Learning Behavior Trees for Autonomous Agents with Hybrid Constraints Evolution


Abstract
:Featured Application
Abstract
1. Introduction
2. Background and Related Works
2.1. Behavior Trees
2.2. Genetic Programming
2.3. Agent Behavior Modeling and Evolving Behavior Trees
3. Methodology
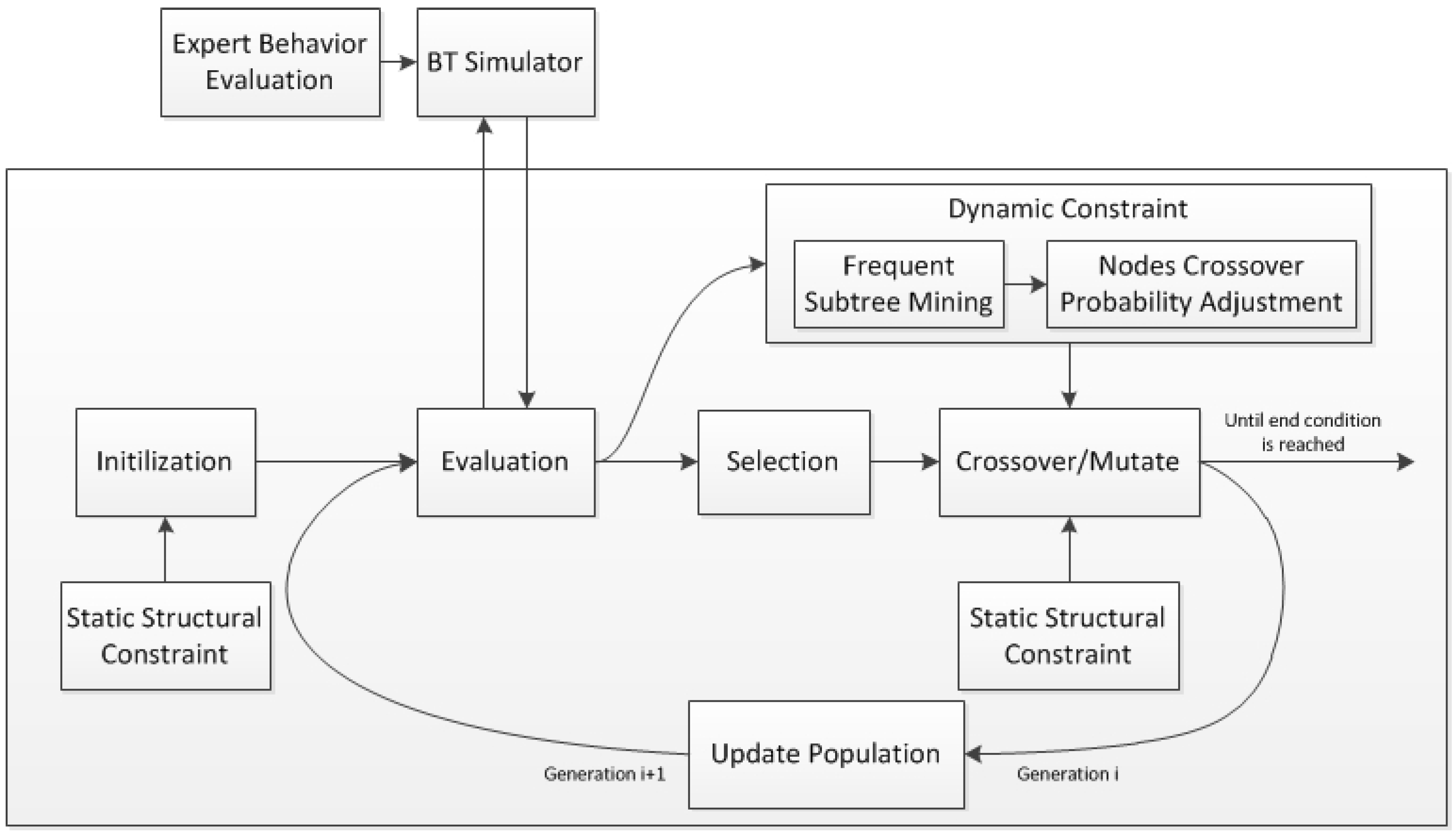
3.1. The Proposed Evolving Behavior Trees Framework
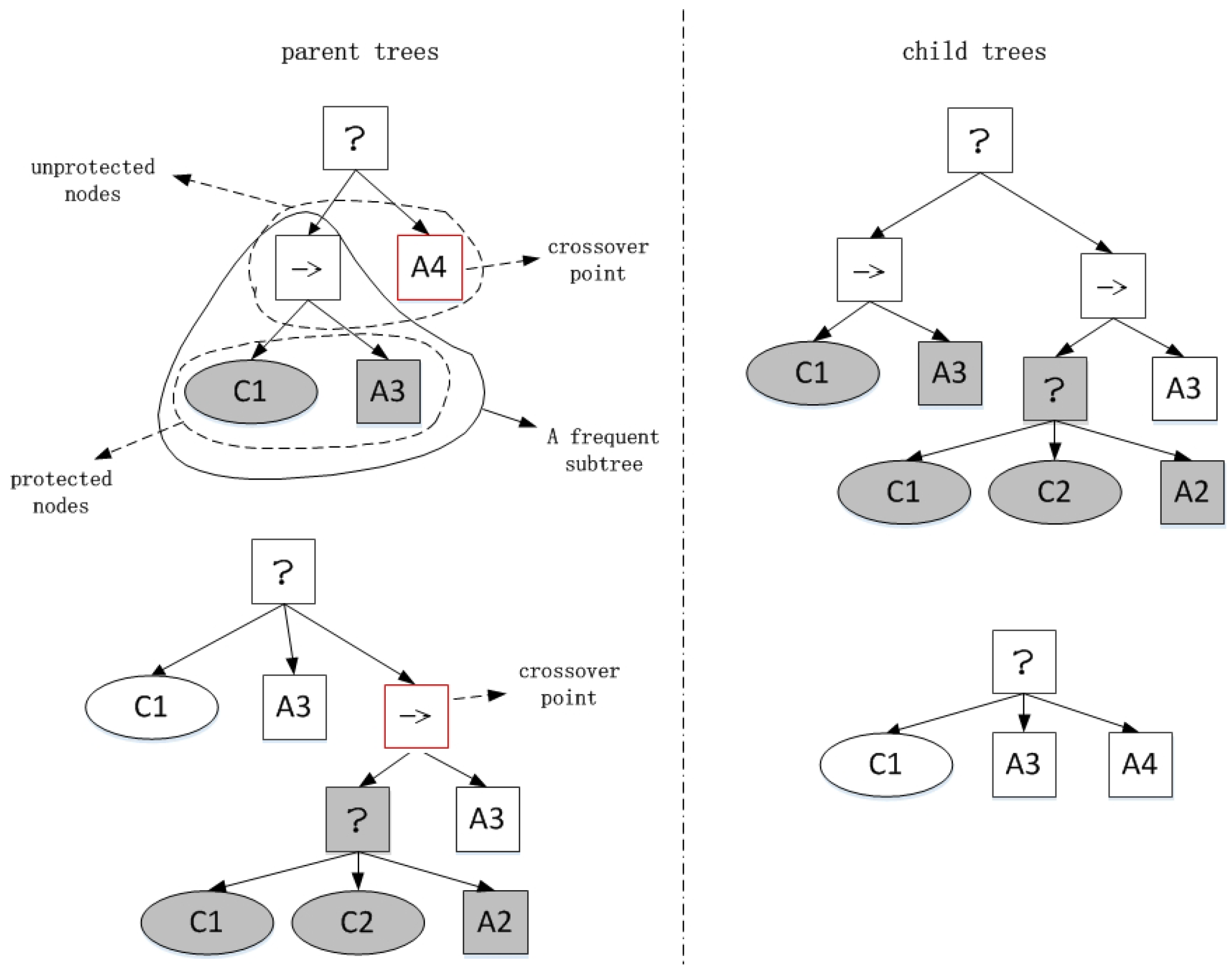
3.2. Dynamic Constrain Based on Frequent Sub-Tree Mining
3.2.1. Frequent Sub-Tree Mining
- and , where depicts the minimal support of a frequent pattern, depicts the minimal node size of a frequent pattern and depicts the maximal node size of a frequent pattern.
