Identifying Brain Abnormalities with Schizophrenia Based on a Hybrid Feature Selection Technology


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Featured Application
Abstract
1. Introduction
2. Methodology
2.1. Feature Selection Methods Based on Machine Learning
2.1.1. Feature Selection with Support Vector Machine
| Algorithm 1: Support vector machine based on recursive feature elimination (SVMRFE) |
| Input: Dataset D |
| Process: |
| 1. Initialization |
| Let the current feature subset contain all features, and the optimal feature subset ; |
| 2. Training the classifier |
| Train a SVM on the training set with the , and evaluate the classification accuracy on the test set; |
| 3. Updating |
| Calculate the importance of each feature in by the scoring function (1), and eliminate features with the smallest score; |
| 4. Updating |
| If the accuracy rate of is greater than that of , then let ; |
| 5. Repeat Steps 2–4 until the stop condition is satisfied. |
| Output: The optimal feature subset |
2.1.2. Feature Selection with Random Forest
| Algorithm 2: Feature section with random forest by Gini importance (RFFS-GI) |
| Input: Dataset D; |
| Process: |
| 1. Randomly choose a feature i into the feature set; |
| 2. Calculate the Gini importance of all features in the feature set with the scoring function (3); |
| 3. Keep features with Gini importance above that of the feature i; |
| Output: Optimal feature subset |
| Algorithm 3: Feature section with random forest by the classification accuracy on the OOB data (RFFS-OOB) |
| Input: Dataset D |
| Process: |
| 1. Generate random forest; |
| 2. Calculate feature importance based the scoring function (4), and sort the scores; |
| 3. The top ranked features are selected as the optimal feature subset. |
| Output: Optimal feature subset. |
2.2. Feature Section Based on Statistical Methods
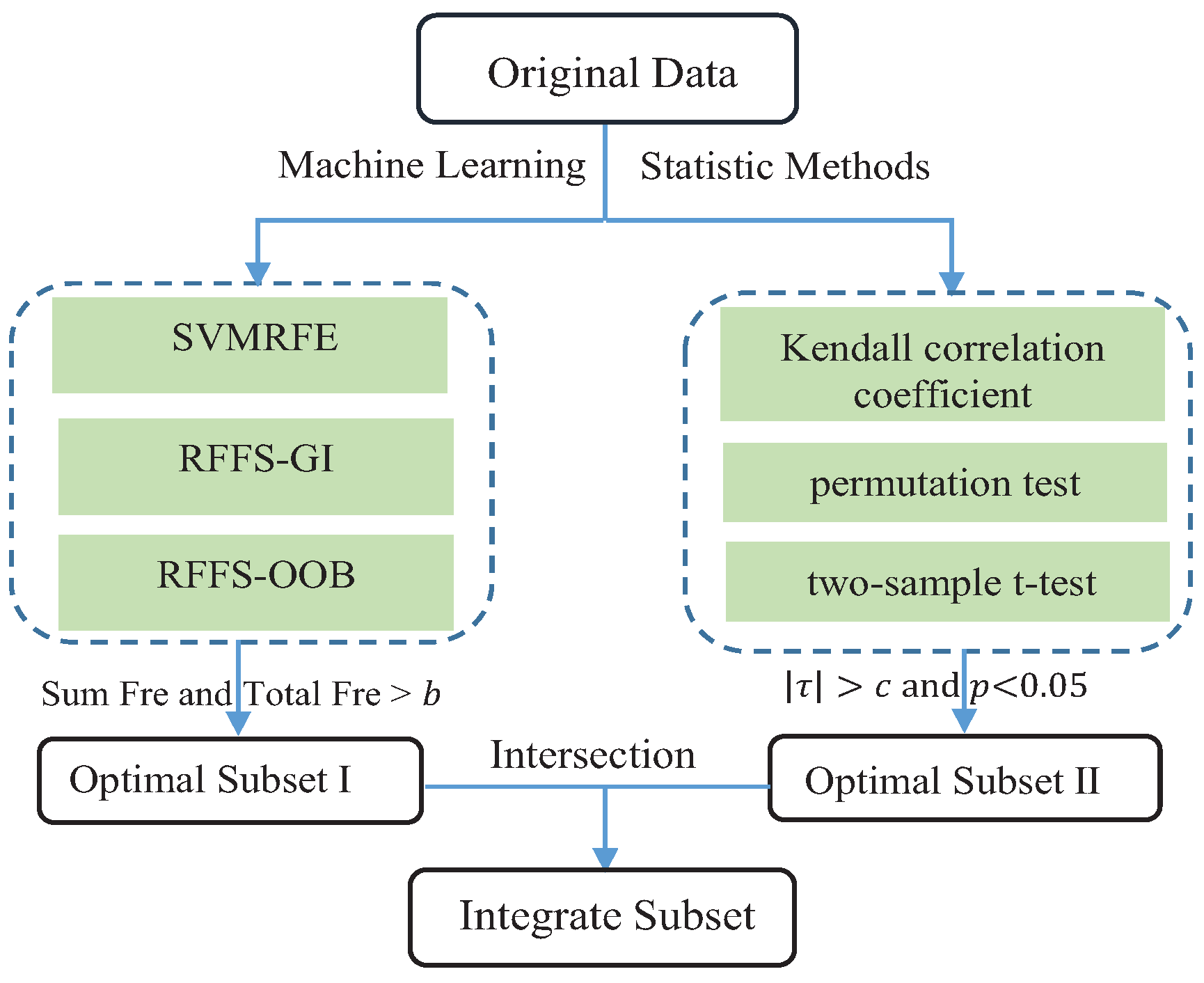
2.3. Hybrid Feature Selection Based on Both Machine Learning and Statistical Methods
2.4. Complex Network Analysis Based on Graph Theory
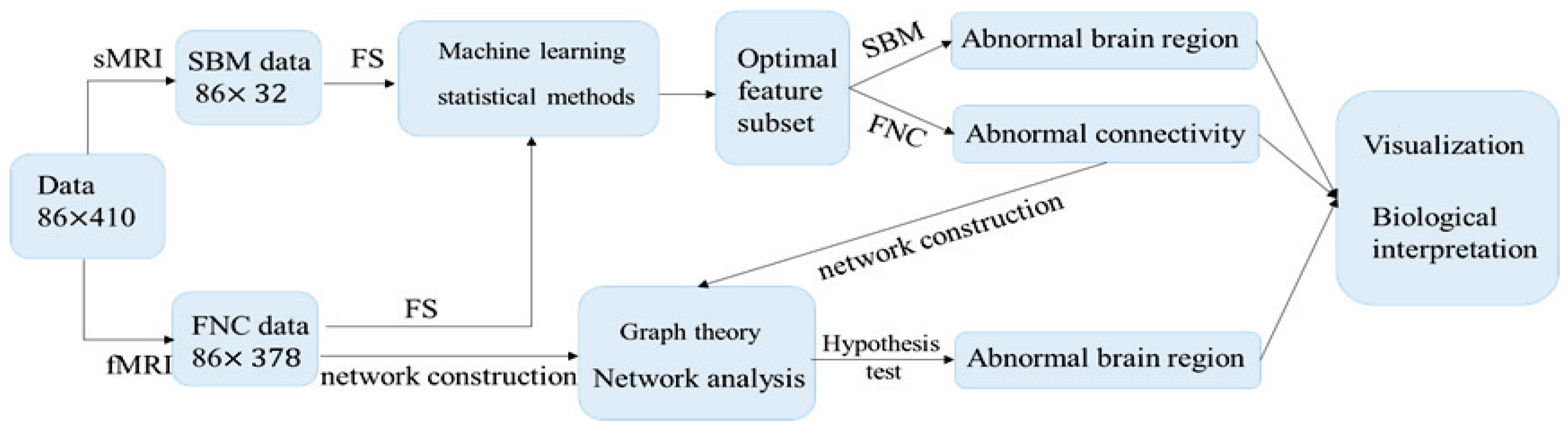
3. Experiments
3.1. Data Collection and Preprocessing
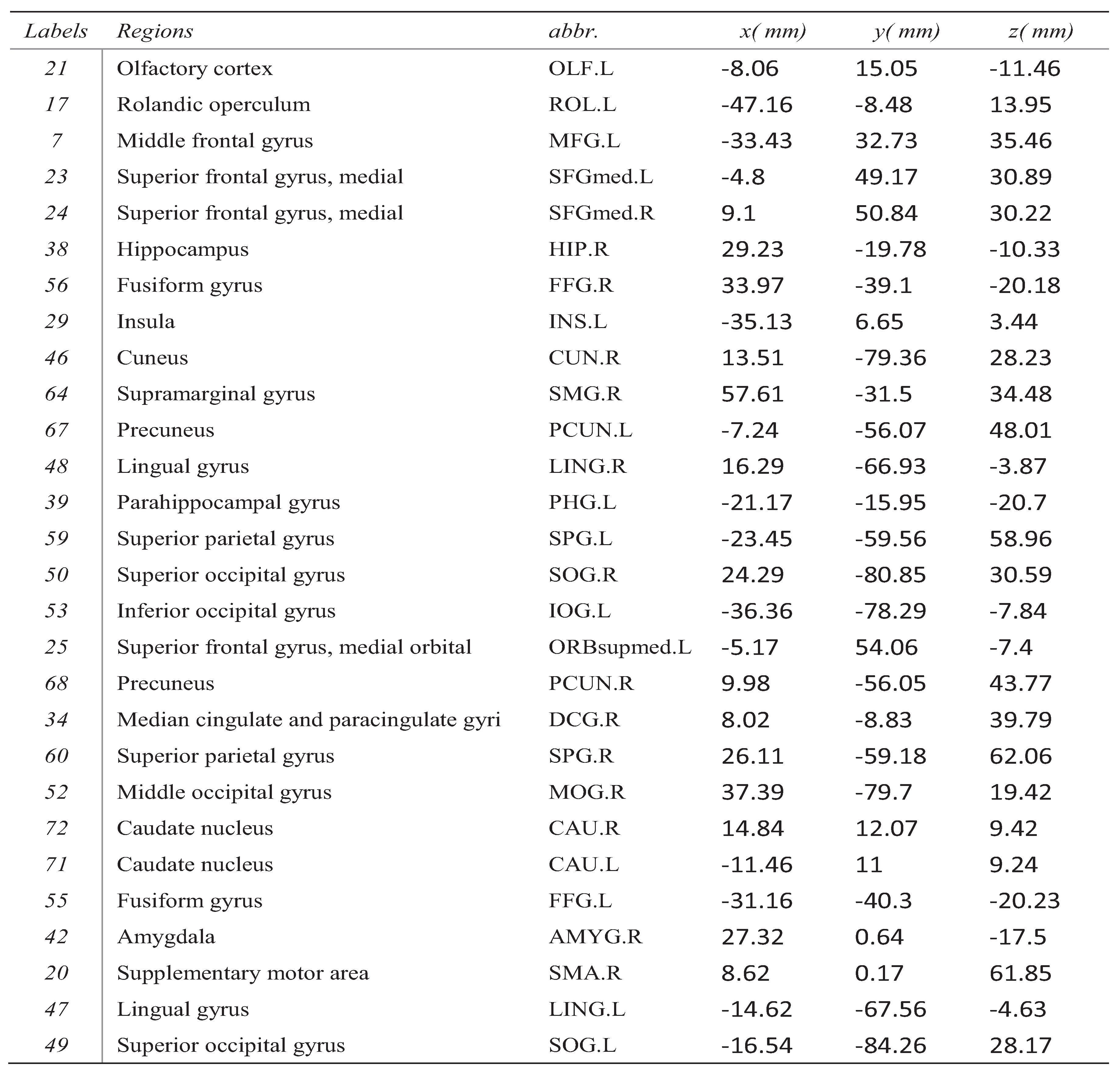
3.2. Locating the Abnormalities in Brains for SZ
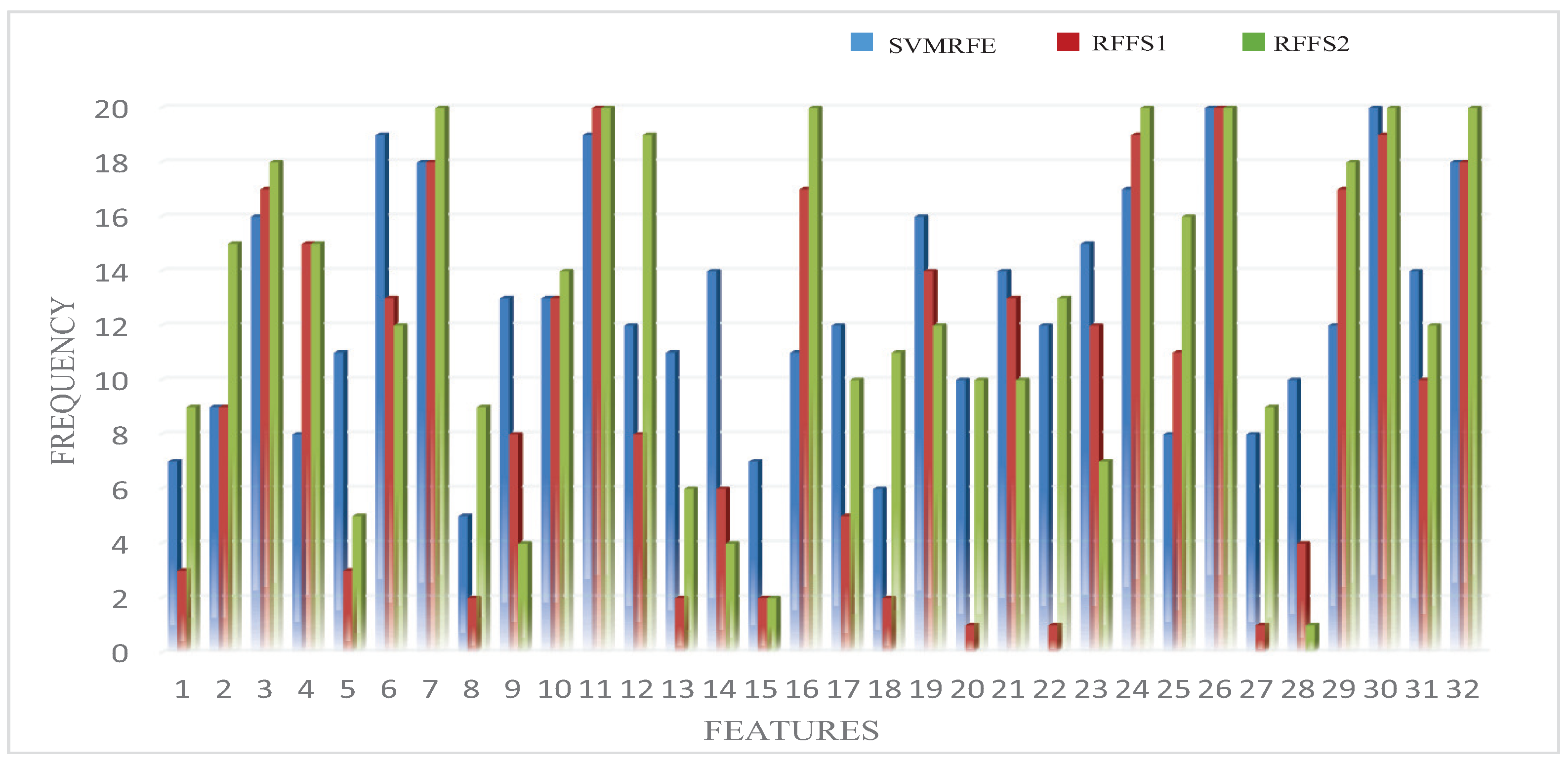
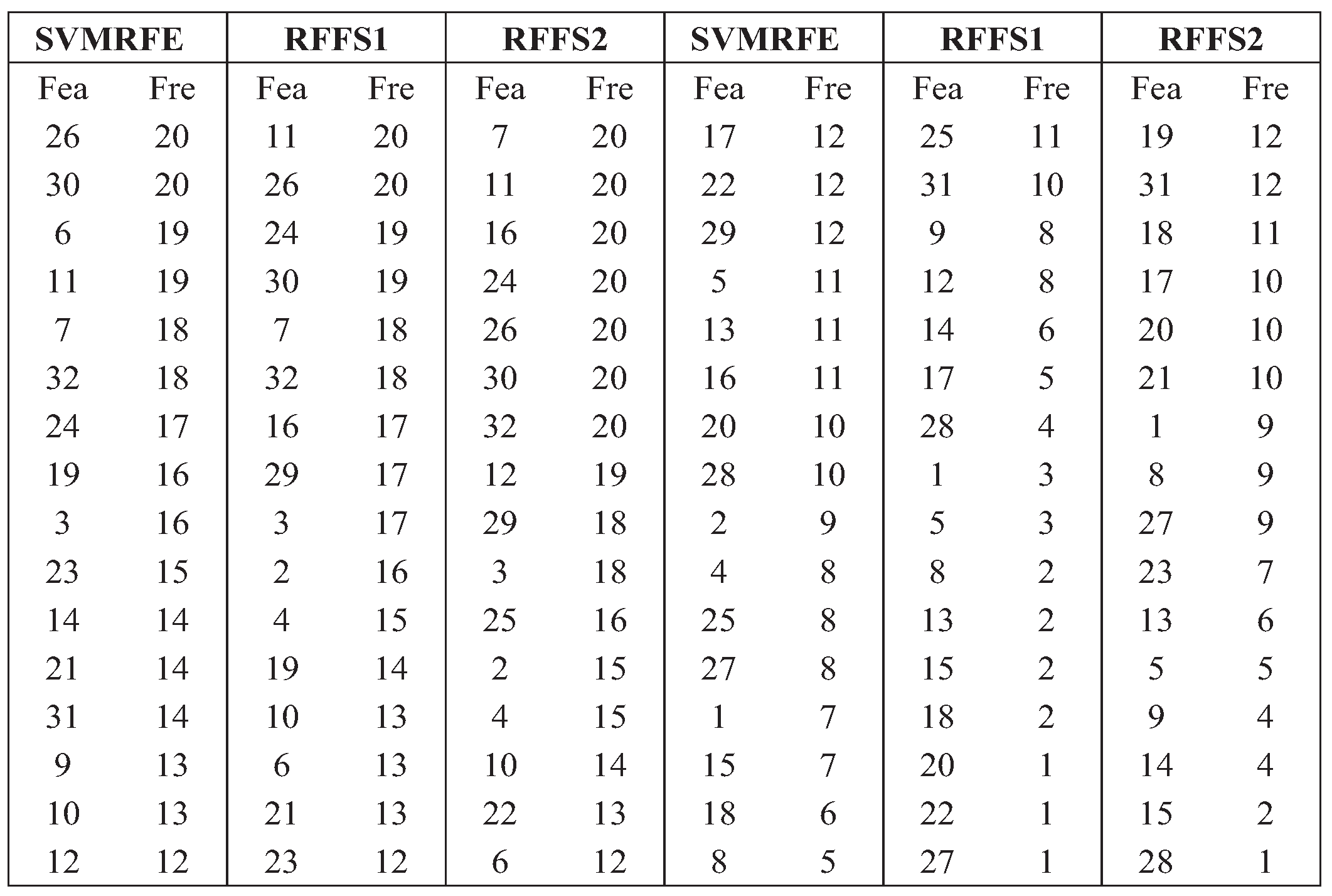
