1. Introduction
Kidney transplants are essential for many end-stage renal disease sufferers. However, finding compatible kidneys may be difficult because of blood or tissue incompatibilities between donors and their intended recipients. The issue of incompatibility can be overcome by establishing a kidney exchange program (KEP). The first of these was performed in South Korea [
1,
2,
3] in 1991 and they have since been widely performed in many countries, including the United States of America [
4,
5,
6,
7,
8,
9], the United Kingdom [
10,
11,
12] and Australia [
13]. A KEP helps a potential living donor to donate his or her kidney, which is incompatible with the intended recipient, to another recipient so that the donor’s intended recipient can also receive a compatible kidney from another donor. The Korea Centers for Disease Control & Prevention (KCDC), the government ministry that maintains a unified administration to avoid disease and to improve public health welfare in South Korea, has recently paid attention to the contribution of the KEP, which increases the number of renal disease sufferers able to receive kidney transplants. The KCDC has pushed ahead with a plan for the development of an integrated IT healthcare platform for the KEP. On the platform, hospitals can register the essential information for verifying the compatibility of their renal disease sufferers. Then, the proposed KEP platform would provide matching plans to maximize the number of possible kidney exchanges in the program. Hence, it is important to establish an efficient optimization model for KEPs that can provide optimized kidney exchange plans within a reasonable time, and, in this paper, we intend to provide a high-performance mathematical programming model easily solvable by commercial optimization solvers (e.g., Cplex, Gurobi) to support the integrated KEP IT healthcare platform of South Korea. We remark that, as in our case, operations research (OR) techniques have been applied and utilized to tackle many important and challenging optimization issues in healthcare (e.g., [
14] for an overview of recent research on several OR applications in healthcare, and [
15,
16] for medical resident scheduling problems and sensor-based patient monitoring problems, respectively).
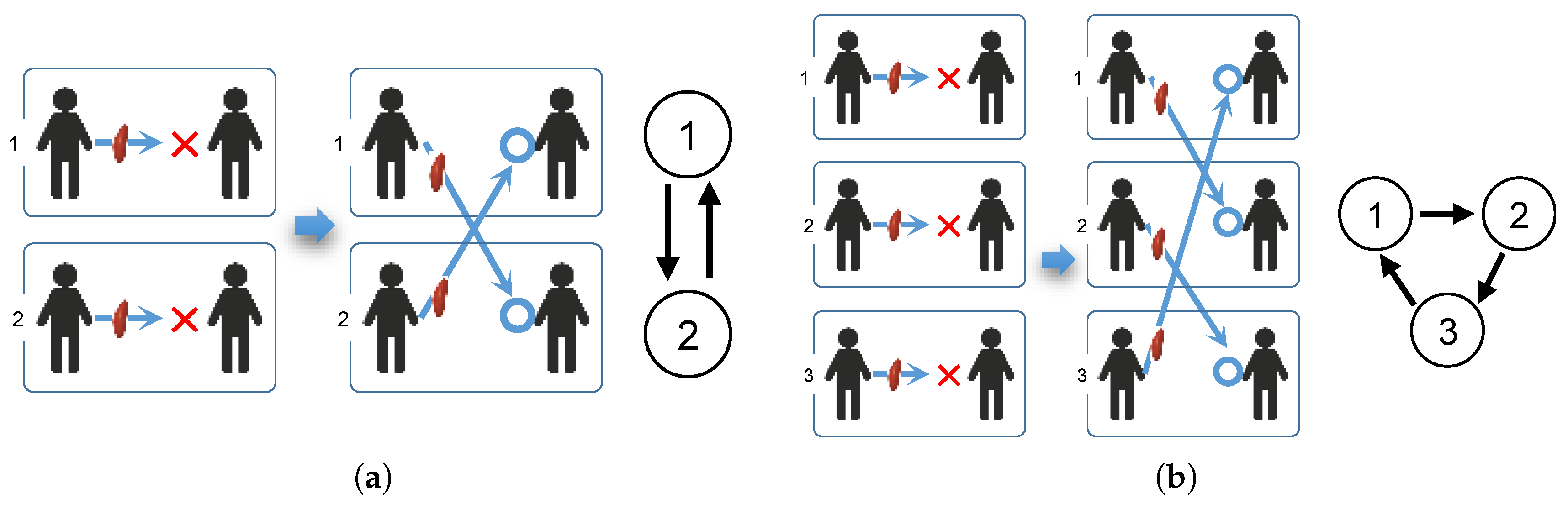
Figure 1 illustrates two-way and three-way KEPs.