- All terminal nodes in a frequent pattern must be leaf nodes (condition nodes or action nodes).
- , where depicts the minimal terminal node size of a frequent pattern.
3.2.2. Nodes Crossover Probability Adjustment
3.3. Evolving BTs with Hybrid Constraints
- Selector node may only be placed at depth levels that are even.
- Sequence node may only be placed at depth levels that are odd.
- All terminal child nodes of a node must be adjacent, and those child nodes must be one or more condition nodes followed by on or more action nodes. If there is only one terminal child node, it must be an action node.
4. Experimental Section
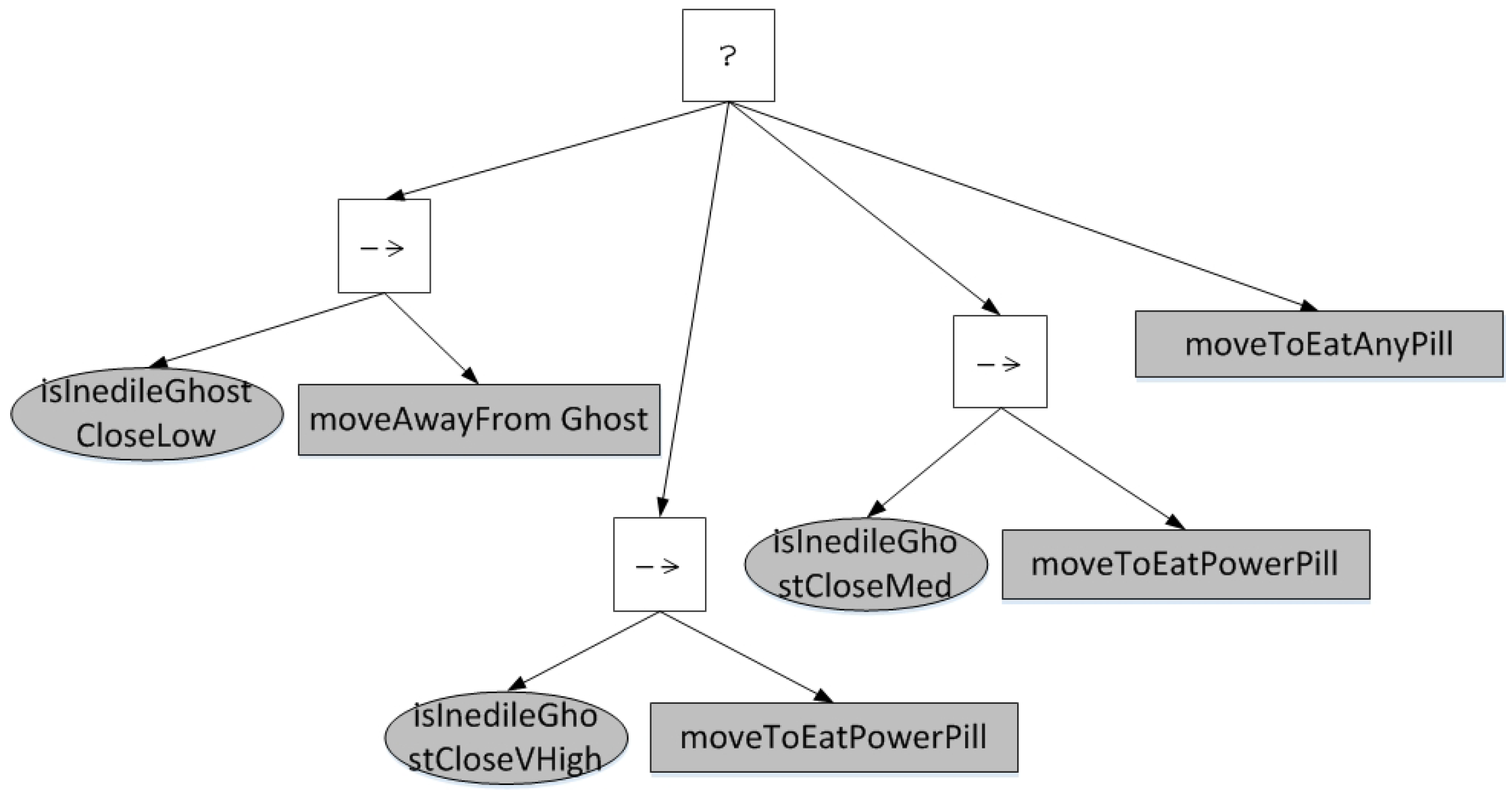
4.1. Simulation Environment and Agents
- Conditions/////, six condition nodes which return ‘true’ if there is a ghost in the ‘Inedible’ state within a certain fixed distance range, as well as targeting that ghost., ////, six condition nodes which return ‘true’ if there is a ghost in the ‘Edible’ state within a certain fixed distance range, as well as targeting that ghost.//, three condition nodes which return ‘true’ if a previous condition node has targeted a ghost, which is edible and whose remaining time in the ‘edible’ state is within a certain fixed range.//, three condition nodes which return ‘true’ if the current point value for eating a ghost is 400/800/1600.
