Identify Road Clusters with High-Frequency Crashes Using Spatial Data Mining Approach



Abstract
:1. Introduction
2. Methodology
2.1. Process Map
- (1)
- Preprocessing
- (2)
- Conceptualization
- (3)
- Spatial data mining
2.2. File Types
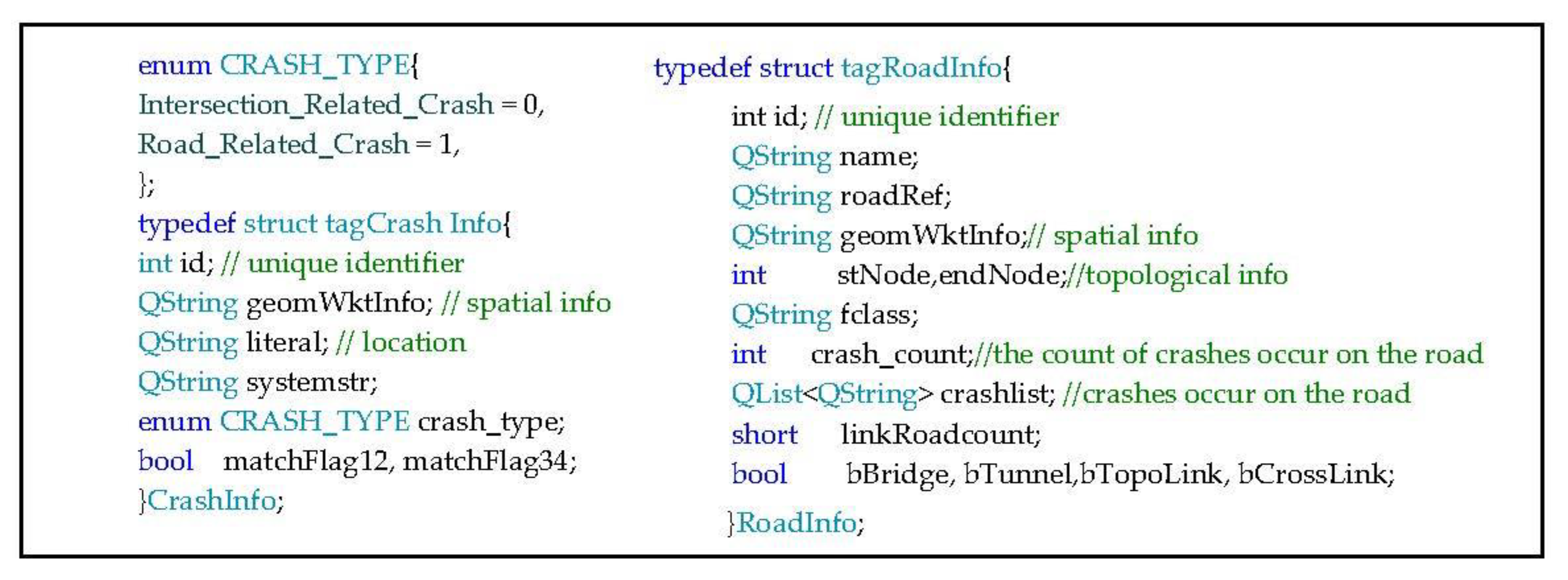
2.2.1. The Input Files
2.2.2. The Intermediate Files
2.2.3. Output Results
2.2.4. Remark on Availability of Input Files
2.3. Methods
2.3.1. Crash Spatial Aggregation Algorithm
- Premise 1
- As the accuracy of crash global positioning system (GPS) coordinate has a positioning error of approximately 10 m [34]. A crash occurs on the road if its coordinates are within 10 m of the buffer of the linear road considering the positioning error of crash.
- Premise 2
- As the Interstate Highway standards for the U.S. Interstate Highway System use a 12 foot (3.7 m) standard lane width [35], a crash occurring on the road can be determined if its coordinates are within 3.7 m of the buffer of the road.
- Condition 1: The shortest distance between traffic crash and road less than 47 m (consider 10 lane roads and GPS positioning accuracy) order by the distance.
