Address Space Layout Randomization Next Generation



Abstract
:1. Introduction
2. ASLR Taxonomy
2.1. Dimension 1: When
- Per-deployment:
- The application is randomized when it is installed in the system. This form of randomization, also known pre-linking, was proposed by Bojinov et al. [20] as a mechanism to provide randomization on systems that do not support position independent code (PIC) or relocatable code.
- Per-boot:
- The randomization is done every time the system boots. That is, the random value or values used to map objects are generated a boot time (see Figure 1). This form of randomization is typically used on systems whose shared libraries are not compiled as PIC, and so the loader has to relocate the memory image to match the actual addresses. This technique for sharing libraries has some drawbacks:
- Once a library has been relocated in memory, it is no longer a copy of the file, but it has been modified to match the current virtual addresses where it has been loaded. Therefore, all subsequent requests to map that library shall use the same addresses in order to share the same pages.
- Since the memory image does not match the file image (because it has been customized for the current position) it is not possible to use the file itself as swap-in area of the image. A full swap-out and swap-in sequence on a swap device is necessary.
PIC code is implemented using relative addressing (the compiler emits offsets with respect to the program counter (PC) rather than absolute directions). Unfortunately, PC relative addressing modes are not available on the i386 architecture, which makes the code slightly larger and slower.The effectiveness of ASLR has pushed some processor developers to include relative addressing in their new architecture families. The x86_64 architecture implements relative for 64 bits instruction set. - Per-exec:
- The randomization takes place when new executable image is loaded in memory (see Figure 1). In the literature, this form of randomization is known “pre-process randomization”. But it must be pointed out that the randomization takes place when a new image is loaded (via the exec() system call) rather than when a new process is created by calling fork().
- Per-fork:
- The randomization takes place every time a new process is created (forked). Recently, Kangjie et al. [21] proposed RuntimeASLR, which implements an aggressive re-randomization of all the fine-grain objects of every child after fork(). This solution sets ASLR of the forked/cloned processes at the same level than the one achieved by an exec(). Unfortunately, Unix API defines that child processes inherit the memory layout of their parents, and so RuntimeASLR breaks compatibility.It is still possible to have a per-fork randomization, while preserving API compatibility if randomization is only applied to new objects. Current ASLR designs allocate new objects in consecutive addresses, but it is possible to re-randomize the base address after a fork, so that new objects are unknown to parent and siblings.
- Per-object:
- The object is randomized when it is created (see Figure 2). Note that, objects that are at a constant distance from another already mapped object are not considered to be randomized on a per-object basis, even if the reference object is randomized. Note that if the position of one of the two objects is leaked, then the position of the other is immediately known.
2.2. Dimension 2: What
2.3. Dimension 3: How
- Partial VM:
- The virtual memory space is divided in ranges or zones (see Figure 3). Each zone contains one or more objects. Typically, zones do not overlap, and so, each zone defines a proper subset of the memory space. In most implementations, only a small range of the memory space is used, that is, the union of all the ranges does not cover all the virtual memory. Partial VM randomization greatly simplifies the implementation of ASLR because object collision are prevented, but the effective entropy is reduced.
- Full VM:
- All the virtual memory space is used to randomize the objects (see Figure 3). When this randomization is used, the order of the main areas (exec, heap, libs, stack, …) are no longer honored. Special care must be taken to avoid overlapping and collisions. The effective entropy is greatly incremented. As far a we know, no current ASLR design uses the full VM randomization.
- Isolated-Object:
- The object is randomly mapped with respect to any other (see Figure 4). Some attacks rely on knowing the address of an object to exploit another one because there is a correlation between them [27,28]. In order to be effective, the correlation entropy of the isolated objects with respect to the rest of objects must be greater than the absolute entropy of each one. Therefore, an information leak of the position of an isolated-object gives no hint of the memory layout of the process but the leaked object.
- Correlated-Object:
- The object is placed taking into account the position of another one (see Figure 4). The position of a correlated object is calculated as a function of the position of another object and a random value. When two objects are mapped together, side by side, they are fully correlated. Some examples of correlated objects are: Linux libraries and PaX thread stacks and libraries.
- Sub-page:
- The offset bits of the page are also randomized (see Figure 5). By default, ASLR implementations use the processor virtual memory paging support to randomize objects. If no additional entropy is added, addresses are page aligned. Depending on the type of object (shared object, contains data or code, swap constraints, etc.) sub-page randomization may be implemented transparently. For example, the stack and the heap have sub-page randomization in current Linux.
