Compute the judgement matrix MJ as the sum of the obtained observation matrix set.
- (c)
On the basis of Breadth-First Search (BFS) algorithm, record the number of independent connected sub-matrices in MJ. The recorded number represents the total number of clusters in the current iteration.
- (d)
Update the judgement matrix
MJ by decreasing the value of each non-zero element as follows:
- (e)
If all elements of the updated judgement matrix MJ become zero, then go to the next step. Otherwise, go to step (c).
- (f)
Analyze the recorded number of sub-matrices in all iterations. The number with the maximum stability degree is viewed as the optimal cluster number.
In step (f), the stability degree of a given sub-matrix number
c refers to the consecutive occurrence number of
c in all iterations. The number with the maximum stability degree means that under this number, the connections of the data samples within the sub-matrices (clusters) are the strongest and hardest to break [
15].
It should be noted that the partitioning clustering algorithm is employed as a fast clustering technique to accelerate the iterative clustering process in step (a). However, its clustering performance is not sufficiently stable when the cluster number is large. To solve this issue, the above identification process is repeated sn times in this paper. Based on sn times calculation, the stability degree of each sub-matrix number can be estimated accurately and the optimal cluster number can be determined through further statistical analysis.
2.2. Rough Fuzzy Clustering Analysis of Power Dataset
Since the uncertainty level in different TNEP cases may vary significantly, it is important to adopt a flexible clustering method to ensure good clustering performance under various datasets.
Traditional clustering methods, such as hard clustering, in which the membership degree of each data sample should only be 0 or 1, are not suitable for TNEP because the power data is inherently continuous. Although soft clustering can deal with continuous data by fuzzy membership degree, it also has the shortcoming of producing overlapped clusters.
Considering the intrinsic characteristics of power dataset, this paper adopts a rough-fuzzy clustering method, which is based on minimizing the following objective function [
16]:
where
h is the cluster number;
n is the sample number of the power dataset;
uij is the membership degree of data sample
xi to cluster
j;
q is the fuzzifier parameter set as 2; and
d(
xi,λ
j) is the Euclidean distance between
xi and cluster center λ
j, which represents the similarity degree between the power values of
xi and λ
j.
Unlike traditional clustering, the rough-fuzzy membership degree is applied in the adopted method to guide the clustering analysis. The corresponding membership degree matrix
u is obtained by the following steps [
17]:
- (a)
Calculate the n × h dissimilarity matrix F by measuring the Euclidean distance between each data sample and each cluster center.
- (b)
Sort the elements of the matrix
F by row in ascending order and obtain a new dissimilarity matrix
