Accelerating 3-D GPU-based Motion Tracking for Ultrasound Strain Elastography Using Sum-Tables: Analysis and Initial Results




Abstract
:1. Introduction
2. Materials and Methods
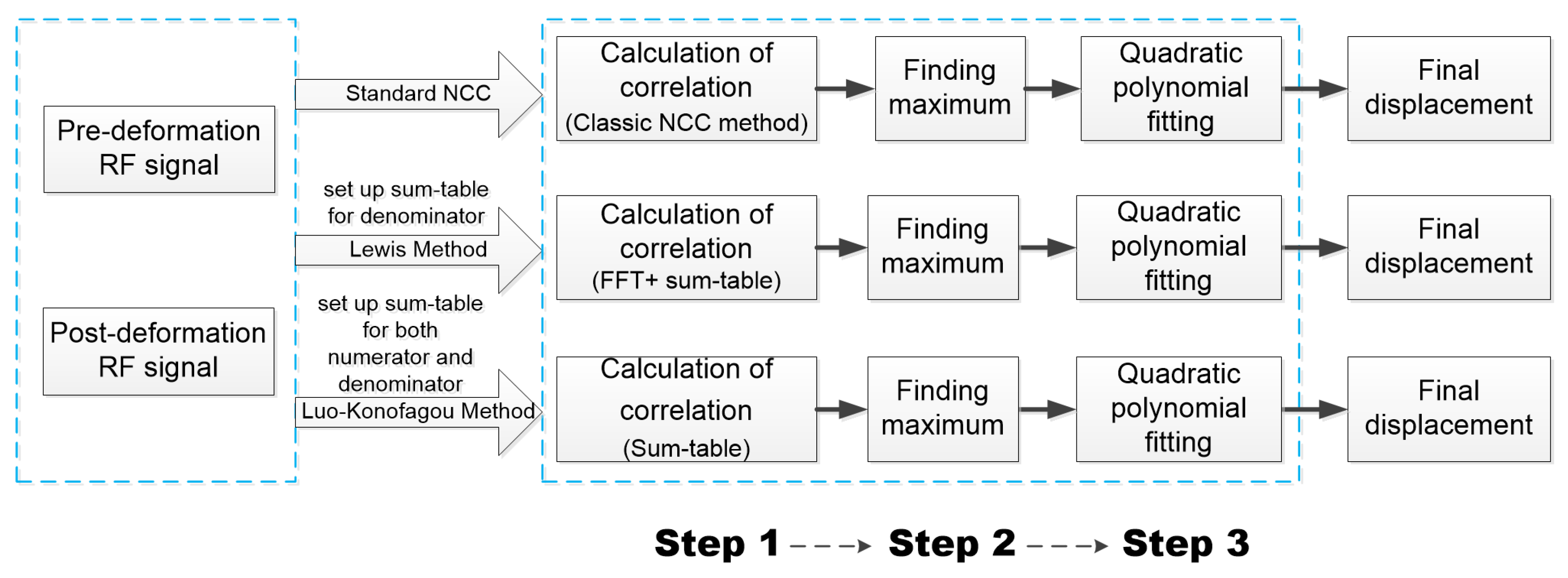
2.1. A Description of GPU-Accelerated Block-Matching Algorithm in USE
2.1.1. A Standard Protocol for Calculating NCC
2.1.2. Lewis’ Sum-Table Method
2.1.3. Luo-Konofagou Sum-Table Method
2.2. GPU Implementation of Three NCC Calculation Methods
2.2.1. A Brief Description of GPU Computing
2.2.2. Block-Matching Using GPU Parallel Computing
2.2.3. Implementing A Standard NCC Calculation on CUDA
2.2.4. Implementing Lewis’ Method on CUDA
2.2.5. Implementing Luo-Konofagou Method
2.3. Experimental Design and Data Analysis
2.3.1. A Tissue-Mimicking Phantom Experiment
2.3.2. Data Analysis
3. Results
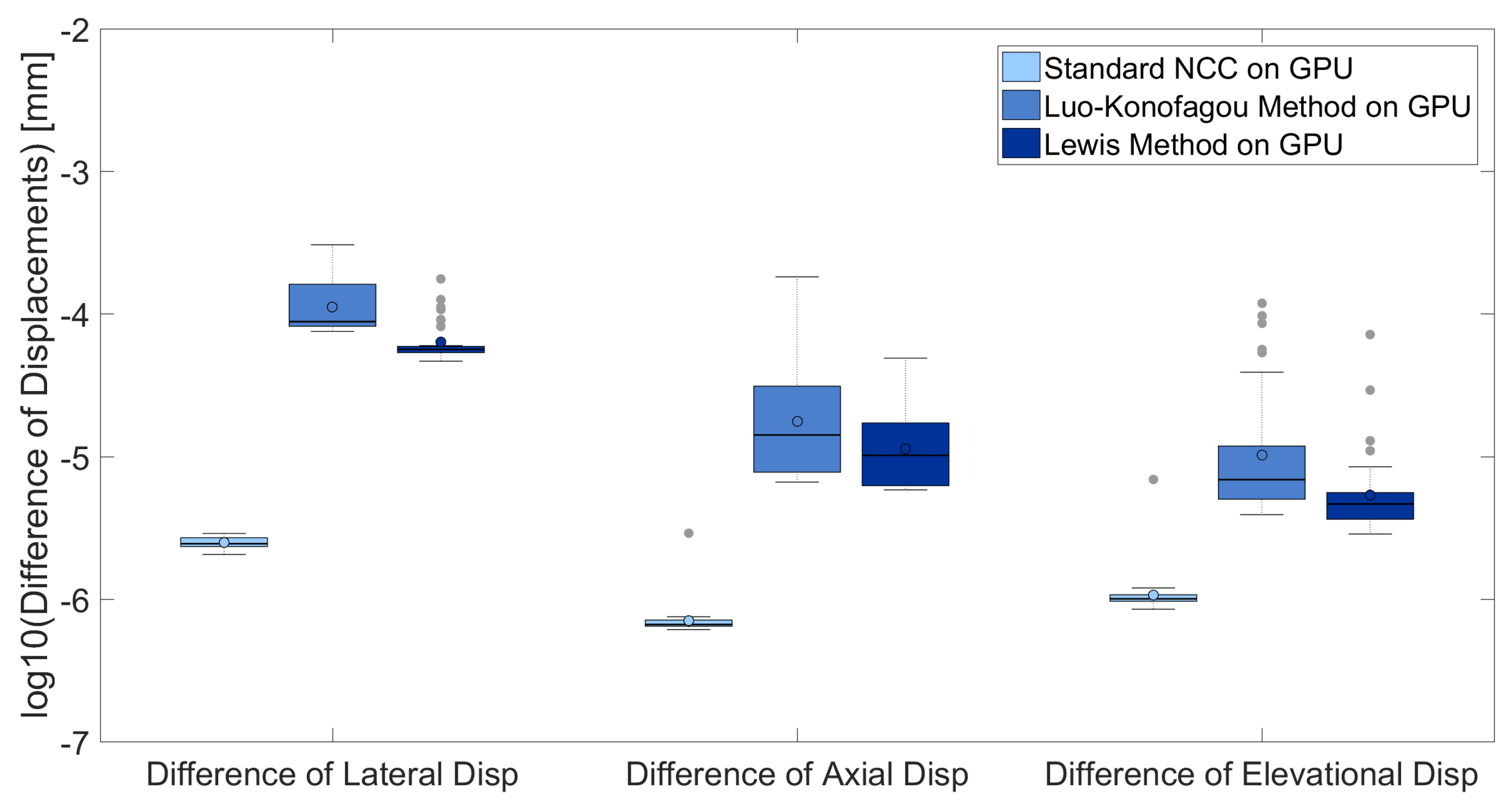
3.1. Comparisons of Accuracy Among Different Implementations
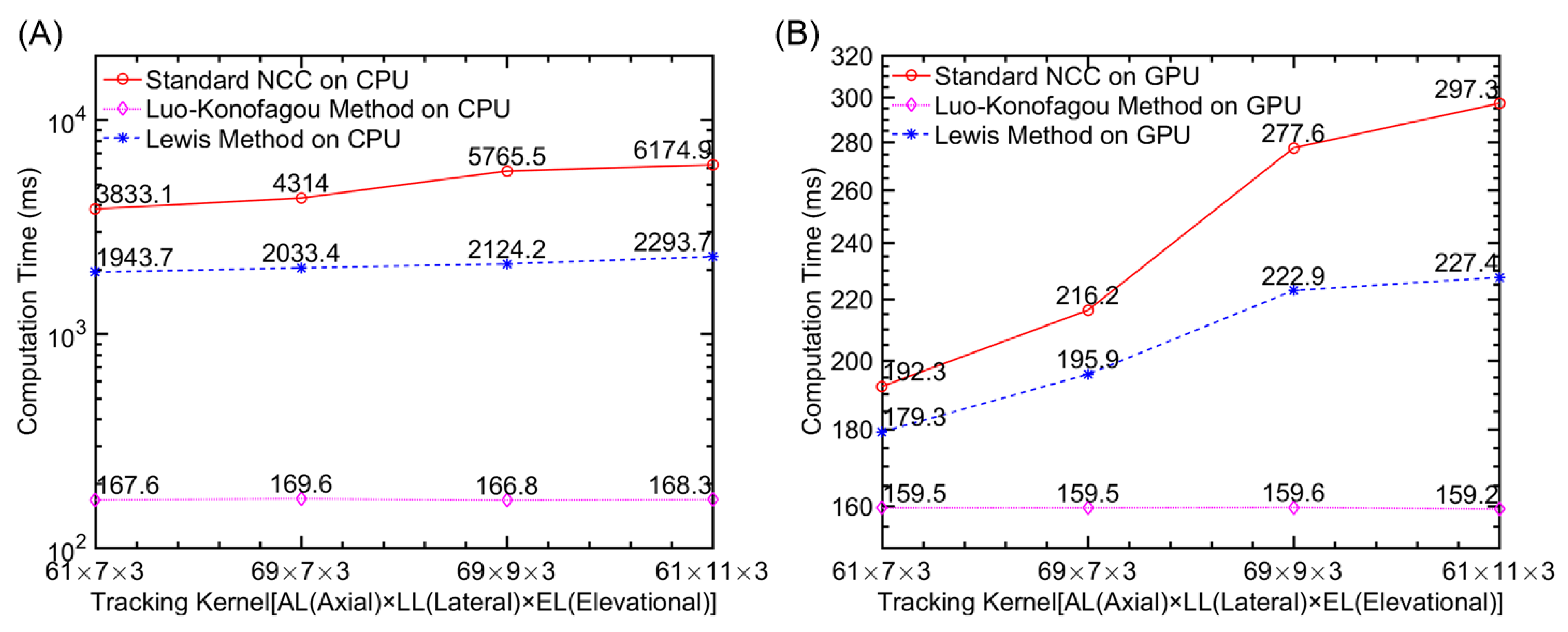
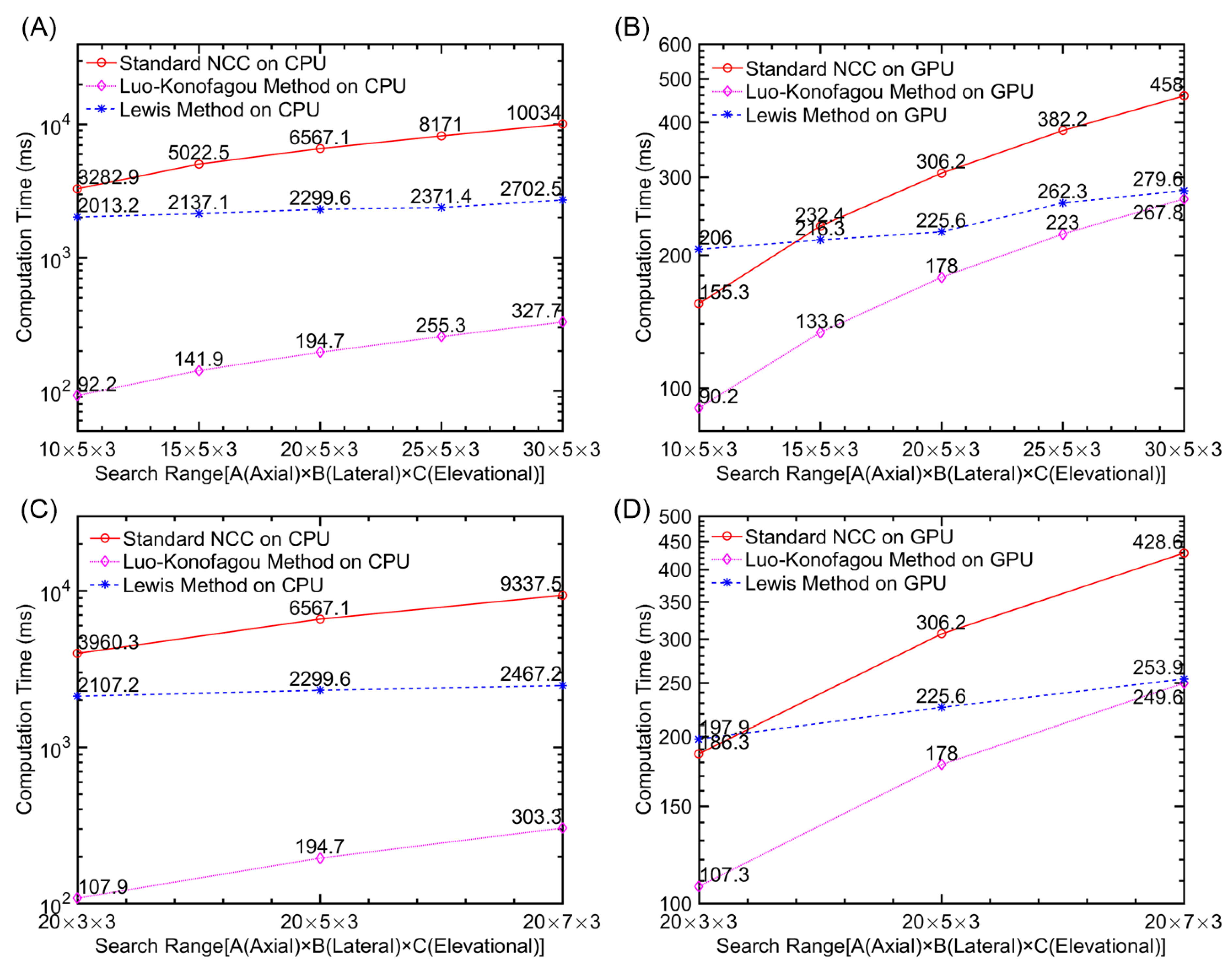
Computational Efficiency
4. Discussion and Summary
Author Contributions
Funding
Conflicts of Interest
Appendix A. Setting up 3-D Sum-Tables for 3-D Ultrasound Echo Data
Appendix B. Analysis of Algorithmic Complexity for Sum-Table Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard NCC | Luo-Konofagou Method | Lewis’ Method | ||
|---|---|---|---|---|
| Numerator | Addition | 6 | ||
| Multiplication | None | |||
| Subtraction | None | 8 | None | |
| Denominator | Addition | 3 | 3 | |
| Multiplication | 1 | 1 | ||
| Subtraction | None | 4 | 4 |
| Lewis’ Method | Luo-Konofagou Method | ||
|---|---|---|---|
| Numerator | Addition | None | |
| Multiplication | None | ||
| Subtraction | None | None | |
| Denominator | Addition | ||