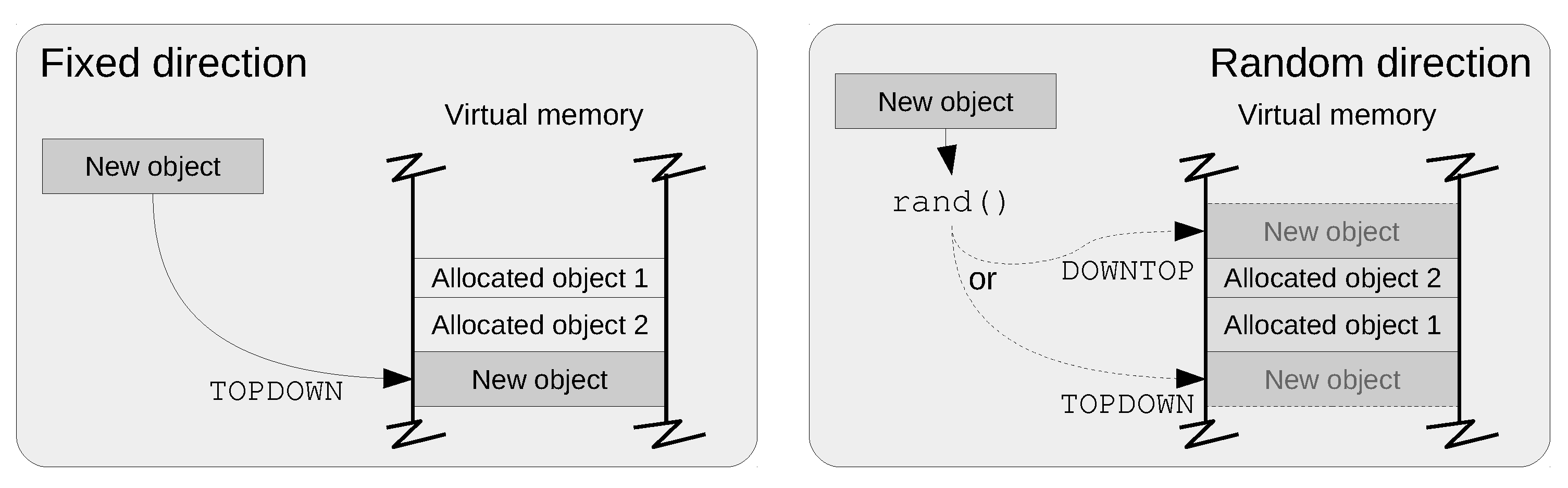
- Direction:
- Up/down search side used on a first-fit allocation strategy (see Figure 6). When allocating objects together, new objects can be placed at higher addresses that the ones already mapped (bottom-up) or at lower addresses (top-down). The direction is used to decide the side to place new objects. There are two situations when the direction is necessary:
- When objects are randomly mapped, it may occur that (if not prevented) a randomly generated address collides with an existing object, in this case, the direction determines the side of the existing object (up or down) where the new one will be mapped.
- When objects are mapped together: the direction bit determines how the area or zone grows.
Note that the direction is not a global parameter or feature of the ASLR, but its scope can be determined on a per-object or per-zone basis. - Bit-Slicing:
- The address of an object is the concatenation of two, or more, random numbers which are obtained at different times (for example, at boot and at exec), as shown in Figure 7. For example, this form can be used when a subset of the addresses must be aligned to a fixed value because of performance reasons. In this case, the alignment can be randomly chosen at boot time, and then align all the mappings to that value. Later, all address bits may be randomized except the aligned bits which are set to the value chosen previously.
- Specific-zone:
- A base address and a direction where objects are allocated together. Taking into account security aspects, the more random bits and the more independent are the mappings the better. On the other side, if the goal is to reduce the overhead, the more compact the layout the better. Specific-zones defines a mechanism that can be used to group together objects of the same or similar level of security, and isolate each group from others of different level of security/criticality Figure 8 shows an example of how the objects allocated to an specific-zone are mapped.
3. ASLR Limitations
3.1. Stacks
- One or more protected pages (page guards) are placed at the end of the thread stack. If the stack overflows, then the process receives a SIGSEGV signal. This guard is further enforced by the GCC flag-fstack-check, which emits extra code to access sequentially all the pages of the stack, thus preventing overflowing by jumping over the page guard.
