1. Introduction
Water contamination is an important environmental concern, posing a need for reliable information on contaminant concentrations in natural waters. This is especially the case in developing countries, where many factories may contribute to water pollution [
1,
2,
3]. The chemical oxygen demand (COD) is an important index that reflects the concentrations of organic pollutants in waters. At present, the analysis of COD is mainly based on a chemical method [
4]. This method uses potassium dichromate in a strongly acidic solution. In an excess of potassium dichromate, the substances in the water samples are reduced. Using a ferroin solution as an indicator, back titration is carried out with sulfuric acid and ferrous ammonium to calculate the amount of reducing substances, based on the amount of consumed ferrous sulfate of ammonia [
5,
6]. This method can detect water, effluent from sewage treatment plants and moderately polluted waste waters. It uses simple detection equipment and produces accurate measurement results. However, this chemical method consumes expensive silver sulfate and large amounts of concentrated sulfuric acid to eliminate the interference of chloride ions. It has the disadvantages of a long analysis period, heavy workload, high energy consumption and the generation of secondary pollution. Several optical methods also have been applied to measure COD in water samples, involving visible spectroscopy [
7], visible–near-infrared spectroscopy [
8], near-infrared spectroscopy [
9], dual-wavelength spectroscopy [
10], ultraviolet (UV) spectroscopy [
11] and photochemical luminescence method. Optical detection methods have the advantage of being fast and easy to operate, making them ideal for COD online real-time monitoring. A review of the available literature confirms that there are several statistical techniques able to determine the relationship between the estimated reflectance and physicochemical parameters of the water sample. In fact, several models were developed to investigate the relationship between measured values of COD in the laboratory and remote sensing reflectance, based on establishing linear, exponential or logarithmic regressions. Recent studies that estimate physicochemical parameters of water using such relationships are cited in
Table 1.
Although their results indicate that Landsat/Thematic Mapper (TM) imagery was used more than other sensors to estimate COD of waters, it has a relatively low potential and low accuracy, compared with other remote sensing techniques for the measurement of COD values in water bodies. Clearly, the relationships between spectral characteristics of images and in situ measurements of COD in the water bodies are still poorly understood. There also are some technical difficulties involved in analyzing the water absorption spectrum. For instance, there is mutual interference and cross sensitivity among different chemical substances, leading to errors. It was found that some of these issues could be resolved by using the capsule network model.
The capsule network is a deep learning model recently introduced by Geoffrey E Hinton in December 2017 [
23], which is original designed for a graph classification mission. It represents a completely novel type of neural network architecture that attempts to overcome the limits and drawbacks of CNN, such as lacking the explicit notion of the entity and losing valuable information during pooling layer. A capsule is a group of neurons that represents the instantiation parameters of an entity in the input data, while the length of the capsule represents the probability that the entity exists in the dataset. The capsule network has achieved good performance (5% error rate) on the task of segmenting and highly overlapping digits on MNIST dataset, which presents in
Figure 1. However, this task could not be done with convolution neural networks (CNN) [
24]. The authors were inspired by this achievement and applied the capsule network on a water spectrum analysis, since the water body contains different chemical substances and each substance has its absorption spectrum. The overall spectrum is the collection of all its substances spectrum that share a similar circumstance with highly overlapping digits. Moreover, this similarity can be further extended to many other remote sensing analyses because the spectrum usually represents the various properties of a particular entity that is present in the data. These properties can include many different types of instantiation parameters.
An interesting part of the capsule network is that it can reconstruct an input by using the outputs of the capsule vectors through the encoder-decoder method. During the training, the capsule vector corresponding to one training label was used to reconstruct the input dataset as a regularization for the optimization. The error between the reconstructed image and the input image was then used to optimize the reconstruction weights and the weights in the capsule network. It has been shown that the reconstruction part is important to the overall excellent performance on the MNIST dataset.
The capsule network was originally designed for 2-D graph classification problems (which actually have 3-D inputs, if you consider each channel as one dimension). This paper demonstrates a way to manipulate the model to fit 1-D input and to output a digital number (COD) instead of a probability vector. The different parameters were tested using this network. It is believed the parameters used in the capsule network give the best estimation of COD in our case study area. The study also shows that it is not necessary to remove noise bands caused by water absorption, which is usually carried out prior to analysis in other remote sensing methods.