F′. Then modify the sorted matrix
F′ as follows [
17]:
- (c)
Convert the modified matrix
F’ into the matrix
F with the original order. Then calculate the membership degree matrix
u by:
As shown in Equations (5) and (6), the 0–1 membership degree is employed if the data sample is closed to the cluster center; otherwise the fuzzy membership degree is employed. On the basis of this mixed membership degree, the rough-fuzzy clustering method integrates the advantages of hard clustering and soft clustering [
16].
The value of cluster center λ
j is updated with the changes of membership degree matrix
u:
Through the above analysis, the mathematical formulation of the rough-fuzzy clustering analysis is represented by Equations (4)–(7). A differential evolution algorithm is adopted to solve the above optimization problem; the detailed solving process can be found in [
18].
2.3. Validation of the Hybrid Clustering Method with a Wind Power Dataset
A typical wind power dataset, which is derived from two wind farms in the EWITS study [
19], is employed to validate the proposed clustering method.
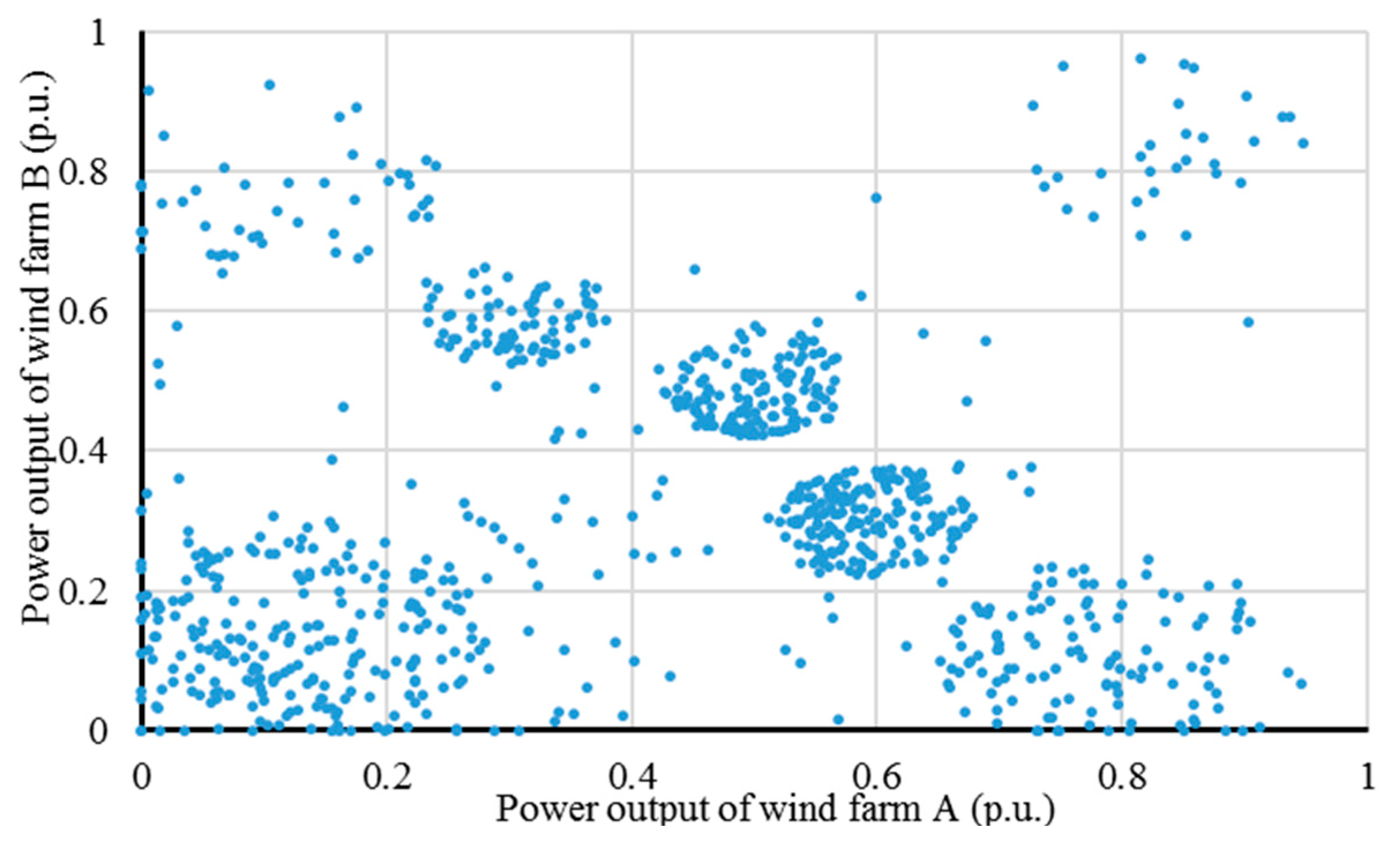
Figure 1 gives its scatter diagram:
Figure 1.
Scatter distribution of the wind power dataset.
Figure 1.
Scatter distribution of the wind power dataset.
The identification of cluster number is implemented first. Here the parameter
sn is set as 40 by experiments with test databases [
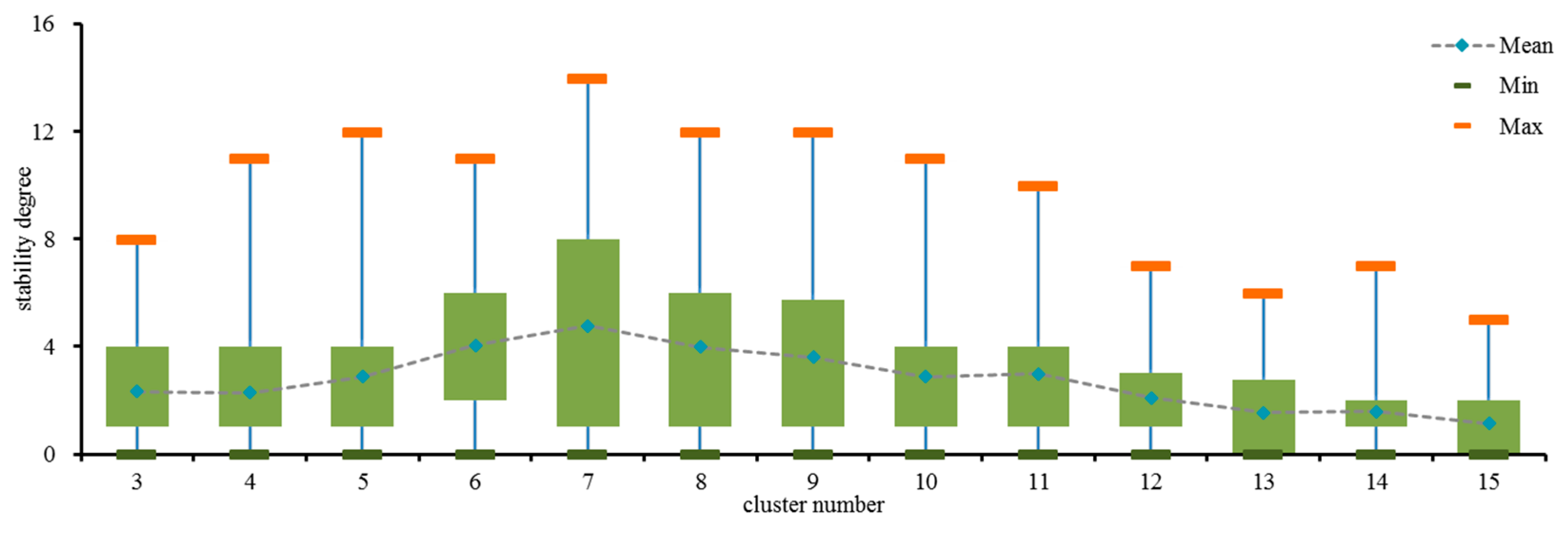
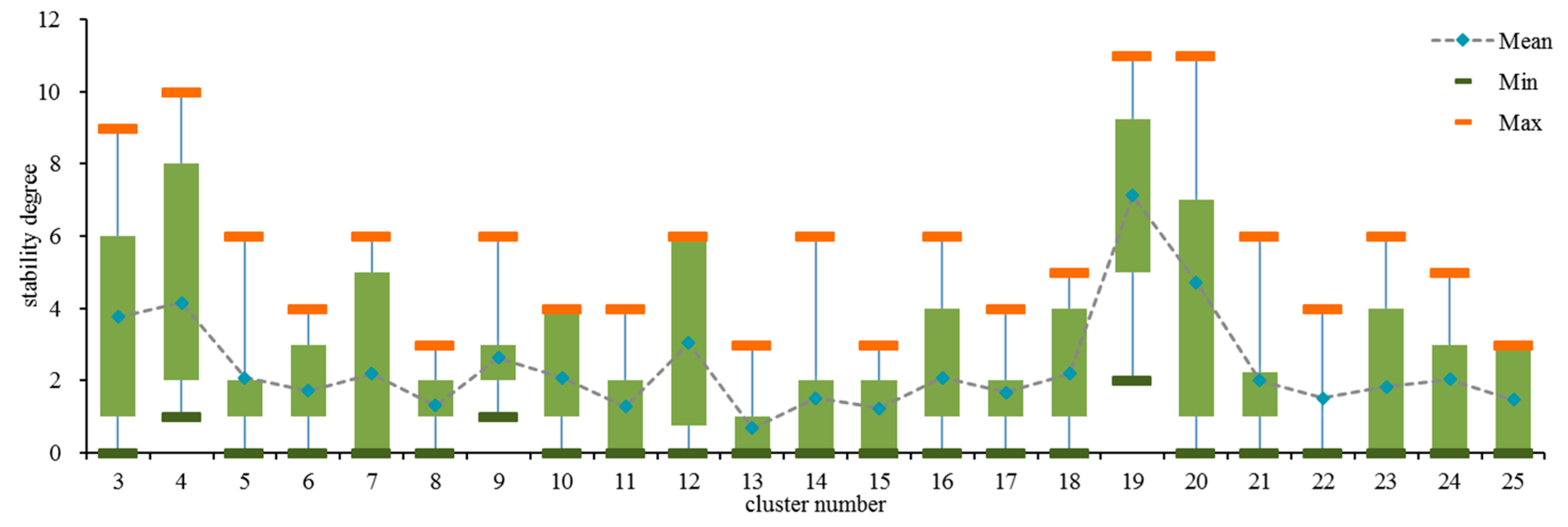
