Minimum Barrier Distance-Based Object Descriptor for Visual Tracking

Abstract
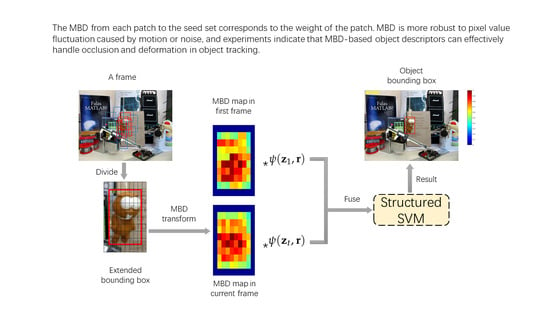
:
1. Introduction
2. Related Work
3. The Proposed Algorithm
3.1. Overview
3.2. Patch-Based Representation
3.3. MBD-Based Patch Weighting
| Algorithm 1 Minimum Barrier Distance transform. |
| Input: image G, seed set S, number of passes k. Output: MBD map D.
|
3.4. Structured SVM Tracking
4. Experimental Results
4.1. Evaluation Method
4.2. Qualitative Evaluation
4.3. Quantitative Evaluation
4.3.1. Evaluation on OTB-100
4.3.2. Evaluation on TColor-128
4.3.3. Evaluation on Challenges
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wang, X.; Li, C.; Luo, B.; Tang, J. SINT++: Robust Visual Tracking via Adversarial Positive Instance Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Li, X.; Shen, C.; Dick, A.; van den Hengel, A. Learning Compact Binary Codes for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2419–2426. [Google Scholar]
- Torr, P.H.; Hare, S.; Saffari, A. Struck: Structured output tracking with kernels. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 263–270. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Han, Z.; Wang, L.; Lu, H. Visual Tracking via Random Walks on Graph Model. IEEE Trans. Cybern. 2016, 46, 2144–2155. [Google Scholar] [CrossRef] [PubMed]
- Nam, H.; Han, B. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the IEEE International Conference on Machine Learning, Miami, FL, USA, 9–11 December 2015; pp. 597–606. [Google Scholar]
- Li, C.; Lin, L.; Zuo, W.; Tang, J. Learning Patch-Based Dynamic Graph for Visual Tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4126–4132. [Google Scholar]
- Kim, H.U.; Lee, D.Y.; Sim, J.Y.; Kim, C.S. SOWP: Spatially Ordered and Weighted Patch Descriptor for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Stanford, CA, USA, 25–28 October 2016; pp. 3011–3019. [Google Scholar]
- Kim, G.Y.; Kim, J.H.; Park, J.S.; Kim, H.T.; Yu, Y.S. Vehicle Tracking using Euclidean Distance. J. Korea Inst. Electron. Commun. Sci. 2012, 7, 1293–1299. [Google Scholar]
- Li, Y.; Zhu, J.; Hoi, S.C.H. Reliable Patch Trackers: Robust visual tracking by exploiting reliable patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 353–361. [Google Scholar]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-modal ranking with soft consistency and noisy labels for RGB-T object tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Strand, R.; Ciesielski, K.C.; Malmberg, F.; Saha, P.K. The minimum barrier distance. Comput. Vis. Image Understand. 2013, 117, 429–437. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient Object Detection: A Discriminative Regional Feature Integration Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Wei, Y.; Wen, F.; Zhu, W.; Sun, J. Geodesic Saliency Using Background Priors. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 29–42. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; Chang, H.J.; Yun, S.; Fischer, T.; Demiris, Y.; Jin, Y.C. Attentional Correlation Filter Network for Adaptive Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4828–4837. [Google Scholar]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust Tracking via Multiple Experts Using Entropy Minimization. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 188–203. [Google Scholar]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. MUlti-Store Tracker (MUSTer): A cognitive psychology inspired approach to object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 749–758. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwon, J.; Lee, K.M. Visual tracking decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1269–1276. [Google Scholar]
- Mei, X.; Ling, H. Robust Visual Tracking and Vehicle Classification via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2259–2272. [Google Scholar] [PubMed] [Green Version]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Tracking by Prediction: A Deep Generative Model for Mutli-person Localisation and Tracking. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1122–1132. [Google Scholar]
- Feng, P.; Xu, C.; Zhao, Z.; Liu, F.; Guo, J.; Yuan, C.; Wang, T.; Duan, K. A deep features based generative model for visual tracking. Neurocomputing 2018, 308, 245–254. [Google Scholar] [CrossRef]
- Avidan, S. Support Vector Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16-22 June 2003; pp. 1064–1072. [Google Scholar]
- Matas, J.; Mikolajczyk, K.; Kalal, Z. P-N learning: Bootstrapping binary classifiers by structural constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 49–56. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust Object Tracking with Online Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ning, J.; Yang, J.; Jiang, S.; Zhang, L.; Yang, M.H. Object Tracking via Dual Linear Structured SVM and Explicit Feature Map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4266–4274. [Google Scholar]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning Collaborative Sparse Representation for Grayscale-thermal Tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wu, X.; Zhao, N.; Cao, X.; Tang, J. Fusing two-stream neural networks for RGB-T object tracking. Neurocomputing 2018, 281, 71–85. [Google Scholar] [CrossRef]
- Wen, L.; Cai, Z.; Lei, Z.; Yi, D.; Li, S.Z. Robust Online Learned Spatio-Temporal Context Model for Visual Tracking. IEEE Trans. Image Process. 2014, 23, 785–796. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.; Torr, P. Struck: Structured Output Tracking with Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Lu, S.; Wang, D.; Wang, S.; Leung, H. Pixel-Wise Spatial Pyramid-Based Hybrid Tracking. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1365–1376. [Google Scholar] [CrossRef]
- He, S.; Yang, Q.; Lau, R.W.H.; Wang, J.; Yang, M.H. Visual Tracking via Locality Sensitive Histograms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2427–2434. [Google Scholar]
- Wang, L.; Lu, H.; Yang, M. Constrained Superpixel Tracking. IEEE Trans. Cybern. 2018, 48, 1030–1041. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Fang, J.; Wang, Q. Robust Superpixel Tracking via Depth Fusion. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 15–26. [Google Scholar] [CrossRef]