2. Materials and Methods
2.1. Datasets
The data were collected from Baiyangdian area, located in the Xiong’an New Area, a prefecture-level city in the Baoding area of Hebei Province, China. It is the largest freshwater area in northern China. It is colloquially referred to as the kidney of North China. The area is home to approximately 50 varieties of fish and multiple varieties of wild geese, duck and other water birds. The area and surrounding parks also are home to a vast number of lotus, reed and other plants. Many locals make a living from harvesting fauna and flora from the area. Related to ongoing drought and over-exploitation of groundwater, as well as the influx of industrial wastewater since the 1980s, this region has faced water shortages and pollution problems, especially in Baiyangdian area.
During field reconnaissance, water spectra were measured using the PSR-3500 portable spectrometer (Spectral Evolution Inc., Lawrence, MA, USA), which covers the spectral range of 350–2500 nm and provides a spectral resolution of 3.5 nm, 10 nm and 7 nm at wavelengths of 700 nm, 1500 nm and 2100 nm. The spectral intervals are 1.5 nm, 3.8 nm and 2.5 nm for these same wavelengths. An example of a hyperspectral plot is shown in
Figure 2.
In
Figure 2, the spectra peak near wavelengths of 1400 nm, 1900 nm and 2500 nm are related to water absorption. These bands are typically ignored in traditional spectral studies. However, this study elected to input all bands into our model because the authors had confidence in the deep learning method to resolve all data. One of the advantages of this deep learning method is that bands are not custom selected. Therefore, scientist can use the model to predict COD without extensive experience in data processing related to remote sensing.
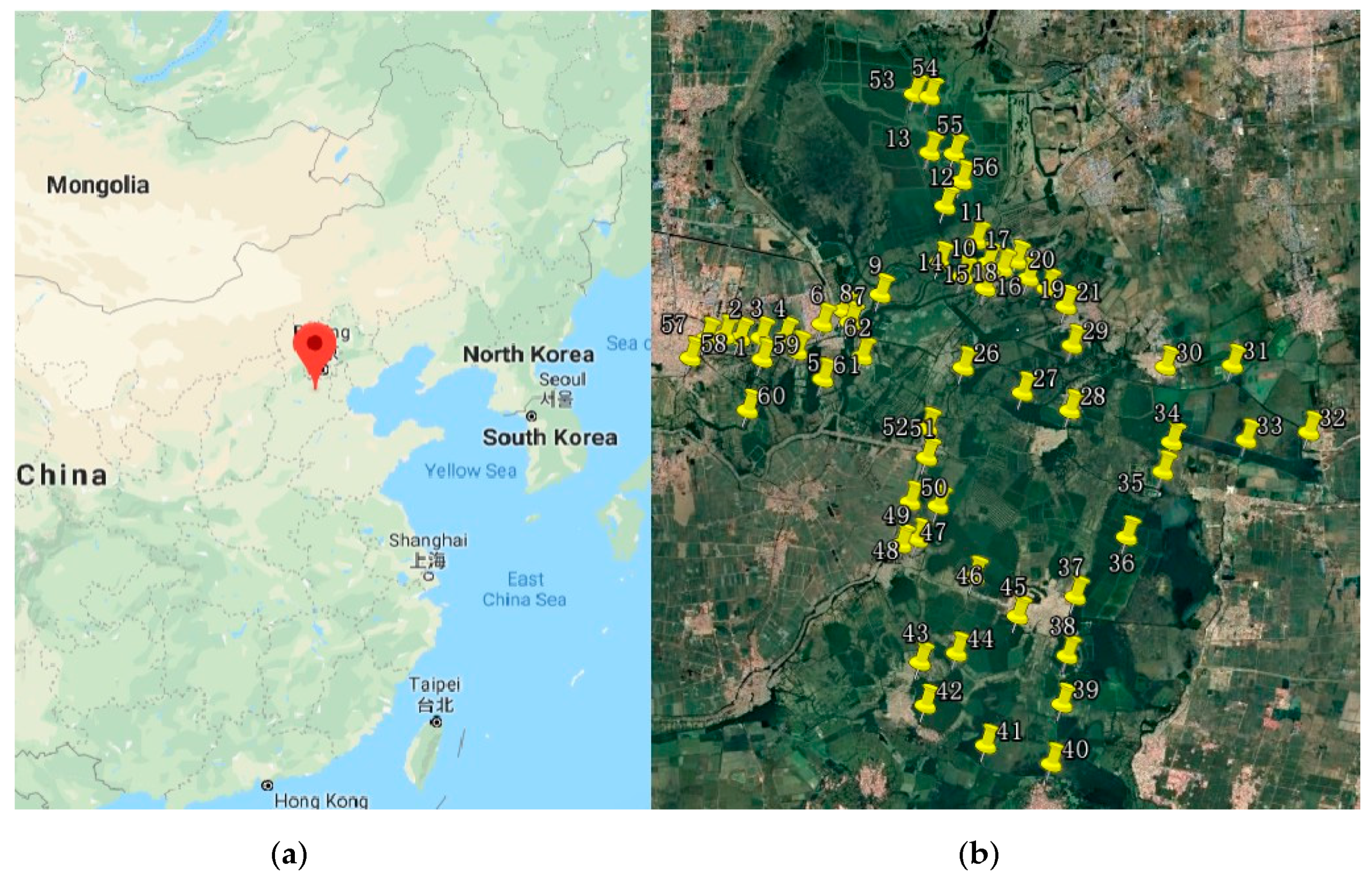
A total of 62 samples were collected from Baiyangdian area. The locations are given in