Figure 1a illustrates a case consisting of only two pairs. Within each pair, the patient and donor are incompatible. However, the patient in pair 1 is compatible with the donor in pair 2 and the patient in pair 2 is compatible with the donor in pair 1. We note that in precedent times, when exchanges between pairs were not allowed, there was no way to perform the transplants. However, with the KEP, exchanges between the pairs become possible, and the two transplants can be performed. As we will explain in detail below, the KEP can be expressed as a digraph for which a node corresponds to an incompatible donor–recipient pair and a directed arc is introduced if a donor in an initial node is compatible with a recipient in the terminal node of the arc (see the graph in
Figure 1a). In practice, three-way exchanges are the most complicated exchanges performed because one of all the operations on an exchange cycle must be performed simultaneously to avoid the risk of one of the donors reneging, and it is technically difficult to simultaneously reserve operation rooms for more than six patients in a hospital.
Figure 1b illustrates three-way kidney exchanges.
As we briefly mentioned before, the KEP model can be expressed by a digraph
, called a
KEP graph in this paper, where
V and
A indicate the set of vertices and arcs of the graph
G, respectively.
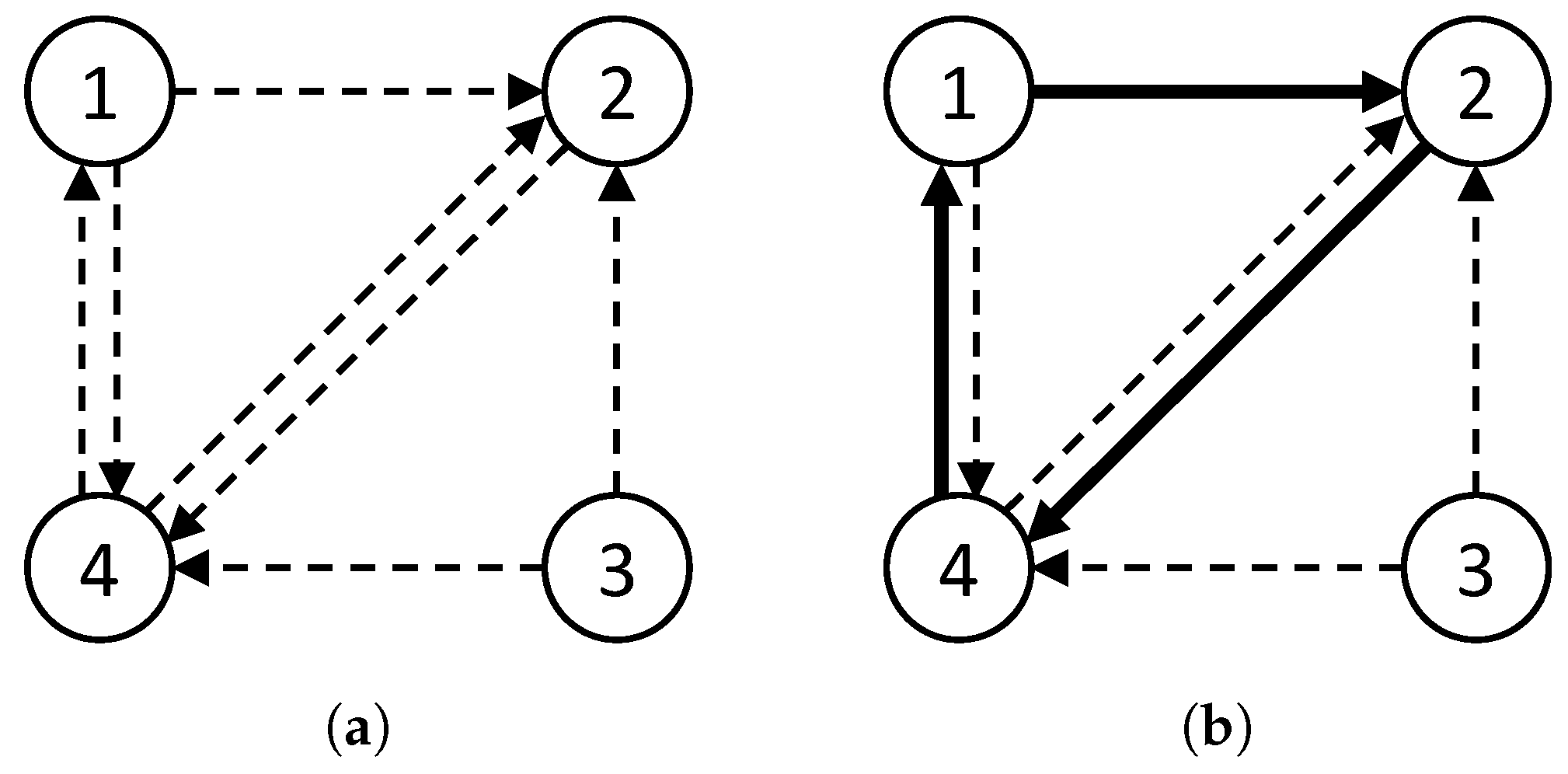
Figure 2 presents an example of
G and a solution to the model (i.e., possible kidney exchanges on a KEP graph). In
Figure 2a, a vertex
corresponds to a current incompatible pair consisting of a patient
i and a donor
i, and an arc
indicates the compatibility between donor
i and patient
j, which means that donor
i can provide his or her kidney to patient
j.
