A 2D-View Depth Image- and CNN-Based 3D Model Identification Method


Abstract
:1. Introduction
1.1. View-Based 3D Model Similarity Measurement
1.2. CNN
2. Materials and Methods
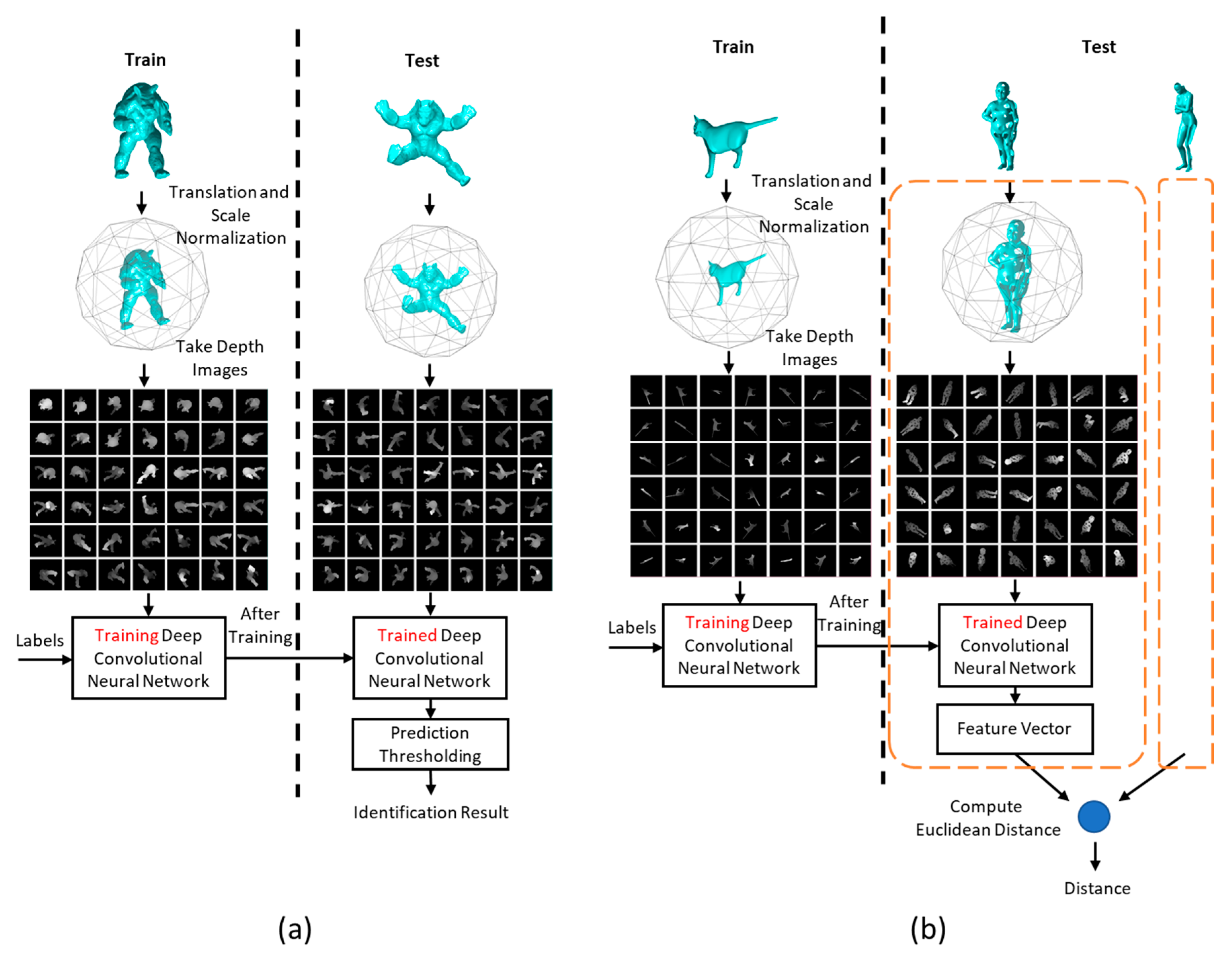
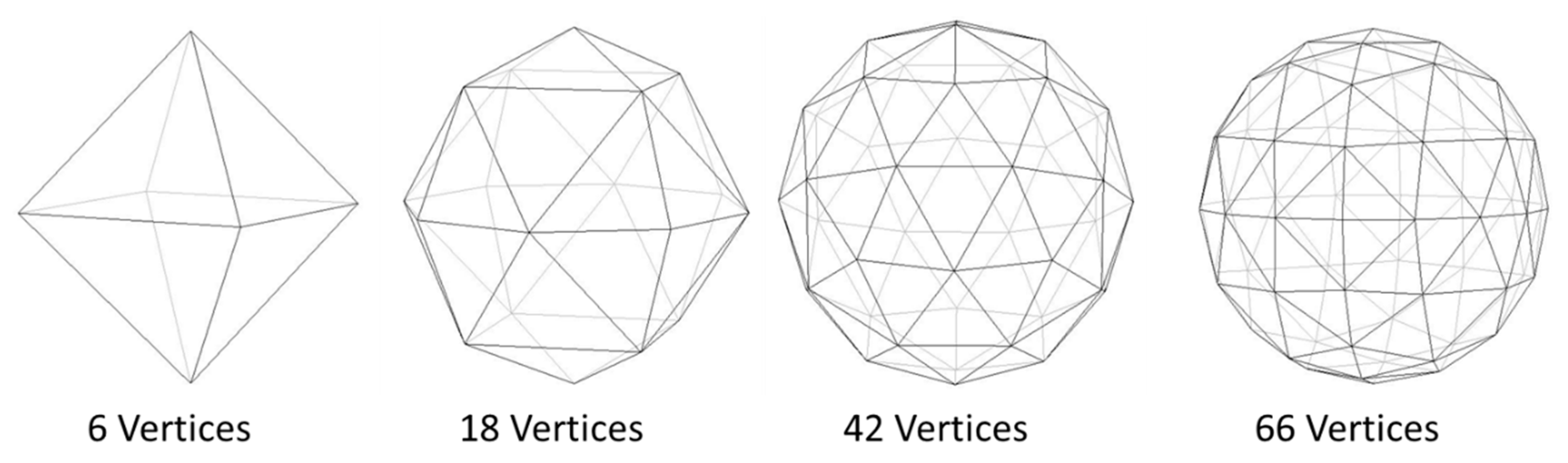
2.1. The Proposed Method