Figure 3. The sampling locations were carefully chosen, given that the main goal of this paper focused on the relationship between the COD value and the hyperspectral data. The authors also wanted to study the impact of human activities on water pollution. Hence, some samples were chosen at the river crossing the city, the edge of the city or the intersection of the rivers. By observing and analyzing the water quality on these points, the information can be acquired on how the human activities impact the water quality. The COD values of all samples were acquired in the laboratory based on conventional chemical methods. These values were treated as the true labels.
This study selected 43 samples as training data and the other 19 samples as testing data. The training and testing sets were representative of the entire water sample set in terms of the minimum, maximum, mean and standard deviation values. This was crucial to our analysis because min-max normalization was used to preprocess the data. This requires similar maxima and minima between the training and testing sets. The statistics of the COD index are given in
Table 2. While histograms representing these data are shown in
Figure 2.
2.2. The Architecture of Capsule Networks
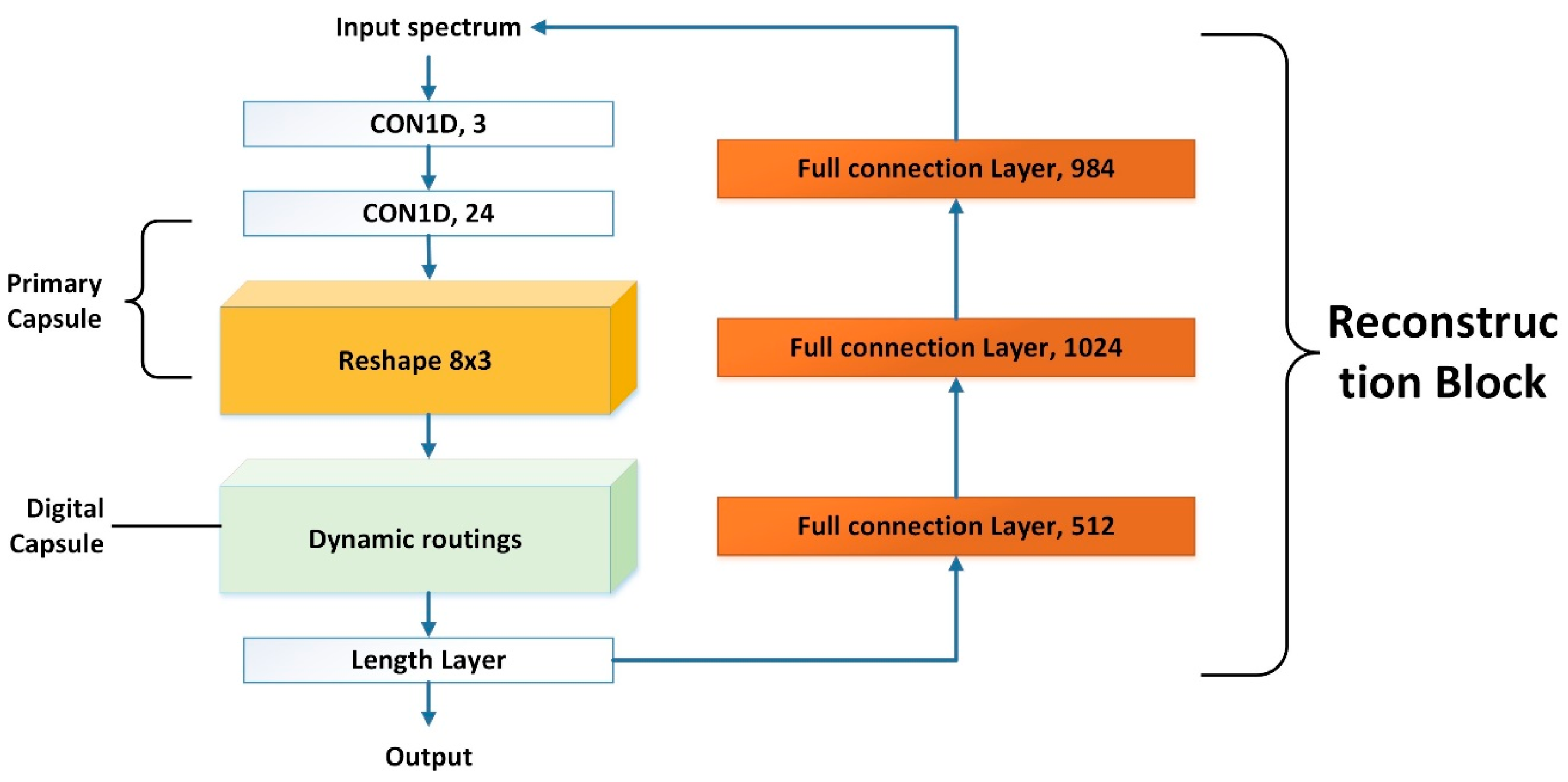
Figure 4 shows the architecture of the capsule network, designed for COD estimation. The model needed to handle 1-D hyperspectral data with a vector length of 984. There are three layers in capsule networks. Each layer was modified to suit our objective. In the first layer, the original 2-D convolution kernel was replaced by a 1-D convolution kernel to fit the 1-D input data. The model was extended by one channel dimension so that the input data met the requirement of the CONV1D function in Python. Moreover, it was found that a small kernel produced better accuracy than a larger one. Hence, a kernel with a size of one was used in our model instead of a kernel of 9 × 9, and only 3 channels were used in our first layer to replace the 256 channels in the original model. It was demonstrated that these modifications reduced the parameters without a loss of accuracy.
