A Multi-Modal Person Recognition System for Social Robots

Abstract
:1. Introduction
2. Related Studies
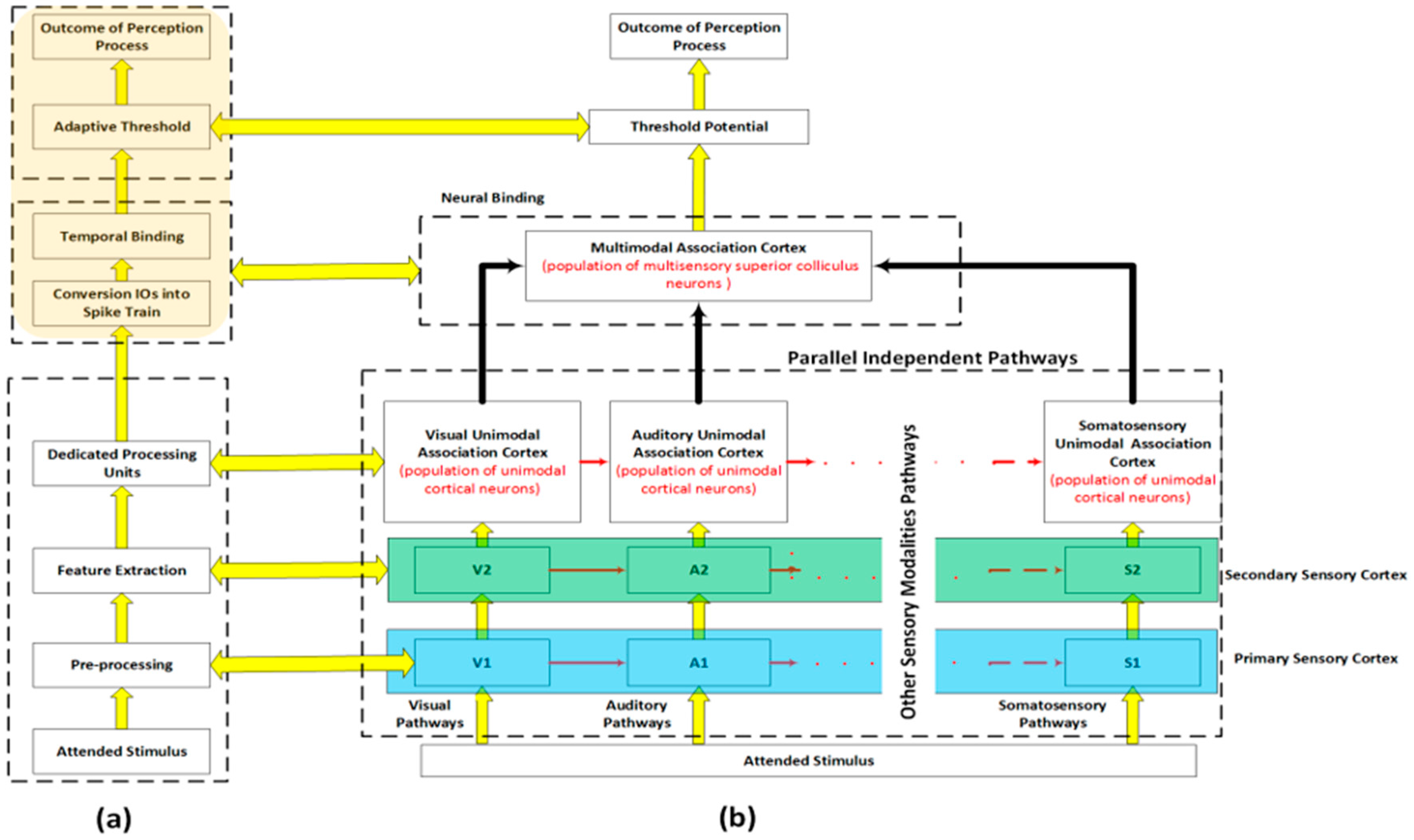
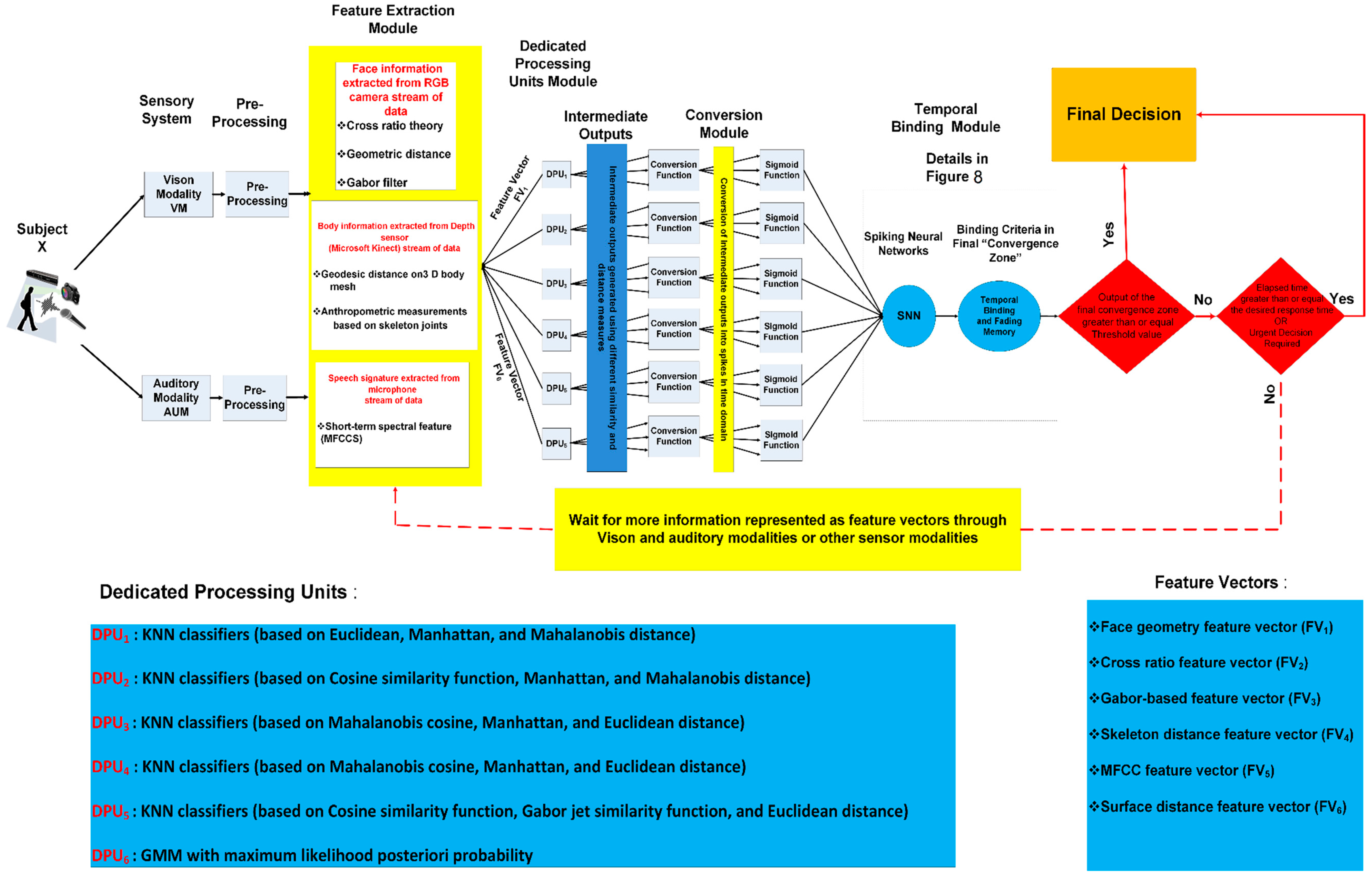
3. Architecture of the Person Recognition System
3.1. Front-End Sensors and Preprocessing
3.2. Feature Extraction
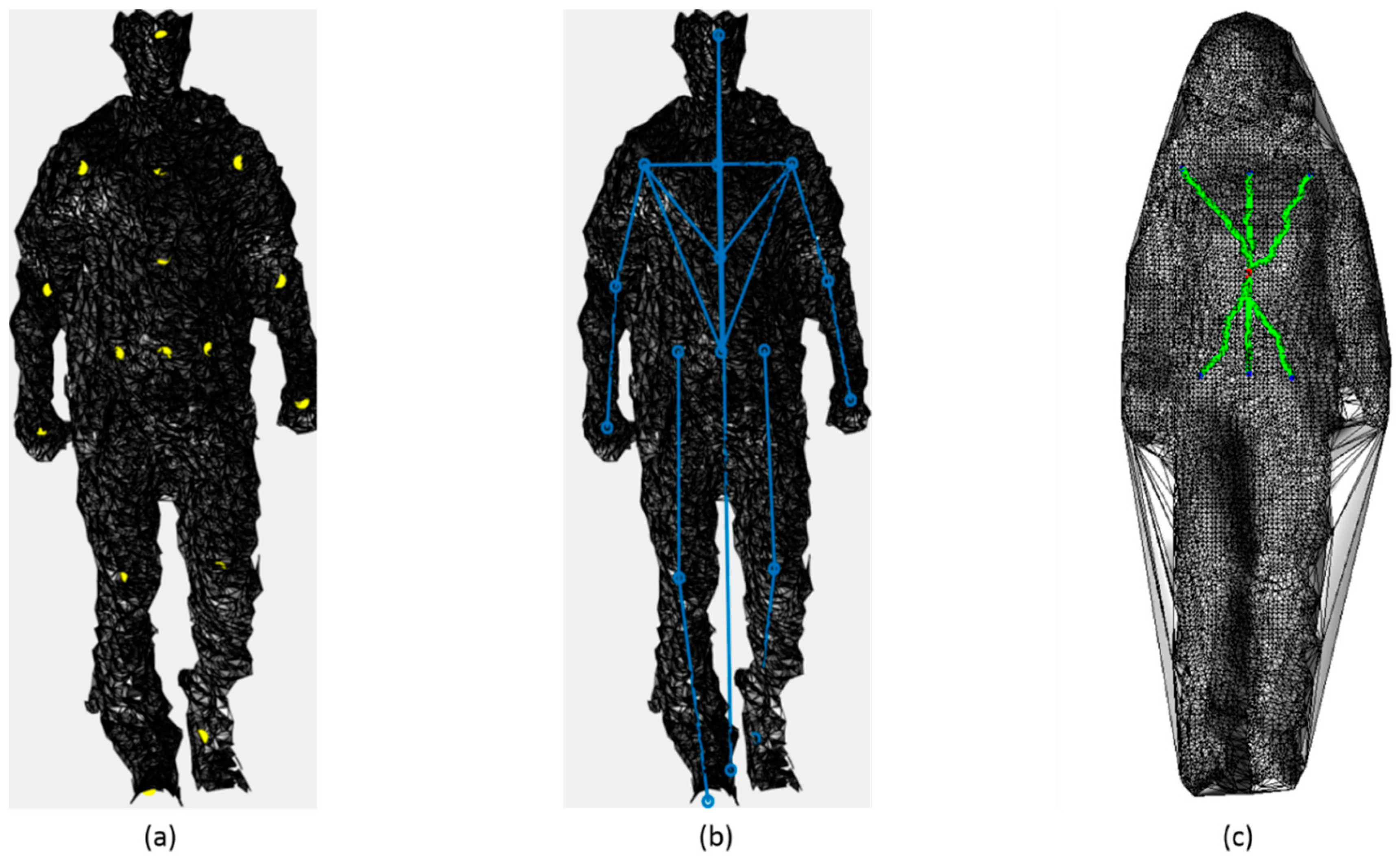
3.2.1. Vision-Based Feature Vectors
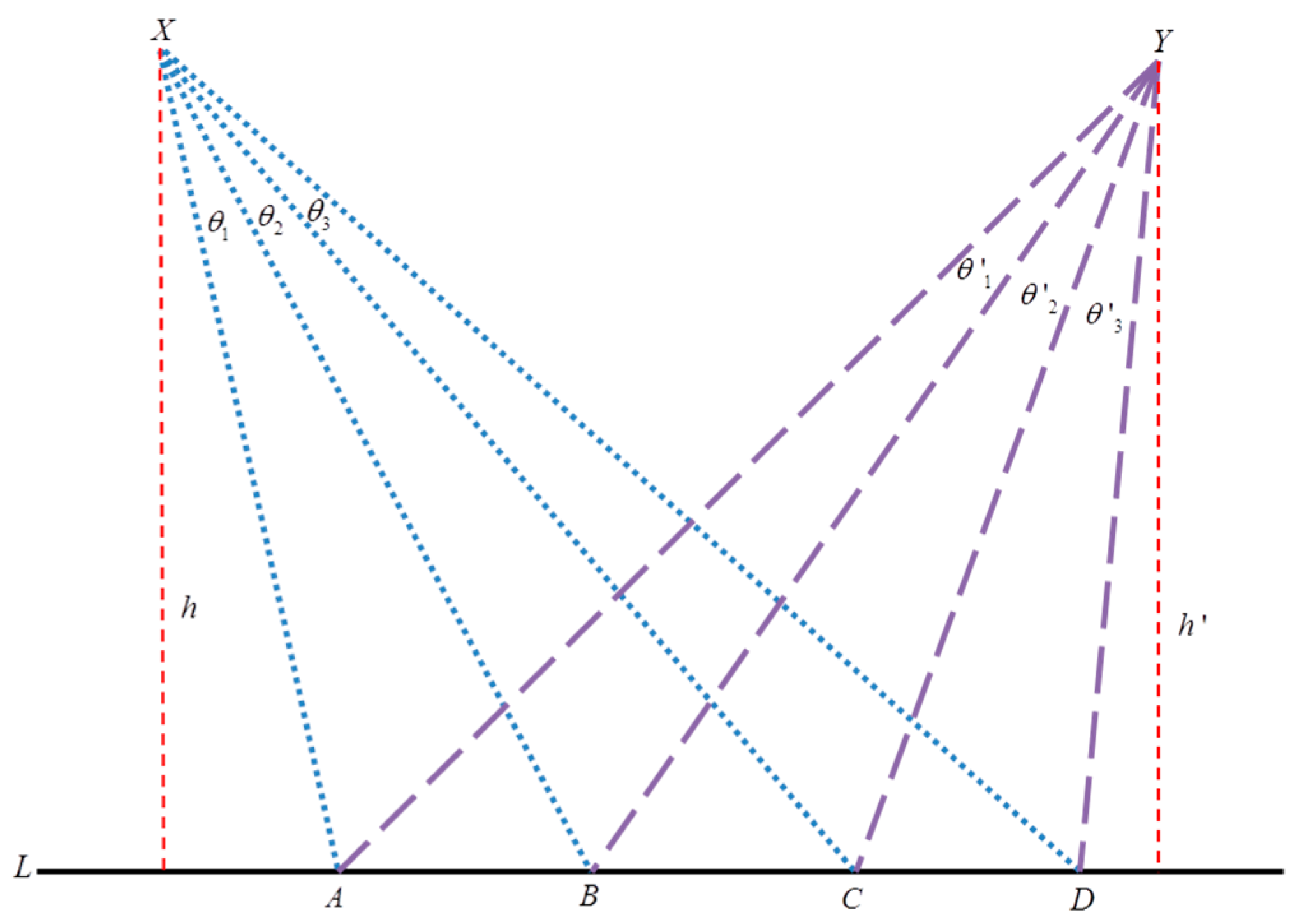
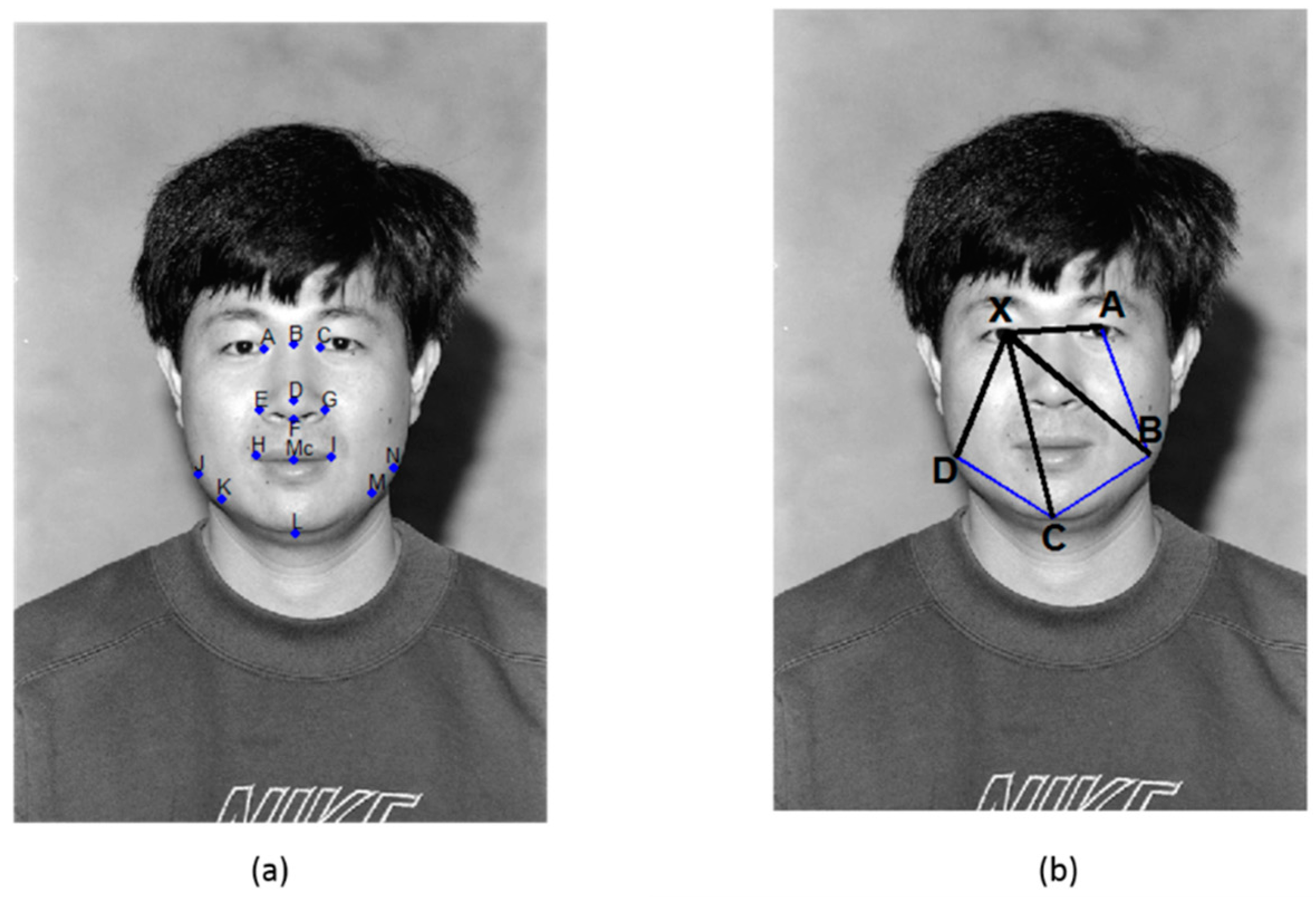
The Configural Features Group
The Appearance-Based Feature Group
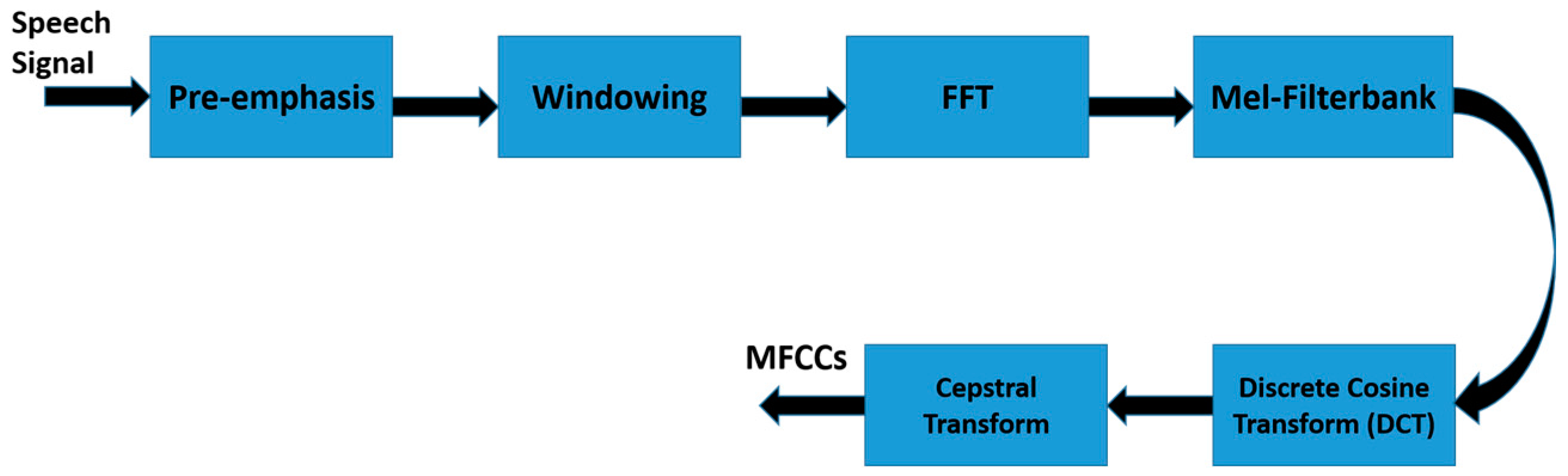
3.2.2. Voice-Based Feature Vector
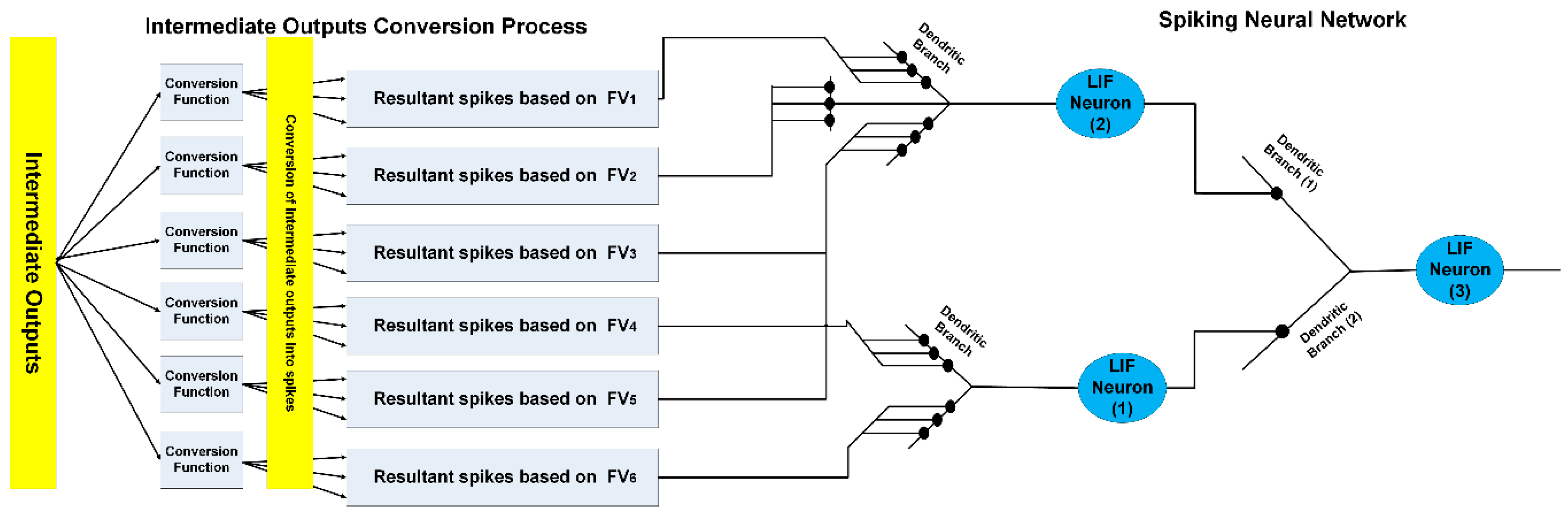