| Multiplication | |||
| Subtraction | None | None |
Appendix C. Analysis of Memory Requirements for Sum-Table Methods
| Search Range (Axial × Lateral × Elevational) | Memory Use (MB) | |
|---|---|---|
| Lewis Method | Luo-Konofagou Method | |
| 3 | 5 | 305 |
| 3 | 5 | 455 |
| 3 | 5 | 605 |
| 3 | 5 | 755 |
| 3 | 5 | 425 |
| 3 | 5 | 635 |
| 3 | 5 | 845 |
| 3 | 5 | 1055 |
References
- Shiina, T.; Nightingale, K.R.; Palmeri, M.L.; Hall, T.J.; Bamber, J.C.; Barr, R.G.; Castera, L.; Choi, B.I.; Chou, Y.H.; Cosgrove, D.; et al. {WFUMB} Guidelines and Recommendations for Clinical Use of Ultrasound Elastography: Part 1: Basic Principles and Terminology. Ultrasound Med. Biol. 2015, 41, 1126–1147. [Google Scholar] [CrossRef]
- Hall, T.J.; Zhu, Y.; Spalding, C.S. In vivo real-time freehand palpation imaging. Ultrasound Med. Biol. 2003, 29, 427–435. [Google Scholar] [CrossRef]
- Burnside, E.S.; Hall, T.J.; Sommer, A.M.; Hesley, G.K.; Sisney, G.A.; Svensson, W.E.; Fine, J.P.; Jiang, J.; Hangiandreou, N.J. Differentiating Benign from Malignant Solid Breast Masses with US Strain Imaging. Radiology 2007, 245, 401–410. [Google Scholar] [CrossRef]
- Itoh, A.; Ueno, E.; Tohno, E.; Kamma, H.; Takahashi, H.; Shiina, T.; Yamakawa, M.; Matsumura, T. Breast Disease: Clinical Application of US Elastography for Diagnosis. Radiology 2006, 239, 341–350. [Google Scholar] [CrossRef] [PubMed]
- Hall, T.J.; Oberait, A.A.; Barbone, P.E.; Sommer, A.M.; Gokhale, N.H.; Goenezent, S.; Jiang, J. Elastic nonlinearity imaging. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–9 September 2009; pp. 1967–1970. [Google Scholar]