20]. Through analyzing the estimated stability degree of each cluster number in 40 trials, statistical results with the cluster number varying from 3 to 15 are illustrated in
Figure 2.
According to
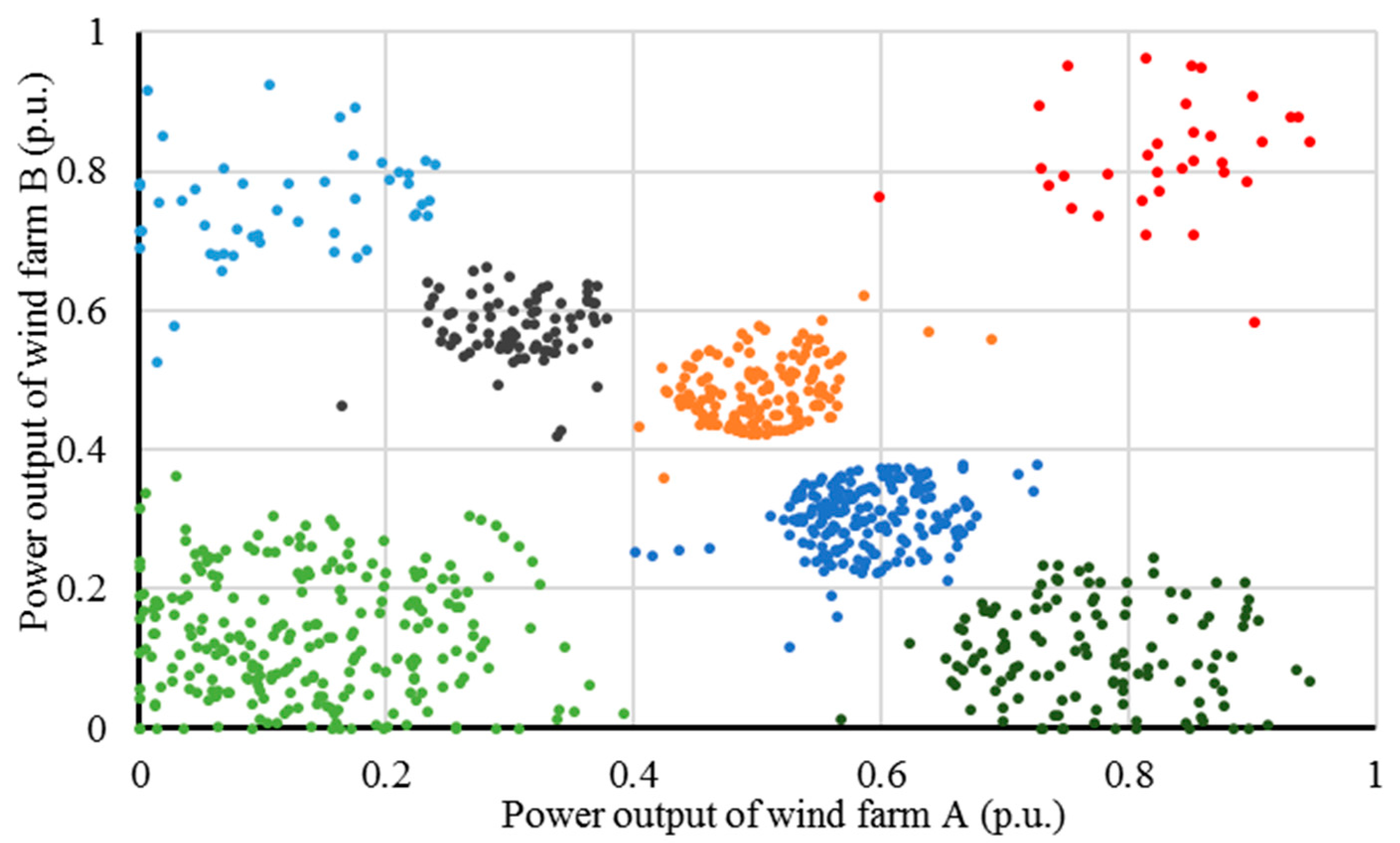
Figure 2, the cluster number 7, which has the maximum stability degree, is determined as the optimal cluster number. Then the power dataset is clustered into seven clusters as depicted in
Figure 3. It can be seen that the clustering result accurately recognizes seven typical combinations of wind power output of the two wind farms. Moreover, there are no overlapping areas among different clusters, showing that the cluster divisions are totally obvious. Hence, the effectiveness of the hybrid clustering method is verified.
Figure 2.
Stability degree boxplot for cluster number analysis.
Figure 2.
Stability degree boxplot for cluster number analysis.
Figure 3.
Clustering result of wind power dataset.
Figure 3.
Clustering result of wind power dataset.
2.4. Selection Strategy for Power System Planning Scenarios from Clustering Result
In order to ensure that the selected scenarios can contain sufficient information on the whole power dataset, as well as control the scenarios’ number to an acceptable range, this paper proposes an effective data sampling strategy as follows:
- (a)
On the basis of clustering results, calculate the radius of each cluster as follows:
where
ri is the radius of the
ith cluster;
ni is the data sample number of cluster
i; and
xk is the data sample belonging to cluster
i.
- (b)
Set
