1. Introduction
Foreground detection based on change detection is the first step in numerous computer vision applications. Output of the background subtraction is usually an input to a post-higher level process, such as video surveillance, object tracking or activity recognition. Therefore, its performance has a huge effect on the performance of higher level tasks. Needless to say, the quality of many computer vision applications directly depends on the quality of the background subtraction method used.
The general idea of background subtraction is to automatically generate a binary mask which classifies the set of pixels into foreground and background. In the simplest case, disparities between the current frame and a background reference frame are usually indicative of foreground objects; this might work in certain specialized scenarios. However, finding a good empty background reference frame in order to perform actual “background subtraction” is always impossible due to the complexity of real-world scenes, due to, for example, illumination changes and dynamic backgrounds. Thus, a multitude of more sophisticated methods have been proposed in the recent past [
1,
2]. Their efforts mainly focus on two aspects: the first takes on more sophisticated learning modes, while employs more powerful feature representations.
In the early research stage, researchers assumed that the history of the pixel’s intensity could be modeled by some distributions. Following this idea, Wren et al. [
3] proposed using a single-Gaussian model to model the distribution of intensities at each pixel location. However, a single model cannot handle dynamic scenes when there is rippling of water or waving trees. Then, a Gaussian mixture model [
4] was proposed to solve this problem, which models the color intensities at each pixel location using a mixture of Gaussian probability density functions. Many improvements were developed to make it more adaptive and robust to critical situations. For example, in [
5], the authors extended this idea by allowing dynamic Gaussian numbers to model each pixel as well as to improve their convergence rate. In another work, Allili et al. [
6] proposed a mixture of general Gaussian to alleviate the constraint of strict Gaussian. However, the Gaussian assumption for pixel intensity distribution is not always true in practical applications. Hence, a nonparametric approach based on Kernel Density Estimation (KDE) was proposed in [
7], which builds a statistical representation of the scene background by estimating the probability density function directly from the data without any priori assumptions. In [
8], to reduce the burden of image storage, Jeisung et al. modified the KDE method by using an adaptive learning rate according to different situations, which allows the model to automatically adapt to various environments. However, the KDEs are time-consuming, and most of them update their models in a first-in-first-out (FIFO) strategy. Thus, they are unable to model both short-term and long-term periodic events.
The authors of [
9] presented an alternative approach to solve the above problem. For each pixel, a codebook is constructed and consists of one or more codewords; history samples at each pixel location are clustered into a set of codewords based on a color distortion metric together with brightness bounds. The number of codewords in each codebook is different following the pixel’s activities. During the detection phase, if the current pixel is similar to one of the codewords, it is classified as a background pixel; otherwise, it will be considered as a foreground pixel. The codebook representation is efficient in speed and memory compared with other traditional models, and the original algorithm has also been improved in several ways. For examples, Sigari et al. [
10] proposed a two-layer codebook model. The first layer in the main codebook models the current background images, while the second layer is the cache which models new background images. Wu et al. [
11] proposed an improved codebook by incorporating the spatial-temporal context of each pixel.
Unprecedented background subtraction methods based on neural networks have been proposed in [
12,
13] and achieve good results on various scenarios. The Self-Organizing Background Subtraction (SOBS) algorithm models each pixel with a neural map of weight vectors. Moving objects are detected through a map of motion and stationary patterns. The background model update at each pixel location is influenced by the labeling decision of its neighbors. As can be seen, more and more recent methods tend to account for neighboring pixels to add robustness to noise. For examples, superpixels and Markov Random Fields [
14], as well as the connected components [
15] focus on improving label coherence using advanced regularization techniques. Some other methods rely on the region level [
16,
17], frame level [
18] or hybrid frame–region level [
19].
The first non-deterministic background subtraction method, called ViBe, was proposed in [
20] and has been shown to outperform many existing methods. Instead of building the probability distribution of the background for each pixel using a Parzen window, ViBe uses a stochastic maintenance strategy to integrate new information into the model. If the pixel in the new frame matches some of the background samples, it is classified as background and has a probability of being inserted into the sample model at the corresponding pixel location. The authors show that the stochastic strategy ensures a smooth, exponentially decaying lifespan for the samples that constitute the pixel models. In order to maintain spatial consistency, a spatial information propagation strategy randomly diffuses pixel values across neighboring pixels, even the ones marked as foreground. Due to its simplicity and effectiveness, we use a similar model update strategy in our background subtraction framework.
