Image-to-Image Translation Using Identical-Pair Adversarial Networks



Abstract
:1. Introduction
- Identical-pair adversarial networks as a new conditional adversarial networks approach are proposed.
- A perceptual similarity network is used as the discriminative network D to distinguish between the real and fake identical-pairs.
- We propose deep feature distance as a perceptual loss to penalize the discrepancy between the two inputs of discriminative network D.
- We extend our work to unpair image-to-image translation by introducing our iPANs to cycleGAN’s framework, respectively.
2. Related Work
3. Methods
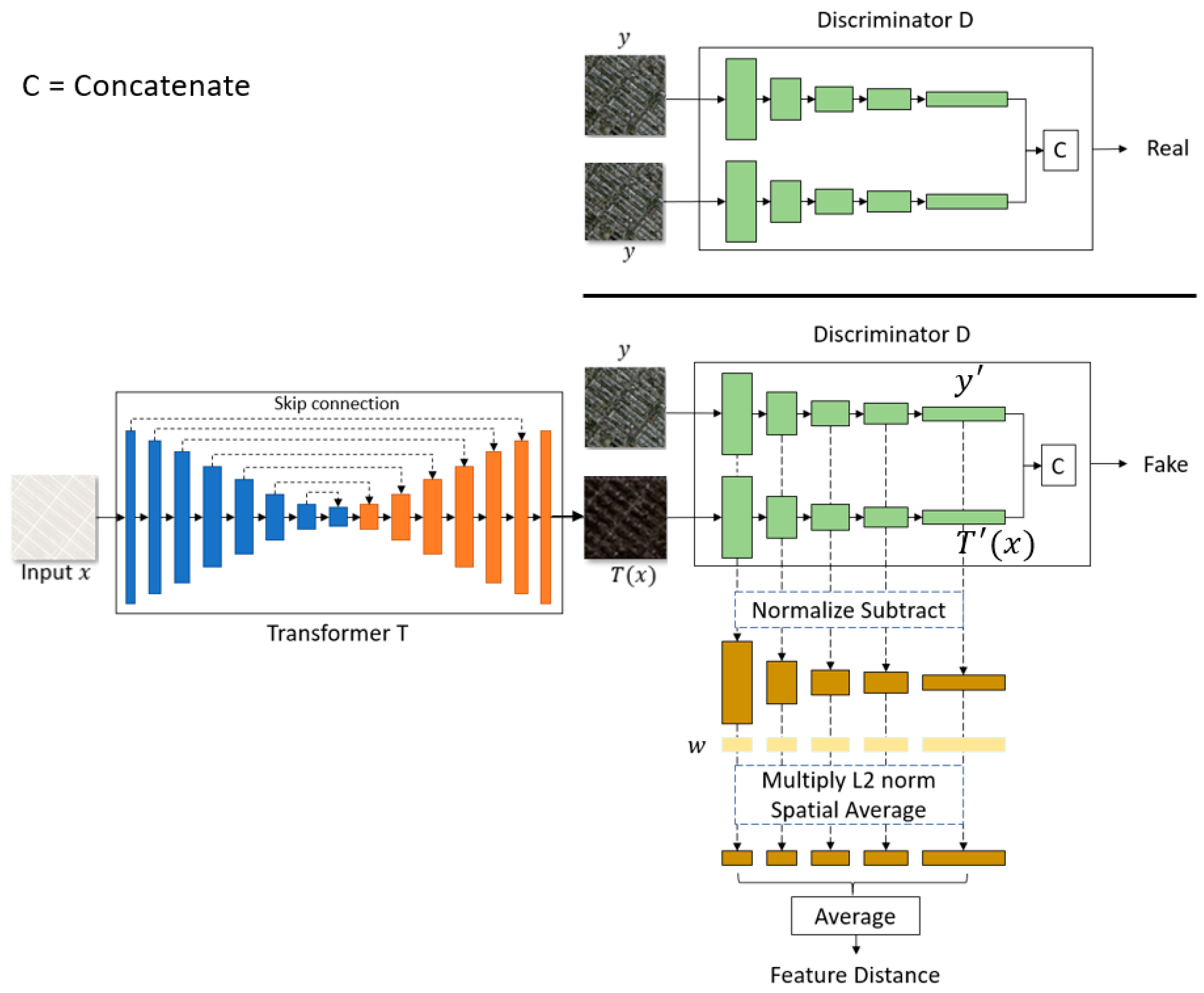
3.1. Proposed Network Architecture
- Training the image transformation network T
- Input image x through T: x → T(x)
- Input T(x) and y through D: T(x), y → D(T(x), y)
- Find loss: L(T) (See Section 3.2)
- Find perceptual loss: Lp (see Section 3.2)
- Total loss: L(T) + Lp
- Backpropagation and update T
- Training discriminative network D
- Input T(x) and y through D: T(x), y → D(T(x), y)
- Find loss: Lfake (See Section 3.2)
- Input duplicate y through D: y, y → D(y, y)
- Find loss Lreal (See Section 3.2)
- Total loss: (Lfake + Lreal)/2
- Backpropagation and update D
3.2. Proposed Loss Functions
4. Experiments and Results
4.1. Experimental Setup
- Dataset from pix2pix for Edges→images, Aerials→images, Labels→facades
- The dataset from BicycleGANs for Night→day
- The dataset from ID-cGANs for De-raining
4.2. Experimental Results
5. Extension to Unpaired Image Translation
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image Inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2002; pp. 417–424. [Google Scholar]
- Luan, Q.; Wen, F.; Cohen-Or, D.; Liang, L.; Xu, Y.-Q.; Shum, H.-Y. Natural image colorization. In Proceedings of the 18th Eurographics Conference on Rendering Techniques, Grenoble, France, 25–27 June 2007; pp. 309–320. [Google Scholar]
- Nasrollahi, K.; Moeslund, T.B. Applications. Super-resolution: A comprehensive survey. Mach. Vis. 2014, 25, 1423–1468. [Google Scholar] [CrossRef]
- Khan, M.W. A survey: Image segmentation techniques. Int. J. Future Comput. 2014, 3, 89. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Miyato, T.; Koyama, M. cGANs with projection discriminator. arXiv 2018, arXiv:1802.05637. [Google Scholar]
- Wang, C.; Xu, C.; Wang, C.; Tao, D. Perceptual adversarial networks for image-to-image transformation. IEEE Trans. Image Process. 2018, 27, 4066–4079. [Google Scholar] [CrossRef]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Lee, H.-Y.; Tseng, H.-Y.; Huang, J.-B.; Singh, M.; Yang, M.-H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Technical University of Munich, Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Murez, Z.; Kolouri, S.; Kriegman, D.; Ramamoorthi, R.; Kim, K. Image to image translation for domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4500–4509. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv 2017, arXiv:03126. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland; pp. 234–241.
