A Novel Discriminating and Relative Global Spatial Image Representation with Applications in CBIR

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
3. Proposed Methodology
3.1. BoVW Model
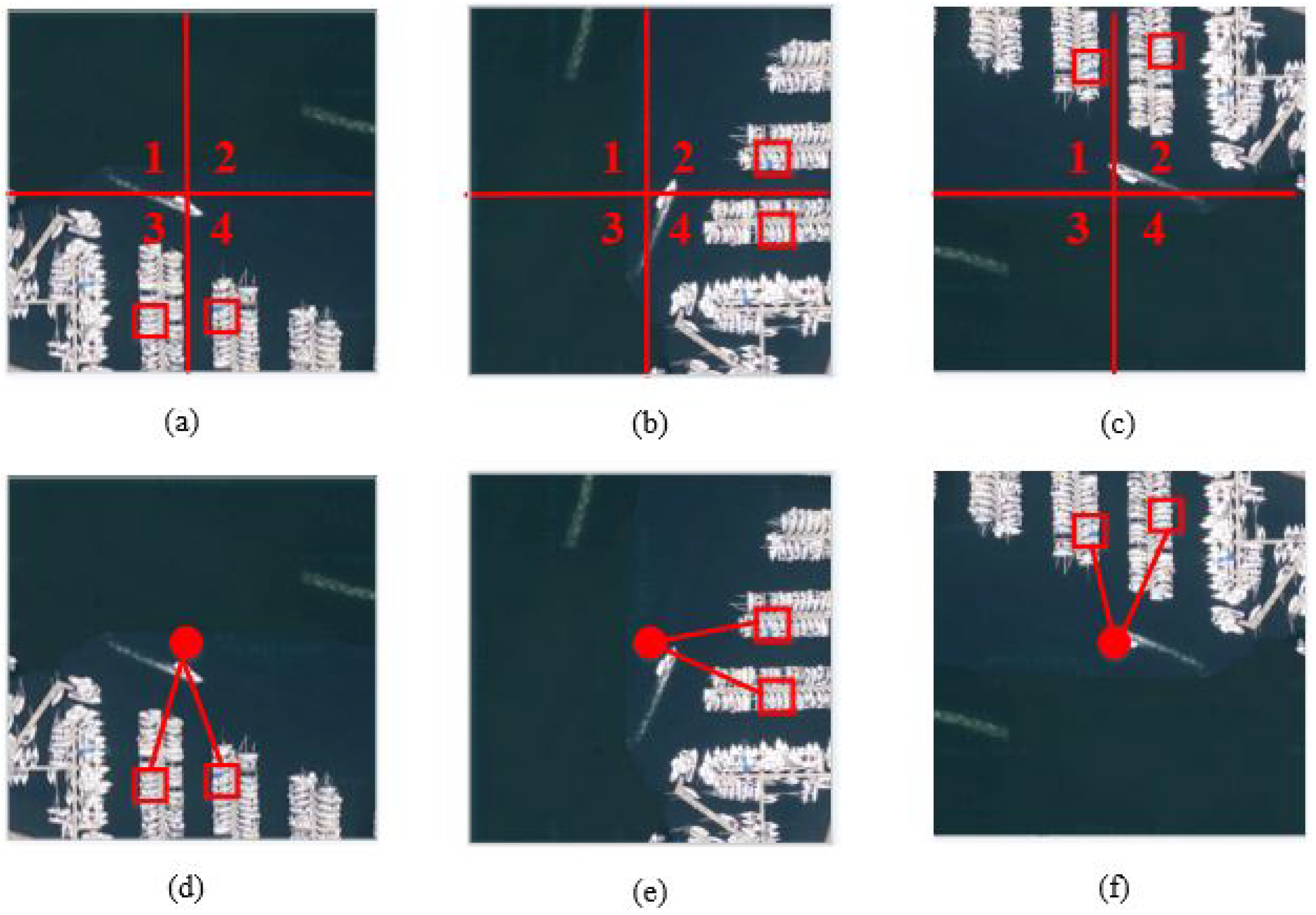
3.2. The Proposed Relative Global Spatial Image Representation (RGSIR)
3.3. Implementation Details
4. Datasets and Performance Evaluation
4.1. Dataset Description
4.2. Evaluation Measures
4.2.1. Precision
4.2.2. Recall
4.2.3. Mean Average Precision (MAP)
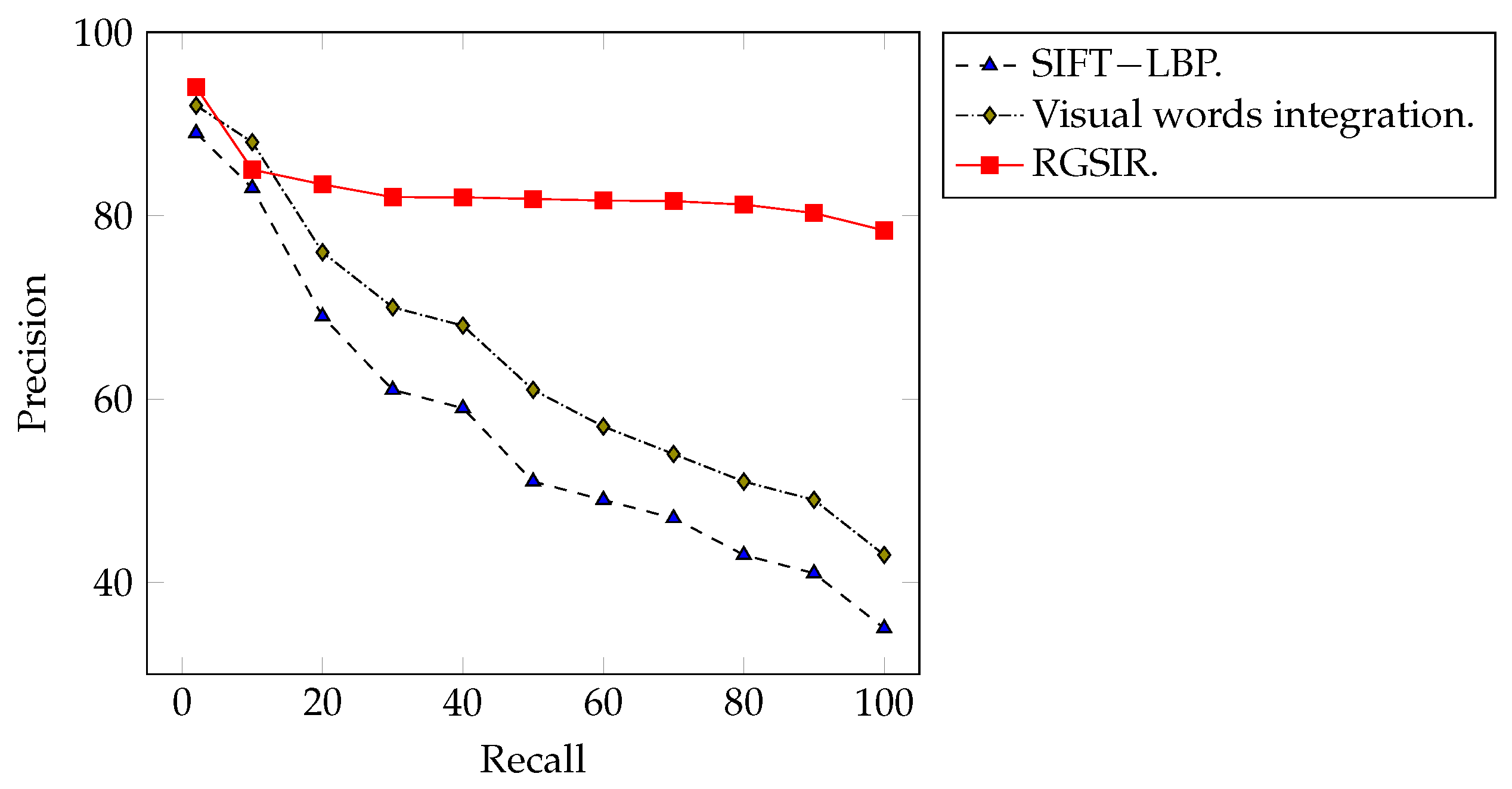
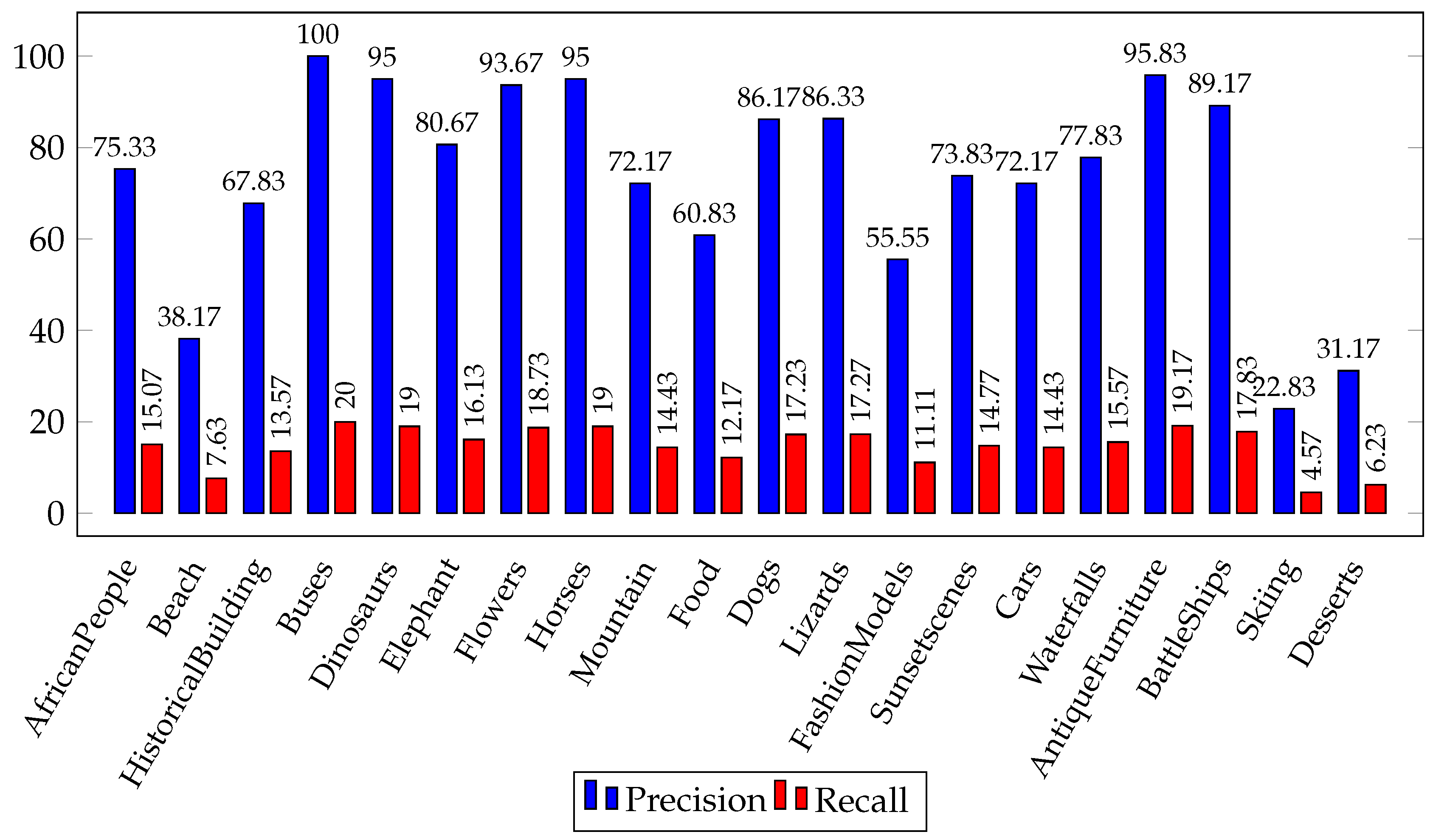
4.3. Performance on Corel-1K Image Dataset
4.4. Performance on Corel-1.5K Image Dataset
4.5. Performance on Corel-2K image Dataset
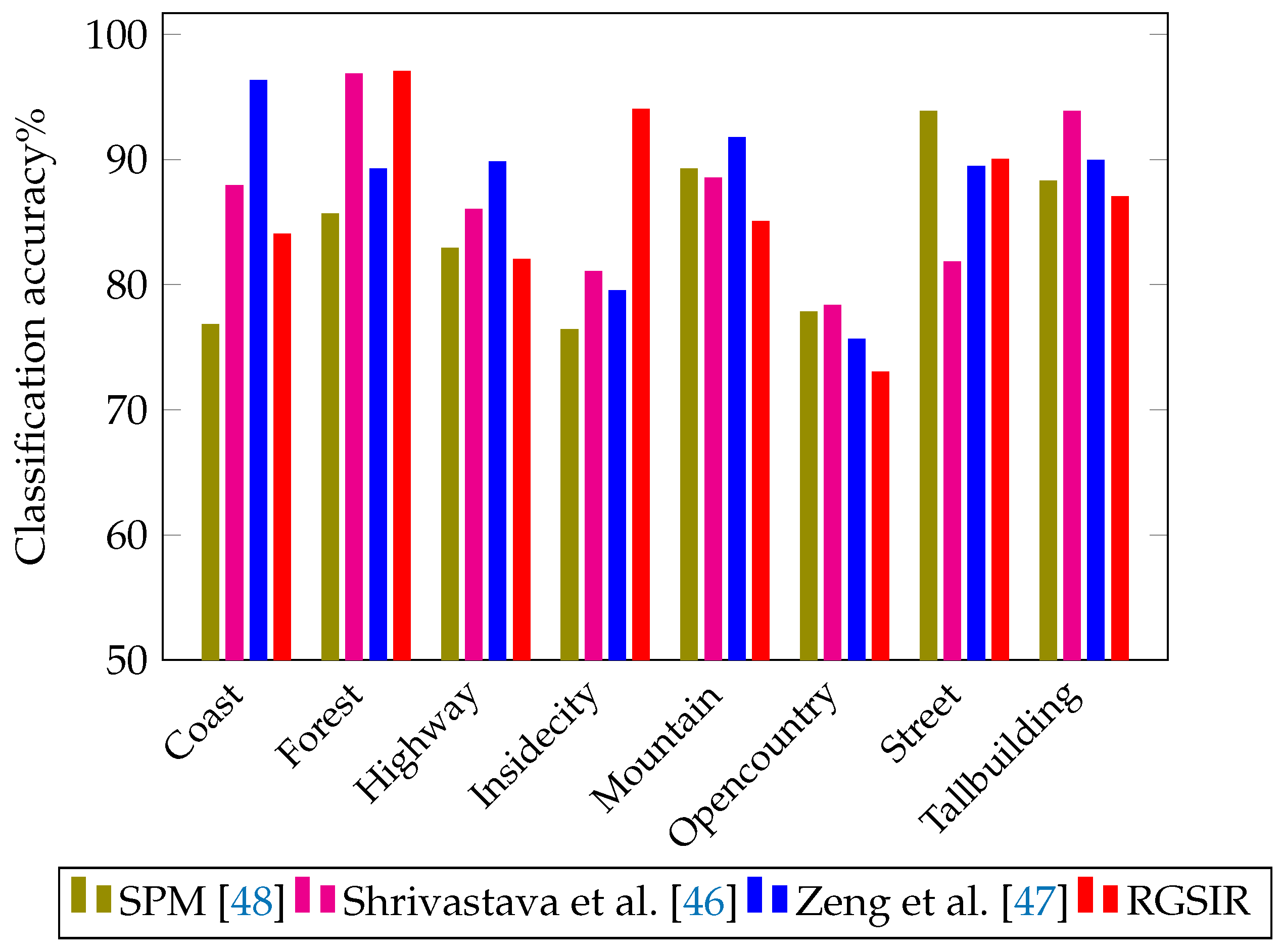
4.6. Image Retrieval Performance While Using Oliva and Torralba (OT-Scene) Dataset
4.7. Performance on the RSSCN Image Dataset
5. Discussion
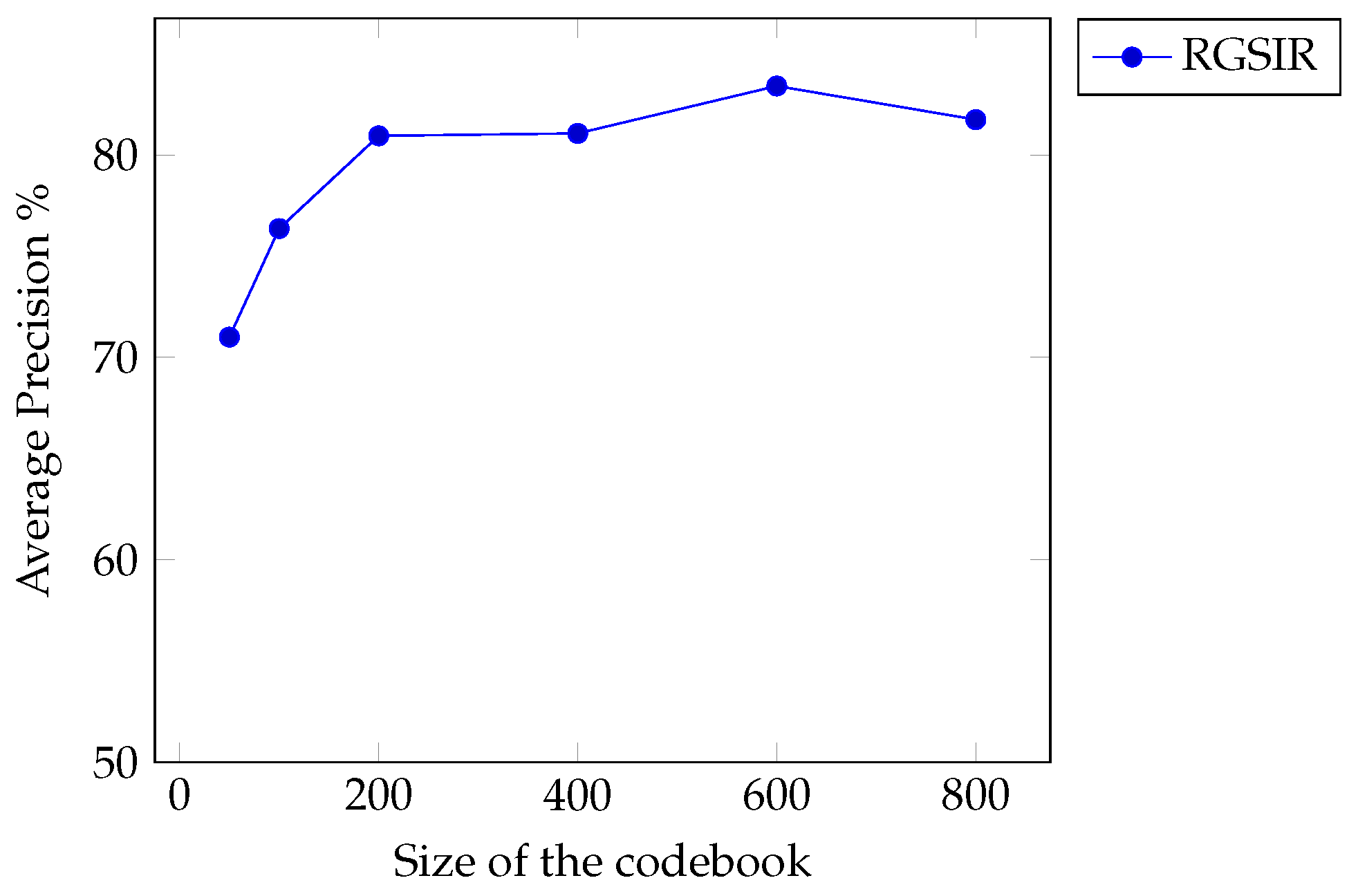
5.1. Factors Affecting the Performance of the System
5.2. Invariance to Basic Transformations
6. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Irtaza, A.; Adnan, S.M.; Ahmed, K.T.; Jaffar, A.; Khan, A.; Javed, A.; Mahmood, M.T. An Ensemble Based Evolutionary Approach to the Class Imbalance Problem with Applications in CBIR. Appl. Sci. 2018, 8, 495. [Google Scholar] [CrossRef]
- Ye, J.; Kobayashi, T.; Toyama, N.; Tsuda, H.; Murakawa, M. Acoustic Scene Classification Using Efficient Summary Statistics and Multiple Spectro-Temporal Descriptor Fusion. Appl. Sci. 2018, 8, 1363. [Google Scholar] [CrossRef]
- Piras, L.; Giacinto, G. Information fusion in content based image retrieval: A comprehensive overview. Inf. Fusion 2017, 37, 50–60. [Google Scholar] [CrossRef]
