A Novel Robust Audio Watermarking Algorithm by Modifying the Average Amplitude in Transform Domain

Abstract
:Featured Application
Abstract
1. Introduction
2. Related Works
3. Principle of the Watermarking Algorithm in Transform Domain
3.1. Principle of Watermark Embedding
3.2. Principle of Watermark Extracting
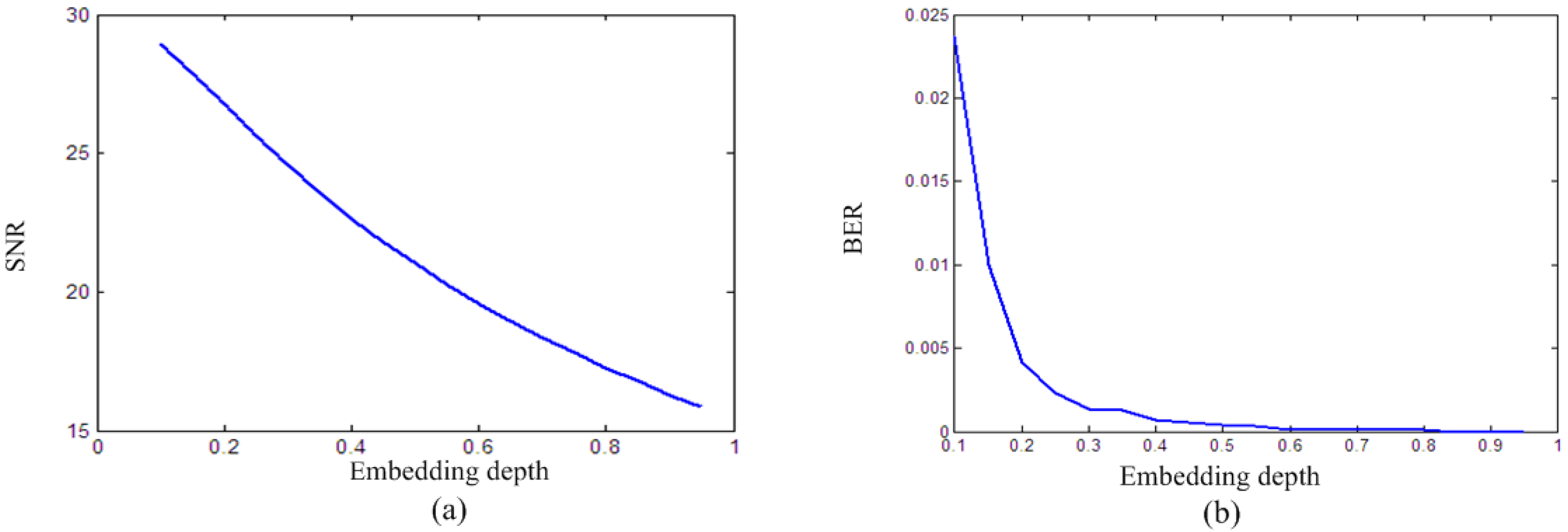
3.3. Impact of the Embedding Depth on Algorithm Performance
4. Implementation of the Proposed Algorithm
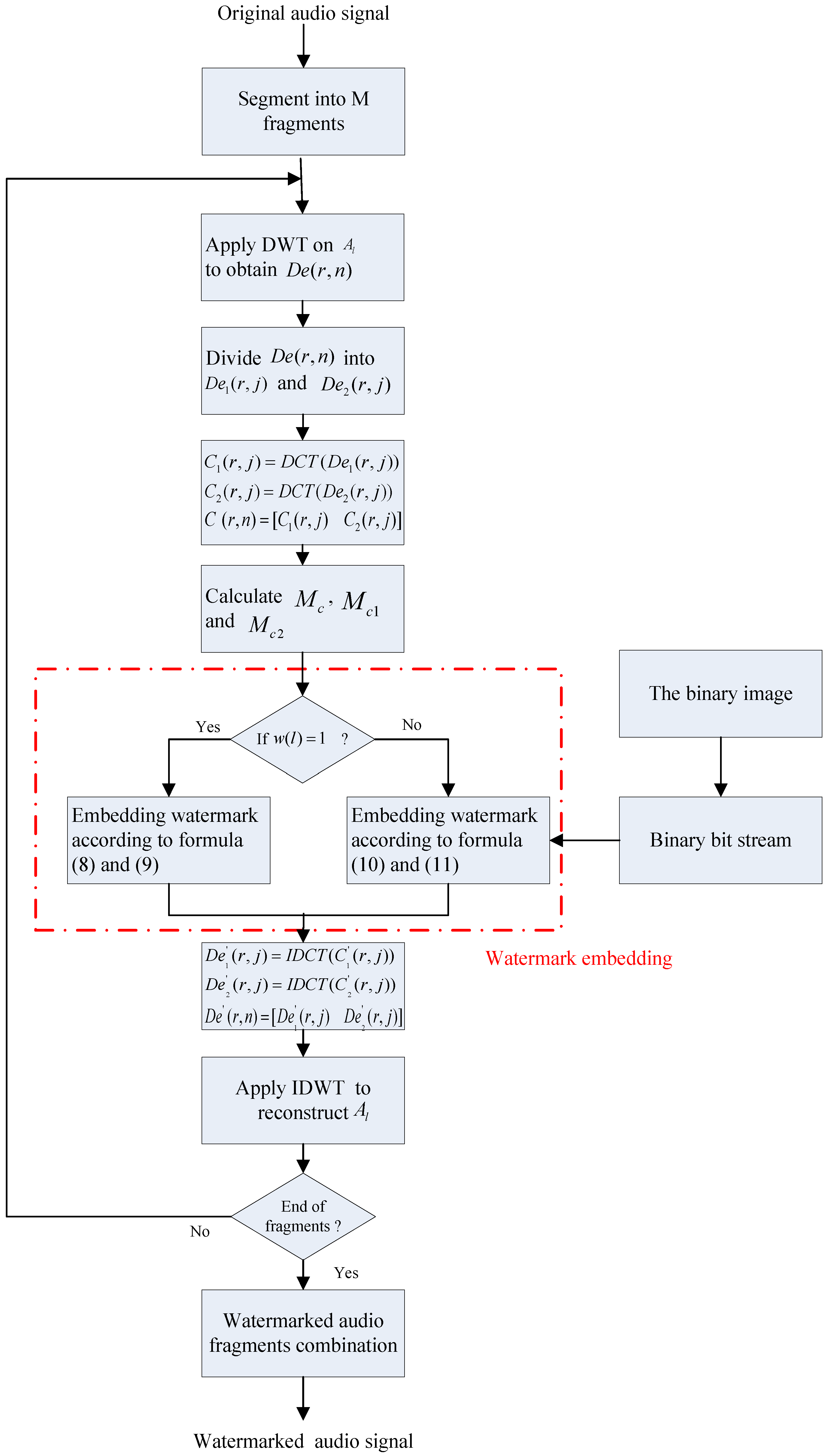
4.1. Procedure for Embedding Watermark
- Step 1:
- Convert the image watermark into the binary bit stream with the length of .
- Step 2:
- The carrier audio is divided into audio fragments () with the length of after low-pass filtering. is the number of the audio fragments, .
- Step 3:
- When changes from 1 to , perform the -level DWT on each fragment to obtain the wavelet coefficients, and select as the embedding frequency-band.
- Step 4:
- Divide into the former packet and the latter packet with the length of according to Formulas (3) and (4).
- Step 5:
- Perform DCT on and to obtain and respectively.
- Step 6:
- Connect and to form an array with the length of .
- Step 7:
- Calculate the average amplitude of , and according to Formulas (5)–(7).
- Step 8:
- If = 1, embed one-bit watermark into according to Formulas (8) and (9). If = 0, embed one-bit watermark into according to Formulas (10) and (11).
- Step 9:
- Perform the inverse DCT on and to obtain and .