Figure 2b demonstrates an example of a feasible solution. The thick arrows represent an exchange cycle among pairs 1, 2, and 4.
We now discuss the optimization problem for a KEP, given a KEP graph
G. The objective of the optimization of a KEP is generally to maximize the number of possible kidney exchanges in a given pool of candidates, and the KEP can be mathematically modeled as an integer programming problem, which is the main focus of this paper. Roth et al. [
17] proposed an edge formulation and a cycle formulation for KEPs, and Abraham et al. [
7] developed a solution algorithm for those formulations. Furthermore, Constantino et al. [
18] proposed two compact formulations—that is, an edge-assignment (EA) formulation and an extended edge (EE) formulation. Manlove and O’Malley [
19] presented how the cycle formulation by Roth et al. [
17] can be extended to find optimal solutions for the KEP in the United Kingdom, which are compatible with U.K. National Living Donor Kidney Sharing Schemes (NLDKSS).
The reformulation-linearization technique (RLT), which we intend to utilize in this paper, is a procedure that can be used to generate a tight linear programming (LP) relaxation for a discrete optimization problem. Various strong formulations on several classes of structured problems are generated by the RLT. Sherali et al. [
20] developed a new integer programming model for the traveling salesman problem (TSP) by applying the RLT to the Miller–Tucker–Zemlin (MTZ) formulation. Moreover, they showed that the resulting formulation dominates the lifted-MTZ formulation of Desrochers and Laporte [
21]. Sherali et al. [
22] applied the RLT to the path-based TSP model using logical restrictions. They proposed a variety of new formulations for the TSP, and exploited several dominance relationships between them. Park et al. [
23] dealt with a two-level facility location–allocation problem arising from the access network design of a telecommunication network. They developed a mixed-integer program for the problem and applied the RLT to improve computational effectiveness.
In this paper, we focus on the best-known compact formulations for the KEP in the literature, which are the EA and EE formulations proposed by Constantino et al. [
18]. We first induce the EE formulation by applying the partial level 1 RLT to the EA formulation. After that, we further strengthen the formulation via the level 1 RLT and propose a new integer programming model that dominates existing formulations. Computational results are provided to demonstrate the effectiveness of our formulation compared to that of those previous. Therefore, the contribution of our study can be summarized as below.
We propose a new integer programming model, which is proved to be more compact and effective than previous optimization models through computational experiments. Although our new formulation gives a solution that allows only one more patient to have a kidney transplant than the matching solutions made by existing formulations, this is a meaningful result because a kidney transplant is immediately related to the precious life of a patient. Furthermore, our proposed model would be directly related to the performance of the KEP IT healthcare platform.
We derive the EE formulation from the EA formulation by applying a systematic approach, the RLT. As presented by Constantino et al. [
18], establishing a more compact integer programming formulation requires the exploitation of the special structures inherent to the problem of interest. On the other hand, by using our approach, such a formulation can be derived by a simple and systematic application of the RLT independent of the problem-specific structures. This difference suggests the possibility that our approach can be applied to other real-world optimization problems to obtain more significant formulations.
This paper is organized as follows:
Section 2 briefly provides the overview of the RLT for the reference.
Section 3 reviews the two representative integer programming models (i.e., the EE and EA formulations) for the KEP in literature.
Section 4 presents how the EE formulation can be derived from the EA formulation by applying the RLT and how we could further strengthen the EE formulation.
Section 5 presents the computational results. Finally, we conclude the discussion in
Section 6.
2. Reformulation-Linearization Technique
In this section, we briefly describe the concept of the RLT process in the context of zero-one integer problems. Let us define the feasible region of a zero-one integer problem as
where
A is a
matrix,
b is a
q vector, and
is the index set of all variables. Without loss of generality, we assume that every component of
A and
b is an integer. Additionally, the inequalities accommodate the upper bounds of
for
. As usual,
and
denote the sets of binary and real numbers, respectively.
The RLT process by Sherali and Adams [
24] to construct relaxation
at any level
in higher dimensional space consists of two steps, as follows:
- Step 1.