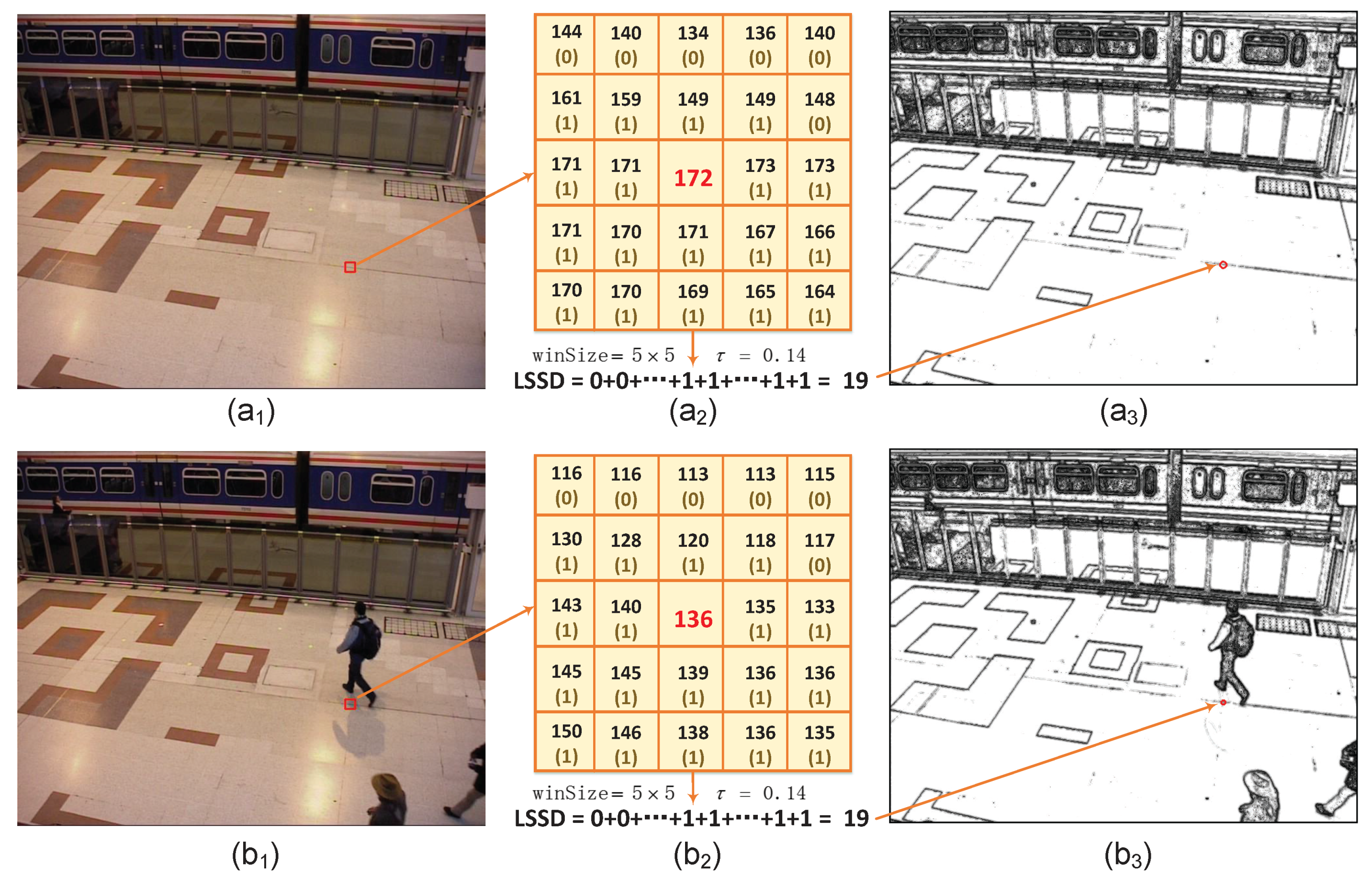
As more effective models appear, more powerful feature representations are also developed to better adapt to challenging situations. These features include color features, edge features, stereo features, motion features and texture features. The Local Binary Pattern (LBP) feature [
21] is the first texture feature proposed for background subtraction. Each pixel is modeled as a group of LBP histograms calculated over its neighborhoods. This method was demonstrated to be tolerant to illumination variations and robust against multimodal background regions, but at the expense of sensitivity to subtle local texture changes. An improved version of LBP called the Scale-Invariant Local Ternary Pattern (SILTP) was proposed in [
22], which exceeds LBP in computational efficiency and tolerance to noises. Recently, Local Binary Similarity Patterns were proposed in [
23], based on absolute difference, and were demonstrated to surpass traditional color comparisons via Hamming distance thresholding. Despite the fact that both of them are robust to illumination variations, they perform poorly in flat areas and result in “holes” in objects. Then, some researchers began to combine different features to benefit from eachother. For example, Yao et al. [
24] proposed a multi-layer background model based on color features and texture features. Han et al. [
25] proposed a background subtraction method using a Support Vector Machine over background likelihood vectors for a set of features which consist of color, gradient, and Haar-like features. More recently, St-Charles et al. [
26] performed the background subtraction by integrating the color features and the Local Binary Similarity Pattern (LBSP) features, and showed state-of-the-art performance.
In this paper, we present a robust background subtraction method which combines color features and texture features to characterize pixel representations. Our contributions lie in three aspects. First, inspired by an illumination invariant feature based on locality-sensitive histograms proposed for object tracking [
27], we develop a novel texture feature named the Local Similarity Statistical Descriptor (LSSD). The LSSD calculates the similarity between the current pixel and its neighborhood pixels. Second, the color features and LSSD features have their own merits and demerits, they can compensate each other for better performance, so a combination of color features and LSSD features are embedded in a low-cost and highly efficient background modelling framework. Third, using the change detection dataset [
28], we evaluate our method against numerous surveillance scenes and the results show that the proposed method outperforms most state-of-the-art methods.
The rest of this paper is organized as follows.
Section 2 introduces the proposed Local Similarity Statistical Descriptor (LSSD).
Section 3 describes the framework for background subtraction. Experimental results on the change detection dataset [
28] are reported in
Section 4. Finally conclusions are given in
Section 5.
3. Background Modeling
In this section, we will give a detailed description of the framework for the proposed background subtraction method, including background model representation, background model initialization, foreground detection, and a background model update.