- The split stack feature (GCC flag-fsplit-stack) generates code to automatically continue the stack in another object (created via mmap()), before it overflows. As a result, the process has discontinuous stacks which will only run out of memory if the program is unable to allocate more memory. This is an interesting feature for threaded programs, as it is no longer necessary to calculate the maximum stack size for each thread. This is currently only implemented in the i386 and x86_64 back-ends running in GNU/Linux.
- It is possible to ask the compiler to print stack usage information for the program, on a per-function basis, using the -fstack-usage flag and making an estimation of stack size.
3.2. Heap
4. ASLRA: ASLR Analyzer
- Sampler:
- Launches a large number of processes and collects the addresses of selected memory objects.
- Analyzer:
- The resulting sampled file is processed to calculate several statistical parameters (see Figure 10, Figure 11 and Figure 12). Besides the basic ones: range, mean, median mode and standard deviation, the analyzer calculates four different entropy estimators: (1) flipping bits, (2) individual byte Shannon entropy, (3) Shannon entropy with variable width bins and (4) Shannon 1-spacing estimator [34]. The tool also provides information about memory fragmentation, conditional entropy, and multiple plots (histogram, distribution, etc.).
5. ASLR Weaknesses
5.1. Non-Full Address Randomized Weakness
5.2. Non-Uniform Distribution Weakness
5.3. Correlation Weakness
5.4. Memory Layout Inheritance Weakness
6. ASLR Constraints and Considerations
- Fragmentation:
- although, from the point of view of security, having objects spread all over the full VM space is the best choice, in some cases it introduces prohibitive fragmentation, which is especially severe in 32-bit systems. Applications that request large objects or make a lot of requests may fail randomly, so it is mandatory to have a mechanism to address this fragmentation.
- Page table footprint:
- a very important aspect that is underestimated is the size of the process page table, because the more the objects are spread, the bigger the page table. This is particularly important in systems with low memory or with a high number of processes. Since each application could have a different level of security, the ASLR design should allow for tuning the page table size versus object spreading.
- Growable areas:
- unfortunately, most applications still use growable areas in some objects. In order to be compatible with these applications, an ASLR must guarantee some form of compatible behavior.
- Homogeneous entropy:
- all objects should have the same amount of entropy, in particular objects of the same type (for example, stacks); otherwise, attackers will focus on the weakest link. Unfortunately, none of the current designs meets this requirement.
- Uniformly distributed:
- all objects should be uniformly distributed; otherwise, attackers can design more effective attacks by focusing on the most frequent addresses.
- ASLR compatibility:
- the ASLR design should be backward-compatible with existing applications. That is, if there is a trade off between security and compatibility, then the design should allow for tuning the application framework to meet application’s needs.
7. ASLR-NG: Address Space Layout Randomization Next Generation
7.1. Allocating Object Strategy
- Isolated: the object is independently randomized using the full virtual memory space of the process. Unlike current implementations, ASLR-NG can use the full VM range to allocate an object, and as a result there no order to the objects and it prevents any kind of correlation attack.
- Specific-zone: objects of the same class are mapped together and isolated from others. A specific-zone is defined by a base address and a direction flag, both of which are initialized when the specific-zone is created (see function new_zone() in Listing 1). The base address is a random value taken from the full VM space, and new objects are placed by following the direction flag (toward higher or lower addresses) with respect to the base address.The main benefit of using specific-zones is that it reduces both fragmentation and page table footprint, which makes ASLR practical and realistic. Furthermore, specific-zones can be created according to MILS criteria, in that objects of the same criticality level may be grouped together. Criticality depends, among other factors, on the permissions and the kind of data stored on the object. Following this rule, ASLR-NG defines five specific-zones (depending on the configuration, see profile modes below):
- Huge pages:
- placing all huge page objects in their own specific-zone removes the correlation weakness between huge pages and normal mmapped objects. This is a specially dangerous form of correlation weakness as described in Section 8.3.
- Thread stacks:
- following the same criteria as the main stack, the thread stacks are isolated from the rest of objects on their own specific-zone.
- Read-write-exec objects:
- although these types of object are seldom used, for example in JIT mapping, they are very sensitive; in fact, Google implements custom randomization in their Chromium browser for these objects as part of its sand-boxing framework.
- Executable objects:
- map requests with executable permission are grouped in a specific-zone. This zone is mainly used to group library codes.
- Default zone:
- any other objects that do not match previous categories are allocated to this specific-zone. In addition, applications can create custom specific-zones to isolate sensitive data. For example, the credentials or certificates of a web server can be isolated from the rest of the regular data. This mechanism can prevent a Heartbleed [42] attack by moving sensitive data (certificates) away from the vulnerable buffer.
