Vibration-Based Signal Analysis for Shearer Cutting Status Recognition Based on Local Mean Decomposition and Fuzzy C-Means Clustering



Abstract
:1. Introduction
2. Basic Theories
2.1. Review of LMD Method
- (1)
- All of the local extrema ni and the time tni of the original signal x(t) are determined, and the mean value mi of the two successive extrema ni and ni+1 is calculated as follows:All mean values mi are connected by straight lines between the corresponding time tni and tni+1, to generate the local mean segments. Then, the local mean segments are smoothed by amoving averaging method, to form a continuous local mean function m11(t).
- (2)
- The local amplitude ai can be given as follows:The moving averaging method is also used to smooth the local amplitude segments, in order to derive the envelope estimate function a11(t).
- (3)
- The local mean function m11(t) is subtracted from the original signal x(t), and the remnant signal, denoted by h11(t), can be given as follows:
- (4)
- The signal h11(t) is demodulated by the envelope estimate function a11(t), and the result, denoted by s11(t), can be calculated as follows:The envelope estimate function a12(t) of s11(t) is calculated. If a12(t) is not equal to one, s11(t) is not a purely frequency-modulated signal, and the above procedure for s11(t) should be repeated until a purely frequency-modulated signal s1n(t) is obtained. This is obtained when the envelope estimate function meets the condition that a1(n+1)(t) of s1n(t) is equal to one. Therefore,where
- (5)
- An envelope signal a1(t) can be derived by the product of all of the envelope estimate functions obtained during the iterative process described above.
- (6)
- The first product function PF1 of the original signal can be generated by the product of the envelope signal a1(t) and the purely frequency-modulated signal s1n(t).
- (7)
- PF1 is then subtracted from the original signal x(t), generating a new signal u1(t). The whole process is repeated k times, until uk(t) is a constant or monotonic function.Finally, the original signal x(t) is decomposed into k PFs and a residual uk(t), and x(t) can be reconstructed as follows:According to above algorithm, we can realize that the LMD method is an adaptive signal decomposition method, based on the local extrema information of the signal itself.
2.2. Fuzzy C-Means Clustering Algorithm
- (1)
- Provide the number of clustering categories c, the fuzzy weighting exponent m, the iteration stop threshold ε, and the maximum number of iterations Tmax. Then, initialize the membership matrix U(t) and set the iterations number t = 0.
- (2)
- The clustering center cj can be calculated as follows:
- (3)
- The membership matrix U(t+1) can be updated as:
- (4)
- If , then the iteration process terminates. Otherwise, set t = t + 1 and return to step (2).
- (5)
- Finally, an optimal membership matrix U* and clustering center C* can be obtained.
- (6)
- The principle of selecting the near is adapted to recognize the unmarked object types. The Hamming near-degree H between the unmarked object A and each clustering center cj, is used to describe the similarity of the two fuzzy subsets. Suppose the number of variables in the sample is r, and the mathematical formula of H can be given as follows:The larger H(A, cj) signifies that the two fuzzy subsets are more similar, and the unmarked object A with the largest H(A, cj) demonstrates that it belongs to the jth category.
3. The Proposed Pattern Recognition Method
3.1. The Optimal PF Component Selection Based on Kullback-Leibler Divergence
- (1)
- Suppose p(x) and q(x) are the probability density functions of original signal x(t) and PFi(t), respectively. p(x) can be defined as follows:where N denotes the sampling number of x(t), h is called the window width or smoothing parameter, and K(*) denotes a kernel function and is commonly expressed as:Likewise, the probability density function q(x) can be obtained.
- (2)
- The Kullback-Leibler distance between x(t) and the ith PF can be defined as:
- (3)
- The KLD between x(t) and the ith PF can be calculated as:The normalized KLD values can be obtained by Equation (20).The smaller the KLD value is, the closer the correlation between the PF and original signal is, and vice versa.