The second layer is called the primary capsule layer. In this layer, the capsule dimension of the input was extended. One fast and convenient way to manipulate the method was to apply the convolution kernels to the input and then reshape the output to the designated number of dimensions. For example, in our model, 24 1-D convolution kernels were applied to the input and then reshaped the output to 3 × 8, reflecting 3 channels and an 8-unit length capsule vector. A small kernel size was used with fewer vectors in the capsule dimension compared with the original network.
The third layer is called the digit capsule layer, which is the key part of the capsule network. For all but the first part of the digit capsule layer, the total input to a capsule
a weighted sum over-all
and
is produced by multiplying the output
of a capsule by a weight matrix
:
where
cij are the coupling coefficients determined by the iterative dynamic routing process. The formula for these
cij is given by:
where
bij is initially set to zero and upgraded by
bij =
bij +
uj|i ·
vj. In this case,
vj is determined in ach iteration in a dynamic routing process. The length of the output vector represents the probability that the entity is contained and exists in the input data. To represent such properties, a non-linear “squashing” activation function, shown in Equation (3) is introduced, which ensures that the short vectors are shrunk to near zero and long vectors are shrunk close to one, leaving their orientation unchanged.
The total routing algorithm is given in
Table 3.
The most important aspect of this routing procedure is that it uses dynamic routing to update the weights ci instead of using back-propagation.
