
A Review of Time-Scale Modification of Music Signals †

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
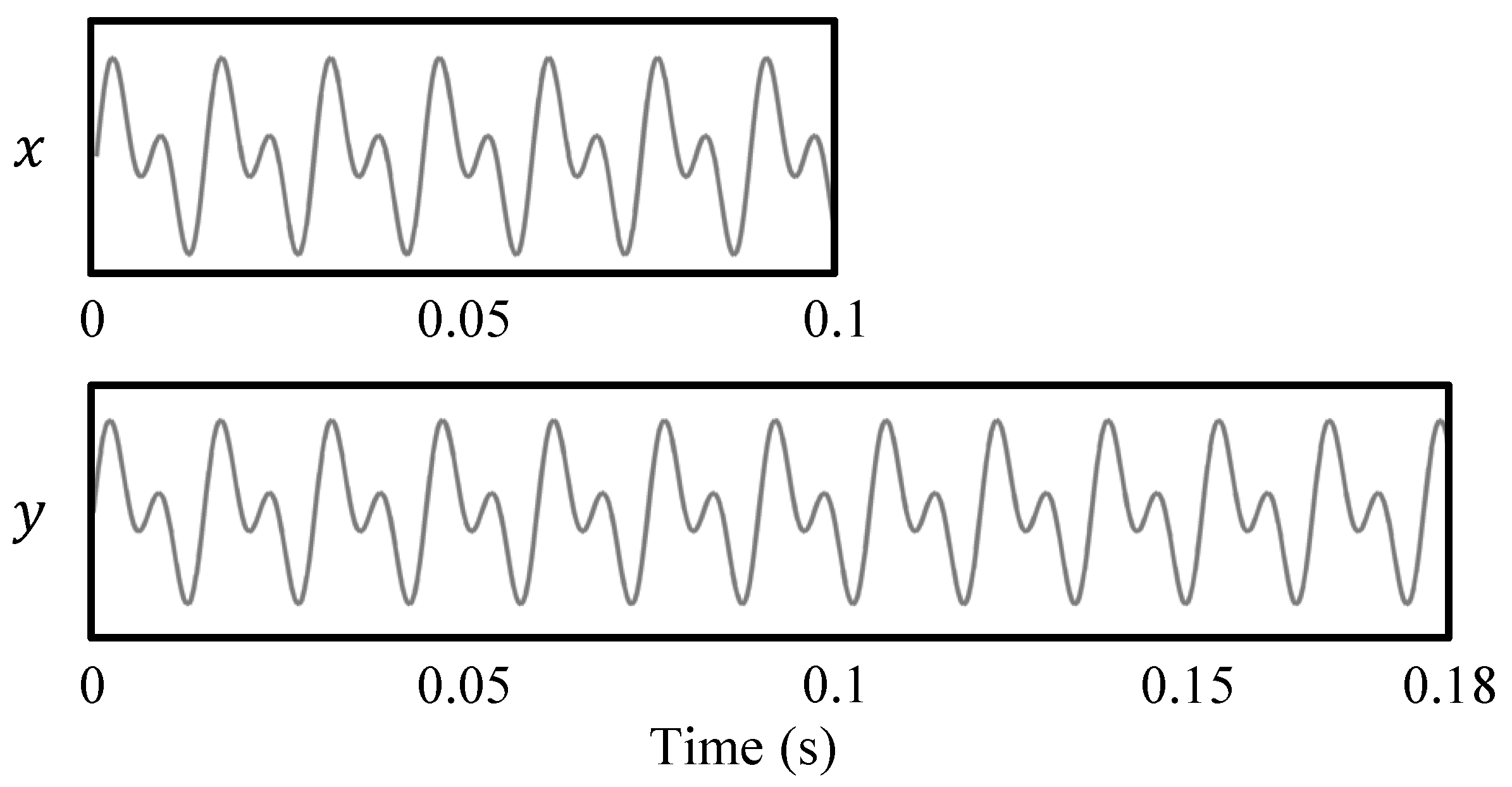
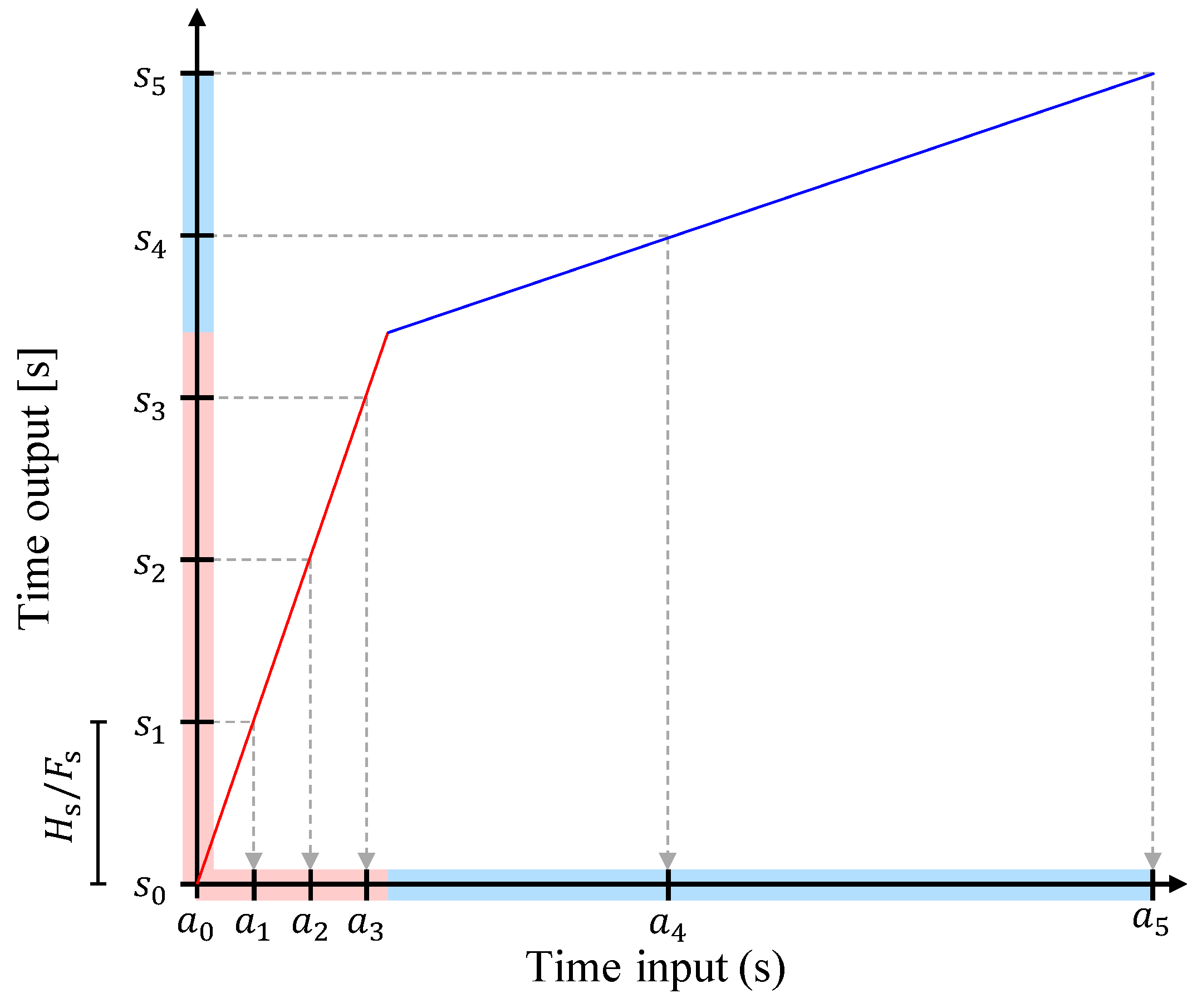
2. Fundamentals of Time-Scale Modification (TSM)
3. TSM Based on Overlap-Add (OLA)
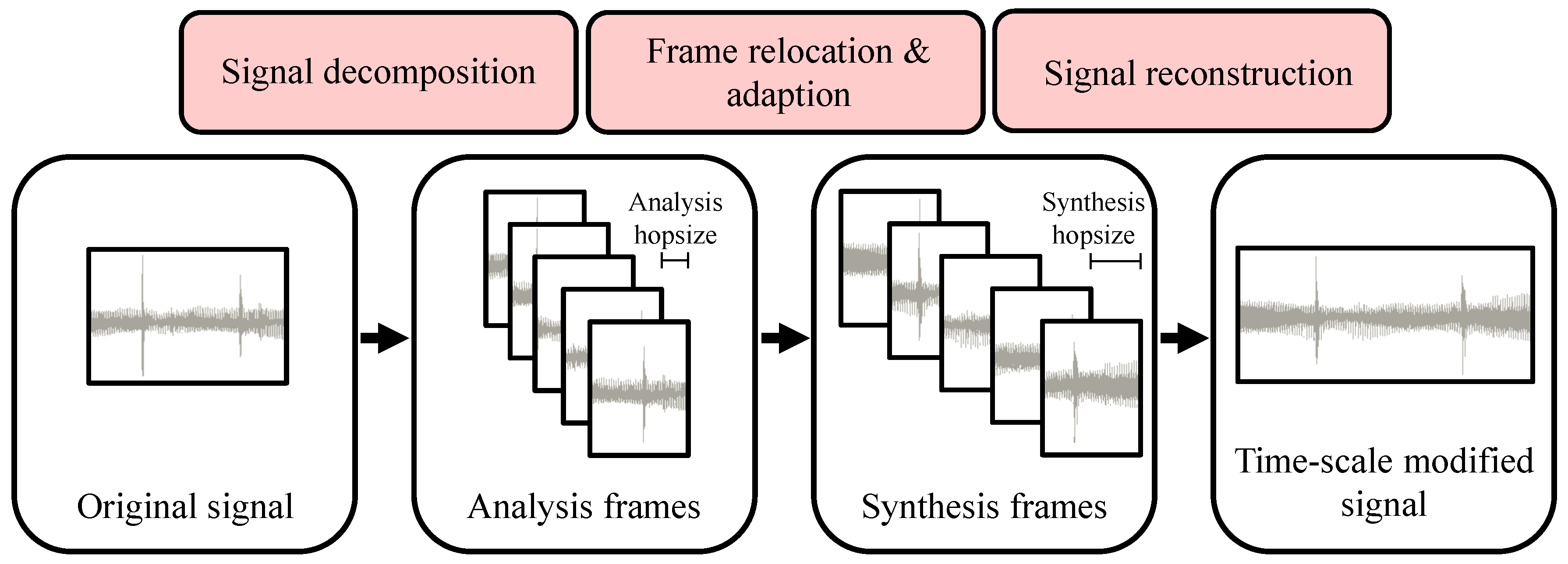
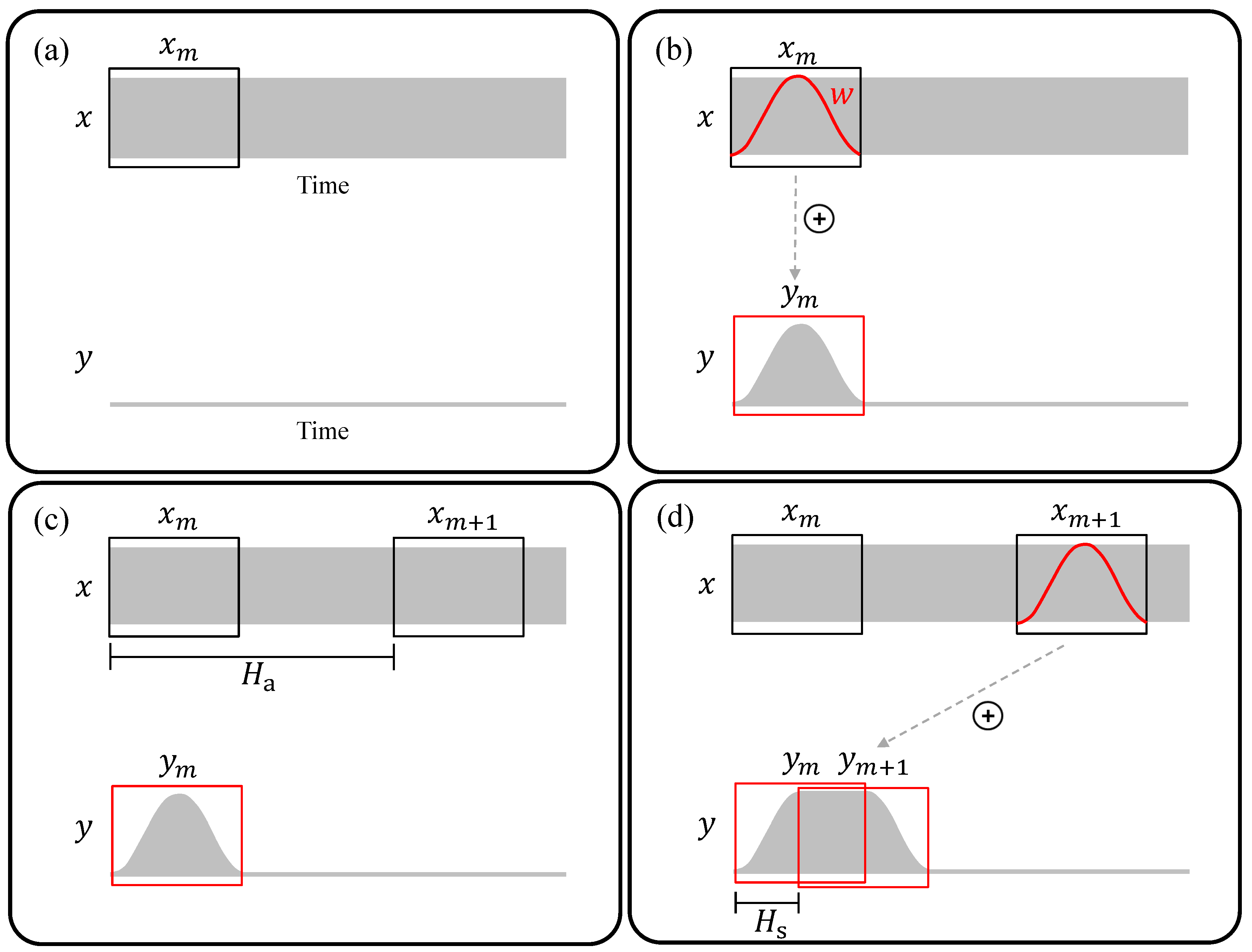
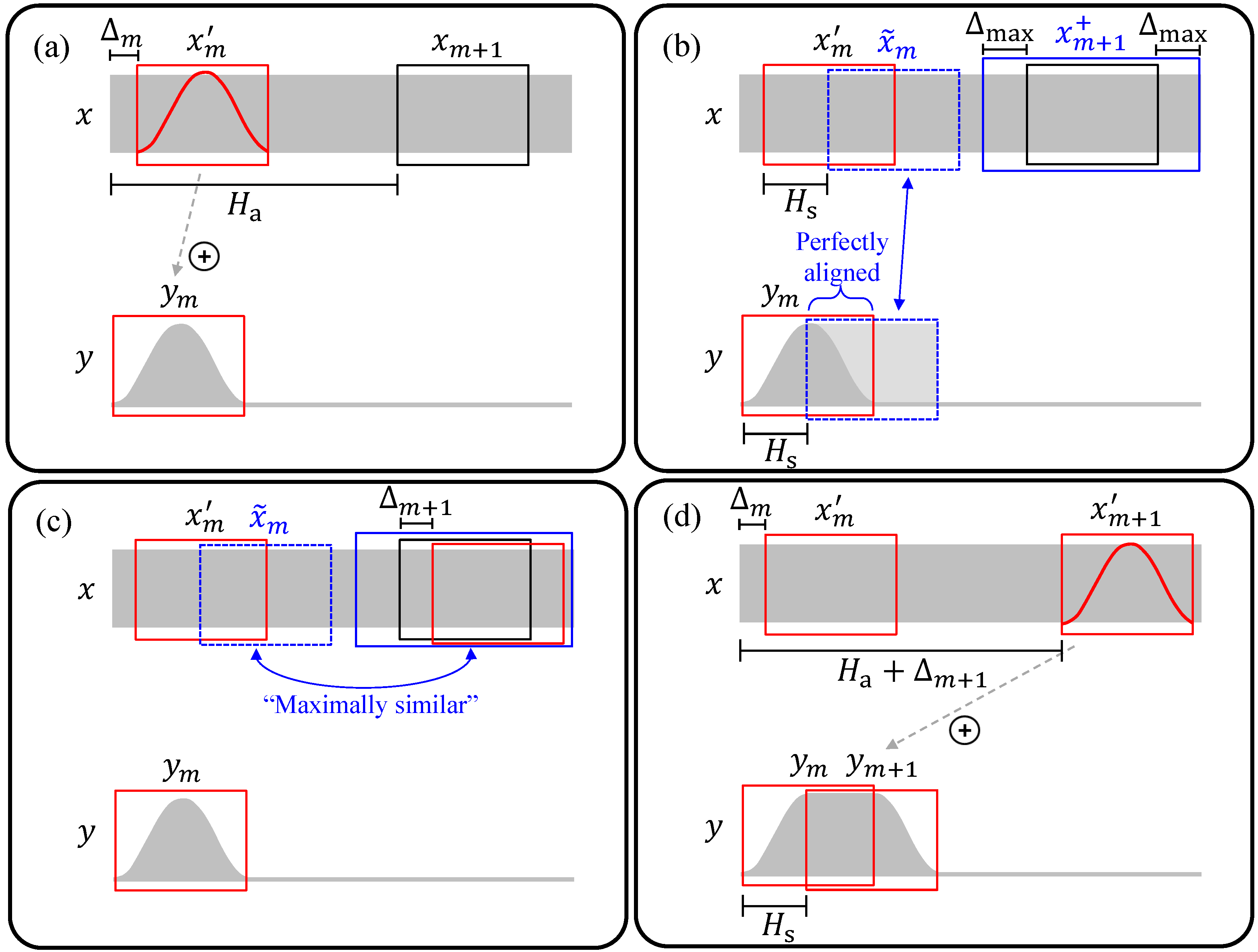
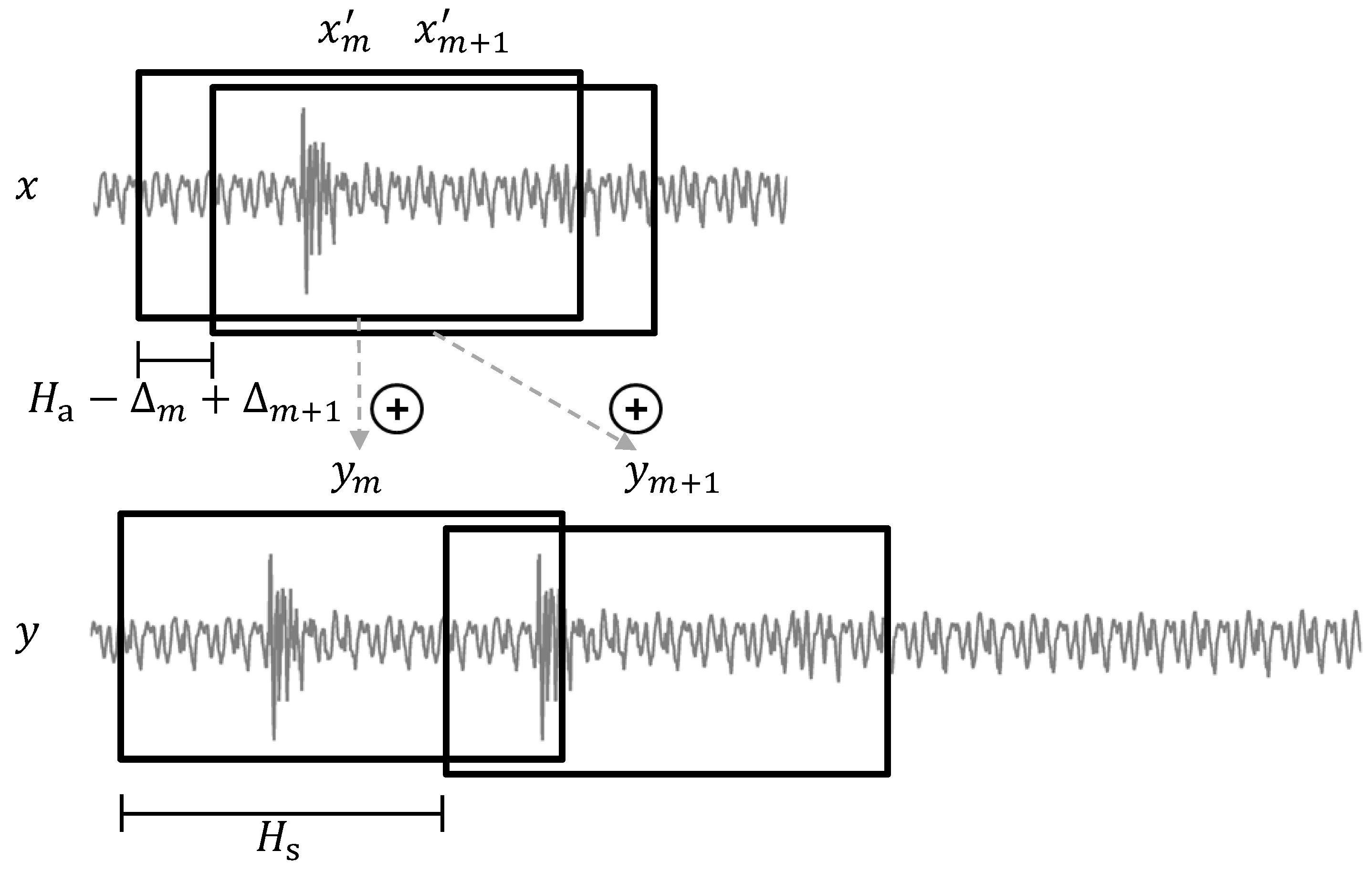
3.1. The Procedure
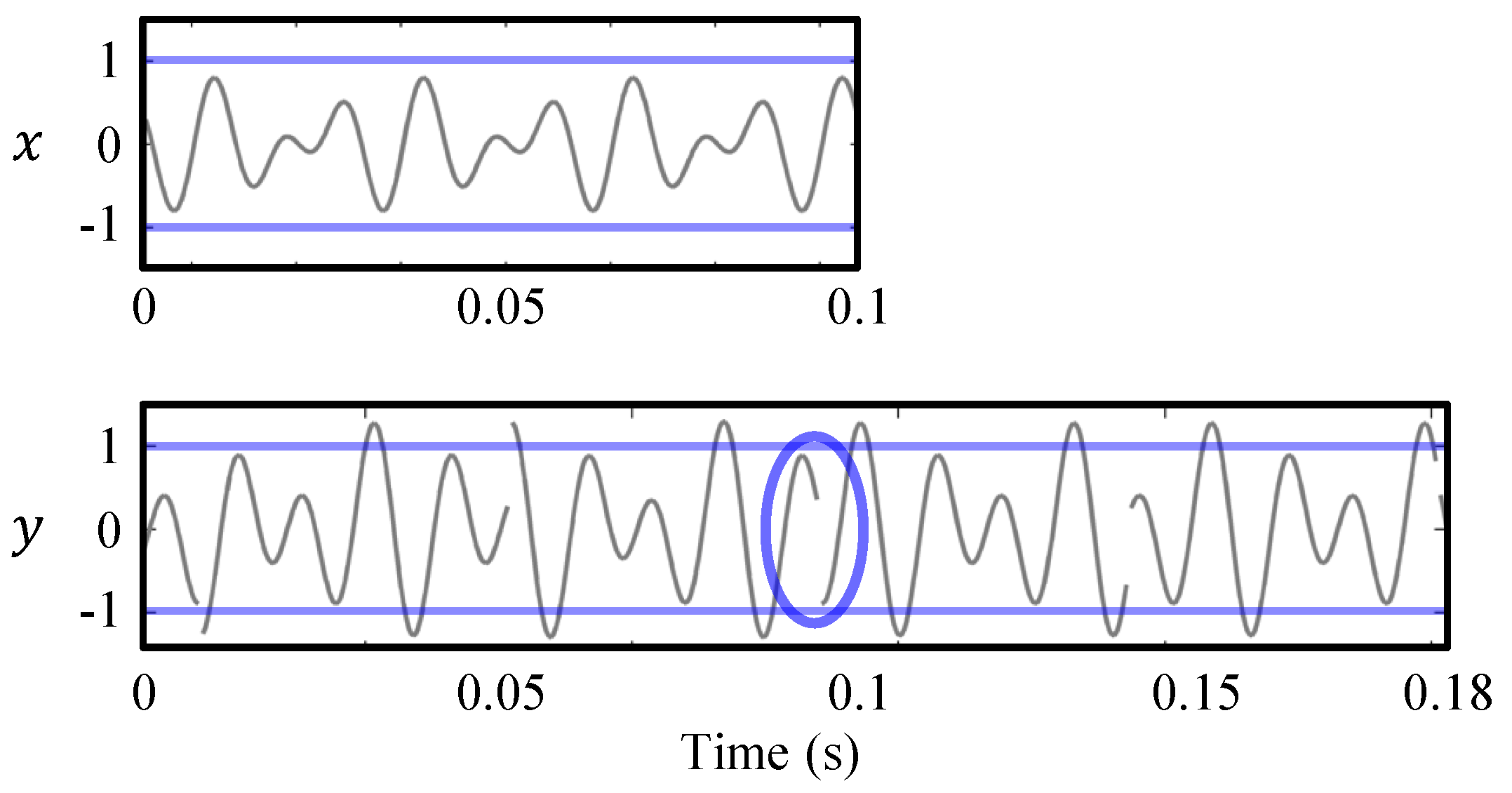
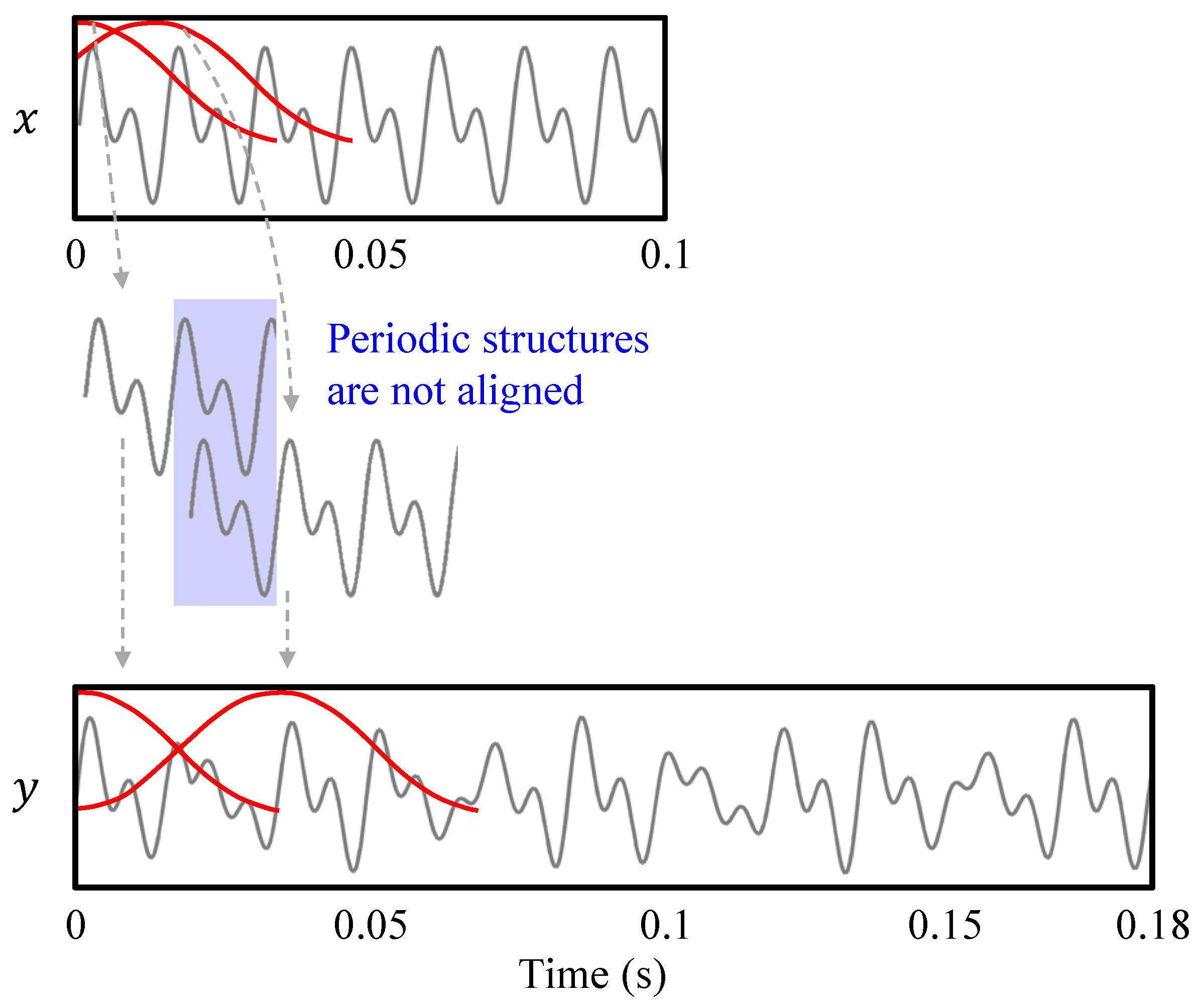
3.2. Artifacts
3.3. Tricks of the Trade