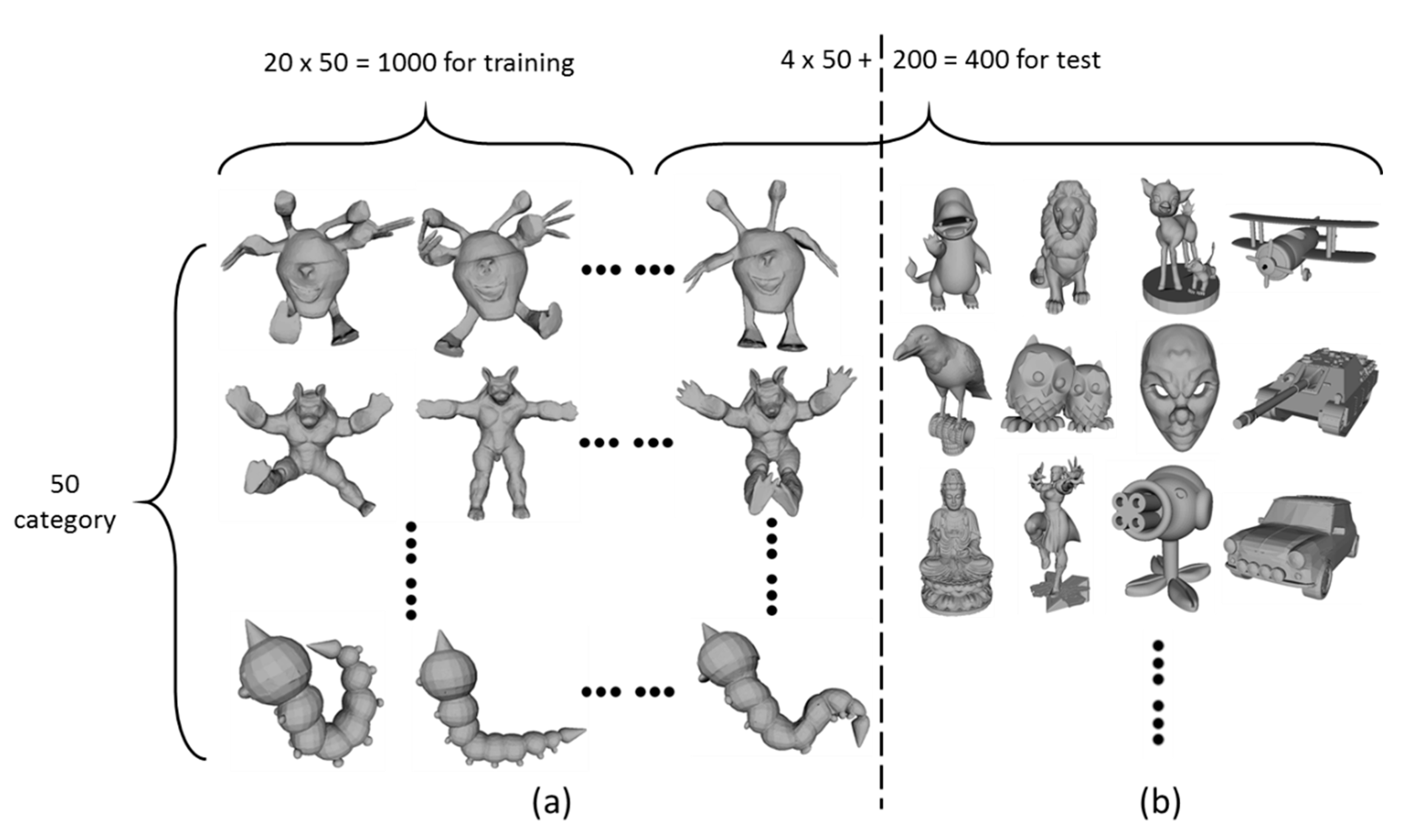
2.2. Dataset of SHREC’15 Non-Rigid 3D Shape Retrieval
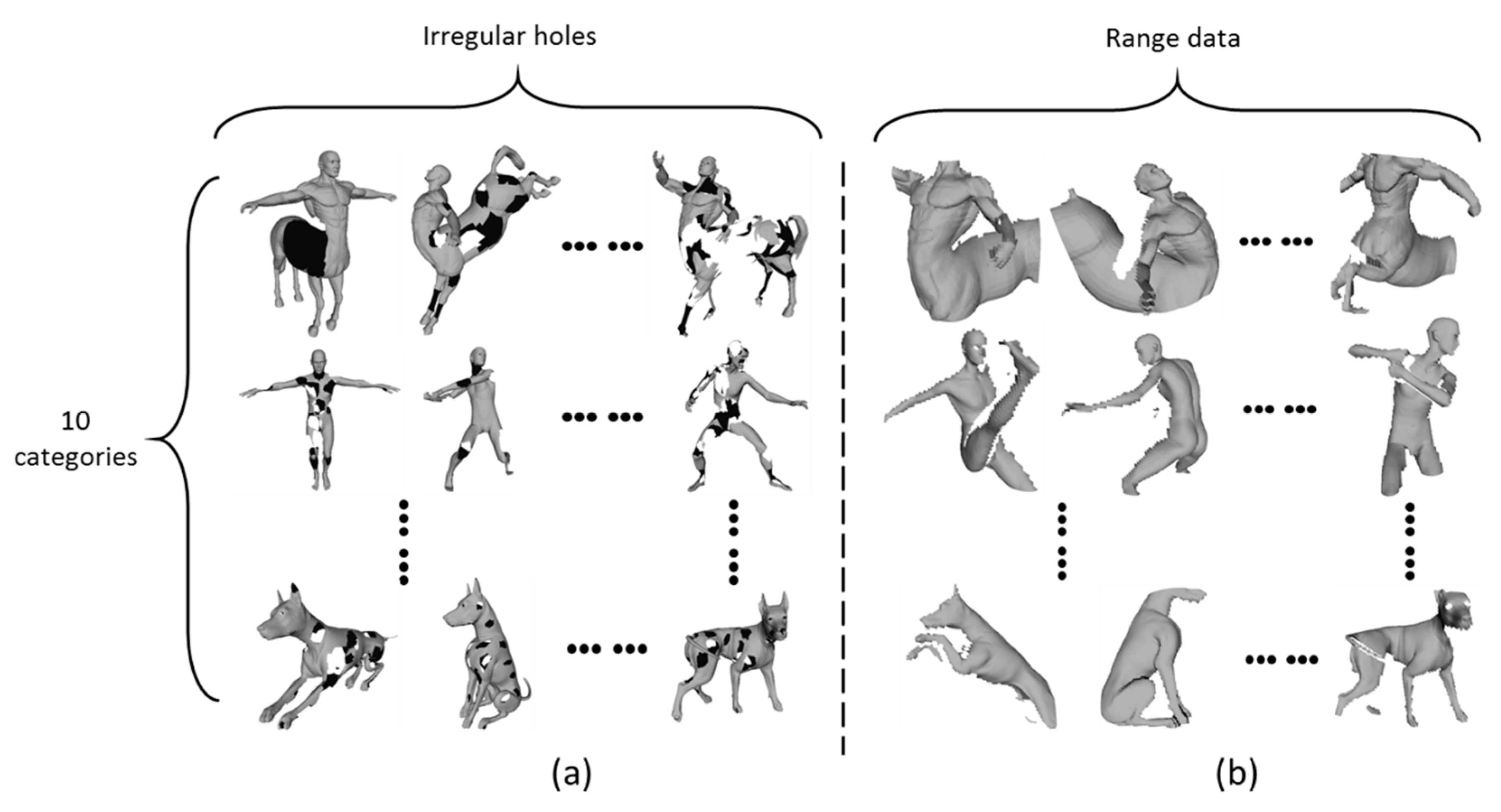
2.3. The Dataset of SHREC’17 Deformable Shape Retrieval with Missing Parts
3. Experimental Results
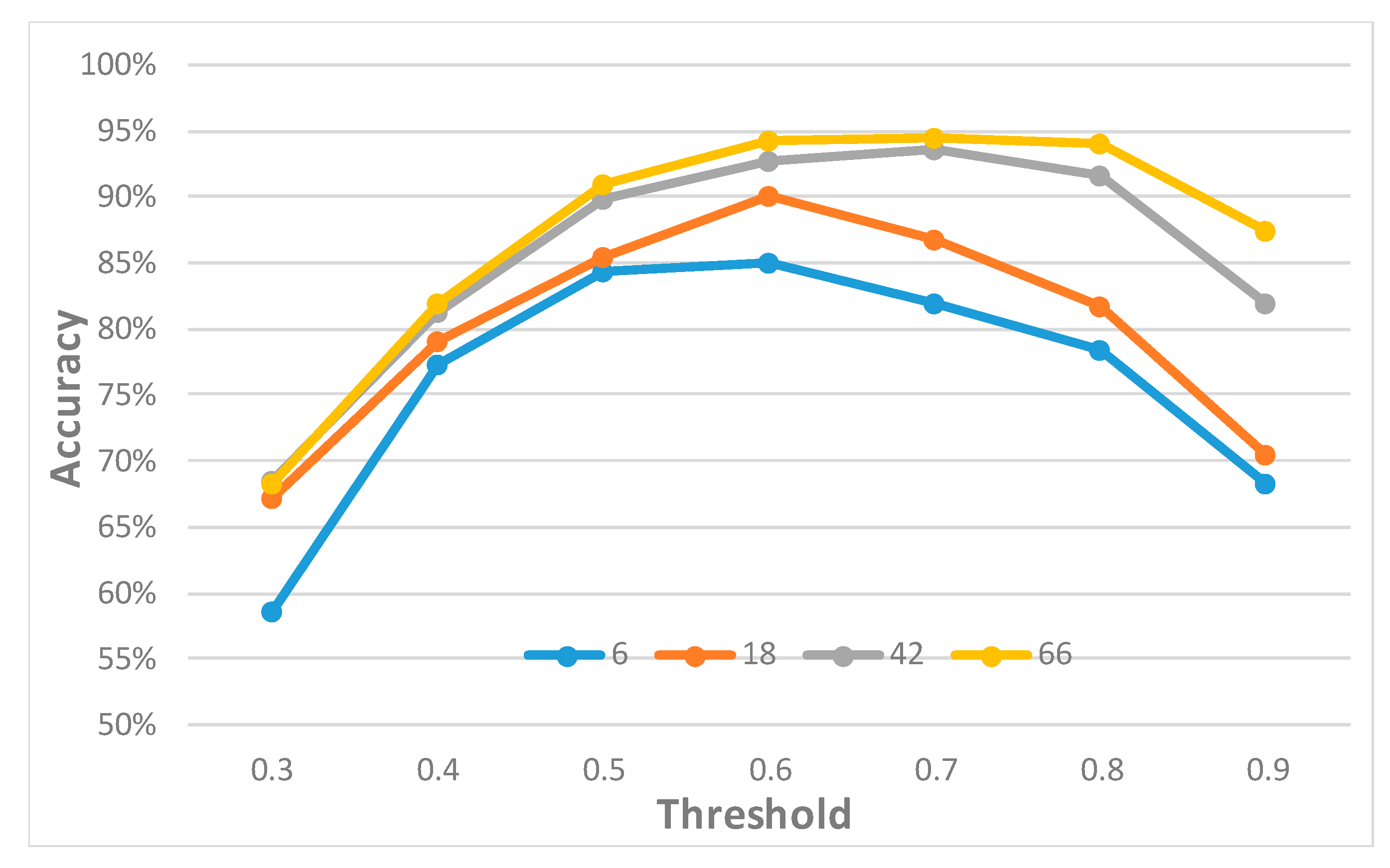
