Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder


Abstract
:
1. Introduction
2. Related Work
2.1. Feature Extraction and Reconstruction
2.2. Generative Adversarial Networks
2.3. GAN-Based Image-to-Image Translation
3. Method
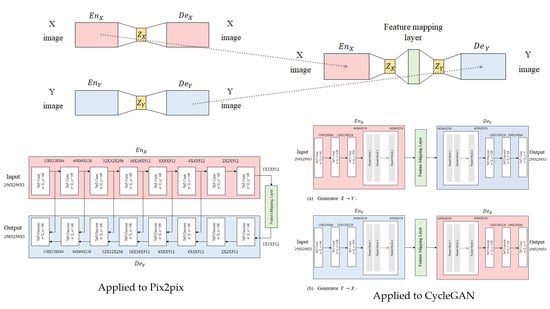
3.1. Feature Space Mapping
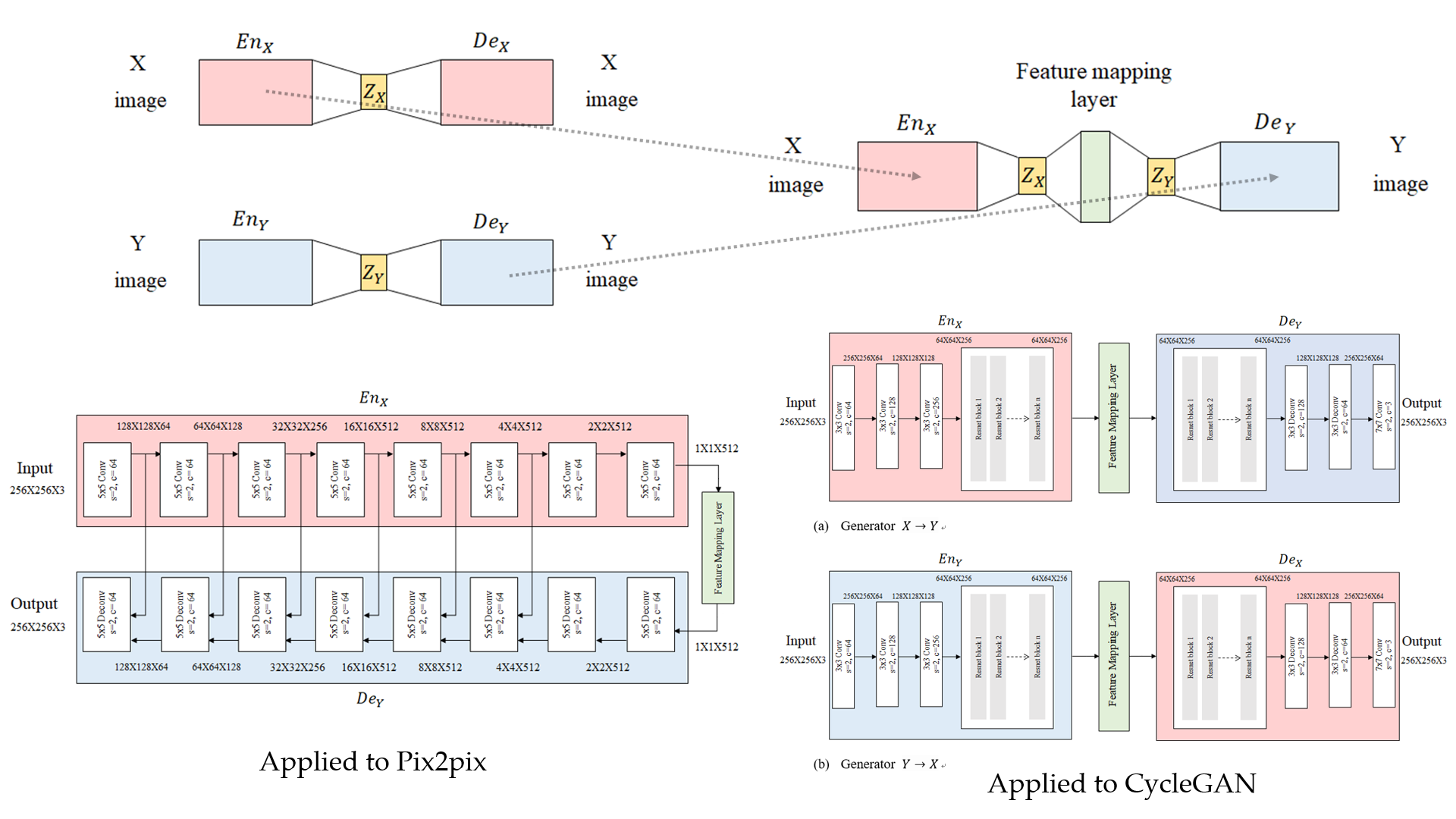
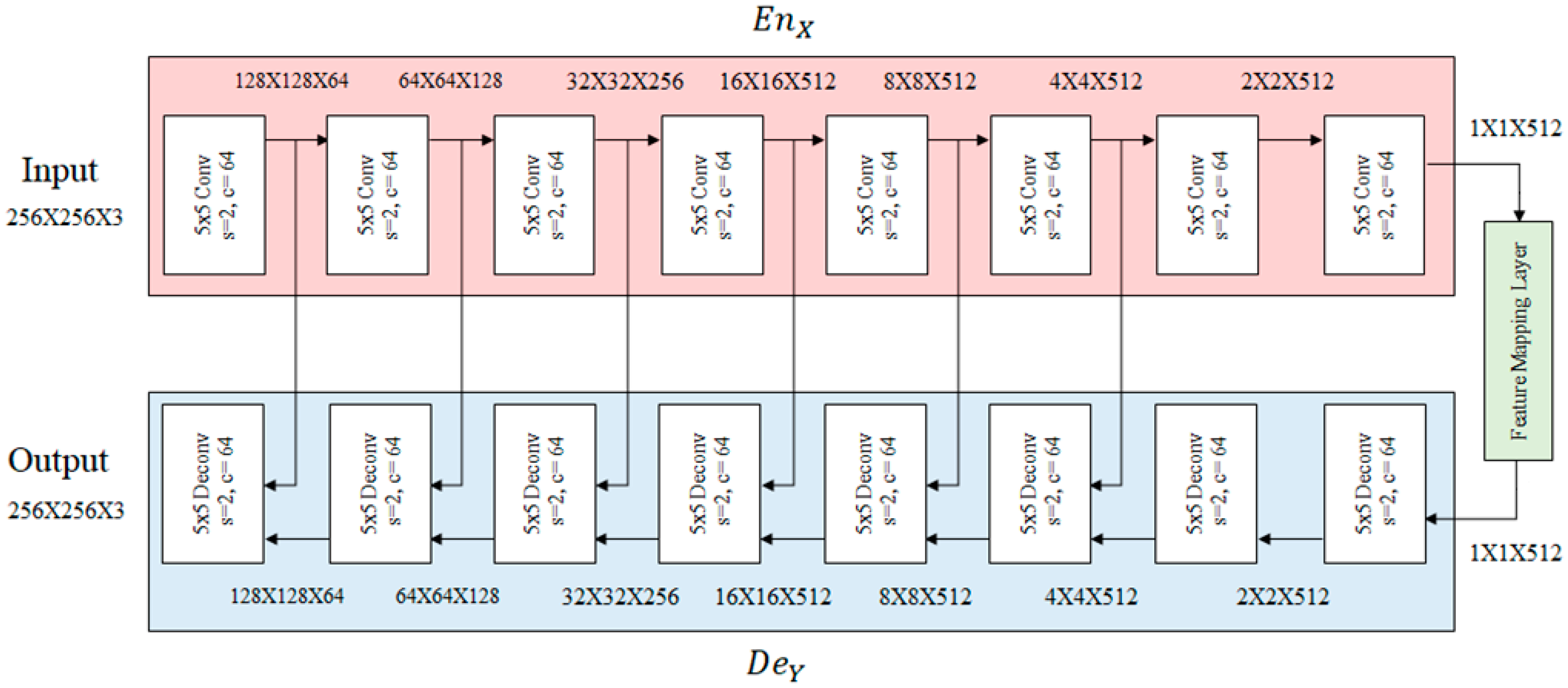
3.2. Model Architecture
3.2.1. Generator and Discriminator
3.2.2. Feature Mapping Layer
4. Results
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Qualitative Comparisons
4.3.1. Comparisons with Baselines
4.3.2. Comparisons with UNIT
4.4. Quantitative Comparisons
4.5. The Effectiveness of the Feature Mapping Layer
5. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A


References
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 649–666. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning-Volume, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward Multimodal Image-to-Image Translation. In Proceedings of the 32th Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 465–476. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Masci, J.; Meier, U.; Cire San, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Proceedings of the 21st International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive Auto-Encoders: Explicit Invariance during Feature Extraction. In Proceedings of the 28th International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2011; pp. 833–840. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 29th Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Nie, D.; Trullo, R.; Lian, J.; Petitjean, C.; Ruan, S.; Wang, Q.; Shen, D. Medical Image Synthesis with Context-Aware Generative Adversarial Networks. In Proceedings of the 20th International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; pp. 417–425. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8183–8192. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. arXiv 2019, arXiv:1903.07291. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Sangkloy, P.; Lu, J.; Fang, C.; Yu, F.; H, J. Scribbler: Controlling Deep Image Synthesis with Sketch and Color. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5400–5409. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. arXiv 2017, arXiv:1701.05957. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O. Coupled Generative Adversarial Networks. In Proceedings of the 31th Advances In Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 469–477. [Google Scholar]
- Zhou, T.; Krahenbuhl, P.; Aubry, M.; Huang, Q.; Efros, A.A. Learning Dense Correspondence via 3d-Guided Cycle Consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 117–126. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. In Proceedings of the 32th Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Yang, X.; Xie, D.; Wang, X. Crossing-Domain Generative Adversarial Networks for Unsupervised Multi-Domain Image-to-Image Translation. In Proceedings of the 26th ACM Multimedia Conference on Multimedia Conference, Seoul, Korea, 22–26 October 2018; pp. 374–382. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Silva, E.A.; Panetta, K.; Agaian, S.S. Quantifying image similarity using measure of enhancement by entropy. In Proceedings of the Mobile Multimedia/Image Processing for Military and Security Applications, Orlando, FL, USA, 11–12 April 2007; p. 65790U. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Galteri, L.; Seidenari, L.; Bertini, M.; Del Bimbo, A. Deep Generative Adversarial Compression Artifact Removal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4826–4835. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training Gans. In Proceedings of the 31th Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochriter, S. Gans Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the 32th Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Label → Photo | |||||
|---|---|---|---|---|---|---|
| SSIM ↑ | PSNR ↑ | MAE ↓ | MSE ↓ | IS ↑ | FID ↓ | |