7.2. Addressing Fragmentation
7.3. Algorithm

- Obtain the hint address and the direction:
- if it is to a specific-zone, then the hint address and the direction are the ones from the specific-zone.
- if it is an isolated object, then the hint address is a random value from the allocation range [min_ASLR, max_ASLR] and the direction is top-down.
- Look for a gap large enough to hold the request from the hint address to the limit of the allocation area determined by the direction. If found, then succeed.
- Look for a gap large enough to hold the request from the hint address to the limit of the allocation area determined by the reverse direction. If found, then succeed.
- Look for a gap large enough to hold the request from the full VM space, starting from the allocation area and working towards the reserved area. If found, then succeed.
- Out of memory error.
7.4. Profile Modes
- Mode 1—Concentrated:
- all objects are allocated in a single specific-zone, which results in a compact layout. The number of entropy bits is not degraded but only the correlation entropy between them. In other words, the cost (if brute force were used) to obtain the address of an object is not reduced by using this mode. The goal is to reduce the footprint of the page table.
- Mode 2—Conservative:
- this mode is equivalent to that used in Linux and PaX. The main stack, the executable and the heap are independently randomized, while the rest (libraries and mmaps) are allocated in the mmap specific-zone. Since the objects are randomized using the full allocation range, ordering is not preserved; for example, the stack may be below the executable.
- Mode 3—Extended:
- this is an extension of the conservative mode, with additional randomization forms: (1) specific-zones for sensitive objects (thread stacks, heap, huge pages, read-write-exec and only executable objects); (2) sub-page randomization of the heap and thread stacks and (3) per-fork randomization. This can be considered a very secure configuration mode which addresses most of the weaknesses and sets a reasonable balance between security and performance. Therefore, this should be the default mode on most systems.
- Mode 4—Paranoid:
- every object is independently randomized, and no specific-zones are used. As a result, there is no correlation between any objects, which could even prevent future sophisticated attacks. It is intended to be used on processes that are highly exposed, for example networking servers, but should be carefully used when applied globally to all system processes because of additional memory overheads.
7.5. Fine Grain Configuration
- Sub-page in ARGV: ASLR-NG randomizes all the sub-page align bits. Although the arguments/environment are in the stack area, the page align bits of ARGV can be randomized.
- Randomize direction: the direction of a specific-zone is re-randomized for every new allocation. As a result, even libraries that typically are loaded sequentially will have some degree of randomness, which is especially useful in the concentrated profile, because it shuffles objects.
- Specific-zone for huge pages: if enabled, ASLR-NG uses a different specific-zone to map huge pages and therefore huge pages are completely isolated and correlation attacks abusing of its low entropy are not longer possible.
- Specific-zone for thread stacks: If enabled, thread stacks are allocated in a designated specific-zone. This no only prevents correlation attacks but also separate its data content from the libraries since both are by default in the same area.
- Inter-Object to Stack, Executable and Heap: each one of these objects is independently randomized, which is the default behavior for Linux and PaX. It was added to support the concentrated mode by disabling it.
- Randomize specific-zones per child: When a new child is spawned, all specific-zones are renewed, which results in a different memory map between the parent and the child, as well as any siblings among them.
- Sub-page in heap and thread stacks: applies sub-page randomization to the thread stacks and the heap. This feature can also be used from user-land on a per object basis, by calling the mmap() with the new flag MAP_INTRA_PAGE.
- Isolate thread stacks: randomizes thread stacks individually. This feature can also be requested by using the MAP_RND_OBJECT flag when calling mmap().
- Isolate LD and vDSO: by enabling this feature, ASLR-NG loads these objects individually instead of using the classic library/mmap zone.
- Bit-slicing: enabling this feature, ASLR-NG generates a random number at boot time which is later used to improve the entropy of some objects when they must be aligned, typically for cache aliasing performance. Instead of setting the sensitive bits to zero, they are set to the random value generated at boot. We have used the core idea of this novel randomization form to address a security issue in the Linux kernel 4.1, to increase entropy by 3 bits in the AMD Bulldozer processor family [31].
- Isolate all objects: all objects are independently randomized. The leakage of any object cannot be used to de-randomize any other. This feature can be used in very exposed or critical environments where security is paramount.