- Nazir, A.; Ashraf, R.; Hamdani, T.; Ali, N. Content based image retrieval system by using HSV color histogram, discrete wavelet transform and edge histogram descriptor. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–6. [Google Scholar]
- Zhu, L.; Shen, J.; Xie, L.; Cheng, Z. Unsupervised visual hashing with semantic assistant for content-based image retrieval. IEEE Trans. Knowl. Data Eng. 2017, 29, 472–486. [Google Scholar] [CrossRef]
- Alzu’bi, A.; Amira, A.; Ramzan, N. Semantic content-based image retrieval: A comprehensive study. J. Vis. Commun. Image Represent. 2015, 32, 20–54. [Google Scholar] [CrossRef]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep Learning for Content-Based Image Retrieval: A Comprehensive Study. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar] [CrossRef]
- Ali, N.; Bajwa, K.B.; Sablatnig, R.; Chatzichristofis, S.A.; Iqbal, Z.; Rashid, M.; Habib, H.A. A novel image retrieval based on visual words integration of SIFT and SURF. PLoS ONE 2016, 11, e0157428. [Google Scholar] [CrossRef] [PubMed]
- Ali, N.; Bajwa, K.B.; Sablatnig, R.; Mehmood, Z. Image retrieval by addition of spatial information based on histograms of triangular regions. Comput. Electr. Eng. 2016, 54, 539–550. [Google Scholar] [CrossRef]
- O’Hara, S.; Draper, B.A. Introduction to the bag of features paradigm for image classification and retrieval. arXiv, 2011; arXiv:1101.3354. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477. [Google Scholar]
- Liu, P.; Miao, Z.; Guo, H.; Wang, Y.; Ai, N. Adding spatial distribution clue to aggregated vector in image retrieval. EURASIP J. Image Video Process. 2018, 2018, 9. [Google Scholar] [CrossRef] [Green Version]
- Anwar, H.; Zambanini, S.; Kampel, M.; Vondrovec, K. Ancient Coin Classification Using Reverse Motif Recognition: Image-based classification of Roman Republican coins. IEEE Signal Process. Mag. 2015, 32, 64–74. [Google Scholar] [CrossRef]