- Actions: an action node which set Pac-Man’s direction to the nearest pill or power pill, returning ‘true’ if any such pill exists in the level or ‘false’ otherwise.: an action node which set Pac-Man’s direction to the nearest normal pill, returning ‘true’ if any such pill exists in the level or ‘false’ otherwise.: an action node which set Pac-Man’s direction to the nearest power pill, returning ‘true’ if any such pill exists in the level or ‘false’ otherwise.: an action node which set Pac-Man’s direction away from the nearest ghost that was targeted in the last condition node executed, returning ‘true’ if a ghost has been targeted or ‘false’ otherwise.: an action node which set Pac-Man’s direction towards the ghost that was targeted in the last condition node executed, returning ‘true’ if a ghost has been targeted or ‘false’ otherwise.
- Fitness FunctionThe fitness function is the sum of averaged game score and a parsimony pressure value as formula [16]. Where x is the evaluated BT, is the fitness value, is the averaged game score for a few game runs, c is a constant value known as the parsimony coefficient, is the node size of x. The simple parsimony pressure can adjust the original fitness based on the size of BT, which will increase the tendency for more compact tree to be selected for reproduction.
4.2. Experimental Setup
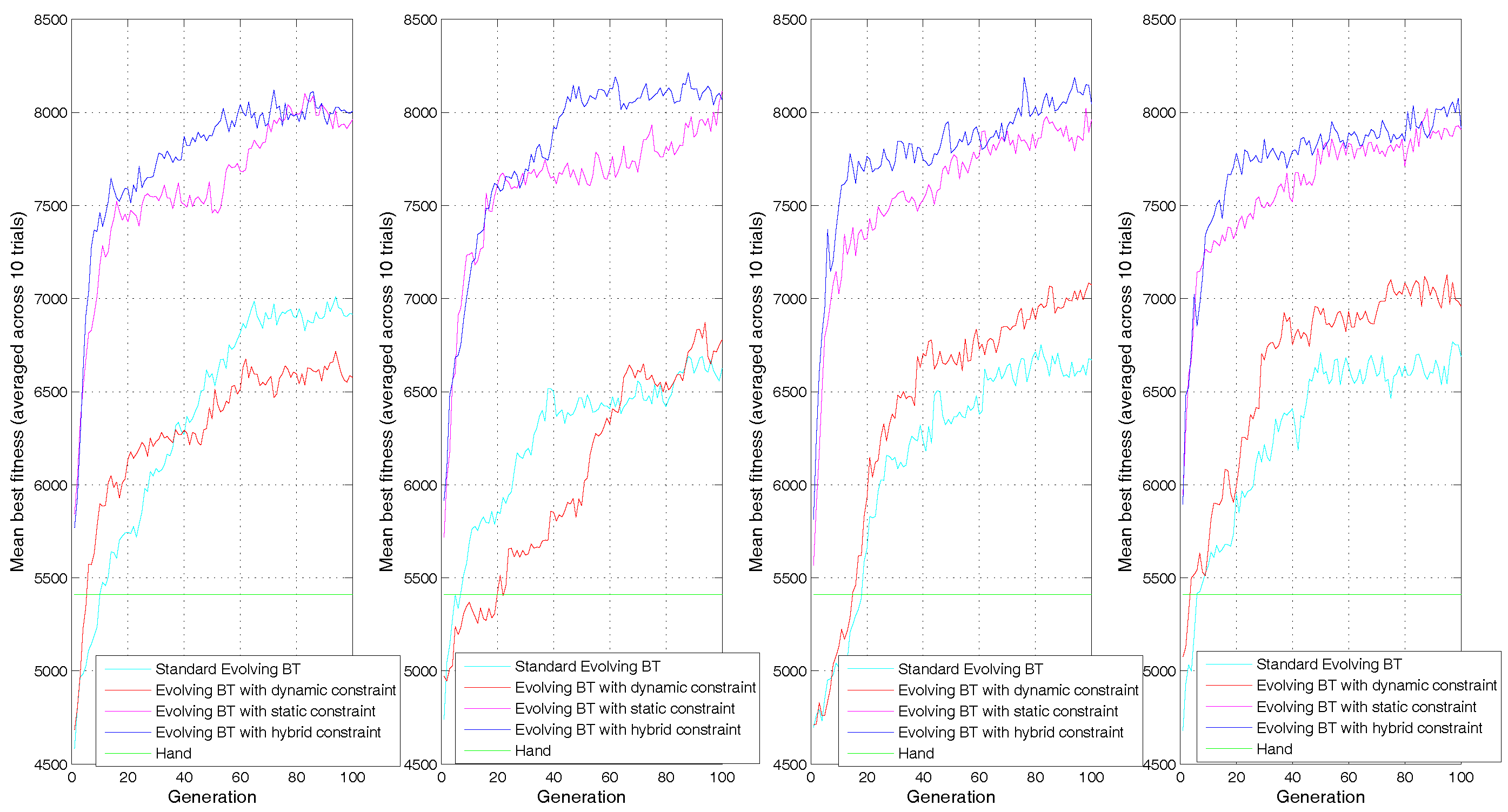
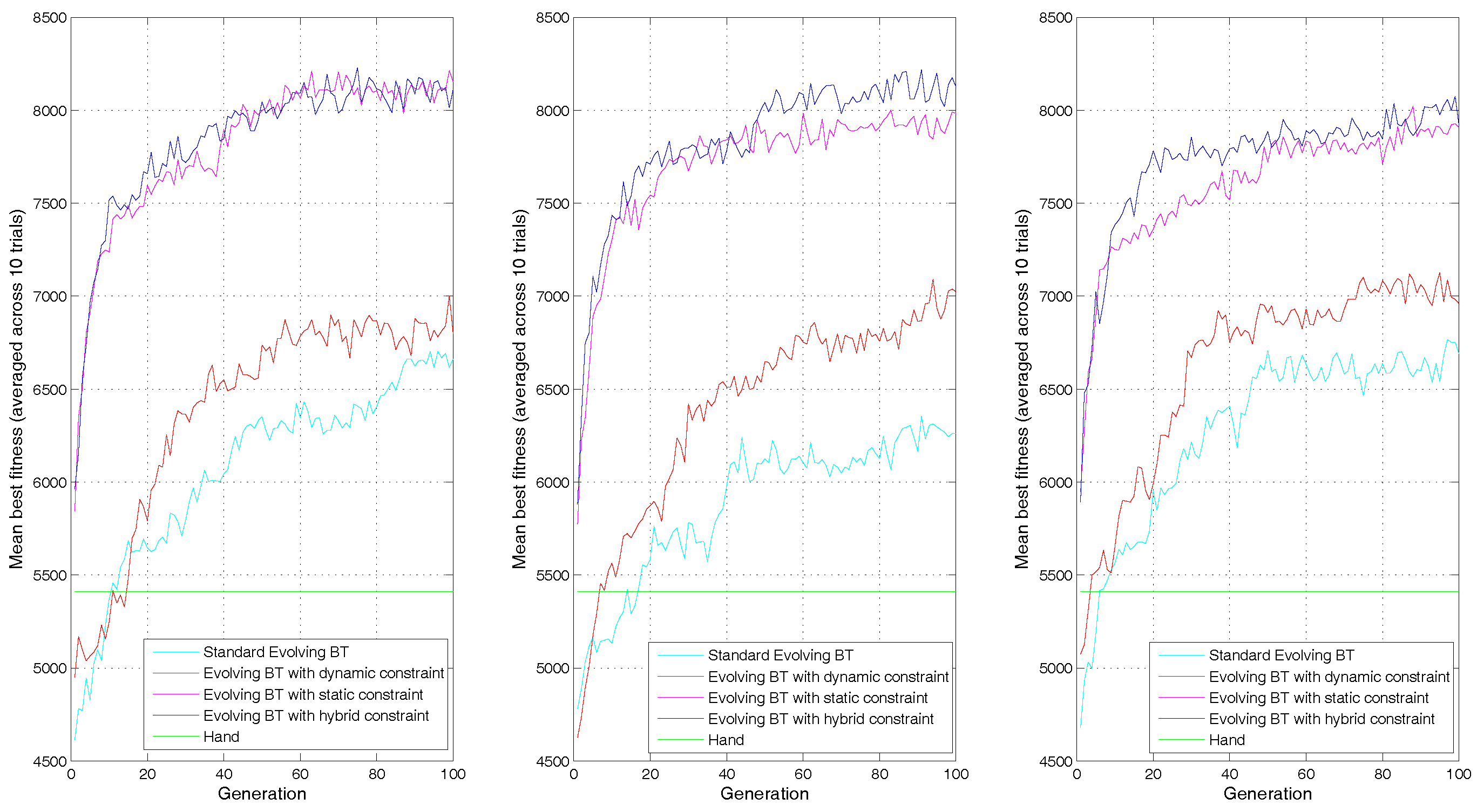
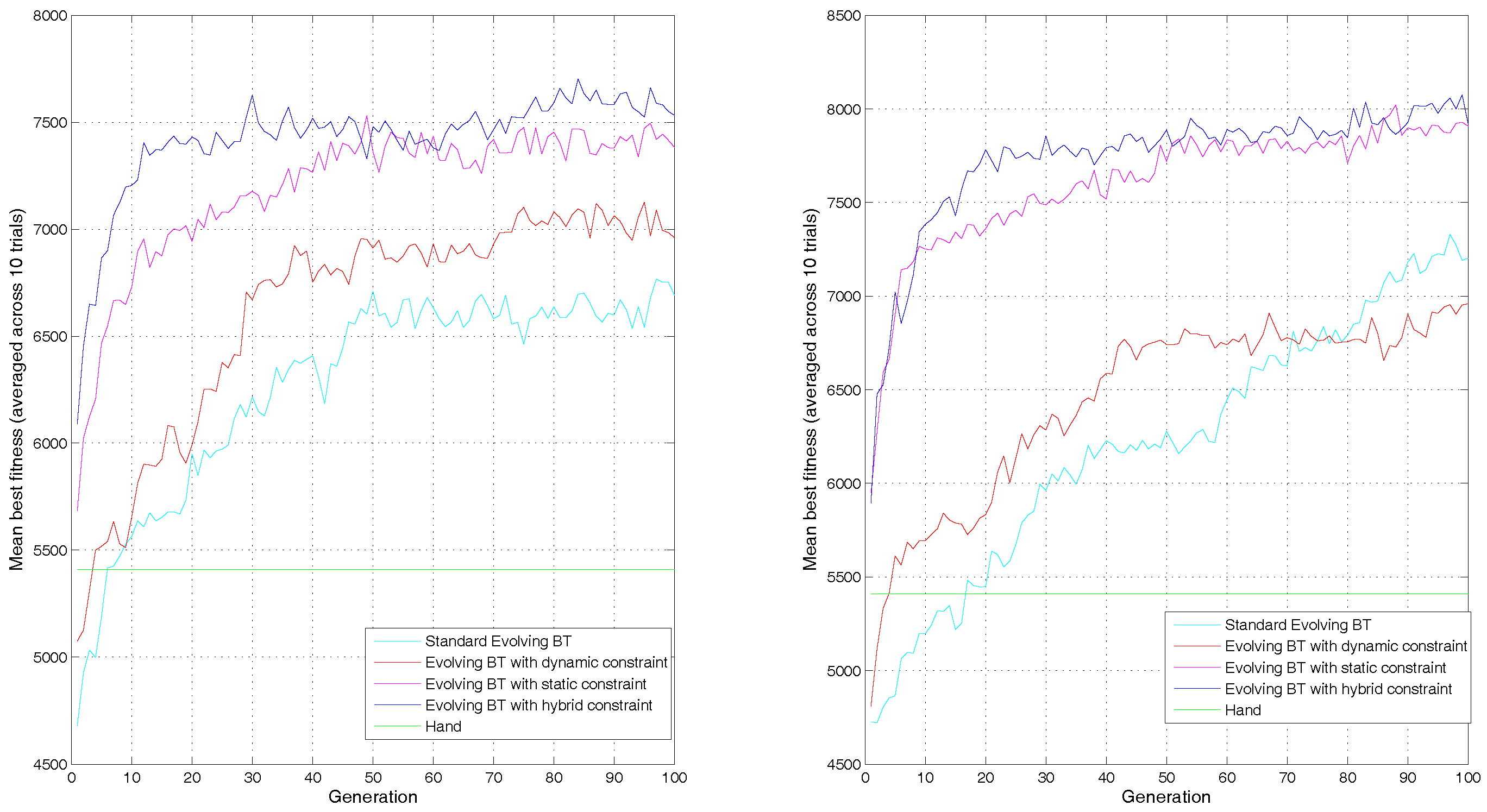
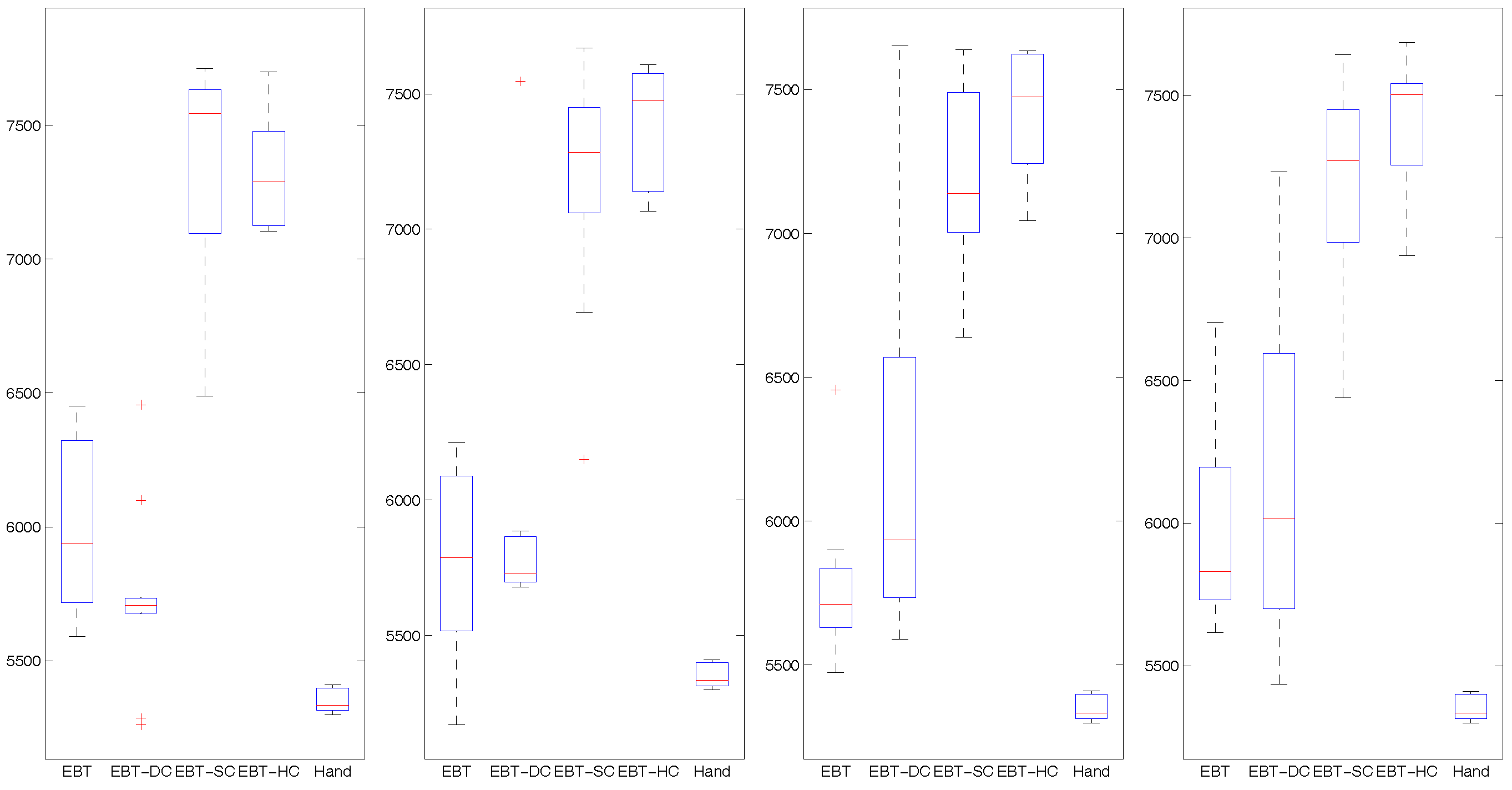
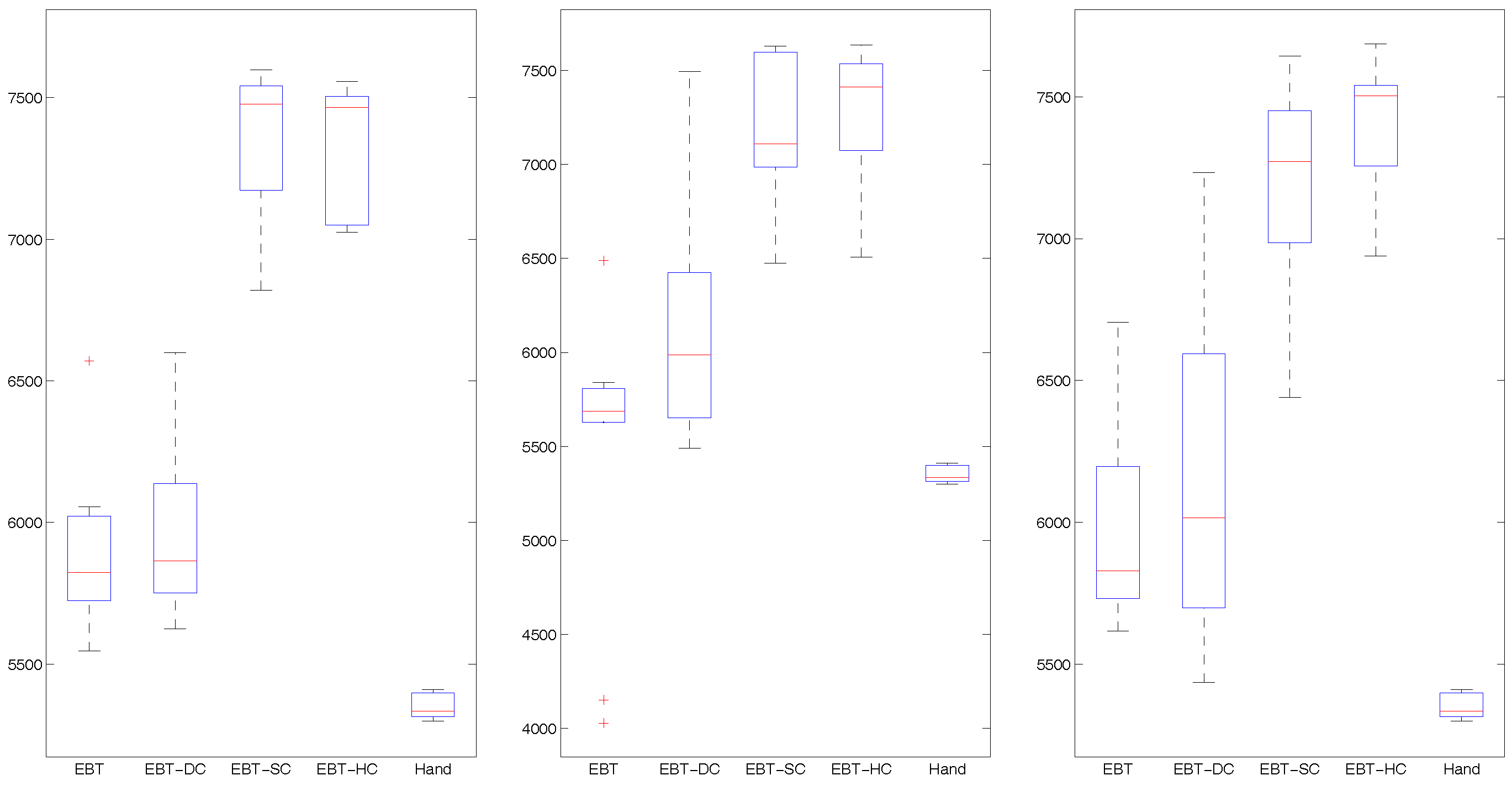
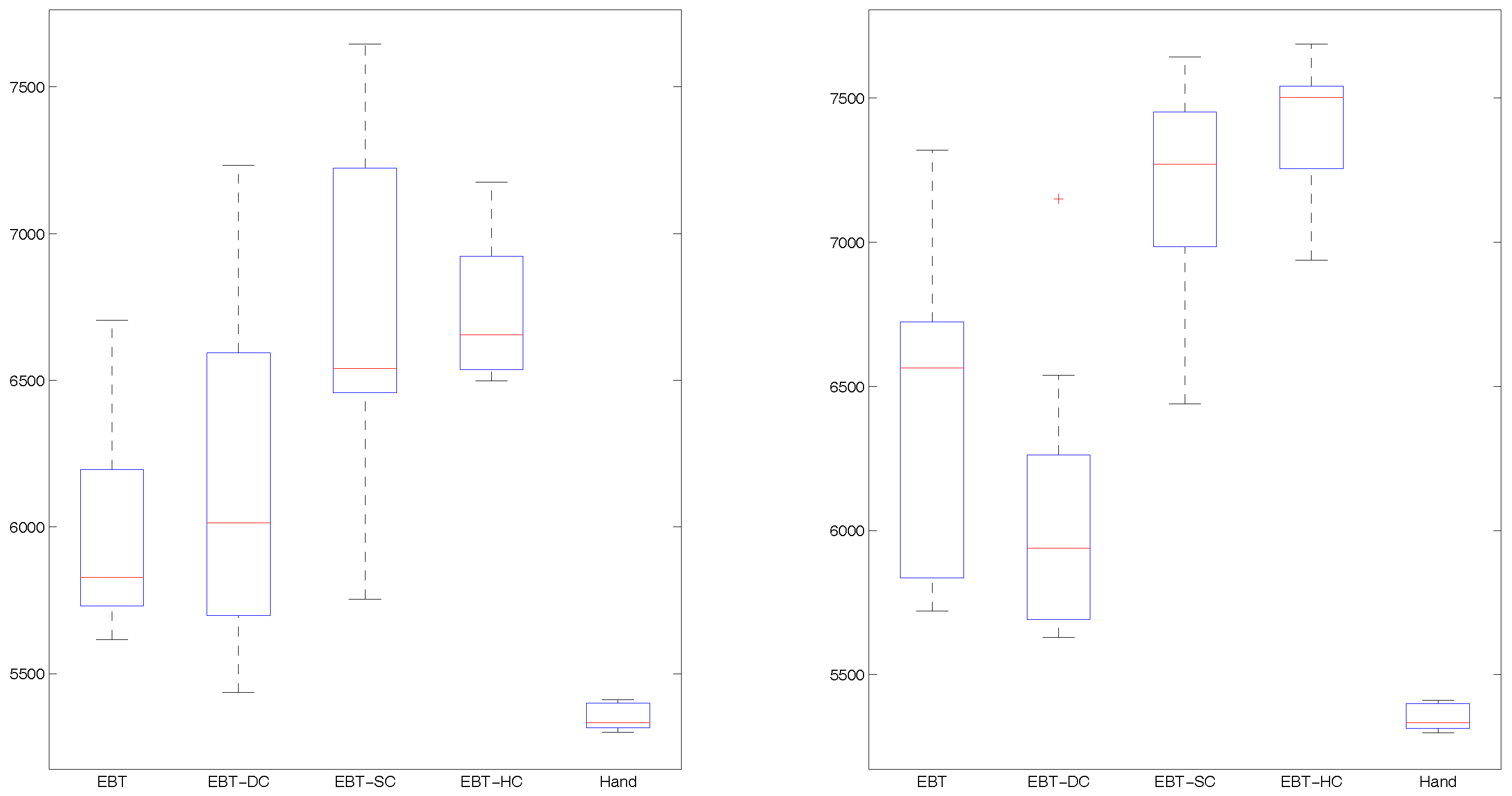
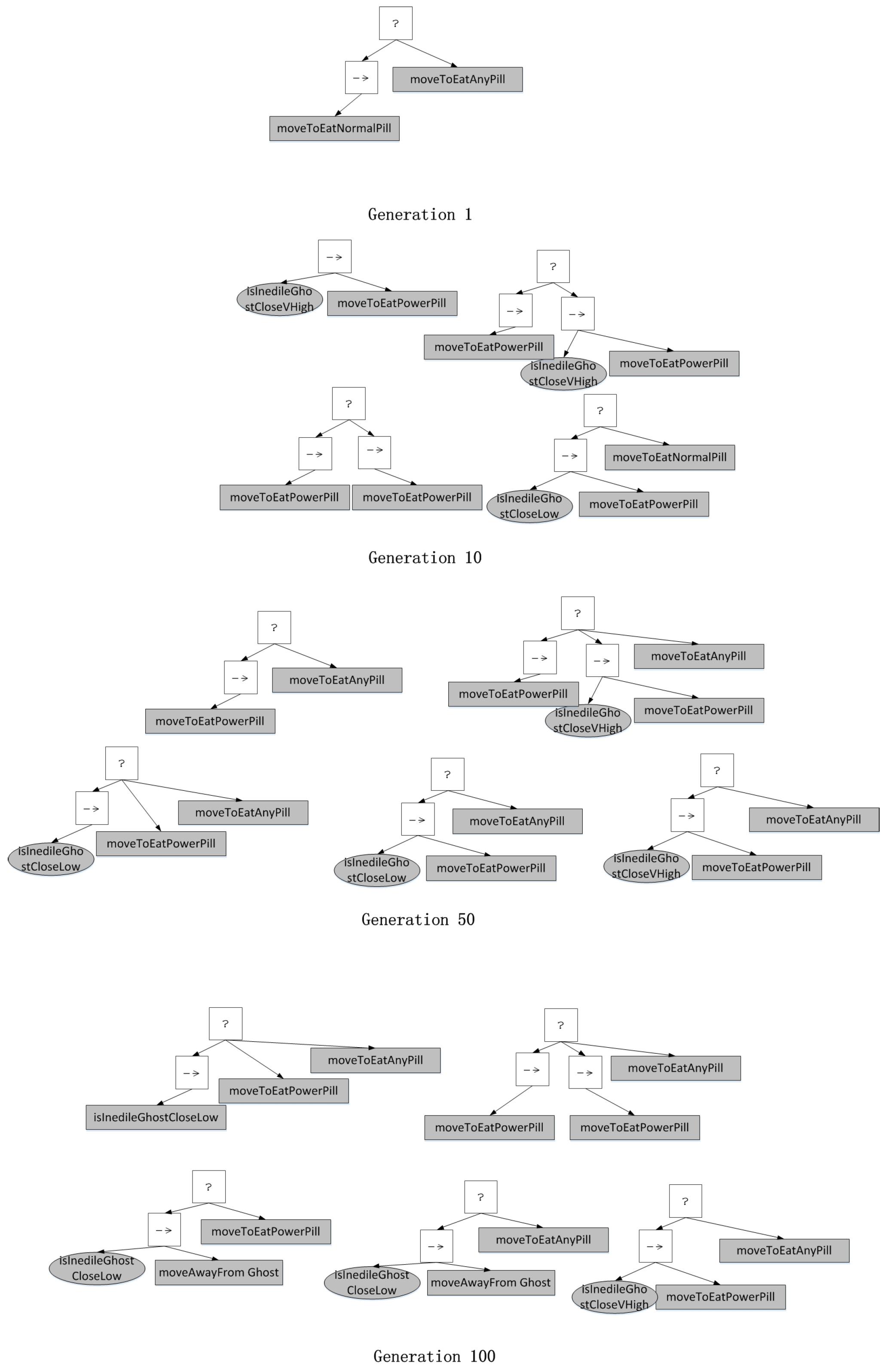
4.3. Results and Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BTs | Behavior Trees |
| FSMs | Finite State Machines |
| NPC | Non-player Characters |
| CGF | Computer-Generated Force |
| GP | Genetic Programming |
| RL | Reinforcement Learning |
| LfO | Learning from Observation |
| NN | Neural Network |
| NSF | National Science Foundation |
References
- Tirnauca, C.; Montana, J.L.; Ontanon, S.; Gonzalez, A.J.; Pardo, L.M. Behavioral Modeling Based on Probabilistic Finite Automata: An Empirical Study. Sensors 2016, 16, 958. [Google Scholar] [CrossRef] [PubMed]