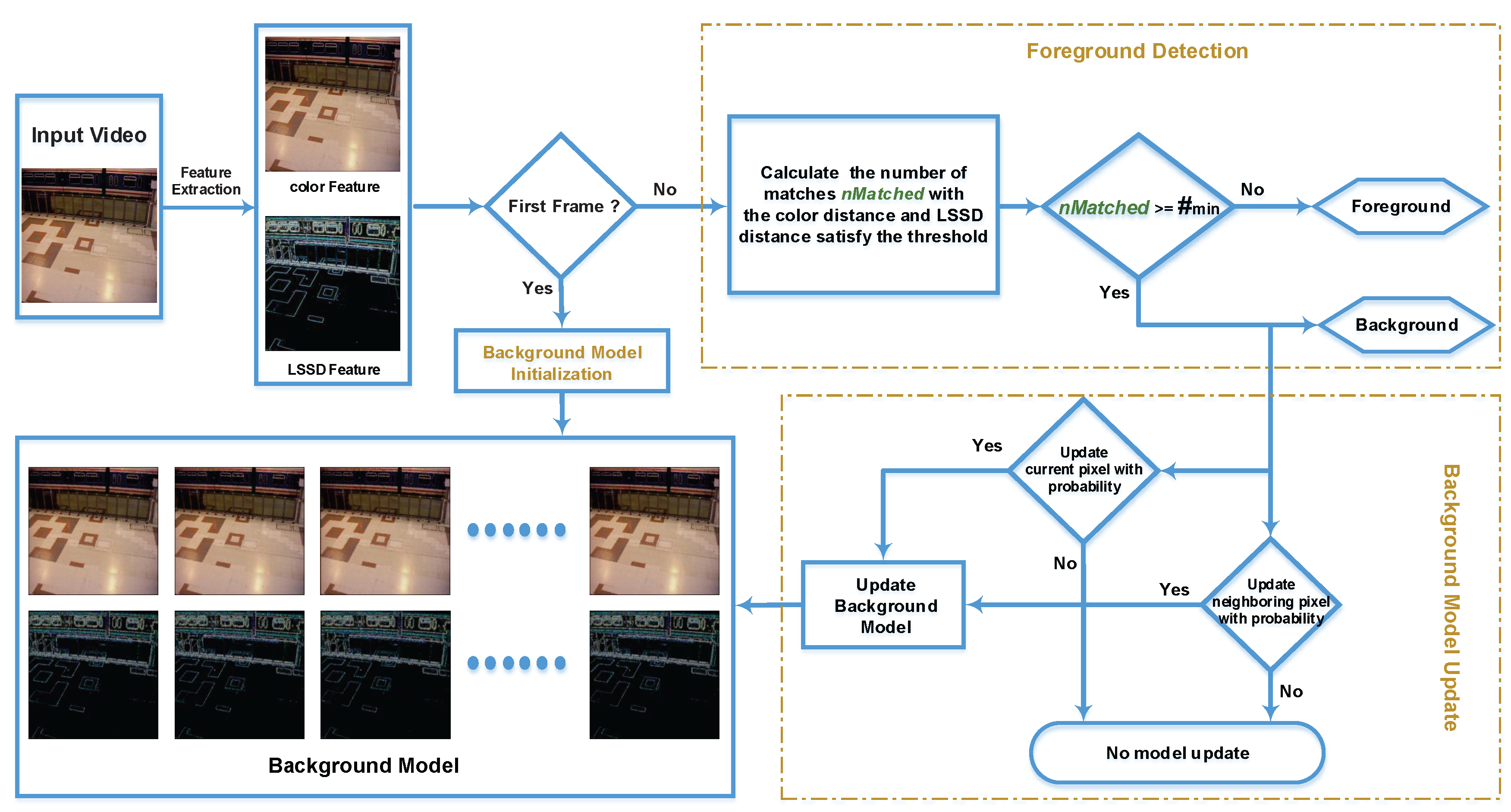
Figure 6 provides a flow chart that captures the entire proposed method.
3.1. Background Model Representation
Most of the background subtraction methods rely on probability density functions [
4,
6] or statistical parameters [
7,
29]. However, these assumptions inevitably introduce a bias in the real-world scenarios. In ViBe [
20], the authors proposed the idea that the observed pixel samples in history would have a higher probability of appearing again. Relying on the collection and maintenance of background model samples with a random approach, a sample consensus background modeling method was proposed and has shown excellent performance in background subtraction.
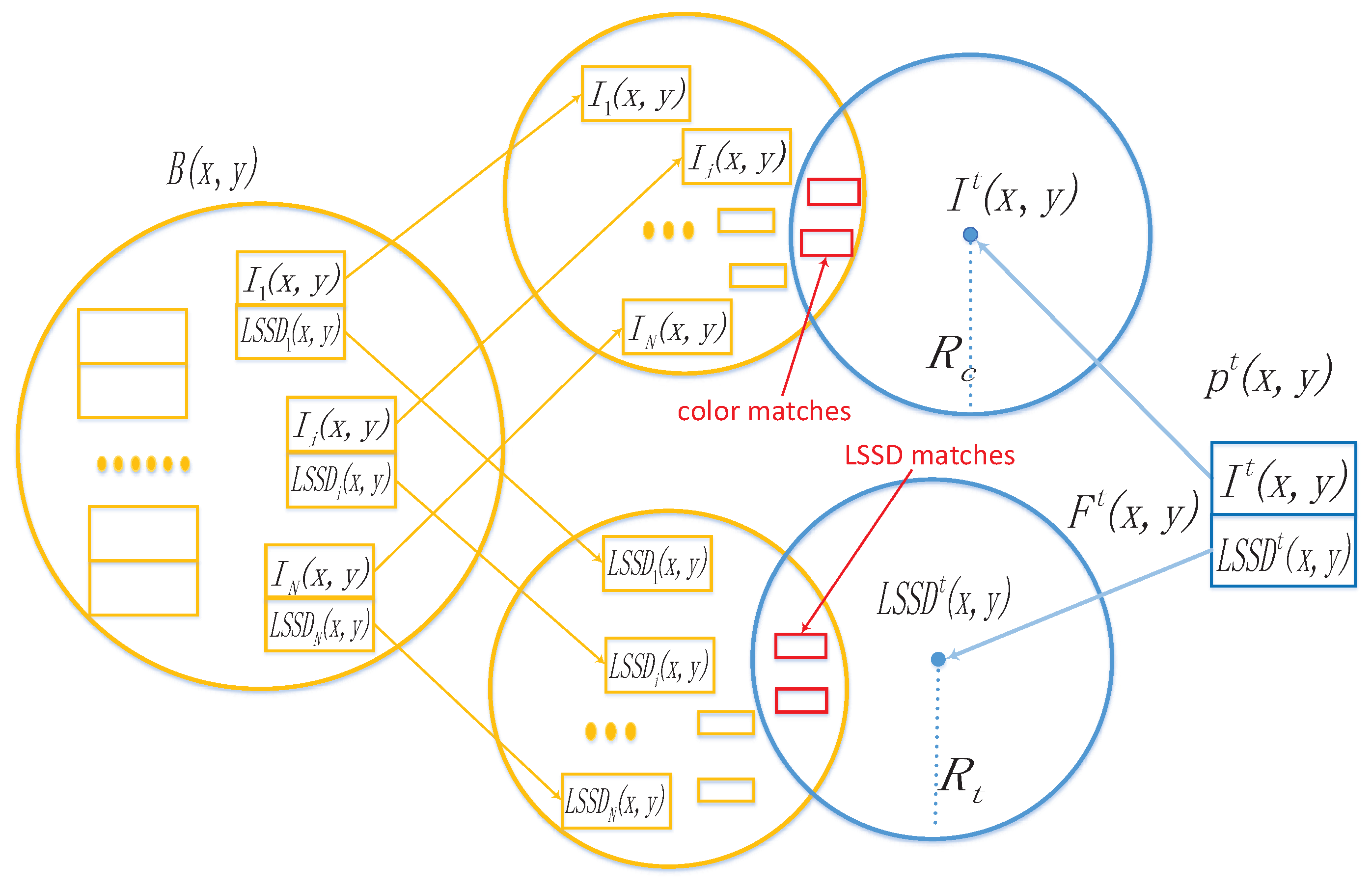
ViBe is a pixel-based flexible and lightweight background subtraction method. Each pixel
in the background is modeled by a set of
N recent background samples:
where
is the pixel color of the
ith background sample. To classify an input pixel
at time
t into foreground or background, it will be compared with the corresponding background model
. Denoting the distance between the input pixel
and background sample
as
, a match is defined as:
where
R is a fixed maximum distance threshold. If the number of matches is larger than or equal to a given threshold
, then the input pixel
is classified as background, otherwise it will be considered as foreground.
The framework of the method presented in this paper is based on ViBe. However, the original algorithm only takes the color feature into consideration; in our background model representation, we integrate the LSSD features and color features to characterize sample representations. That is to say, each background sample
in Equation (
9) consists of color and texture features. For a pixel
, its background samples in our method is modeled as:
where each background sample
contains the color feature and LSSD feature,
.
3.2. Background Model Initialization
Many popular background subtraction methods need a sequence of frames to initialize the background model [
12,
30]. However, in some application scenarios, we hope to segment the foreground in few initialization sequences or even from the second frame on. Furthermore, many applications require the algorithm to refresh or re-initialize the background model in the presence of sudden scene changes. Hence, in this paper, we use a single frame (the first frame) to initialize the background model.
Under the assumption that neighboring pixels share a similar temporal distribution at a given time, the background model of pixel
is initialized by randomly taking the sample features from its neighborhood pixels for
N times as follows:
where
is the neighboring pixel of
and the probability of chosing
follows a 2D Gaussian distribution. In our experiments, a
