CP-SSD: Context Information Scene Perception Object Detection Based on SSD


Abstract
:1. Introduction
2. Related Work
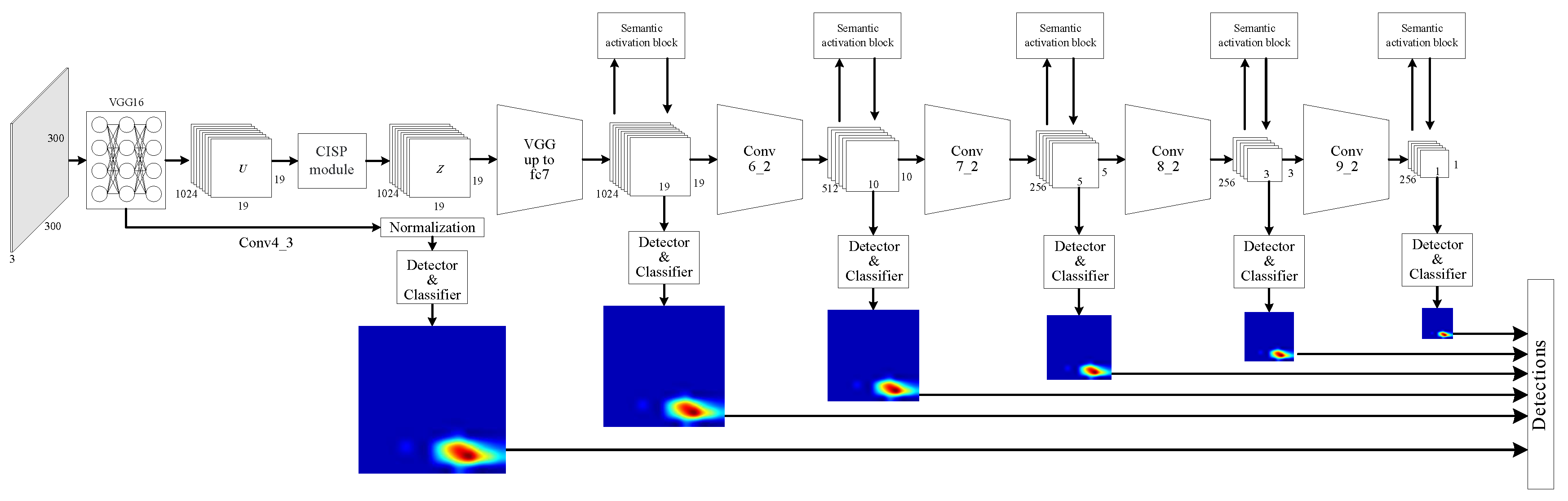
3. CP-SSD
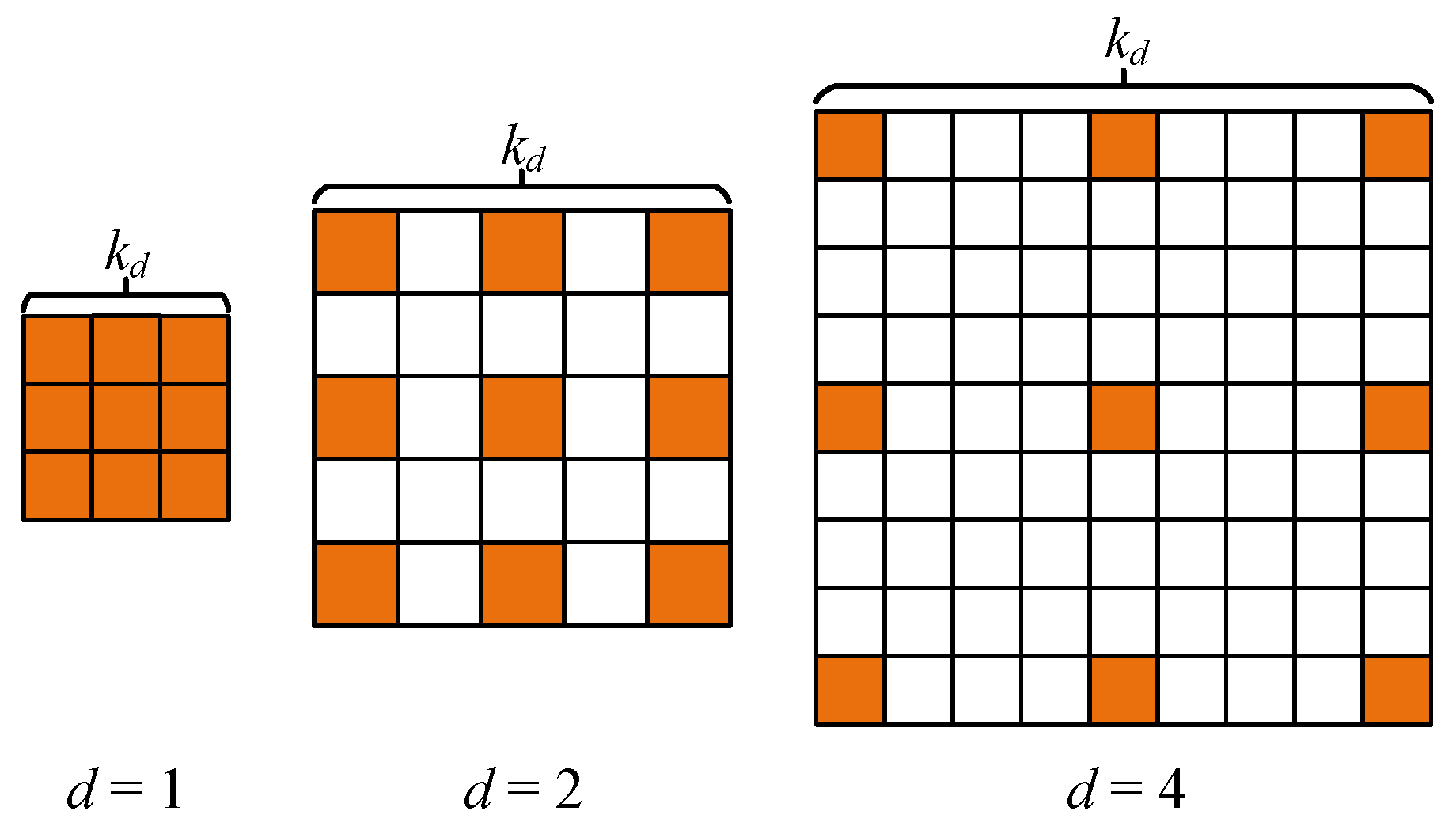
3.1. Dilated Convolution and Receptive Field
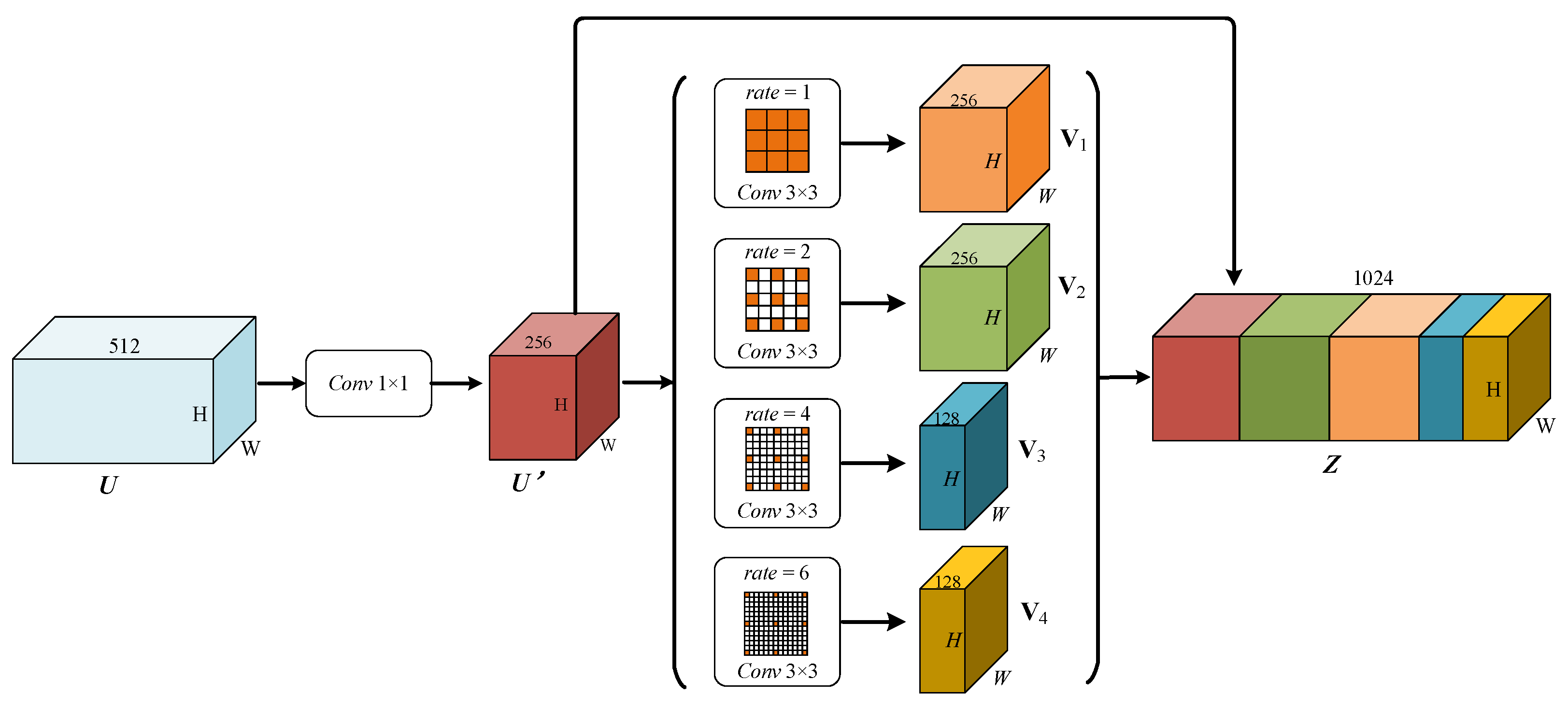
3.2. Context Information Scene Perception Module
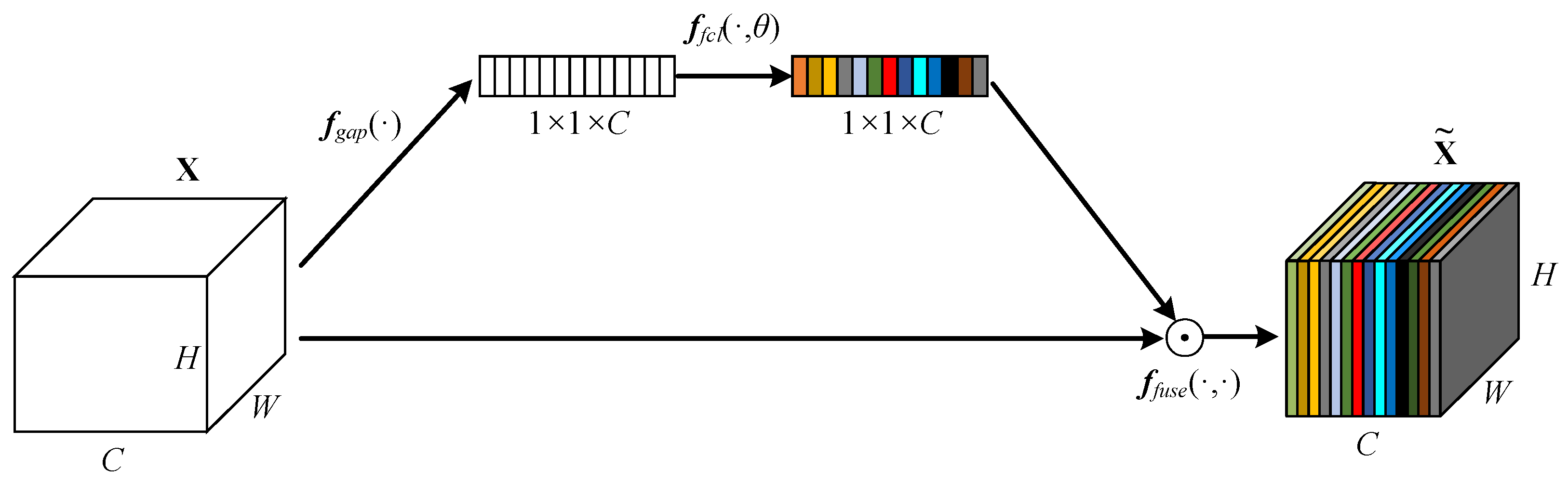
3.3. Semantic Activation Block
4. Analysis and Discussion of Experimental Results
4.1. Data Sets and Data Enhancements
4.2. Experimental Parameter Settings
4.3. Ssd with Context Information Scene Perception Module
4.4. Ssd with Semantic Activation Block
4.5. Comparison of Methods
4.6. Detection Examples
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; The MIT Press: Cambridge, MA, USA, 1995; p. 3361. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference. arXiv 2019, arXiv:1902.10421. [Google Scholar]
- Wang, Y.; Xie, L.; Liu, C.; Qiao, S.; Zhang, Y.; Zhang, W.; Tian, Q.; Yuille, A. Sort: Second-order response transform for visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1359–1368. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 343–3440. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Tang, P.; Wang, X.; Bai, X.; Liu, W. Multiple instance detection network with online instance classifier refinement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2843–2851. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS 2017 Autodiff Workshop, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5936–5944. [Google Scholar]
- Shrivastava, A.; Gupta, A. Contextual priming and feedback for faster r-cnn. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 330–348. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow |
| SSD [4] | 77.2 | 78.8 | 85.3 | 75.7 | 71.5 | 49.1 | 85.7 | 86.4 | 87.8 | 60.6 | 82.7 |
| SSD+CISP | 77.6 | 80.5 | 85.1 | 76.0 | 71.1 | 52.9 | 86.1 | 86.4 | 87.1 | 61.3 | 81.8 |
| Method | mAP | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | tv |
| SSD [4] | 77.2 | 76.5 | 84.9 | 86.7 | 84.0 | 79.2 | 51.3 | 77.5 | 78.7 | 86.7 | 76.2 |
| SSD+CISP | 77.6 | 76.7 | 84.5 | 86.4 | 85.0 | 79.0 | 53.0 | 76.5 | 80.9 | 85.5 | 77.3 |
| Method | mAP | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow |
| SSD [4] | 77.2 | 78.8 | 85.3 | 75.7 | 71.5 | 49.1 | 85.7 | 86.4 | 87.8 | 60.6 | 82.7 |
| SSD+SAB | 77.6 | 81.3 | 84.9 | 75.7 | 72.0 | 50.7 | 85.4 | 86.4 | 87.9 | 61.8 | 82.3 |
| Method | mAP | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | tv |
| SSD [4] | 77.2 | 76.5 | 84.9 | 86.7 | 84.0 | 79.2 | 51.3 | 77.5 | 78.7 | 86.7 | 76.2 |
| SSD+SAB | 77.6 | 77.7 | 85.6 | 87.7 | 81.9 | 79.1 | 52.4 | 77.5 | 81.6 | 84.7 | 76.3 |
| Method | backbone | mAP | Aero | bike | bird | boat | bottle | bus | car | cat | chair | cow |
| RCNN [3] | AlexNet | 50.2 | 67.1 | 64.1 | 46.7 | 32.0 | 30.5 | 56.4 | 57.2 | 65.9 | 27.0 | 47.3 |
| Fast [18] | VGG16 | 70.0 | 77.0 | 78.1 | 69.3 | 59.4 | 38.3 | 81.6 | 78.6 | 86.7 | 42.8 | 78.8 |
| Faster [19] | VGG16 | 73.2 | 76.5 | 79.0 | 70.9 | 65.5 | 52.1 | 83.1 | 84.7 | 86.4 | 52.0 | 81.9 |
| Faster [8] | ResNet101 | 76.4 | 79.8 | 80.7 | 76.2 | 68.3 | 55.9 | 85.1 | 85.3 | 89.8 | 56.7 | 87.8 |
| RON384++ [25] | VGG16 | 77.6 | 86.0 | 82.5 | 76.9 | 69.1 | 59.2 | 86.2 | 85.5 | 87.2 | 59.9 | 81.4 |
| Shrivastava et al. [26] | VGG16 | 76.4 | 79.3 | 80.5 | 76.8 | 72.0 | 58.2 | 85.1 | 86.5 | 89.3 | 60.6 | 82.2 |