- Step 10:
- Recombine and into and perform the inverse DWT to reconstruct the watermarked audio fragment .
- Step 11:
- Repeat Step 3 to Step 10 until all watermarks are embedded.
- Step 12:
- Recombine () as the watermarked audio signal .
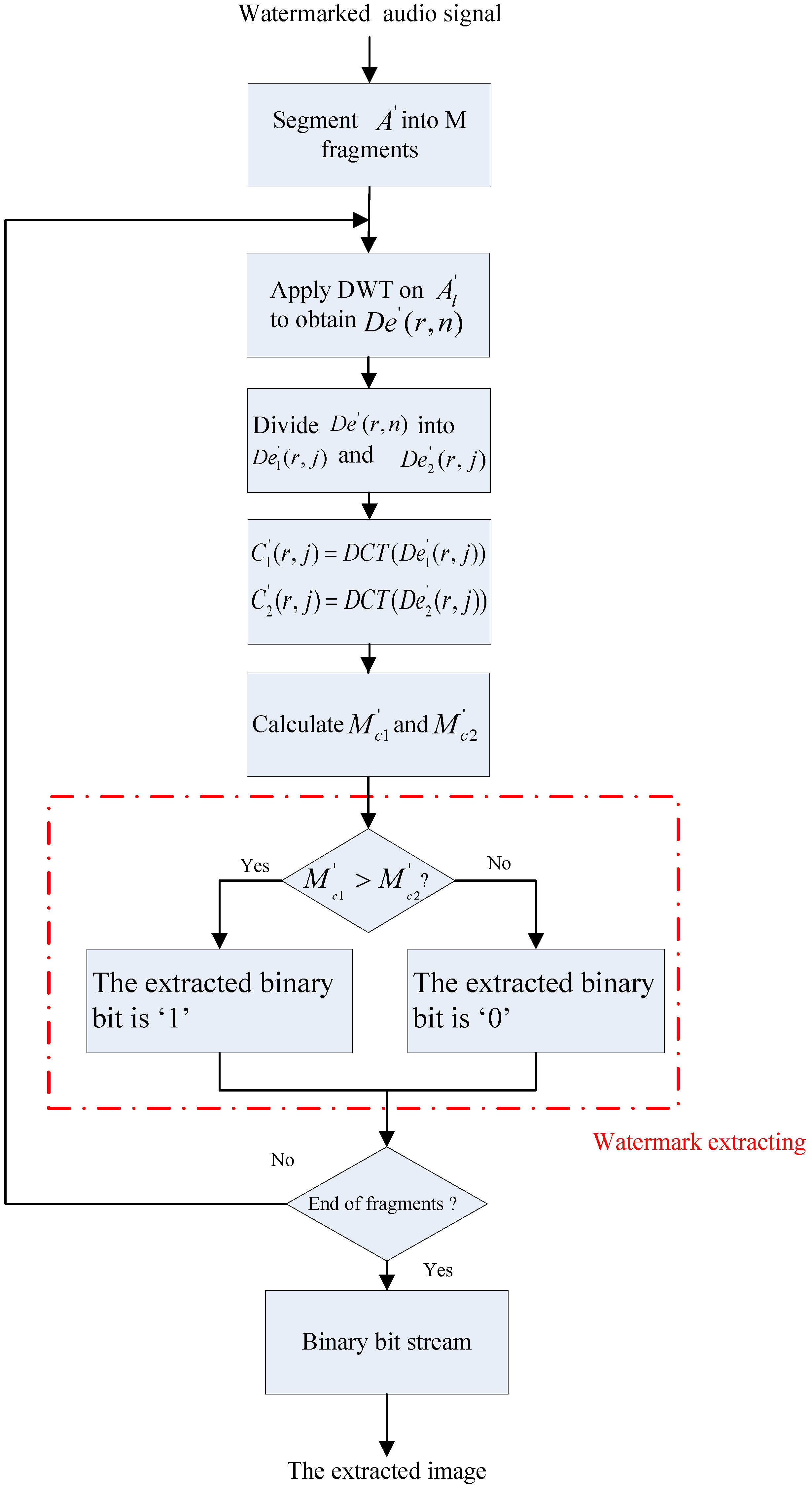
4.2. Procedure for Extracting Watermark
- Step 1:
- Segment the watermarked audio signal into audio fragments with the length of .