neighborhood region has been demonstrated to be a good choice.
The number of background samples per pixel was recommended to have a value of
N = 20 in [
20]. In fact,
N is used to balance the precision and sensitively of the model. A larger
N value leads to great precision but lower sensitivity, and vice-versa. Due to the larger representation space induced by multiple features, we consider increasing the number of background samples and determine the value of
N based on the experiment results performed on the CDnet2012 dataset [
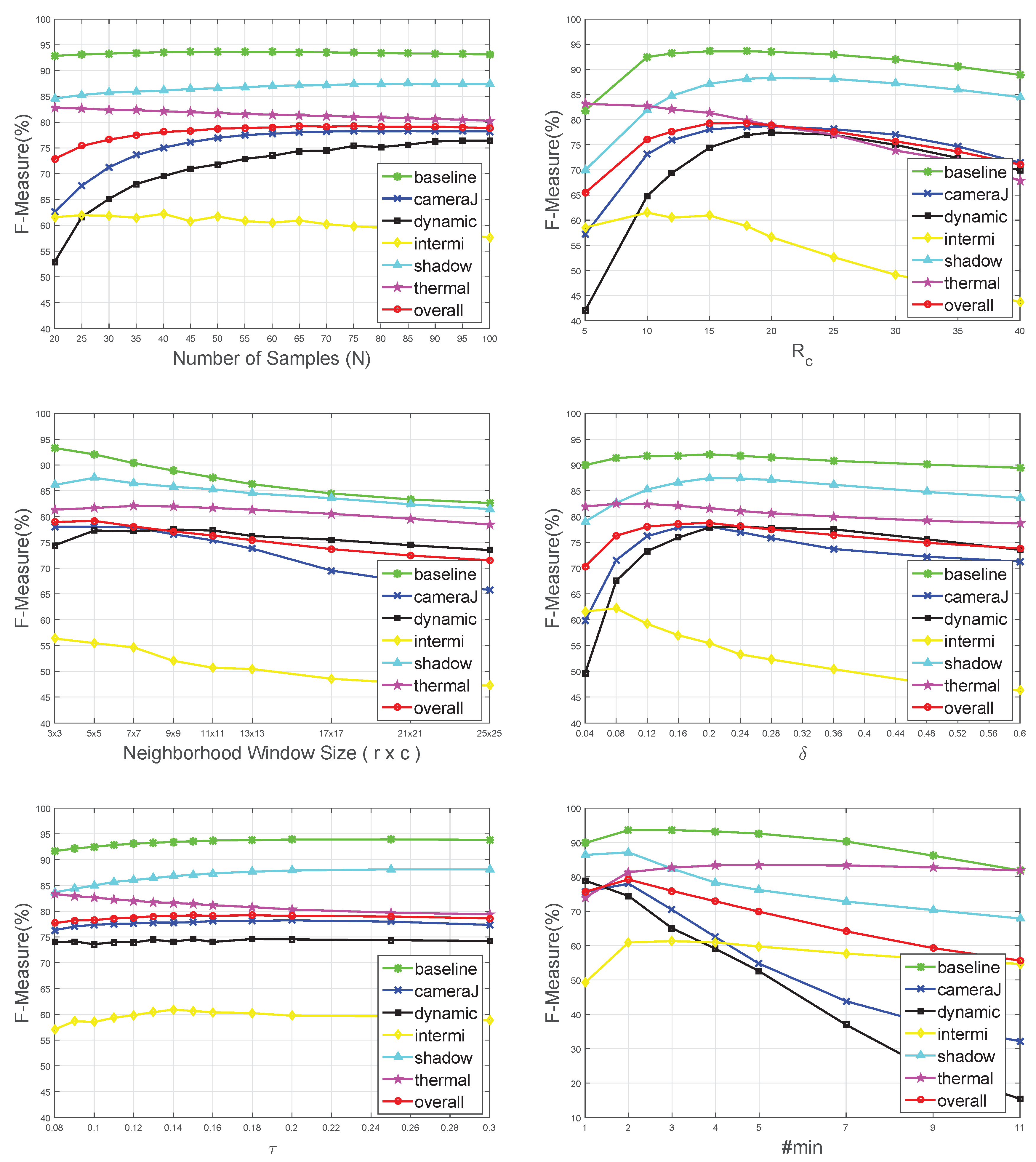
28]. As can be seen in Figure 9 (the first subgraph), in some categories, like baseline, camera jitter and shadow, their F-Measure scores tend to be saturated when
N reaches the value of 65. Meanwhile, in some other categories, like thermal and intermittent object motion, with the value of
N increased continuously, the F-Measure score decreases. We can thus find that the value of
N depends on the complexity of the scenarios. In this paper, we set
N = 45 for all categories. Although the overall F-Measure score tends to reach a maximum when
N reaches the value of 65, larger
N values increase memory and computational complexity, while there is little performance improvement.
As shown in
Figure 6 , the background model is initialized as follows. First, the color feature map
I and the LSSD feature map
are extracted from the first input frame. Then, for each pixel
in the input frame, we randomly select a position
in its
neighborhood region and get the color feature
from its color feature map
I and the LSSD feature
from its LSSD feature map
. Finally, the combination of the color feature and the LSSD feature
becomes a background sample of the pixel
. Repeating this process
N times, the background model of
is established. After all the pixels have been traversed, we obtain the final initialized background model. To make it easier to understand, the left bottom of
Figure 6 which contains
N color feature maps and
N LSSD feature maps represents the initialized background model. The color feature and LSSD feature from each column represents a background sample of the corresponding pixel.
3.3. Foreground Detection
The ViBe algorithm relies on the collection and maintenance of history background samples with a random approach, and determine whether the input pixels fit its background model by counting the number of matches within an intersection threshold. Since our background model integrates multiple features, we proposed a few tweaks to the original algorithm to globally improve our results.
Denoting the input frame at time
t as
, to classify a pixel
as foreground or background, we will first calculate the number of matches between the input pixel and its background sample model