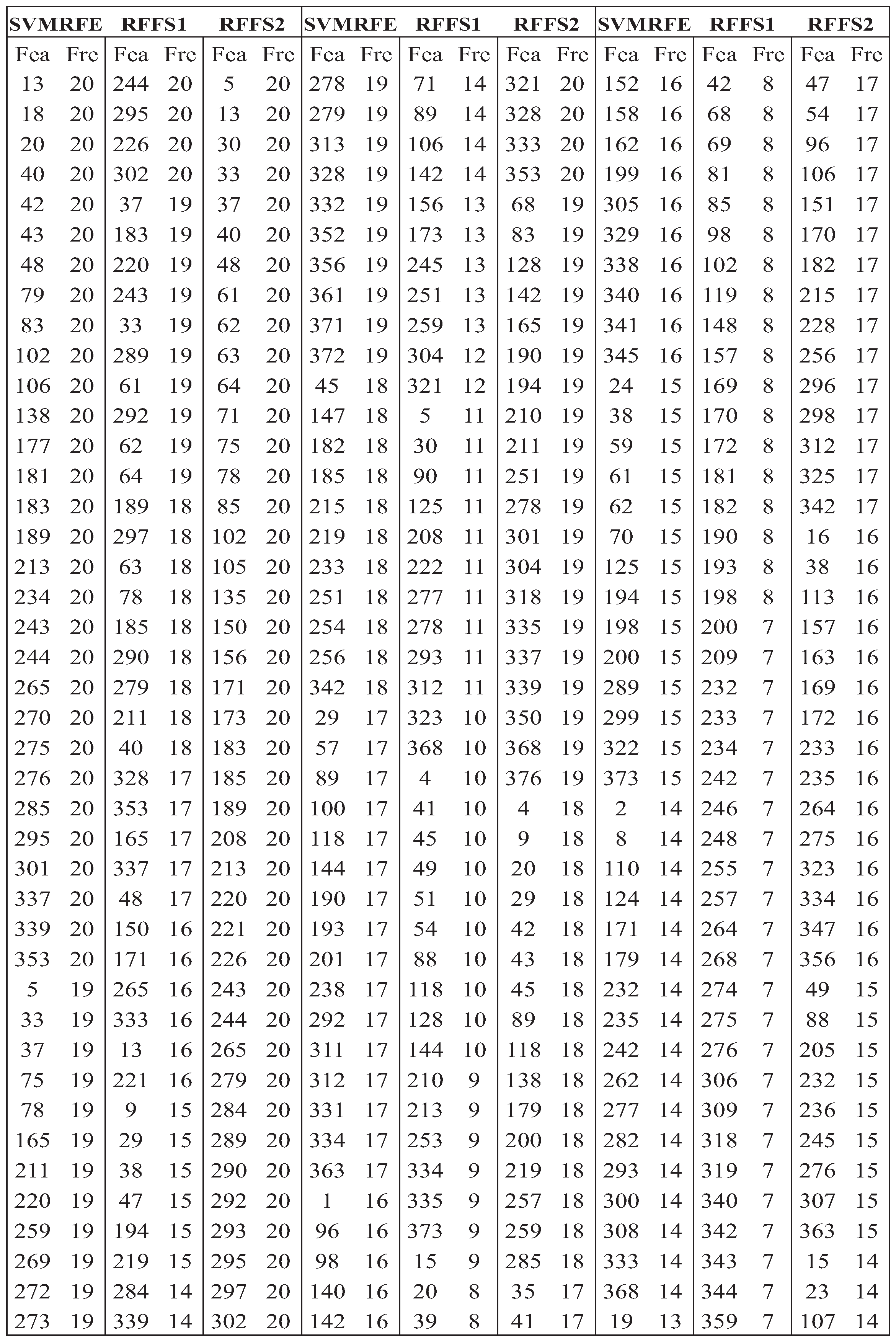
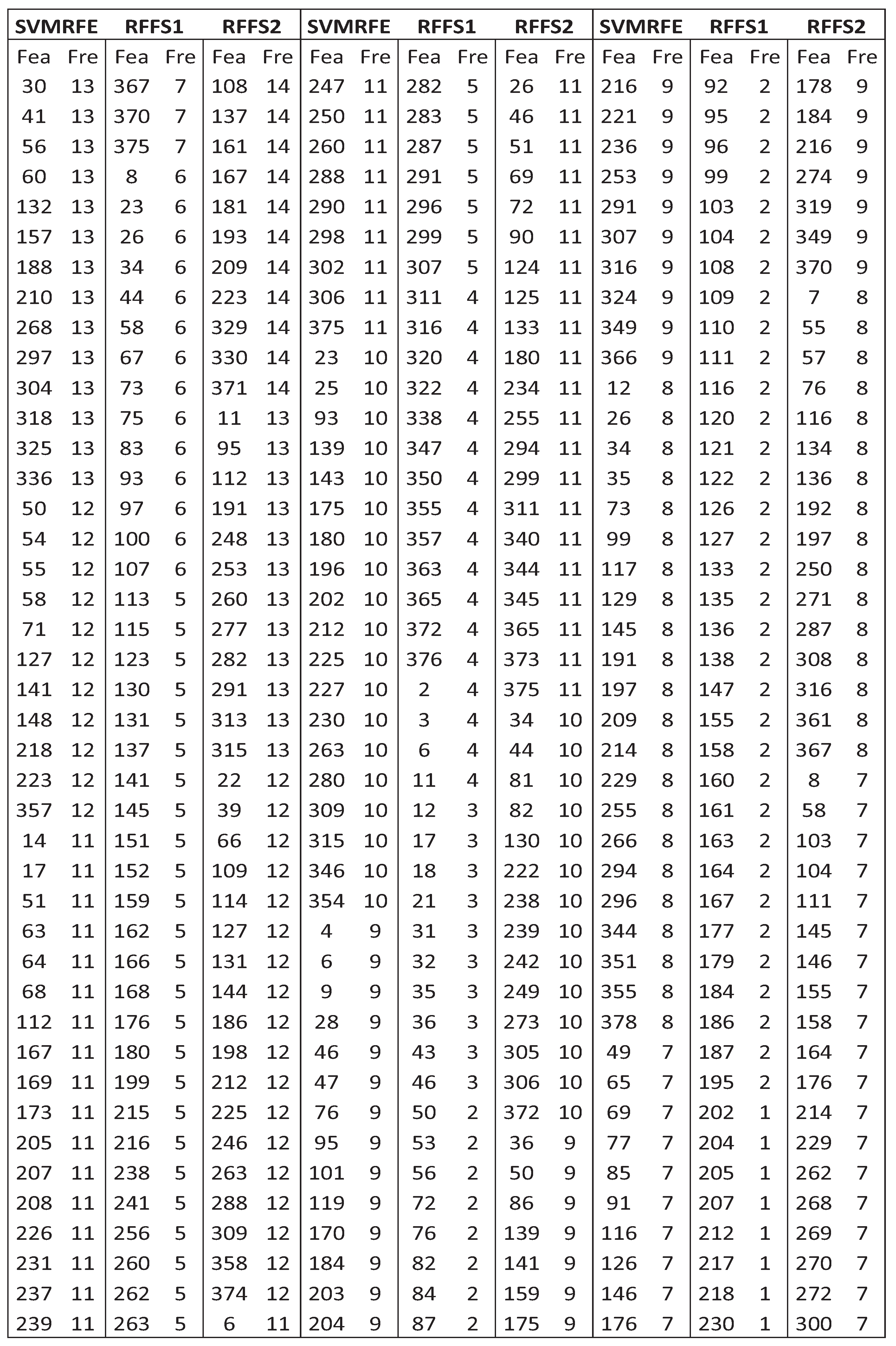
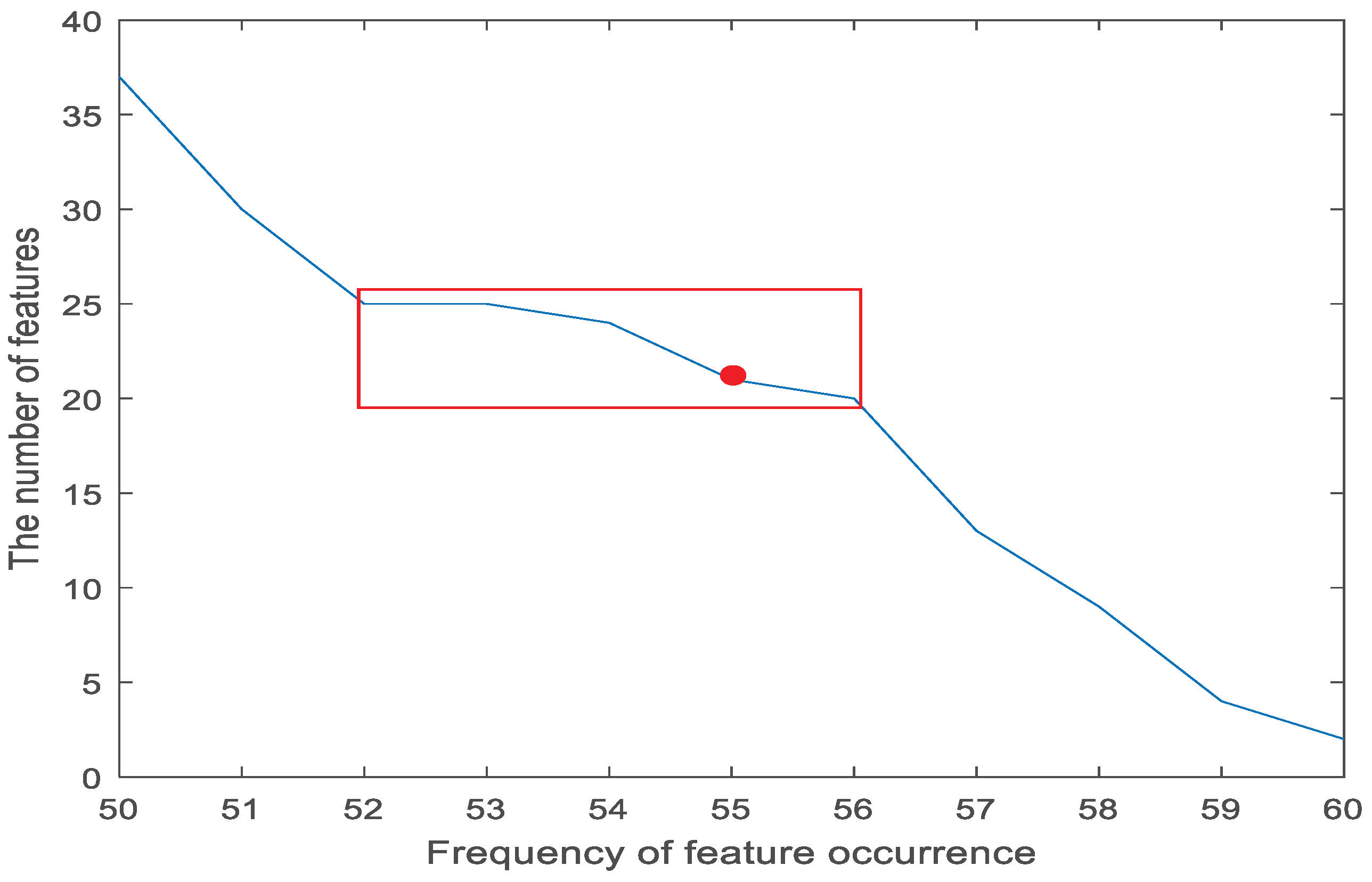
3.2.1. Feature Selection Results Based on Machine Learning Methods
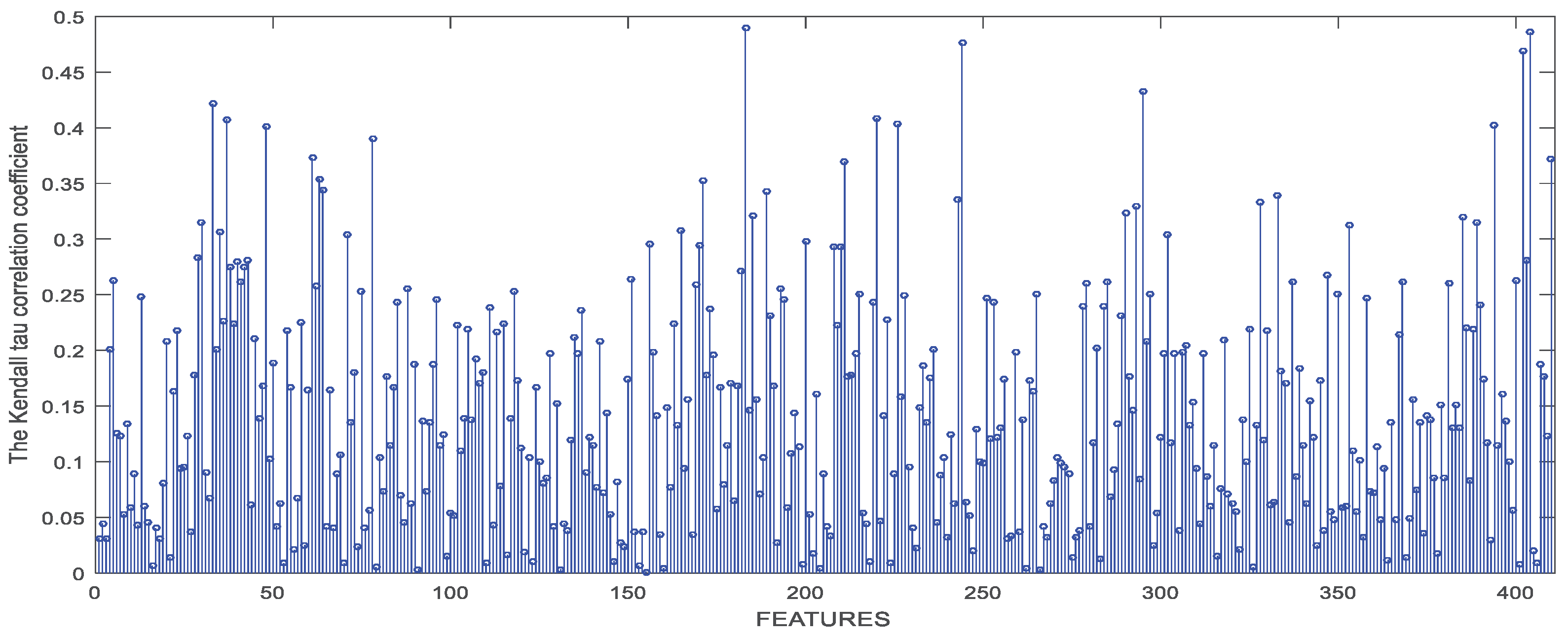
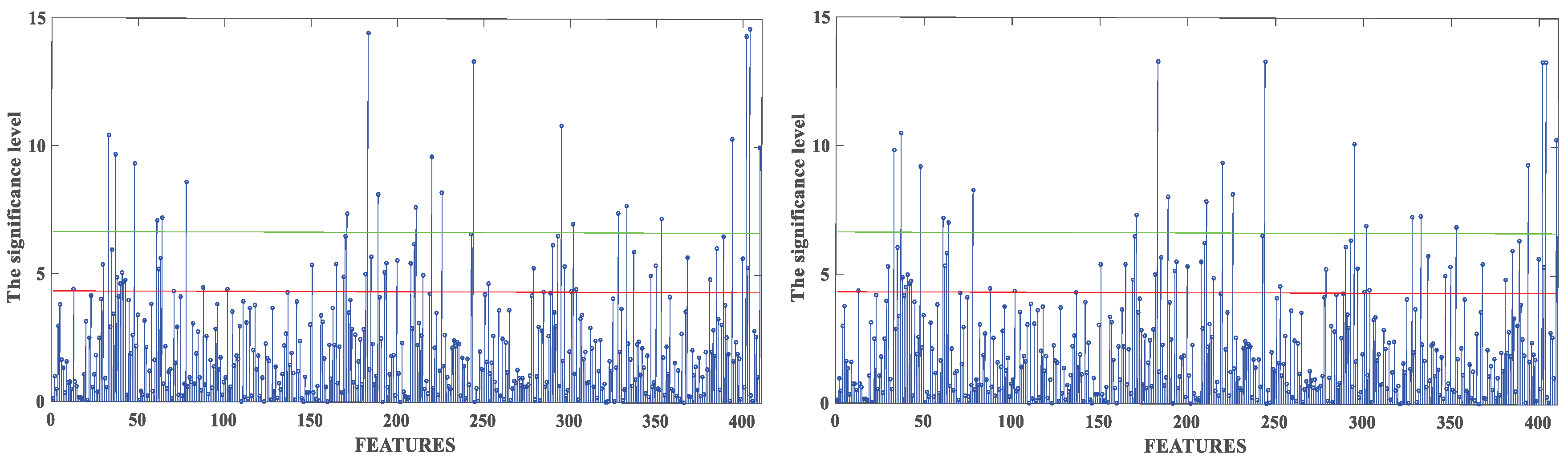
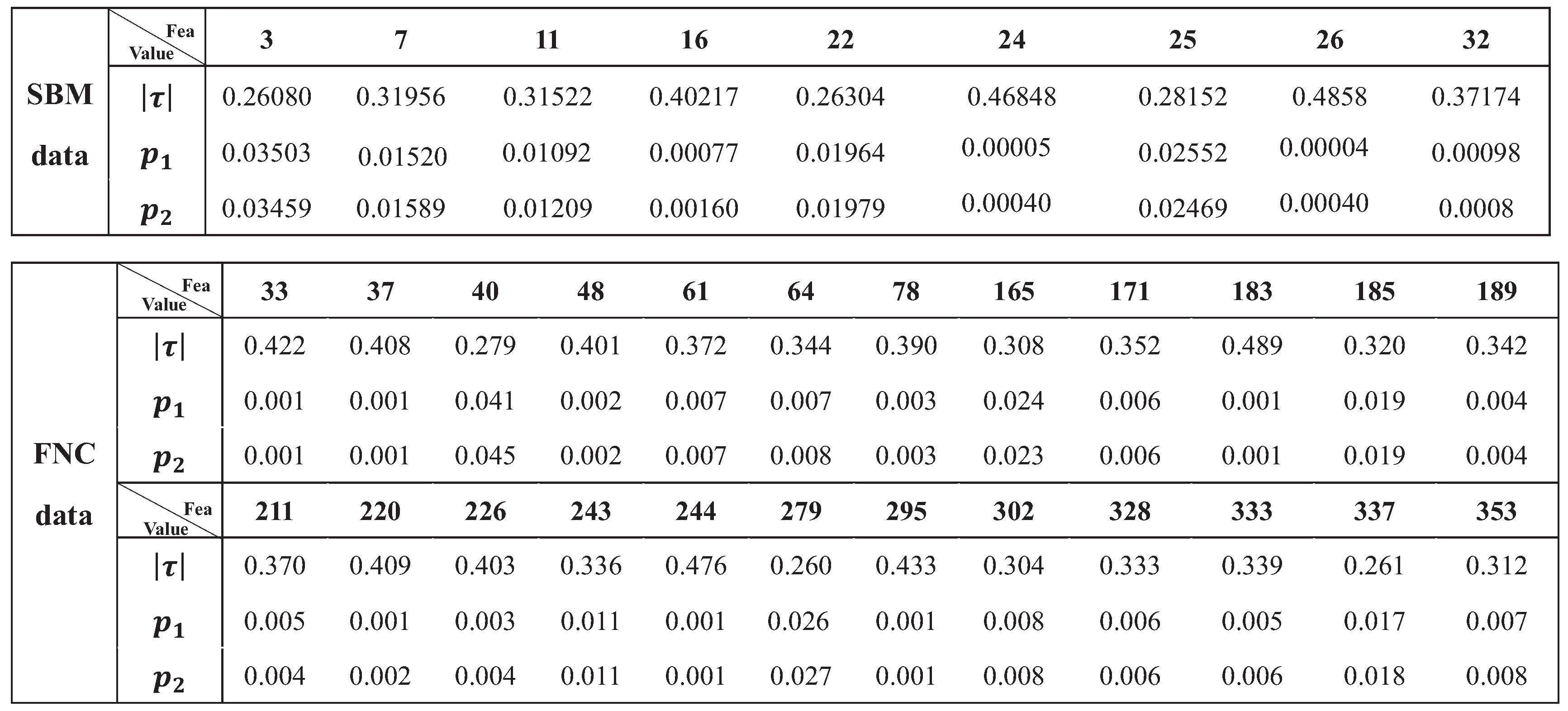
3.2.2. Feature Selection Results Based on Statistical Methods
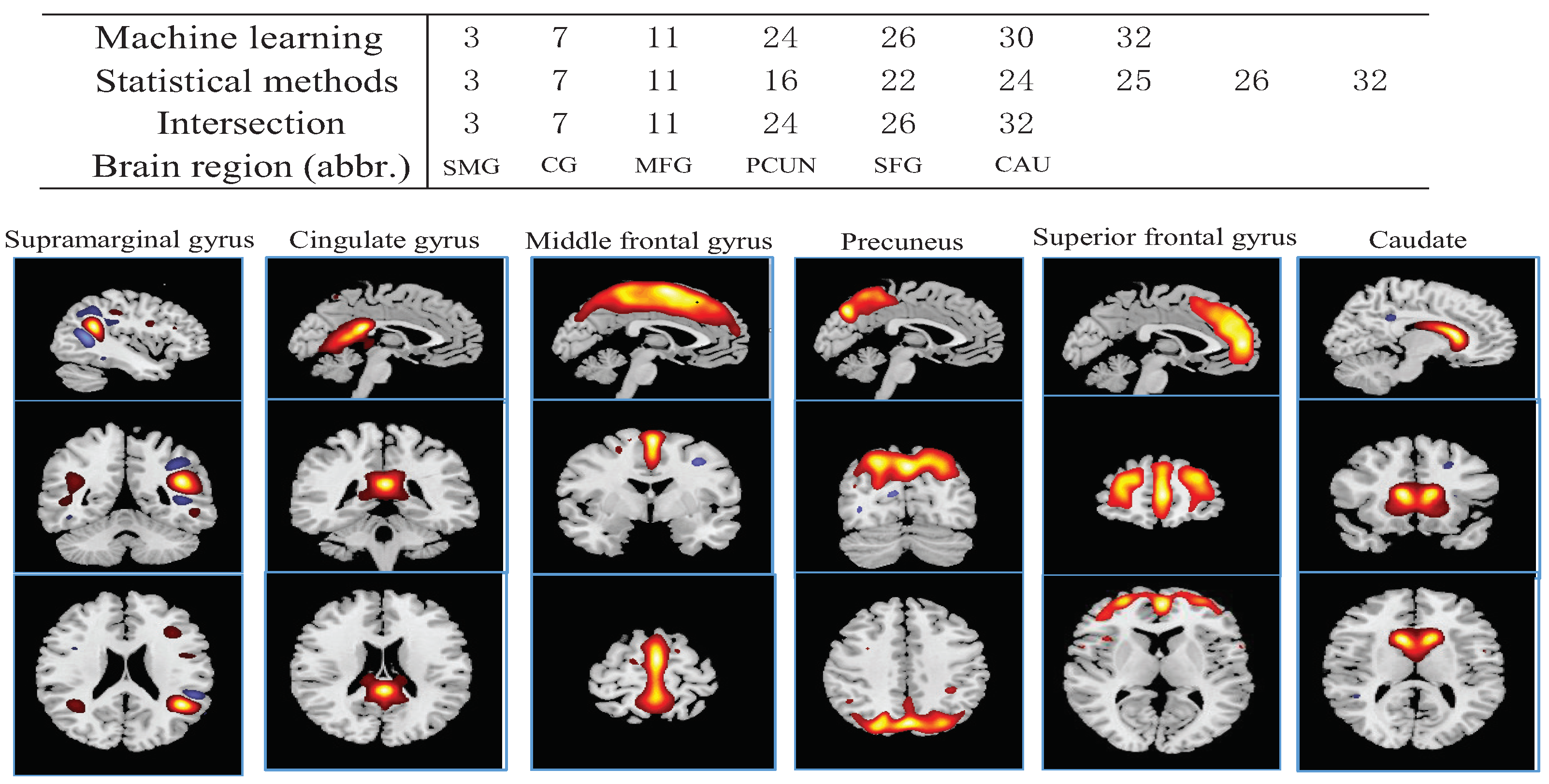
3.2.3. Feature Selection Results Based on a Hybrid Method
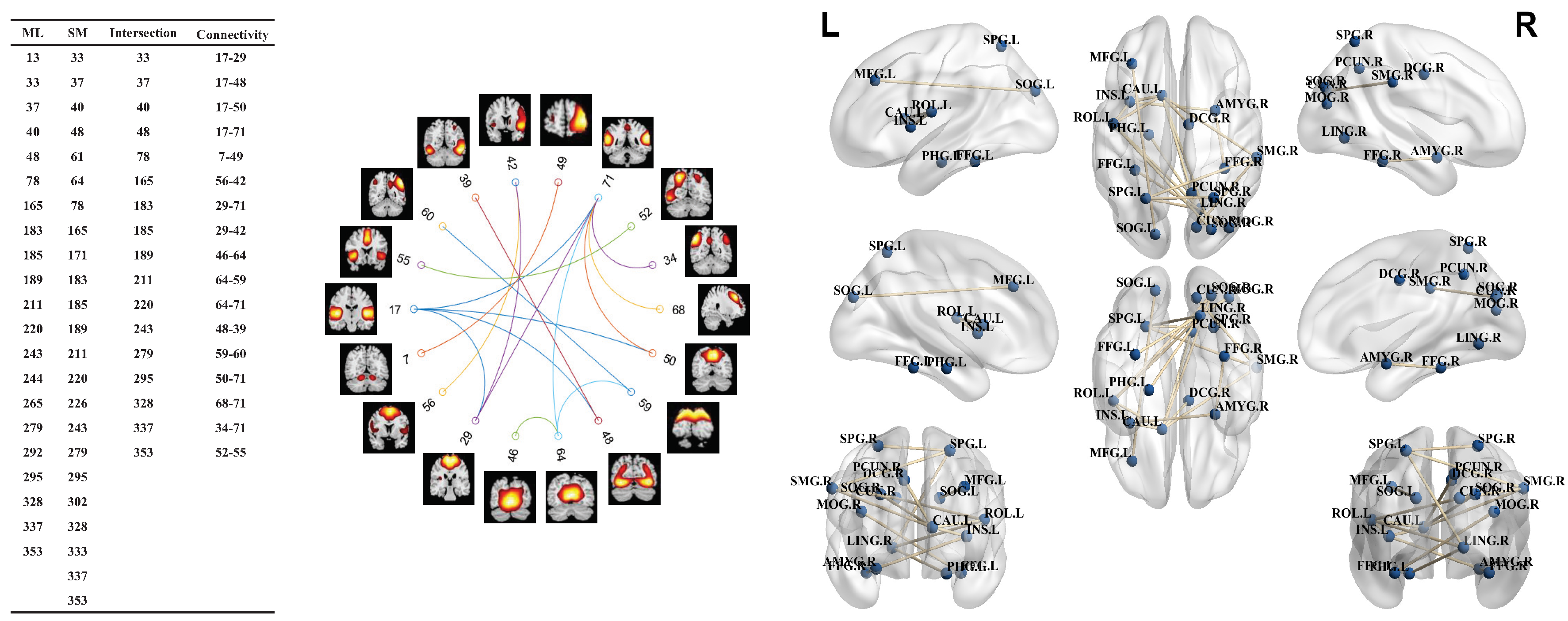
3.3. Network Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A








References
- Sui, J.; Qi, S.; van Erp, T.G.M.; Bustillo, J.; Jiang, R.; Lin, D.; Turner, J.A.; Damaraju, E.; Mayer, A.R.; Cui, Y.; et al. Multimodal neuromarkers in schizophrenia via cognition-guided MRI fusion. Nat. Commun. 2018, 9, 3028. [Google Scholar] [CrossRef] [PubMed]
- Mp, V.D.H.; Fornito, A. Brain networks in schizophrenia. Neuropsychol. Rev. 2014, 24, 32–48. [Google Scholar] [CrossRef]
- Woo, C.W.; Chang, L.J.; Lindquist, M.A.; Wager, T.D. Building better biomarkers: Brain models in translational neuroimaging. Nat. Neurosci. 2017, 20, 365–377. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Fryer, S.L.; Fu, Z.; Lin, D.; Sui, J.; Chen, J.; Damaraju, E.; Mennigen, E.; Stuart, B.; Mathalon, D.H.J.N. Dynamic functional connectivity impairments in early schizophrenia and clinical high-risk for psychosis. NeuroImage 2018, 180, 632–645. [Google Scholar] [CrossRef]
- Shine, J.M.; Bissett, P.G.; Bell, P.T.; Koyejo, O.; Balsters, J.H.; Gorgolewski, K.J.; Moodie, C.A.; Poldrack, R.A. The dynamics of functional brain networks: Integrated network states during cognitive task performance. Neuron 2016, 92, 544–554. [Google Scholar] [CrossRef]
- Rosenberg, M.D.; Finn, E.S.; Scheinost, D.; Papademetris, X.; Shen, X.; Constable, R.T.; Chun, M.M. A neuromarker of sustained attention from wholebrain functional connectivity. Nat. Neurosci. 2016, 19, 165–171. [Google Scholar] [CrossRef]
- Finn, E.S.; Shen, X.; Scheinost, D.; Rosenberg, M.D.; Huang, J.; Chun, M.M.; Papademetris, X.; Constable, R.T. Functional connectome fingerprinting: Identifying individuals using patterns of brain connectivity. Nat. Neurosci. 2015, 18, 1664–1671. [Google Scholar] [CrossRef] [PubMed]