3.2. Feature Extraction Based on Time-Frequency Statistical Parameters
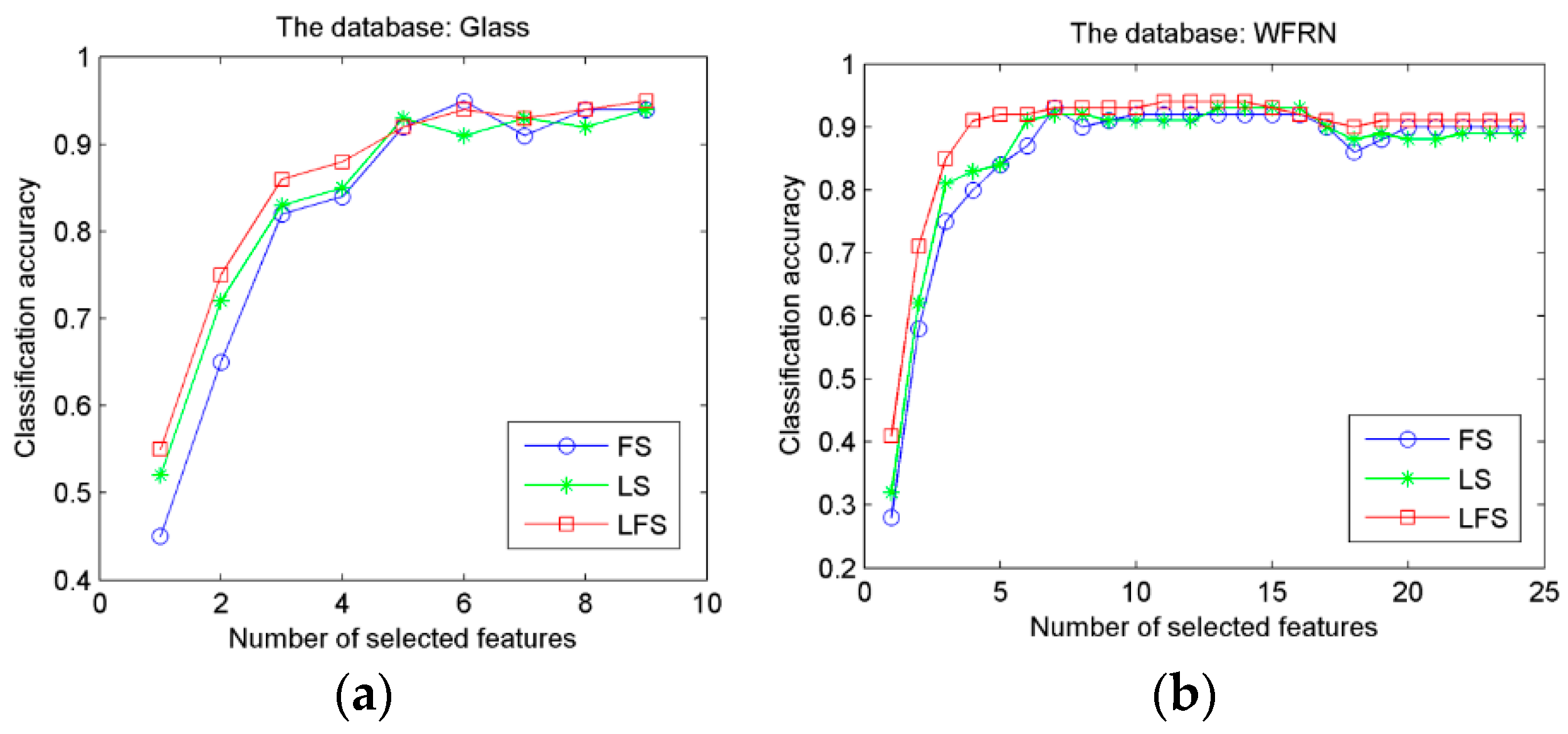
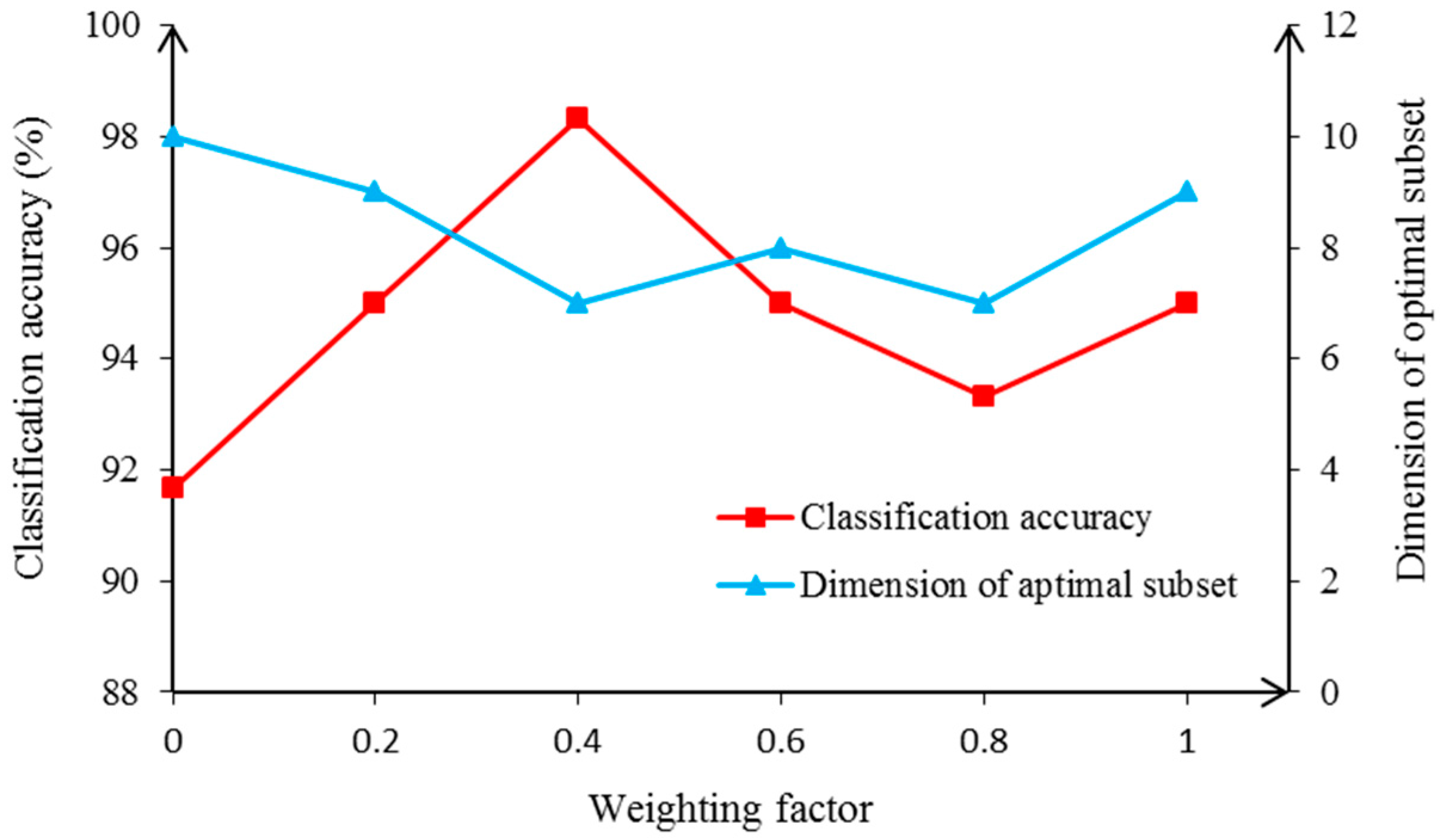
3.3. Feature Ranking and Selection Based on Improved Laplacian Score Algorithm
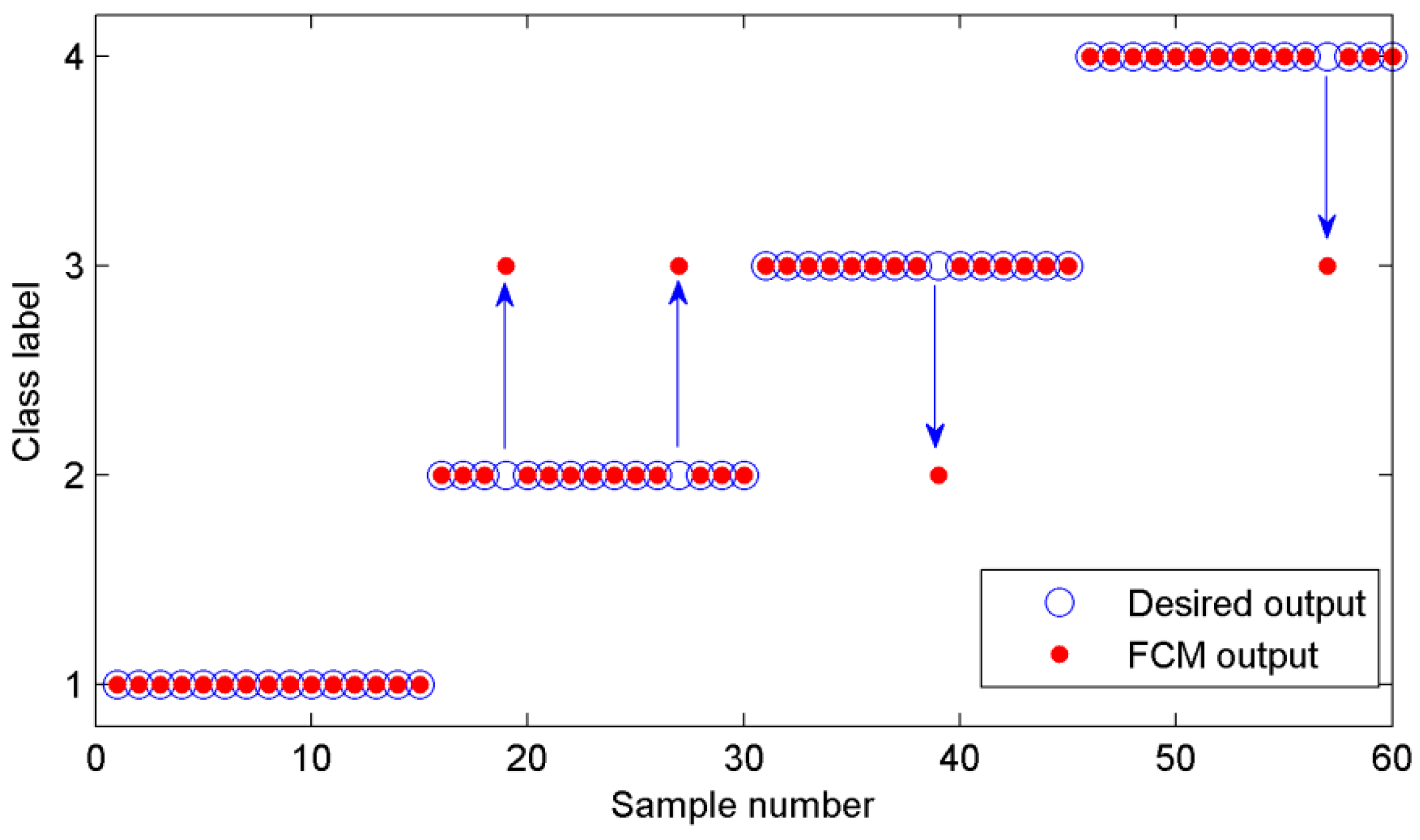
4. Experimental Validation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Si, L.; Wang, Z.; Tan, C.; Liu, X. A novel approach for coal seam terrain prediction through information fusion of improved D-S evidence theory and neural network. Measurement 2014, 54, 140–151. [Google Scholar] [CrossRef]
- Si, L.; Wang, Z.; Liu, Z.; Liu, X.; Tan, C.; Xu, R. Health condition evaluation for a shearer through the integration of a fuzzy neural network and improved particle swarm optimization algorithm. Appl. Sci. 2016, 6, 171. [Google Scholar] [CrossRef]
- Lee, J.; Kim, J.; Kim, H. Development of enhanced Wigner-Ville distribution function. Mech. Syst. Signal Process. 2001, 13, 367–398. [Google Scholar] [CrossRef]
- Lin, J.; Qu, L. Feature extraction based on Morlet wavelet and its application for mechanical fault diagnosis. J. Sound Vib. 2000, 234, 135–148. [Google Scholar] [CrossRef]
- Sanz, J.; Perera, R.; Huerta, C. Fault diagnosis of rotating machinery based on auto-associative neural networks and wavelet transforms. J. Sound Vib. 2007, 302, 981–999. [Google Scholar] [CrossRef]
- Fu, Y.; Chui, C.; Teo, C. Accurate two-dimensional cardiac strain calculation using adaptive windowed Fourier transform and Gabor wavelet transform. Int. J. Comput. Assist. Radiol. 2013, 8, 135–144. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.; Shen, Z.; Long, S.; Wu, M.; Shih, H.; Zheng, Q.; Yen, N.; Tung, C.; Liu, H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.; Li, H.; Li, P.; Liu, H. Study on planetary gear fault diagnosis based on entropy feature fusion of ensemble empirical mode decomposition. Measurement 2016, 91, 140–154. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.; Srikanth, N. A novel empirical mode decomposition with support vector regression for wind speed forecasting. IEEE Trans. Neural Netw. Learn. 2016, 27, 1793–1798. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y. Empirical mode decomposition as a time-varying multirate signal processing system. Mech. Syst. Signal Process. 2016, 76–77, 759–770. [Google Scholar] [CrossRef]
- Smith, J. The local mean decomposition and its application to EEG perception data. J. R. Soc. Interface 2005, 2, 443–454. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.; Zhang, K.; Yang, Y. Local mean decomposition method and its application to roller bearing fault diagnosis. Chin. J. Mech. Eng. 2009, 20, 2711–2717. [Google Scholar]
- Li, B.; Xu, M.; Wang, R.; Huang, W. A fault diagnosis scheme for rolling bearing based on local mean decomposition and improved multiscale fuzzy entropy. J. Sound Vib. 2016, 360, 277–299. [Google Scholar] [CrossRef]
- Wei, Y.; Xu, M.; Li, Y.; Huang, W. Gearbox fault diagnosis based on local mean decomposition, permutation entropy and extreme learning machine. J. Vibroeng. 2016, 18, 1459–1473. [Google Scholar]
- Wodecki, J.; Stefaniak, P.; Obuchowski, J.; Wylomanska, A.; Zimroz, R. Combination of principal component analysis and time-frequency representations of multichannel vibration data for gearbox fault detection. J. Vibroeng. 2016, 18, 2167–2175. [Google Scholar]
- Fu, S.; Liu, K.; Xu, Y.; Liu, Y. Rolling bearing diagnosing method based on time domain analysis and adaptive fuzzy C-means clustering. Shock Vib. 2016, 2016, 9412787. [Google Scholar]
- Chen, Y.; Lin, C. Combining SVMs with various feature selection strategies. Feature Extr. 2006, 207, 315–324. [Google Scholar]
