1. Introduction
Over the years, the remote sensing domain has been characterized by numerous technological improvements (e.g., increased spatial resolution, shorter revisit time, increased number of spectral bands). These improvements were made possible through several Earth Observation missions, e.g., the Landsat program sustained by NASA and the United Stated Geological Survey (USGS), the Sentinel program financed by European Space Agency, Envisat’s ASAR mission. In addition, many of the recent missions have functioned under an open data access policy for research purposes. This fact has a direct impact on the interest manifested in using this type of data in many realms, such as agriculture, land cover and land use planning, resource management, urbanization, and sustainable development.
One possible method for the analysis of satellite image time series (SITS) is to compare two satellite images captured at two successive moments of time, over the same area of interest [
1,
2,
3,
4]. These methods are generally called change detection methods. However, although they can successfully detect abrupt changes (e.g., deforestation, natural disasters, building construction), these methods are not able to identify complex spatio-temporal structures that evolve in a defined time-frame (e.g., measuring the effects of floods, urban expansion, land cover and land use modifications). In the later cases, SITS analysis methods that involve information extraction from multi-temporal data are usually preferred.
The main difficulties when dealing with SITS are the irregular time sampling, the missing samples (e.g., due to cloud cluttering and haze that affect images captured by optical sensors, technical artifacts) and, also, the high spatial and temporal data dimensionality. In general, multi-temporal approaches require the processing of large amounts of data characterized by a high degree of variability in terms of temporal, spatial and multi-spectral information.
The spatio-temporal evolution patterns may span different periods of time and may affect small to large regions. For example, urban transformations affect small regions and have multiple construction phases spanning several years. In contrast, flood events may affect larger areas then in the previous case, but, depending on their intensity, the consequences may be observed over shorter or longer periods of time (e.g., land slides are irreversible). In this context, the characterization of temporal evolutions is strictly related to the fact that the processes that occur in dynamic scenes have different time scales and affect small to large areas.
Therefore, the requirements that SITS analysis methods must fulfill are: (1) the ability to capture complex spatio-temporal changes and (2) the potential to emphasize both short-term and long-term modifications. Developing an algorithm that can deal with the spatial, temporal and spectral diversity of Earth Observation data is a challenging task to accomplish and more so when the amount of knowledge that a human expert transfers to the system is limited.
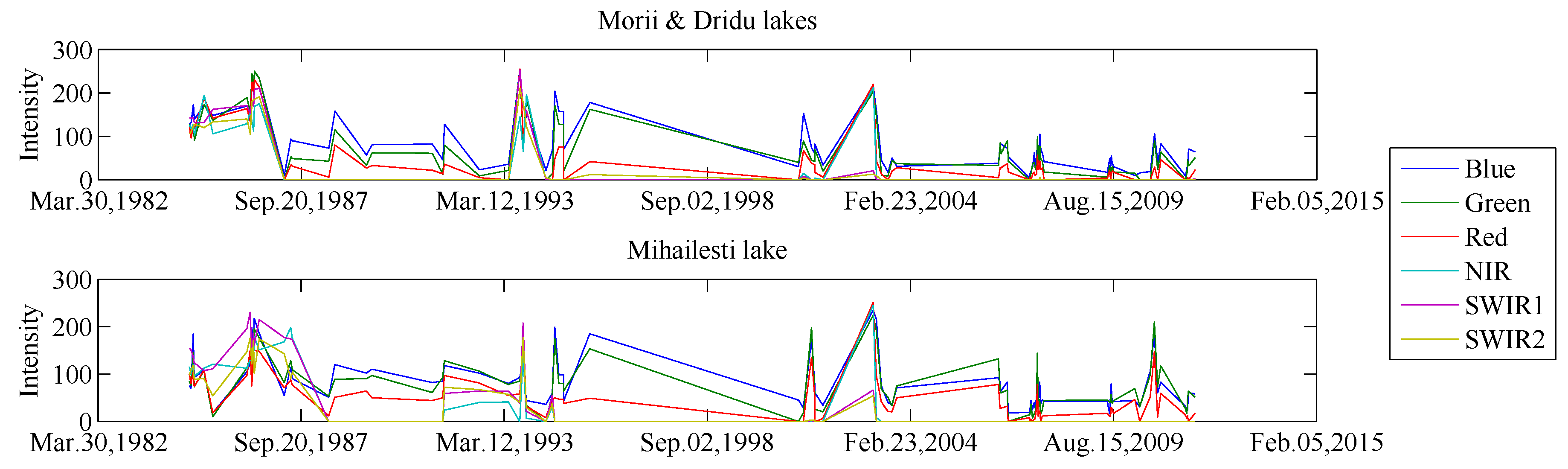
Many multi-temporal analysis techniques use a SITS classification that incorporates various dissimilarity measures to compare two temporal sequences. In SITS, by similar evolution, we understand a group of scene points that share the same behavior for the entire period of time or for most of it. Each point in a SITS is characterized by a spectro-temporal signature. An example of a spectro-temporal signature is provided in
Figure 1 for a SITS acquired by the Landsat sensor with six spectral bands.
Some of the methods used to assess the degree of similarity between temporal sequences have emerged directly from text classification, speech recognition, or genomic data classification [
5,
6]. Dynamic Time Warping (DTW) has proved to be an essential tool not only for spoken-word recognition, but also for understanding similarities between evolution profiles in SITS [
7,
8]. DTW is able of handling comparisons between sequences characterized by irregular time sampling or missing data issues [
7]. In this regard, K-means with DTW as the distance measure the yield land cover and land use maps of SITS [
7]. However, performing an unsupervised clustering over an entire multi-spectral SITS data is time-consuming, and the temporal characteristics of the data may be missed. Other versions of DTW include a weighting procedure to mark the seasonality characteristics of temporal evolutions [
9,
10]. This weighting procedure works well for cropland mapping, but it may not be helpful for other applications that do not account for a periodicity effect (e.g., construction of buildings). In addition, recently, a tree-based structure formed of multiple K-means clustering algorithms that use the DTW distance measure was developed in [
11] for the indexing and classification of SITS.