- Yeo, D.; Son, J.; Han, B.; Han, J.H. Superpixel-Based Tracking-by-Segmentation Using Markov Chains. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 511–520. [Google Scholar]
- Yang, F.; Lu, H.; Yang, M.H. Robust superpixel tracking. IEEE Trans. Image Process. 2014, 23, 1639–1651. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Lin, L.; Zuo, W.; Tang, J.; Yang, M.H. Visual Tracking via Dynamic Graph Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Meshgi, K.; Maeda, S.I.; Oba, S.; Ishii, S. Data-Driven Probabilistic Occlusion Mask to Promote Visual Tracking. In Proceedings of the IEEE Conference on Computer and Robot Vision, Victoria, BC, Canada, 1–3 June 2016; pp. 178–185. [Google Scholar]
- Kwak, S.; Nam, W.; Han, B.; Han, J.H. Learning occlusion with likelihoods for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1551–1558. [Google Scholar]
- Liu, T.; Wang, G.; Yang, Q. Real-time part-based visual tracking via adaptive correlation filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4902–4912. [Google Scholar]
- Strand, R.; Ciesielski, K.C.; Malmberg, F.; Saha, P.K. The Minimum Barrier Distance: A Summary of Recent Advances. In Proceedings of the International Conference on Discrete Geometry for Computer Imagery, Vienna, Austria, 19–21 September 2017; pp. 57–68. [Google Scholar]
- Ciesielski, K.C.; Strand, R.; Malmberg, F.; Saha, P.K. Efficient algorithm for finding the exact minimum barrier distance. Comput. Vis. Image Understand. 2014, 123, 53–64. [Google Scholar] [CrossRef]
- Zhang, J.; Sclaroff, S.; Lin, Z.; Shen, X.; Price, B.; Mech, R. Minimum Barrier Salient Object Detection at 80 FPS. In Proceedings of the IEEE International Conference on Computer Vision, Lyon, France, 19–22 October 2015; pp. 1404–1412. [Google Scholar]
- Wang, Q.; Zhang, L.; Kpalma, K. Fast filtering-based temporal saliency detection using Minimum Barrier Distance. In Proceedings of the IEEE International Conference on Multimedia Expo Workshops, Hong Kong, China, 10–14 July 2017; pp. 232–237. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Liang, P.; Blasch, E.; Ling, H. Encoding Color Information for Visual Tracking: Algorithms and Benchmark. IEEE Trans. Image Process. 2015, 24, 5630–5644. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.H. Long-term correlation tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Yang, T.; Chan, A.B. Learning Dynamic Memory Networks for Object Tracking. arXiv, 2018; arXiv:1803.07268. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. DCFNet: Discriminant Correlation Filters Network for Visual Tracking. arXiv, 2017; arXiv:1704.04057. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Jia, X.; Lu, H.; Yang, M.H. Visual tracking via adaptive structural local sparse appearance model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1822–1829. [Google Scholar]