- Oberai, A.A.; Gokhale, N.H.; Goenezen, S.; Barbone, P.E.; Hall, T.J.; Sommer, A.M.; Jiang, J. Linear and nonlinear elasticity imaging of soft tissue in vivo: Demonstration of feasibility. Phys. Med. Biol. 2009, 54, 1191–1207. [Google Scholar] [CrossRef] [PubMed]
- Goenezen, S.; Dord, J.F.; Sink, Z.; Barbone, P.E.; Jiang, J.; Hall, T.J.; Oberai, A.A. Linear and Nonlinear Elastic Modulus Imaging: An Application to Breast Cancer Diagnosis. IEEE Trans. Med Imaging 2012, 31, 1628–1637. [Google Scholar] [CrossRef]
- Varghese, T.; Ophir, J. A theoretical framework for performance characterization of elastography: The strain filter. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 1997, 44, 164–172. [Google Scholar] [CrossRef] [PubMed]
- Righetti, R.; Ophir, J.; Ktonas, P. Axial resolution in elastography. Ultrasound Med. Biol. 2002, 28, 101–113. [Google Scholar] [CrossRef]
- Thitaikumar, A.; Righetti, R.; Krouskop, T.A.; Ophir, J. Resolution of axial shear strain elastography. Phys. Med. Biol. 2006, 51, 5245–5257. [Google Scholar] [CrossRef] [PubMed]
- Kallel, F.; Bertrand, M.; Ophir, J. Fundamental limitations on the contrast-transfer efficiency in elastography: An analytic study. Ultrasound Med. Biol. 1996, 22, 463–470. [Google Scholar] [CrossRef]
- Rosen, D.; Wang, Y.; Jiang, J. Virtual Breast Quasi-static Elastography (VBQE): A Case Study in Contrast Transfer Efficiency of Viscoelastic Imaging. Ultrason. Imaging 2017, 39, 108–125. [Google Scholar] [CrossRef]
- Jiang, J.; Peng, B. Ultrasonic Methods for Assessment of Tissue Motion in Elastography. In Ultrasound Elastography for Biomedical Applications and Medicine; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2018; Chapter 4; pp. 35–70. [Google Scholar]
- Zhu, Y.; Hall, T.J. A Modified Block Matching Method for Real-Time Freehand Strain Imaging. Ultrason. Imaging 2002, 24, 161–176. [Google Scholar] [CrossRef]