- Ali, N.; Zafar, B.; Riaz, F.; Dar, S.H.; Ratyal, N.I.; Bajwa, K.B.; Iqbal, M.K.; Sajid, M. A Hybrid Geometric Spatial Image Representation for scene classification. PLoS ONE 2018, 13, e0203339. [Google Scholar] [CrossRef] [PubMed]
- Zafar, B.; Ashraf, R.; Ali, N.; Ahmed, M.; Jabbar, S.; Naseer, K.; Ahmad, A.; Jeon, G. Intelligent Image Classification-Based on Spatial Weighted Histograms of Concentric Circles. Comput. Sci. Inf. Syst. 2018, 15, 615–633. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Voume 2, pp. 2169–2178. [Google Scholar]
- Li, X.; Song, Y.; Lu, Y.; Tian, Q. Spatial pooling for transformation invariant image representation. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1509–1512. [Google Scholar]
- Karmakar, P.; Teng, S.W.; Lu, G.; Zhang, D. Rotation Invariant Spatial Pyramid Matching for Image Classification. In Proceedings of the 2015 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Adelaide, Australia, 23–25 November 2015; pp. 1–8. [Google Scholar]
- Liu, D.; Hua, G.; Viola, P.; Chen, T. Integrated feature selection and higher-order spatial feature extraction for object categorization. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Khan, R.; Barat, C.; Muselet, D.; Ducottet, C. Spatial orientations of visual word pairs to improve bag-of-visual-words model. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 89.1–89.11. [Google Scholar]
