An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level


Abstract
:1. Introduction
2. Related Work
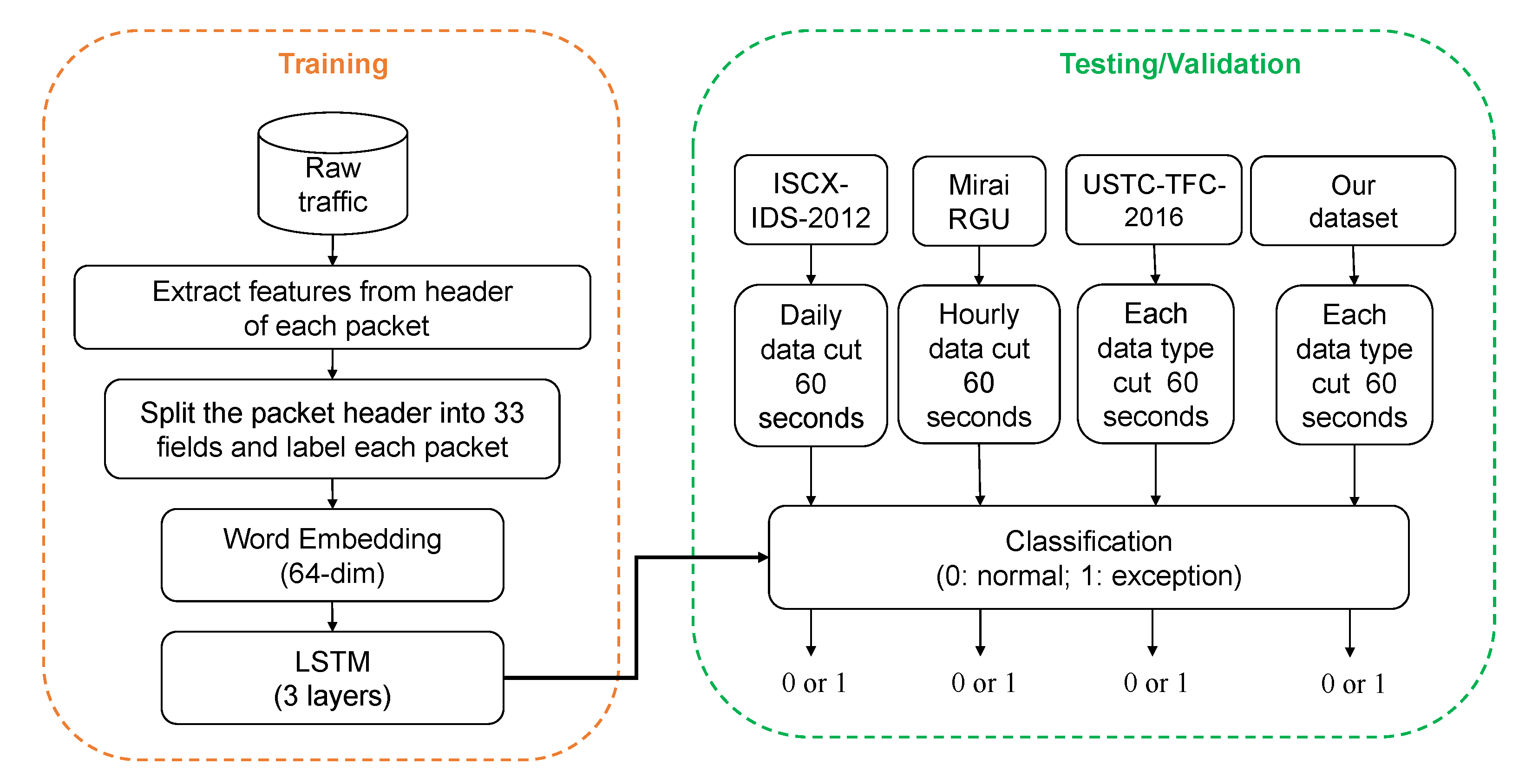
3. Methodology
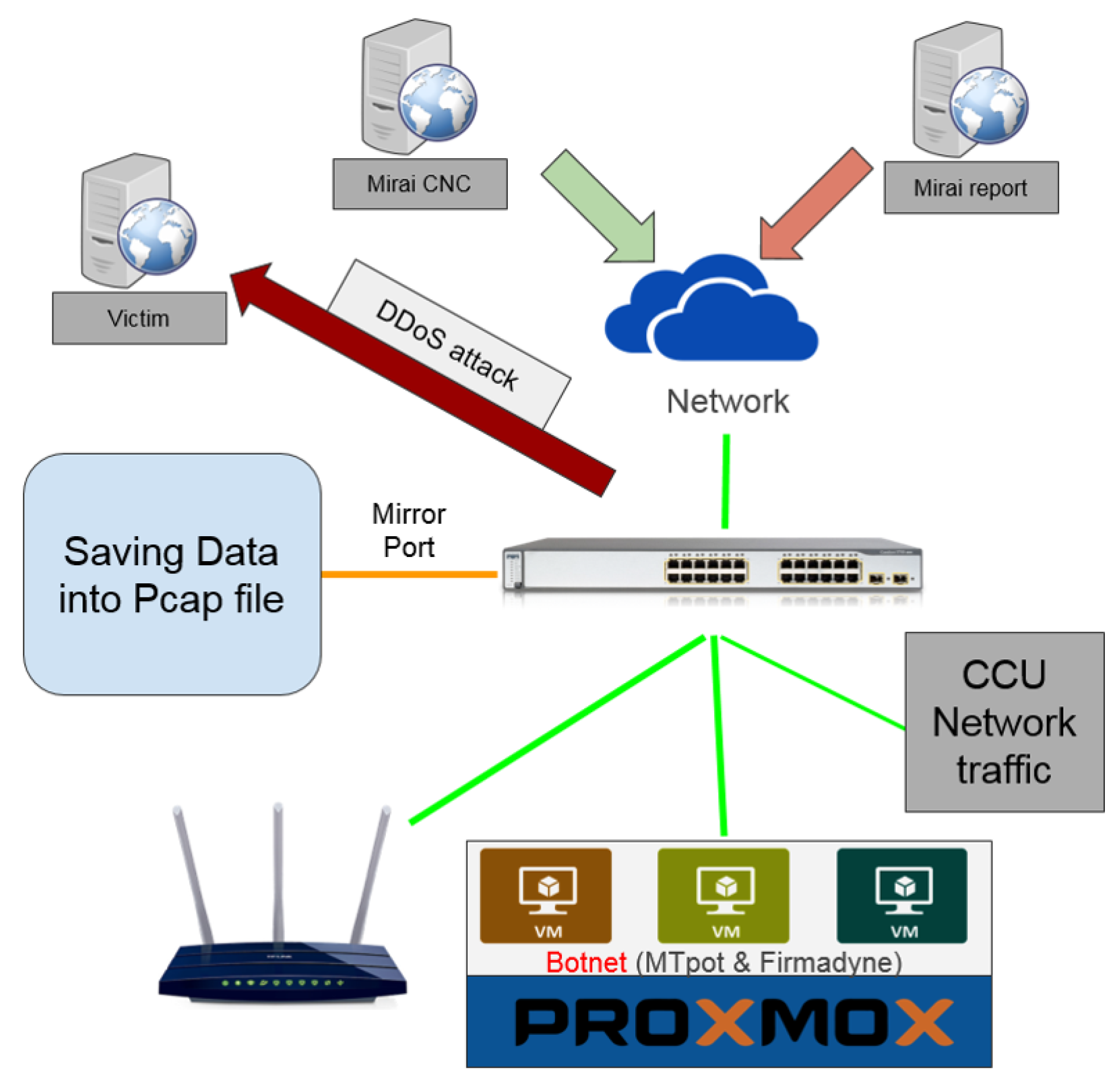
3.1. Dataset
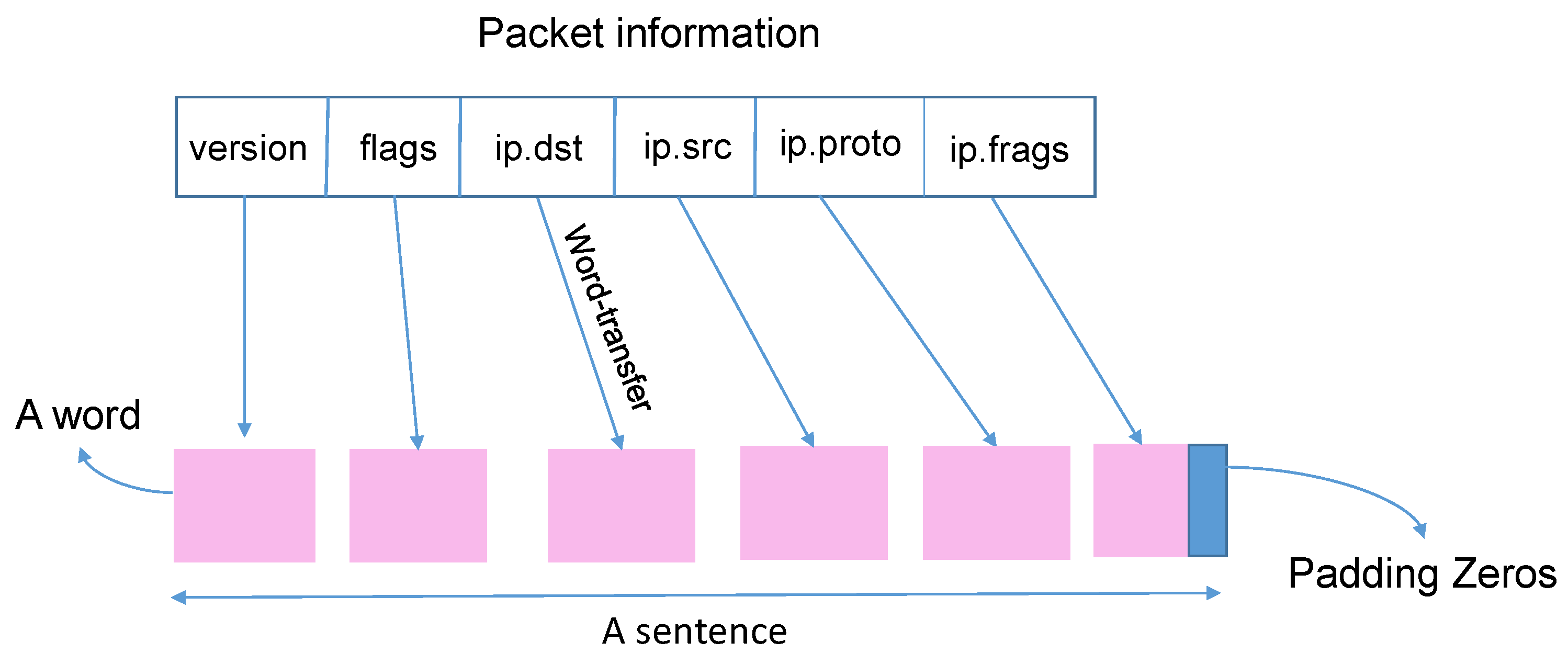
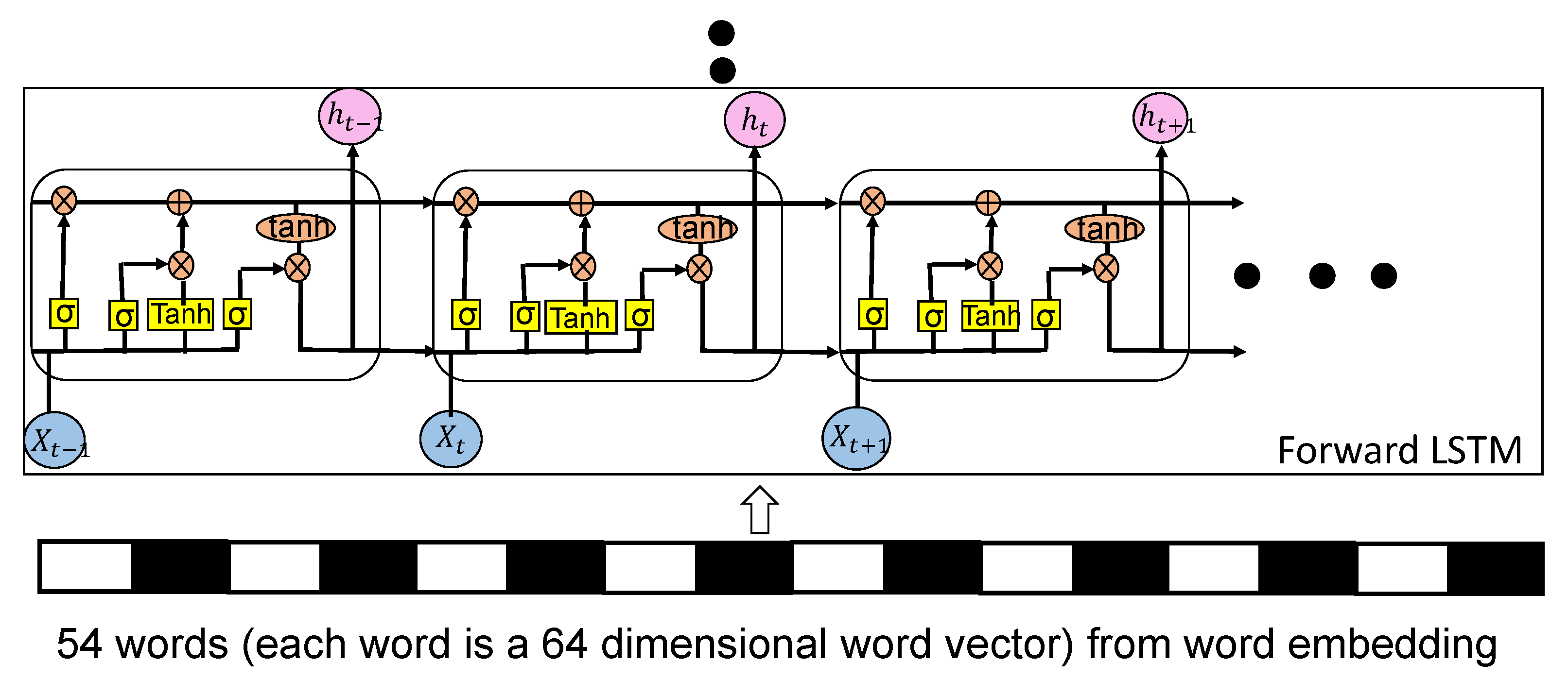
3.2. Word Embedding and Data Preprocessing
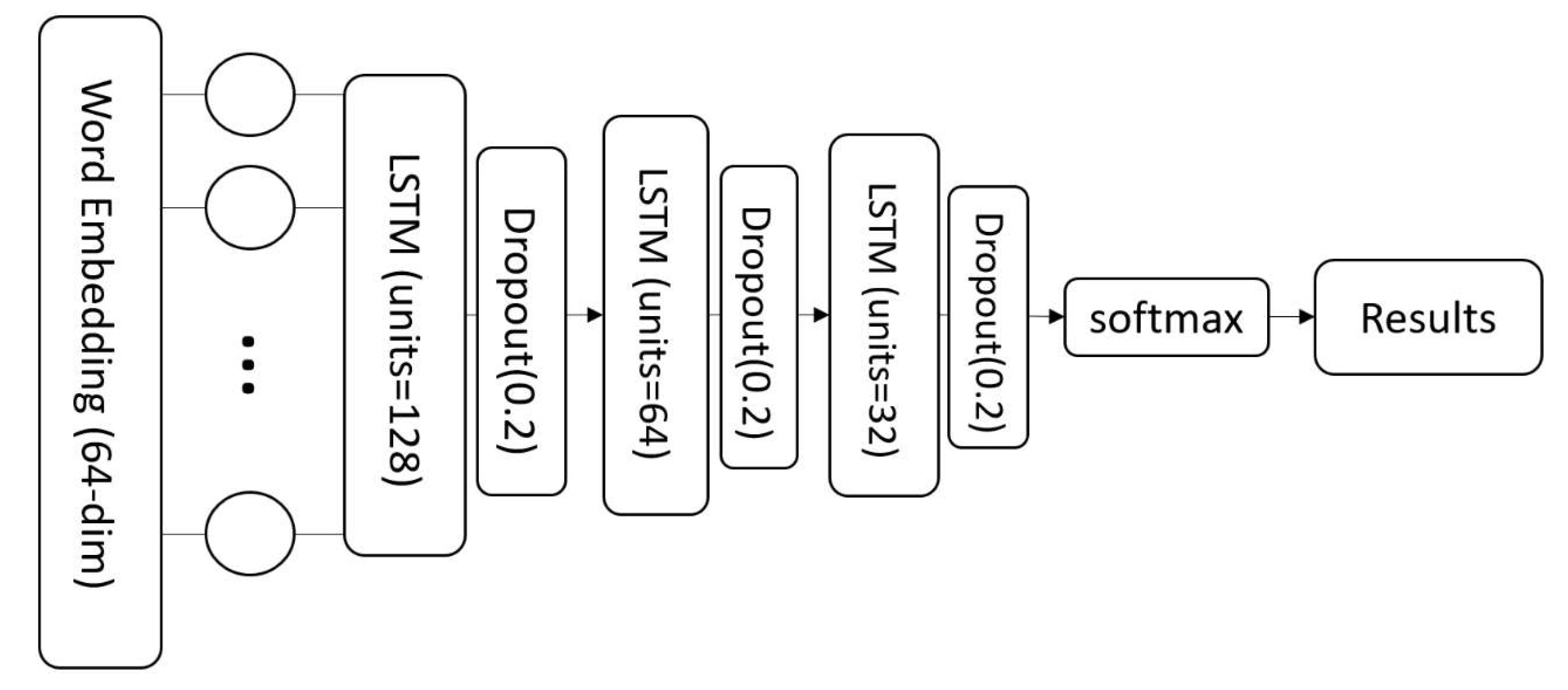
3.3. Classification
| Algorithm 1: Algorithm for packet-based traffic classification |
| Data: Sequence of raw packets from network Result: Accuracy, precision, recall, f1-score, FAR, loss
|
4. Evaluation Results
- True Positive (TP)—Attack packet that is correctly classified as an attack.