(Reformulation) Multiply each constraint defining the feasible region with every product factor of the form , where , , and , and then apply the identity for all .
- Step 2.
(Linearization) Linearize the resulting polynomial system by substituting a variable for every distinct product term , where .
The results of Sherali and Adams [
24] show that, by denoting the projection of
onto the space of the original variables
x by
, we obtain the hierarchy of relaxations
where
denotes the linear programming relaxation of
X. The results above imply that we can theoretically obtain the convex hull of the feasible solution set
X via the level
r RLT and can hence obtain the optimal solution by solving the linear programming problem over
.
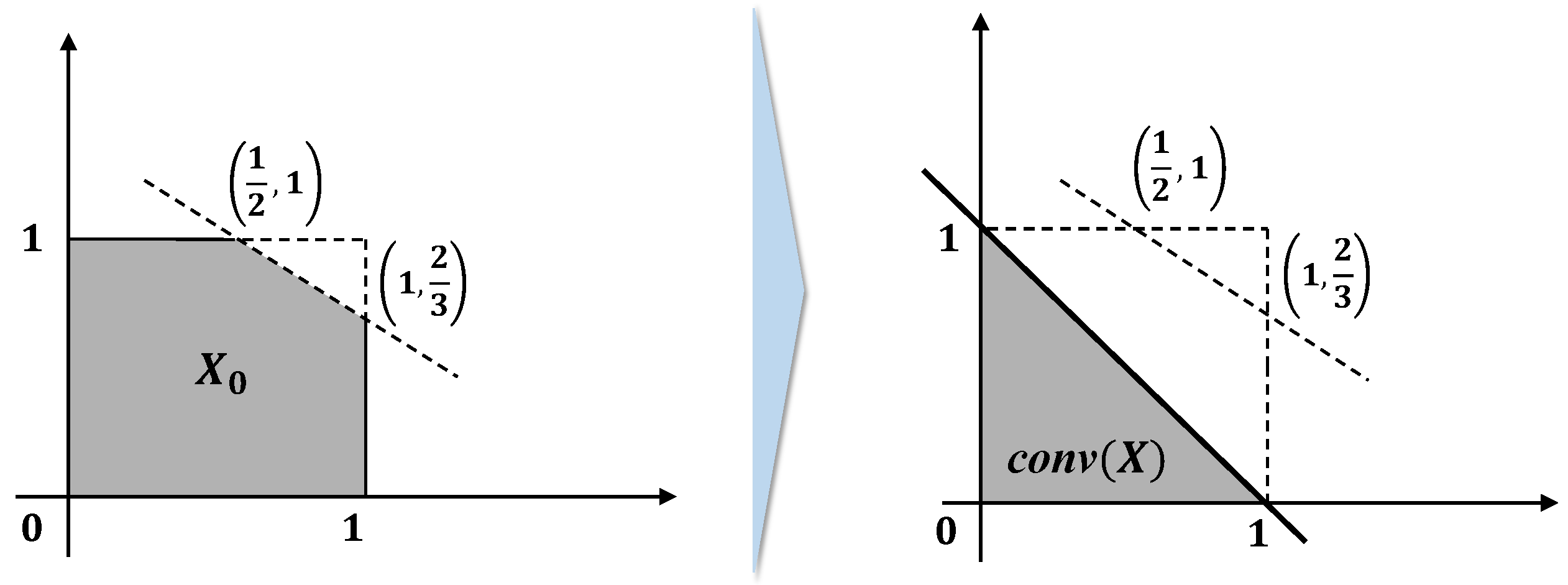
For a better understanding, we illustrate the RLT process through the following example [
25].
Example 1. Consider the following polytope: The linear programming of this polytope is given as ,
and the convex hull of X is given as (see Figure 3). Now, we apply the level 2 RLT to to illustrate how can be obtained by the RLT process.
- Step 1.
(Reformulation) Multiply each constraint of by each of the factors ,
,
,
and .
This process generates various duplicated or redundant inequalities; thus, we summarize the valid inequalities only, as follows: - Step 2.
(Linearization) After linearizing the resulting polynomial system by substituting a variable for the product term ,
we have By and ,
we have .
Therefore, the last set of inequalities produceswhich is .
3. Two Representative Models for the KEP: EA and EE Formulations
In this section, we present two compact formulations, the EA and EE formulations, which were proposed by Constantino et al. [
18] as reference models. In these formulations, the possible cycles in
G and
L are considered to be defined as a set composed of indices
, where
indicates the upper bound on the possible number of cycles in
G. The additional parameters and decision variables used in the formulation are given as follows:
Parameters
: Weight of edge , representing the level of compatibility between donor i and recipient j.
k: Maximum cycle length.
