Learning Frameworks for Cooperative Spectrum Sensing and Energy-Efficient Data Protection in Cognitive Radio Networks


Abstract
:1. Introduction
1.1. Motivation
1.2. Contributions
- We first introduce a new energy harvesting model, which is represented by a transformed Poisson distribution proven to give the nearest fit to the empirical measurements of a solar energy harvesting node for time-slotted operation [25].
- We also introduce a new CNN-based technique for cooperative spectrum sensing to enhance the performance of spectrum sensing by increasing the probability of detection while guaranteeing a low probability of false alarm.
- We then formulate the stochastic problem of the data encryption decision policy as the framework of a constrained MDP, and solve the problem by using the transfer learning actor–critic algorithm.
2. System Model
- if bits,
- if bits,
- if bits.
3. Energy Harvesting Model
4. Convolutional Neural Network-Based Cooperative Spectrum Sensing
- The FC trains the CNN using historical sensing data represented by the local spectrum decisions provided by the SUs.
- At the beginning of each time slot, all the SUs are required to perform local spectrum sensing by using an energy detection method and reporting their sensing outcomes to the FC via a control channel.
- The FC uses the new sensing data as input for the trained CNN to make a global decision about the PU state on the channel of interest, and then feeds back the final decision to the SUs.
4.1. Local Spectrum Sensing
4.2. Convolutional Neural Network-Based Cooperative Spectrum Sensing
4.2.1. Network Configuration
- The input layer stores the input sensing data in the form of a gray scale image with size , where K is the number of secondary users.
- The convolutional (CONV2D) layer contains K neurons (filters) that connect to the local subregions of the input image to learn its features by scanning through it. In this work, each region has a size of .
- The rectified linear unit (ReLU) layer uses the ReLU function to introduce nonlinearity to the CNN by performing a threshold operation on each input element, simply defined as
- The fully connected layer combines all the local information from the original image (e.g., the results of feature extraction) determined in the previous layers to classify the status of the PU, which is active or inactive . Consequently, the size of the output data is equal to the number of states of the primary user.
- The softmax and output layers follow right after the fully connected layer for the classification problem. The softmax layer uses an output unit activation function, also known as a normalized exponential function, to create a categorical probability distribution for the two input elements (A and ), as follows:where is the class prior probability; is an element class; and is the output value from previous layer of the sample given class . Thereafter, the output (or classification) layer takes the values from the softmax function and assigns each input to one of the two classes.
4.2.2. Network Training and PU Status Prediction
5. Transfer Learning Actor–Critic Framework for Data Protection in Cognitive Radio Networks
5.1. Markov Decision Process
- R = 0 if the SU stays idle, or the transmission is not successful.
- R = 10 if the transmission is successful, and the data are encrypted by AES-128.
- R = 12 if the transmission is successful, and the data are encrypted by AES-192.
- R = 14 if the transmission is successful, and the data are encrypted by AES-256.
5.2. Transfer Learning Actor–Critic Algorithm
5.2.1. Case 1
5.2.2. Case 2
- (1)
- The SU decides to stay idle to save energy for the next time slot.
- (2)
- The SU transmits encrypted information to the fusion center.