| Baseline (Pix2pix) | 0.2863 | 12.8684 | 41.7085 | 3547.5539 | 2.3955 ± 0.1610 | 101.04794 |
| Baseline (CycleGAN) | 0.3416 | 14.5333 | 35.4496 | 2558.5918 | 2.3421 ± 0.2216 | 75.3792 |
| UNIT | 0.3526 | 14.6102 | 35.4176 | 2653.8875 | 2.3304 ± 0.2486 | 82.7469 |
| Ours + 3*3 convolutional layer (on CycleGAN) | 0.3571 | 14.2083 | 36.1383 | 2714.3276 | 2.4554 ± 0.1582 | 69.1041 |
| Metrics | Photo → Label | |||||
|---|---|---|---|---|---|---|
| SSIM ↑ | PSNR ↑ | MAE ↓ | MSE ↓ | IS ↑ | FID ↓ | |
| Baseline (CycleGAN) | 0.5568 | 15.0977 | 25.7486 | 2185.6808 | 2.1170 ± 0.1927 | 107.4895 |
| Ours w/o feature mapping layer | 0.5054 | 13.5550 | 37.9918 | 2999.5845 | 2.2096 ± 0.1290 | 107.3393 |
| Ours + 1 × 1 convolutional layer | 0.5326 | 14.5956 | 33.2103 | 2439.4565 | 1.9608 ± 0.1521 | 96.7853 |
| Ours + 3 × 3 convolutional layer | 0.5526 | 15.4477 | 29.9302 | 2040.3728 | 2.0509 ± 0.1997 | 93.4251 |
| Ours + 7 × 7 depth-wise convolutional layer | 0.5029 | 13.1269 | 37.9808 | 3301.7309 | 2.1264 ± 0.1557 | 126.5632 |
| Ours + 1 × 1 convolutional layer + residual connection (in FML) | 0.5006 | 13.6503 | 39.0486 | 2928.5135 | 2.1674 ± 0.1042 | 120.7020 |
| Ours + 3 × 3 convolutional layer + residual connection (in FML) | 0.5017 | 13.5443 | 37.6828 | 3026.7782 | 2.0445 ± 0.1418 | 108.9408 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, J.; Eom, H.; Choi, Y.S. Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder. Appl. Sci. 2019, 9, 4780. https://doi.org/10.3390/app9224780
Yoo J, Eom H, Choi YS. Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder. Applied Sciences. 2019; 9(22):4780. https://doi.org/10.3390/app9224780
Chicago/Turabian StyleYoo, Jaechang, Heesong Eom, and Yong Suk Choi. 2019. "Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder" Applied Sciences 9, no. 22: 4780. https://doi.org/10.3390/app9224780
APA StyleYoo, J., Eom, H., & Choi, Y. S. (2019). Image-To-Image Translation Using a Cross-Domain Auto-Encoder and Decoder. Applied Sciences, 9(22), 4780. https://doi.org/10.3390/app9224780