- Dubuisson, S.; Gonzales, C. A survey of datasets for visual tracking. Mach. Vis. Appl. 2015, 27, 23–52. [Google Scholar] [CrossRef]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T Object Tracking: Benchmark and Baseline. arXiv, 2018; arXiv:1805.08982. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MEEM [19] | MUSTer [20] | SOWP [10] | LCT [50] | DSST [48] | KCF [5] | Struck [4] | TLD [21] | ACFN [18] | OURS | |
|---|---|---|---|---|---|---|---|---|---|---|
| IV (36) | 0.728/0.515 | 0.770/0.592 | 0.766/0.554 | 0.732/0.557 | 0.708/0.485 | 0.693/0.471 | 0.545/0.422 | 0.535/0.401 | 0.777/0.554 | 0.765/0.553 |
| OPR (63) | 0.794/0.525 | 0.744/0.537 | 0.787/0.547 | 0.746/0.538 | 0.670/0.448 | 0.670/0.450 | 0.593/0.424 | 0.570/0.390 | 0.777/0.543 | 0.816/0.573 |
| SV (64) | 0.736/0.470 | 0.710/0.512 | 0.746/0.475 | 0.681/0.488 | 0.662/0.409 | 0.636/0.396 | 0.600/0.404 | 0.565/0.388 | 0.764/0.551 | 0.779/0.526 |
| OCC (49) | 0.741/0.504 | 0.734/0.554 | 0.754/0.528 | 0.682/0.507 | 0.615/0.426 | 0.625/0.441 | 0.537/0.394 | 0.535/0.371 | 0.756/0.542 | 0.799/0.557 |
| DEF (44) | 0.754/0.489 | 0.689/0.524 | 0.741/0.527 | 0.689/0.499 | 0.568/0.412 | 0.617/0.436 | 0.527/0.383 | 0.484/0.341 | 0.772/0.535 | 0.813/0.563 |
| MB (29) | 0.731/0.556 | 0.678/0.544 | 0.702/0.567 | 0.669/0.533 | 0.611/0.467 | 0.606/0.463 | 0.594/0.468 | 0.542/0.435 | 0.731/0.568 | 0.757/0.592 |
| FM (39) | 0.752/0.542 | 0.683/0.533 | 0.723/0.556 | 0.681/0.534 | 0.584/0.442 | 0.625/0.463 | 0.626/0.470 | 0.563/0.434 | 0.758/0.566 | 0.780/0.595 |
| IPR (51) | 0.794/0.529 | 0.773/0.551 | 0.828/0.567 | 0.782/0.557 | 0.724/0.485 | 0.697/0.467 | 0.639/0.453 | 0.613/0.432 | 0.785/0.546 | 0.801/0.562 |
| OV (14) | 0.685/0.488 | 0.591/0.469 | 0.633/0.497 | 0.592/0.452 | 0.487/0.373 | 0.512/0.401 | 0.503/0.384 | 0.488/0.361 | 0.692/0.508 | 0.713/0.537 |
| BC (31) | 0.746/0.519 | 0.784/0.581 | 0.775/0.570 | 0.734/0.550 | 0.702/0.477 | 0.718/0.500 | 0.566/0.438 | 0.470/0.362 | 0.769/0.542 | 0.783/0.590 |
| LR (9) | 0.808/0.382 | 0.747/0.415 | 0.903/0.423 | 0.699/0.399 | 0.708/0.314 | 0.671/0.290 | 0.671/0.313 | 0.627/0.346 | 0.818/0.515 | 0.808/0.457 |
| average (100) | 0.781/0.530 | 0.774/0.577 | 0.803/0.560 | 0.762/0.562 | 0.695/0.475 | 0.693/0.476 | 0.640/0.463 | 0.597/0.427 | 0.802/0.575 | 0.835/0.595 |
| MemTrack [51] | Scale_DLSSVM [29] | DCFNet [52] | CNN-SVM [8] | SiamFC-3s [53] | SINT++ [2] | OURS-Eu | OURS-L1 | OURS-KL | OURS-Ga | OURS | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PR | 0.822 | 0.803 | 0.751 | 0.814 | 0.772 | 0.768 | 0.751 | 0.797 | 0.762 | 0.604 | 0.835 |
| SR | 0.627 | 0.562 | 0.580 | 0.555 | 0.583 | 0.574 | 0.546 | 0.563 | 0.550 | 0.407 | 0.595 |
| Car4 | Girl | Coke | Deer | Tiger1 | Couple | Singer1 | Singer2 | Shaking | CarScale | Football | Football1 | Walking2 | Sylvester | Freeman1 | Freeman3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPVT [43] | 2.0 | 2.8 | 9.7 | 4.5 | 5.5 | 7.2 | 5.0 | 12.5 | 5.6 | 7.5 | 4.8 | 2.5 | 3.1 | 5.6 | 10.0 | 3.0 |
| Ours | 2.4 | 4.2 | 5.9 | 4.4 | 11.6 | 5.3 | 7.0 | 162.5 | 9.6 | 15.9 | 3.8 | 2.7 | 8.2 | 6.6 | 2.7 | 3.3 |
| Car4 | Girl | Coke | Deer | Tiger1 | Couple | Singer1 | Singer2 | Shaking | CarScale | Football | Football1 | Walking2 | Sylvester | Freeman1 | Freeman3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPVT [43] | 90 | 80 | 72 | 76 | 65 | 68 | 75 | 82 | 72 | 70 | 72 | 78 | 82 | 71 | 47 | 82 |