. This procedure can be formulated as follows:
where
is the number of matches,
is the input pixel feature,
is the background sample feature,
obtains the distance between the input sample and the given background model sample, and
R is a fixed maximum distance threshold. However, as we know, the input pixel
contains two features: the color feature and the LSSD feature
. Hence, we should calculate the distances in two different ways.
First, to calculate the similarity between two color features, L1 or L2 distance are the most commonly used metrics due to their simplicity and efficiency [
20,
31]. However, based on our experimental results, L2 distance is not only an expensive operation, but is also no better than a simpler L1 distance. Hence, we decided to use the L1 distance to calculate the similarity between color features. If the color distance satisfies:
then a color feature match is found. The color threshold
controls the robustness of the background model. A small
leads to sensitive foreground detection result, while a larger
has better resistance against relevant change, but makes it more difficult to detect foreground objects that are very similar to the background. We also determine the value of
based on the experiment results performed on the CDnet2012 dataset [
28]. As it can be seen in Figure 9 (the second subgraph), the overall F-Measure score tends to arrive at a maximum when
sets the value of 15.
Second, to calculate the similarity between two LSSD features, we use a similar strategy with the color features. As we defined in Equation (
7), we know that the LSSD feature values distribute in the range of
.
is the number of pixels contained in neighborhood window
E, so we define the texture threshold as:
, where
. If the texture distance satisfies:
then a LSSD feature match is found. According to the experiment results shown in Figure 9 (third and fourth subgraph), we can see that
and the window size
set to be
can achieve optimal performance.
In order to integrate the color feature and LSSD feature into the consideration, in the match-calculating procedure, we first calculate the color similarity. If the color distance is less than the pre-defined threshold
, then LSSD similarity is calculated. That is to say, to find a match through Equation (
13), both the color and LSSD feature must be successfully matched.
Figure 7 displays the matching process.
After obtaining the number of matches, we take the label of pixel
as follows:
where 1 means foreground and 0 means background.
is the minimum number of matches required for pixel classification. If the number of matches is larger than or equal to
, the current pixel is classified as background, and vice-versa. In this paper, we set
= 2 to get a reasonable trade-off between computational complexity and noise resistance.