tmin as the minimum sampling number of a single cluster, then determine the sampling number of each cluster by:
where
ti is the sampling number of cluster
i and symbol “⎿⏌” is the rounded-down value of a quantity. It can be inferred that a large sampling number will be applied to the cluster with a large radius. This means that the cluster having the larger distribution range will be sampled more times, thus fully extracting the corresponding data information.
- (c)
According to the calculated sampling number, a total of Σ
ti data samples are sampled at random to generate the typical scenario set. For each scenario, the corresponding occurrence probability is given by:
where α
k is the occurrence probability of scenario
k;
h is the cluster number.
- (d)
Examine the accuracy of the generated typical scenario set by calculating the correlation coefficient between the data distribution represented by the typical scenario set and the whole power dataset.
- (e)
Repeat steps (c)–(d) sm times. Based on sm times calculation, the scenario set with the largest correlation coefficient is determined to be the optimal scenario set and is employed in the subsequent TNEP model.
4. The Solution Method Based on Modified NSGA-II
Since the evolutionary algorithm has been proven to be efficient to solve the TNEP problem [
21,
22], this paper adopted a modified NSGA-II to solve the above multi-objective TNEP problem.
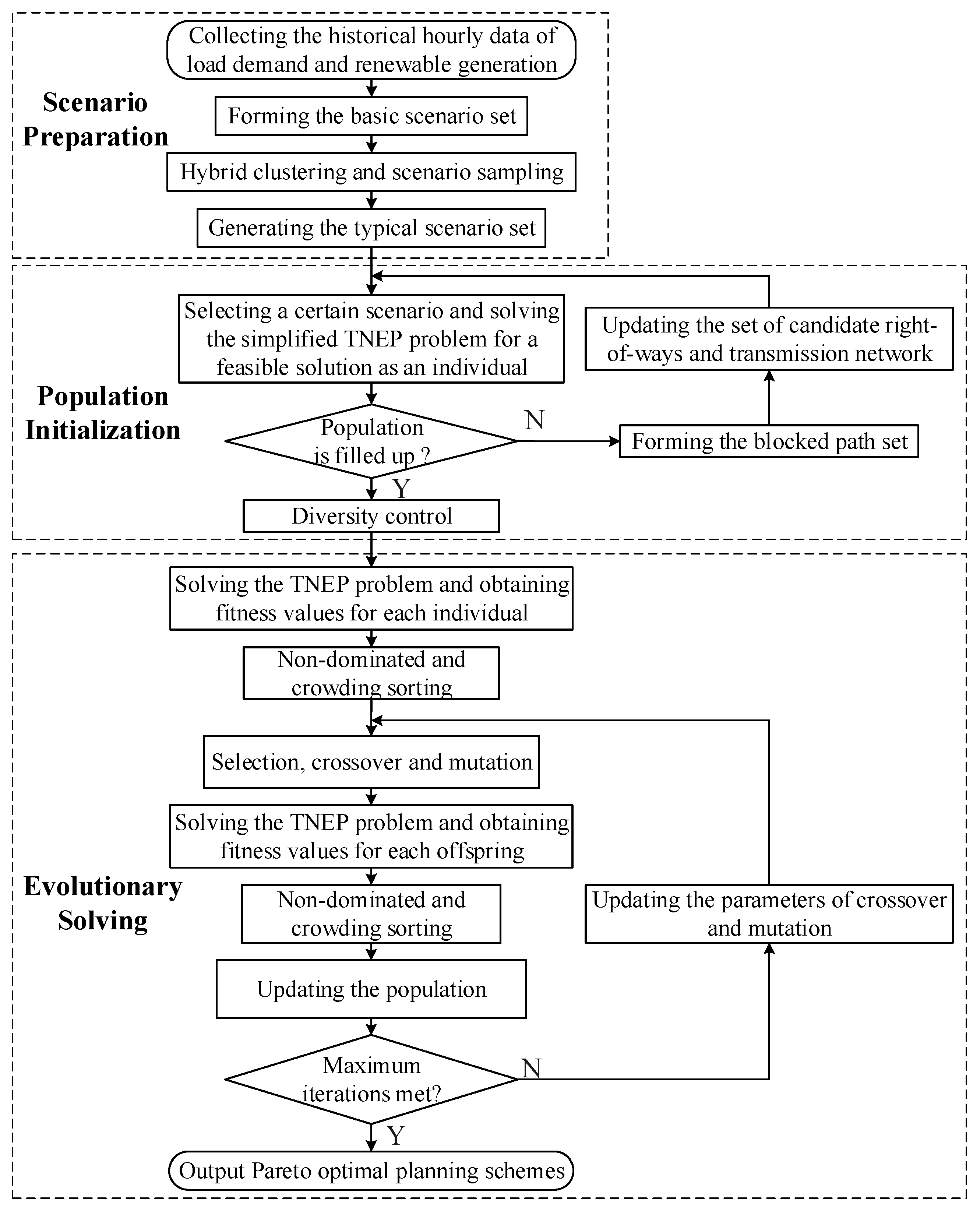
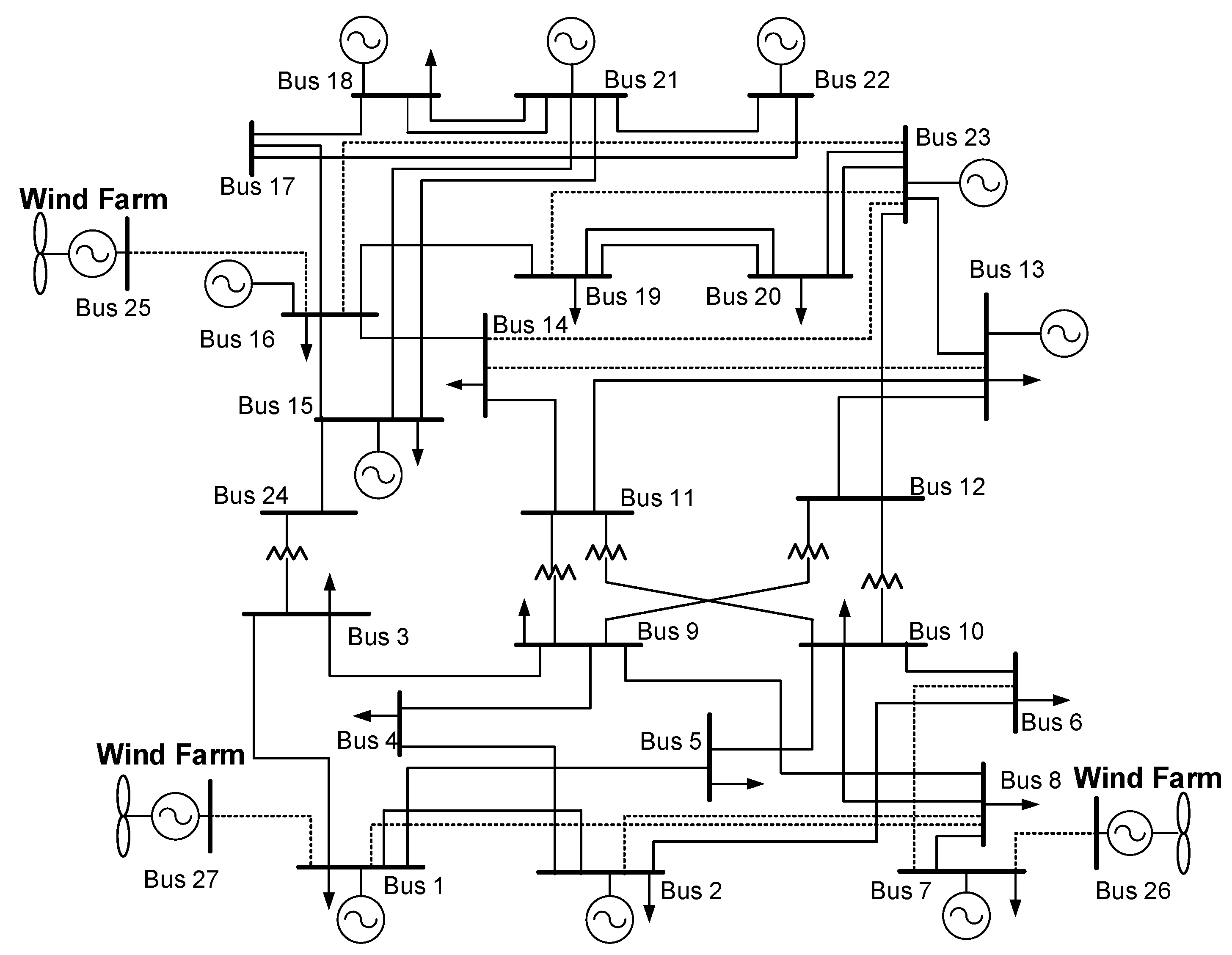
Figure 4 shows the solving process of the proposed TNEP model, while the detail of each part is given below.
