State-of-the-Art Mobile Intelligence: Enabling Robots to Move Like Humans by Estimating Mobility with Artificial Intelligence

 ,
, 

Abstract
: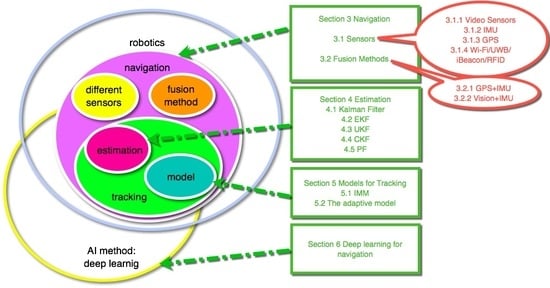
1. Introduction
2. Survey Organization
3. Navigation
3.1. Sensors
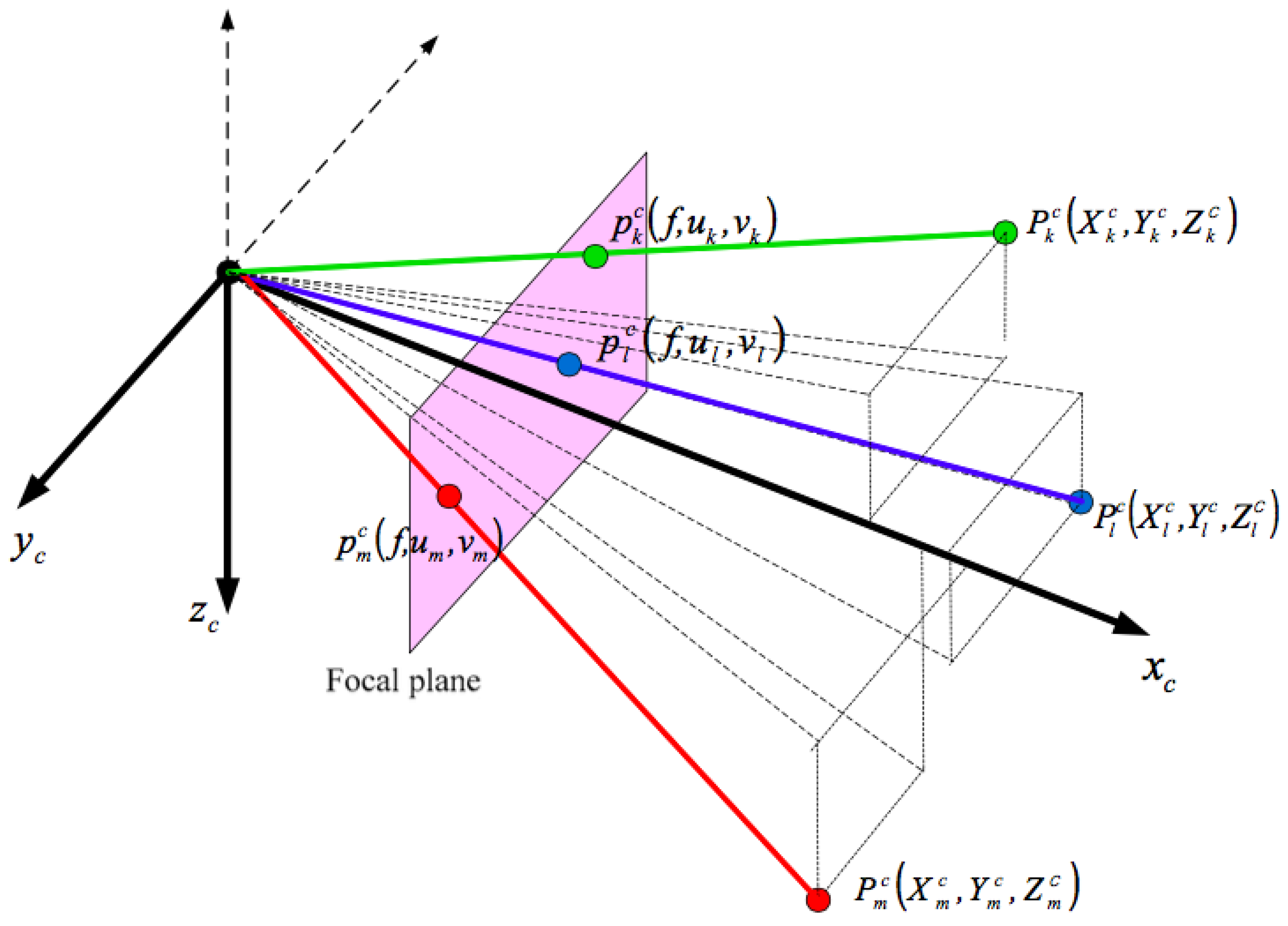
3.1.1. Video Sensors
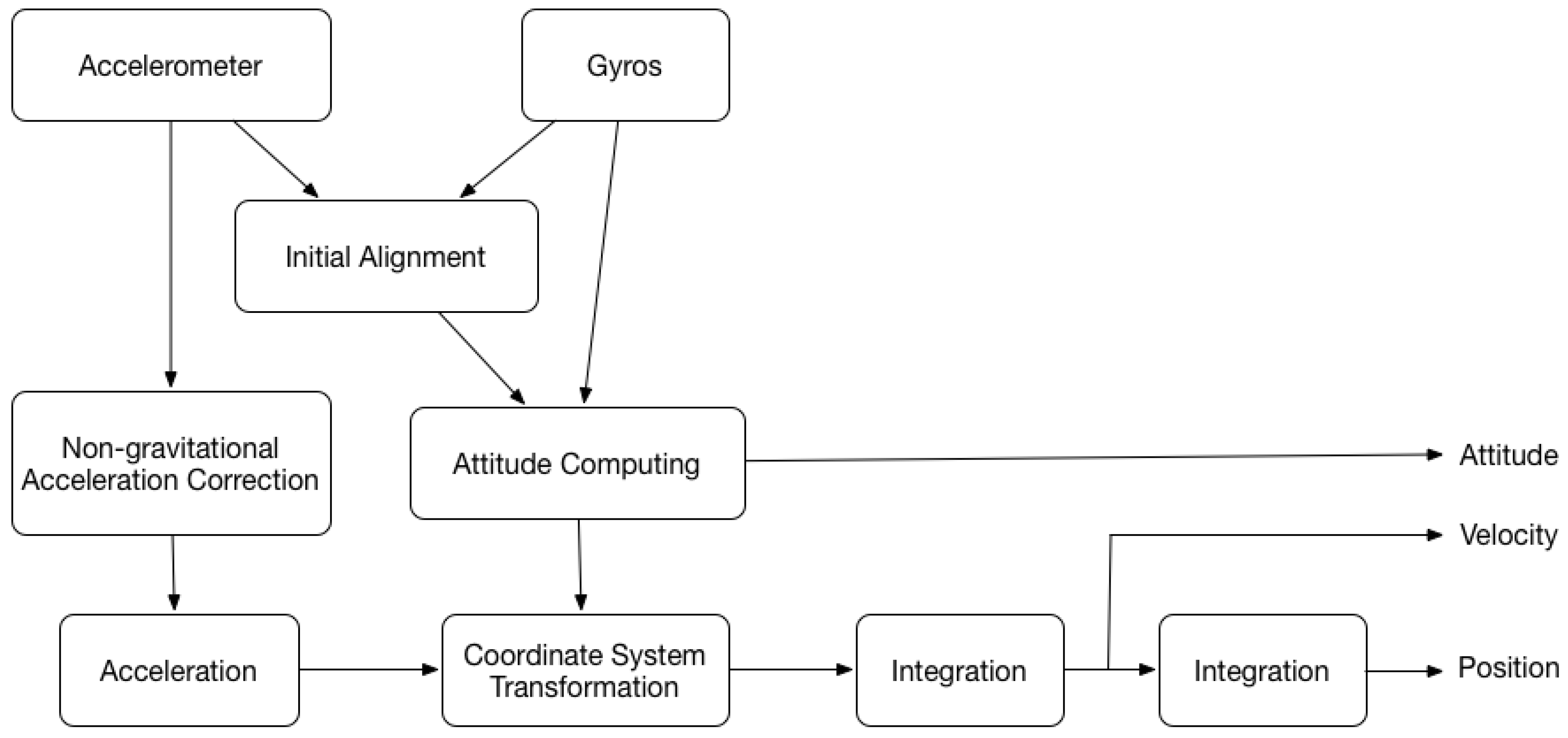
3.1.2. IMU
3.1.3. GPS
3.1.4. Wi-Fi, UWB, iBeacon, and Radio Frequency Identification
3.2. Fusion Method
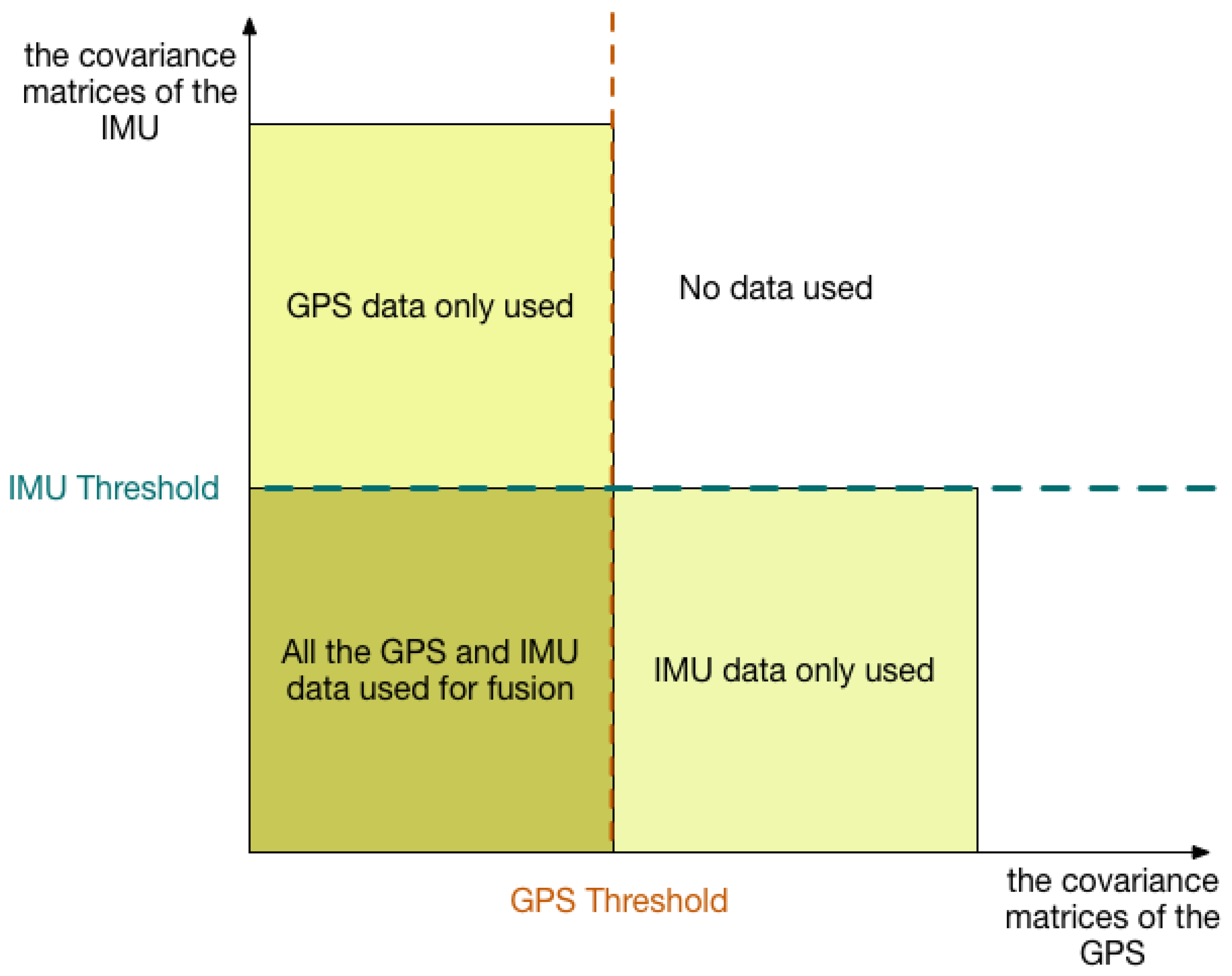
3.2.1. GPS + IMU