The pseudocode of foreground detection procedure is shown in Algorithm 1:
| Algorithm 1: Foreground Detection |
Input: current input pixel
Output: the FG/BG label of
- 1:
= 0, i = 0 - 2:
while && - 3:
- 4:
if - 5:
goto failedMatch; - 6:
- 7:
if - 8:
goto failedMatch; - 9:
++; - 10:
failedMatch: - 11:
i++; - 12:
if - 13:
is foreground; - 14:
else - 15:
is background;
|
3.4. Background Model Update
Many background model update strategies have been summarized in [
2]. Most of them use the first-in-first-out (FIFO) strategy to update their models. However, there is no evidence to show that this is optimal. In this paper, a conservative, stochastic update strategy is adopted. It contains two steps:
First, if the input pixel is classified as background, whether it will be used to update its background model is determined by a random probability . We call a time subsampling factor which controls the adaptation speed of the background model. A small value of leads to high update probability and makes a rapid evolution background model, and vice-versa. If is determined to update its background model, a background sample feature randomly picked from its background model will be replaced by .
Second, if the input pixel is classified as background, it also has the same probability () of updating one of its neighborhood background models , where the position chosen randomly from its neighborhood . Then, a randomly selected background model sample in will be replaced by .
The pseudocode of the update procedure is shown in Algorithm 2:
| Algorithm 2: Background Model Update |
Input: the FG/BG label of pixel
- 1:
if is background - 2:
if % - 3:
update with ; - 4:
if % - 5:
update with ; - 6:
else - 7:
return;
|
In the first step, the background samples are replaced randomly instead of replacing the oldest one, guaranteeing a smooth, exponentially decaying lifespan for the background samples. This update strategy cancels the time window concept and new samples can be incorporated into the background model only if they are classified as background, thus prevent static foreground objects from being absorbed into the background model too fast. However, this conservative updating strategy may cause a “ghosting” effect, which is the result of falsely classified pixel regions caused by the removal of scene objects, like static objects suddenly starting to move away. A popular method of dealing with this situation is through the “detection support map [
32]” which saves the number of times that a pixel has been consecutively classified as foreground. If the value exceeds a given threshold, then the pixel is classified into the background model, however, this strategy will add parameters and increase the computational complexity.
Fortunately, the second step in our model update procedure allows “ghosting” regions to be automatic absorbed into the background model as time goes by. As neighboring pixels share similar spatial distribution, according to the neighborhood diffusion update strategy, background models hidden by the removed object will be updated with neighboring pixel samples from time to time. Moreover, the neighborhood diffusion step also enhances the spatial coherence and prevents the spread of background samples across boundaries. Even if a input sample is wrongfully diffused from one background model to another, the odds that it might be matched are much lower due to the use of the LSSD texture feature.
4. Experimental Results
4.1. Evaluation Datasets
To evaluate the performance of our method and compare it with other state-of-the-art methods, a standard, publicly available dataset, CDnet2012, is considered [
28]. This dataset consists of 31 videos from realistic scenarios with nearly 90,000 frames. These videos are grouped into six categories, namely: baseline, camera jitter, dynamic background, intermittent object motion, shadow, and thermal. Accurate human constructed ground-truths are available for all sequences, so exhaustive competitive comparison is possible with different methods.
Figure 8 shows some sample images and their corresponding ground-truths. To our knowledge, this is one of the most complete datasets for background subtraction; a complete overview of this dataset is depicted in
Table 1.
4.2. Evaluation Metrics
In order to compare the methods, a total of seven different metrics have been defined to evaluate different quality characteristics. Let
stand for the true positives which hold the number of pixels correctly labeled as foreground,
stand for the true negatives which hold the number of pixels correctly labeled as background,
stand for the false positives which hold the number of pixels incorrectly labeled as foreground, and
stand for the false negatives which hold the number of pixels incorrectly labeled as background. According to [
28], these metrics are defined as follows:
Recall (Re) =
Specificity (Sp) =
False positive rate (FPR) =
False negative rate (FNR) =
Percentage of wrong classifications (PWC) =
Precision (Pr) =
F-Measure (FM) =
The sums of all pixels in each category are used to calculate these metrics, and an overall category is defined based on the mean of each category. For PWC, FNR and FPR metrics, lower values indicate higher accuracy, but for Re, Sp, Pr and FM, higher values indicate better performance.
During these metrics, we are especially interested in the F-Measure score, which is the most common metric used for background subtraction methods comparison in the literature. As the F-Measure metric is calculated by a combination of multiple evaluation metrics, the overall performance of a background subtraction method is highly correlated with its F-Measure performance. Most state-of-the-art background subtraction methods typically exhibit higher F-Measure scores than worse-performing background subtraction methods [
28].
4.3. Parameters Setting
Our method consists of a few parameters which can be adjusted for optimal performance. Since we evaluated our algorithm on the CDnet2012 dataset [
28], we used a universal parameter set for all videos to respect the competition rules. Nevertheless, for some applications, parameters can be fine-tuned for some specific needs. Overall, the six parameters, detailed below, were tuned in the dataset. The performance with different parameter settings is shown in
Figure 9.
: the number of samples stored in the background model for each pixel.
: minimum number of sample matches to label an input pixel as background. An optimum is found at .
: color distance threshold to determine whether an input pixel matches the background sample.
: neighborhood window size to calculate LSSD features in Equation (
7).
: interval factor used to calculate LSSD features in Equation (
8).
: parameter factor used to calculate the LSSD distance threshold
in Equation (
15).
In our proposed method, the classification decision is made independently for each pixel. The foreground detection result can benefit from a regularization step, which combines information from neighboring pixels and assigns homogeneous labels on uniform regions. In preliminary experiments, simple median filtering provided superior results to morphological operations. Thus, we decided to use a median filter for post-processing. In this paper, we use a uniform median filter for all evaluated methods. In practice, the input image is a three-channel color image; we process each channel independently and run them in three parallel threads. The final segmentation result is the bitwise OR operation of the three segmentation results from channels.