The methodology described in [
12] for time series analysis is based on computing change maps between pairs of consecutive images using different similarity measures (e.g., correlation coefficient, first order Kullback–Liebler Divergence, Conditional Information, Normalized Compression Distance). The change maps are transformed into a collection of words through the K-means clustering algorithm. All the words form a dictionary. The transformed change maps are processed afterwards using the Latent Dirichlet Allocation (LDA) model to discover classes (or evolution-topics) based on the latent information from the scene. Thus, the final results of the analysis provide an unsupervised classification of the spatio-temporal evolutions into classes.
A study of several general purpose supervised classifiers, like Random Forest and Support Vector Machine (SVM), was presented in [
13] as a solution for land cover mapping. The features extracted from the images were spectral features (e.g., color, normalized difference vegetation, water and build-up indexes, brightness, greenness, wetness, brilliance) and temporal features (e.g., statistical values from normalized difference vegetation index profile, phenological parameters marking important events in a season like sowing, threshing, cropping). However, SVM and Random Forest classifiers are known for having large training times, which may last even several days [
13]. In this sense, this type of classification system cannot be used for online retrieval of spatio-temporal evolutions, where a fast response is needed. In addition, supervised classifiers need large amounts of training data. This requirement is not easy to fulfill in SITS classification tasks.
Frequent sequential pattern analysis was introduced in [
14,
15] for unsupervised SITS mining. This approach performs a quantization of the images in the SITS using a fixed number of gray levels (or, labels) and forms a sequence of
T labels for each pixel location, where
T is the number of images in the SITS. In this context, an ordered list of labels is called a frequent sequential pattern if the number of its occurrences in the SITS is greater than a fixed threshold. Inferring spatial connectivity constraints when determining the frequent sequential patterns proved to be efficient in monitoring crop or ground deformations [
14]. However, the determination of the frequency of sequential patterns in SITS is sensitive to the number of levels used for image quantization. In addition, the method extracts a large number of patterns which may be difficult to interpret in terms of changes that appear in an area. Moreover, missing data may raise difficulties when interpreting the results for SITS analysis.
Apart from the irregular time sampling, missing data, and high data variability in the spatial, temporal, and spectral domains that were mentioned above, another difficult challenge that is met in SITS analysis is the assignment of semantic meaning to patterns of spatio-temporal evolution. This challenge is most frequently met when unsupervised techniques are used for SITS analysis. In these cases, a method to determine the optimal number of evolution classes is usually used [
16]. A query-by-example retrieval method would alleviate this issue by associating semantic meaning to each query that a user addresses to the retrieval system. In this regard, we hereby present a query-by-example retrieval method whose goal is to separate spatio-temporal evolutions that are similar to a given query from non-similar ones. After the user performs a specific query, the retrieval method consists of two main steps. Firstly, the system performs the computation of distance measures between the query and the rest of spatio-temporal evolutions. Secondly, an optimal threshold is determined through the Expectation-Maximization technique in order to obtain a binary map displaying similar patterns with respect to the given query. The rest of the paper is structured as follows. The two-step retrieval method is presented in
Section 2.
Section 3 and
Section 4 present the experiments conducted over several SITS datasets, discuss the results obtained for different application scenarios, and compare the proposed method to other SITS analysis methods. Finally, the last section concludes the paper.
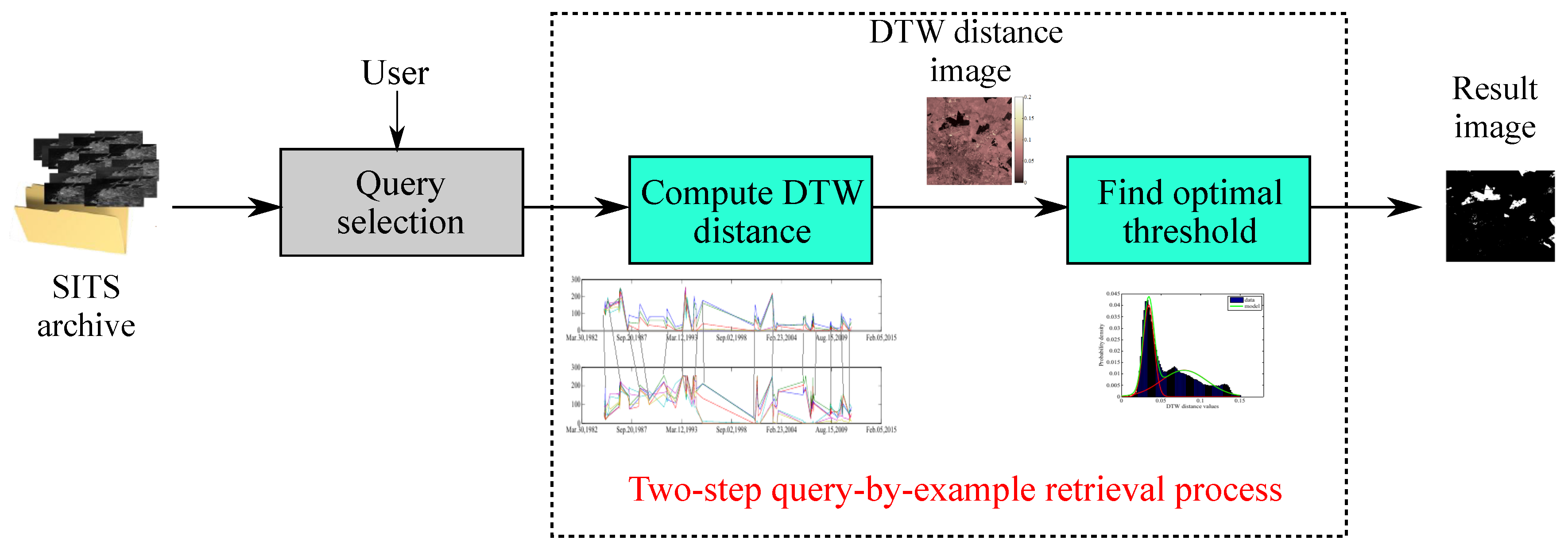
2. Materials and Methods
In this paper, the SITS analysis is approached through time series information retrieval, which is the process of searching inside a collection of data. The proposed search process starts with a query provided by the end-user, whose aim is to identify evolutions that are similar (i.e., have similar behavior) to the selected query. Firstly, the proposed method determines the degree of similarity between a specific query and the rest of the spatio-temporal evolutions. This step is performed by computing the DTW measure between the query and the rest of the evolutions. The DTW score is expected to be small for similar evolutions and large for non-similar ones. The retrieval process consists of deciding whether a certain evolution is similar to the given query or not. In this sense, the retrieval process can be seen as a problem of separating the spatio-temporal evolutions into two classes (i.e., similar versus non-similar with respect to a given query). The class identification is performed via Bayesian decision theory and it is based on determining the optimal threshold that separates relevant from irrelevant evolution patterns with respect to a given query.