4. TSM Based on Waveform Similarity Overlap-Add (WSOLA)
4.1. The Procedure
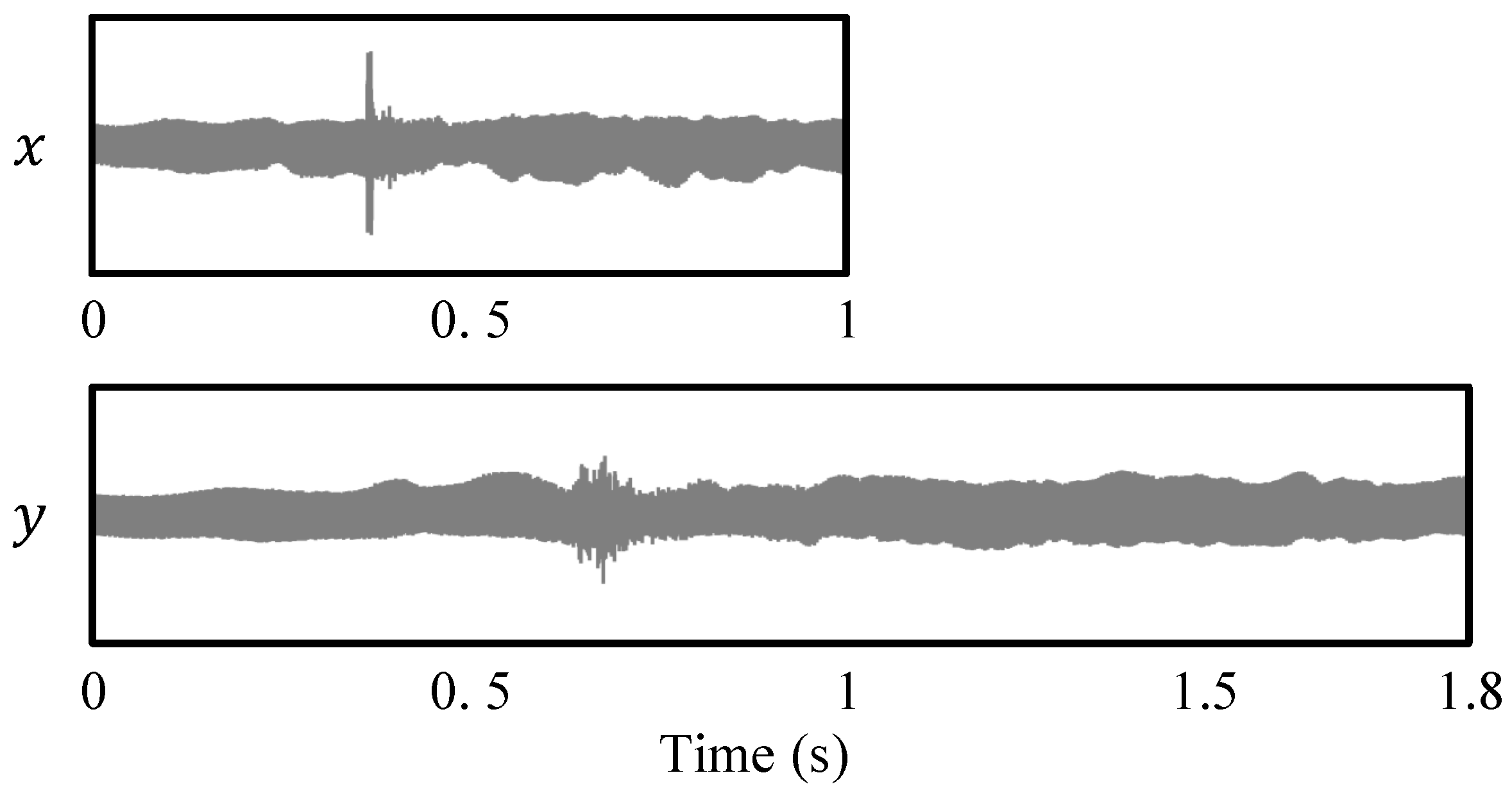
4.2. Artifacts
4.3. Tricks of the Trade
5. TSM Based on the Phase Vocoder (PV-TSM)
5.1. Overview
5.2. The Short-Time Fourier Transform
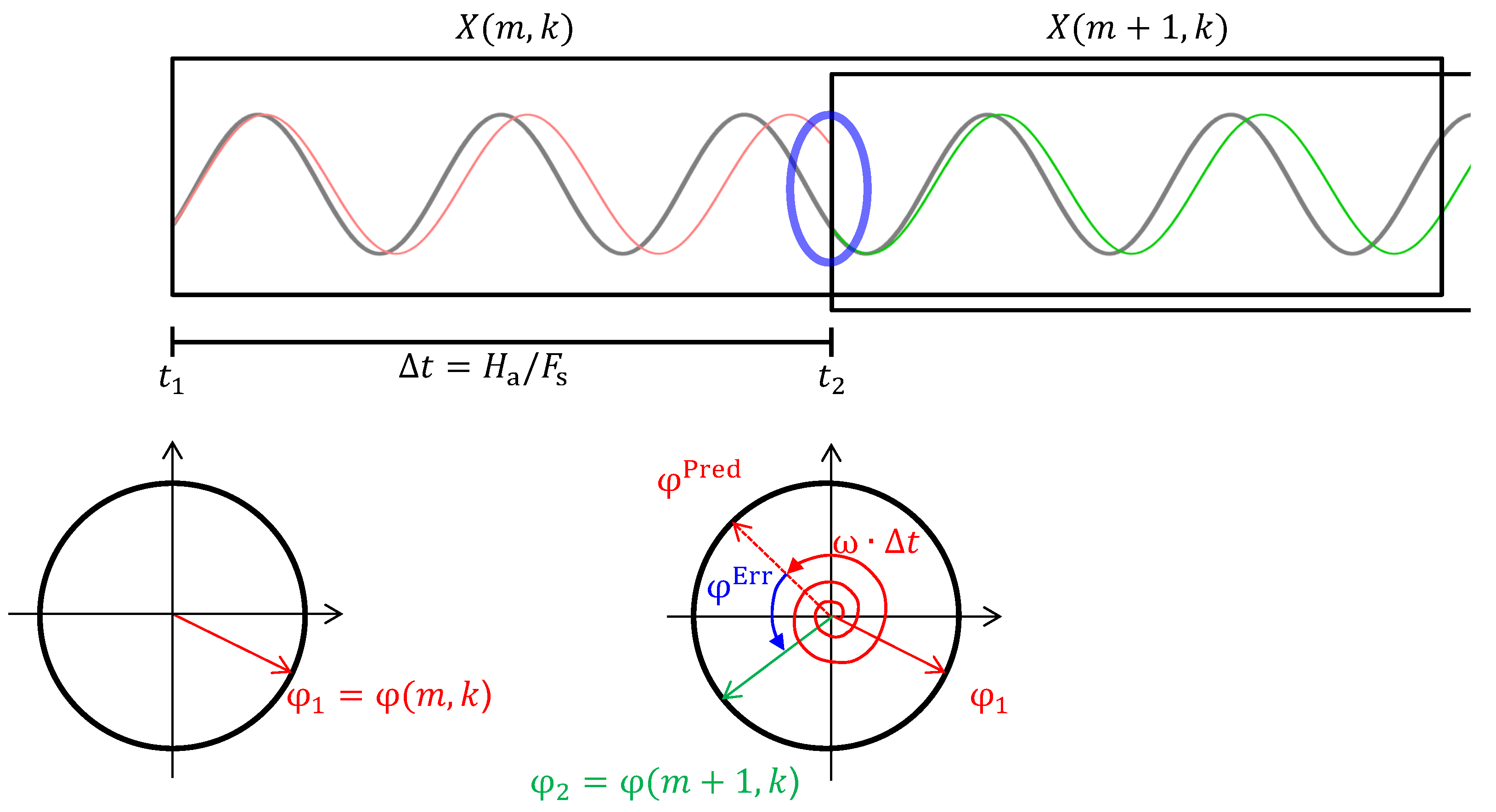
5.3. The Phase Vocoder
5.4. PV-TSM
5.5. Artifacts
5.6. Tricks of the Trade
6. TSM Based on Harmonic-Percussive Separation
6.1. The Procedure
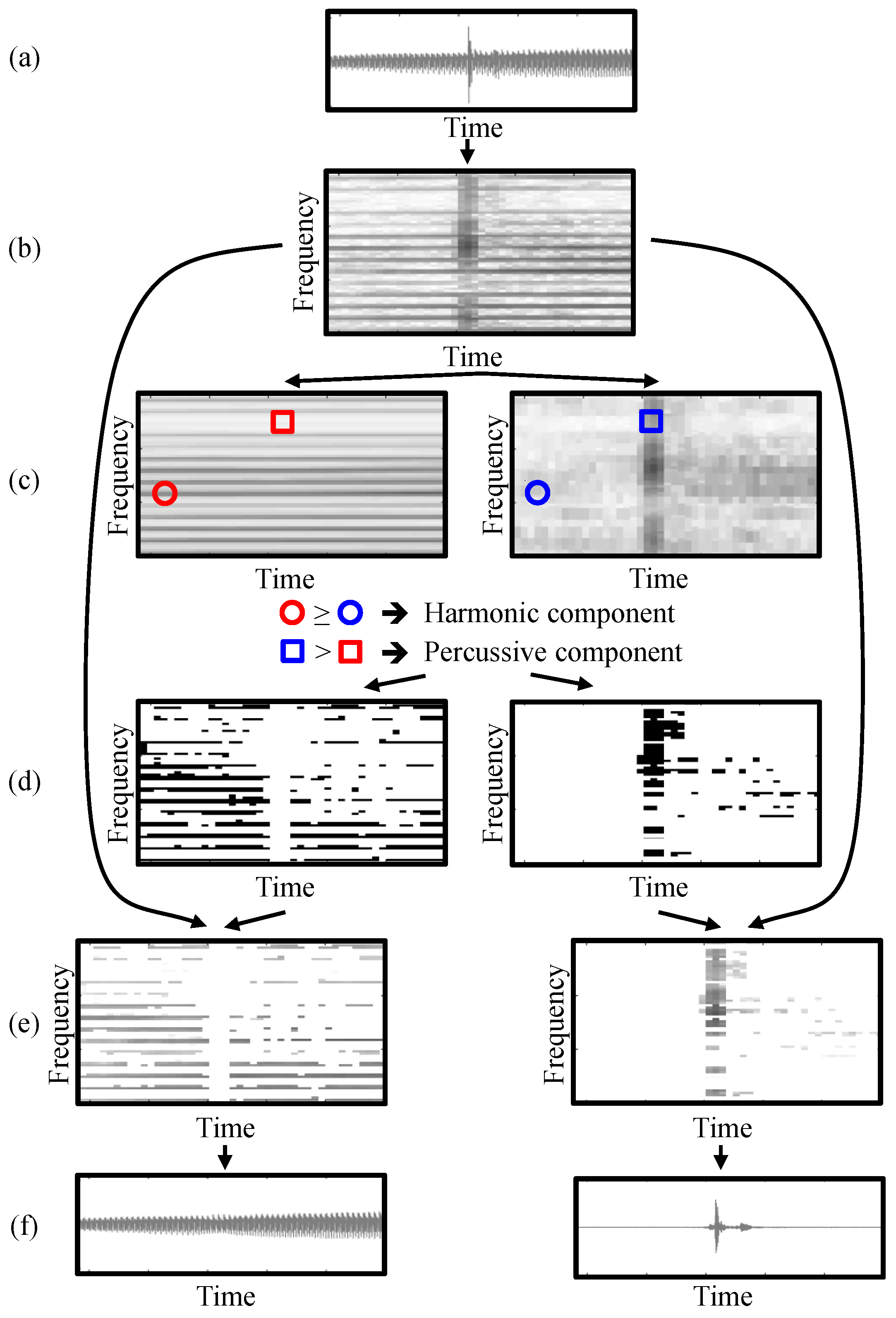
6.2. Harmonic-Percussive Separation
7. Applications
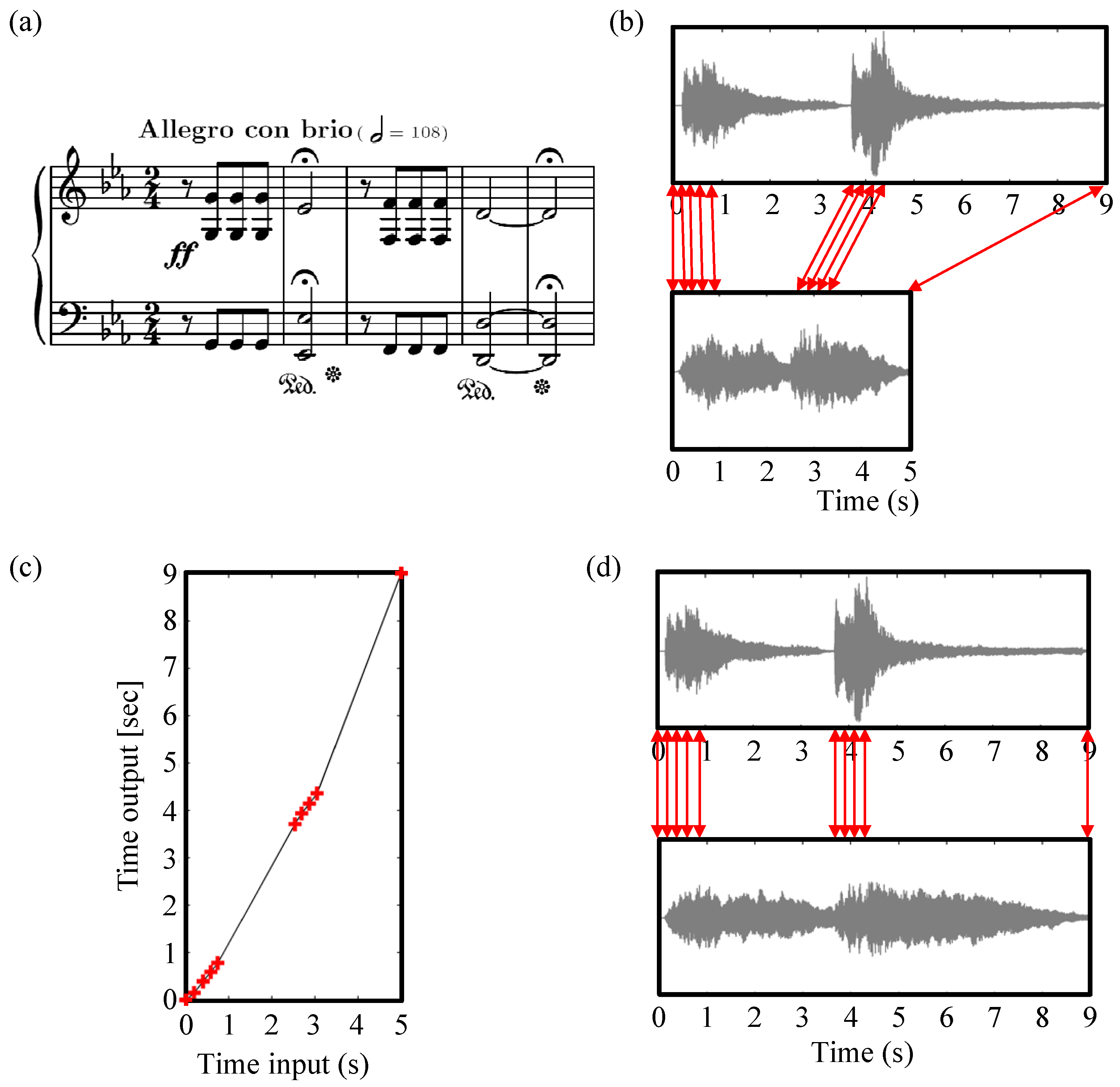
7.1. Music Synchronization—Non-Linear TSM
7.2. Pitch-Shifting