3.3. Dedicated Processing Units and Generation of the Intermediate Outputs
3.3.1. Dedicated Processing Units for Vision-Based Feature Vectors
3.3.2. Dedicated Processing Units for Voice-Based Feature Vector
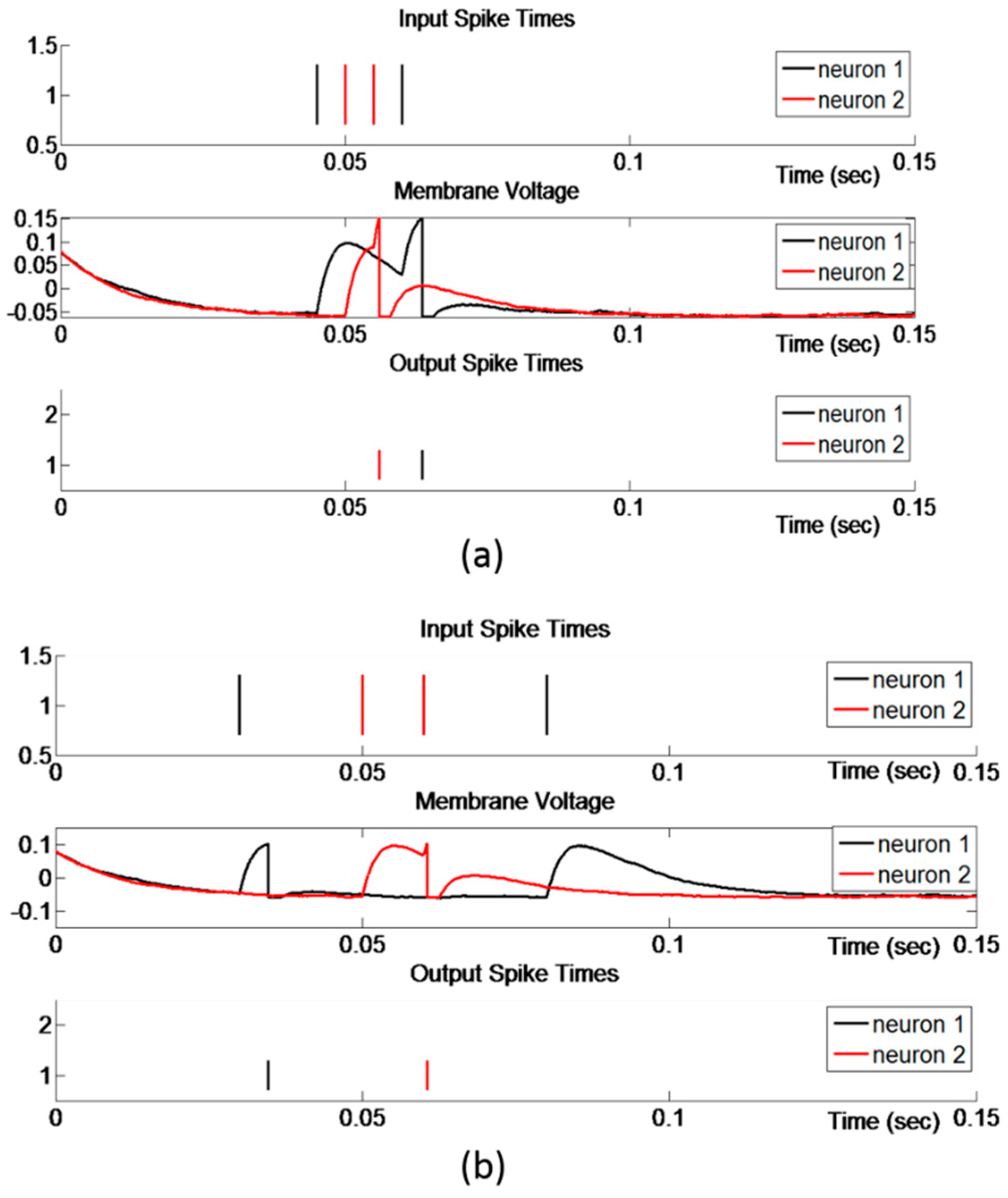
3.4. Temporal Binding via Spiking Neural Networks
4. Experimental Results
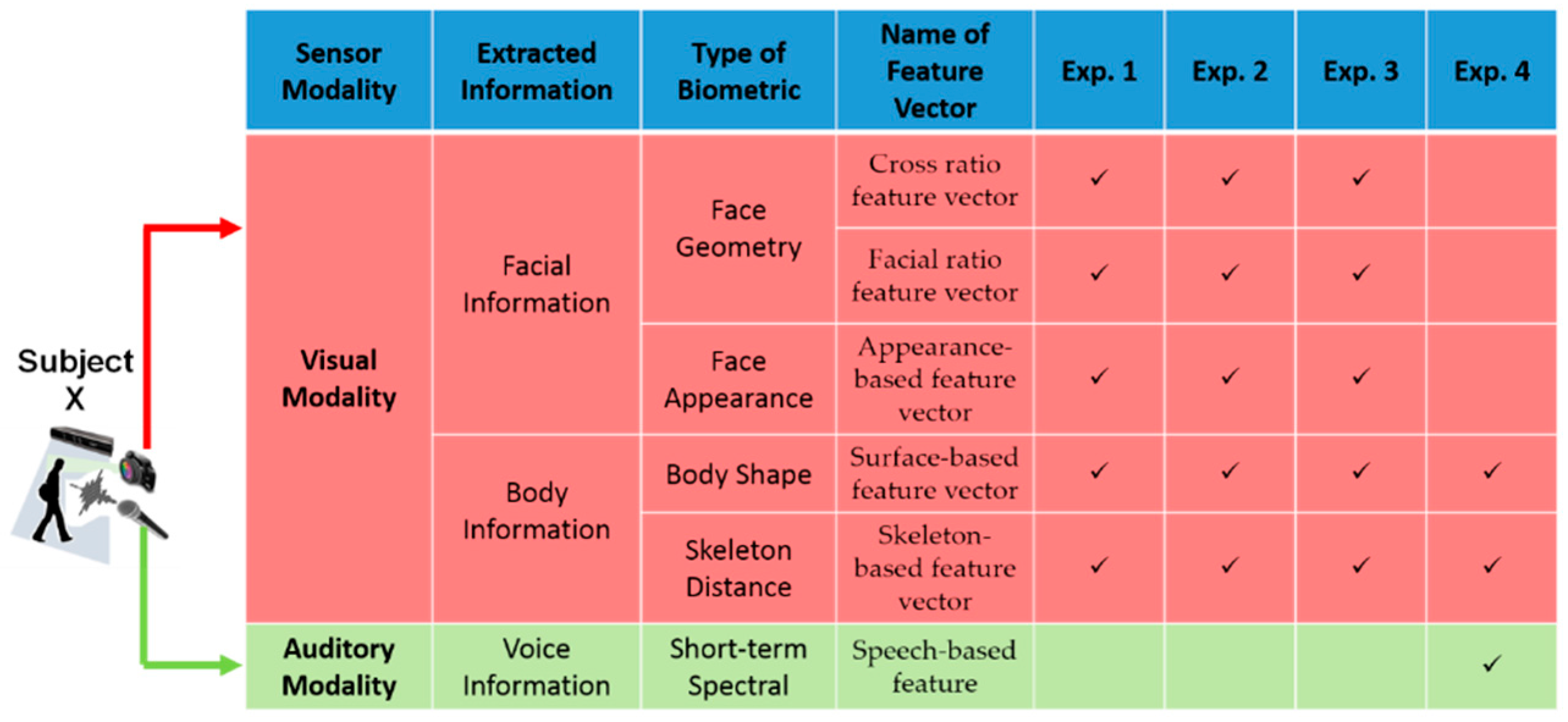
4.1. Generation of Multi-Modal Data Set
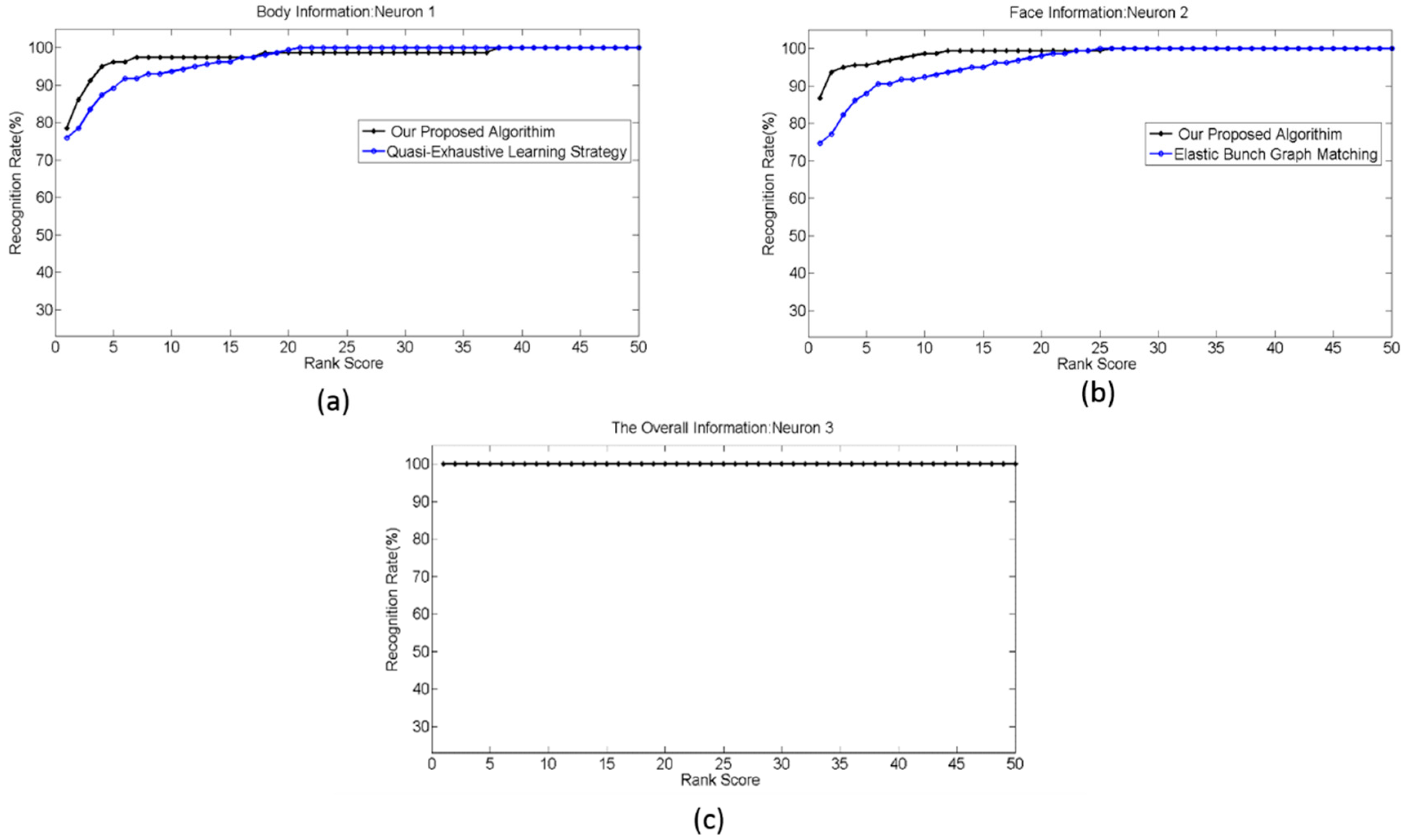
4.2. Experiment 1
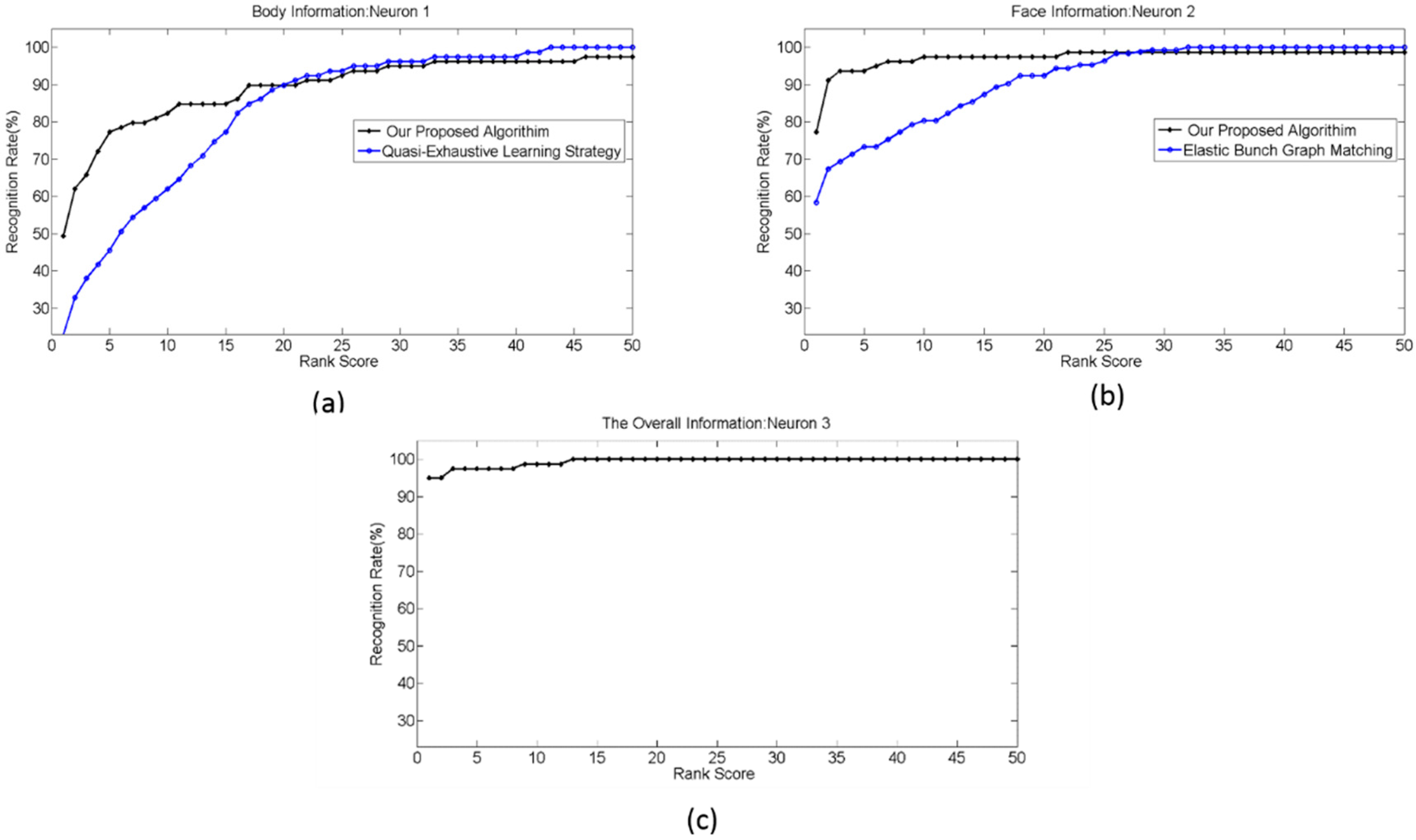
4.3. Experiment 2
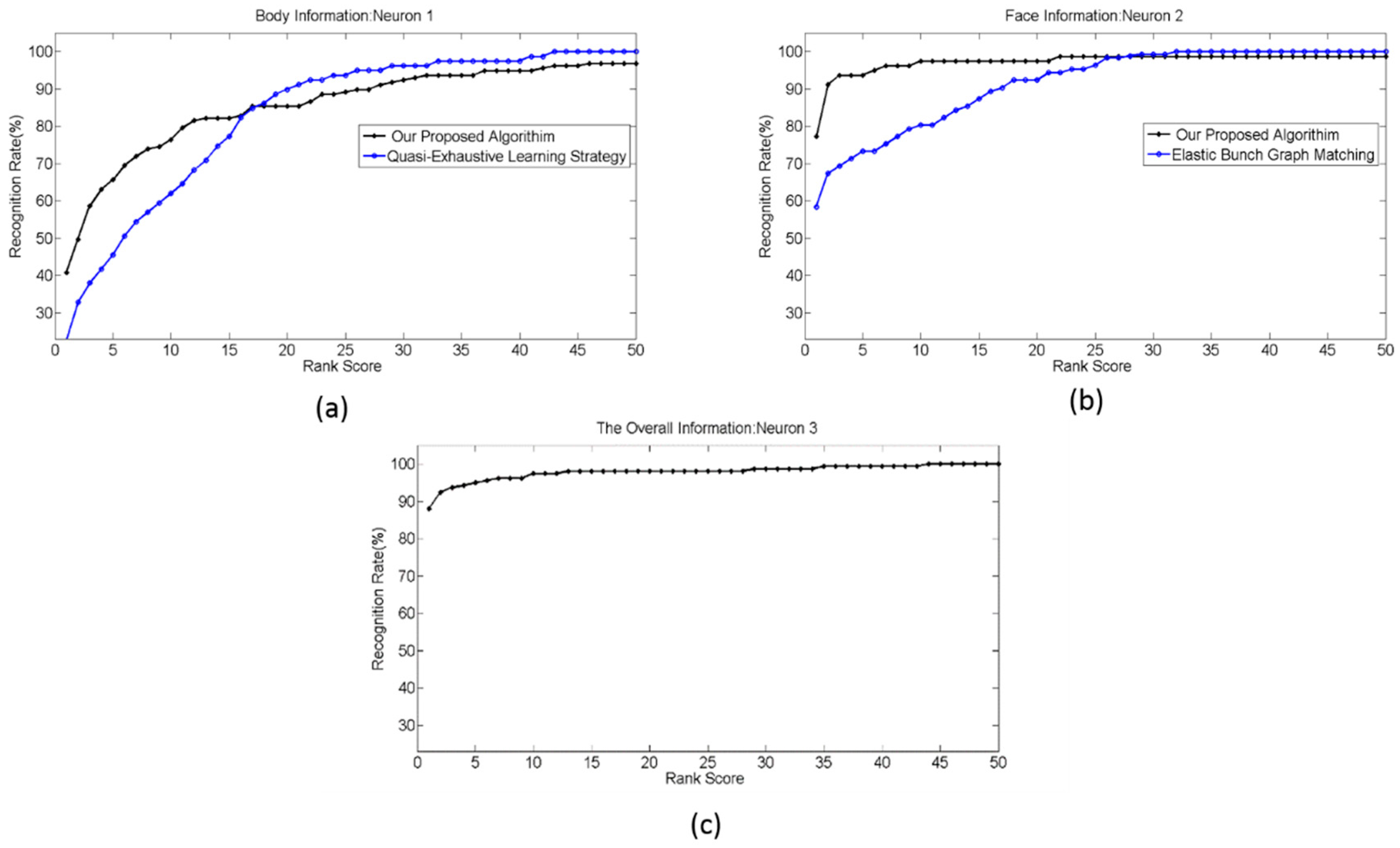
4.4. Experiment 3
4.5. Experiment 4
5. Discussions