- if
- if
- if
6. Results and Discussion
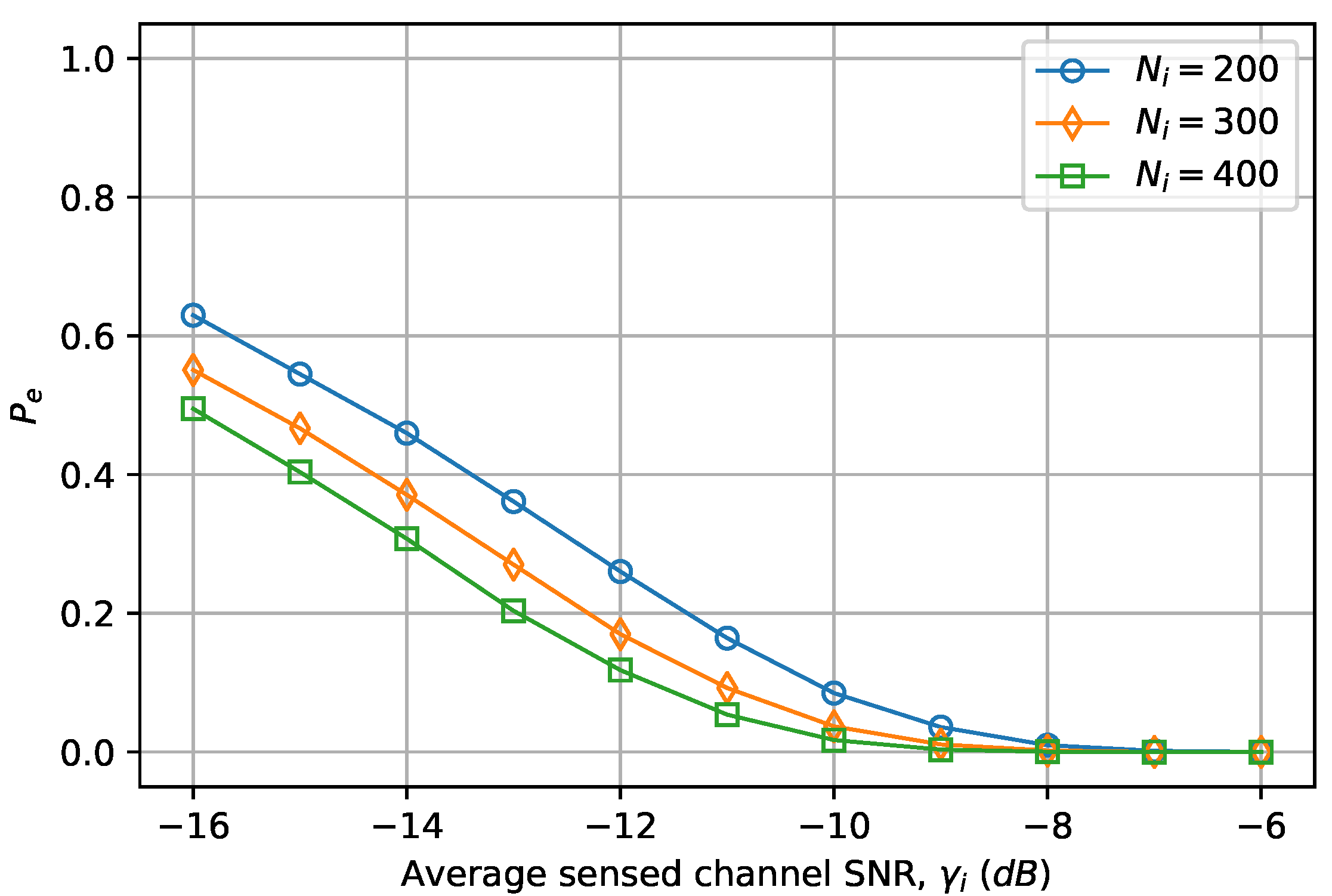
6.1. Convolutional Neural Network-Based Cooperative Spectrum Sensing
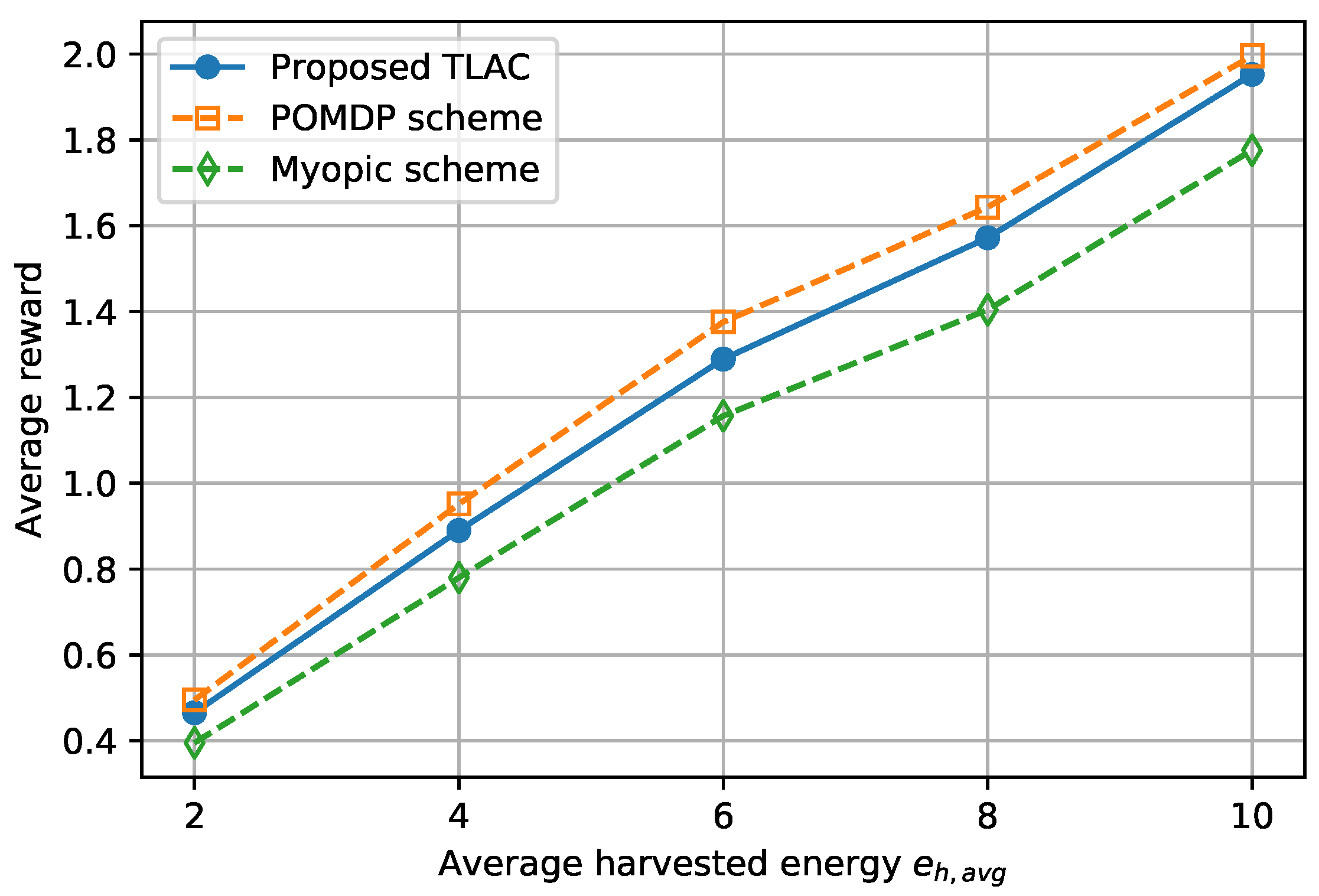
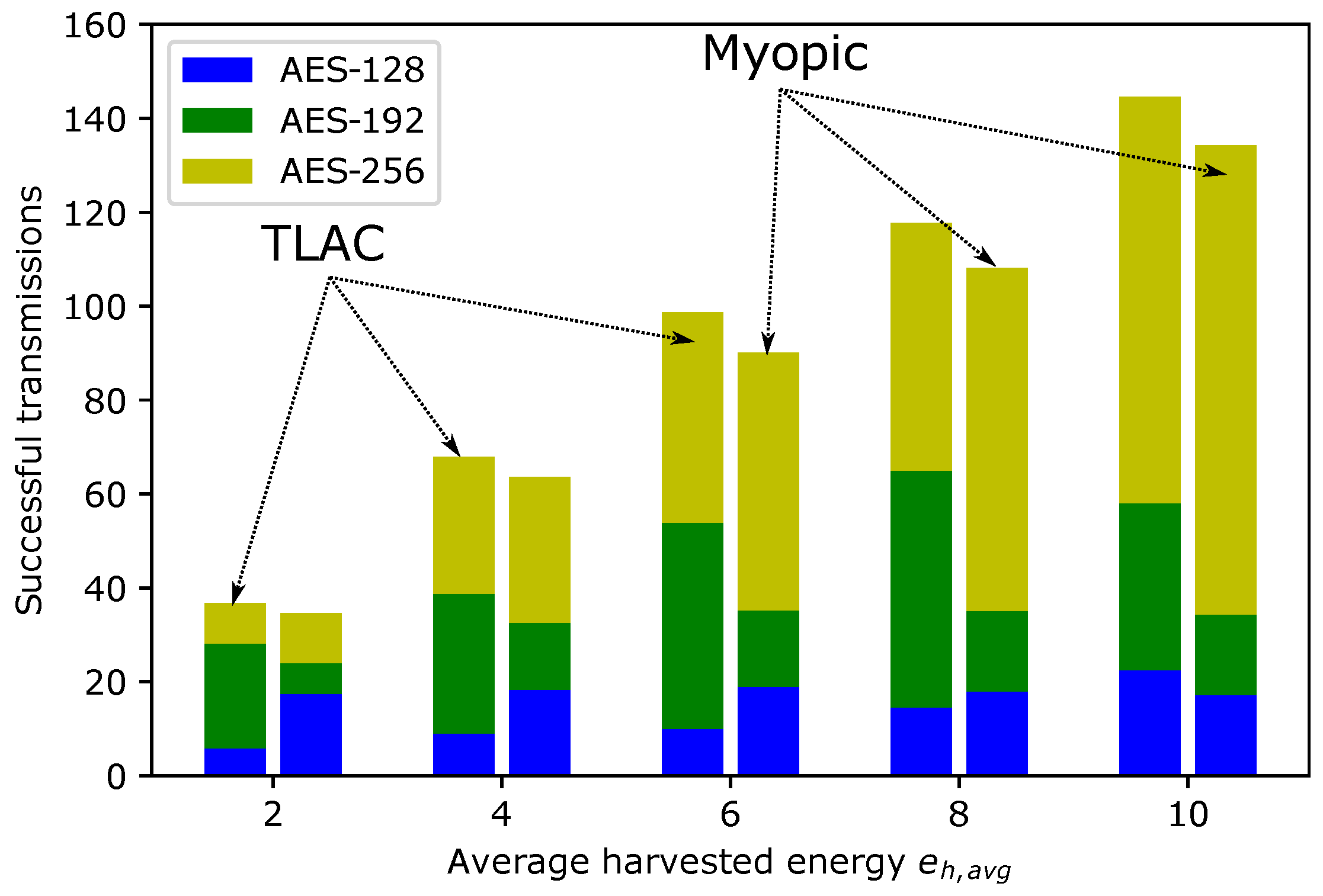
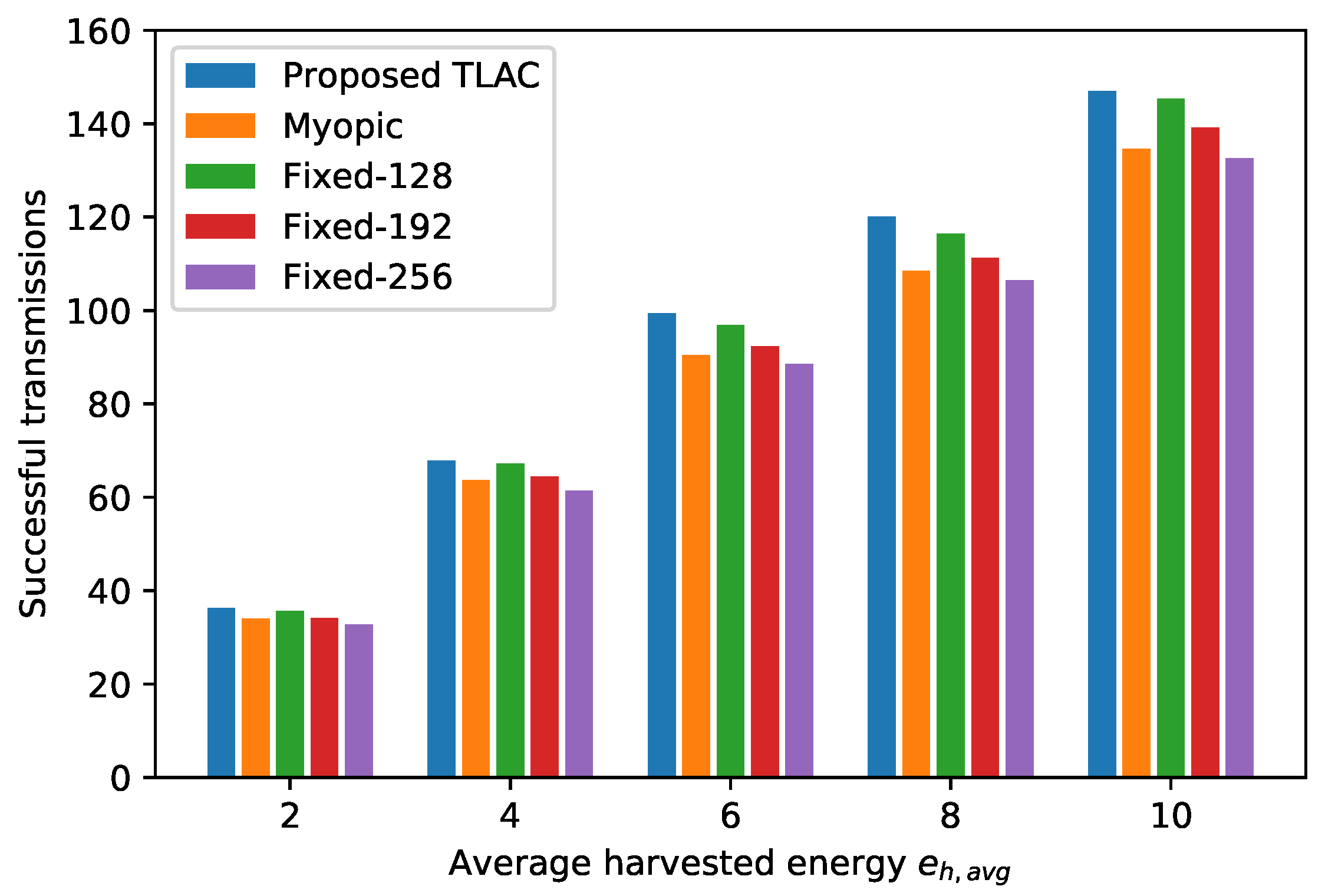
6.2. Transfer Learning Actor–Critic Solution for Energy-Efficient Data Protection Scheme
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Joshi, G.; Nam, S.; Kim, S. Cognitive Radio Wireless Sensor Networks: Applications, Challenges and Research Trends. Sensors 2013, 13, 11196–11228. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Hong, D. Optimal Spectrum Access for Energy Harvesting Cognitive Radio Networks. IEEE Trans. Wirel. Commun. 2013, 12, 6166–6179. [Google Scholar] [CrossRef]
- Park, S.; Kim, H.; Hong, D. Cognitive radio networks with energy harvesting. IEEE Trans. Wirel. Commun. 2013, 12, 1386–1397. [Google Scholar] [CrossRef]