7.3. Websources
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cliff, D. Hang the DJ: Automatic Sequencing and Seamless Mixing of Dance-Music Tracks; Technical Report; HP Laboratories Bristol: Bristol, Great Britain, 2000. [Google Scholar]
- Ishizaki, H.; Hoashi, K.; Takishima, Y. Full-automatic DJ mixing system with optimal tempo adjustment based on measurement function of user discomfort. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Kobe, Japan, 26–30 October 2009; pp. 135–140.
- Moinet, A.; Dutoit, T.; Latour, P. Audio time-scaling for slow motion sports videos. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Maynooth, Ireland, 2–5 September 2013.
- Verhelst, W.; Roelands, M. An overlap-add technique based on waveform similarity (WSOLA) for high quality time-scale modification of speech. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Minneapolis, MN, USA, 27–30 April 1993.
- Flanagan, J.L.; Golden, R.M. Phase vocoder. Bell Syst. Tech. J. 1966, 45, 1493–1509. [Google Scholar] [CrossRef]
- Laroche, J.; Dolson, M. Improved phase vocoder time-scale modification of audio. IEEE Trans. Speech Audio Process. 1999, 7, 323–332. [Google Scholar] [CrossRef]
- Portnoff, M.R. Implementation of the digital phase vocoder using the fast Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 243–248. [Google Scholar] [CrossRef]
- Driedger, J.; Müller, M.; Ewert, S. Improving time-scale modification of music signals using harmonic-percussive separation. IEEE Signal Process. Lett. 2014, 21, 105–109. [Google Scholar] [CrossRef]
- Zölzer, U. DAFX: Digital Audio Effects; John Wiley & Sons, Inc.: New York, NY, USA, 2002. [Google Scholar]
- Roucos, S.; Wilgus, A.M. High quality time-scale modification for speech. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Tampa, Florida, USA, 26–29 April 1985; Volume 10, pp. 493–496.
- Moulines, E.; Charpentier, F. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Commun. 1990, 9, 453–467. [Google Scholar] [CrossRef]
- Laroche, J. Autocorrelation method for high-quality time/pitch-scaling. In Proceedings of the IEEE Workshop Applications of Signal Processing to Audio and Acoustics (WASPAA), Mohonk, NY, USA, 17–20 October 1993; pp. 131–134.
- Grofit, S.; Lavner, Y. Time-scale modification of audio signals using enhanced WSOLA with management of transients. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 106–115. [Google Scholar] [CrossRef]
- Gabor, D. Theory of communication. J. Inst. Electr. Eng. IEE 1946, 93, 429–457. [Google Scholar] [CrossRef]
- Müller, M. Fundamentals of Music Processing; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Griffin, D.W.; Lim, J.S. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Dolson, M. The phase vocoder: A tutorial. Comput. Music J. 1986, 10, 14–27. [Google Scholar] [CrossRef]
- Laroche, J.; Dolson, M. Phase-vocoder: About this phasiness business. In Proceedings of the IEEE ASSP Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 19–22 October 1997.