- Condition 2: Attribute matching between name of road and location of crash.
- Condition 3: The shortest distance between traffic crash and road is less than 10 m (consider GPS positioning accuracy).
- Condition 4: The shortest distance between traffic crash and road is minimum in all datasets.
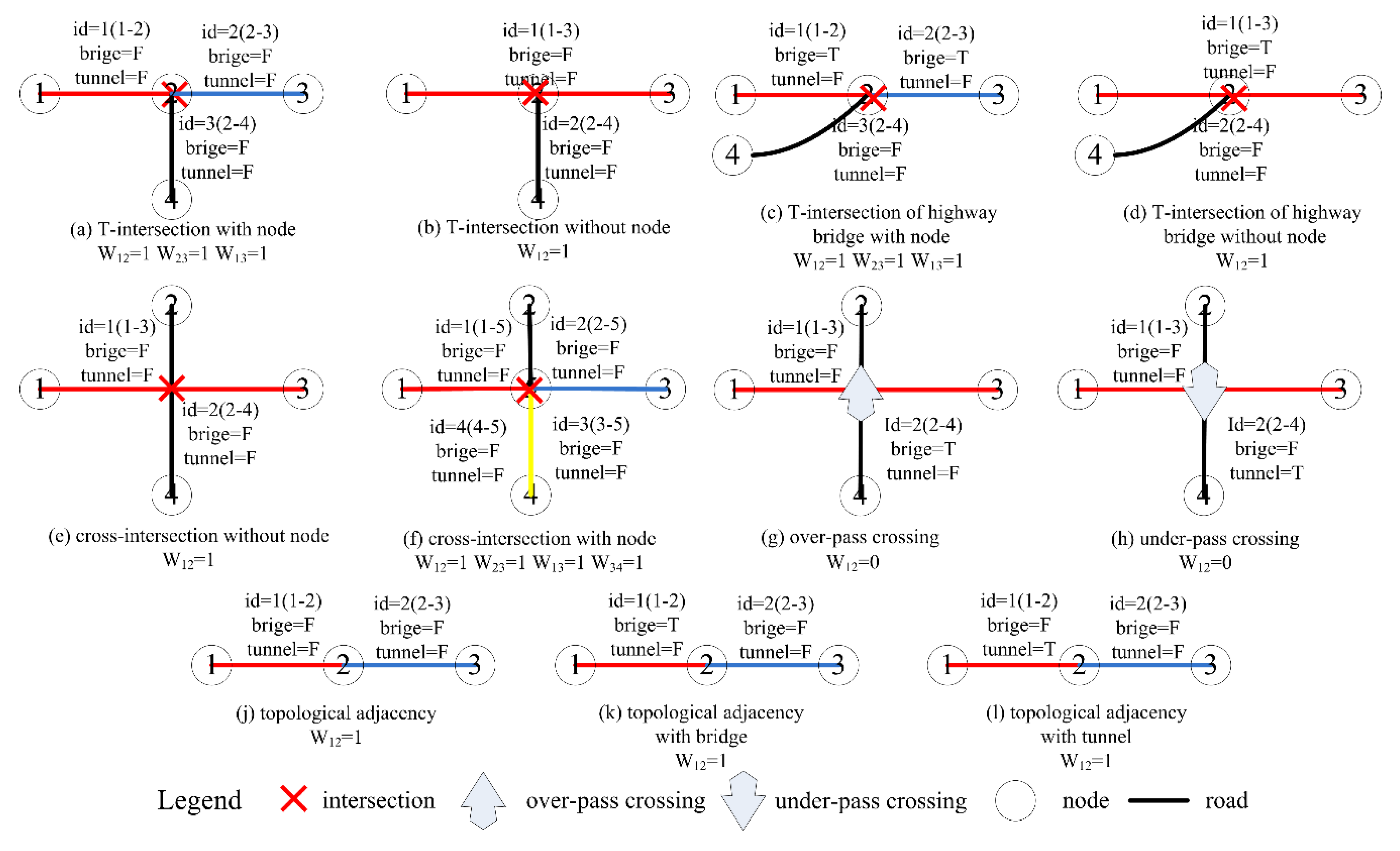
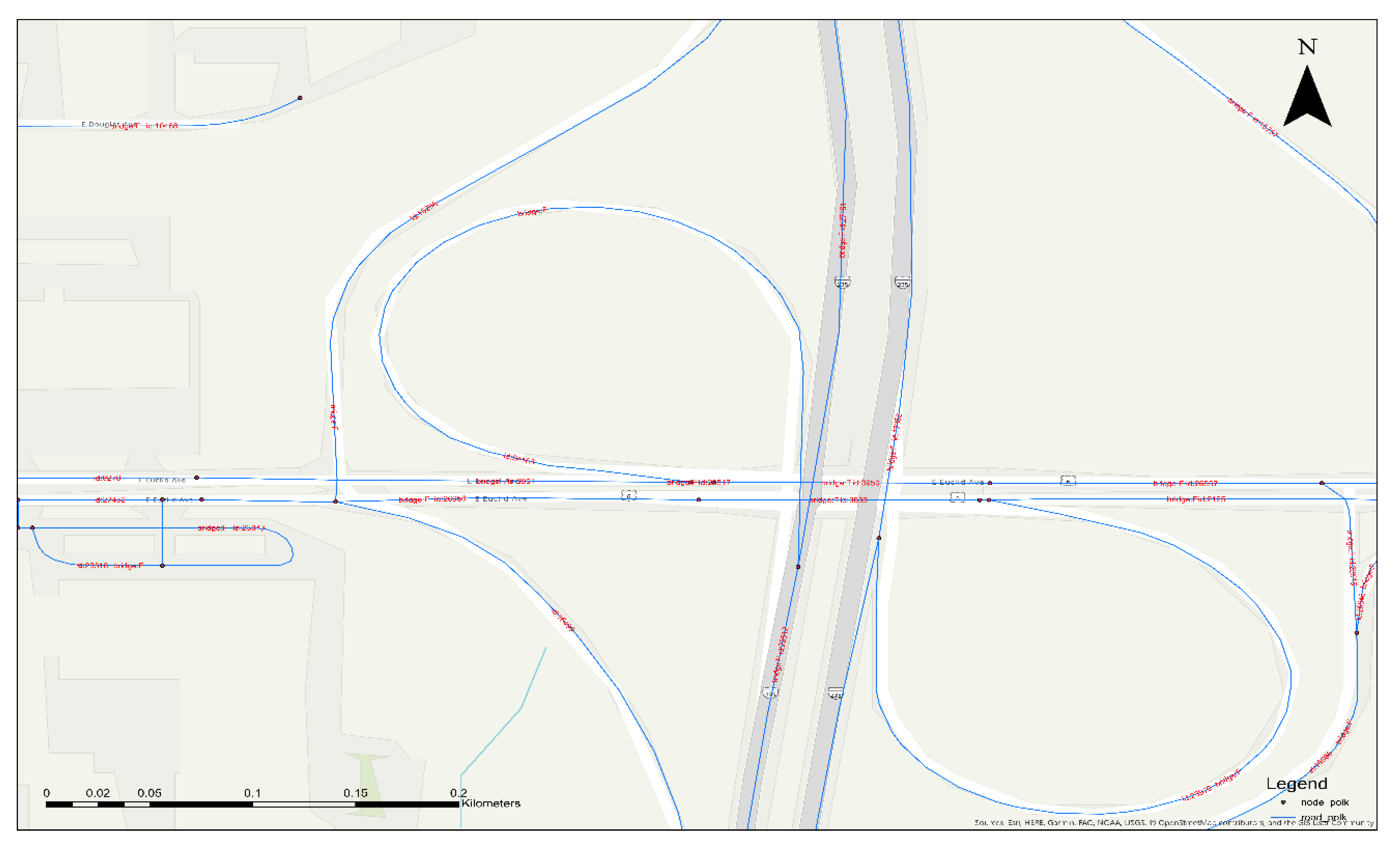
2.3.2. SWMR Construction Algorithm
- The spatial weights of SWMR are 1 if the roads are topological adjacent for the following cases. (a) T-intersection with node, (c) T-intersection of highway bridge with node, (f) cross-intersection with node, (j) topological adjacency, (k) topological adjacency with bridge, and (l) topological adjacency with tunnel.