- Pappas, N.; Jeon, J.; Ephremides, A.; Traganitis, A. Optimal utilization of a cognitive shared channel with a rechargeable primary source node. J. Commun. Netw. 2012, 14, 162–168. [Google Scholar] [CrossRef]
- Sultan, A. Sensing and Transmit Energy Optimization for an Energy Harvesting Cognitive Radio. IEEE Wirel. Commun. Lett. 2012, 1, 500–503. [Google Scholar] [CrossRef]
- Razaque, A.; Elleithy, K.M. Energy-Efficient Boarder Node Medium Access Control Protocol for Wireless Sensor Networks. Sensors 2014, 14, 5074–5117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, Y.-C.; Zeng, Y.; Peh, E.; Huang, A.T. Sensing-Throughput Tradeoff for Cognitive Radio Networks. IEEE Trans. Wirel. Commun. 2008, 7, 1326–1337. [Google Scholar] [CrossRef]
- Lee, S.; Zhang, R.; Huang, K. Opportunistic Wireless Energy Harvesting in Cognitive Radio Networks. IEEE Trans. Wirel. Commun. 2013, 12, 4788–4799. [Google Scholar] [CrossRef]
- Rossi, P.S.; Ciuonzo, D.; Romano, G. Orthogonality and Cooperation in Collaborative Spectrum Sensing through MIMO Decision Fusion. IEEE Trans. Wirel. Commun. 2013, 12, 5826–5836. [Google Scholar] [CrossRef]
- Holcomb, S.; Rawat, D.B. Recent security issues on cognitive radio networks: A survey. In Proceedings of the IEEE SoutheastCon 2016, Norfolk, VA, USA, 30 March–3 April 2016; pp. 1–6. [Google Scholar]
- Fragkiadakis, A.G.; Tragos, E.Z.; Askoxylakis, I.G. A Survey on Security Threats and Detection Techniques in Cognitive Radio Networks. IEEE Commun. Surv. Tutor. 2013, 15, 428–445. [Google Scholar] [CrossRef]
- Wen, H.; Li, S.; Zhu, X.; Zhou, L. A framework of the PHY-layer approach to defense against security threats in cognitive radio networks. IEEE Netw. 2013, 27, 34–39. [Google Scholar]