- Li, P.C.; Lee, W.N. An Efficient Speckle Tracking Algorithm for Ultrasonic Imaging. Ultrason. Imaging 2002, 24, 215–228. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Xie, H.; Erkamp, R.; Kim, K.; Jia, C.; Rubin, J.M.; O’Donnell, M. 3-D Correlation-Based Speckle Tracking. Ultrason. Imaging 2005, 27, 21–36. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Hall, T.J. A parallelizable real-time motion tracking algorithm with applications to ultrasonic strain imaging. Phys. Med. Biol. 2007, 52, 3773–3790. [Google Scholar] [CrossRef] [PubMed]
- Pellot-Barakat, C.; Frouin, F.; Insana, M.F.; Herment, A. Ultrasound elastography based on multiscale estimations of regularized displacement fields. IEEE Trans. Med. Imaging 2004, 23, 153–163. [Google Scholar] [CrossRef] [PubMed]
- Fisher, T.G.; Hall, T.J.; Panda, S.; Richards, M.S.; Barbone, P.E.; Jiang, J.; Resnick, J.; Barnes, S. Volumetric Elasticity Imaging with a 2-D CMUT Array. Ultrasound Med. Biol. 2010, 36, 978–990. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, J.; Hall, T. A 3-D Region-Growing Motion-Tracking Method for Ultrasound Elasticity Imaging. Ultrasound Med. Biol. 2018, 44, 1638–1653. [Google Scholar] [CrossRef] [PubMed]
- Peng, B.; Wang, Y.; Hall, T.J.; Jiang, J. A GPU-Accelerated 3-D Coupled Subsample Estimation Algorithm for Volumetric Breast Strain Elastography. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2017, 64, 694–705. [Google Scholar] [CrossRef]
- Luo, J.; Konofagou, E.E. A fast normalized cross-correlation calculation method for motion estimation. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2010, 57, 1347–1357. [Google Scholar] [PubMed]