- The spatial weights of SWMR are 1 if the roads are geometric adjacent for the following cases. (b) T-intersection without node, (d) T-intersection of highway bridge without node, and (e) cross-intersection without node.
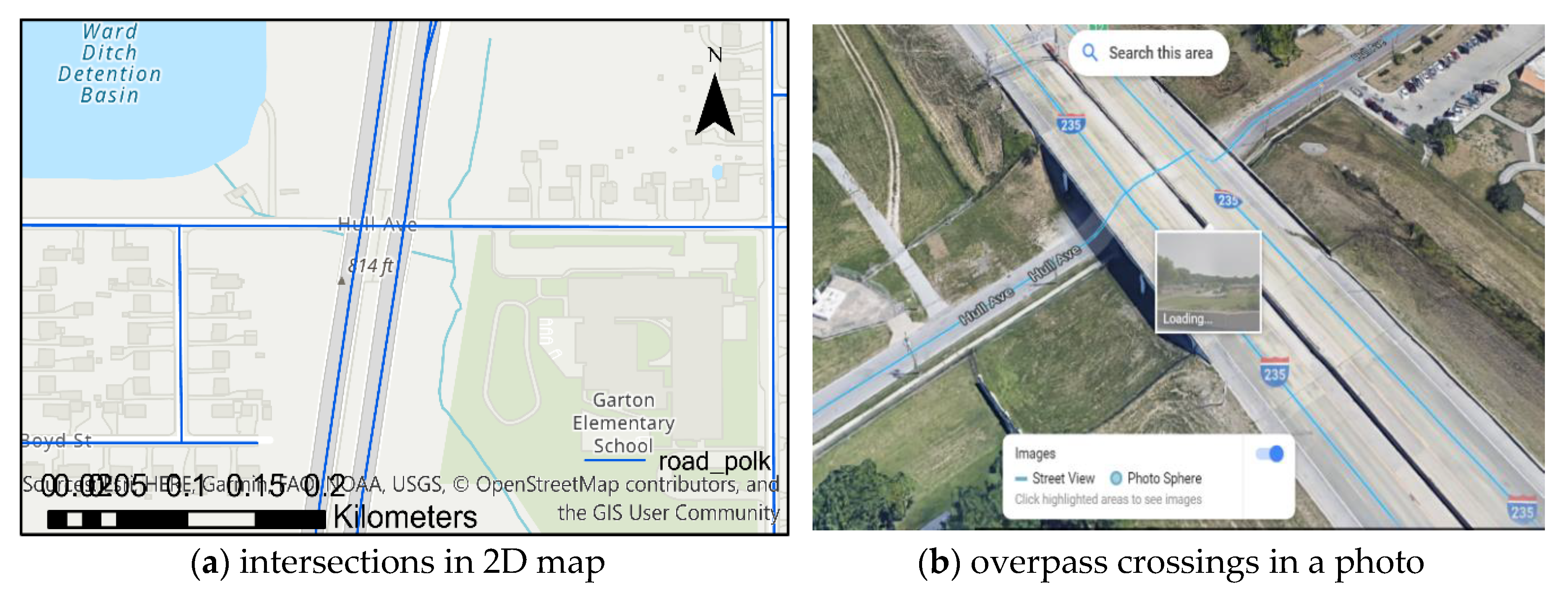
- The spatial weights of SWMR are 0 if the roads are neither geometric adjacent nor non topological adjacent for the following cases; (g) overpass crossing and (h) underpass crossing.