- Zafar, B.; Ashraf, R.; Ali, N.; Ahmed, M.; Jabbar, S.; Chatzichristofis, S.A. Image classification by addition of spatial information based on histograms of orthogonal vectors. PLoS ONE 2018, 13, e0198175. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, K.T.; Irtaza, A.; Iqbal, M.A. Fusion of local and global features for effective image extraction. Appl. Intell. 2017, 47, 526–543. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, B.; Qin, Z.; Xiong, J. Spatial weighting for bag-of-features based image retrieval. In Integrated Uncertainty in Knowledge Modelling and Decision Making; Springer: Berlin/Heidelberg, Germany, 2013; pp. 91–100. [Google Scholar]
- Zeng, S.; Huang, R.; Wang, H.; Kang, Z. Image retrieval using spatiograms of colors quantized by gaussian mixture models. Neurocomputing 2016, 171, 673–684. [Google Scholar] [CrossRef]
- Yu, J.; Qin, Z.; Wan, T.; Zhang, X. Feature integration analysis of bag-of-features model for image retrieval. Neurocomputing 2013, 120, 355–364. [Google Scholar] [CrossRef]
- Ali, N.; Mazhar, D.A.; Iqbal, Z.; Ashraf, R.; Ahmed, J.; Khan, F.Z. Content-Based Image Retrieval Based on Late Fusion of Binary and Local Descriptors. arXiv, 2017; arXiv:1703.08492. [Google Scholar] [Green Version]
- Filliat, D. A visual bag of words method for interactive qualitative localization and mapping. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3921–3926. [Google Scholar]
- Hu, F.; Zhu, Z.; Mejia, J.; Tang, H.; Zhang, J. Real-time indoor assistive localization with mobile omnidirectional vision and cloud GPU acceleration. AIMS Electron. Electr. Eng. 2017, 1, 74–99. [Google Scholar] [CrossRef]
- Li, L.; Feng, L.; Wu, J.; Sun, M.X.; Liu, S.l. Exploiting global and local features for image retrieval. J. Cent. South Univ. 2018, 25, 259–276. [Google Scholar] [CrossRef]
- Liu, S.; Wu, J.; Feng, L.; Qiao, H.; Liu, Y.; Luo, W.; Wang, W. Perceptual uniform descriptor and ranking on manifold for image retrieval. Inf. Sci. 2018, 424, 235–249. [Google Scholar] [CrossRef]