Figure 4.
The solving process of TNEP problem by the modified NSGA-II.
Figure 4.
The solving process of TNEP problem by the modified NSGA-II.
4.1. Scenario Preparation for TNEP
In the beginning, the hourly data of each uncertain factor is collected to form the basic scenario set. Then the proposed clustering method is employed to cluster the basic scenario set and to recognize all the typical combinations. Furthermore, a typical scenario set is generated from the clustering results by means of the proposed sampling strategy.
4.2. The Initialization of Population
To speed up the convergence of problem solving, the initial population is generated based on the typical scenario set. For each individual, its initialization procedures are as follows:
- (a)
Select a certain scenario with deterministic load demand and renewable generation from the typical scenario set.
- (b)
According to the selected scenario, the original TNEP problem is simplified to a single-scenario single-objective problem, in which Equation (21) or Equation (22) is selected alternatively as the optimization objective.
- (c)
Solve the simplified problem by using software for MILP. The linearization method of Equation (13) can be found in [
3]. The obtained planning result is considered as an individual.
It should be noted that the above initialized method may result in similar individuals, which will affect the global search in the subsequent problem solving. Hence, the idea of the “blocked path” is adopted to diversify the initial individuals [
6]. After each individual is generated, the right-of-ways where
nij ≠ 0 are selected to form the blocked path set Γ, which is defined by:
where
i-j is the right-of-way between nodes
i-j; Ω is the set of candidate right-of-ways;
rand [0,
nij] is to generate a random integer within [0,
nij]. It can be seen that the set of candidate right-of-ways is updated by removing the right-of-ways in the blocked path set. Moreover, for each right-of-way in the blocked path set,
lines are added to the original transmission network. With the updated candidate set and transmission network, the new individuals can be guaranteed to be different from one to another while the initial search area is also expanded.
After all individuals are generated, the diversity check and mutation manipulation are also conducted to ensure that any two individuals are different in at least two right-of-ways.
4.3. Procedures of Evolutionary Solving
- (a)
With the planning result determined by each individual, solve the simplified multi-scenario TNEP problem in turn. The optimization results, which include transmission investment cost and curtailed renewable generation, are considered as two fitness values for the corresponding individual.
- (b)
For all individuals, carry out the non-dominated and crowding sorting according to the fitness values.
- (c)
On the basis of the sorting results, tournament selection, single-point crossover and mutation are implemented to generate offspring. In this paper, the mutation manipulation is to add or remove a line for a selected right-of-way with 50/50 probability [
5,
6].
- (d)
Likewise, solve the simplified TNEP problem for each offspring, and integrate the offspring and parent population for non-dominated and crowding sorting. Then update the population by removing the individuals with the lowest ranking.
- (e)
If maximum iterations are met, go to step (f). Otherwise, update the parameters of crossover and mutation as follows, then go to step (c):
where
PCR and
PMU are the parameters of crossover probability and mutation probability respectively;
itc is the current number of iterations;
ita is an artificial parameter, which is set to be 20% of the maximum iteration number; symbol “⎾⏋” denotes the rounded-up value of a quantity; and
dMU is the mutation operator, which represents the number of right-of-ways that should mutate in a mutation manipulation.
- (f)
Output the planning results from the Pareto optimal front.
According to the idea in [
23], this paper proposes an adaptive control strategy for the parameters of crossover and mutation in step (e). With Equations (24) and (25), large values of
PCR and
dMU are employed in the early iterations to diversify the search area and to ensure the global optimization. In later iterations, as the global optimal area is gradually determined, a large value of
PMU is employed while
dMU decreases, which means that a large number of individuals will be mutated and few right-of-ways (
dMU will eventually be decreased to 1) will be changed for each individual. Since the mutation manipulation is only to add or remove a line for each selected right-of-way, a large value of
PMU is employed in later iterations to enhance the local search; this will not have an adverse effect on the optimal solution.
6. Conclusions
This paper presents a multi-objective approach for TNEP under uncertainty. A novel hybrid clustering method is proposed to generate typical scenarios for the consideration of uncertain renewable generation and load demand. Moreover, through analyzing the distribution characteristics of renewable power output, an appropriate curtailment of renewable generation is realized in TNEP to improve the economic efficiency of planning schemes.