2.3.3. Cluster and Outlier Analysis (Local Moran’s I)
3. Data Description
3.1. The Spatial Data of Roads
3.2. The Spatial Data of Road-Related Crashes
4. Results and Discussion
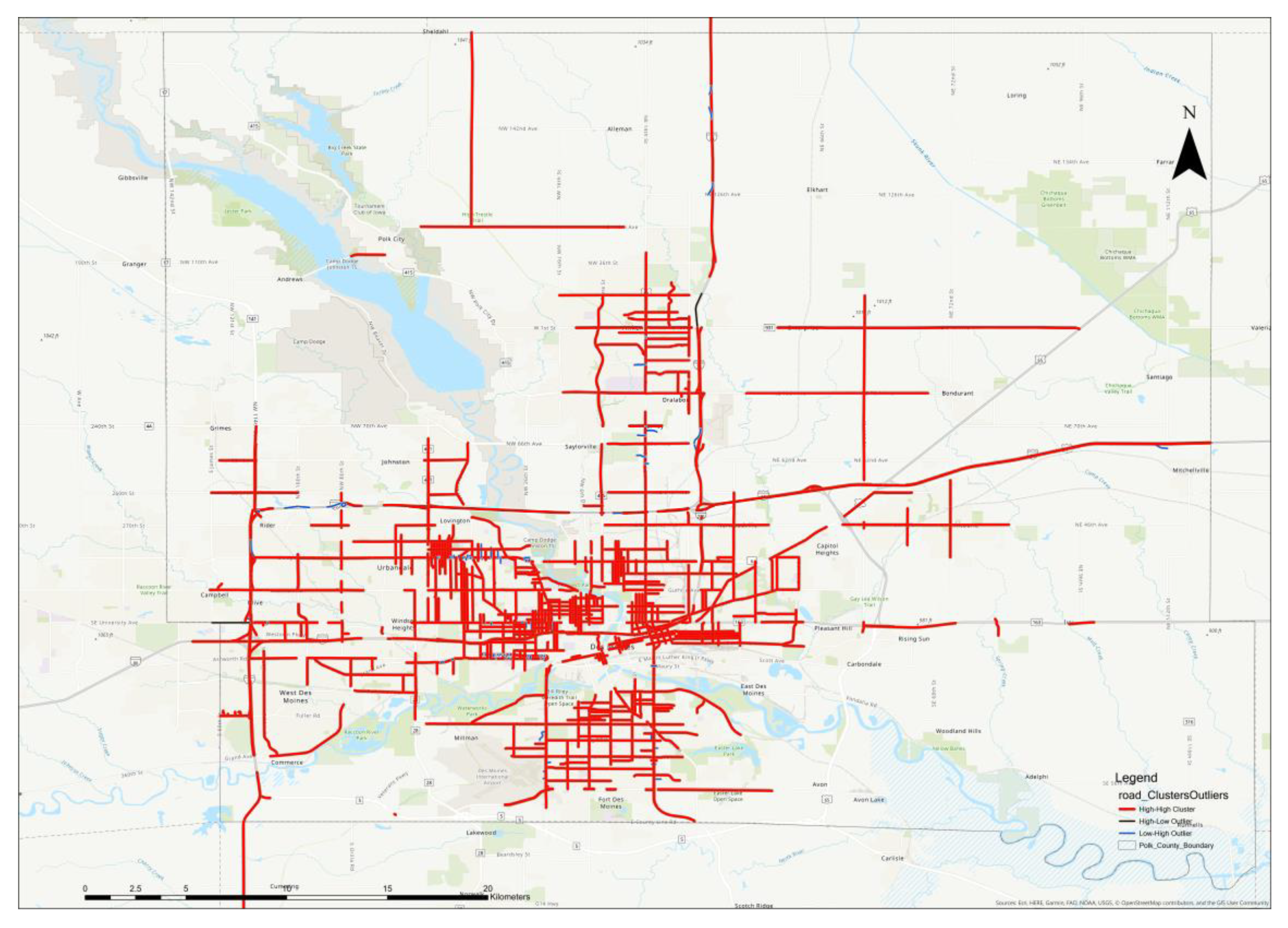
4.1. The SWMR of Polk County
4.2. The Results of Road Cluster and Outlier Analysis of Polk County
5. Recommendation of Future Work
5.1. Spatiotemporal Data Mining Approach.
5.2. Identify Traffic Bottleneck.
5.3. Identify Certain Roadway Damages.
5.4. Cloud-Based RCHC Identification
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Harirforoush, H.; Bellalite, L.; Bénié, G.B. Spatial and Temporal Analysis of Seasonal Traffic Accidents. Am. J. Traffic Transp. Eng. 2019, 4, 7–16. [Google Scholar] [CrossRef] [Green Version]
- Pelaez, C.G.A.; Garcia, F.; de la Escalera, A.; Armingol, J.M. Driver Monitoring Based on Low-Cost 3-D Sensors. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1855–1860. [Google Scholar] [CrossRef] [Green Version]
- Carmona, J.; García, F.; Martín, D.; Escalera, A.; Armingol, J. Data Fusion for Driver Behaviour Analysis. Sensors 2015, 15, 25968–25991. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Elsevier/Morgan Kaufmann: Amsterdam, The Netherland; Boston, MA, USA, 2012; ISBN 978-0-12-381480-7. [Google Scholar]
- Kumar, S.; Toshniwal, D. A data mining framework to analyze road accident data. J. Big Data 2015, 2, 26. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Deng, P.; Wan, J.; Zhang, D.; Vasilakos, A.V.; Rong, X. Data Mining for the Internet of Things: Literature Review and Challenges. Int. J. Distrib. Sens. Netw. 2015, 11, 431047. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.; Toshniwal, D.; Parida, M. A comparative analysis of heterogeneity in road accident data using data mining techniques. Evol. Syst. 2017, 8, 147–155. [Google Scholar] [CrossRef]
- Castro, Y.; Kim, Y.J. Data mining on road safety: Factor assessment on vehicle accidents using classification models. Int. J. Crashworthiness 2016, 21, 104–111. [Google Scholar] [CrossRef]
- Taamneh, M.; Alkheder, S.; Taamneh, S. Data-mining techniques for traffic accident modeling and prediction in the United Arab Emirates. J. Transp. Saf. Secur. 2017, 9, 146–166. [Google Scholar] [CrossRef]
- Li, L.; Shrestha, S.; Hu, G. Analysis of road traffic fatal accidents using data mining techniques. In Proceedings of the 2017 IEEE 15th International Conference on Software Engineering Research, Management and Applications (SERA), London, UK, 7–9 June 2017; IEEE: London, UK, 2017; pp. 363–370. [Google Scholar] [CrossRef]