- Wu, J.; Feng, L.; Liu, S.; Sun, M. Image retrieval framework based on texton uniform descriptor and modified manifold ranking. J. Vis. Commun. Image Represent. 2017, 49, 78–88. [Google Scholar] [CrossRef]
- Varish, N.; Pradhan, J.; Pal, A.K. Image retrieval based on non-uniform bins of color histogram and dual tree complex wavelet transform. Multimedia Tools Appl. 2017, 76, 15885–15921. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.S.; Tong, X.Y.; Hu, F.; Zhong, Y.; Datcu, M.; Zhang, L. Exploiting Deep Features for Remote Sensing Image Retrieval: A Systematic Investigation. arXiv, 2017; arXiv:1707.07321. [Google Scholar]
- Vassou, S.A.; Anagnostopoulos, N.; Amanatiadis, A.; Christodoulou, K.; Chatzichristofis, S.A. Como: A compact composite moment-based descriptor for image retrieval. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, Florence, Italy, 19–21 June 2017; p. 30. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Anwar, H.; Zambanini, S.; Kampel, M. Encoding spatial arrangements of visual words for rotation-invariant image classification. In Proceedings of the 36th German Conference, GCPR 2014, Münster, Germany, 2–5 September 2014; pp. 443–452. [Google Scholar]
- Tuytelaars, T. Dense interest points. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2281–2288. [Google Scholar]
- Mehmood, Z.; Anwar, S.M.; Ali, N.; Habib, H.A.; Rashid, M. A novel image retrieval based on a combination of local and global histograms of visual words. Math. Probl. Eng. 2016, 2016, 8217250. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.Z. Real-time computerized annotation of pictures. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 985–1002. [Google Scholar] [PubMed]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, X.; Liu, W.; Gan, J. Image retrieval based on effective feature extraction and diffusion process. Multimedia Tools Appl. 2018, 1–28. [Google Scholar] [CrossRef]