4.4. Performance Evaluation
Firstly, to demonstrate our key contribution, the LSSD texture feature is shown to be preferable to other texture features (LBP [
21], SILTP [
22], and LBSP [
26]). In
Table 2 , we present the performance comparison of different features with respect to the the CDnet2012 dataset. Here, we can see that the LSSD feature obtains a much higher F-Measure score than LBP and SILTP. This may explain that although LBP and SILTP can detect texture variation easily, they are too sensitive to the noise and dynamic background in some scenarios, resulting in poor overall performance. We also see that the LBSP feature obtains much higher F-Measure score than the other texture features. This is the benefit obtained from combining temporal and spatial information to describe texture changes. Others only take spatial information to calculate the features. Although LBSP obtains the highest F-Measure score when only taking the texture features, we will demonstrate that when integrated with the color features, our method performs much better than all others.
Secondly, to demonstrate the effectiveness of the combination of color features and texture features, we select the two typical sequences office and boat. The clothes in the office include flat texture, which is very similar to the texture of the wall; the boat sequence contains the complex background of a rippled water surface.
Figure 10 shows the experimental results when only using color features (the second column), only using texture features (the third column) and using color features and texture features (the fourth column). For the office sequences, the color information can well distinguish the person and the wall, but only using the texture features will result in missed detection, resulting in “holes” in objects. For the boat sequences, which contain the movement of water, only using the color features will generate false detection. However, using the LSSD texture features will suppress these false detections. The experimental results in
Figure 10 demonstrate that the color features and the LSSD features have their own merits and demerits. They can compensate for each other to obtain a better segmentation result. In
Table 2 , we also present the results obtained when combining the color features and the LSSD features. According to the F-Measure scores, we can see that all texture features obtain performance improvement when combined with the color features; our method surpasses the LBSP and achieves the highest improvement. This is due to the robustness of the LSSD feature as compared with other intrinsic noise-sensitive texture features.
Thirdly, we present the complete results of our method using the evaluation framework of the CDnet2012 dataset [
28]. As shown in
Table 3, we can see that our method performs well on the dataset with a overall F-Measure of 0.7924. In the baseline and shadow categories, one of the F-Measure scores is 0.9361 and the other is 0.8714. Both of the recall metric scores exceed
. These two categories mainly consist of sequences where cars and pedestrians are the main focus with challenges like illumination variation and camouflage. We also see that the camera jitter and dynamic background categories are well handled by our method; the F-Measure and precision scores are all above
. The same can be said for the thermal sequences, as the precision metric gets a high score of
. However, we also notice that the intermittent object motion category poses the greatest challenge. This category mainly consists of sequences with abandoned objects and parked cars that suddenly start moving. The main challenge involves static object detection, but it is not what most background subtraction methods are good at.
Fourthly, in
Table 4 we show how our method compared with some of the state-of-the-art methods. Due to a lack of space, we only chose seven classic methods: GMM [
4], KDE [
7], ViBe [
20], SOBS [
12], PSR-MRF [
14], PBAS [
33] and LOBSTER [
26]. Among them, GMM, KDE, SOBS, PBAS and ViBe are pixel-level methods. PSR-MRF is region-level method. LOBSTER and our method are hybrid methods. The results of other methods are from the website
www.changedetection.net. For a specific metric, if the method obtains a best score on it, the corresponding value is highlighted in bold. From
Table 4 we can see that the ViBe has the best precision performance, LOBSTER has the best specificity performance, PBAS has the best performance on FPR and PWC metrics, and our method is the best in three out of seven metrics: recall, FNR and F-Measure. Of note, the F-Measure score is 0.7924, which is much higher than for all other methods. The LOBSTER method is very similar to our method. Both of them are hybrid methods, which combine pixel-level and region-level analyses. The LOBSTER presents a modified spatio-temporal binary texture descriptor derived from the Local Binary Similarity Pattern (LBSP) and results in a dramatic performance increase. However, as we concluded previously, the local binary pattern texture feature is noise-sensitive. In
Table 5, we give a detail per-category average F-Measure comparisons between our method and the LOBSTER method. In the camera jitter and dynamic background categories, the F-Measure scores of our method are much higher than for LOBSTER. In particular, in the dynamic background category, our method shows an amazing
increase. Again, this demonstrates that the LSSD texture feature not only has the advantage of dealing with illumination variation and camouflage problems as most other texture features do, but also overcomes the disadvantage of noise sensitivity, which makes our method more robust in realistic difficult environmental conditions, like complex background motion and camera vibration.
Finally, we present some qualitative comparisons between LOBSTER, ViBe, GMM, and our method with respect to the CDnet2012 dataset. As shown in
Figure 11, we chose six sequences from each category. Each row exhibits a comparison among these methods; from top to bottom they are highway (baseline), traffic (camera jitter), fall (dynamic background), sofa (intermittent object motion), copyMachine (shadow) and library (thermal). The first column is the input image from difference sequences, the second column represents the corresponding ground-truth, the third column shows the segmentation results of our method, the fourth column represents the segmentation results of the LOBSTER [
26], the fifth column is the segmentation results of the ViBe [
20] and the last column shows the output of the GMM [
4] segmentation. Several visual conclusions can be obtained from observing these images. In most cases, our LSSD methodachieves better segmentation results than the other alternatives. In the highway sequence of baseline, the foreground segmentation results of our algorithm are perfect, almost the same as with the ground-truth. In the traffic and fall sequences with camera vibration and dynamic background, unlike the other methods, repetitive movements of the background objects are implicitly avoided in our background model, especially in the traffic sequence, where the highway fence is segmented as foreground in the remaining methods. In the fall sequence, few tree leaves are considered as foreground in our method, and thus the robustness of the LSSD texture feature may be of benefit. A camouflage problem, in which there are significant similarities between the background colors and foreground colors causing holes in the segmentation results, is also shown in several sequences, such as sofa and copyMachine. In the sofa sequence, the color of the man’s trousers is similar to the color of the sofa. Even humans find it hard to segment them accurately, while our method obtains a concatenate foreground mask. Meanwhile, holes are detected in the results for LOBSTER and ViBe, resulting in the foreground object being divided into several parts. It is also amazing that the GMM achieved blank results. This may be because, as time goes by, the foreground object is fully absorbed into the background model. For the box left on the floor, which should considered as foreground and never be absorbed into the background model, we observed that in LOBSTER, ViBe and GMM, the box eroded as time went on, creating false negatives, while our method maintained a lower absorption rate. In the copyMachine sequence, we can see a similar phenomenon to the sofa sequence. The segmentation results of other methods are not as good as ours. Lastly, in the library sequence from thermal, most of the methods obtain a perfect segmentation result except GMM.