- Ou, L.; Yu, D. Rolling Bearing fault diagnosis based on Laplacian score and fuzzy C-means clustering. Chin. J. Mech. Eng. 2014, 25, 1352–1357. [Google Scholar]
- Feng, H.; Chang, G.; Kong, J. Fault diagnosis method of bearing based on Laplacian score and hypersphere support vector machine. Comput. Meas. Control 2015, 23, 1102–1105. [Google Scholar]
- Xiao, Y.; Sheng, L.; Zhang, D. Supervised and unsupervised parallel subspace learning for larger scale image recognition. IEEE Trans. Circuits Syst. Video 2012, 22, 1497–1511. [Google Scholar]
- Wang, L.P.; Wang, Y.L.; Chang, Q. Feature selection methods for big data bioinformatics: A survey from the search perspective. Methods 2016, 111, 21–31. [Google Scholar] [CrossRef] [PubMed]
- Oh, I.-S.; Lee, J.-S.; Moon, B.-R. Hybrid genetic algorithms for feature selection. IEEE Trans. Pattern Anal. 2004, 26, 1424–1437. [Google Scholar]
- Wang, L.P.; Zhou, N.; Chu, F. A general wrapper approach to selection of class-dependent features. IEEE Trans. Neural Netw. 2008, 19, 1267–1278. [Google Scholar] [CrossRef]
- Kanai, R.; Desavale, R.; Chavan, S. Experimental-based fault diagnosis of rolling bearings using artificial neural network. J. Tribol. Trans. ASME 2016, 138, 031103. [Google Scholar] [CrossRef]
- Chine, W.; Mellit, A.; Lughi, V.; Malek, A.; Sulligoi, G.; Pavan, A. A novel fault diagnosis technique for photovoltaic systems based on artificial neural networks. Renew. Energy 2016, 90, 501–512. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. A Survey of randomized algorithms for training neural networks. Inf. Sci. 2016, 364–365, 146–155. [Google Scholar] [CrossRef]
- Yang, C.; Hou, J. Fed-batch fermentation penicillin process fault diagnosis and detection based on support vector machine. Neurocomputing 2016, 190, 117–123. [Google Scholar] [CrossRef]