- Deselaers, T.; Keysers, D.; Ney, H. Features for image retrieval: An experimental comparison. Inf. Retr. 2008, 11, 77–107. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Xu, J.M. On the relation between multi-instance learning and semi-supervised learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 1167–1174. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; pp. 577–584. [Google Scholar]
- Shrivastava, P.; Bhoyar, K.; Zadgaonkar, A. Image Classification Using Fusion of Holistic Visual Descriptions. Int. J. Image Graph. Signal Process. 2016, 8, 47. [Google Scholar] [CrossRef]
- Zang, M.; Wen, D.; Liu, T.; Zou, H.; Liu, C. A pooled Object Bank descriptor for image scene classification. Expert Syst. Appl. 2018, 94, 250–264. [Google Scholar] [CrossRef]
- Yin, H. Scene Classification Using Spatial Pyramid Matching and Hierarchical Dirichlet Processes. MSc Thesis, Rochester Institute of Technology, Rochester, NY, USA, 2010. [Google Scholar]
- Walia, E.; Verma, V. Boosting local texture descriptors with Log-Gabor filters response for improved image retrieval. Int. J. Multimedia Inf. Retr. 2016, 5, 173–184. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, OR, Florida, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv, 2014; arXiv:1405.3531. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Mousavian, A.; Kosecka, J. Deep convolutional features for image based retrieval and scene categorization. arXiv, 2015; arXiv:1509.06033. [Google Scholar]