- False Positive (FP)—Benign packet that is incorrectly classified as an attack.
- True Negative (TN)—Benign packet that is correctly classified as normal.
- False Negative (FN)—Attack packet that is incorrectly classified as normal.
4.1. Time Efficiency
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies, New York, NY, USA, 3–5 December 2016; pp. 21–26. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D. N-BaIoT—Network-Based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 2018, 17, 11–22. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware Traffic Classification Using Convolutional Neural Networks for Representation Learning. In Proceedings of the 31st International Conference on Information Networking, Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar] [CrossRef]
- Chen, Y.C.; Li, Y.J.; Tseng, A.; Lin, T. Deep Learning for Malicious Flow Detection. In Proceedings of the IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications, Montreal, QC, Canada, 8–13 October 2017. [Google Scholar]
- Yuan, X.; Li, C.; Li, X. DeepDefense: Identifying DDoS Attack via Deep Learning. In Proceedings of the IEEE International Conference on Smart Computing, Hong Kong, China, 29–31 May 2017. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Ye, X. Using a Recurrent Neural Network and Restricted Boltzmann Machines for Malicious Traffic Detection. NeuroQuantology 2018, 6, 21954–21961. [Google Scholar] [CrossRef]
- Hwang, R.H.; Peng, M.C.; Huang, C.W. Detecting IoT Malicious Traffic based on Autoencoder and Convolutional Neural Network. IEEE Globecom Conf. 2019. submitted. [Google Scholar]
- Radford, B.J.; Apolonio, L.M.; Trias, A.J.; Simpson, J.A. Network Traffic Anomaly Detection Using Recurrent Neural Networks. arXiv 2018, arXiv:1803.10769. [Google Scholar]
- Cui, J.; Long, J.; Min, E.; Mao, Y. WEDL-NIDS: Improving Network Intrusion Detection Using Word Embedding-Based Deep Learning Method. In Proceedings of the International Conference on Modeling Decisions for Artificial Intelligence, Palma de Mallorce, Spain, 15–18 October 2018; pp. 283–295. [Google Scholar]
- Kim, M.S.; Kong, H.J.; Hong, S.C.; Chung, S.H.; Hong, J.W. A flow-based method for abnormal network traffic detection. In Proceedings of the 2004 IEEE/IFIP Network Operations and Management Symposium, Seoul, Korea, 23 April 2004; pp. 599–612. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation, Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2013, arXiv:1402.3722. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft Malware Classification Challenge. 2018. Available online: https://arxiv.org/pdf/1802.10135.pdf (accessed on 29 May 2019).