- Lewis, J. Fast Template Matching. In Proceedings of the Canadian Image Processing and Pattern Recognition Society, Quebec City, QC, Canada, 15–19 May 1995. Vision Interface 95. [Google Scholar]
- Insana, M.F.; Chaturvedi, P.; Hall, T.J.; gBilgen, M. 3-D companding using linear arrays for improved strain imaging. In Proceedings of the Ultrasonics Symposium, Toronto, ON, Canada, 5–8 October 1997; Volume 2, pp. 1435–1438. [Google Scholar]
- Konofagou, E.E.; Ophir, J. Precision estimation and imaging of normal and shear components of the 3D strain tensor in elastography. Phys. Med. Biol. 2000, 45, 1553–1563. [Google Scholar] [CrossRef]
- Patil, A.V.; Garson, C.D.; Hossack, J.A. 3D prostate elastography: Algorithm, simulations and experiments. Phys. Med. Biol. 2007, 52, 3643–3663. [Google Scholar] [CrossRef]
- Rivaz, H.; Boctor, E.; Foroughi, P.; Zellars, R.; Fichtinger, G.; Hager, G. Ultrasound Elastography: A Dynamic Programming Approach. IEEE Trans. Med. Imaging 2008, 27, 1373–1377. [Google Scholar] [CrossRef]
- Treece, G.M.; Lindop, J.E.; Gee, A.H.; Prager, R.W. Freehand ultrasound elastography with a 3-D probe. Ultrasound Med. Biol. 2008, 34, 463–474. [Google Scholar] [CrossRef]
- Idzenga, T.; Gaburov, E.; Vermin, W.; Menssen, J.; Korte, C.L.D. Fast 2-D ultrasound strain imaging: The benefits of using a GPU. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2014, 61, 207–213. [Google Scholar] [CrossRef]
- Yang, X.; Deka, S.; Righetti, R. A hybrid CPU-GPGPU approach for real-time elastography. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2011, 58, 2631–2645. [Google Scholar] [CrossRef]