- Palaniyappan, L.; Mahmood, J.; Balain, V.; Mougin, O.; Gowland, P.A.; Liddle, P.F. Structural correlates of formal thought disorder in schizophrenia: An ultra-high field multivariate morphometry study. Schizophr. Res. 2015, 168, 305–312. [Google Scholar] [CrossRef] [Green Version]
- Kong, Y.; Yu, T. A graph-embedded deep feedforward network for disease outcome classification and feature selection using gene expression data. Bioinformatics 2018, 34, 3727–3737. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suk, H.I.; Lee, S.W.; Shen, D. Deep ensemble learning of sparse regression models for brain disease diagnosis. Med. Image Anal. 2017, 37, 101–113. [Google Scholar] [CrossRef] [Green Version]
- Demirhan, A. The effect of feature selection on multivariate pattern analysis of structural brain MR images. Phys. Med. 2018, 47, 103–111. [Google Scholar] [CrossRef]
- Cao, F.; Liu, Y.; Wang, D. Efficient Saliency Detection Using Convolutional Neural Networks with Feature Selection. Inf. Sci. 2018, 456, 34–49. [Google Scholar] [CrossRef]
- Liu, Z.T.; Wu, M.; Cao, W.H.; Mao, J.W.; Tan, G.Z. Speech emotion recognition based on feature selection and extreme learning machine decision tree. Neurocomputing 2018, 273, 271–280. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Lazar, C.; Taminau, J.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C.; De, S.V.; Duque, R.; Bersini, H.; Nowé, A. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1106–1119. [Google Scholar] [CrossRef]
- Foithong, S.; Pinngern, O.; Attachoo, B. Feature subset selection wrapper based on mutual information and rough sets. Expert Syst. Appl. 2012, 39, 574–584. [Google Scholar] [CrossRef]
- Cadenas, J.M.; Garrido, M.C.; Martínez, R. Feature subset selection Filter-Wrapper based on low quality data. Expert Syst. Appl. 2013, 40, 6241–6252. [Google Scholar] [CrossRef]
- Shen, Q.; Diao, R.; Su, P. Feature Selection Ensemble. Turing 100 2012, 10, 289–306. [Google Scholar]
- Lu, H.; Chen, J.; Yan, K.; Jin, Q.; Xue, Y.; Gao, Z. A hybrid feature selection algorithm for gene expression data classification. Neurocomputing 2017, 256, 56–62. [Google Scholar] [CrossRef]
- Zhe, F.L. A Novel Hybrid Feature Selection Methods and Prediction for Ready Biodegradibility of Chemicals Using Random Forests and Boruta. In Proceedings of the 8th International Conference on Researches in Engineering, Technology and Sciences (ICRETS), Istanbul, Turkey, 13–14 August 2015. [Google Scholar]