- Chathurani, N.; Geva, S.; Chandran, V.; Cynthujah, V. Content-Based Image (Object) Retrieval with Rotational Invariant Bag-of-Visual Words Representation. In Proceedings of the 2015 IEEE 10th International Conference on Industrial and Information Systems (ICIIS), Peradeniya, Sri Lanka, 18–20 December 2015; pp. 152–157. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name/ Method | RGSIR | Li et al. [29] | Level-1 RBF-NN [9] | Visual Words Integration SIFT-SURF [8] | SWBOF [23] | SIFT-LBP [25] |
|---|---|---|---|---|---|---|
| African People | 72.80 | 76.55 | 73.06 | 60.08 | 64.00 | 57.00 |
| Beach | 69.40 | 63.70 | 69.98 | 60.39 | 54.00 | 58.00 |
| Building | 66.20 | 69.05 | 76.76 | 69.66 | 53.00 | 43.00 |
| Bus | 97.16 | 87.70 | 92.24 | 93.65 | 94.00 | 93.00 |
| Dinosaur | 100.00 | 99.40 | 99.35 | 99.88 | 98.00 | 98.00 |
| Elephant | 80.80 | 91.05 | 81.38 | 70.76 | 78.00 | 58.00 |
| Flower | 94.60 | 91.70 | 83.40 | 88.37 | 71.00 | 83.00 |
| Horse | 90.80 | 95.40 | 82.81 | 82.77 | 93.00 | 68.00 |
| Mountain | 76.20 | 83.40 | 78.60 | 61.08 | 42.00 | 46.00 |
| Food | 86.00 | 65.80 | 82.71 | 65.09 | 50.00 | 53.00 |
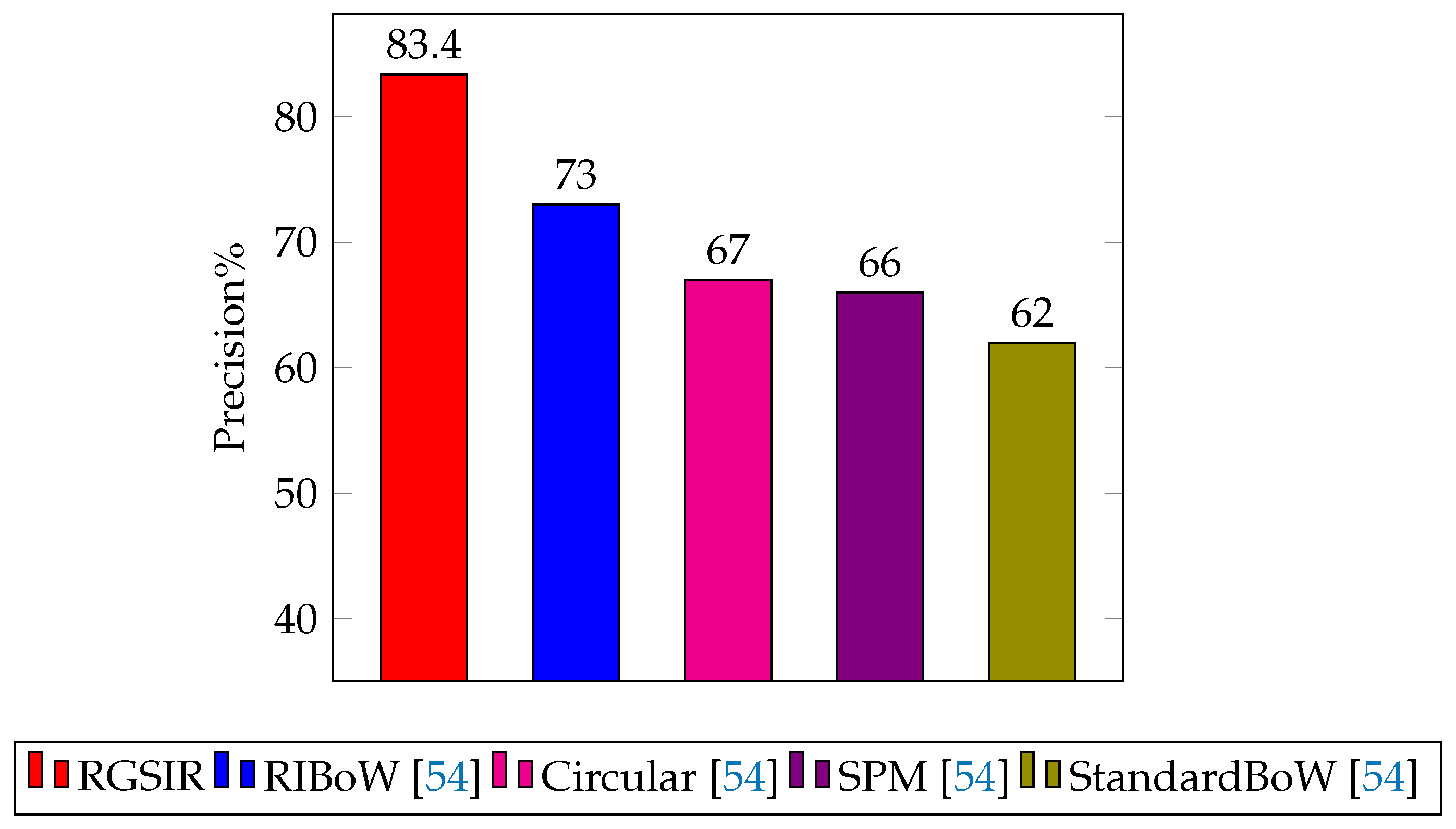
| Mean | 83.40 | 82.36 | 82.03 | 75.17 | 69.70 | 65.70 |
| Class Name/ Method | RGSIR | Li et al. [29] | Level-1 RBF-NN [9] | Visual Words Integration SIFT-SURF [8] | SWBOF [23] | SIFT-LBP [25] |
|---|---|---|---|---|---|---|
| African People | 14.56 | 15.31 | 14.61 | 12.02 | 12.80 | 11.4 |
| Beach | 13.88 | 12.74 | 14.00 | 12.08 | 10.80 | 11.6 |
| Building | 13.24 | 13.81 | 15.35 | 13.93 | 10.30 | 8.6 |
| Bus | 19.43 | 17.54 | 18.45 | 18.73 | 18.80 | 18.6 |
| Dinosaur | 20.00 | 19.88 | 19.87 | 19.98 | 19.60 | 19.6 |
| Elephant | 16.16 | 18.21 | 16.28 | 14.15 | 15.60 | 11.6 |
| Flower | 18.92 | 18.34 | 16.68 | 17.67 | 14.20 | 16.6 |