The original model had to be modified because the range of the output in the digit capsule layer was not compatible with the label. The original model is supposed to output a probability that is used for classification, which has a range from zero to one. However, this study is dealing with a regression problem. In this case, the true label does not have a constraint on its range. Here, two options were outlined to solve this problem. Either a full-connection layer can be added after the digit capsule layer, whereby this full-connection layer builds a mapping between [0, 1] → R that makes the regression possible, or a min-max normalization can be applied to the label to compress the label into the range [0, 1]. The min-max normalization is preferred because the default weight setting is usually near to zero. In this case, the value of y = ∑ wx + b is small compared with the true label. When the label value is large, then it takes much more time to converge using a full-connection layer. However, there is no such problem, when the label compresses into [0, 1], which has the same range as the output from the digit capsule layer.
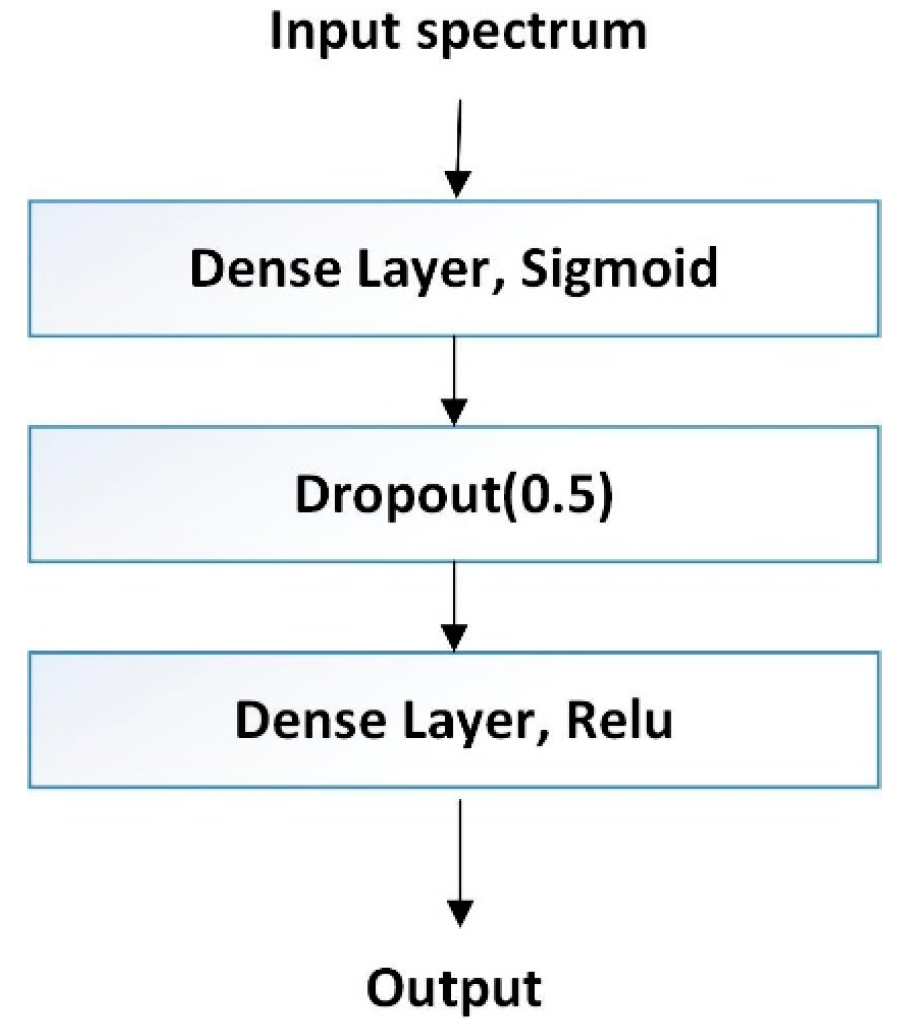
Finally, the reconstruction block in the original capsule network was redesigned as a linear regression model for COD quantification, based on the output vector from the digital capsule layer. The reconstruction loss was used to encourage the digital capsule to encode and decode instantiation parameters. During the training, the output of the digital capsule layer was fed into the decoder, consisting of three fully connected layers, as shown in
Figure 4.