3.2.2. Vision + IMU Integration
4. Tracking
4.1. Models for Tracking
4.2. Estimation
4.2.1. Kalman Filter
4.2.2. EKF
4.2.3. UKF
4.2.4. CKF
4.2.5. PF
4.3. Experiment and Analysis
4.3.1. Case One
4.3.2. Case Two
5. Deep Learning for Navigation
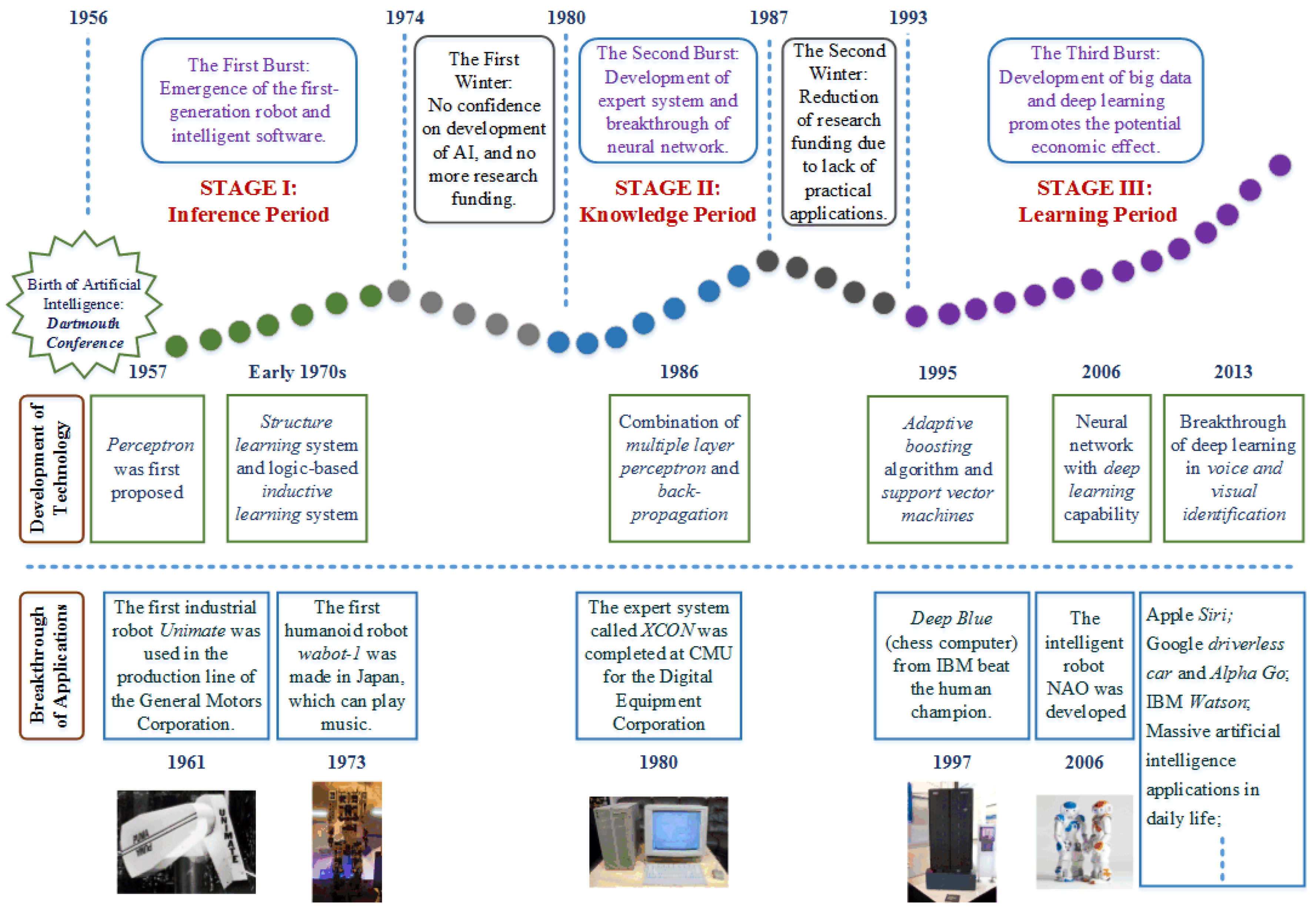
5.1. History of AI
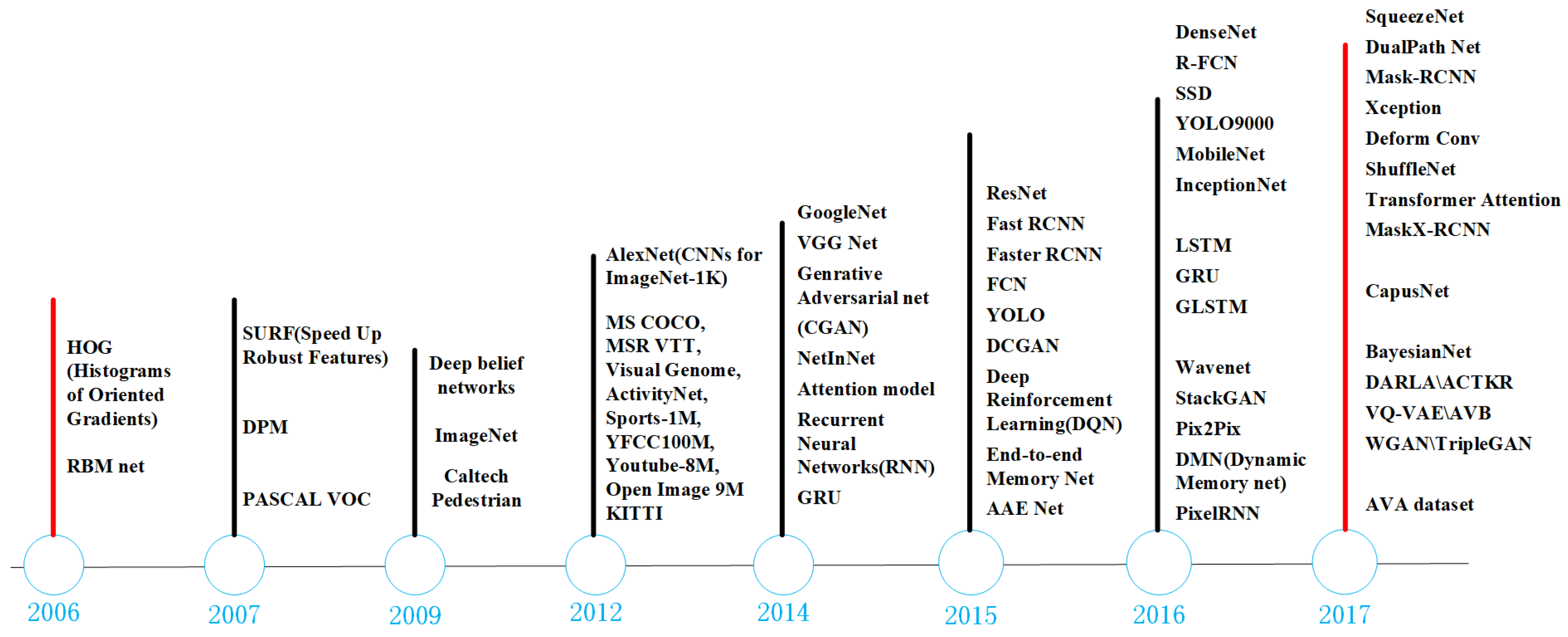
5.2. An Overview of Deep Learning
5.3. Add the Intelligence to the Robot
6. Conclusions
- As we have mentioned in Section 5, it is necessary to combine the estimation and AI methods. In essence, the estimation method is based on probability theory, while the AI method, especially the deep learning method, is based on statistical analysis. These methods have different theoretical foundations, and bringing them together requires in-depth research. These two methods are complementary. However, how to use deep learning methods to provide a more realistic model and how to use the estimation method to develop the prior knowledge of the deep neural network is an open field of study.