| Horse | 18.16 | 19.08 | 16.56 | 16.55 | 18.60 | 13.6 |
| Mountain | 15.24 | 16.68 | 15.72 | 12.22 | 8.40 | 9.2 |
| Food | 17.20 | 13.16 | 16.54 | 13.02 | 10.00 | 10.6 |
| Mean | 16.68 | 16.48 | 16.41 | 15.03 | 13.94 | 13.14 |
| Performance and Name of Method | RGSIR | Ali et al. [26] | Visual words Integration SIFT-SURF [8] | GMM + mSpatiogram [24] | SQ + Spatiogram [24] |
|---|---|---|---|---|---|
| Precision | 82.85 | 72.60 | 74.95 | 74.10 | 63.95 |
| Recall | 16.57 | 14.52 | 14.99 | 13.80 | 12.79 |
| Performance/ Method | RGSIR | Visual Words Integration SIFT-SURF [8] | MissSVM [44] | MI-SVM [45] |
|---|---|---|---|---|
| MAP | 79.09 | 65.41 | 65.20 | 54.60 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zafar, B.; Ashraf, R.; Ali, N.; Iqbal, M.K.; Sajid, M.; Dar, S.H.; Ratyal, N.I. A Novel Discriminating and Relative Global Spatial Image Representation with Applications in CBIR. Appl. Sci. 2018, 8, 2242. https://doi.org/10.3390/app8112242
Zafar B, Ashraf R, Ali N, Iqbal MK, Sajid M, Dar SH, Ratyal NI. A Novel Discriminating and Relative Global Spatial Image Representation with Applications in CBIR. Applied Sciences. 2018; 8(11):2242. https://doi.org/10.3390/app8112242
Chicago/Turabian StyleZafar, Bushra, Rehan Ashraf, Nouman Ali, Muhammad Kashif Iqbal, Muhammad Sajid, Saadat Hanif Dar, and Naeem Iqbal Ratyal. 2018. "A Novel Discriminating and Relative Global Spatial Image Representation with Applications in CBIR" Applied Sciences 8, no. 11: 2242. https://doi.org/10.3390/app8112242
APA StyleZafar, B., Ashraf, R., Ali, N., Iqbal, M. K., Sajid, M., Dar, S. H., & Ratyal, N. I. (2018). A Novel Discriminating and Relative Global Spatial Image Representation with Applications in CBIR. Applied Sciences, 8(11), 2242. https://doi.org/10.3390/app8112242