Decision Variables
: 1 if a kidney is transplanted from donor i to patient j, and 0 otherwise.
: 1 if node i is included in cycle l, and 0 otherwise.
Then, the EA formulation is given as follows:
The objective function of Equation (
1a) is to maximize the sum of weights of the transplantations. Because the weight of each edge indicates the appropriateness of the corresponding transplantation, the KEP maximizing the total appropriateness of all transplantations is planned. We note that setting
to the same value for all
allows the maximum number of possible kidney exchanges in a given pool of candidates to be obtained. Constraint (
1b) indicates that if a donor in pair
i donates his or her kidney to a patient in another pair, then the patient in pair
i must receive a kidney. This constraint further implies that if a donor does not participate in transplantation, the paired patient would not receive a kidney. Constraint (
1c) implies that a donor cannot donate more than one kidney. Constraint (
1d) ensures that the length of each cycle cannot be greater than
k. Constraint (
1e) assigns a pair to a cycle if it takes part in kidney exchanges. We note that because
, a pair has to be assigned to one of the cycles. Constraint (
1f) implies that if a donor in pair
i gives his or her kidney to a patient in pair
j and if the pair
i is assigned to a cycle
l, then pair
j also has to be included in cycle
l. Constraints (
1g) and (
1h) indicate that all the decision variables in the model are binary variables.
We now present the EE formulation. We suppose that there are copies of graph G and we let the index of each copy be , where L is a set of the copies of G. Then, the EE formulation requires the additional decision variables , as follows:
Then, the EE formulation is given as follows:
The objective function of Equation (
2a) indicates that the model maximizes the total weight of arcs among all copies of
G. Constraint (
2b) ensures that the number of kidneys given by donor
i and received by patient
i should be same at each pair
i for each copy
l. Constraint (
2c) indicates that a pair can donate or receive at most one kidney. We note that the constraint holds for all copies
and that an arc cannot be selected for more than two copies of
G. Constraint (
2d) restricts the length of exchange cycles to less than or equal to
k.
In addition, in order to have further simplified formulations, symmetry elimination constraints were applied, as discussed by Constantino et al. [
18]:
for the EA formulation, and
for the EE formulation. These inequalities enforce node
l to be in cycle
l and enforce all other nodes in the cycle to have indices larger than
l. For further details, we refer the readers to Constantino et al. [
18].
4. RLT Applications
In this section, we will present the application of the RLT to two existing compact formulations (i.e., the EA and EE formulations). We first show that the EE formulation can be derived by applying the RLT to the EA formulation systemically without relying on any problem-specific structures or insights. After that, we derive a new compact formulation that dominates the EE formulation by further applying the RLT to it.
4.1. Derivation of the EE Formulation from the EA Formulation
We now apply a specialized version of the RLT to the EA formulation by following the discussion by Sherali and Adams [
24,
26]. To contain the size of the resulting relaxation, we apply only a partial first-level version of this approach. Our approach is to first reformulate the EA formulation by generating the additional (nonlinear) implied constraints. By applying a linearization, which substitutes variables in place of each distinct nonlinear term, we can expose the useful relationships between the new and original variables that intend to enforce the nonlinear relationships. Specifically, we perform the following operations:
Reformulation step (R1) produces
for
and
for
. Therefore, we have
for
and we only use
u variables for the linearization. Step (R2) produces
for
. Step (R3) gives
for
, and surrogates them for each
, which results in
for
. By Constraints (
1c) and (
1e), we have
for
. Reformulation step (R4) generates
for
, which leads to
. Therefore,
multiplied by
for each
yields
for
(
is substituted by
l for convenience). Next, surrogating
for each
gives
for
. Hence, by Constraint (
1d), we have
for
. According to the first statement of step (R5) along with
for
, we can obtain
for
. The next statement along with the first result produces
for
. Therefore, we can replace the objective function of Equation (
1a) with
. Consequently, after substituting
for
, the RLT application constructs the EE formulation. We again emphasize that the aforementioned procedures do not rely on any problem-specific structures or insights, but they derive the same compact formulation, the EE formulation, from the EA formulation.
4.2. Extended Formulation Derived from the EE Formulation
In this subsection, we further strengthen the EE formulation by applying the RLT while maintaining the y variables. The specific RLT procedure we perform is explained in detail below.
Reformulation step (R6) produces for . Step (R7) gives three classes of valid inequalities , , and for . Step (R8) generates for . The last step (R9) produces for , and for .