- Reinforcement learning has become a novel form, by which, for example, AlphaGo Zero has become its own teacher [146] to learning how to play go. The system starts off with a neural network that knows nothing about the game and then plays games against itself. Finally, the neural network is tuned and updated to predict moves, as well as the eventual winner of the games. The new player AlphaGo is obviously different from human chess players obviously. It may well be better than a human being because it is its own teacher and is not taught by a human being. Can we guess that a robot could have more intelligence than humans? How can we know if it will be able to move faster and be more flexible?
- End-to-end navigation with high intelligence should be executed on the hardware comprising the robot. If the deep learning method is used, current terminal hardware cannot achieve such a large amount of training. The current mechanisms are generally to train the network offline on high-performance hardware such as GPUs, and then online to give the model’s output. The estimation methods usually use a recursion solution form of the state equation; the calculation amount is small and can be executed on current terminal hardware. If combined with the AI method, controlling the total amount of calculating required by the entire system must be considered.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. The Details about Estimation Methods
Appendix A.1. EKF
Appendix A.2. UKF

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Different Parts of Filter | Standard Kalman Filter | EKF |
|---|---|---|
| System Model | ||
| Transformation | / | |
| Prediction of the State | ||
| Updaton of the State | ||
| Filter gain | ||
| Prediction of the Covariance | ||
| Updaton of the Covariance |
| Different Parts of Filter | UKF |
|---|---|
| System Model | |
| Prediction of the State | where and with |
| Updation of the State | |
| Filter gain | |
| Prediction of the Covariance | |
| Updation of the Covariance |
| Different Parts of Filter | CKF |
|---|---|
| System Model | |
| Prediction of the State | where and with |
| Updaton of the State | |
| Filter gain | |
| Prediction of the Covariance | |
| Updaton of the Covariance |
References
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Zhu, A.Z.; Atanasov, N.; Daniilidis, K. Event-based feature tracking with probabilistic data association. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4465–4470. [Google Scholar]
- Dan, L.; Dai-Hong, J.; Rong, B.; Jin-Ping, S.; Wen-Jing, Z.; Chao, W. Moving object tracking method based on improved lucas-kanade sparse optical flow algorithm. In Proceedings of the 2017 International Smart Cities Conference (ISC2), Wuxi, China, 14–17 September 2017; pp. 1–5. [Google Scholar]
- Leshed, G.; Velden, T.; Rieger, O.; Kot, B.; Sengers, P. In-car gps navigation: Engagement with and disengagement from the environment. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; ACM: New York, NY, USA, 2008; pp. 1675–1684. [Google Scholar]
- Ascher, C.; Kessler, C.; Wankerl, M.; Trommer, G. Dual IMU indoor navigation with particle filter based map-matching on a smartphone. In Proceedings of the 2010 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Zurich, Switzerland, 15–17 September 2010; pp. 1–5. [Google Scholar]
- Nikolos, I.K.; Valavanis, K.P.; Tsourveloudis, N.C.; Kostaras, A.N. Evolutionary algorithm based offline/online path planner for UAV navigation. IEEE Trans. Syst. Man Cybern. Part B 2003, 33, 898–912. [Google Scholar]
- Golden, S.A.; Bateman, S.S. Sensor measurements for Wi-Fi location with emphasis on time-of-arrival ranging. IEEE Trans. Mob. Comput. 2007, 6, 1185–1198. [Google Scholar] [CrossRef]
- Zàruba, G.V.; Huber, M.; Kamangar, F.; Chlamtac, I. Indoor location tracking using RSSI readings from a single Wi-Fi access point. Wirel. Netw. 2007, 13, 221–235. [Google Scholar] [CrossRef]
- Adams, J.C.; Gregorwich, W.; Capots, L.; Liccardo, D. Ultra-wideband for navigation and communications. In Proceedings of the 2001 IEEE Aerospace Conference, Big Sky, MT, USA, 10–17 March 2001; Volume 2, pp. 2–785. [Google Scholar]
- Kim, Y.R.; Sul, S.K.; Park, M.H. Speed sensorless vector control of induction motor using extended Kalman filter. IEEE Trans. Ind. Appl. 1994, 30, 1225–1233. [Google Scholar]
- Sabatini, A.M. Quaternion-based extended Kalman filter for determining orientation by inertial and magnetic sensing. IEEE Trans. Biomed. Eng. 2006, 53, 1346–1356. [Google Scholar] [CrossRef] [PubMed]
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef]
- Arasaratnam, I.; Haykin, S. Cubature kalman filters. IEEE Trans. Autom. Control 2009, 54, 1254–1269. [Google Scholar] [CrossRef]
- Singer, R.A. Estimating optimal tracking filter performance for manned maneuvering targets. IEEE Trans. Aerosp. Electron. Syst. 1970, AES-6, 473–483. [Google Scholar] [CrossRef]
- Zhou, H.; Jing, Z.; Wang, P. Maneuvering Target Tracking; National Defense Industry Press: Beijing, China, 1991. [Google Scholar]