- Ciuonzo, D.; Aubry, A.; Carotenuto, V. Rician MIMO Channel- and Jamming-Aware Decision Fusion. IEEE Trans. Signal Process. 2017, 65, 3866–3880. [Google Scholar] [CrossRef]
- Xu, X.; He, B.; Yang, W.; Zhou, X.; Cai, Y. Secure Transmission Design for Cognitive Radio Networks with Poisson Distributed Eavesdroppers. IEEE Trans. Inf. Forensics Secur. 2016, 11, 373–387. [Google Scholar] [CrossRef]
- Elkashlan, M.; Wang, L.; Duong, T.Q.; Karagiannidis, G.K.; Nallanathan, A. On the Security of Cognitive Radio Networks. IEEE Trans. Veh. Technol. 2015, 64, 3790–3795. [Google Scholar] [CrossRef]
- Wang, B.; Zhan, Y.; Zhang, Z. Cryptanalysis of a Symmetric Fully Homomorphic Encryption Scheme. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1460–1467. [Google Scholar] [CrossRef]
- Sultan, A.; Yang, X.; Hajomer, A.A.; Hu, W. Chaotic Constellation Mapping for Physical-Layer Data Encryption in OFDM-PON. IEEE Photonics Technol. Lett. 2018, 30, 339–342. [Google Scholar] [CrossRef]
- Angizi, S.; He, Z.; Bagherzadeh, N.; Fan, D. Design and Evaluation of a Spintronic In-Memory Processing Platform for Non-Volatile Data Encryption. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2017. [Google Scholar] [CrossRef]
- Sen, J. A Survey on Security and Privacy Protocols for Cognitive Wireless Sensor Networks. J. Netw. Inf. Secur. 2013, 1, 1–43. [Google Scholar]
- Do-Vinh, Q.; Hoan, T.N.K.; Koo, I. Energy-Efficient Data Encryption Scheme for Cognitive Radio Networks. IEEE Sens. J. 2018, 18, 2050–2059. [Google Scholar] [CrossRef]
- NIST Standards. Advanced Encryption Standard (AES); NIST Standards: Gaithersburg, MD, USA, 2001.