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2019; pp. 5967–5976. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Ružić, T.; Pižurica, A. Context-aware patch-based image inpainting using Markov random field modeling. IEEE Trans. Image Process. 2015, 24, 444–456. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Z.; Yang, Q.; Sheng, B. Colorization Using Neural Network Ensemble. IEEE Trans. Image Process. 2017, 26, 5491–5505. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Proceedings of Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona International Convention Centre, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. arXiv 2017, arXiv:1701.05957. [Google Scholar]
- Zhu, J.-Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative visual manipulation on the natural image manifold. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 8–16 October 2016; pp. 597–613. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Neural photo editing with introspective adversarial networks. arXiv 2016, arXiv:1609.07093. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Lotter, W.; Kreiman, G.; Cox, D. Unsupervised learning of visual structure using predictive generative networks. arXiv 2015, arXiv:1511.06380. [Google Scholar]
- Zhu, J.-Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 465–476. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. April 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Transformation Network T | ||||||
|---|---|---|---|---|---|---|
| Layers | Kernel | Stride | Channels | W × H | Activation | BN |
| Input: Image | 3 | 256 × 256 | ||||
| Conv. Layer 1 | 4 | 2 | 64 | 128 × 128 | LeakyReLU | |
| Conv. Layer 2 | 4 | 2 | 128 | 64 × 64 | LeakyReLU | True |
| Conv. Layer 3 | 4 | 2 | 256 | 32 × 32 | LeakyReLU | True |
| Conv. Layer 4 | 4 | 2 | 512 | 16 × 16 | LeakyReLU | True |
| Conv. Layer 5 | 4 | 2 | 512 | 8 × 8 | LeakyReLU | True |
| Conv. Layer 6 | 4 | 2 | 512 | 4 × 4 | LeakyReLU | True |
| Conv. Layer 7 | 4 | 2 | 512 | 2 × 2 | LeakyReLU | True |
| Conv. Layer 8 | 4 | 2 | 512 | 1 × 1 | LeakyReLU | |
| Deconv. Layer 9 | 4 | 2 | 1024 | 2 × 2 | ReLU | True |
| Concatenate (Layer 9, Layer 6) | ||||||
| Deconv. Layer 10 | 4 | 2 | 1024 | 4 × 4 | ReLU | True |
| Concatenate (Layer 10, Layer 5) | ||||||
| Deconv. Layer 11 | 4 | 2 | 1024 | 8 × 8 | ReLU | True |
| Concatenate (Layer 11, Layer 4) | ||||||