- Toubman, A.; Poppinga, G.; Roessingh, J.J.; Hou, M.; Luotsinen, L.; Lovlid, R.A.; Meyer, C.; Rijken, R.; Turcanik, M. Modeling CGF Behavior with Machine Learning Techniques: Requirements and Future Directions. In Proceedings of the 2015 Interservice/Industry Training, Simulation, and Education Conference, Orlando, FL, USA, 30 November–4 December 2015; pp. 2637–2647. [Google Scholar]
- Diller, D.E.; Ferguson, W.; Leung, A.M.; Benyo, B.; Foley, D. Behavior modeling in commercial games. In Proceedings of the 2004 Conference on Behavior Representation in Modeling and Simulation (BRIMS), Arlington, VA, USA, 17–20 May 2004; pp. 17–20. [Google Scholar]
- Kamrani, F.; Luotsinen, L.J.; Løvlid, R.A. Learning objective agent behavior using a data-driven modeling approach. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2017; pp. 002175–002181. [Google Scholar]
- Luotsinen, L.J.; Kamrani, F.; Hammar, P.; Jändel, M.; Løvlid, R.A. Evolved creative intelligence for computer generated forces. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2017; pp. 003063–003070. [Google Scholar]
- Yao, J.; Huang, Q.; Wang, W. Adaptive human behavior modeling for air combat simulation. In Proceedings of the 2015 IEEE/ACM 19th International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Chengdu, China, 14–16 October 2015; pp. 100–103. [Google Scholar]
- Sagredo-Olivenza, I.; Gómez-Martín, P.P.; Gómez-Martín, M.A.; González-Calero, P.A. Trained Behavior Trees: Programming by Demonstration to Support AI Game Designers. IEEE Trans. Games 2017. [Google Scholar] [CrossRef]
- Sekhavat, Y.A. Behaivor Trees for Computer Games. Int. J. Artif. Intell. Tools 2017, 1, 1–27. [Google Scholar]
- Rabin, S. AI Game Programming Wisdom 4; Nelson Education: Scarborough, ON, Canada, 2014; Volume 4. [Google Scholar]
- Colledanchise, M.; Ögren, P. Behavior Trees in Robotics and AI: An Introduction. arXiv, 2017; arXiv:1709.00084. [Google Scholar]
- Nicolau, M.; Perezliebana, D.; Oneill, M.; Brabazon, A. Evolutionary Behavior Tree Approaches for Navigating Platform Games. IEEE Trans. Comput. Intell. AI Games 2017, 9, 227–238. [Google Scholar] [CrossRef] [Green Version]
- Perez, D.; Nicolau, M.; O’Neill, M.; Brabazon, A. Evolving behaviour trees for the mario AI competition using grammatical evolution. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Torino, Italy, 27–29 April 2011; pp. 123–132. [Google Scholar]