8. Evaluation
8.1. Randomization Forms
8.2. Absolute Address Entropy
- 32-bits: a 32-bit x86 architecture, without PAE. Note that when an i386 application is executed in a x86_64 system, the memory layout is different. Our experiments are executed in a truly 32-bit system, and so the virtual memory space available to any process is 3 GB.
- 64-bits: a 64-bit x86_64 architecture. The virtual memory space available for the user is bytes.
8.3. Correlation in ASLR-NG
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Aga, M.T.; Austin, T. Smokestack: Thwarting DOP Attacks with Runtime Stack Layout Randomization. In Proceedings of the 2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Washington, DC, USA, 16–20 February 2019; pp. 26–36. [Google Scholar] [CrossRef]
- Jelinek, J. Object Size Checking to Prevent (Some) Buffer Overflows (GCC FORTIFY). 2004. Available online: http://gcc.gnu.org/ml/gcc-patches/2004-09/msg02055.html (accessed on 17 July 2019).
- Shahriar, H.; Zulkernine, M. Mitigating Program Security Vulnerabilities: Approaches and Challenges. ACM Comput. Surv. 2012, 44, 11. [Google Scholar] [CrossRef]
- Carlier, M.; Steenhaut, K.; Braeken, A. Symmetric-Key-Based Security for Multicast Communication in Wireless Sensor Networks. Computers 2019, 8, 27. [Google Scholar] [CrossRef]
- Choudhary, J.; Balasubramanian, P.; Varghese, D.M.; Singh, D.P.; Maskell, D. Generalized Majority Voter Design Method for N-Modular Redundant Systems Used in Mission- and Safety-Critical Applications. Computers 2019, 8, 10. [Google Scholar] [CrossRef]
- Shacham, H.; Page, M.; Pfaff, B.; Goh, E.J.; Modadugu, N.; Boneh, D. On the effectiveness of address-space randomization. In Proceedings of the 11th ACM Conference on Computer and Communications Security, Washington, DC, USA, 25–29 October 2004; ACM: New York, NY, USA, 2004; pp. 298–307. [Google Scholar] [CrossRef]
- Marco-Gisbert, H.; Ripoll, I. Preventing Brute Force Attacks Against Stack Canary Protection on Networking Servers. In Proceedings of the 12th International Symposium on Network Computing and Applications, Cambridge, MA, USA, 22–24 August 2013; pp. 243–250. [Google Scholar] [CrossRef]
- Marco-Gisbert, H.; Ripoll, I. On the effectiveness of NX, SSP, RenewSSP and ASLR against stack buffer overflows. In Proceedings of the 13th International Symposium on Network Computing and Applications, Cambridge, MA, USA, 21–23 August 2014; pp. 145–152. [Google Scholar]
- Friginal, J.; de Andrés, D.; Ruiz, J.C.; Gil, P.J. Attack Injection to Support the Evaluation of Ad Hoc Networks. In Proceedings of the 2010 29th IEEE Symposium on Reliable Distributed Systems, New Delhi, India, 31 October–3 November 2010; pp. 21–29. [Google Scholar] [CrossRef]
- Xu, J.; Kalbarczyk, Z.; Iyer, R. Transparent runtime randomization for security. In Proceedings of the 22nd International Symposium on Reliable Distributed Systems, Florence, Italy, 6–8 October 2003; pp. 260–269. [Google Scholar] [CrossRef]
- Zhan, X.; Zheng, T.; Gao, S. Defending ROP Attacks Using Basic Block Level Randomization. In Proceedings of the 2014 IEEE Eighth International Conference on Software Security and Reliability-Companion, San Francisco, CA, USA, 30 June–2 July 2014; pp. 107–112. [Google Scholar] [CrossRef]
- Kil, C.; Jim, J.; Bookholt, C.; Xu, J.; Ning, P. Address space layout permutation (ASLP): Towards fine-grained randomization of commodity software. In Proceedings of the 2006 22nd Annual Computer Security Applications Conference (ACSAC’06), Miami Beach, FL, USA, 11–15 December 2006; pp. 339–348. [Google Scholar]
- Iyer, V.; Kanitkar, A.; Dasgupta, P.; Srinivasan, R. Preventing Overflow Attacks by Memory Randomization. In Proceedings of the 2010 IEEE 21st International Symposium on Software Reliability Engineering, San Jose, CA, USA, 1–4 November 2010; pp. 339–347. [Google Scholar] [CrossRef]
- Van der Veen, V.; dutt Sharma, N.; Cavallaro, L.; Bos, H. Memory Errors: The Past, the Present, and the Future. In Proceedings of the 15th International Conference on Research in Attacks, Intrusions, and Defenses, Amsterdam, The Netherlands, 12–14 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 86–106. [Google Scholar] [CrossRef]
- Pax Team. PaX Address Space Layout Randomization (ASLR). 2003. Available online: http://pax.grsecurity.net/docs/aslr.txt (accessed on 17 July 2019).