- Jilkov, V.; Angelova, D.; Semerdjiev, T.A. Design and comparison of mode-set adaptive IMM algorithms for maneuvering target tracking. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 343–350. [Google Scholar] [CrossRef]
- Jin, X.B.; Du, J.J.; Jia, B. Maneuvering target tracking by adaptive statistics model. J. China Univ. Posts Telecommun. 2013, 20, 108–114. [Google Scholar]
- Kong, X. INS algorithm using quaternion model for low cost IMU. Robot. Auton. Syst. 2004, 46, 221–246. [Google Scholar] [CrossRef]
- Mirzaei, F.M.; Roumeliotis, S.I. A Kalman filter-based algorithm for IMU-camera calibration: Observability analysis and performance evaluation. IEEE Trans. Robot. 2008, 24, 1143–1156. [Google Scholar] [CrossRef]
- Nistér, D.; Naroditsky, O.; Bergen, J. Visual odometry. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; Volume 1, pp. 1–8. [Google Scholar]
- Elfes, A. Using occupancy grids for mobile robot perception and navigation. Computer 1989, 22, 46–57. [Google Scholar] [CrossRef]
- Thrun, S. Learning metric-topological maps for indoor mobile robot navigation. Artif. Intell. 1998, 99, 21–71. [Google Scholar] [CrossRef]
- DeSouza, G.N.; Kak, A.C. Vision for mobile robot navigation: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 237–267. [Google Scholar] [CrossRef]
- Kam, M.; Zhu, X.; Kalata, P. Sensor fusion for mobile robot navigation. Proc. IEEE 1997, 85, 108–119. [Google Scholar] [CrossRef]
- Lambooij, M.; Fortuin, M.; Heynderickx, I.; IJsselsteijn, W. Visual discomfort and visual fatigue of stereoscopic displays: A review. J. Imaging Sci. Technol. 2009, 53. [Google Scholar] [CrossRef]
- Kim, Y.; Hwang, D.H. Vision/INS integrated navigation system for poor vision navigation environments. Sensors 2016, 16, 1672. [Google Scholar] [CrossRef] [PubMed]
- Babel, L. Flight path planning for unmanned aerial vehicles with landmark-based visual navigation. Robot. Auton. Syst. 2014, 62, 142–150. [Google Scholar] [CrossRef]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis. In International Workshop on Vision Algorithms; Springer: Berlin/Heidelberg, Germany, 1999; pp. 298–372. [Google Scholar]
- Badino, H.; Yamamoto, A.; Kanade, T. Visual odometry by multi-frame feature integration. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 222–229. [Google Scholar]
- Tardif, J.P.; George, M.; Laverne, M.; Kelly, A.; Stentz, A. A new approach to vision-aided inertial navigation. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 4161–4168. [Google Scholar]
- Bergmann, P.; Wang, R.; Cremers, D. Online Photometric Calibration for Auto Exposure Video for Realtime Visual Odometry and SLAM. arXiv, 2017; arXiv:1710.02081. [Google Scholar]
- Peretroukhin, V.; Clement, L.; Kelly, J. Reducing drift in visual odometry by inferring sun direction using a bayesian convolutional neural network. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2035–2042. [Google Scholar]
- Kim, A.; Golnaraghi, M. A quaternion-based orientation estimation algorithm using an inertial measurement unit. In Proceedings of the Position Location and Navigation Symposium, PLANS 2004, Monterey, CA, USA, 26–29 April 2004; pp. 268–272. [Google Scholar]
- Lee, H.; Mousa, A.M. GPS travelling wave fault locator systems: Investigation into the anomalous measurements related to lightning strikes. IEEE Trans. Power Deliv. 1996, 11, 1214–1223. [Google Scholar] [CrossRef]
- Buchli, B.; Sutton, F.; Beutel, J. GPS-equipped wireless sensor network node for high-accuracy positioning applications. In European Conference on Wireless Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 179–195. [Google Scholar]
- Li, B.; Zhang, S.; Shen, S. CSI-based WiFi-inertial state estimation. In Proceedings of the 2016 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Baden-Baden, Germany, 19–21 September 2016; pp. 244–250. [Google Scholar]
- Marquez, A.; Tank, B.; Meghani, S.K.; Ahmed, S.; Tepe, K. Accurate UWB and IMU based indoor localization for autonomous robots. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–4. [Google Scholar]
- Lee, J.S.; Su, Y.W.; Shen, C.C. A comparative study of wireless protocols: Bluetooth, UWB, ZigBee, and Wi-Fi. In Proceedings of the 33rd Annual Conference of the IEEE Industrial Electronics Society, IECON 2007, Taipei, Taiwan, 5–8 November 2007; pp. 46–51. [Google Scholar]
- Corna, A.; Fontana, L.; Nacci, A.; Sciuto, D. Occupancy detection via iBeacon on Android devices for smart building management. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition, EDA Consortium, Grenoble, France, 9–13 March 2015; pp. 629–632. [Google Scholar]
- Lin, X.Y.; Ho, T.W.; Fang, C.C.; Yen, Z.S.; Yang, B.J.; Lai, F. A mobile indoor positioning system based on iBeacon technology. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 4970–4973. [Google Scholar]