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Appendix B
| (Skeleton-Based Feature) |
|---|
| • Euclidean distance between floor and head. • Euclidean distance between floor and neck. • Euclidean distance between floor and left hip. • Euclidean distance between floor and right hip. • Mean of Euclidean distances of floor to right hip and floor to left hip. • Euclidean distance between neck and left shoulder. • Euclidean distance between neck and right shoulder. • Mean of Euclidean distances of neck to left shoulder and neck to right shoulder. • Ratio between torso and legs. • Euclidean distance between torso and left shoulder. • Euclidean distance between torso and right shoulder. • Euclidean distance between torso and mid hip. • Euclidean distance between torso and neck. • Euclidean distance between left hip and left knee. • Euclidean distance between right hip and right knee. • Euclidean distance between left knee and left foot. • Euclidean distance between right knee and right foot. • Left leg length. • Right leg length. • Euclidean distance between left shoulder and left elbow. • Euclidean distance between right shoulder and right elbow. • Euclidean distance between left elbow and left hand. • Euclidean distance between right elbow and right hand.Left arm length. • Right arm length. • Torso length. • Height estimate. • Euclidean distance between hip center and right shoulder. • Euclidean distance between hip center and left shoulder. |
| (Surface-Based Feature Vector) |
|---|
| • Geodesic distance between left hip and left knee. • Geodesic distance between right hip and right knee. • Geodesic distance between torso center and left shoulder. • Geodesic distance between torso center and right shoulder. • Geodesic distance between torso center and left hip. • Geodesic distance between torso center and right hip. • Geodesic distance between right shoulder and left shoulder. • Geodesic distance between left hip and left knee. • Geodesic distance between right hip and right knee. • Geodesic distance between torso center and left shoulder. • Geodesic distance between torso center and right shoulder. • Geodesic distance between torso center and left hip. • Geodesic distance between torso center and right hip. • Geodesic distance between right shoulder and left shoulder. |
References
- Chalabi, M. How Many People Can You Remember? 2015. Available online: https://fivethirtyeight.com/features/how-many-people-can-you-remember/ (accessed on 15 April 2016).