- Soltani, A.; Askari, S. Exploring spatial autocorrelation of traffic crashes based on severity. Injury 2017, 48, 637–647. [Google Scholar] [CrossRef]
- Shekhar, S.; Jiang, Z.; Ali, R.; Eftelioglu, E.; Tang, X.; Gunturi, V.; Zhou, X. Spatiotemporal Data Mining: A Computational Perspective. ISPRS Int. J. Geo-Inf. 2015, 4, 2306–2338. [Google Scholar] [CrossRef]
- Zheng, Y. Trajectory Data Mining: An Overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 29. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Pourghasemi, H.R. Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling. Catena 2017, 157, 310–324. [Google Scholar] [CrossRef]
- Ouni, F.; Belloumi, M. Pattern of road traffic crash hot zones versus probable hot zones in Tunisia: A geospatial analysis. Accid. Anal. Prev. 2019, 128, 185–196. [Google Scholar] [CrossRef]
- Xie, Z.; Yan, J. Detecting traffic accident clusters with network kernel density estimation and local spatial statistics: An integrated approach. J. Transp. Geogr. 2013, 31, 64–71. [Google Scholar] [CrossRef]
- Blazquez, C.A.; Celis, M.S. A spatial and temporal analysis of child pedestrian crashes in Santiago, Chile. Accid. Anal. Prev. 2013, 50, 304–311. [Google Scholar] [CrossRef]
- Zhang, T.; Lin, G. On Moran’s I coefficient under heterogeneity. Comput. Stat. Data Anal. 2016, 95, 83–94. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association-LISA. Geogr. Anal. 2010, 27, 93–115. [Google Scholar] [CrossRef]
- Jana, M.; Sar, N. Modeling of hotspot detection using cluster outlier analysis and Getis-Ord Gi * statistic of educational development in upper-primary level, India. Model. Earth Syst. Environ. 2016, 2, 60. [Google Scholar] [CrossRef] [Green Version]
- Mitra, S. Spatial Autocorrelation and Bayesian Spatial Statistical Method for Analyzing Intersections Prone to Injury Crashes. Transp. Res. Rec. 2009, 2136, 92–100. [Google Scholar] [CrossRef]
- Yuan, Y.; Cave, M.; Zhang, C. Using Local Moran’s I to identify contamination hotspots of rare earth elements in urban soils of London. Appl. Geochem. 2018, 88, 167–178. [Google Scholar] [CrossRef]
- Soltanolkotabi, M.; Candés, E.J. A geometric analysis of subspace clustering with outliers. Ann. Stat. 2012, 40, 2195–2238. [Google Scholar] [CrossRef]