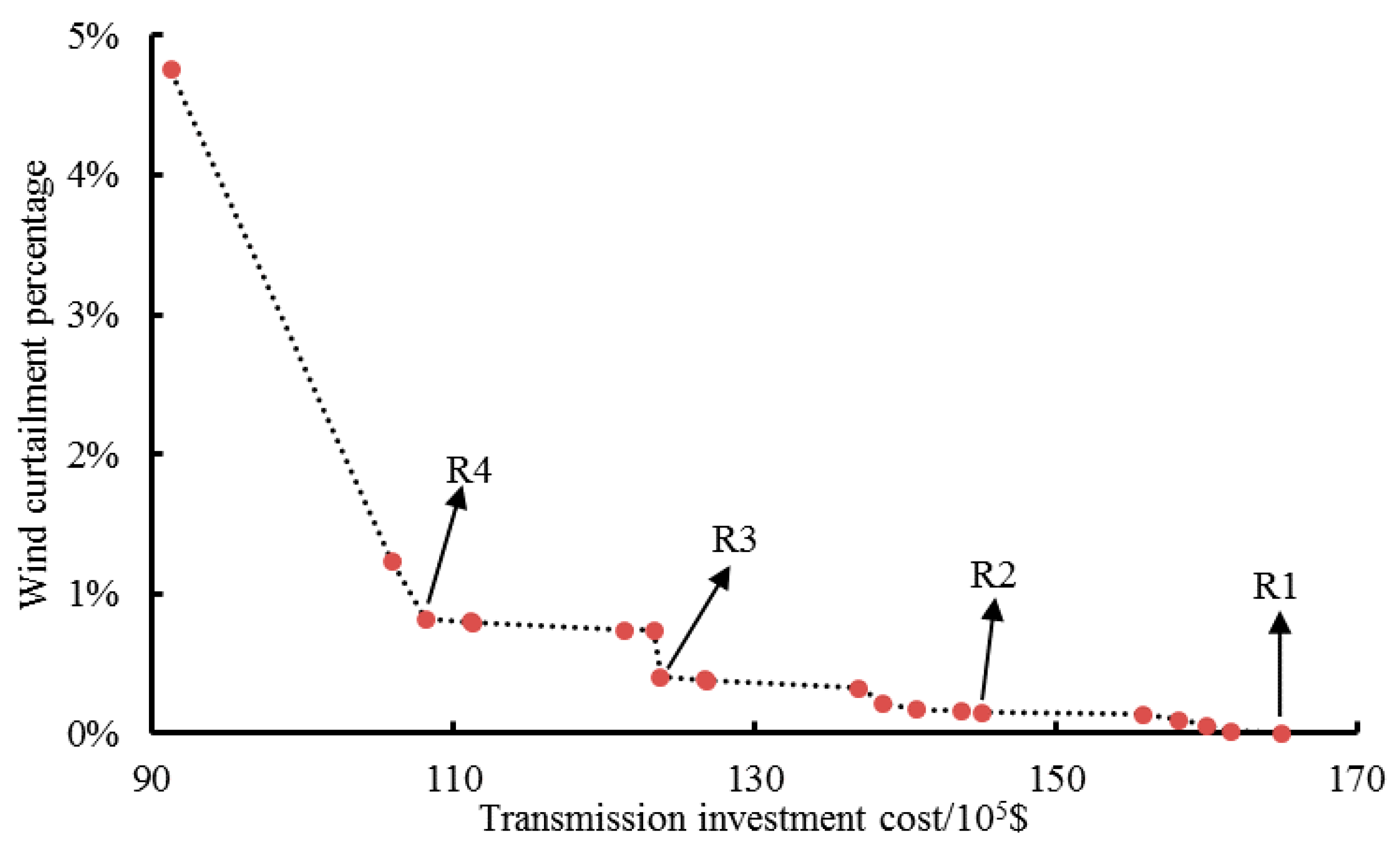
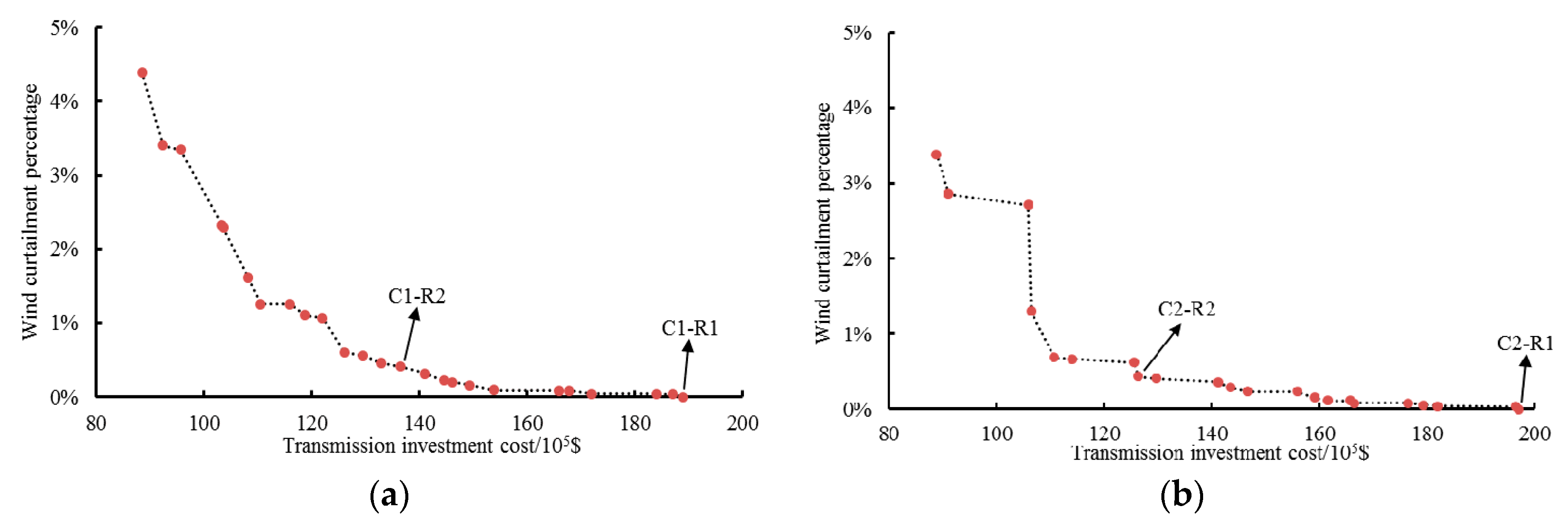
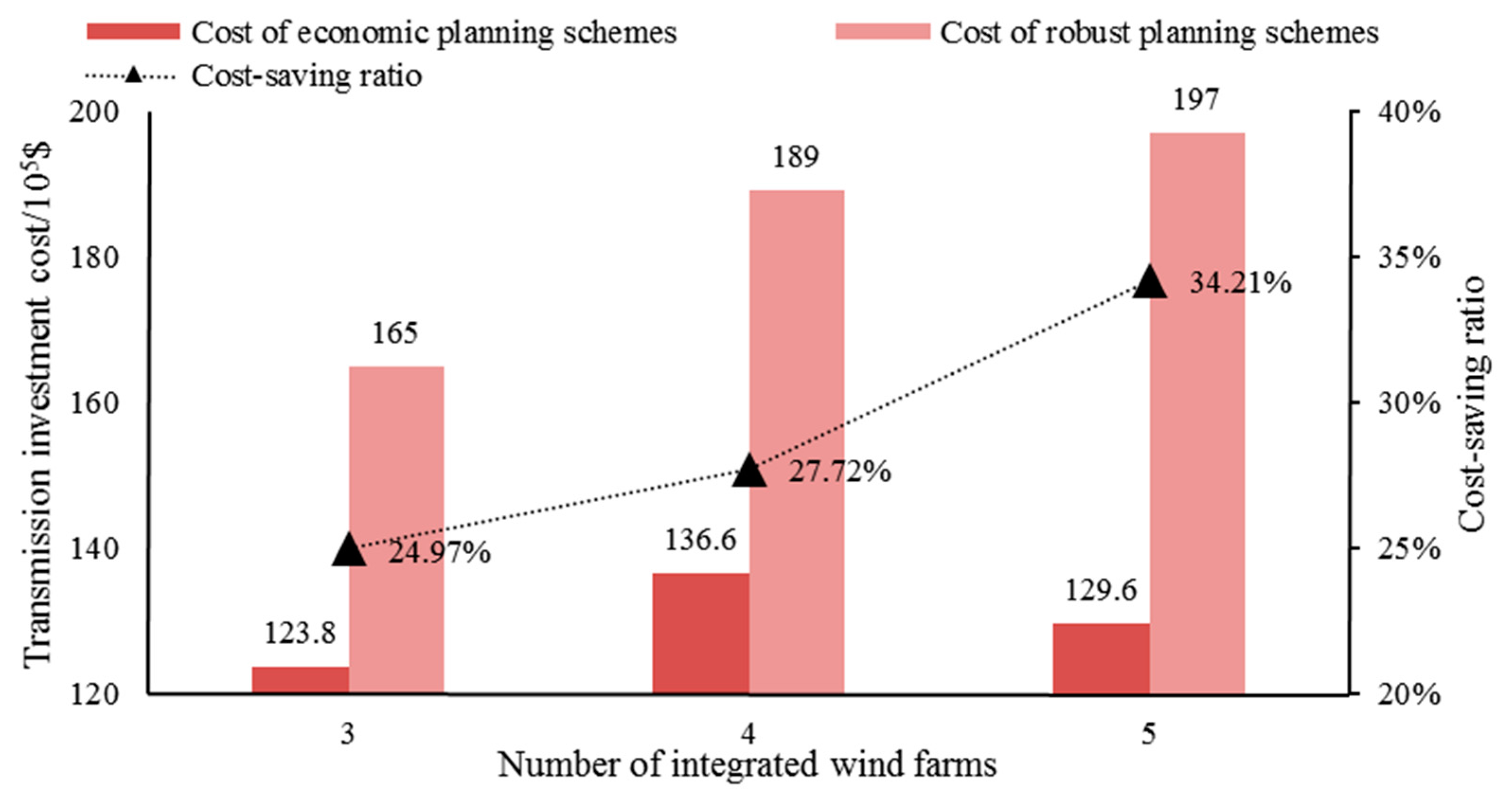
Numerical results demonstrate that the transmission investment can be effectively reduced by curtailing part of the peak renewable power output. The robustness and effectiveness of the proposed TNEP method are validated through comparing two robust TNEP methods and MCS. Further analysis indicates that the proposed TNEP method can provide more reasonable and economic planning schemes under increased uncertainties. In summary, this new TNEP method provides a flexible and economic way of TNEP, and the typical scenarios obtained by clustering analysis can accurately simulate the uncertainties.
In this paper, the conventional generation capacities and loads in TNEP are artificially set. Further work will be carried out on the coordinated generation and transmission planning problem, considering long-term forecasting of power generation and demand.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