- Sacks, O.W. The Mind’s Eye, 1st ed.; Alfred A. Knopf: New York, NY, USA, 2010. [Google Scholar]
- Brunelli, R.; Falavigna, D. Person identification using multiple cues. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 955–966. [Google Scholar] [CrossRef]
- Zhou, X.; Bhanu, B. Feature fusion of side face and gait for video-based human identification. Pattern Recognit. 2008, 41, 778–795. [Google Scholar] [CrossRef]
- Zhou, X.; Bhanu, B. Integrating face and gait for human recognition at a distance in video. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2007, 37, 1119–1137. [Google Scholar] [CrossRef]
- Palanivel, S.; Yegnanarayana, B. Multimodal person authentication using speech, face and visual speech. Comput. Vis. Image Underst. 2008, 109, 44–55. [Google Scholar] [CrossRef]
- Gong, S.; Cristani, M.; Yan, S.; Loy, C.C. (Eds.) Person Re-Identification; Springer: London, UK, 2014. [Google Scholar]
- Dantcheva, A.; Velardo, C.; D’Angelo, A.; Dugelay, J.-L. Bag of soft biometrics for person identification. Multimed. Tools Appl. 2011, 51, 739–777. [Google Scholar] [CrossRef]
- Arigbabu, O.A.; Ahmad, S.M.S.; Adnan, W.A.W.; Yussof, S. Recent advances in facial soft biometrics. Vis. Comput. 2015, 31, 513–525. [Google Scholar] [CrossRef]
- Feng, G.; Dong, K.; Hu, D.; Zhang, D. When Faces Are Combined with Palmprints: A Novel Biometric Fusion Strategy. In Biometric Authentication SE-95; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3072, pp. 701–707. [Google Scholar]
- Jain, A.; Nandakumar, K.; Lu, X.; Park, U. Integrating faces, fingerprints, and soft biometric traits for user recognition. In Biometric Authentication; Springer: Berlin/Heidelberg, Germany, 2004; pp. 259–269. [Google Scholar]
- Raghavendra, R.; Dorizzi, B.; Rao, A.; Kumar, G.H. Designing efficient fusion schemes for multimodal biometric systems using face and palmprint. Pattern Recognit. 2011, 44, 1076–1088. [Google Scholar] [CrossRef]
- Samangooei, S.; Guo, B.; Nixon, M.S. The Use of Semantic Human Description as a Soft Biometric. In Proceedings of the 2nd IEEE International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 29 September–1 October 2008; pp. 1–7. [Google Scholar]
- Maity, S.; Abdel-Mottaleb, M.; Asfour, S.S. Multimodal Biometrics Recognition from Facial Video via Deep Learning. Signal Image Process. Int. J. 2017, 8, 81–90. [Google Scholar]
- Shahroudy, A.; Ng, T.-T.; Gong, Y.; Wang, G. Deep Multimodal Feature Analysis for Action Recognition in RGB+D Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2016. [Google Scholar] [CrossRef] [PubMed]
- Frischholz, R.W.; Dieckmann, U. BiolD: A multimodal biometric identification system. Computer (Long Beach Calif.) 2000, 33, 64–68. [Google Scholar] [CrossRef]
- Ayodeji, O.; Mumtazah, S.; Ahmad, S.; Azizun, W.; Adnan, W. Integration of multiple soft biometrics for human identification. Pattern Recognit. Lett. 2015, 68, 278–287. [Google Scholar]
- Abreu, M.C.D.; Fairhurst, M. Enhancing Identity Prediction Using a Novel Approach to Combining Hard- and Soft-Biometric Information. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 41, 599–607. [Google Scholar] [CrossRef]
- Dantcheva, A.; Elia, P.; Ross, A. What Else Does Your Biometric Data Reveal? A Survey on Soft Biometrics. IEEE Trans. Inform. Forensics Secur. 2016, 11, 441–467. [Google Scholar] [CrossRef]
- Liu, A.A.; Xu, N.; Nie, W.Z.; Su, Y.T.; Wong, Y.; Kankanhalli, M. Benchmarking a Multimodal and Multiview and Interactive Dataset for Human Action Recognition. IEEE Trans. Cybern. 2017, 47, 1781–1794. [Google Scholar] [CrossRef] [PubMed]
- Al-Hmouz, R.; Daqrouq, K.; Morfeq, A.; Pedrycz, W. Multimodal biometrics using multiple feature representations to speaker identification system. In Proceedings of the 2015 International Conference on Information and Communication Technology Research (ICTRC), Abu Dhabi, UAE, 17–19 May 2015; pp. 314–317. [Google Scholar]
- Karczmarek, P.; Kiersztyn, A.; Pedrycz, W. Generalized Choquet Integral for Face Recognition. Int. J. Fuzzy Syst. 2017, 1–9. [Google Scholar] [CrossRef]
- Boucenna, S.; Cohen, D.; Meltzoff, A.N.; Gaussier, P.; Chetouani, M. Robots Learn to Recognize Individuals from Imitative Encounters with People and Avatars. Sci. Rep. 2016, 6, 19908. [Google Scholar] [CrossRef] [PubMed]
- Asada, M.; Hosoda, K.; Kuniyoshi, Y.; Ishiguro, H.; Inui, T.; Yoshikawa, Y.; Ogino, M.; Yoshida, C. Cognitive Developmental Robotics: A Survey. IEEE Trans. Auton. Ment. Dev. 2009, 1, 12–34. [Google Scholar] [CrossRef]
- Clemo, H.R.; Keniston, L.P.; Meredith, M.A. Structural Basis of Multisensory Processing. In The Neural Bases of Multisensory Processes; CRC Press: Boca Raton, FL, USA, 2011; pp. 3–14. [Google Scholar]
- Stein, B.E. The New Handbook of Multisensory Processes; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Romanski, L. Convergence of Auditory, Visual, and Somatosensory Information in Ventral Prefrontal Cortex. In The Neural Bases of Multisensory Processes; CRC Press: Boca Raton, FL, USA, 2011; pp. 667–682. [Google Scholar]
- Milner, A.D.; Goodale, M.A. The Visual Brain in Action, 2nd ed.; Oxford University Press: Oxford, NY, USA, 2006. [Google Scholar]
- Costanzo, L.S. Physiology, 2nd ed.; Saunders: Philadelphia, PA, USA, 2002. [Google Scholar]
- Halit, H.; de Haan, M.; Schyns, P.G.; Johnson, M.H. Is high-spatial frequency information used in the early stages of face detection? Brain Res. 2006, 1117, 154–161. [Google Scholar] [CrossRef] [PubMed]
- Goffaux, V.; Hault, B.; Michel, C.; Vuong, Q.C.; Rossion, B. The respective role of low and high spatial frequencies in supporting configural and featural processing of faces. Perception 2005, 34, 77–86. [Google Scholar] [CrossRef] [PubMed]
- Niculescu, A.; van Dijk, B.; Nijholt, A.; Limbu, D.K. Socializing with Olivia, the Youngest Robot Receptionist Outside the Lab. In International Conference on Social Robotics; Springer: Berlin/Heidelberg, Germany, 2010; pp. 50–62. [Google Scholar]
- Chellappa, R.; Wilson, C.L.; Sirohey, S. Human and machine recognition of faces: A survey. Proc. IEEE 1995, 83, 705–741. [Google Scholar] [CrossRef]
- Kauffmann, L.; Ramanoël, S.; Peyrin, C. The neural bases of spatial frequency processing during scene perception. Front. Integr. Neurosci. 2014, 8, 37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wallraven, C.; Schwaninger, A.; BÜlthoff, H.H. Learning from humans: Computational modeling of face recognition. Netw. Comput. Neural Syst. 2005, 16, 401–418. [Google Scholar] [CrossRef] [PubMed]