Specifically, the proposed approach is a two-step process: (1) compute DTW distances and (2) find the optimal threshold. The process is summarized in
Figure 2 and starts by computing a DTW distance image containing all the DTW dissimilarity scores with respect to a fixed query. After applying the optimal threshold over the DTW distance image, the final result is a binary map which aids in delimiting similar spatio-temporal evolutions.
2.1. Dynamic Time Warping (DTW)
The first step in retrieving spatio-temporal patterns that are similar to a given query is to measure the degree of similarity between the query sequence and the rest of the sequences. This can be achieved through Dynamic Time Warping, which has been widely used in many applications related to speech recognition [
5] and DNA analysis [
6]. The method is usually applied to find the optimal alignment path between two sequences,
and
, which may have different lengths (i.e.,
) [
17]. This is a frequently met situation in SITS analysis due to technological artifacts or cloud cluttering problems that may occur in images captured by optical remote sensing sensors. Mathematically, the DTW distance measure between two sequences,
and
, can be recurrently defined as
where
is the Euclidean distance between two current elements
and
of the sequences,
is the partial similarity score between
and
for any
and
. As can be observed from the above equation, the optimization problem aims at finding the best alignment between subsequences of
and
.
In the above formulation, the following initial conditions are considered:
The overall DTW similarity between and is given by the score . Computing the overall score is equivalent to determining the elements of a distance matrix where the element on row i and column j is .
The recurrence relation used in the computation of the DTW similarity score implies the computation of a
matrix, whose elements are the distances
(
,
). Each distance
uses the smallest value between the closest previous neighbors in the matrix. The DTW matrix is computed from left to right and top to bottom. The last element
represents the overall DTW score of similarity, whilst the path that is followed to compute the score of similarity provides the optimal alignment. An example of DTW-based optimal alignment together with the DTW distance matrix
D is shown in
Table 1 for two sequences of one-dimensional elements. In this example, we considered that
is the difference in absolute values of the elements. The element on the lower-right of the matrix is the total score of the similarity between the two sequences.
If the similarity scores are computed between spatio-temporal sequences in a multispectral SITS, the sequences are formed by the vector elements
and
whose dimensions are given by the number of frequency bands used by the remote sensing sensors. Let us denote by
c the number of spectral bands. Then,
is the Euclidean distance between two vector elements in a space with
c dimensions:
where
and
.
The DTW similarity score is computed between the query provided by the user and each spatio-temporal sequence in the SITS. The result is a DTW distance image that assesses the scores of similarity between the given query and the evolutions for each pixel location.
As already mentioned, the DTW distance is expected to be small for evolutions that are similar to the query and large for non-similar evolutions. This is due to the fact that, if the spatio-temporal evolutions are similar, the DTW algorithm finds an alignment with a smaller cost between the corresponding temporal sequences and the given query than in the case of non-similar evolutions. Therefore, the separation of similar from non-similar evolution patterns is equivalent to finding an optimal threshold that can be applied over DTW distances in order to retrieve the specific pattern queried by the end-user.
2.2. Determining the Optimal Threshold Using Expectation-Maximization
In the previous subsection, we described the process of determining the DTW distance image containing DTW similarity scores with respect to a query selected by an end-user. The following step in the automatic extraction of evolutions that have similar behavior to a given query is the optimal thresholding step. More precisely, we aim to separate the DTW distance scores between two classes, a class of similar evolutions and a class of non-similar spatio-temporal evolutions. Separating these two classes of evolutions translates into finding the optimal threshold to be applied on the DTW similarity scores. In this sense, we formulate the problem of query-by-example SITS retrieval in terms of the Bayesian decision theory.