- Step 2:
- Perform -level DWT on to obtain the wavelet coefficients .
- Step 3:
- Divide into and with the length of .
- Step 4:
- Perform DCT on and to obtain and respectively.
- Step 5:
- Calculate the average amplitudes of and to obtain and according to Formulas (6) and (7).
- Step 6:
- If , the extracted binary information is ‘1’, otherwise, it is ‘0’.
- Step 7:
- Repeat Step 2 to Step 6 until all binary watermarks are extracted.
- Step 8:
- Convert the extracted binary stream into binary image watermark.
5. Performance Evaluation
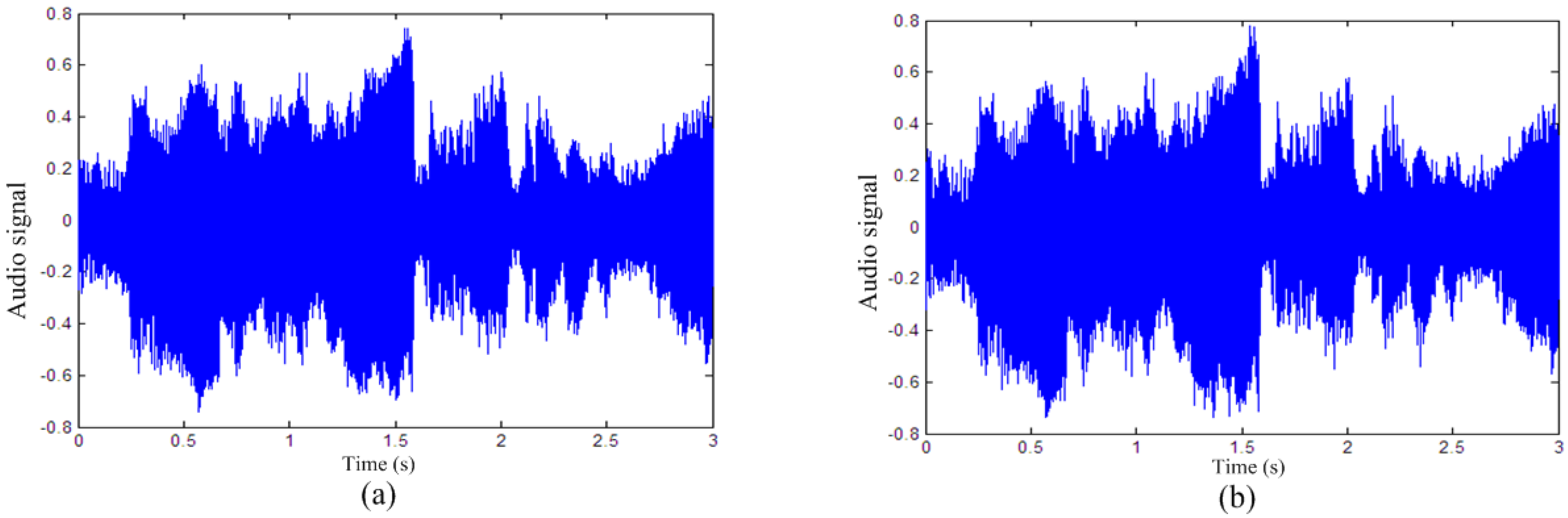
5.1. Imperceptibility and Payload Capacity
5.2. Robustness
- Low-pass filtering: applying low-pass filter with cutoff frequency of four kilohertz.
- Amplitude scaling: scaling the amplitude of the watermarked audio signal by 0.8.
- Amplitude scaling: scaling the amplitude of the watermarked audio signal by 1.2.