We summarize the overall RLT process above to derive a new compact formulation from the EE formulation in
Figure 4. By augmenting the valid inequalities generated above to some set of constraints from the EE and EA formulations, we derive a new integer programming model for the KEP, which is more compact and tighter than the EE formulation, as follows:
5. Computational Results
In this section, we present the results of the computational experiments for the KEP. The experiments were performed using an Intel(R) Core(TM) i7-4770 CPU @ 3.40 GHz, and CPLEX 12.4 as a LP/MIP (mixed integer programming) optimization solver. The experiments were designed to compare the EA, EE, and RLT formulations in terms of performance. Problem instances were constructed as by Constantino et al. [
18]. A random generator that created random KEP graphs of chosen certain arc densities was used. To be specific, on each position of the node adjacency matrix of a graph, a probability
p is used to determine whether the element equals 1 or 0. Constantino et al. [
18] used values of 0.2, 0.5, and 0.7 for the probability
p. However, it was found that with probabilities of 0.5 and 0.7, almost every instance had an optimal objective
n equal to the number of nodes. Because
n is the trivial upper bound of these KEP problems, no formulation can improve the linear relaxation bound of such problem instances. Thus, because an important goal of this paper is to compare the tightness of KEP formulations,
p was set to 0.1, 0.2, and 0.5 for low-, medium-, and high-density instances, respectively. For each density, we generated the problem instances with the input parameter
. In addition,
n, the number of pairs, was further set to 10, 20, and 30 for each
k. For each
n and
k, 10 instances were generated and tested. All the cases were executed within a time limit of 3600 s. The formulations were compared in terms of the optimality gap (GAP) and the execution time. The GAP is calculated by
, where
is the best objective function value of the integer programming model and
is the optimal objective function value of the corresponding linear programming relaxation. Hence, the lower the GAP obtained, the better the solution (i.e., closer to the optimal solution). On the other hand,
and
are the average elapsed time of the integer programming model and its linear programming relaxation, respectively.
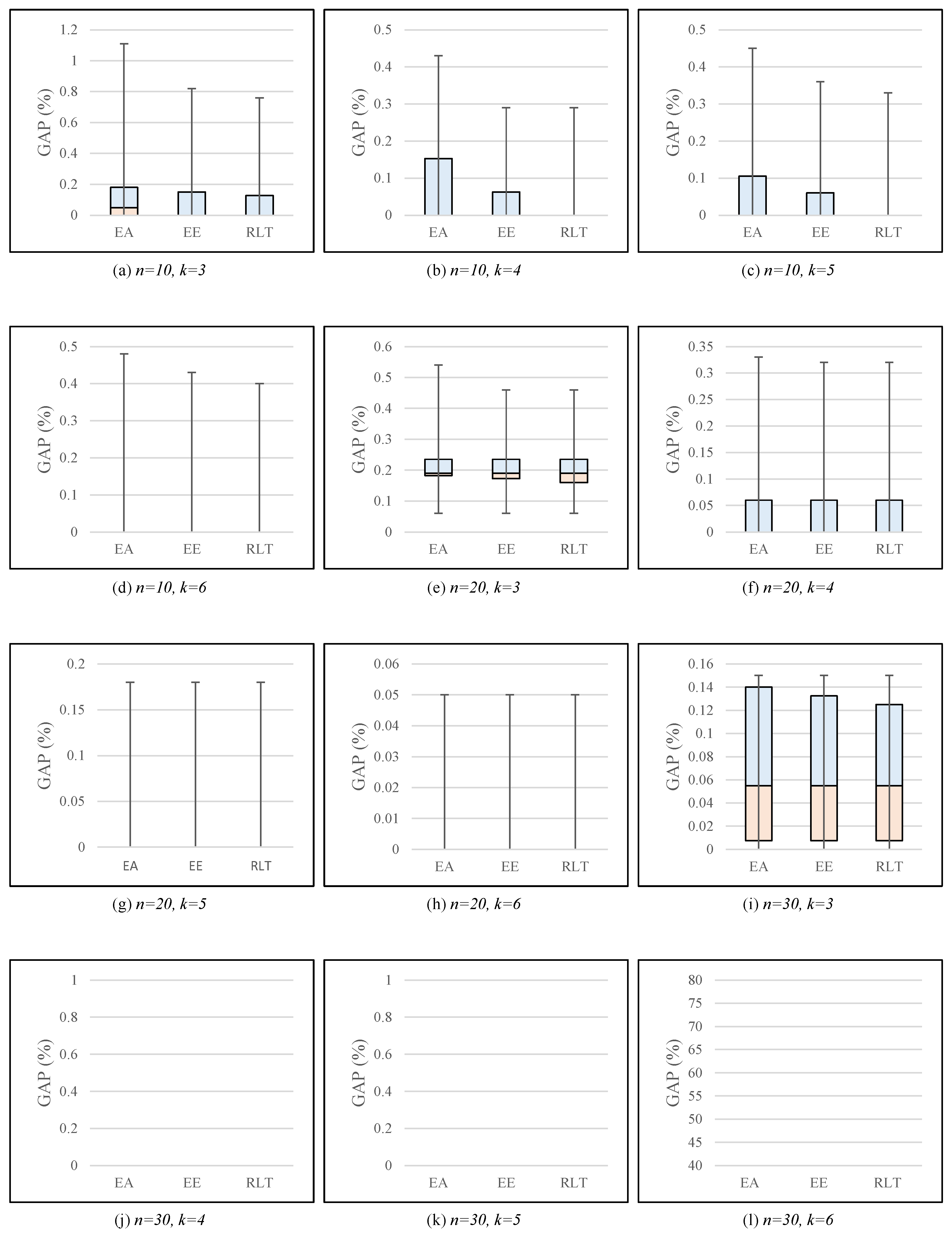
Table 1 summarizes the computational results for low-density instances. The EE formulation found the optimal upper bound for 43 out of 120 low-density instances. Of the remaining 77 instances for which the EE formulation could not find the optimal solution, the upper bounds of 36 instances were improved by our RLT model. Subsequently, the average value of the GAP was improved by our RLT formulation. On the other hand, the improvement in the GAP obtained by the RLT formulation tended to be smaller as
k grew.