- He, Z.; Cui, B.; Zhou, W.; Yokoi, S. A proposal of interaction system between visitor and collection in museum hall by iBeacon. In Proceedings of the 2015 10th International Conference on Computer Science & Education (ICCSE), Cambridge, UK, 22–24 July 2015; pp. 427–430. [Google Scholar]
- Koühne, M.; Sieck, J. Location-based services with iBeacon technology. In Proceedings of the 2014 2nd International Conference on Artificial Intelligence, Modelling and Simulation (AIMS), Madrid, Spain, 18–20 November 2014; pp. 315–321. [Google Scholar]
- Jin, X.B.; Dou, C.; Su, T.l.; Lian, X.f.; Shi, Y. Parallel irregular fusion estimation based on nonlinear filter for indoor RFID tracking system. Int. J. Distrib. Sens. Netw. 2016, 12, 1472930. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, J. A comprehensive multi-factor analysis on RFID localization capability. Adv. Eng. Inform. 2011, 25, 32–40. [Google Scholar] [CrossRef]
- Martin, E.; Vinyals, O.; Friedland, G.; Bajcsy, R. Precise indoor localization using smart phones. In Proceedings of the 18th ACM international conference on Multimedia. ACM, Firenze, Italy, 25–29 October 2010; pp. 787–790. [Google Scholar]
- Yang, C.; Shao, H.R. WiFi-based indoor positioning. IEEE Commun. Mag. 2015, 53, 150–157. [Google Scholar] [CrossRef]
- Ferrera, E.; Capitán, J.; Marrón, P.J. From Fast to Accurate Wireless Map Reconstruction for Human Positioning Systems. In Iberian Robotics Conference; Springer: Cham, Switzerland, 2017; pp. 299–310. [Google Scholar]
- Kotaru, M.; Joshi, K.; Bharadia, D.; Katti, S. SpotFi: Decimeter Level Localization Using WiFi. SIGCOMM Comput. Commun. Rev. 2015, 45, 269–282. [Google Scholar]
- Liu, Y.; Fan, X.; Lv, C.; Wu, J.; Li, L.; Ding, D. An innovative information fusion method with adaptive Kalman filter for integrated INS/GPS navigation of autonomous vehicles. Mech. Syst. Signal Process. 2018, 100, 605–616. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Nguyen, V.H.; Nguyen, H.V. Tightly-coupled INS/GPS integration with magnetic aid. In Proceedings of the 2017 2nd International Conference on Control and Robotics Engineering (ICCRE), Bangkok, Thailand, 1–3 April 2017; pp. 207–212. [Google Scholar]
- Alatise, M.B.; Hancke, G.P. Pose Estimation of a Mobile Robot Based on Fusion of IMU Data and Vision Data Using an Extended Kalman Filter. Sensors 2017, 17, 2164. [Google Scholar] [CrossRef] [PubMed]
- Su, S.; Zhou, Y.; Wang, Z.; Chen, H. Monocular Vision-and IMU-Based System for Prosthesis Pose Estimation During Total Hip Replacement Surgery. IEEE Trans. Biomed. Circuits Syst. 2017, 11, 661–670. [Google Scholar] [CrossRef] [PubMed]
- Malyavej, V.; Kumkeaw, W.; Aorpimai, M. Indoor robot localization by RSSI/IMU sensor fusion. In Proceedings of the 2013 10th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Krabi, Thailand, 15–17 May 2013; pp. 1–6. [Google Scholar]
- Zhang, P.; Gu, J.; Milios, E.E.; Huynh, P. Navigation with IMU/GPS/digital compass with unscented Kalman filter. In Proceedings of the 2005 IEEE International Conference Mechatronics and Automation, Niagara Falls, ON, Canada, 29 July–1 August 2005; Volume 3, pp. 1497–1502. [Google Scholar]
- Ma, S.; Zhang, Y.; Xu, Y.; Wang, B.; Cheng, J.; Zhao, Q. Indoor robot navigation by coupling IMU, UWB, and encode. In Proceedings of the 2016 10th International Conference on Software, Knowledge, Information Management & Applications (SKIMA), Chengdu, China, 15–17 December 2016; pp. 429–432. [Google Scholar]
- Fan, Q.; Sun, B.; Sun, Y.; Wu, Y.; Zhuang, X. Data Fusion for Indoor Mobile Robot Positioning Based on Tightly Coupled INS/UWB. J. Navig. 2017, 70, 1079–1097. [Google Scholar] [CrossRef]
- Ruiz, A.R.J.; Granja, F.S.; Honorato, J.C.P.; Rosas, J.I.G. Accurate pedestrian indoor navigation by tightly coupling foot-mounted IMU and RFID measurements. IEEE Trans. Instrum. Meas. 2012, 61, 178–189. [Google Scholar] [CrossRef] [Green Version]
- Jiménez, A.R.; Seco, F.; Zampella, F.; Prieto, J.C.; Guevara, J. Indoor localization of persons in aal scenarios using an inertial measurement unit (IMU) and the signal strength (SS) from RFID tags. In International Competition on Evaluating AAL Systems through Competitive Benchmarking; Springer: Berlin/Heidelberg, Germany, 2012; pp. 32–51. [Google Scholar]
- Caron, F.; Duflos, E.; Pomorski, D.; Vanheeghe, P. GPS/IMU data fusion using multisensor Kalman filtering: Introduction of contextual aspects. Inf. Fusion 2006, 7, 221–230. [Google Scholar] [CrossRef]
- Rios, J.A.; White, E. Fusion Filter Algorithm Enhancements for a MEMS GPS/IMU; Crossbow Technology Inc.: Milpitas, CA, USA, 2002. [Google Scholar]
- Saadeddin, K.; Abdel-Hafez, M.F.; Jarrah, M.A. Estimating vehicle state by GPS/IMU fusion with vehicle dynamics. J. Intell. Robot. Syst. 2014, 74, 147–172. [Google Scholar] [CrossRef]
- Werries, A.; Dolan, J.M. Adaptive Kalman Filtering Methods for Low-Cost GPS/INS Localization for Autonomous Vehicles; Research Showcase CMU: Pittsburgh, PA, USA, 2016; Available online: http://http://repository.cmu.edu/robotics/ (accessed on 20 February 2018).