- Noise corruption: adding zero-mean Gaussian noise to the watermarked audio signal with 20 dB.
- Noise corruption: adding zero-mean Gaussian noise to the watermarked audio signal with 30 dB.
- Noise corruption: adding zero-mean Gaussian noise to the watermarked audio signal with 35 dB.
- MP3 compression: applying MP3 compression with 64 kbps to the watermarked audio signal.
- MP3 compression: applying MP3 compression with 128 kbps to the watermarked audio signal.
- Re-sampling: dropping the sampling rate of the watermarked audio signal from 44,100 Hz to 22,050 Hz and then rose back to 44,100 Hz.
- Re-quantization: quantizing the watermarked audio signal from 16-bit/sample to 8-bit/sample and then back to 16-bit/sample.
- Echo addition: adding an echo signal with a delay of 50 ms and a decay of five percent to the watermarked audio signal.
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Shiva, M.G.; D’Souza, R.J.; Varaprasad, G. Digital signature-based secure node disjoint multipath routing protocol for wireless sensor networks. IEEE Sens. J. 2012, 12, 2941–2949. [Google Scholar] [CrossRef]
- Kai, C.; Kuo, W.C. A new digital signature algorithm based on chaotic maps. Nonlinear Dyn. 2013, 74, 1003–1012. [Google Scholar]
- Zhou, X.; Zhang, H.; Wang, C.Y. A robust image watermarking technique based on DWT, APDCBT, and SVD. Symmetry 2018, 10, 77. [Google Scholar] [CrossRef]
- Wang, X.Y.; Shi, Q.L.; Wang, S.M.; Yang, H.Y. A blind robust digital watermarking using invariant exponent moments. Int. J. Electron. Commun. 2016, 70, 416–426. [Google Scholar] [CrossRef]
- Wang, C.Y.; Zhang, Y.P.; Zhou, X. Robust image watermarking algorithm based on ASIFT against geometric attacks. Appl. Sci. 2018, 8, 410. [Google Scholar] [CrossRef]
- Natgunanathan, I.; Xiang, Y.; Hua, G.; Beliakov, G.; Yearwood, J. Patchwork-Based multi-layer audio watermarking. IEEE Trans. Audio Speech Lang. Process. 2017, 25, 2176–2187. [Google Scholar] [CrossRef]
- Xiang, S.J.; Li, Z.H. Reversible audio data hiding algorithm using noncausal prediction of alterable orders. EURASIP J. Audio Speech Music Process. 2017, 4. [Google Scholar] [CrossRef]
- Hu, H.T.; Hsu, L.Y.; Chou, H.H. Variable-dimensional vector modulation for perceptual-based DWT blind audio watermarking with adjustable payload capacity. Digit. Signal Process. 2014, 31, 115–123. [Google Scholar] [CrossRef]
- Singh, D.; Singh, S.K. DWT-SVD and DCT based robust and blind watermarking scheme for copyright protection. Multimed. Tools Appl. 2017, 76, 13001–13024. [Google Scholar] [CrossRef]
- Lutovac, B.; Daković, M.; Stanković, S.; Orović, I. An algorithm for robust image watermarking based on the DCT and Zernike moments. Multimed. Tools Appl. 2017, 76, 23333–23352. [Google Scholar] [CrossRef]
- Shukla, D.; Sharma, M. A new approach for scene-based digital video watermarking using discrete wavelet transforms. Int. J. Adv. Appl. Sci. 2018, 5, 148–160. [Google Scholar] [CrossRef]
- Hu, H.T.; Chou, H.H.; Yu, C.; Hsu, L.Y. Incorporation of perceptually adaptive QIM with singular value decomposition for blind audio watermarking. EURASIP J. Adv. Signal Process. 2014, 12, 1–12. [Google Scholar] [CrossRef]