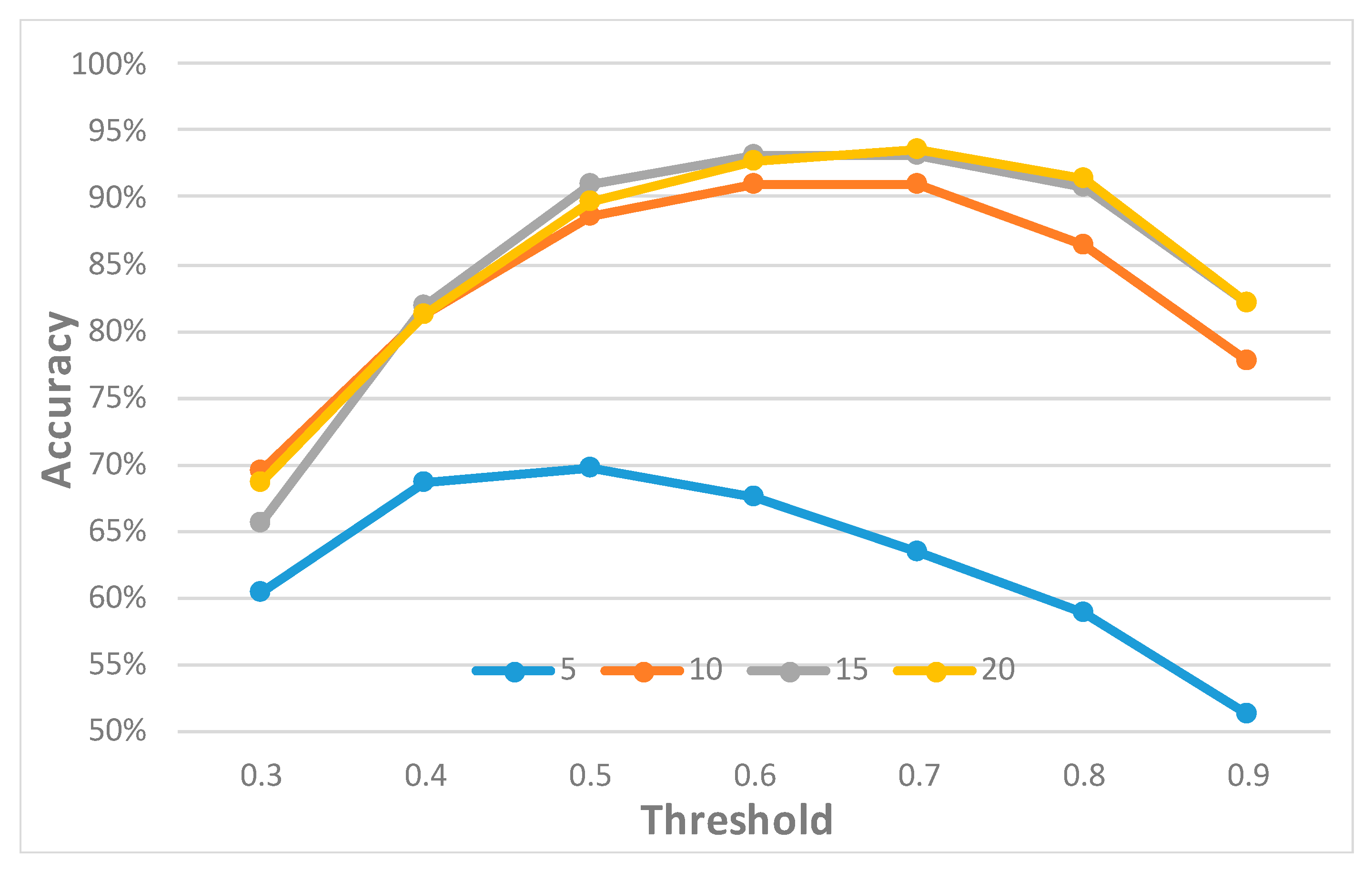
3.1. 3D Model Identification
- True Positive: If a query 3D model is a deformed version of an original copyrighted 3D model () and the identification system correctly identifies the query 3D model.
- True Negative: If a query 3D model is irrelevant () and the