- Kocher, P.; Horn, J.; Fogh, A.; Genkin, D.; Gruss, D.; Haas, W.; Hamburg, M.; Lipp, M.; Mangard, S.; Prescher, T.; et al. Spectre Attacks: Exploiting Speculative Execution. arXiv 2019, arXiv:1801.01203. [Google Scholar]
- Lipp, M.; Schwarz, M.; Gruss, D.; Prescher, T.; Haas, W.; Fogh, A.; Horn, J.; Mangard, S.; Kocher, P.; Genkin, D.; et al. Meltdown: Reading Kernel Memory from User Space. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), San Francisco, CA, USA, 16–20 April 2018. [Google Scholar]
- Edge, J. Kernel Address Space Layout Randomization. 2013. Available online: https://lwn.net/Articles/569635 (accessed on 17 July 2019).
- Rahman, M.A.; Asyhari, A.T. The Emergence of Internet of Things (IoT): Connecting Anything, Anywhere. Computers 2019, 8, 40. [Google Scholar] [CrossRef]
- Bojinov, H.; Boneh, D.; Cannings, R.; Malchev, I. Address space randomization for mobile devices. In Proceedings of the Fourth ACM Conference on Wireless Network Security, Hamburg, Germany, 14–17 June 2011; ACM: New York, NY, USA, 2011; pp. 127–138. [Google Scholar] [CrossRef]
- Lu, K.; Nürnberger, S.; Backes, M.; Lee, W. How to Make ASLR Win the Clone Wars: Runtime Re-Randomization. In Proceedings of the 23rd Annual Symposium on Network and Distributed System Security (NDSS 2016), San Diego, CA, USA, 21 February 2015. [Google Scholar]
- Hiser, J.; Nguyen-Tuong, A.; Co, M.; Hall, M.; Davidson, J. ILR: Where’d My Gadgets Go? In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 571–585. [Google Scholar] [CrossRef]
- Xu, H.; Chapin, S.J. Address-space layout randomization using code islands. J. Comput. Secur. 2009, 17, 331–362. [Google Scholar] [CrossRef]
- Crane, S.; Liebchen, C.; Homescu, A.; Davi, L.; Larsen, P.; Sadeghi, A.R.; Brunthaler, S.; Franz, M. Readactor: Practical code randomization resilient to memory disclosure. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 763–780. [Google Scholar]
- Wartell, R.; Mohan, V.; Hamlen, K.W.; Lin, Z. Binary Stirring: Self-randomizing Instruction Addresses of Legacy x86 Binary Code. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; ACM: New York, NY, USA, 2012; pp. 157–168. [Google Scholar] [CrossRef]
- Lin, Z.; Riley, R.D.; Xu, D. Polymorphing Software by Randomizing Data Structure Layout. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment; Flegel, U., Bruschi, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 107–126. [Google Scholar] [Green Version]
- Marco-Gisbert, H.; Ripoll, I. On the Effectiveness of Full-ASLR on 64-bit Linux. In Proceedings of the In-Depth Security Conference 2014 (DeepSec), Vienna, Austria, 18–21 November 2014. [Google Scholar]
- Bittau, A.; Belay, A.; Mashtizadeh, A.; Mazières, D.; Boneh, D. Hacking Blind. In Proceedings of the 35th IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; Available online: http://www.ieee-security.org/TC/SP2014/papers/HackingBlind.pdf (accessed on 17 July 2019).
- Drepper, U. Growable Maps Removal. 2008. Available online: https://lwn.net/Articles/294001/ (accessed on 17 July 2019).
- Lefevre, V. Silent Stack-Heap Collision under GNU/Linux. 2014. Available online: https://gcc.gnu.org/ml/gcc-help/2014-07/msg00076.html (accessed on 17 July 2019).
- Marco-Gisbert, H.; Ripoll, I. AMD Bulldozer Linux ASLR Weakness: Reducing Entropy by 87.5%. 2015. Available online: http://hmarco.org/bugs/AMD-Bulldozer-linux-ASLR-weakness-reducing-mmaped-files-by-eight.html (accessed on 17 July 2019).