- Glowacz, A. DC Motor Fault Analysis with the Use of Acoustic Signals, Coiflet Wavelet Transform, and K-Nearest Neighbor Classifier. Arch. Acoust. 2015, 40, 321–327. [Google Scholar] [CrossRef]
- Li, Z.X.; Jiang, Y.; Hu, C.; Peng, Z. Recent progress on decoupling diagnosis of hybrid failures in gear transmission systems using vibration sensor signal: A review. Measurement 2016, 90, 4–19. [Google Scholar] [CrossRef]
- Glowacz, A. Diagnostics of Direct Current machine based on analysis of acoustic signals with the use of symlet wavelet transform and modified classifier based on words. Eksploat. Niezawodn. Maint. Reliab. 2014, 16, 554–558. [Google Scholar]
- Lei, W.N.; Chang, L.C. Robust and high-quality time-domain audio watermarking based on low-frequency amplitude modification. IEEE Trans. Multimed. 2006, 8, 46–59. [Google Scholar]
- Erfani, Y.; Siahpoush, S. Robust audio watermarking using improved TS echo hiding. Digit. Signal Process. 2009, 19, 809–814. [Google Scholar] [CrossRef]
- Basia, P.; Pitas, I.; Nikolaidis, N. Robust audio watermarking in the time domain. IEEE Trans. Multimed. 1998, 3, 232–241. [Google Scholar] [CrossRef]
- Kumsawat, P. A genetic algorithm optimization technique for multiwavelet-based digital audio watermarking. EURASIP J. Adv. Signal Process. 2010, 1, 1–10. [Google Scholar] [CrossRef]
- Natgunanathan, I.; Xiang, Y.; Rong, Y.; Peng, D. Robust patchwork-based watermarking method for stereo audio signals. Multimed Tools Appl. 2014, 72, 1387–1410. [Google Scholar] [CrossRef]
- Megias, D.; Serra-Ruiz, J.; Fallahpour, M. Efficient self-synchronized blind audio watermarking system based on time domain and FFT amplitude modification. Signal Process. 2010, 90, 3078–3092. [Google Scholar] [CrossRef]
- Tewari, T.K.; Saxena, V.; Gupta, J.P. A digital audio watermarking algorithm using selective mid band DCT coefficients and energy threshold. Int. J. Audio Technol. 2014, 17, 365–371. [Google Scholar]
- Hu, H.T.; Hsu, L.Y. Robust transparent and high capacity audio watermarking in DCT domain. Signal Process. 2015, 109, 226–235. [Google Scholar] [CrossRef]
- Li, W.; Xue, X.; Lu, P. Localized audio watermarking technique robust against time-scale modification. IEEE Trans. Multimed. 2006, 8, 60–90. [Google Scholar] [CrossRef]
- Chen, S.T.; Huang, H.N.; Chen, C.J.; Tseng, K.K.; Tu, S.Y. Adaptive audio watermarking via the optimization point of view on the wavelet-based entropy. Digit. Signal Process. 2013, 23, 971–980. [Google Scholar] [CrossRef]
- Wu, Q.L.; Wu, M. Novel Audio information hiding algorithm based on Wavelet Transform. J. Electron. Inf. Technol. 2016, 38, 834–840. [Google Scholar]
- Wu, S.; Huang, J.; Huang, D.; Shi, Y.Q. Efficiently self-synchronized audio watermarking for assured audio data transmission. IEEE Trans. Broadcast. 2005, 51, 69–76. [Google Scholar] [CrossRef]
- Chen, S.T.; Wu, G.D.; Huang, H.N. Wavelet-domain audio watermarking algorithm using optimisation-based quantisation. IET Signal Process. 2010, 4, 720–727. [Google Scholar] [CrossRef]
- Abd, F.; Samie, E. An efficient singular value decomposition algorithm for digital audio watermarking. Int. J. Audio Technol. 2009, 12, 27–45. [Google Scholar]