4.5. Processing Speed and Memory Usage
Background subtraction is often the first step in many vision applications. Processing speed and memory usage are critical items of information for researchers to consider before choosing which method to use. Thus, we give a detailed analysis of the time and space complexity of our method in this section.
The computational speed of our method is investigated with different size sequences coming from the CDnet2012 dataset [
28]. Our method has been implemented in C++ and uses the OpenCV [
34] image processing library. All the experiments are carried out on a 4.2-Ghz Intel Core-i7 7700 K with 32 GB RAM and a Windows 10 operating system. The results are reported in
Table 6. Although the combination of color features and texture features will increase the computational complexity, we can see that our algorithm also achieves the real-time performance. Since our method operates at the pixel level, it has the potential for hardware implementation or high-speed parallel implementation.
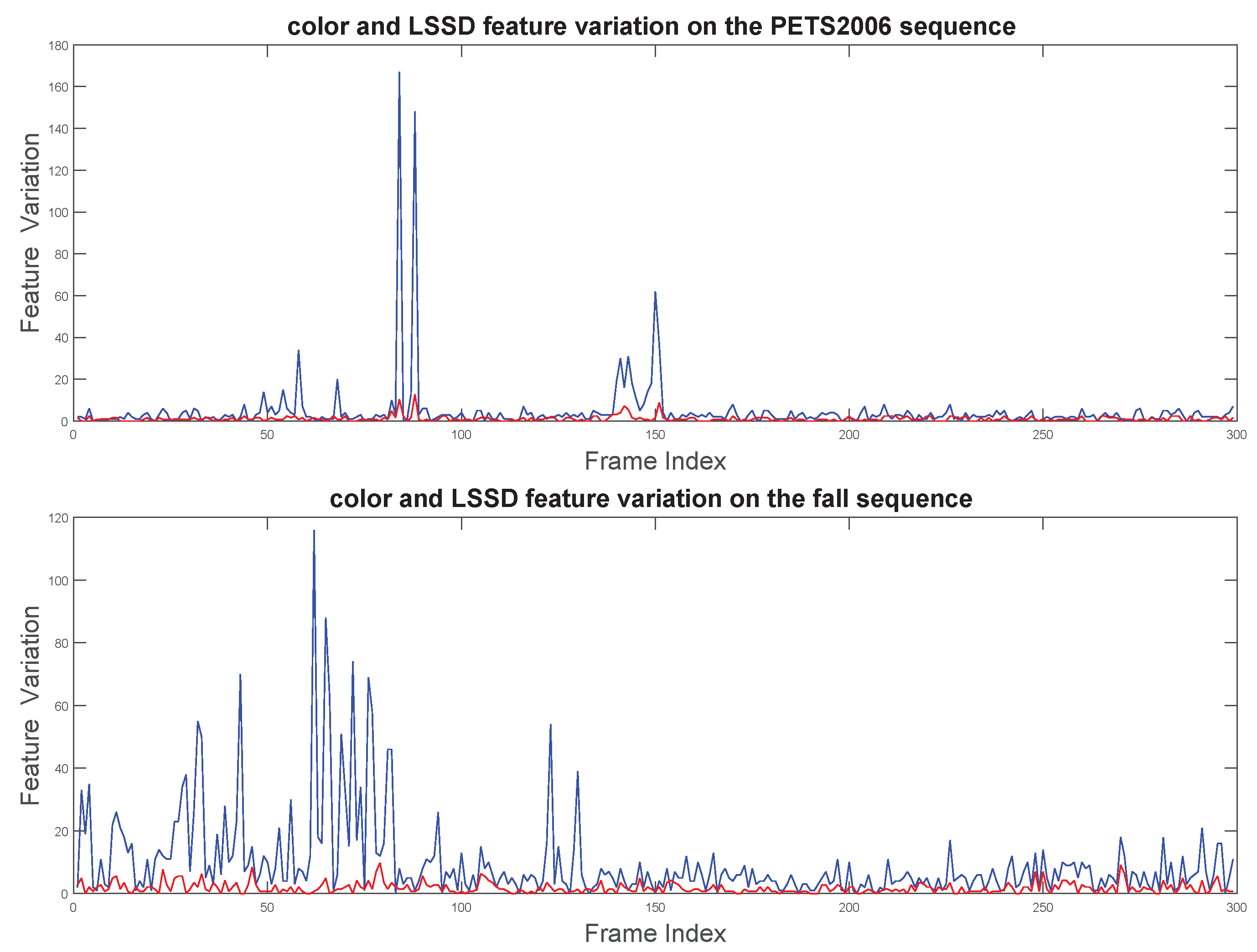
As for the memory usage of our method, considering the size of the input image is , the background model sample of each pixel is N, and we find that the space complexity of our method is . For a pixel p, each background sample requires one byte of memory to store the intensity information and one byte of memory to store the LSSD information per channel. According to the parameters set in our experiment described above, each pixel background model contains background samples. Then, for a color sequence with frame size of (e.g., PETS2006), the memory requirement of our method would be about 300 MB. This is consistent with the results obtained by the Visual Studio 2015 performance analysis tool. For an embedded platform, decreasing the number of background samples can dramatically reduce the memory usage.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}