| Ours | 84 | 59 | 55 | 79 | 69 | 60 | 38 | 7 | 69 | 55 | 71 | 79 | 60 | 68 | 47 | 64 |
| Basketball | Bolt | Boy | CarDark | Cross | David1 | David2 | David3 | Dog | Doll | Dudek | Faceocc1 | Faceocc2 | Fish | Fleetface | Freeman4 | Ironman | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPVT [43] | 6.3 | 8.2 | 3.5 | 3.1 | 7.6 | 8.5 | 10.3 | 16.4 | 4.2 | 8.5 | 10.9 | 10.8 | 5 | 8.7 | 8.5 | 20.1 | 73 |
| Ours | 4.2 | 3.5 | 2.1 | 1.1 | 2.2 | 3.7 | 1.8 | 5.1 | 5.1 | 6.5 | 11.0 | 14.0 | 9.3 | 8.5 | 21.5 | 61.5 | 54.8 |
| Jogging | Jumping | Lemming | Liquor | Matrix | Mhyang | Motor | MountainBike | Skating1 | Skiing | Soccer | Subway | Suv | Tiger2 | Trellis | Walking | Woman | |
| RPVT [43] | 14.6 | 7.0 | 22.4 | 15.6 | 26 | 17.3 | 67.8 | 6.5 | 7.9 | 86.2 | 55.6 | 4.3 | 9 | 12.3 | 10.6 | 5.3 | 4.1 |
| Ours | 4.4 | 3.0 | 7.0 | 6.1 | 86.0 | 4.7 | 148.7 | 8.6 | 21.6 | 4.7 | 61.4 | 3.5 | 11.8 | 11.3 | 12.7 | 3.4 | 4.0 |
| Jumping | Car4 | Singer1 | Walking1 | Walking2 | Sylvester | Deer | FaceOcc2 | |
|---|---|---|---|---|---|---|---|---|
| OPM [41] | 2.7 | 4.1 | 3.9 | 2.6 | 0.5 | 2.4 | 0.9 | 4.7 |
| Ours | 3.0 | 2.4 | 7.0 | 3.4 | 8.2 | 6.6 | 4.4 | 9.3 |
| ACFN [18] | Staple [54] | MEEM [19] | Struck [4] | KCF [5] | LCT [50] | SOWP [10] | DGT [9] | OURS | |
|---|---|---|---|---|---|---|---|---|---|
| PO (41) | 0.724/0.547 | 0.763/0.553 | 0.730/0.514 | 0.635/0.475 | 0.647/0.484 | 0.682/0.537 | 0.781/0.555 | 0.778/0.557 | 0.806/0.567 |
| HO (43) | 0.567/0.382 | 0.458/0.360 | 0.583/0.413 | 0.337/0.265 | 0.418/0.302 | 0.453/0.335 | 0.541/0.403 | 0.568/0.427 | 0.567/0.419 |
| SBC (31) | 0.830/0.587 | 0.858/0.620 | 0.816/0.562 | 0.684/0.500 | 0.777/0.533 | 0.770/0.565 | 0.838/0.593 | 0.819/0.566 | 0.868/0.620 |
| HBC (27) | 0.669/0.481 | 0.576/0.409 | 0.655/0.442 | 0.458/0.331 | 0.529/0.347 | 0.569/0.392 | 0.626/0.445 | 0.630/0.443 | 0.629/0.436 |
| MB (53) | 0.638/0.484 | 0.599/0.463 | 0.639/0.490 | 0.575/0.442 | 0.547/0.408 | 0.586/0.438 | 0.647/0.498 | 0.670/0.490 | 0.653/0.493 |
| DEF (63) | 0.744/0.537 | 0.686/0.500 | 0.743/0.497 | 0.616/0.440 | 0.611/0.435 | 0.686/0.508 | 0.741/0.531 | 0.768/0.523 | 0.795/0.555 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, Z.; Guo, L.; Li, C.; Xiong, Z.; Wang, X. Minimum Barrier Distance-Based Object Descriptor for Visual Tracking. Appl. Sci. 2018, 8, 2233. https://doi.org/10.3390/app8112233
Tu Z, Guo L, Li C, Xiong Z, Wang X. Minimum Barrier Distance-Based Object Descriptor for Visual Tracking. Applied Sciences. 2018; 8(11):2233. https://doi.org/10.3390/app8112233
Chicago/Turabian StyleTu, Zhengzheng, Linlin Guo, Chenglong Li, Ziwei Xiong, and Xiao Wang. 2018. "Minimum Barrier Distance-Based Object Descriptor for Visual Tracking" Applied Sciences 8, no. 11: 2233. https://doi.org/10.3390/app8112233
APA StyleTu, Z., Guo, L., Li, C., Xiong, Z., & Wang, X. (2018). Minimum Barrier Distance-Based Object Descriptor for Visual Tracking. Applied Sciences, 8(11), 2233. https://doi.org/10.3390/app8112233