- Zhao, Y. Applying Time-Differenced Carrier Phase in Nondifferential GPS/IMU Tightly Coupled Navigation Systems to Improve the Positioning Performance. IEEE Trans. Veh. Technol. 2017, 66, 992–1003. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR-based Driving Path Generation Using Fully Convolutional Neural Networks; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Jaradat, M.A.K.; Abdel-Hafez, M.F. Non-Linear Autoregressive Delay-Dependent INS/GPS Navigation System Using Neural Networks. IEEE Sens. J. 2017, 17, 1105–1115. [Google Scholar] [CrossRef]
- Bostanci, E.; Bostanci, B.; Kanwal, N.; Clark, A.F. Sensor fusion of camera, GPS and IMU using fuzzy adaptive multiple motion models. Soft Comput. 2017, 21, 1–14. [Google Scholar] [CrossRef]
- Huang, G.; Eckenhoff, K.; Leonard, J. Optimal-state-constraint EKF for visual-inertial navigation. In Robotics Research; Springer: Cham, Switzerland, 2018; pp. 125–139. [Google Scholar]
- Zhang, X.; Huo, L. A Vision/Inertia Integrated Positioning Method Using Position and Orientation Matching. Math. Probl. Eng. 2017, 2017, 6835456. [Google Scholar] [CrossRef]
- Dong, X.; He, B.; Dong, X.; Dong, J. Monocular visual-IMU odometry using multi-channel image patch exemplars. Multimedia Tools Appl. 2017, 76, 11975–12003. [Google Scholar] [CrossRef]
- Ascani, A.; Frontoni, E.; Mancini, A.; Zingaretti, P. Feature group matching for appearance-based localization. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2008, Nice, France, 22–26 September 2008; pp. 3933–3938. [Google Scholar]
- Audi, A.; Pierrot-Deseilligny, M.; Meynard, C.; Thom, C. Implementation of an IMU Aided Image Stacking Algorithm in a Digital Camera for Unmanned Aerial Vehicles. Sensors 2017, 17, 1646. [Google Scholar] [CrossRef] [PubMed]
- Kneip, L.; Chli, M.; Siegwart, R.Y. Robust real-time visual odometry with a single camera and an IMU. In Proceedings of the British Machine Vision Conference 2011; British Machine Vision Association: Durham, UK, 2011. [Google Scholar]
- Spaenlehauer, A.; Fremont, V.; Sekercioglu, Y.A.; Fantoni, I. A Loosely-Coupled Approach for Metric Scale Estimation in Monocular Vision-Inertial Systems; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Reid, D. An algorithm for tracking multiple targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Grewal, M.S. Kalman filtering. In International Encyclopedia of Statistical Science; Springer: Berlin, Germany; London, UK, 2011; pp. 705–708. [Google Scholar]
- Sinharay, A.; Pal, A.; Bhowmick, B. A kalman filter based approach to de-noise the stereo vision based pedestrian position estimation. In Proceedings of the 2011 UkSim 13th International Conference on Computer Modelling and Simulation (UKSim), Cambridge, UK, 30 March–1 April 2011; pp. 110–115. [Google Scholar]
- Ljung, L. Asymptotic behavior of the extended Kalman filter as a parameter estimator for linear systems. IEEE Trans. Autom. Control 1979, 24, 36–50. [Google Scholar] [CrossRef]
- Hoshiya, M.; Saito, E. Structural identification by extended Kalman filter. J. Eng. Mech. 1984, 110, 1757–1770. [Google Scholar] [CrossRef]
- Dhaouadi, R.; Mohan, N.; Norum, L. Design and implementation of an extended Kalman filter for the state estimation of a permanent magnet synchronous motor. IEEE Trans. Power Electron. 1991, 6, 491–497. [Google Scholar] [CrossRef]
- Marins, J.L.; Yun, X.; Bachmann, E.R.; McGhee, R.B.; Zyda, M.J. An extended Kalman filter for quaternion-based orientation estimation using MARG sensors. In Proceedings of the 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems, Maui, HI, USA, 29 October–3 November 2001; Volume 4, pp. 2003–2011. [Google Scholar]
- Yang, S.; Baum, M. Extended Kalman filter for extended object tracking. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4386–4390. [Google Scholar]
- Julier, S.J. The scaled unscented transformation. In Proceedings of the 2002 American Control Conference, Anchorage, AK, USA, 8–10 May 2002; Volume 6, pp. 4555–4559. [Google Scholar]
- Hong-de, D.; Shao-wu, D.; Yuan-cai, C.; Guang-bin, W. Performance comparison of EKF/UKF/CKF for the tracking of ballistic target. Indones. J. Electr. Eng. Comput. Sci. 2012, 10, 1692–1699. [Google Scholar] [CrossRef]
- Ding, Z.; Balaji, B. Comparison of the unscented and cubature Kalman filters for radar tracking applications. In Proceedings of the IET International Conference on Radar Systems, Glasgow, UK, 22–25 October 2012. [Google Scholar]
- Jagan, B.O.L.; Rao, S.K.; Lakshmi, M.K. Concert Assessment of Unscented and Cubature Kalman Filters for Target Tracking. J. Adv. Res. Dyn. Control Syst. 2017, 9, 72–80. [Google Scholar]
- Pesonen, H.; Piché, R. Cubature-based Kalman filters for positioning. In Proceedings of the 2010 7th Workshop on Positioning Navigation and Communication (WPNC), Dresden, Germany, 11–12 March 2010; pp. 45–49. [Google Scholar]
- Chang, L.; Hu, B.; Li, A.; Qin, F. Transformed unscented Kalman filter. IEEE Trans. Autom. Control 2013, 58, 252–257. [Google Scholar] [CrossRef]
- Dunik, J.; Straka, O.; Simandl, M. Stochastic integration filter. IEEE Trans. Autom. Control 2013, 58, 1561–1566. [Google Scholar] [CrossRef]
- Carpenter, J.; Clifford, P.; Fearnhead, P. Improved particle filter for nonlinear problems. IEE Proc.-Radar Sonar Navig. 1999, 146, 2–7. [Google Scholar] [CrossRef]
- Van Der Merwe, R.; Doucet, A.; De Freitas, N.; Wan, E.A. The unscented particle filter. In Proceedings of the Advances in Neural Information Processing Systems 14 (NIPS 2001), Vancouver, BC, Canada, 3–8 December 2001; pp. 584–590. [Google Scholar]
- Chopin, N. A sequential particle filter method for static models. Biometrika 2002, 89, 539–552. [Google Scholar] [CrossRef]
- Nummiaro, K.; Koller-Meier, E.; Van Gool, L. An adaptive color-based particle filter. Image Vis. Comput. 2003, 21, 99–110. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Chen, Z.; Qu, Y.; Xi, Z.; Bo, Y.; Liu, B. Efficient Particle Swarm Optimized Particle Filter Based Improved Multiple Model Tracking Algorithm. Comput. Intell. 2017, 33, 262–279. [Google Scholar] [CrossRef]
- McCarthy, J.; Minsky, M.L.; Rochester, N.; Shannon, C.E. A proposal for the dartmouth summer research project on artificial intelligence, 31 August 1955. AI Mag. 2006, 27, 12. [Google Scholar]
- Ross, T. Machines that think. Sci. Am. 1933, 148, 206–208. [Google Scholar] [CrossRef]
- Frank, R. The Perceptron a Perceiving and Recognizing Automaton; Tech. Rep.; Cornell Aeronautical Laboratory: Buffalo, NY, USA, 1957; pp. 85–460. [Google Scholar]