| YOLO [21] | Darknet | 57.9 | 77.0 | 67.2 | 57.7 | 38.3 | 22.7 | 68.3 | 55.9 | 81.4 | 36.2 | 60.8 |
| SSD321 [4] | ResNet101 | 77.1 | 76.3 | 84.6 | 79.3 | 64.6 | 47.2 | 85.4 | 84.0 | 88.8 | 60.1 | 82.6 |
| SSD300 [4] | VGG16 | 77.2 | 78.8 | 85.3 | 75.7 | 71.5 | 49.1 | 85.7 | 86.4 | 87.8 | 60.6 | 82.7 |
| CP-SSD(SSD+CISP+SAB) | VGG16 | 77.8 | 83.9 | 86.3 | 80.1 | 69.9 | 50.6 | 86.5 | 85.6 | 88.4 | 62.8 | 79.4 |
| Method | backbone | mAP | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
| RCNN [3] | AlexNet | 50.2 | 40.9 | 66.6 | 57.8 | 65.9 | 53.6 | 26.7 | 56.5 | 38.1 | 52.8 | 50.2 |
| Fast [18] | VGG16 | 70.0 | 68.9 | 84.7 | 82.0 | 76.6 | 69.9 | 31.8 | 70.1 | 74.8 | 80.4 | 70.4 |
| Faster [19] | VGG16 | 73.2 | 65.7 | 84.8 | 84.6 | 77.5 | 76.7 | 38.8 | 73.6 | 73.9 | 83.0 | 72.6 |
| Faster [8] | ResNet101 | 76.4 | 69.4 | 88.3 | 88.9 | 80.9 | 78.4 | 41.7 | 78.6 | 79.8 | 85.3 | 72.0 |
| RON384++ [25] | VGG16 | 77.6 | 73.3 | 85.9 | 86.8 | 82.2 | 79.6 | 52.4 | 78.2 | 76.0 | 86.2 | 78.0 |
| Shrivastava et al. [26] | VGG16 | 76.4 | 69.2 | 87.0 | 87.2 | 81.6 | 78.2 | 44.6 | 77.9 | 76.7 | 82.4 | 71.9 |
| YOLO [21] | Darknet | 57.9 | 48.5 | 77.2 | 72.3 | 71.3 | 63.5 | 28.9 | 52.2 | 54.8 | 73.9 | 50.8 |