identification system correctly identifies it as irrelevant.
- False Positive: If a query 3D model is irrelevant () but the identification system wrongly identifies it as one of the 3D models in the database, or if a query 3D model is a deformed version of an original copyrighted 3D model (), but the identification system identifies it as a wrong one in the database, which means the query is not the deformed version of the 3D model that was identified by the system.
- False Negative: If a query 3D model is a deformed version of an original copyrighted 3D model (), but the identification system identifies it as irrelevant.
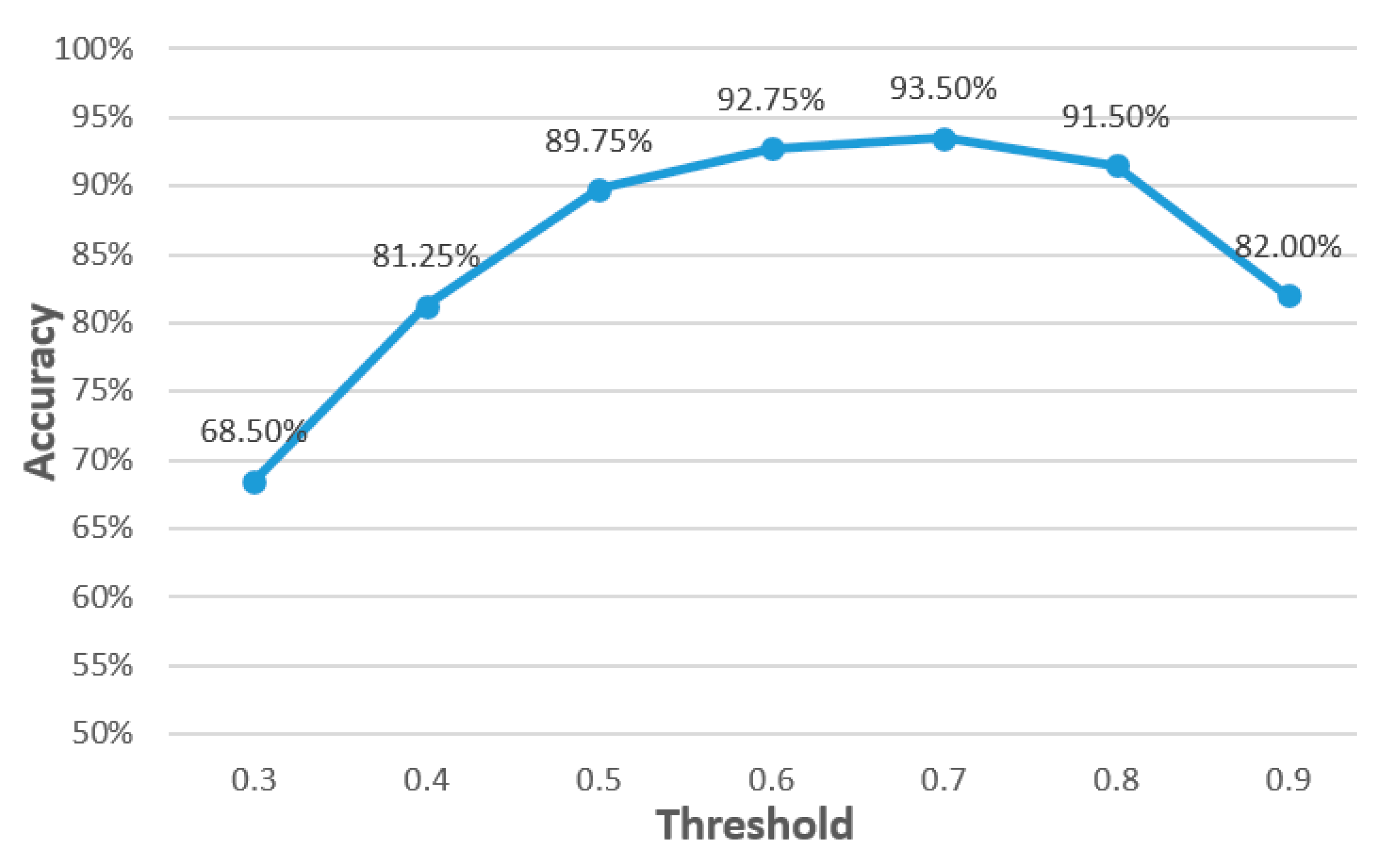
- Accuracy:
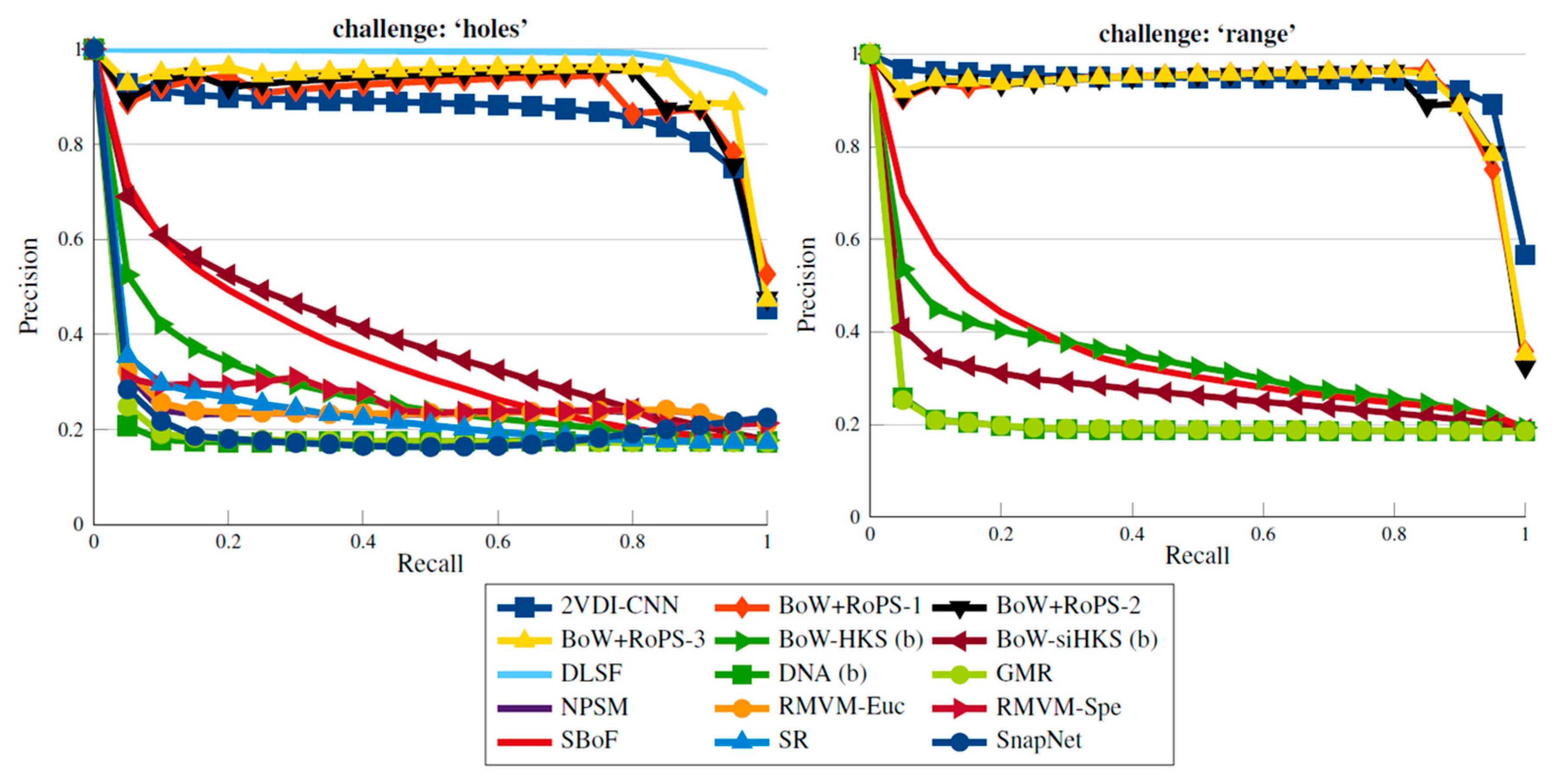
3.2. Deformable 3D Model Retrieval with Missing Parts
- Nearest neighbor: The percentage of best matches that belong to the query’s class.