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; The MIT Press: London, UK, 1998; p. 331. [Google Scholar]
- Berenji, H.; Vengerov, D. A convergent actor–critic-based FRL algorithm with application to power management of wireless transmitters. IEEE Trans. Fuzzy Syst. 2003, 11, 478–485. [Google Scholar] [CrossRef]
- Taylor, M.E.; Stone, P. Transfer Learning for Reinforcement Learning Domains: A Survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Lee, P.; Eu, Z.A.; Han, M.; Tan, H.P. Empirical modeling of a solar-powered energy harvesting wireless sensor node for time-slotted operation. In Proceedings of the 2011 IEEE Wireless Communications and Networking Conference, Cancun, Mexico, 28–31 March 2011; pp. 179–184. [Google Scholar]
- Zhang, S.; Wang, H.; Zhang, X. Estimation of channel state transition probabilities based on Markov Chains in cognitive radio. J. Commun. 2014, 9, 468–474. [Google Scholar] [CrossRef]
- Kim, J.M.; Lee, H.S.; Yi, J.; Park, M. Power Adaptive Data Encryption for Energy-Efficient and Secure Communication in Solar-Powered Wireless Sensor Networks. J. Sens. 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Othman, S.B. Performance evaluation of encryption algorithm for wireless sensor networks. In Proceedings of the 2012 International Conference on Information Technology and e-Services (ICITeS), Sousse, Tunisia, 24–26 March 2012; pp. 1–8. [Google Scholar]
- Medepally, B.; Mehta, N.B.; Murthy, C.R. Implications of Energy Profile and Storage on Energy Harvesting Sensor Link Performance. In Proceedings of the GLOBECOM 2009—2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar]
- Ho, C.K.; Zhang, R. Optimal Energy Allocation for Wireless Communications with Energy Harvesting Constraints. IEEE Trans. Signal Process. 2012, 60, 4808–4818. [Google Scholar] [CrossRef]
- Tarighati, A.; Gross, J.; Jalden, J. Decentralized Hypothesis Testing in Energy Harvesting Wireless Sensor Networks. IEEE Trans. Signal Process. 2017, 65, 4862–4873. [Google Scholar] [CrossRef]
- Zhang, W.; Mallik, R.; Letaief, K. Optimization of cooperative spectrum sensing with energy detection in cognitive radio networks. IEEE Trans. Wirel. Commun. 2009, 8, 5761–5766. [Google Scholar] [CrossRef]
- Atapattu, S.; Tellambura, C.; Jiang, H. Conventional Energy Detector. In Energy Detection for Spectrum Sensing in Cognitive Radio, 1st ed.; Springer: New York, NY, USA, 2014; Chapter 2; pp. 11–26. [Google Scholar]
- Quan, Z.; Cui, S.; Sayed, A.H. Optimal Linear Cooperation for Spectrum Sensing in Cognitive Radio Networks. IEEE J. Sel. Top. Signal Process. 2008, 2, 28–40. [Google Scholar] [CrossRef]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017; p. 318. [Google Scholar]
- Stone, J.V. Bayes’ Rule: A Tutorial Introduction to Bayesian Analysis, 2013 ed.; Sebtel Press: Sheffield, UK, 2013; p. 174. [Google Scholar]
- Singh, S.; Jaakkola, T.; Littman, M.L.; Szepesvári, C. Convergence results for single-step on-policy reinforcement-learning algorithms. Mach. Learn. 2000, 38, 287–308. [Google Scholar] [CrossRef]
- Teguig, D.; Scheers, B.; Nir, V.L. Data fusion schemes for cooperative spectrum sensing in cognitive radio networks. In Proceedings of the 2012 Military Communications and Information Systems Conference (MCC), Gdansk, Poland, 8–9 October 2012; pp. 1–7. [Google Scholar]
- Vu-Van, H.; Koo, I. Cooperative spectrum sensing with collaborative users using individual sensing credibility for cognitive radio network. IEEE Trans. Consum. Electron. 2011, 57, 320–326. [Google Scholar] [CrossRef]