- Marco-Gisbert, H.; Ripoll, I. CVE-2015-1593—Linux ASLR Integer Overflow: Reducing Stack Entropy by Four. 2015. Available online: http://hmarco.org/bugs/linux-ASLR-integer-overflow.html (accessed on 17 July 2019).
- Marco-Gisbert, H.; Ripoll, I. Linux ASLR Mmap Weakness: Reducing Entropy by Half. 2015. Available online: http://hmarco.org/bugs/linux-ASLR-reducing-mmap-by-half.html (accessed on 17 July 2019).
- Beirlant, J.; Dudewicz, E.J.; Györfi, L.; Van der Meulen, E.C. Nonparametric entropy estimation: An overview. Int. J. Math. Stat. Sci. 1997, 6, 17–39. [Google Scholar]
- Lesne, A. Shannon entropy: A rigorous notion at the crossroads between probability, information theory, dynamical systems and statistical physics. Math. Struct. Comput. Sci. 2014, 24, e240311. [Google Scholar] [CrossRef]
- Kozachenko, L.F.; Leonenko, N.N. Sample estimate of the entropy of a random vector. Probl. Inf. Transm. 1987, 23, 95–101. [Google Scholar]
- ’pi3’ Zabrocki, A. Scraps of Notes on Remote Stack Overflow Exploitation. 2010. Available online: http://www.phrack.org/issues.html?issue=67&id=13#article (accessed on 17 July 2019).
- Herlands, W.; Hobson, T.; Donovan, P.J. Effective entropy: Security-centric metric for memory randomization techniques. In Proceedings of the 7th Workshop on Cyber Security Experimentation and Test (CSET 14), San Diego, CA, USA, 18 August 2014. [Google Scholar]
- Uchenick, G.M.; Vanfleet, W.M. Multiple independent levels of safety and security: High assurance architecture for MSLS/MLS. In Proceedings of the MILCOM 2005—2005 IEEE Military Communications Conference, Atlantic City, NJ, USA, 17–20 October 2005; Volume 1, pp. 610–614. [Google Scholar] [CrossRef]
- Rohlf, C.; Ivnitskiy, Y. Attacking Clientside JIT Compilers; Black Hat: Las Vegas, NV, USA, 2011. [Google Scholar]
- Lee, B.; Lu, L.; Wang, T.; Kim, T.; Lee, W. From Zygote to Morula: Fortifying Weakened ASLR on Android. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 424–439. [Google Scholar] [CrossRef]
- The Heartbleed Bug. 2014. Available online: http://heartbleed.com (accessed on 17 July 2019).
- Wilson, P.; Johnstone, M.; Neely, M.; Boles, D. Dynamic storage allocation: A survey and critical review. In Memory Management; Baler, H., Ed.; Springer: Berlin/Heidelberg, Germany, 1995; Volume 986, pp. 1–116. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description | |
|---|---|---|
| When | Per-boot | Every time the system is booted. |
| Per-exec | Every time a new image is executed. | |
| Per-fork | Every time a new process is spawned. | |
| Per-object | Every time a new object is created. | |
| What | Stack | Stack of the main process. |
| LD | Dynamic linker/loader. | |
| Executable | Loadable segments (text, data, bss, …). | |
| Heap | Old-fashioned dynamic memory of the process: brk(). | |
| vDSO/VVAR | Objects exported by the kernel to the user space. | |
| ARGV | Command line arguments and environment variables of the process. | |
| Mmaps/libs | Objects allocated calling mmap(). | |
| How | Partial VM | A sub-range of the VM space is used to map the object. |
| Full VM | The full VM space is used to map the object. | |
| Isolated-object | The object is randomized independently from any other. | |
| Correlated-object | The object is randomized with respect to another. | |
| Sub-page | Page offset bits are randomized. | |
| Bit-slicing | Different slices of the address are randomized at different times. | |
| Direction | Top-down/bottom-up search side used on a first-fit allocation strategy. | |
| Specific-zone | A base address and a direction where objects are allocated together. | |
| Object | Description |