- Baltrusaitis, T.; Robinson, P.; Morency, L. OpenFace: An open source facial behavior analysis toolkit. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Rojas, M.M.; Masip, D.; Todorov, A.; Vitria, J. Automatic prediction of facial trait judgments: Appearance vs. structural models. PLoS ONE 2011, 6, e23323. [Google Scholar] [CrossRef] [PubMed]
- Tien, S.-C.; Chia, T.-L.; Lu, Y. Using cross-ratios to model curve data for aircraft recognition. Pattern Recognit. Lett. 2003, 24, 2047–2060. [Google Scholar] [CrossRef]
- Lei, G. Recognition of planar objects in 3-D space from single perspective views using cross ratio. IEEE Trans. Robot. Autom. 1990, 6, 432–437. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numerische Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Shen, L.; Bai, L. A review on Gabor wavelets for face recognition. Pattern Anal. Appl. 2006, 9, 273–292. [Google Scholar] [CrossRef]
- Serrano, Á.; de Diego, I.M.; Conde, C.; Cabello, E. Analysis of variance of Gabor filter banks parameters for optimal face recognition. Pattern Recognit. Lett. 2011, 32, 1998–2008. [Google Scholar] [CrossRef]
- Sung, J.; Bang, S.-Y.; Choi, S. A Bayesian network classifier and hierarchical Gabor features for handwritten numeral recognition. Pattern Recognit. Lett. 2006, 27, 66–75. [Google Scholar] [CrossRef]
- Daugman, J.G. Two-dimensional spectral analysis of cortical receptive field profiles. Vis. Res. 1980, 20, 847–856. [Google Scholar] [CrossRef]
- Shen, L.; Bai, L. MutualBoost learning for selecting Gabor features for face recognition. Pattern Recognit. Lett. 2006, 27, 1758–1767. [Google Scholar] [CrossRef]
- Zheng, D.; Zhao, Y.; Wang, J. Features Extraction Using a Gabor Filter Family. In Proceedings of the Sixth Lasted International Conference, Signal and Image Processing, Honolulu, HI, USA, 23–25 August 2004; pp. 139–144. [Google Scholar]
- Serrano, Á.; de Diego, I.M.; Conde, C.; Cabello, E. Recent advances in face biometrics with Gabor wavelets: A review. Pattern Recognit. Lett. 2010, 31, 372–381. [Google Scholar] [CrossRef]
- Miller, G.A. The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychol. Rev. 1956, 63, 81–97. [Google Scholar] [CrossRef] [PubMed]
- Kinnunen, T.; Li, H. An overview of text-independent speaker recognition: From features to supervectors. Speech Commun. 2010, 52, 12–40. [Google Scholar] [CrossRef]
- Burkitt, A.N. A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Branco, T.; Häusser, M. The single dendritic branch as a fundamental functional unit in the nervous system. Curr. Opin. Neurobiol. 2010, 20, 494–502. [Google Scholar] [CrossRef] [PubMed]
- London, M.; Häusser, M. Dendritic Computation. Annu. Rev. Neurosci. 2005, 28, 503–532. [Google Scholar] [CrossRef] [PubMed]
- Poirazi, P.; Brannon, T.; Mel, B.W. Pyramidal neuron as two-layer neural network. Neuron 2003, 37, 989–999. [Google Scholar] [CrossRef]
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition: A literature survey. ACM Comput. Surv. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Phillips, P.J.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Leonard, G.; Doddington, G. TIDIGITS LDC93S10. Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Barbosa, I.B.; Cristani, M.; del Bue, A.; Bazzani, L.; Murino, V. Re-identification with RGB-D sensors. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–10. [Google Scholar]
- Maass, W.; Natschlager, T.; Markram, H. A model for real-time computation in generic neural microcircuits. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; pp. 229–236. [Google Scholar]
- Bolle, R.M.; Connell, J.H.; Pankanti, S.; Ratha, N.K.; Senior, A.W. The relation between the ROC curve and the CMC. In Proceedings of the Fourth IEEE Workshop on Automatic Identification Advanced Technologies (AUTO ID 2005), Buffalo, NY, USA, 17–18 October 2005; Volume 2005, pp. 15–20. [Google Scholar]
- Jain, A.K.; Dass, S.C.; Nandakumar, K. Soft biometric traits for personal recognition systems. In Biometric Authentication; Springer: Berlin, Germany, 2004; pp. 731–738. [Google Scholar]
- Ailisto, H.; Vildjiounaite, E.; Lindholm, M.; Mäkelä, S.-M.; Peltola, J. Soft biometrics—Combining body weight and fat measurements with fingerprint biometrics. Pattern Recognit. Lett. 2006, 27, 325–334. [Google Scholar] [CrossRef]
- Zewail, R.; Elsafi, A.; Saeb, M.; Hamdy, N. Soft and hard biometrics fusion for improved identity verification. In Proceedings of the 2004 47th Midwest Symposium on Circuits and Systems, 2004 (MWSCAS ’04), Hiroshima, Japan, 25–28 July 2004; Volume 1, pp. 225–228. [Google Scholar]














| Approach | Biometric Modalities | Category | Accuracy | No. of Subjects |
|---|---|---|---|---|
| [62] | fingerprint (main) + gender, ethnicity, and height (auxiliary) | invasive | 90.2% | 160 |
| [11] | face and fingerprint(main) + gender, ethnicity, and height (auxiliary) | invasive | 95.5% | 263 |
| [63] | fingerprint and body weight | invasive | 96.1% | 62 |
| [64] | fingerprint and iris | invasive | 97.0% | 21 |
| [18] | face (main) + age and gender (auxiliary) | non-invasive | 97.67% | 79 |
| [18] | fingerprint (main) + age and gender (auxiliary) | invasive | 96.76% | 79 |
| [8] | skin color, hair color, eye color, weight, torso clothes color, legs clothes color, beard presence, moustache presence, glasses presence | non-invasive | not available | 646 |
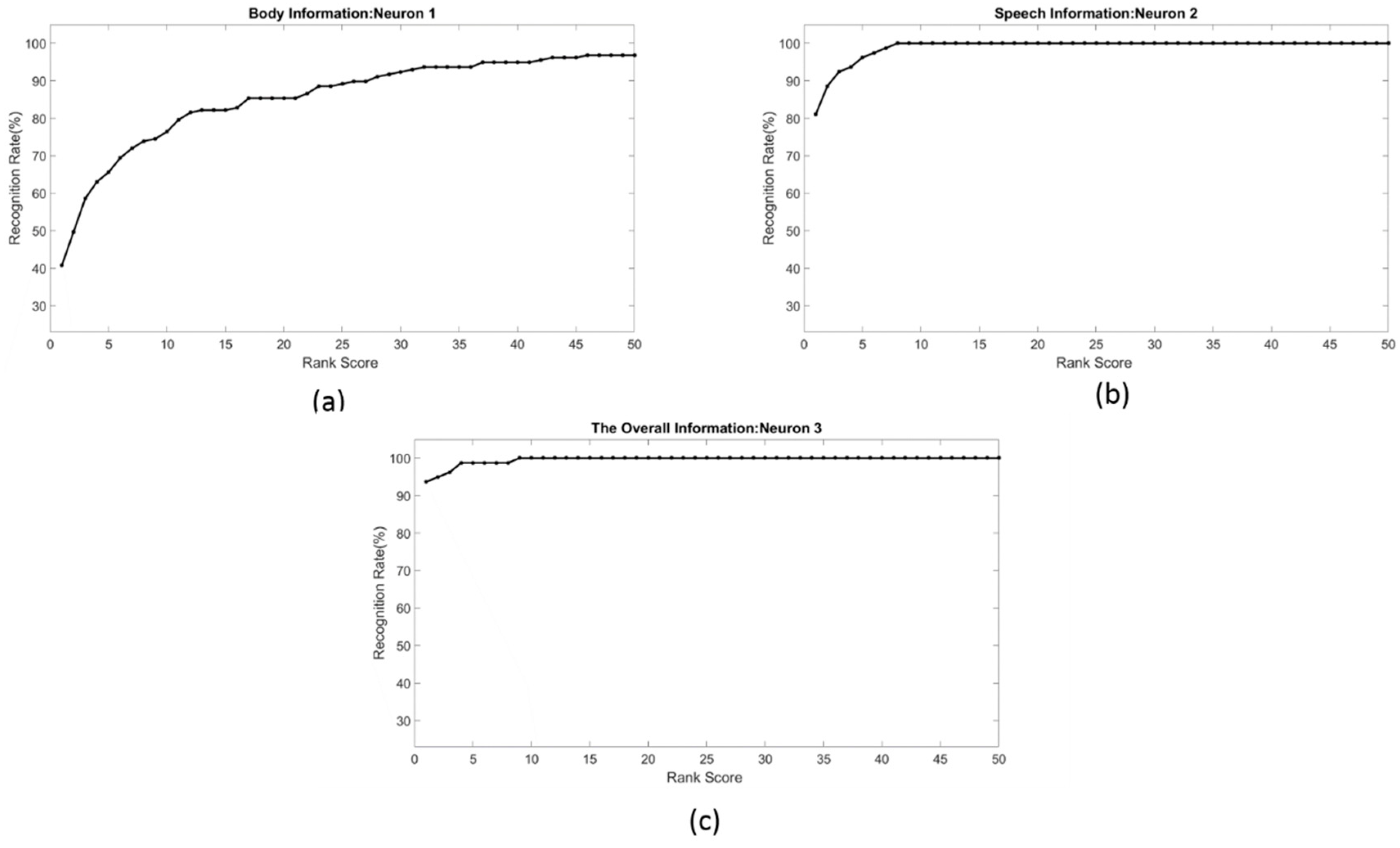
| our approach | face, body, speech, and skeleton | non-invasive | 100% (Figure 11c) | 79 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Qaderi, M.K.; Rad, A.B. A Multi-Modal Person Recognition System for Social Robots. Appl. Sci. 2018, 8, 387. https://doi.org/10.3390/app8030387
Al-Qaderi MK, Rad AB. A Multi-Modal Person Recognition System for Social Robots. Applied Sciences. 2018; 8(3):387. https://doi.org/10.3390/app8030387
Chicago/Turabian StyleAl-Qaderi, Mohammad K., and Ahmad B. Rad. 2018. "A Multi-Modal Person Recognition System for Social Robots" Applied Sciences 8, no. 3: 387. https://doi.org/10.3390/app8030387
APA StyleAl-Qaderi, M. K., & Rad, A. B. (2018). A Multi-Modal Person Recognition System for Social Robots. Applied Sciences, 8(3), 387. https://doi.org/10.3390/app8030387