- Lyu, H.; Wan, M.; Han, J.; Liu, R.; Wang, C. A filter feature selection method based on the Maximal Information Coefficient and Gram-Schmidt Orthogonalization for biomedical data mining. Comput. Biol. Med. 2017, 89, 264–274. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Miao, C.; Sun, Y.; Qin, X.; Li, H. A two-stage feature selection and intelligent fault diagnosis method for rotating machinery using hybrid Filter and Wrapper method. Neurocomputing 2017, 275, 2426–2439. [Google Scholar] [CrossRef]
- Moon, M.; Nakai, K. Stable feature selection based on the ensemble L1-norm support vector machine for biomarker discovery. BMC Genom. 2016, 17, 1026. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Yang, W.; Long, J.; Zhang, Y.; Feng, J.; Li, Y.; Huang, B. Discriminative analysis of Parkinson’s disease based on whole-brain functional connectivity. PLoS ONE 2015, 10, e0124153. [Google Scholar] [CrossRef] [PubMed]
- Zeng, L.L.; Shen, H.; Liu, L.; Wang, L.; Li, B.; Fang, P.; Zhou, Z.; Li, Y.; Hu, D. Identifying major depression using whole-brain functional connectivity: A multivariate pattern analysis. Brain J. Neurol. 2012, 135, 1498–1507. [Google Scholar] [CrossRef]
- Haznedar, M.M.; Buchsbaum, M.S.; Hazlett, E.A.; Shihabuddin, L.; New, A.; Siever, L.J. Cingulate gyrus volume and metabolism in the schizophrenia spectrum. Schizophr. Res. 2004, 71, 249–262. [Google Scholar] [CrossRef]
- Calabrese, D.R.; Wang, L.; Harms, M.P.; Ratnanather, J.T.; Barch, D.M.; Cloninger, C.R.; Thompson, P.A.; Miller, M.I.; Csernansky, J.G. Cingulate gyrus neuroanatomy in schizophrenia subjects and their non-psychotic siblings. Schizophr. Res. 2008, 104, 61–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shah, C.; Zhang, W.; Xiao, Y.; Yao, L.; Zhao, Y.; Gao, X.; Liu, L.; Liu, J.; Li, S.; Tao, B. Common pattern of gray-matter abnormalities in drug-naive and medicated first-episode schizophrenia: A multimodal meta-analysis. Psychol. Med. 2016, 47, 401–413. [Google Scholar] [CrossRef]
- Chang, M.; Womer, F.Y.; Bai, C.; Zhou, Q.; Wei, S.; Jiang, X.; Geng, H.; Zhou, Y.; Tang, Y.; Wang, F. Voxel-Based Morphometry in Individuals at Genetic High Risk for Schizophrenia and Patients with Schizophrenia during Their First Episode of Psychosis. PLoS ONE 2016, 11, e0163749. [Google Scholar] [CrossRef]