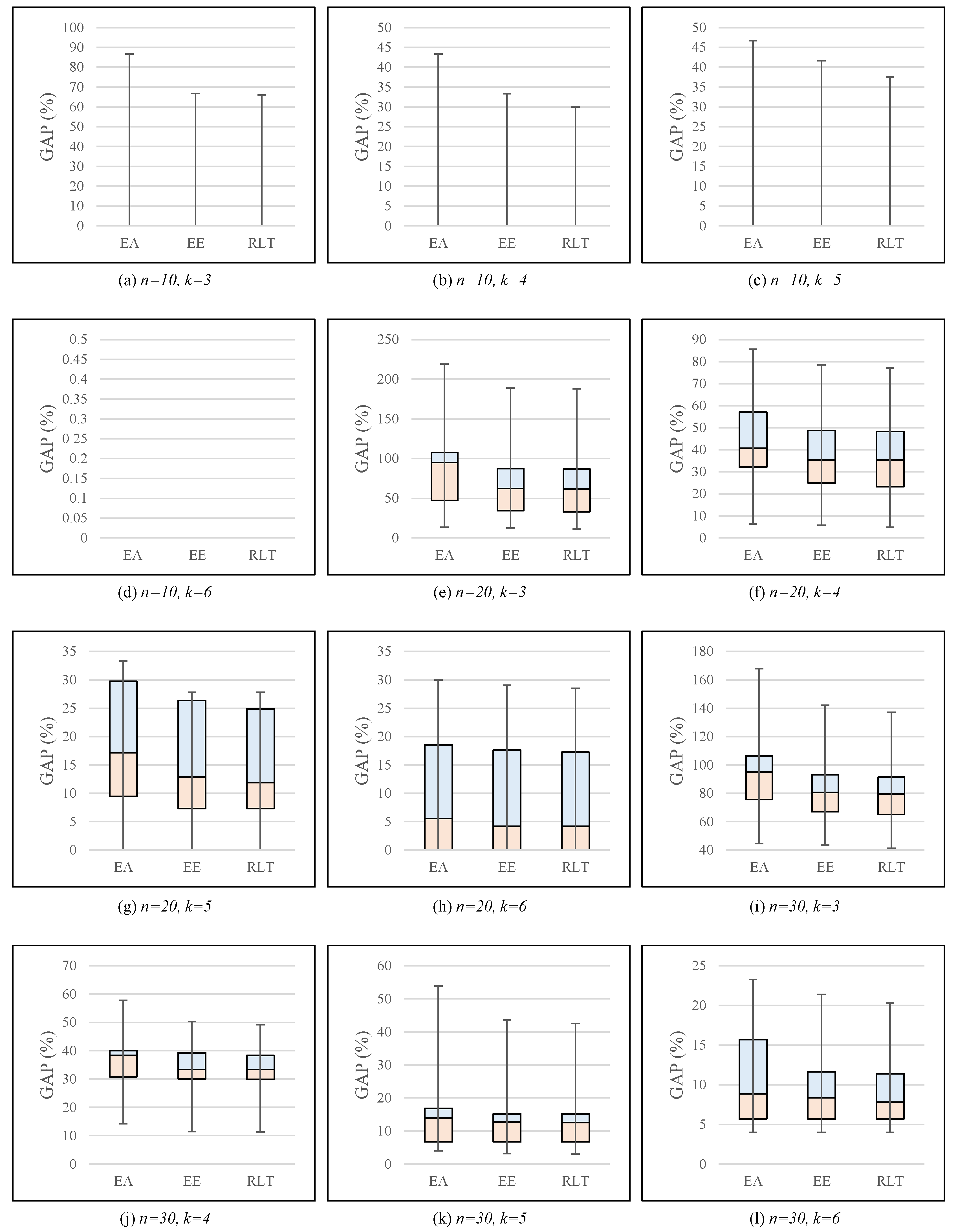
Figure 5 presents box plots of the GAPs (%) produced by each formulation from problem instances for each combination of
. From the figure, we can observe that our RLT formulation yielded the lowest average GAPs, and that furthermore, the variability of the GAPs produced by our RLT formulation was also lower than that of the best-known compact formulations. Specifically, both the maximum and minimum GAPs, as well as the difference between the lower and upper quartiles, significantly dropped from the EA formulation to the EE formulation, and then further again to the RLT formulation. Moreover, such observations were consistent for every combination of
. The results imply that the EA formulation is highly dominated by the EE and RLT formulations, and moreover, that our proposed RLT formulation is more reliable than the EE formulation in terms of solution quality—that is, our approach produces more reliable and higher quality solutions than the best-known compact formulations, without compromising computational time.