- McDermott, C.D.; Majdani, F.; Petrovski, A.V. Botnet Detection in the Internet of Things using Deep Learning Approaches. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Mikolov, T.; tau Yih, W.; Zweig, G. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A Deep Learning Approach to Network Intrusion Detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning Hierarchical Spatial-Temporal Features Using Deep Neural Networks to Improve Intrusion Detection. IEEE Access 2018, 6, 1792–1806. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Year | Method | Feature | Shortcomings |
|---|---|---|---|---|
| M. S. Kim [11] | 2004 | Formulization | flow-based | For offline detection |
| R. Fu [12] | 2016 | LSTM, GRU | flow-based | For offline detection |
| B J. Radford [9] | 2018 | LSTM | flow-based | For offline detection |
| C. Li [7] | 2018 | RNN, RBM | process packet, flow-based | For offline detection |
| Y. Chen [4] | 2018 | TSDNN, QDBP | flow-based, N class | For offline classification |
| X. Yuan [5] | 2017 | LSTM, GRU | process packet, flow-based | For offline detection |
| J. Cui [10] | 2018 | WEDL-NIDS | process packet, flow-based | For offline detection |
| Ours | 2019 | LSTM, Word-embedding | raw data, packet-based | Target for online detection |
| Benign | Malware | |||
|---|---|---|---|---|
| App Type | Size (MB) | Class | Malware Type | Size (MB) |
| Facetime | 2.4 | Voice/Video | Tinba | 2.55 |
| Skype | 4.22 | Chat/IM | Zeus | 13.4 |
| Bittorent | 7.33 | P2P | Shifu | 57.9 |
| Gmail | 9.05 | Email/Webmail | Neris | 90.1 |
| Outlook | 11.1 | Email/Webmail | Cridex | 94.7 |
| WorldOfWarcraft | 14.9 | Game | Nsisay | 281 |
| MySQL | 22.3 | Database | Geodo | 28.8 |
| FTP | 60.2 | Data transfer | Miuref | 16.3 |
| SMB | 1206 | Data transfer | Virut | 109 |
| 1618 | Social Network | Htbot | 83.6 | |
| Header | Extended Fields | Details |
|---|---|---|
| Ether header (3) | extended to 7 fields | ether.dst(2 × 3), ether.src(2 × 3), ether.type |
| IP header (12) | extended to 14 fields | ip.version, ip.ihl, ip.tos, ip.len, ip.id, ip.flags, ip.frag, ip.ttl, ip.proto, ip.chksum, ip.src(2 × 2), ip.dst(2 × 2) |
| TCP header (10) | extended to 12 fields | tcp.sport, tcp.dport, tcp.seq(2 × 2), tcp.ack(2 × 2), tcp.dataofs, tcp.reserved, tcp.flags, tcp.window, tcp.chksum, tcp.ugptr |
| UDP header (4) | extended to 12 fields | udp.sport, udp.dpot, udp.len, udp.chksum, 0, 0, 0, 0, 0, 0, 0, 0 |
| Predicted Classs | |||
|---|---|---|---|
| Malicious | Benign | ||
| Ground truth | Malicious | True Positive (TP) | False Negative (FN) |
| Benign | False Position (FP) | True Negative (TN) | |
| All | Train/Test | Validation | ||
|---|---|---|---|---|
| 6/12 | Benign | 5,947,337 | 26,374 | average: 4148/60 s |
| Attack | 26,374 | 26,643 | ||
| 6/13 | Benign | 3,925,130 | 100,000 | average: 1209 /60 s |
| Attack | 1,838,019 | 100,000 | ||
| 6/14 | Benign | 8,687,942 | 100,000 | average: 5947 /60 s |
| Attack | 960,711 | 100,000 | ||
| 6/15 | Benign | 17,551,503 | 100,000 | average: 12,746 /60 s |
| Attack | 17,431,539 | 100,000 | ||
| 6/16 | Benign | 17,260,920 | 50,000 | average: 7580 /60 s |
| Attack | 49,764 | 49,764 | ||
| Attack Type | All | Train /Test | Validation |
|---|---|---|---|
| syn | 1,526,926 | 728,000 | 1,526,926 /10 s |
| ack | 5,390,837 | 728,000 | 5,390,770 /50 s |