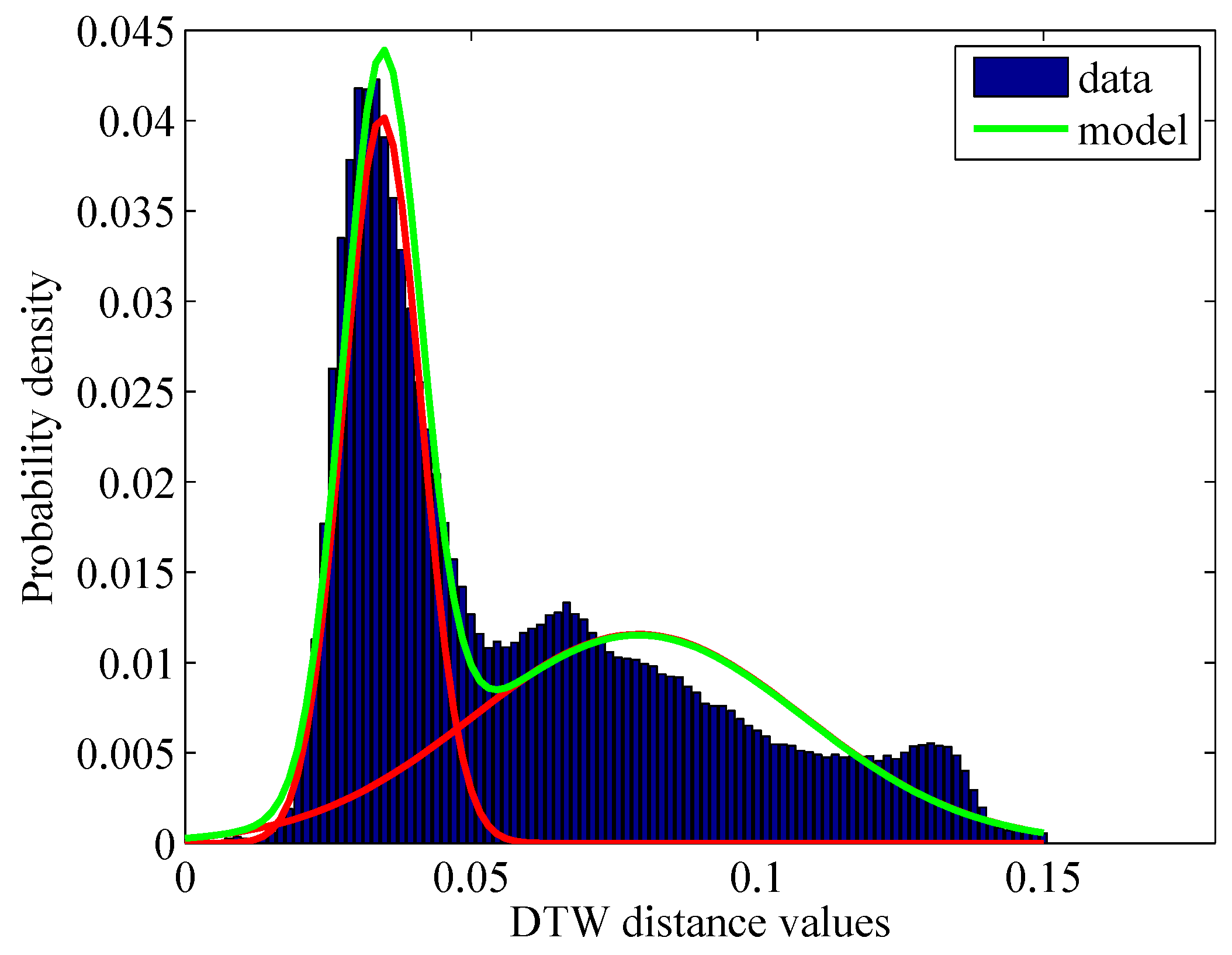
The DTW similarity scores computed for a given query follow a multimodal distribution. This can be observed from
Figure 3, where the query selected for retrieval is from an agricultural area in a long SITS (88 temporal samples). As expected, the first lobe corresponds to similar evolutions. This is argued by the fact that DTW similarity scores are smaller for similar evolutions than for non-similar evolutions. Furthermore, the histogram profile shown in
Figure 3 confirms the idea of separating similar from non-similar evolutions using the Maximum Likelihood (ML) technique.
In the following text, we denote the random variable associated to the computed DTW similarity scores by
X, whilst
x represents a particular DTW score. Following the formalism initially presented in [
18], let us assume that the scores are drawn from a mixture of two Gaussian distributions,
and
. The first Gaussian distribution corresponds to evolutions that are
similar to the given query, whereas the second component refers to
non-similar evolutions.
The Maximum Likelihood Estimation (MLE) framework determines the parameter values that make the observed data most likely, i.e., that maximize the likelihood function and fit the model to the data. Following the above considerations, the overall posterior probability can be decomposed as
where
is the set of model parameters, whilst
and
are the mixture probabilities [
19] such that
. The mixture components are modeled as Gaussian densities:
with
, whilst
and
are the mean and standard deviation pairs corresponding to similar and non-similar evolutions, respectively. The set of parameters
is determined iteratively using the Expectation-Maximization (EM) algorithm. Specifically, each iteration
j is decomposed in two basic steps:
Expectation step (E-step). Compute the log-likelihood (i.e., the logarithm of the posterior probability) with respect to the current values of the parameters
:
Maximization step (M-step). Update the model parameters such that the log-likelihood approaches its maximum, i.e., the convergence of the EM algorithm guarantees that the log-likelihood value is increased with each iteration [
19]. It is usually convenient to introduce a mapping between the new model parameters
and the previous ones
. According to [
18] and following the notations in [
19], the means, squared standard deviations, and mixture probabilities for each class
can be re-estimated using the following set of relations:
where
is the total number of pixels in the distance image (i.e., the number of spatio-temporal evolutions) and
values are derived as
The initialization of the EM algorithm is done by separating the similarity scores into two subsets,
and
. Any unsupervised clustering method can be applied, but we chose the
K-means (
) clustering method due to its fast response time when the number of clusters is small. However, being an unsupervised clustering method, a constraint must still be fulfilled. Namely, the cluster of similar evolutions must be characterized by DTW similarity scores that are smaller than the DTW similarity scores obtained for the temporal sequences pertaining to the cluster of non-similar evolutions with respect to the query. The initial values for the prior probabilities, means, and squared standard deviations can be easily computed as statistics over the two subsets,
and
. Compared to the initialization proposed in [
1], the K-means initialization speeds up the convergence of the EM algorithm [
19], and thus, the speed of the whole algorithm.