|---|---|
| Arguments | The arguments received by main() and the environment variables of the process. |
| HEAP | The initial heap location as returned by brk(). |
| Main Stack | The stack of the process, that is the address of a local variable of the main() function. |
| Dynamic Loader | For dynamic executables, the address of ld.so. |
| vDSO | Linux specific object exporting services like for example the syscall mechanism. |
| Glibc | The standard C library used by the majority of processes. |
| Thread Stack | The stack created by default then a new thread is created by the libpthread.so library. |
| FIRST_CHILD_MAP | The address returned by the first mmap() object of a child process. |
| EXEC | The address where the executable is loaded. |
| MAP_HUGETLB | Address of a large block (2 Mb) reserved via mmap() using the flag MAP_HUGETLB. |
| Feature | Modes | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Sub-page in ARGV | ✓ | ✓ | ✓ | ✓ |
| Randomize direction | ✓ | ✓ | ✓ | ✓ |
| Bit-slicing | ✓ | ✓ | ✓ | ✓ |
| Isolate stack, executable and heap | ✓ | ✓ | ✓ | |
| Specific-zone for huge pages | ✓ | ✓ | ||
| Randomize specific-zones per child | ✓ | ✓ | ||
| Sub-page in heap and thread stacks | ✓ | ✓ | ||
| Specific-zone for thread stacks | ✓ | |||
| Specific-zone for read-write-exec objects | ✓ | |||
| Specific-zone for exec objects | ✓ | |||
| Isolate thread stacks | ✓ | |||
| Isolate LD and vDSO | ✓ | |||
| Isolate all objects | ✓ | |||
| Feature and Forms | OS X | Linux | PaX | ASLR-NG |
|---|---|---|---|---|
| ASLR per-exec | ✓ | ✓ | ✓ | |
| Inter-object in stack, exec. and heap | ✓ | ✓ | ✓ | ✓ |
| Sub-page in main stack | ✓ | ✓ | ✓ | ✓ |
| Sub-page in ARGV and heap (brk) | ✓ | ✓ | ||
| Inter-object in LD and vDSO | ✓ | |||
| Inter-object in thread stacks | ✓ | |||
| Sub-page in thread stacks | ✓ | |||
| Load libraries order randomized | ✓ | |||
| Multiple specific-zone support | ✓ | |||
| Randomize specific-zones per child | ✓ | |||
| Bit-slicing randomization | ✓ | |||
| Sub-page per mmap request | ✓ | |||
| Inter-object per mmap request | ✓ | |||
| Uniform distribution | ✓ | |||
| Full VM range | ✓ |
| Object | 32-Bits | 64-Bits | ||||||
|---|---|---|---|---|---|---|---|---|
| OS X | Linux | PaX | ASLR-NG | OS X | Linux | PaX | ASLR-NG | |
| ARGV | 8 | 11 | 27 | 31.5 | 16 | 22 | 39 | 47 |
| Main stack | 8 | 19 | 23 | 27.5 | 16 | 30 | 35 | 43 |
| Heap (brk) | 8.7 | 13 | 23.3 | 27.5 | 15.9 | 28 | 35 | 43 |
| Heap (mmap) | 7.7 | 8 | 15.7 | 27.5 | 16 | 28 | 28.5 | 43 |
| Thread stacks | 11 | 8 | 15.7 | 27.5 | 16 | 28 | 28.5 | 43 |
| Sub-page object | - | - | - | 27.5 | - | - | - | 43 |
| Regular mmaps | 7.7 | 8 | 15.7 | 19.5 | 16 | 28 | 28.5 | 35 |
| Libraries | 7.7 | 8 | 15.7 | 19.5 | 16 | 28 | 28.5 | 35 |
| vDSO | 7.7 | 8 | 15.7 | 19.5 | 16 | 21.4 | 28.5 | 35 |
| Executable | 8 | 8 | 15 | 19.5 | 16 | 28 | 27 | 35 |
| Huge pages | 0 | 0 | 5.7 | 9.5 | 7 | 19 | 19.5 | 26 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marco-Gisbert, H.; Ripoll Ripoll, I. Address Space Layout Randomization Next Generation. Appl. Sci. 2019, 9, 2928. https://doi.org/10.3390/app9142928
Marco-Gisbert H, Ripoll Ripoll I. Address Space Layout Randomization Next Generation. Applied Sciences. 2019; 9(14):2928. https://doi.org/10.3390/app9142928
Chicago/Turabian StyleMarco-Gisbert, Hector, and Ismael Ripoll Ripoll. 2019. "Address Space Layout Randomization Next Generation" Applied Sciences 9, no. 14: 2928. https://doi.org/10.3390/app9142928
APA StyleMarco-Gisbert, H., & Ripoll Ripoll, I. (2019). Address Space Layout Randomization Next Generation. Applied Sciences, 9(14), 2928. https://doi.org/10.3390/app9142928