- Asmara, R.A.; Agustina, R.; Hidayatulloh. Comparison of Discrete Cosine Transforms (DCT), Discrete Fourier Transforms (DFT), and Discrete Wavelet Transforms (DWT) in Digital Image Watermarking. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 245–249. [Google Scholar]
- Wang, X.; Qi, W.; Liu, P. A new adaptive digital audio watermarking based on support vector regression. J. Netw. Comput. Appl. 2008, 31, 735–749. [Google Scholar] [CrossRef]
- Wang, X.Y.; Zhao, H. A novel synchronization invariant audio watermarking algorithm based on DWT and DCT. IEEE Trans. Signal Process. 2006, 54, 4835–4840. [Google Scholar] [CrossRef]
- Vivekananda, B.K.; Sengupta, I.; Das, A. An adaptive audio watermarking based on the singular value decomposition in the wavelet domain. Digit. Signal Process. 2010, 20, 1547–1558. [Google Scholar]
- Dhar, P.K.; Shimamure, T. Blind audio watermarking in transform domain based on singular value decomposition and exponential-log operations. Radioengineering 2017, 26, 552–561. [Google Scholar] [CrossRef]
- Lei, B.Y.; Soon, I.Y.; Li, Z. Blind and robust audio watermarking algorithm based on SVD-DCT. Signal Process. 2011, 91, 1973–1984. [Google Scholar] [CrossRef]
- Vivekananda, B.K.; Sengupta, I.; Das, A. A new audio watermarking scheme based on singular value decomposition and quantization. Circuits Syst. Signal Process. 2011, 30, 915–927. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Proposed | Paper [4] | Paper [16] | Paper [25] | Paper [12] | Paper [19] |
|---|---|---|---|---|---|---|
| SNR (dB) | 23.49 | N/A | 21.37 | 18.42 | 20.32 | 26.79 |
| Capacity(bps) | 172.27 | 125 | 43.07 | 172.27 | 139.97 | 34.14 |
| NC | 1 | N/A | N/A | N/A | N/A | 1 |
| BER (%) | 0.00 | 0.00 | N/A | N/A | 0.12 | 0.00 |
| Attack | Proposed | Paper [4] | Paper [16] | Paper [25] | Paper [12] | Paper [19] |
|---|---|---|---|---|---|---|
| A | 0.01 | 0.39 | 21.97 | 28.25 | 0.12 | 6.93 |
| B | 0.01 | 2.87 | 0.50 | 0.30 | 0.12 | N/A |
| C | 0.01 | 17.92 | 0.47 | 0.35 | N/A | N/A |
| D | 2.27 | N/A | N/A | N/A | 1.29 | N/A |
| E | 0.22 | N/A | N/A | N/A | 0.31 | N/A |
| F | 0.07 | 0.78 | N/A | N/A | N/A | 0.00 |
| G | 0.08 | 1.95 | 2.45 | 6.85 | 0.12 | 0.00 |
| H | 0.01 | N/A | 1.12 | 4.97 | 1.61 | 0.00 |
| I | 0.01 | 0.00 | 1.00 | 6.45 | 0.12 | 0.00 |
| J | 0.14 | 0.78 | N/A | N/A | 0.12 | 0.00 |
| K | 0.01 | N/A | N/A | N/A | 0.84 | N/A |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Q.; Wu, M. A Novel Robust Audio Watermarking Algorithm by Modifying the Average Amplitude in Transform Domain. Appl. Sci. 2018, 8, 723. https://doi.org/10.3390/app8050723
Wu Q, Wu M. A Novel Robust Audio Watermarking Algorithm by Modifying the Average Amplitude in Transform Domain. Applied Sciences. 2018; 8(5):723. https://doi.org/10.3390/app8050723
Chicago/Turabian StyleWu, Qiuling, and Meng Wu. 2018. "A Novel Robust Audio Watermarking Algorithm by Modifying the Average Amplitude in Transform Domain" Applied Sciences 8, no. 5: 723. https://doi.org/10.3390/app8050723
APA StyleWu, Q., & Wu, M. (2018). A Novel Robust Audio Watermarking Algorithm by Modifying the Average Amplitude in Transform Domain. Applied Sciences, 8(5), 723. https://doi.org/10.3390/app8050723