| Deconv. Layer 12 | 4 | 2 | 1024 | 16 × 16 | ReLU | True |
| Concatenate (Layer 12, Layer 3) | ||||||
| Deconv. Layer 13 | 4 | 2 | 512 | 32 × 32 | ReLU | True |
| Concatenate (Layer 13, Layer 2) | ||||||
| Deconv. Layer 14 | 4 | 2 | 256 | 64 × 64 | ReLU | True |
| Concatenate (Layer 14, Layer 1) | ||||||
| Deconv. Layer 15 | 4 | 2 | 128 | 128 × 128 | Tanh | |
| Output: transformed image | 3 | 256 × 256 | ||||
| Discriminative Network D | ||||||
|---|---|---|---|---|---|---|
| Layers | Kernel | Stride | Channels | W × H | Activation | BN |
| Input: image1, 2 to network streams | 3 | 256 × 256 | LeakyReLU | True | ||
| Conv. Layer 1 | 4 | 2 | 64 | 128, 128 | LeakyReLU | True |
| Conv. Layer 2 | 4 | 2 | 128 | 64, 64 | LeakyReLU | True |
| Conv. Layer 3 | 4 | 2 | 256 | 32, 32 | LeakyReLU | True |
| Conv. Layer 4 | 4 | 2 | 512 | 16, 16 | LeakyReLU | True |
| Conv. Layer 5 | 4 | 2 | 1024 | 8, 8 | LeakyReLU | True |
| Conv. Layer 6 | 1 | 8, 8 | ||||
| Concatenate (stream1, stream2) | ||||||
| Output: real or fake pair | ||||||
| Edges → Shoes | ||||
|---|---|---|---|---|
| PSNR | SSIM | UQI | VIF | |
| Pix2pix | 15.74 | 0.42 | 0.07 | 0.05 |
| PAN | 19.51 | 0.78 | 0.34 | 0.23 |
| Ours | 21.01 | 0.88 | 0.94 | 0.24 |
| De-raining | ||||
| PSNR | SSIM | UQI | VIF | |
| ID-cGAN | 22.91 | 0.81 | 0.64 | 0.38 |
| PAN | 23.35 | 0.83 | 0.66 | 0.40 |
| Ours | 31.59 | 0.89 | 0.78 | 0.51 |
| Aerial photos → Maps | ||||
| PSNR | SSIM | UQI | VIF | |
| Pix2pix | 26.20 | 0.64 | 0.09 | 0.02 |
| PAN | 28.32 | 0.75 | 0.33 | 0.16 |
| Ours | 31.9 | 0.79 | 0.64 | 0.23 |
| Label→Facade | ||||
| PSNR | SSIM | UQI | VIF | |
| Pix2Pix | 12.85 | 0.35 | 0.80 | 0.05 |
| PAN | 12.42 | 0.31 | 0.77 | 0.05 |
| Dual-GAN | 12.74 | 0.53 | 0.73 | 0.13 |
| Ours | 14.08 | 0.45 | 0.86 | 0.14 |
| Night → Day | ||||
| PSNR | SSIM | UQI | VIF | |
| Pix2Pix | 9.46 | 0.57 | 0.76 | 0.14 |
| bicycleGANs | 17.33 | 0.64 | 0.60 | 0.12 |
| Ours | 18.13 | 0.54 | 0.88 | 0.14 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sung, T.L.; Lee, H.J. Image-to-Image Translation Using Identical-Pair Adversarial Networks. Appl. Sci. 2019, 9, 2668. https://doi.org/10.3390/app9132668
Sung TL, Lee HJ. Image-to-Image Translation Using Identical-Pair Adversarial Networks. Applied Sciences. 2019; 9(13):2668. https://doi.org/10.3390/app9132668
Chicago/Turabian StyleSung, Thai Leang, and Hyo Jong Lee. 2019. "Image-to-Image Translation Using Identical-Pair Adversarial Networks" Applied Sciences 9, no. 13: 2668. https://doi.org/10.3390/app9132668
APA StyleSung, T. L., & Lee, H. J. (2019). Image-to-Image Translation Using Identical-Pair Adversarial Networks. Applied Sciences, 9(13), 2668. https://doi.org/10.3390/app9132668