- Deshmukh, N.P.; Kang, H.J.; Billings, S.D.; Taylor, R.H.; Hager, G.D.; Boctor, E.M. Elastography Using Multi-Stream GPU: An Application to Online Tracked Ultrasound Elastography, In-Vivo and the da Vinci Surgical System. PLoS ONE 2014, 9, 1–32. [Google Scholar] [CrossRef]
- Rosenzweig, S.; Palmeri, M.; Nightingale, K. GPU-based real-time small displacement estimation with ultrasound. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2011, 58, 399–405. [Google Scholar] [CrossRef]
- Chang, L.W.; Hsu, K.H.; Li, P.C. GPU-based color Doppler ultrasound processing. In Proceedings of the 2009 IEEE International Ultrasonics Symposium, Rome, Italy, 20–23 September 2009; pp. 1836–1839. [Google Scholar]
- Azar, R.Z.; Goksel, O.; Salcudean, S.E. Sub-sample displacement estimation from digitized ultrasound RF signals using multi-dimensional polynomial fitting of the cross-correlation function. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2010, 57, 2403–2420. [Google Scholar] [CrossRef]
- Liu, D.; Ebbini, E.S. Real-Time 2-D Temperature Imaging Using Ultrasound. IEEE Trans. Biomed. Eng. 2010, 57, 12–16. [Google Scholar]
- Peng, B.; Huang, L. A GPU-Accelerated High-quality Displacement Estimation Method and Its Applications in Strain Elastography. OptoElectron. Eng. 2016, 43, 83–88. [Google Scholar]
- Sengupta, S.; Harris, M.; Garland, M.; Owens, J. Efficient Parallel Scan Algorithms for GPUs. In Scientific Computing with Multicore and Accelerators; Taylor & Francis: Abingdon, UK, 2011; pp. 413–442. [Google Scholar]
- Blelloch, G.E. Scans as primitive parallel operations. IEEE Trans. Comput. 1989, 38, 1526–1538. [Google Scholar] [CrossRef]
- Varghese, T.; Ophir, J.; Céspedes, I. Noise reduction in elastograms using temporal stretching with multicompression averaging. Ultrasound Med. Biol. 1996, 22, 1043–1052. [Google Scholar] [CrossRef]