- Liang, M.; Zhou, Y.; Jiang, T.; Liu, Z.; Tian, L.; Liu, H.; Hao, Y. Widespread functional disconnectivity in schizophrenia with resting-state functional magnetic resonance imaging. Neuroreport 2006, 17, 209–213. [Google Scholar] [CrossRef]
- Xu, Y.; Qin, W.; Zhuo, C.; Xu, L.; Zhu, J.; Liu, X.; Yu, C. Selective functional disconnection of the orbitofrontal subregions in schizophrenia. Psychol. Med. 2017, 47, 1637–1646. [Google Scholar] [CrossRef]
- Zhang, D.; Guo, L.; Hu, X.; Li, K.; Zhao, Q.; Liu, T. Increased cortico-subcortical functional connectivity in schizophrenia. Brain Imaging Behav. 2012, 6, 27–35. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Martino, F.D.; Valente, G.; Staeren, N.; Ashburner, J.; Goebel, R.; Formisano, E. Combining multivariate voxel selection and support vector machines for mapping and classification of fMRI spatial patterns. NeuroImage 2008, 43, 44–58. [Google Scholar] [CrossRef] [PubMed]
- You, W.; Yang, Z.; Ji, G. PLS-based recursive feature elimination for high-dimensional small sample. Knowl.-Based Syst. 2014, 55, 15–28. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sens. Actuators B Chem. 2015, 212, 353–363. [Google Scholar] [CrossRef]
- Huang, M.L.; Hung, Y.H.; Lee, W.M.; Li, R.K.; Jiang, B.R. SVM-RFE based feature selection and Taguchi parameters optimization for multiclass SVM classifier. Sci. World J. 2014, 2014, 795624. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Sharmila, D.J.S.; Singh, S. SVMRFE based approach for prediction of most discriminatory gene target for type II diabetes. Genom. Data 2017, 12, 28–37. [Google Scholar] [CrossRef] [PubMed]
- Ho, T.K. Random Decision Forests. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; p. 827. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.S.; Rahman, M.K.; Kaykobad, M.; Rahman, M.S. isGPT: An optimized model to identify sub-Golgi protein types using SVM and Random Forest based feature selection. Artif. Intell. Med. 2017, 84, 90–100. [Google Scholar] [CrossRef]
- Zhou, Q.; Hao, Z.; Zhou, Q.; Fan, Y.; Luo, L. Structure damage detection based on random forest recursive feature elimination. Mech. Syst. Signal Process. 2014, 46, 82–90. [Google Scholar] [CrossRef]