- Dorran, D.; Lawlor, R.; Coyle, E. A hybrid time-frequency domain approach to audio time-scale modification. J. Audio Eng. Soc. 2006, 54, 21–31. [Google Scholar]
- Kraft, S.; Holters, M.; von dem Knesebeck, A.; Zölzer, U. Improved PVSOLA time stretching and pitch shifting for polpyhonic audio. In Proceedings of the International Conference on Digital Audio Effects (DAFx), York, UK, 17–21 September 2012.
- Moinet, A.; Dutoit, T. PVSOLA: A phase vocoder with synchronized overlapp-add. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Paris, France, 19–23 September 2011; pp. 269–275.
- Nagel, F.; Walther, A. A novel transient handling scheme for time stretching algorithms. In Proceedings of the AES Convention, New York, NY, USA, 2009; pp. 185–192.
- Fitzgerald, D. Harmonic/percussive separation using median filtering. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Graz, Austria, 6–10 September 2010; pp. 246–253.
- Verma, T.S.; Meng, T.H. Time scale modification using a sines+transients+noise signal model. In Proceedings of the Digital Audio Effects Workshop (DAFx98), Barcelona, Spain, 19–21 November 1998.
- Levine, S. N.; Smith, J.O., III. A sines+transients+noise audio representation for data compression and time/pitch scale modications. In Proceedings of the AES Convention, Amsterdam, The Netherlands, 16–19 May 1998.
- Verma, T.S.; Meng, T.H. An analysis/synthesis tool for transient signals that allows a flexible sines+transients+noise model for audio. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Seattle, Washington, DC, USA, 12–15 May 1998; pp. 3573–3576.
- Verma, T.S.; Meng, T.H. Extending spectral modeling synthesis with transient modeling synthesis. Comput. Music J. 2000, 24, 47–59. [Google Scholar] [CrossRef]
- Serra, X.; Smith, J.O. Spectral modeling synthesis: A sound analysis/synthesis system based on a deterministic plus stochastic decomposition. Comput. Music J. 1990, 14, 12–24. [Google Scholar] [CrossRef]
- Duxbury, C.; Davies, M.; Sandler, M. Improved time-scaling of musical audio using phase locking at transients. In Proceedings of Audio Engineering Society Convention, Munich, Germany, 10–13 May 2002.
- Cañadas-Quesada, F.J.; Vera-Candeas, P.; Ruiz-Reyes, N.; Carabias-Orti, J.J.; Molero, P.C. Percussive/harmonic sound separation by non-negative matrix factorization with smoothness/sparseness constraints. EURASIP J. Audio Speech Music Process. 2014. [Google Scholar] [CrossRef]
- Duxbury, C.; Davies, M.; Sandler, M. Separation of transient information in audio using multiresolution analysis techniques. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Limerick, Ireland, 17–22 September 2001.
- Gkiokas, A.; Papavassiliou, V.; Katsouros, V.; Carayannis, G. Deploying nonlinear image filters to spectrograms for harmonic/percussive separation. In Proceedings of the International Conference on Digital Audio Effects (DAFx), York, UK, 17–21 September 2012.
- Ono, N.; Miyamoto, K.; LeRoux, J.; Kameoka, H.; Sagayama, S. Separation of a monaural audio signal into harmonic/percussive components by complementary diffusion on spectrogram. In Proceedings of the European Signal Processing Conference, Lausanne, Switzerland, 25–29 August 2008; pp. 240–244.
- Park, J.; Lee, K. Harmonic-percussive source separation using harmonicity and sparsity constraints. In Proceedings of the International Conference on Music Information Retrieval (ISMIR), Málaga, Spain, 26–30 October 2015; pp. 148–154.
- Tachibana, H.; Ono, N.; Kameoka, H.; Sagayama, S. Harmonic/percussive sound separation based on anisotropic smoothness of spectrograms. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 2059–2073. [Google Scholar] [CrossRef]
- Müller, M.; Driedger, J. Data-driven sound track generation. In Multimodal Music Processing; Müller, M., Goto, M., Schedl, M., Eds.; Schloss Dagstuhl–Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2012; Volume 3, pp. 175–194. [Google Scholar]
- Haghparast, A.; Penttinen, H.; Välimäki, V. Real-time pitch-shifting of musical signals by a time-varying factor using normalized filtered correlation time-scale modification. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Bordeaux, France, 10–15 September 2007; pp. 7–14.
- Schörkhuber, C.; Klapuri, A.; Sontacchi, A. Audio pitch shifting using the constant-q transform. J. Audio Eng. Soc. 2013, 61, 562–572. [Google Scholar]
- Alvin and the Chipmunks—Recording Technique. Available online: https://en.wikipedia.org/wiki/Alvin_and_the_Chipmunks#Recording_technique (accessed on 3 December 2015).
- Markel, J.D.; Gray, A.H. Linear Prediction of Speech; Springer Verlag: Secaucus, NJ, USA, 1976. [Google Scholar]
- Röbel, A.; Rodet, X. Efficient spectral envelope estimation an its application to pitch shifting and envelope preservation. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Madrid, Spain, 20–22 September 2005.
- Röbel, A.; Rodet, X. Real time signal transposition with envelope preservation in the phase vocoder. In Proceedings of the International Computer Music Conference (ICMC), Barcelona, Spain, 5–9 September 2005; pp. 672–675.
- Driedger, J.; Müller, M. TSM Toolbox. Available online: http://www.audiolabs-erlangen.de/resources/ matlab/pvoc/ (accessed on 5 February 2016).
- Driedger, J.; Müller, M. TSM Toolbox: MATLAB implementations of time-scale modification algorithms. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Erlangen, Germany, 1–5 September 2014; pp. 249–256.
- Ellis, D.P.W. A Phase Vocoder in Matlab. Available online: http://www.ee.columbia.edu/dpwe/resources/ matlab/pvoc/ (accessed on 3 December 2015).
- McFee, B. Librosa—Time Stretching. Available online: https://bmcfee.github.io/librosa/generated/librosa.effects.time_stretch.html (accessed on 3 December 2015).
- Breakfast Quay. Rubber Band Library. Aailable online: http://breakfastquay.com/rubberband/ (accessed on 26 November 2015).
- Parviainen, O. Soundtouch Audio Processing Library. Available online: http://www.surina.net/soundtouch/ (accessed on 27 November 2015).
- Zplane Development. Élastique Time Stretching & Pitch Shifting SDKs. Available online: http://www.zplane.de/index.php?page=description-elastique (accessed on 5 February 2016).

















© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Driedger, J.; Müller, M. A Review of Time-Scale Modification of Music Signals. Appl. Sci. 2016, 6, 57. https://doi.org/10.3390/app6020057
Driedger J, Müller M. A Review of Time-Scale Modification of Music Signals. Applied Sciences. 2016; 6(2):57. https://doi.org/10.3390/app6020057
Chicago/Turabian StyleDriedger, Jonathan, and Meinard Müller. 2016. "A Review of Time-Scale Modification of Music Signals" Applied Sciences 6, no. 2: 57. https://doi.org/10.3390/app6020057
APA StyleDriedger, J., & Müller, M. (2016). A Review of Time-Scale Modification of Music Signals. Applied Sciences, 6(2), 57. https://doi.org/10.3390/app6020057