After the estimation of the
model parameters, the optimal threshold
that separates the two classes (i.e.,
similar and
non-similar) is determined from the equality
that naturally follows from the Maximum Likelihood rule
Taking the logarithm of both sides of Equation (
13) yields a quadratic equation in
that has two possible solutions. However, only one of these solutions lies between
and
and this solution represents the optimal threshold value.
After determining the optimal threshold value
, the DTW distance image
is transformed into a binary image
, delimiting the locations of evolutions that are similar to the given query:
where
and
,
W and
H being the width and height of the images in SITS.
3. Experiments
The proposed method for the retrieval of specific spatio-temporal patterns in SITS was tested on series of Landsat images captured at different periods of time and over different locations. In all application scenarios described hereafter, all of the available spectral bands were taken into consideration, namely green, red, blue, Near Infrared and two Short-Wave Infrared bands. Moreover, the spatial resolution of the Landsat sensor was 30 m.
The first series consists of a short time series of 10 images acquired between 1984 and 1993 (i.e., an image is acquired each year), over Bucharest, Romania, and regions surrounding the city. The size of the images is
pixels and the captures were taken in different seasons of the years. Several samples of the time series, along with their acquisition moments, are shown in
Figure 4. In this case, the task was to determine similar changes that occurred during the formation of three accumulation lakes near Bucharest, namely Dridu, Mihailesti, and Morii. Two of these lakes evolved similarly, whereas the third one went through several modifications over the time period mentioned above.
The second dataset is formed of 13 Landsat images of
pixels capturing the Dobrogea region, Romania, between 6 May 2000 and 9 September 2001. Some images from the dataset, together with the corresponding timespan, are shown in
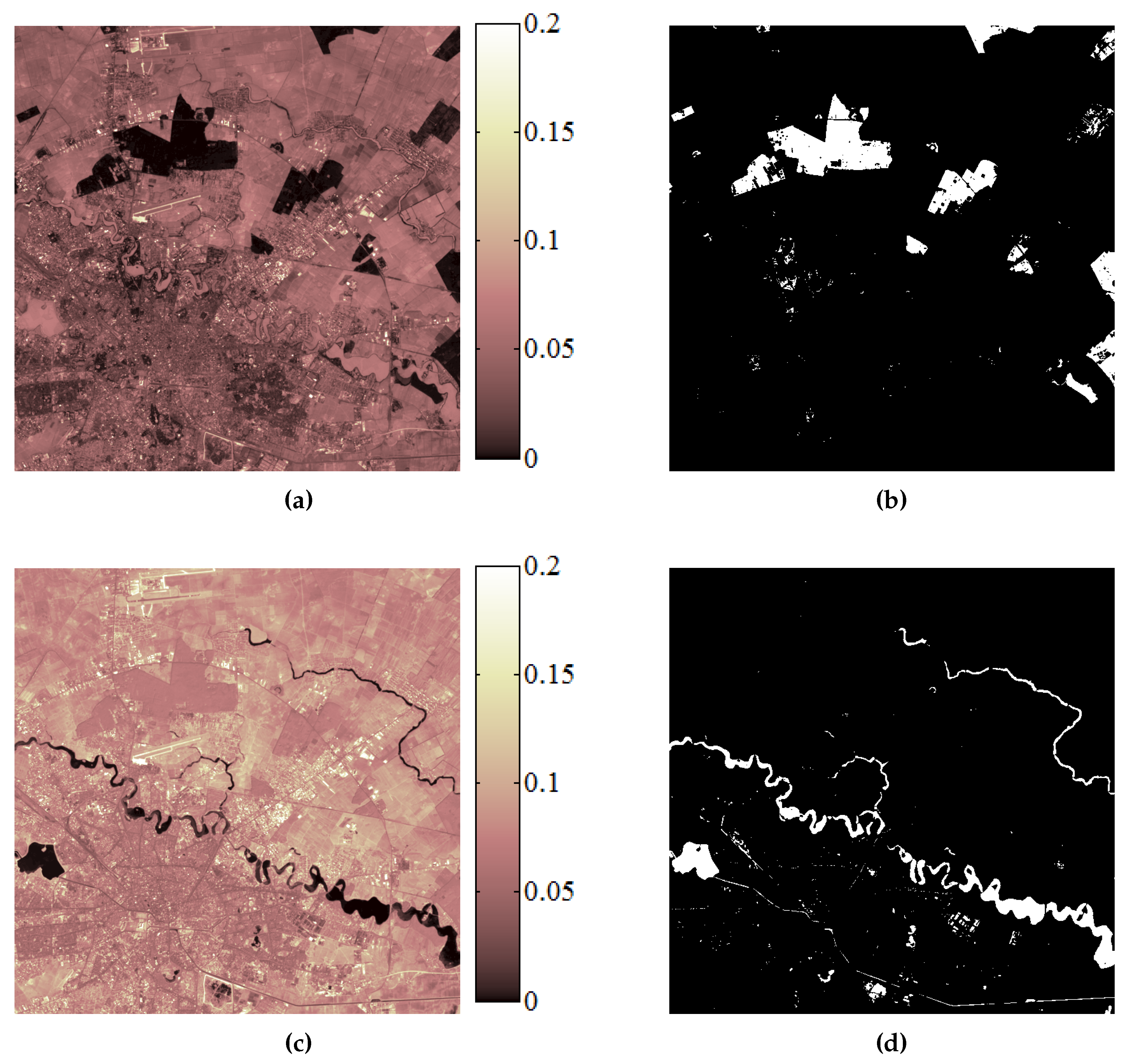
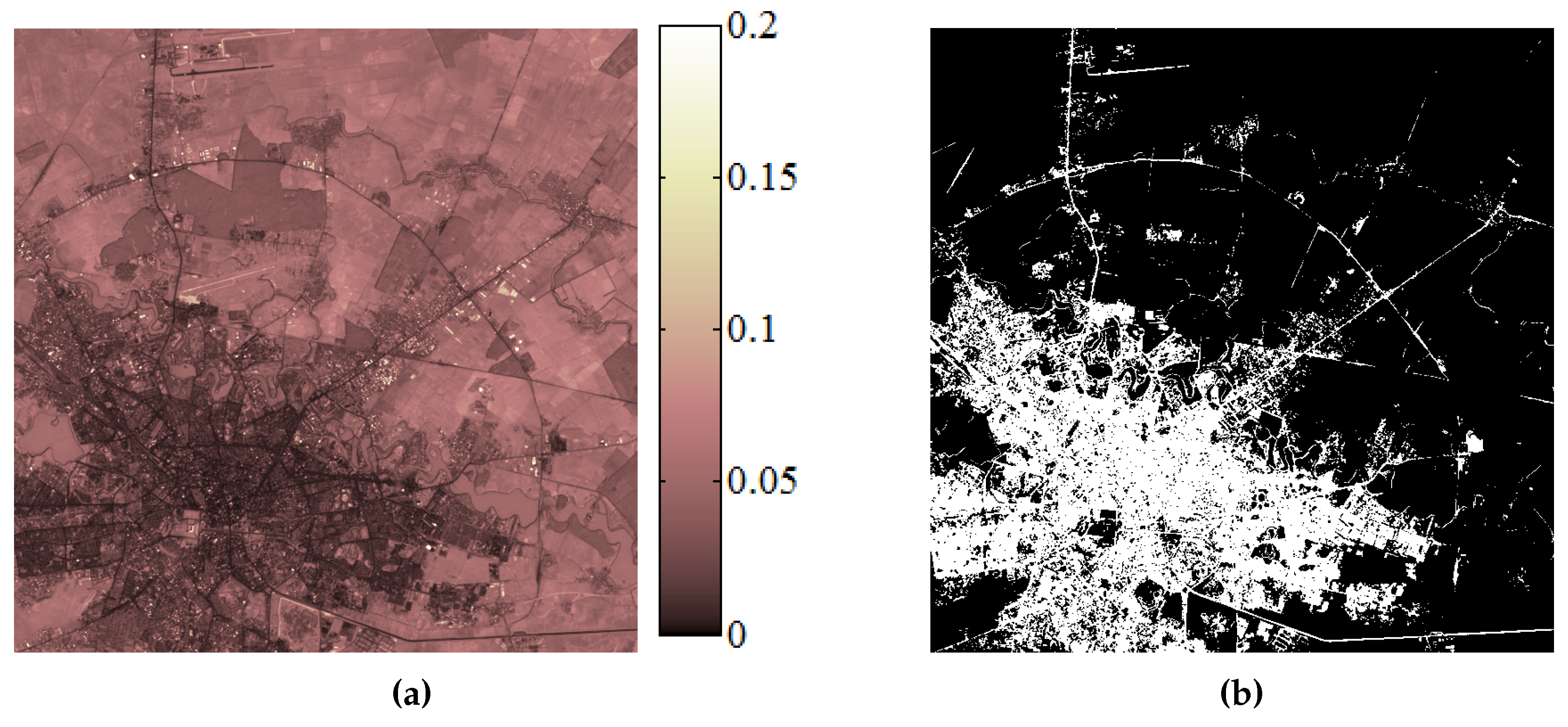
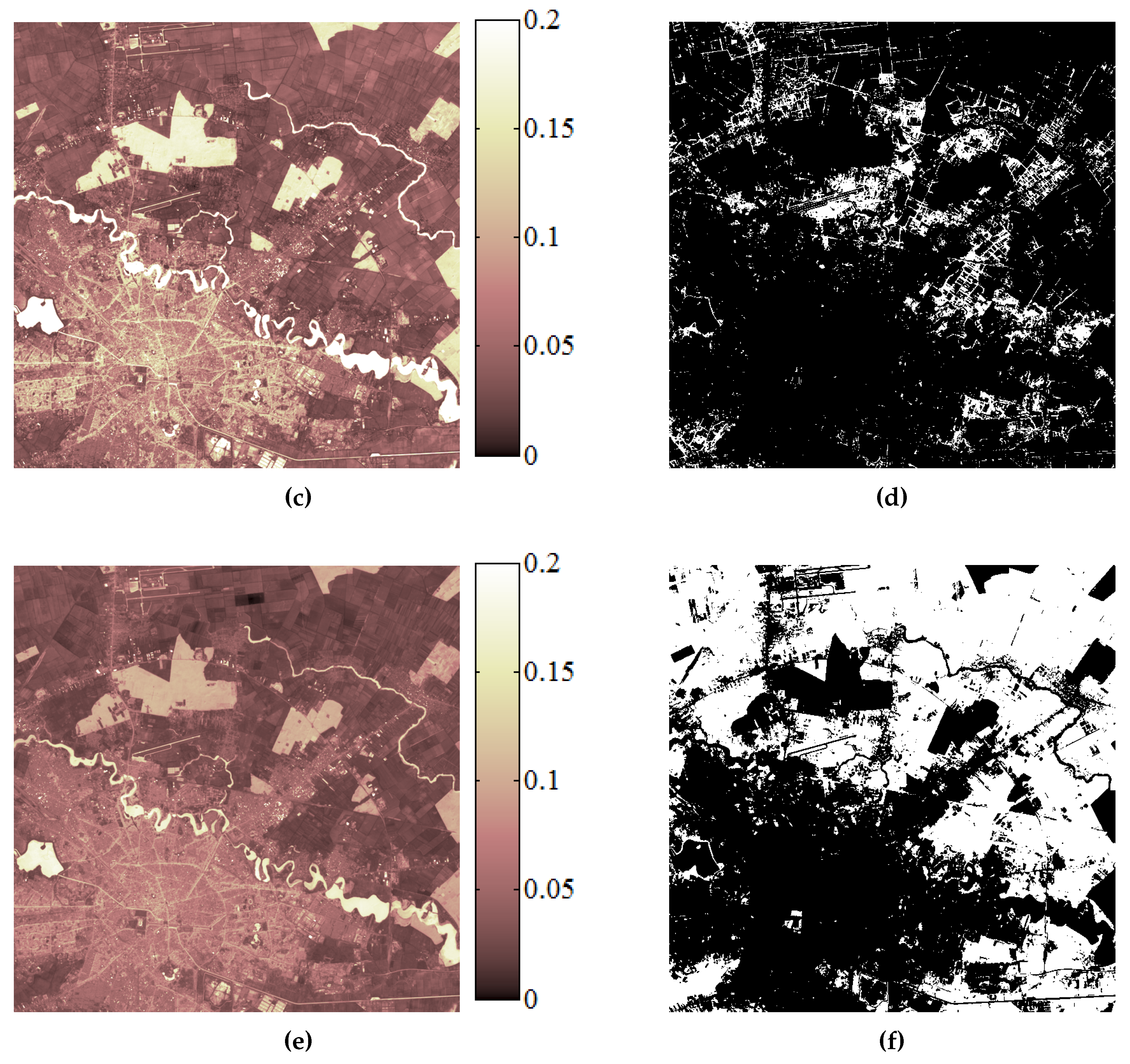
Figure 5. In May 2000, the heavy rain led to the swelling of Danube river which caused floods in this region (
Figure 5a). A rapid assessment of the area affected by floods is necessary in this type of situation. Therefore, the application considered in this case was oriented towards the delimitation of areas affected by floods.