- Wang, L.P.; Fu, X. Data Mining with Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Song, Y.; Jiang, Q.; Yan, X. Fault diagnosis and process monitoring using a statistical pattern framework based on a self-organizing map. J. Cent. South Univ. 2015, 22, 601–609. [Google Scholar] [CrossRef]
- Liu, H.; Wang, X.; Jiao, Y. Damage identification for irregular-shaped bridge based on fuzzy C-means clustering improved by particle swarm optimization algorithm. J. Vibroeng. 2016, 18, 2149–2166. [Google Scholar]
- Liu, L.; Sun, S.; Yu, H.; Yue, X.; Zhang, D. A modified fuzzy C-means (FCM) clustering algorithm and its application on carbonate fluid identification. J. Appl. Geophys. 2016, 129, 28–35. [Google Scholar] [CrossRef]
- Rajaby, E.; Ahadi, S.; Aghaeinia, H. Robust color image segmentation using fuzzy C-means with weighted hue and intensity. Digit. Signal Process. 2016, 51, 170–183. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Niyogi, P. Laplacian Score for Feature Selection. Proceedings of Advances in Neural Information Processing System; The Neural Information Processing Systems (NIPS) Foundation: Vancouver, BC, Canada, 2005; pp. 507–514. [Google Scholar]
- Lichman, M. UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]; School of Information and Computer Science, University of California: Irvine, CA, USA, 2013. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Number of Training Samples | Number of Testing Samples | Number of Categories | Number of Features |
|---|---|---|---|---|
| Glass | 150 | 50 | 6 | 9 |
| WFRN | 500 | 100 | 4 | 24 |
| Weighting Factor | New Order of the 28 Features |
|---|---|
| 0 | 23, 26, 12, 7, 1, 9, 13, 6, 20, 18, 22, 11, 14, 2, 17, 10, 24, 3, 15, 8, 21, 5, 27, 25, 4, 28, 19, 16 |