| SSD321 [4] | ResNet101 | 77.1 | 76.9 | 86.7 | 87.2 | 85.4 | 79.1 | 50.8 | 77.2 | 82.6 | 87.3 | 76.6 |
| SSD300 [4] | VGG16 | 77.2 | 76.5 | 84.9 | 86.7 | 84.0 | 79.2 | 51.3 | 77.5 | 78.7 | 86.7 | 76.2 |
| CP-SSD(SSD+CISP+SAB) | VGG16 | 77.8 | 77.9 | 83.1 | 88.1 | 84.5 | 80.0 | 53.5 | 74.1 | 77.1 | 86.4 | 77.0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Peng, T.; Tan, N. CP-SSD: Context Information Scene Perception Object Detection Based on SSD. Appl. Sci. 2019, 9, 2785. https://doi.org/10.3390/app9142785
Jiang Y, Peng T, Tan N. CP-SSD: Context Information Scene Perception Object Detection Based on SSD. Applied Sciences. 2019; 9(14):2785. https://doi.org/10.3390/app9142785
Chicago/Turabian StyleJiang, Yun, Tingting Peng, and Ning Tan. 2019. "CP-SSD: Context Information Scene Perception Object Detection Based on SSD" Applied Sciences 9, no. 14: 2785. https://doi.org/10.3390/app9142785
APA StyleJiang, Y., Peng, T., & Tan, N. (2019). CP-SSD: Context Information Scene Perception Object Detection Based on SSD. Applied Sciences, 9(14), 2785. https://doi.org/10.3390/app9142785