- Jiang, J.; Hall, T.J. A coupled subsample displacement estimation method for ultrasound-based strain elastography. Phys. Med. Biol. 2015, 60, 8347–8364. [Google Scholar] [CrossRef] [PubMed]
- Briechle, K.; Hanebeck, U.D. Template Matching Using Fast Normalized Cross Correlation. In Proceedings SPIE, Optical Pattern Recognition XII; SPIE: Bellingham, WA, USA, 2001; Volume 4387, pp. 95–102. [Google Scholar]







| Implementation Method | Computing Time (milliseconds) |
|---|---|
| Standard-NCC-CPU | 5760.0 ± 9.3 |
| Luo-Konofagou-CPU | 168.5 ± 2.2 |
| Lewis-CPU | 2120.0 ± 5.5 |
| Standard-NCC-GPU | 278.1 ± 0.9 |
| Luo-Konofagou-GPU | 159.9 ± 0.4 |
| Lewis-GPU | 225.2 ± 3.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, B.; Luo, S.; Xu, Z.; Jiang, J. Accelerating 3-D GPU-based Motion Tracking for Ultrasound Strain Elastography Using Sum-Tables: Analysis and Initial Results. Appl. Sci. 2019, 9, 1991. https://doi.org/10.3390/app9101991
Peng B, Luo S, Xu Z, Jiang J. Accelerating 3-D GPU-based Motion Tracking for Ultrasound Strain Elastography Using Sum-Tables: Analysis and Initial Results. Applied Sciences. 2019; 9(10):1991. https://doi.org/10.3390/app9101991
Chicago/Turabian StylePeng, Bo, Shasha Luo, Zhengqiu Xu, and Jingfeng Jiang. 2019. "Accelerating 3-D GPU-based Motion Tracking for Ultrasound Strain Elastography Using Sum-Tables: Analysis and Initial Results" Applied Sciences 9, no. 10: 1991. https://doi.org/10.3390/app9101991
APA StylePeng, B., Luo, S., Xu, Z., & Jiang, J. (2019). Accelerating 3-D GPU-based Motion Tracking for Ultrasound Strain Elastography Using Sum-Tables: Analysis and Initial Results. Applied Sciences, 9(10), 1991. https://doi.org/10.3390/app9101991