| 0.2 | 23, 5, 6, 3, 15, 13, 10, 14, 28, 9, 24, 7, 1, 18, 19, 21, 20, 11, 27, 26, 12, 22, 2, 17, 8, 25, 4, 16 |
| 0.4 | 23, 9, 13, 10, 24, 19, 21, 5, 6, 20, 7, 1, 3, 15, 18, 22, 4, 8, 11, 14, 28, 27, 25, 2, 17, 26, 12, 16 |
| 0.6 | 23, 4, 8, 22, 11, 28, 27, 2, 17, 10, 3, 24, 5, 6, 15, 7, 1, 12, 16, 19, 21, 14, 13, 20, 18, 25, 26, 9 |
| 0.8 | 23, 15, 18, 5, 6, 20, 2, 17, 21, 7, 24, 19, 9, 13, 26, 12, 22, 4, 10, 1, 11, 14, 3, 8, 27, 25, 28, 16 |
| 1 | 23, 26, 12, 2, 17, 9, 13, 1, 3, 15, 21, 5, 6, 14, 28, 22, 4, 24, 19, 25, 16, 11, 27, 7, 18, 20, 10, 8 |
| Classification Methods | Training Samples (%) | Testing Samples (%) |
|---|---|---|
| K-means | 95.71 | 86.67 |
| SOM | 94.82 | 83.33 |
| BPNN | 97.86 | 93.33 |
| SVM | 98.57 | 96.67 |
| FCM | 99.29 | 98.33 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Si, L.; Wang, Z.; Tan, C.; Liu, X. Vibration-Based Signal Analysis for Shearer Cutting Status Recognition Based on Local Mean Decomposition and Fuzzy C-Means Clustering. Appl. Sci. 2017, 7, 164. https://doi.org/10.3390/app7020164
Si L, Wang Z, Tan C, Liu X. Vibration-Based Signal Analysis for Shearer Cutting Status Recognition Based on Local Mean Decomposition and Fuzzy C-Means Clustering. Applied Sciences. 2017; 7(2):164. https://doi.org/10.3390/app7020164
Chicago/Turabian StyleSi, Lei, Zhongbin Wang, Chao Tan, and Xinhua Liu. 2017. "Vibration-Based Signal Analysis for Shearer Cutting Status Recognition Based on Local Mean Decomposition and Fuzzy C-Means Clustering" Applied Sciences 7, no. 2: 164. https://doi.org/10.3390/app7020164
APA StyleSi, L., Wang, Z., Tan, C., & Liu, X. (2017). Vibration-Based Signal Analysis for Shearer Cutting Status Recognition Based on Local Mean Decomposition and Fuzzy C-Means Clustering. Applied Sciences, 7(2), 164. https://doi.org/10.3390/app7020164