- Yao, D.J.; Yang, J.; Zhan, X.J. Feature selection algorithm based on random forest. J. Jilin Univ. 2014, 44, 137–141. [Google Scholar] [CrossRef]
- Nanthagopal, A.P.; Sukanesh, R. Wavelet statistical texture features-based segmentation and classification of brain computed tomography images. IET Image Process. 2013, 7, 25–32. [Google Scholar] [CrossRef]
- Mehlhorn, H.; Schreiber, F. Small-World Property. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 1957–1959. [Google Scholar]
- Mittal, V.A.; Walker, E.F. Diagnostic and Statistical Manual of Mental Disorders. Psychiatry Res. 2011, 189, 158–159. [Google Scholar] [CrossRef] [Green Version]
- Segall, J.M.; Allen, E.A.; Jung, R.E.; Erhardt, E.B.; Arja, S.K.; Kiehl, K.; Calhoun, V.D. Correspondence between structure and function in the human brain at rest. Front. Neuroinform. 2012, 6, 10. [Google Scholar] [CrossRef] [Green Version]
- Allen, E.A.; Erhardt, E.B.; Damaraju, E.; Gruner, W.; Segall, J.M.; Silva, R.F.; Havlicek, M.; Rachakonda, S.; Fries, J.; Kalyanam, R.; et al. A baseline for the multivariate comparison of resting-state networks. Front. Syst. Neurosci. 2011, 5, 2. [Google Scholar] [CrossRef]
- Xia, M.; Wang, J.; He, Y. BrainNet Viewer: A network visualization tool for human brain connectomics. PLoS ONE 2013, 8, e68910. [Google Scholar] [CrossRef]
- Xia, M.; Womer, F.Y.; Chang, M.; Zhu, Y.; Zhou, Q.; Edmiston, E.K.; Jiang, X.; Wei, S.; Duan, J.; Xu, K. Shared and Distinct Functional Architectures of Brain Networks Across Psychiatric Disorders. Schizophr. Bull. 2018, 45, 450–463. [Google Scholar] [CrossRef]
- Yong, L.; Meng, L.; Yuan, Z.; Yong, H.; Yihui, H.; Ming, S.; Chunshui, Y.; Haihong, L.; Zhening, L.; Tianzi, J. Disrupted small-world networks in schizophrenia. Brain 2008, 131, 945–961. [Google Scholar] [CrossRef] [Green Version]
- Benes, F.M. Evidence for neurodevelopment disturbances in anterior cingulate cortex of post-mortem schizophrenic brain. Schizophr. Res. 1991, 5, 187–188. [Google Scholar] [CrossRef]
- Mirjalili, M.; Hossein-Zadeh, G.-A. Characterization of schizophrenia by linear kernel canonical correlation analysis of resting-state functional MRI and structural MRI. In Proceedings of the 2017 7th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 26–27 October 2017; pp. 37–41. [Google Scholar]