- First tier and second tier: The percentage of models belonging to the query’s class that appear within the top and 2 matches where the number of models in the query’s class is K.
- Discounted cumulative gain: A statistic that weights correct results near the front of the list more than correct results later in the ranked list.
- Precision-recall curve: Precision is the ratio of retrieved models that are relevant to a given query, while recall is the ratio of relevant models to a given query that have been retrieved from the total number of relevant models. Thus, a higher P-R curve indicates better retrieval performance.
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ishengoma, F.R.; Mtaho, A.B. 3D Printing Developing Countries Perspectives. Int. J. Comput. Appl. 2014, 104, 30–34. [Google Scholar] [CrossRef]
- Pirjan, A.; Petrosanu, D.-M. The Impact of 3D Printing Technology on the Society and Economy. J. Inf. Syst. Oper. Manag. 2013, 7, 360–370. [Google Scholar]
- Weinberg, M. What’s the Deal with Copyright and 3D Printing? Available online: https://www.publicknowledge.org/files/What%27s%20the%20Deal%20with%20Copyright_%20Final%20version2.pdf (accessed on 7 August 2017).
- Gupta, D.; Tarlock, M. 3D Printing, Copyright Challenges, and the DMCA. New Matter 2013, 38, 1–16. Available online: http://www.fbm.com/files/Uploads/Documents/3D%20Printing%20Copyright%20Challenges%20and%20the%20DMCA.pdf (accessed on 24 September 2017).
- Milano, D. Content Control: Digital Watermarking and Fingerprinting. Available online: http://www.rhozet.com/whitepapers/Fingerprinting-Watermarking.pdf (accessed on 7 August 2017).
- Chen, D.; Tian, X.; Shen, M. On Visual Similarity based 3D Model Retrieval. Eurographics 2003, 22, 223–232. [Google Scholar] [CrossRef]
- Papadakis, P.; Pratikakis, I.; Perantonis, S.J.; Theoharis, T. Efficient 3D Shape Matching and Retrieval using A Concrete Radialized Spherical Projection Representation. Pattern Recognit. 2007, 40, 2437–2452. [Google Scholar] [CrossRef]
- Ohbuchi, R.; Osada, K.; Furuya, T.; Banno, T. Salient Local Visual Features for Shape-Based 3D Model Retrieval. In Proceedings of the IEEE International Conference on Shape Modeling and Applications (SMI’08), Stony Brook, New York, NY, USA, 4–6 June 2008; pp. 93–102. [Google Scholar] [CrossRef]
- Lian, Z.; Godil, A.; Sun, X. Visual Similarity based 3D Shape Retrieval using Bag-of-Features. In Proceedings of the IEEE International Conference on Shape Modeling and Applications (SMI’10), Aix-en-Provence, France, 21–23 June 2010. [Google Scholar] [CrossRef]
- Chaouch, M.; Verroust-Blondet, A. Alignment of 3D Models. Graph. Models 2009, 71, 63–76. [Google Scholar] [CrossRef]
- Johan, H.; Li, B.; Wei, Y. 3D Model Alignment based on Minimum Projection Area. Vis. Comput. 2011, 27, 565–574. [Google Scholar] [CrossRef]
- Shih, J.L.; Lee, C.H.; Wang, J. A New 3D Model Retrieval Approach based on the Elevation Descriptor. Pattern Recognit. 2007, 40, 283–295. [Google Scholar] [CrossRef]
- Chaouch, M.; Verroust-Blondet, A. 3D Model Retrieval based on Depth Line Descriptor. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007. [Google Scholar] [CrossRef]
- Daras, P.; Axenopoulos, A. A Compact Multi-View Descriptor for 3D Object Retrieval. In Proceedings of the 2009 Seventh International Workshop on Content-Based Multimedia Indexing, Chania, Greece, 3–5 June 2009. [Google Scholar] [CrossRef]
- Papadakis, P.; Pratikakis, I.; Theoharis, T.; Perantonis, S. PANORAMA: A 3D Shape Descriptor Based on Panoramic Views for Unsupervised 3D Object Retrieval. Int. J. Comput. Vis. 2010, 89, 117–192. [Google Scholar] [CrossRef]