- Crevier, D. AI: The Tumultuous History of the Search for Artificial Intelligence; Basic Books: New York, NY, USA, 1993. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- CireşAn, D.; Meier, U.; Masci, J.; Schmidhuber, J. Multi-column deep neural network for traffic sign classification. Neural Netw. 2012, 32, 333–338. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar]
- Seeliger, K.; Fritsche, M.; Güçlü, U.; Schoenmakers, S.; Schoffelen, J.M.; Bosch, S.; van Gerven, M. Convolutional neural network-based encoding and decoding of visual object recognition in space and time. NeuroImage 2017, in press. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Chen, C.; Meng, F.; Liu, H. 3D action recognition using multi-temporal skeleton visualization. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 623–626. [Google Scholar]
- Polvara, R.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R. Obstacle Avoidance Approaches for Autonomous Navigation of Unmanned Surface Vehicles. J. Navig. 2018, 71, 241–256. [Google Scholar] [CrossRef]
- Li, C.; Konomis, D.; Neubig, G.; Xie, P.; Cheng, C.; Xing, E. Convolutional Neural Networks for Medical Diagnosis from Admission Notes; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network; Cornell University arXiv Institution: Ithaca, NY, USA, 2013. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation; Cornell University arXiv Institution: Ithaca, NY, USA, 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition; Cornell University arXiv Institution: Ithaca, NY, USA, 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning; AAAI: San Francisco, CA, USA, 2017; Volume 4, p. 12. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q.; van der Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii Convention Center, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger; Cornell University arXiv Institution: Ithaca, NY, USA, 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Quebec, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Hu, R.; Dollár, P.; He, K.; Darrell, T.; Girshick, R. Learning to Segment Every Thing; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering; CVPR: Honolulu, HI, USA, 2017; Volume 1, p. 9. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I. Training Recurrent Neural Networks; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Huang, Y.; Wu, Z.; Meng, H.; Xu, M.; Cai, L. Question detection from acoustic features using recurrent neural network with gated recurrent unit. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6125–6129. [Google Scholar]
- Gulcehre, C.; Chandar, S.; Cho, K.; Bengio, Y. Dynamic Neural Turing Machine with Soft and Hard Addressing Schemes; Cornell University arXiv Institution: Ithaca, NY, USA, 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Los Angeles, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Lawrence Zitnick, C.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Das, A.; Agrawal, H.; Zitnick, L.; Parikh, D.; Batra, D. Human attention in visual question answering: Do humans and deep networks look at the same regions? Comput. Vis. Image Underst. 2017, 163, 90–100. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Streiffer, C.; Raghavendra, R.; Benson, T.; Srivatsa, M. DarNet: A Deep Learning Solution for Distracted Driving Detection. In Proceedings of the Middleware Industry 2017, Industrial Track of the 18th International Middleware Conference, Las. Vegas, NV, USA, 11–15 December 2017. [Google Scholar]
- Luo, J.; Yan, B.; Wood, K. InnoGPS for Data-Driven Exploration of Design Opportunities and Directions: The Case of Google Driverless Car Project. J. Mech. Des. 2017, 139, 111416. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, S.; Tang, J.; Zhang, Z.; Gaudiot, J.L. CAAD: Computer Architecture for Autonomous Driving; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Sucar, E.; Hayet, J.B. Bayesian Scale Estimation for Monocular SLAM Based on Generic Object Detection for Correcting Scale Drift; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Noureldin, A.; El-Shafie, A.; Bayoumi, M. GPS/INS integration utilizing dynamic neural networks for vehicular navigation. Inf. Fusion 2011, 12, 48–57. [Google Scholar] [CrossRef]
- Bezenac, E.d.; Pajot, A.; Patrick, G. Deep Learning for Physical Processes: Incorporating Prior Scientific Knowledge; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Bhattacharyya, A.; Fritz, M.; Schiele, B. Long-Term On-Board Prediction of People in Traffic Scenes under Uncertainty; Cornell University arXiv Institution: Ithaca, NY, USA, 2017. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]












| Reference | Sensors |
|---|---|
| [18,49,50] | GPS, IMU |
| [19,51,52] | Camera, IMU |
| [36,53] | Wi-Fi, IMU |
| [54] | GPS, Digital Compass, IMU |
| [37,55,56] | UWB, IMU |
| [57,58] | RFID, IMU |
| Estimation Method | Linear | Nonlinear | Non-Gaussian Process/Measurement Noise | Computational Complexity |
|---|---|---|---|---|
| Kalman Filter | Yes | No | No | low |
| EKF | / | Yes | No | medium |
| UKF | / | Yes | No | medium |
| CKF | / | Yes | No | medium |
| PL | / | Yes | Yes | high |
| The Used Models | The Tracking Covariance |
|---|---|
| CV | 350.08 |
| CA | 290.76 |
| Singer model | 210.40 |
| current model | 178.98 |
| IMM algorithm model | 123.02 |
| the adaptive model | 120.75 |
| The Used Methods | The Tracking Covariance |
|---|---|
| EKF | 148.06 |
| UKF | 120.75 |
| CKF | 123.45 |
| PF | 122.29 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, X.-B.; Su, T.-L.; Kong, J.-L.; Bai, Y.-T.; Miao, B.-B.; Dou, C. State-of-the-Art Mobile Intelligence: Enabling Robots to Move Like Humans by Estimating Mobility with Artificial Intelligence. Appl. Sci. 2018, 8, 379. https://doi.org/10.3390/app8030379
Jin X-B, Su T-L, Kong J-L, Bai Y-T, Miao B-B, Dou C. State-of-the-Art Mobile Intelligence: Enabling Robots to Move Like Humans by Estimating Mobility with Artificial Intelligence. Applied Sciences. 2018; 8(3):379. https://doi.org/10.3390/app8030379
Chicago/Turabian StyleJin, Xue-Bo, Ting-Li Su, Jian-Lei Kong, Yu-Ting Bai, Bei-Bei Miao, and Chao Dou. 2018. "State-of-the-Art Mobile Intelligence: Enabling Robots to Move Like Humans by Estimating Mobility with Artificial Intelligence" Applied Sciences 8, no. 3: 379. https://doi.org/10.3390/app8030379
APA StyleJin, X. -B., Su, T. -L., Kong, J. -L., Bai, Y. -T., Miao, B. -B., & Dou, C. (2018). State-of-the-Art Mobile Intelligence: Enabling Robots to Move Like Humans by Estimating Mobility with Artificial Intelligence. Applied Sciences, 8(3), 379. https://doi.org/10.3390/app8030379