- Calderone, D.J.; Hoptman, M.J.; Antígona, M.; Sangeeta, N.C.; Mauro, C.J.; Moshe, B.; Javitt, D.C.; Butler, P.D. Contributions of low and high spatial frequency processing to impaired object recognition circuitry in schizophrenia. Cerebr. Cortex 2013, 23, 1849–1858. [Google Scholar] [CrossRef]
- Susan, W.G.; Thermenos, H.W.; Snezana, M.; Tsuang, M.T.; Faraone, S.V.; Mccarley, R.W.; Shenton, M.E.; Green, A.I.; Alfonso, N.C.; Peter, L.V.; et al. Hyperactivity and hyperconnectivity of the default network in schizophrenia and in first-degree relatives of persons with schizophrenia. Proc. Natl. Acad. Sci. USA 2009, 106, 1279–1284. [Google Scholar] [CrossRef] [Green Version]
- Corr, P.J. Reinforcement sensitivity theory and personality. Neurosci. Biobehav. Rev. 2004, 28, 317–332. [Google Scholar] [CrossRef] [PubMed]
- Jylhä, P.; Isometsä, E. Temperament, character and symptoms of anxiety and depression in the general population. Eur. Psychiatry 2006, 21, 389–395. [Google Scholar] [CrossRef]
- Van Schuerbeek, P.; Baeken, C.; De Raedt, R.; De Mey, J.; Luypaert, R. Individual differences in local gray and white matter volumes reflect differences in temperament and character: A voxel-based morphometry study in healthy young females. Brain Res. 2011, 1371, 32–42. [Google Scholar] [CrossRef] [PubMed]
- Trimble, M. Molecular neuropharmacology, a foundation for clinical neuroscience. Psychiatry 2002, 73, 210. [Google Scholar] [CrossRef]
- Qingbao, Y.; Allen, E.A.; Jing, S.; Arbabshirani, M.R.; Godfrey, P.; Calhoun, V.D. Brain connectivity networks in schizophrenia underlying resting state functional magnetic resonance imaging. Curr. Top. Med. Chem. 2012, 12, 2415–2425. [Google Scholar] [CrossRef]
- Gaudio, S.; Wiemerslage, L.; Brooks, S.J.; Schiöth, H.B. A systematic review of resting-state functional-MRI studies in anorexia nervosa: Evidence for functional connectivity impairment in cognitive control and visuospatial and body-signal integration. Neurosci. Biobehav. Rev. 2016, 71, 578–589. [Google Scholar] [CrossRef]
- Wu, C.; Zheng, Y.; Li, J.; Wu, H.; She, S.; Liu, S.; Ning, Y.; Li, L. Brain substrates underlying auditory speech priming in healthy listeners and listeners with schizophrenia. Psychol. Med. 2016, 47, 837–852. [Google Scholar] [CrossRef] [Green Version]