Similarly,
Table 2 demonstrates the computational results for medium-density instances. According to the results, the average GAP was smaller than for the low-density instances for all the formulations. Having such a result is intuitive because the medium-density graph had more arcs representing compatibility; thus, feasible solutions could be more easily found than in the low-density cases. In the experiments, the EE formulation found the optimal upper bounds for 83 out of 120 instances. Our RLT formulation improved the upper bounds of 17 out of the remaining 37 instances whose optimal solutions were not obtained by the EE formulation. When it comes to the box plots of the GAPs for the medium-density problem instances, we are able to make similar observations to those for the low-density instances as presented in
Figure 6. As mentioned previously, compared to the low-density case, there were more combinations of
for which the GAPs of all the problem instances were equal to zero (i.e., (j), (k) and (l) in
Figure 6).
Finally, the computational results for the high-density instances are presented in
Table 3. We observe that the GAPs of all the formulations were equal to 0 for all the instances; hence, we here compare them in terms of the computational time only. As presented in
Table 3, in terms of computational time, the RLT formulation outperformed the EA formulation, but the EE formulation performed slightly better than the RLT formulation. However, both cases were reasonably acceptable for practical-size problems. We remark that high-density instances rarely appear in real-world situations, as a donor is unlikely to find as many compatible patients as in high-density cases in a given pool of candidates.
6. Conclusions
In this paper, we first show that the EE formulation, until now considered to be the most compact formulation, can be systematically derived from the EA formulation through the RLT process. A previous study developed the EE formulation by exploiting special structures inherent to the problem. However, we show that we can readily apply the RLT procedure to the EA formulation to obtain the same EE formulation. Furthermore, we apply the RLT to the EA and EE formulations and thereby derive a tighter and more compact formulation. Computational results show that the proposed RLT model outperforms the existing EA and EE formulations in terms of solution quality as well as computational time. Specifically, the RLT model provides improved GAPs in several instances for which the EE formulation could not find the optimal solutions within the time limit—especially for low- and medium-density graphs. For high-density instances, although the RLT model does not significantly reduce the execution time, it can produce the same high-quality solutions as the existing formulations. We believe that, given the results obtained by the proposed model, it could be utilized in the integrated KEP IT healthcare platform to obtain optimized KEP exchange plans.
As extended research, several models derived from that proposed in this paper can be considered. For example, firstly, a problem dealing with fair allocations, such as in terms of donor and patient age and health, among the pairs in the candidate pool may be interesting. Indeed, some problems of fairness in kidney transplantation or kidney exchange are discussed by Bertsimas et al. [
27] and by Anderson [
15] respectively in literature. Secondly, some limitations of this study include that all data (e.g.,
) were considered to be certain. When a KEP solution is actually implemented, it may be possible to have several unexpected events, including last-minute incompatibility and unavailability of either donors or recipients [
28,
29]. To handle the data or event uncertainty in KEPs, Alvelos et al. [
29], for example, examined an optimization problem whose objective was to maximize the expected number of transplants in a KEP given that all the arcs and vertices in a KEP graph have equal probabilities of failure, and there are some attempts to apply robust optimization theory [
30,
31] to a KEP [
28]. Thus, we can extend our model to incorporate the aforementioned uncertainties and take the solution approaches, such as stochastic optimization or robust optimization techniques, into account. Finally, proposing an efficient heuristic-based approach for solving highly large-scale problems more generally would be the topic for future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}