- Li, L.C.; Wang, J.; Li, S. An Adaptive Cooperative Spectrum Sensing Scheme Based on the Optimal Data Fusion Rule. In Proceedings of the 4th International Symposium on Wireless Communication Systems, Trondheim, Norway, 17–19 October 2007; pp. 582–586. [Google Scholar]
- Zhao, Q.; Krishnamachari, B.; Liu, K. On myopic sensing for multi-channel opportunistic access: Structure, optimality, and performance. IEEE Trans. Wirel. Commun. 2008, 7, 5431–5440. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Primary user (PU) signal at time step t | |
| , | The received signal and additive white Gaussian noise at the ith secondary user (SU) at time step t |
| Mean | |
| Variance | |
| Average gain of the sensed channel at the ith SU | |
| Battery capacity of the SU | |
| The energy consumption for spectrum sensing process | |
| The remaining energy, harvested energy, transmit energy of the SU respectively | |
| The key length of the encryption method | |
| The security level corresponding with the key length | |
| The system probabilities of detection and false alarm | |
| Markov decision process (MDP) Tuple: State space , Action space , Transition probability function , and Reward function | |
| The belief that the PU is inactive in a time slot | |
| Discount factor | |
| State-value function | |
| Policy function | |
| The actor and the critic step-size parameters | |
| Temporal difference (TD) error |
| Symbol | Description | Value |
|---|---|---|
| K | The number of secondary users | 10 |
| The number of sensing samples collected by each secondary user | 300 | |
| Average signal-to-noise ratio (SNR) of the sensed channel that was used for training the CNN (dB) | −16 to −6 | |
| , | Probability of the primary user’s state transition from A to , and vice versa | 0.2 |
| Symbol | Description | Value |
|---|---|---|
| Average SNR of the sensed channel (dB) | −10 | |
| , | Transition probabilities between states (A and ) of the primary user | 0.2 |
| Battery capacity (packets) | 160 | |
| Energy consumption for the whole spectrum sensing process (packets) | 1 | |
| Energy consumption for data encryption using the Advanced Encryption Standard (AES) algorithm with key length (packets) | ||
| Average harvested energy (packets) | ||
| Average energy consumption for data transmission (packets) | 40 | |
| Discount factor | 0.9 | |
| Critic learning rate | 0.2 | |
| Actor learning rate | 0.1 | |
| Initial transfer rate | 0.5 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Do, V.Q.; Koo, I. Learning Frameworks for Cooperative Spectrum Sensing and Energy-Efficient Data Protection in Cognitive Radio Networks. Appl. Sci. 2018, 8, 722. https://doi.org/10.3390/app8050722
Do VQ, Koo I. Learning Frameworks for Cooperative Spectrum Sensing and Energy-Efficient Data Protection in Cognitive Radio Networks. Applied Sciences. 2018; 8(5):722. https://doi.org/10.3390/app8050722
Chicago/Turabian StyleDo, Vinh Quang, and Insoo Koo. 2018. "Learning Frameworks for Cooperative Spectrum Sensing and Energy-Efficient Data Protection in Cognitive Radio Networks" Applied Sciences 8, no. 5: 722. https://doi.org/10.3390/app8050722
APA StyleDo, V. Q., & Koo, I. (2018). Learning Frameworks for Cooperative Spectrum Sensing and Energy-Efficient Data Protection in Cognitive Radio Networks. Applied Sciences, 8(5), 722. https://doi.org/10.3390/app8050722