- Qiu, L.; Yan, H.; Zhu, R.; Yan, J.; Yuan, H.; Han, Y.; Yue, W.; Tian, L.; Zhang, D. Correlations between exploratory eye movement, hallucination, and cortical gray matter volume in people with schizophrenia. BMC Psychiatry 2018, 18, 226. [Google Scholar] [CrossRef]
- Viher, P.; Walther, S. SU67. Aberrant Resting-State Functional Connectivity in the Motor System and Motor Abnormalities in Schizophrenia. Schizophr. Bull. 2017, 43, S185–S186. [Google Scholar] [CrossRef] [Green Version]
- Sha, Z.; Wager, T.D.; Mechelli, A.; He, Y. Common Dysfunction of Large-Scale Neurocognitive Networks Across Psychiatric Disorders. Biol. Psychiatry 2019, 85, 379–388. [Google Scholar] [CrossRef] [PubMed]
- Anticevic, A.; Cole, M.W.; Murray, J.D.; Corlett, P.R.; Wang, X.-J.; Krystal, J.H. The role of default network deactivation in cognition and disease. Trends Cogn. Sci. 2012, 16, 584–592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Menon, V. Large-scale brain networks and psychopathology: A unifying triple network model. Trends Cogn. Sci. 2011, 15, 483–506. [Google Scholar] [CrossRef]
- Wager, T.D.; Smith, E.E. Neuroimaging studies of working memory. Cogn. Affect. Behav. Neurosci. 2003, 3, 255–274. [Google Scholar] [CrossRef]
- Wu, L.; Caprihan, A.; Bustillo, J.; Mayer, A.; Calhoun, V. An approach to directly link ICA and seed-based functional connectivity: Application to schizophrenia. NeuroImage 2018, 179, 448–470. [Google Scholar] [CrossRef]









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, C.; Lu, L.; Yang, L.; Kennedy, P.J. Identifying Brain Abnormalities with Schizophrenia Based on a Hybrid Feature Selection Technology. Appl. Sci. 2019, 9, 2148. https://doi.org/10.3390/app9102148
Qiao C, Lu L, Yang L, Kennedy PJ. Identifying Brain Abnormalities with Schizophrenia Based on a Hybrid Feature Selection Technology. Applied Sciences. 2019; 9(10):2148. https://doi.org/10.3390/app9102148
Chicago/Turabian StyleQiao, Chen, Lujia Lu, Lan Yang, and Paul J. Kennedy. 2019. "Identifying Brain Abnormalities with Schizophrenia Based on a Hybrid Feature Selection Technology" Applied Sciences 9, no. 10: 2148. https://doi.org/10.3390/app9102148
APA StyleQiao, C., Lu, L., Yang, L., & Kennedy, P. J. (2019). Identifying Brain Abnormalities with Schizophrenia Based on a Hybrid Feature Selection Technology. Applied Sciences, 9(10), 2148. https://doi.org/10.3390/app9102148