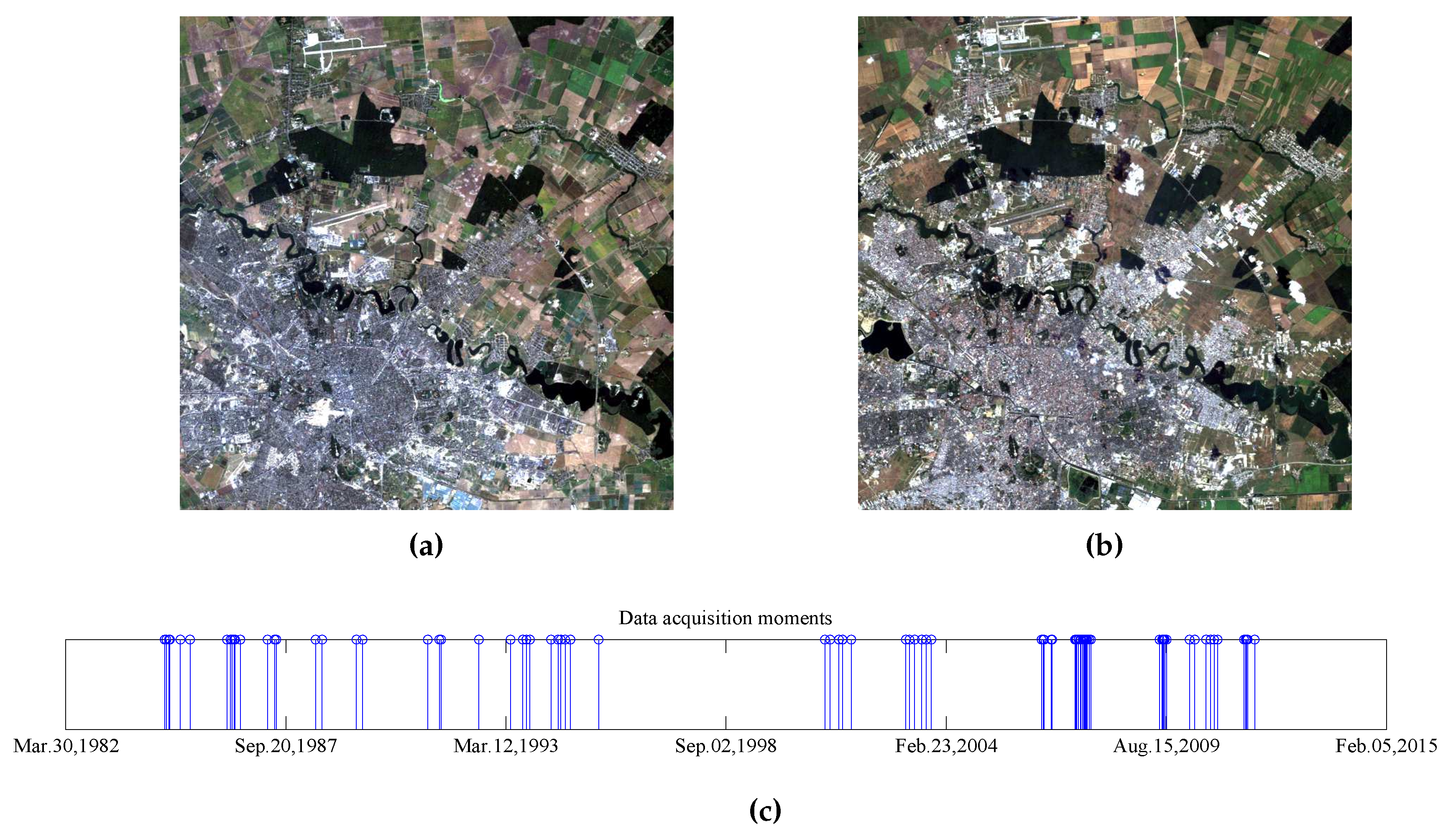
The third time series spans a longer period of time than the previous time series, almost 28 years between 14 September 1984 and 27 October 2011, and contains 88 multispectral images of
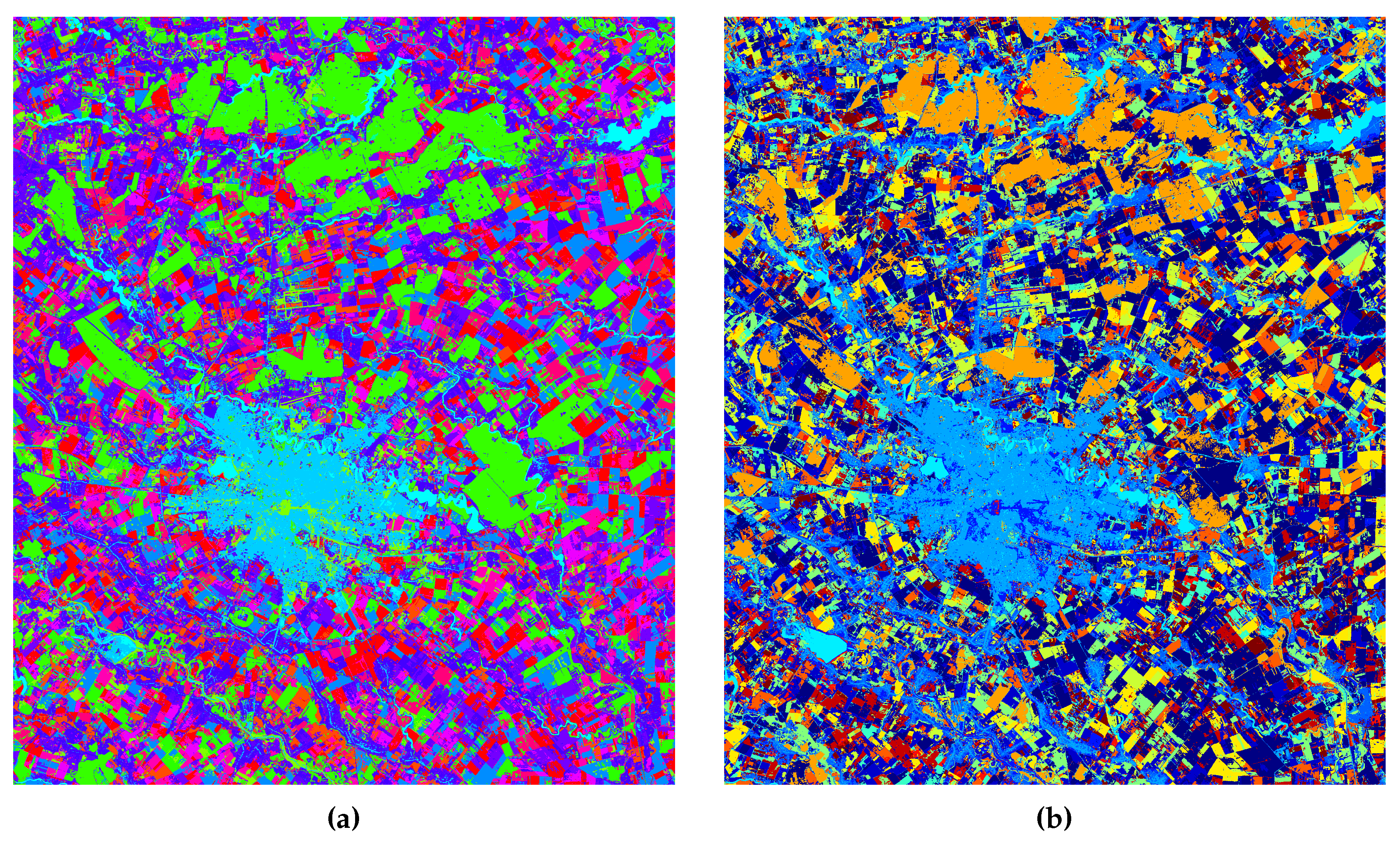
pixels. The location is still Bucharest, Romania and surrounding regions, but the area captured by the SITS is smaller than in the previous case. The first and last images from the long-term SITS, along with the corresponding temporal distribution of the acquisitions, are shown in
Figure 6. In general, long-term SITS acquisition is characterized by irregular temporal sampling with data captured under different meteorological (e.g., precipitation, clouds, season) and illumination conditions. These issues make the query-by-example retrieval in long-term SITS a challenging task to accomplish if other types of distance measure (e.g., Euclidean distance) are used to assess the degree of similarity between the temporal sequences. There are two main applications where the information extracted from long-term SITS shows its potential, namely land cover and land use mapping. These two applications impact the sustainable management of the natural resources, urban planning, and agriculture.
In all cases, the user was asked to select a single evolution in the area of interest and then the proposed algorithm was applied to identify other spatio-temporal evolutions with similar spectro-temporal signatures.
5. Conclusions
In this paper, we described an effective query-by-example retrieval system that can be used for the exploitation of Earth Observation SITS. The strategy is based on a two-step procedure. The first step consists of measuring the degree of similarity between a query provided by the user and other spatio-temporal evolutions in SITS. The second step consists of separating similar and non-similar patterns via an optimal thresholding technique applied over the DTW distance image obtained in the first step.
The experiments showed that, even if the SITS is irregularly sampled, affected by clouds or haze, or if the acquisitions are performed in different seasons and under different illumination conditions, the method is able to recognize specific patterns in SITS. In order to show the effectiveness and applicability of our proposed retrieval method, we considered several application scenarios. First, we considered the problem of retrieving similar spatio-temporal patterns from the SITS by analyzing a specific case, namely the construction of two accumulation lakes with different histories. In the second scenario, we exploited the proposed method to assess the damage that floods produce over a region. This is a typical scenario in emergency situations when a fast and effective evaluation of the affected areas is mandatory. In the last scenario, we considered long SITS and aimed to build land cover and land use maps that provide fundamental information for many applications, including change analysis, crop estimation, sustainable management of natural resources, and urbanization planning.
Being characterized by a low computational complexity, the proposed method for retrieving similar spatio-temporal evolutions based on a specific query represents a good candidate for the online analysis and annotation of SITS. Moreover, the method is designed to use the entire information provided by a multispectral remote sensing sensor, regardless of the number of spectral bands.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}