- Lian, Z.; Zhang, J.; Choi, S.; ElNaghy, H.; El-Sana, J.; Furuya, T.; Giachetti, A.; Guler, R.A.; Lai, L.; Li, C.; et al. SHREC’15 Track: Non-rigid 3D Shape Retrieval. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Zurich, Switzerland, 2–3 May 2015. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Milolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Heinly, J.; Dunn, E.; Frahm, J.-M. Comparative Evaluation of Binary Features. In Computer Vision–ECCV; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7573, pp. 759–773. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2006. [Google Scholar]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual Categorization with Bags of Keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision (ECCV’04), Prague, Czech Republic, 11–14 May 2004. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.-R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014. [Google Scholar] [CrossRef]
- Rodola, E.; Cosmo, L.; Litany, O.; Bronstein, M.M.; Bronstein, A.M.; Audebert, N.; Hamza, A.B.; Boulch, A.; Castellani, U.; Do, M.N.; et al. SHREC’17: Deformable Shape Retrieval with Missing Parts. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Lisbon, Portugal, 23–24 April 2017. [Google Scholar] [CrossRef]
- Shilane, P.; Min, P.; Kazhdan, M.; Funkhouser, T. The Princeton Shape Benchmark. In Proceedings of the Shape Modeling International (SMI’04), Genova, Italy, 7–9 June 2004. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1: 2: /* get prediction values*/ 3: if 4: if 5: /*correctly identified the 3D model*/ 6: else 7: /* wrongly identified*/ 8: end 9: else /* copyrighted one is missed by the system*/ 10: 11: end 12: 13: 14: 15: if 16: /*correctly rejected irrelevant 3D model*/ 17: else 18: /* wrongly identified*/ 19: end |
| Threshold | True Positive | True Negative | False Positive | False Negative | Accuracy |
|---|---|---|---|---|---|
| 0.3 | 199 | 75 | 125 | 1 | 68.50% |
| 0.4 | 199 | 126 | 74 | 1 | 81.25% |
| 0.5 | 198 | 161 | 39 | 2 | 89.75% |
| 0.6 | 193 | 178 | 22 | 7 | 92.75% |
| 0.7 | 183 | 191 | 9 | 17 | 93.50% |
| 0.8 | 172 | 194 | 6 | 28 | 91.50% |
| 0.9 | 131 | 197 | 3 | 69 | 82.00% |
| Method | NN | 1-Tier | 2-Tier | DCG |
|---|---|---|---|---|
| DLSF | 1.000 | 0.971 | 0.999 | 0.998 |
| 2VDI-CNN (ours) | 0.906 | 0.818 | 0.937 | 0.954 |
| SBoF | 0.815 | 0.326 | 0.494 | 0.780 |
| BoW-siHKS | 0.710 | 0.370 | 0.566 | 0.790 |
| BoW+RoPS-3 | 0.607 | 0.918 | 0.970 | 0.968 |
| BoW+RoPS-1 | 0.597 | 0.877 | 0.963 | 0.956 |
| BoW-HKS | 0.578 | 0.261 | 0.436 | 0.725 |
| RMVM-Euc | 0.392 | 0.226 | 0.402 | 0.679 |
| BoW+RoPS-2 | 0.380 | 0.894 | 0.965 | 0.955 |
| NPSM | 0.347 | 0.222 | 0.395 | 0.676 |
| RMVM-Spe | 0.251 | 0.228 | 0.410 | 0.676 |
| SR | 0.241 | 0.225 | 0.395 | 0.676 |
| GMR | 0.186 | 0.172 | 0.343 | 0.642 |
| SnapNet | 0.117 | 0.172 | 0.349 | 0.641 |
| DNA | 0.078 | 0.163 | 0.348 | 0.632 |
| Method | NN | 1-Tier | 2-Tier | DCG |
|---|---|---|---|---|
| 2VDI-CNN (ours) | 0.969 | 0.906 | 0.977 | 0.980 |
| SBoF | 0.811 | 0.317 | 0.510 | 0.769 |
| BoW+RoPS-2 | 0.643 | 0.910 | 0.962 | 0.962 |
| BoW+RoPS-3 | 0.639 | 0.908 | 0.964 | 0.965 |
| BoW-HKS | 0.519 | 0.326 | 0.537 | 0.736 |
| BoW+RoPS-1 | 0.515 | 0.915 | 0.959 | 0.960 |
| BoW-siHKS | 0.377 | 0.268 | 0.485 | 0.699 |
| GMR | 0.178 | 0.184 | 0.371 | 0.640 |
| DNA | 0.130 | 0.183 | 0.366 | 0.640 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, Y.; Kim, J. A 2D-View Depth Image- and CNN-Based 3D Model Identification Method. Appl. Sci. 2017, 7, 988. https://doi.org/10.3390/app7100988
Hong Y, Kim J. A 2D-View Depth Image- and CNN-Based 3D Model Identification Method. Applied Sciences. 2017; 7(10):988. https://doi.org/10.3390/app7100988
Chicago/Turabian StyleHong, Yiyu, and Jongweon Kim. 2017. "A 2D-View Depth Image- and CNN-Based 3D Model Identification Method" Applied Sciences 7, no. 10: 988. https://doi.org/10.3390/app7100988
APA StyleHong, Y., & Kim, J. (2017). A 2D-View Depth Image- and CNN-Based 3D Model Identification Method. Applied Sciences, 7(10), 988. https://doi.org/10.3390/app7100988