- Lim, C.U.; Baumgarten, R.; Colton, S. Evolving behaviour trees for the commercial game DEFCON. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Torino, Italy, 7–9 April 2010; pp. 100–110. [Google Scholar]
- Mcclarron, P.; Ollington, R.; Lewis, I. Effect of Constraints on Evolving Behavior Trees for Game AI. In Proceedings of the International Conference on Computer Games Multimedia & Allied Technologies, Los Angeles, CA, USA, 15–18 November 2016. [Google Scholar]
- Press, J.R.K.M. Genetic programming II: Automatic discovery of reusable programs. Comput. Math. Appl. 1995, 29, 115. [Google Scholar]
- Poli, R.; Langdon, W.B.; Mcphee, N.F. A Field Guide to Genetic Programming; lulu.com: Morrisville, NC, USA, 2008; pp. 229–230. [Google Scholar]
- Scheper, K.Y.W.; Tijmons, S.; Croon, G.C.H.E.D. Behavior Trees for Evolutionary Robotics. Artif. Life 2016, 22, 23–48. [Google Scholar] [CrossRef] [PubMed]
- Champandard, A.J. Behaivor Trees for Next-gen Game AI. Available online: http://aigamedev.com/insider/presentations/behavior-trees/ (accessed on 12 December 2007).