4. Conclusions
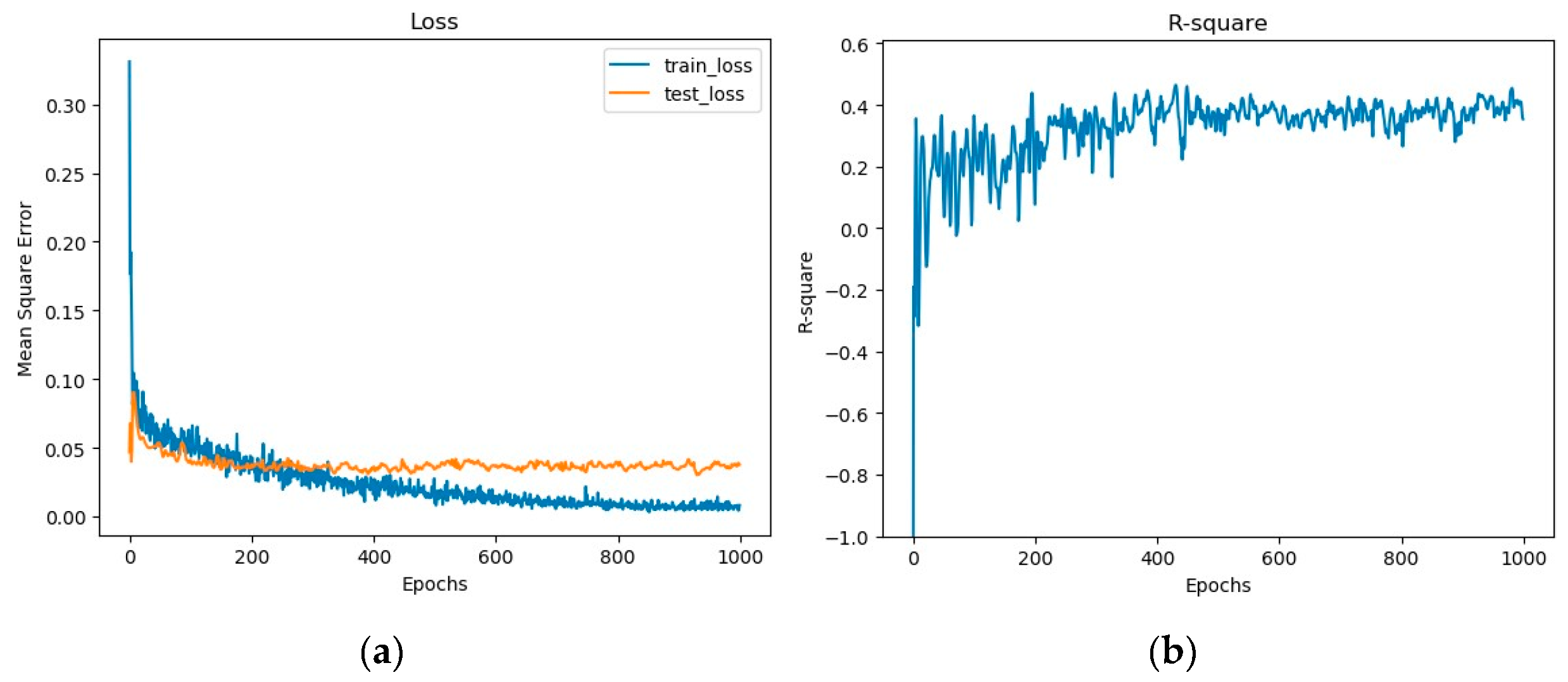
The capsule network is a recently proposed deep learning network, and only limited studies have explored its potential applications. Motivated by the novelty of the capsule network, this study attempted to use it for hyperspectral regression. Herein, a modified three-layer capsule network for water COD prediction based on 1-D hyperspectral data was provided. It was tested using a real dataset collected in the Baiyangdian area in North China. In addition, a comparable BP network architecture was designed to compare with the capsule network. The capsule network achieved better results, with a limited training set of samples. Moreover, the architecture of the original capsule network was largely simplified because the authors found it unnecessary to use many channels and large kernels. It was also demonstrated that denoising is not necessary for our model, making the model more universally applicable. To the authors’ knowledge, the complexity of the capsule network has not been well explored, and further efforts should be devoted to investigating its potential. The fact that this simple capsule network gave unparalleled performance in COD prediction is an early indication that this method is very useful for 1-D regression problems.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}