| http | 744,991 | 728,000 | 3152 /60 s |
| udp | 4,567,726 | 728,000 | 4,567,659 /58 s |
| Benign | Malware | ||||||
|---|---|---|---|---|---|---|---|
| Type | All | Train/Test | Validate (avg/60 s) | Type | All | Train/Test | Validate (avg./60 s) |
| Facetime | 6000 | 6000 | 6000 | Tinba | 22,000 | 22,000 | 729 |
| Skype | 12,000 | 12,000 | 12,000 | Zeus | 93,141 | 93,141 | 105 |
| BitTorrent | 15,000 | 15,000 | 15,000 | Shifu | 500,000 | 100,000 | 3 |
| Gmail | 25,000 | 25,000 | 25,000 | Neris | 499,218 | 100,000 | 896 |
| Outlook | 15,000 | 15,000 | 15,000 | Cridex | 461,548 | 100,000 | 34 |
| World Of Warcraft | 140,000 | 100,000 | 140,000 | Nsis-ay | 352,266 | 100,000 | 5617 |
| MySQL | 200,000 | 100,000 | 200,000 | Geodo | 250,000 | 100,000 | 12 |
| FTP | 360,000 | 100,000 | 360,000 | Miuref | 88,560 | 88,560 | 7 |
| SMB | 925,453 | 200,000 | 925,453 | Virut | 440,625 | 100,000 | 858 |
| 1,210,060 | 100,000 | 1,210,060 | Total | 2,707,358 | 803,701 | - | |
| Total | 2,908,513 | 1,058,000 | - | - | |||
| File | No# of Pcap | All (Benign, Attack) | Train/Test | Validate(avg./60 s) |
|---|---|---|---|---|
| Capture_2 | 3 (N) | (129,178, 0) | 100,000 | 14,100 |
| Capture_3 | 1 (M) | (54,641, 393,325) | 100,000 | 9795 |
| Capture_4 | 6 (N, M) | (268,461, 518,105) | 100,000 | 10,010 |
| Capture_5 | 1 (N, M) | (67,239, 519,376) | 100,000 | 9780 |
| Capture_6 | 1 (N, M) | (66,989, 519,609) | 100,000 | 9781 |
| Capture_7 | 1 (N, M) | (67,061, 519,400) | 100,000 | 9783 |
| Capture_8 | 1 (N, M, S) | (66,801, 981,651) | 100,000 | 9996 |
| Capture_9 | 12 (N, M, G) | (72,204, 1,373,042) | 100,000 | 10,004 |
| Capture_10 | 7 (N, M, GT) | (70,457, 969,937) | 100,000 | 9784 |
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | F-Score (%) | FPR (%) |
|---|---|---|---|---|---|
| ISCX-IDS-2012 | 99.99 | 99.98 | 99.99 | 99.99 | |
| USTC-TFC-2016 | 99.99 | 100 | 99.99 | 99.99 | |
| Mirai-RGU | 100 | 100 | 100 | 100 | 0 |
| Mirai-CCU | 99.46 | 99.63 | 99.38 | 99.51 | 0.026 |
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | F-Score (%) | FPR (%) |
|---|---|---|---|---|---|
| ISCX-IDS-2012 | 99.97 | 100 | 99.97 | 99.98 | 0 |
| USTC-TFC-2016 | 99.88 | 99.99 | 99.86 | 99.93 | 0.02 |
| Mirai-RGU | 99.98 | 99.99 | 99.95 | 99.97 | 0 |
| Mirai-CCU | 99.36 | 99.49 | 99.27 | 99.38 | 0.031 |
| Mirai-RGU | |||||
|---|---|---|---|---|---|
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | F-Score (%) | FPR (%) |
| Mirai-CCU | 97.22 | 96.25 | 98.73 | 97.5 | 0.36 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, R.-H.; Peng, M.-C.; Nguyen, V.-L.; Chang, Y.-L. An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level. Appl. Sci. 2019, 9, 3414. https://doi.org/10.3390/app9163414
Hwang R-H, Peng M-C, Nguyen V-L, Chang Y-L. An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level. Applied Sciences. 2019; 9(16):3414. https://doi.org/10.3390/app9163414
Chicago/Turabian StyleHwang, Ren-Hung, Min-Chun Peng, Van-Linh Nguyen, and Yu-Lun Chang. 2019. "An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level" Applied Sciences 9, no. 16: 3414. https://doi.org/10.3390/app9163414
APA StyleHwang, R. -H., Peng, M. -C., Nguyen, V. -L., & Chang, Y. -L. (2019). An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level. Applied Sciences, 9(16), 3414. https://doi.org/10.3390/app9163414