- Zhang, Q.; Yin, Q.; Xu, K. Towards an Integrated Learning Framework for Behavior Modeling of Adaptive CGFs. In Proceedings of the IEEE 9th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 10–11 December 2016; Volume 2, pp. 7–12. [Google Scholar]
- Fernlund, H.K.G.; Gonzalez, A.J.; Georgiopoulos, M.; Demara, R.F. Learning tactical human behavior through observation of human performance. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2006, 36, 128. [Google Scholar] [CrossRef]
- Stein, G.; Gonzalez, A.J. Building High-Performing Human-Like Tactical Agents Through Observation and Experience; IEEE Press: Piscataway, NJ, USA, 2011; p. 792. [Google Scholar]
- Teng, T.H.; Tan, A.H.; Tan, Y.S.; Yeo, A. Self-organizing neural networks for learning air combat maneuvers. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Ontañón, S.; Mishra, K.; Sugandh, N.; Ram, A. Case-Based Planning and Execution for Real-Time Strategy Games. In Proceedings of the International Conference on Case-Based Reasoning: Case-Based Reasoning Research and Development, Northern Ireland, UK, 13–16 August 2007; pp. 164–178. [Google Scholar]
- Aihe, D.O.; Gonzalez, A.J. Correcting flawed expert knowledge through reinforcement learning. Expert Syst. Appl. 2015, 42, 6457–6471. [Google Scholar] [CrossRef]
- Robertson, G.; Watson, I. Building behavior trees from observations in real-time strategy games. In Proceedings of the International Symposium on Innovations in Intelligent Systems and Applications, Madrid, Spain, 2–4 September 2015; pp. 1–7. [Google Scholar]
- Dey, R.; Child, C. Ql-bt: Enhancing behaviour tree design and implementation with q-learning. In Proceedings of the IEEE Conference on Computational Intelligence in Games (CIG), Niagara Falls, ON, Canada, 11–13 August 2013; pp. 1–8. [Google Scholar]
- Zhang, Q.; Sun, L.; Jiao, P.; Yin, Q. Combining Behavior Trees with MAXQ Learning to Facilitate CGFs Behavior Modeling. In Proceedings of the 4th International Conference on IEEE Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017. [Google Scholar]
- Asai, T.; Abe, K.; Kawasoe, S.; Arimura, H.; Sakamoto, H.; Arikawa, S. Efficient Substructure Discovery from Large Semi-structured Data. In Proceedings of the Siam International Conference on Data Mining, Arlington, Arlington, VA, USA, 11–13 April 2002. [Google Scholar]
- Chi, Y.; Muntz, R.R.; Nijssen, S.; Kok, J.N. Frequent Subtree Mining—An Overview. Fundam. Inf. 2005, 66, 161–198. [Google Scholar]
- Williams, P.R.; Perezliebana, D.; Lucas, S.M. Ms. Pac-Man Versus Ghost Team CIG 2016 Competition. In Proceedings of the IEEE Conference on Computational Intelligence and Games (CIG), Santorini, Greece, 20–23 September 2016. [Google Scholar]
- Christensen, H.J.; Hoff, J.W. Evolving Behaviour Trees: Automatic Generation of AI Opponents for Real-Time Strategy Games. Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2016. [Google Scholar]
- Osborn, J.C.; Samuel, B.; Mccoy, J.A.; Mateas, M. Evaluating play trace (Dis)similarity metrics. In Proceedings of the AIIDE, Raleigh, NC, USA, 3–7 October 2014. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Parameter | Value |
|---|---|---|
| fixed to all approaches | population size | 100 |
| generations | 100 | |
| initial min depth | 2 | |
| initial max depth | 3 | |
| selection tournament size | ||
| parsimony coefficient | 0.7 | |
| variable to all approaches | new chromosomes | |
| crossover probability | 0.6/0.7/0.8/0.9 | |
| reproduction probability | 0.4/0.3/0.2/0.1 | |
| mutation probability | 0.01/0.1 | |
| EBT-DC/EBT-HC | superior individuals | |
| the minimal support | 0.3 | |
| the minimal node size | 3 | |
| the maximal node size | 15 | |
| the minimal terminal node size | 2 | |
| the discount factor | 0.9 |
| EBT | EBT-DC | EBT-SC | EBT-HC | ||
|---|---|---|---|---|---|
| Crossover probability | 0.6 | 6011.8 ± 320.2 | 5734.6 ± 347.3 | 7344.8 ± 428.4 | 7324.5 ± 221.8 |
| 0.7 | 5768.0 ± 341.6 | 5930.9 ± 572.2 | 7174.5 ± 454.0 | 7371.0 ± 224.0 | |
| 0.8 | 5781.7 ± 267.9 | 6274.8 ± 728.5 | 7169.6 ± 353.1 | 7419.5 ± 218.5 | |
| 0.9 | 5978.8 ± 361.1 | 6168.4 ± 609.4 | 7173.5 ± 402.2 | 7406.5 ± 258.2 | |
| new chromosomes | 0.1 | 5886.4 ± 282.9 | 5962.3 ± 311.3 | 7353.6 ± 274.9 | 7350.0 ± 221.4 |
| 0.2 | 5471.7 ± 769.9 | 6105.8 ± 592.1 | 7197.0 ± 369.3 | 7300.5 ± 344.9 | |
| 0.3 | 5978.8 ± 361.1 | 6168.4 ± 609.4 | 7173.5 ± 402.2 | 7406.5 ± 258.2 | |
| Mutation probability | 0.01 | 5978.8 ± 361.1 | 6168.4 ± 609.4 | 6720.7 ± 606.6 | 6737.2 ± 262.6 |
| 0.1 | 6456.9 ± 523.0 | 6087.7 ± 473.0 | 7173.5 ± 402.2 | 7406.5 ± 258.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Yao, J.; Yin, Q.; Zha, Y. Learning Behavior Trees for Autonomous Agents with Hybrid Constraints Evolution. Appl. Sci. 2018, 8, 1077. https://doi.org/10.3390/app8071077
Zhang Q, Yao J, Yin Q, Zha Y. Learning Behavior Trees for Autonomous Agents with Hybrid Constraints Evolution. Applied Sciences. 2018; 8(7):1077. https://doi.org/10.3390/app8071077
Chicago/Turabian StyleZhang, Qi, Jian Yao, Quanjun Yin, and Yabing Zha. 2018. "Learning Behavior Trees for Autonomous Agents with Hybrid Constraints Evolution" Applied Sciences 8, no. 7: 1077. https://doi.org/10.3390/app8071077
APA StyleZhang, Q., Yao, J., Yin, Q., & Zha, Y. (2018). Learning Behavior Trees for Autonomous Agents with Hybrid Constraints Evolution. Applied Sciences, 8(7), 1077. https://doi.org/10.3390/app8071077