- Hashimoto, S.; Yoshiki, S.; Saeki, R.; Mimura, Y.; Ando, R.; Nanba, S. Development and application of traffic accident density estimation models using kernel density estimation. J. Traffic Transp. Eng. 2016, 3, 262–270. [Google Scholar] [CrossRef] [Green Version]
- Anderson, T.K. Kernel density estimation and K-means clustering to profile road accident hotspots. Accid. Anal. Prev. 2009, 41, 359–364. [Google Scholar] [CrossRef] [PubMed]
- Mawarni, M.; Machdi, I. Dynamic nearest neighbours for generating spatial weight matrix. In Proceedings of the 2016 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Malang, Indonesia, 15–16 October 2016; IEEE: Malang, Indonesia, 2016; pp. 257–262. [Google Scholar] [CrossRef]
- Qu, X.; Lee, L. Estimating a spatial autoregressive model with an endogenous spatial weight matrix. J. Econom. 2015, 184, 209–232. [Google Scholar] [CrossRef]
- Ermagun, A.; Levinson, D. An introduction to the network weight matrix. Geogr. Anal. 2018, 50, 76–96. [Google Scholar] [CrossRef]
- Obe, R.O.; Hsu, L.S. PostgreSQL: Up and Running, 2nd ed.; O’Reilly: Sebastopol, CA, USA, 2014; ISBN 978-1-4493-7319-1. [Google Scholar]
- Bogorny, V.; Avancini, H.; de Paula, B.C.; Kuplich, C.R.; Alvares, L.O. Weka-STPM: A Software Architecture and Prototype for Semantic Trajectory Data Mining and Visualization. Trans. GIS 2011, 15, 227–248. [Google Scholar] [CrossRef]
- Singh, P.S.; Lyngdoh, R.B.; Chutia, D.; Saikhom, V.; Kashyap, B.; Sudhakar, S. Dynamic shortest route finder using pgRouting for emergency management. Appl. Geomat. 2015, 7, 255–262. [Google Scholar] [CrossRef]
- Scott, L.M.; Janikas, M.V. Spatial Statistics in ArcGIS. In Handbook of Applied Spatial Analysis; Fischer, M.M., Getis, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 27–41. ISBN 978-3-642-03646-0. [Google Scholar] [CrossRef]
- Anselin, L.; Syabri, I.; Kho, Y. GeoDa: An Introduction to Spatial Data Analysis. Geogr. Anal. 2006, 38, 5–22. [Google Scholar] [CrossRef]
- Wing, M.G.; Eklund, A.; Kellogg, L.D. Consumer-Grade Global Positioning System (GPS) Accuracy and Reliability. J. For. 2005, 103, 169–173. [Google Scholar] [CrossRef]
- Khan, M.; Abdel-Rahim, A.; Williams, C.J. Potential crash reduction benefits of shoulder rumble strips in two-lane rural highways. Accid. Anal. Prev. 2015, 75, 35–42. [Google Scholar] [CrossRef]
- Getis, A.; Aldstadt, J. Constructing the Spatial Weights Matrix Using a Local Statistic. Geogr. Anal. 2004, 36, 90–104. [Google Scholar] [CrossRef]
- Seya, H.; Yamagata, Y.; Tsutsumi, M. Automatic selection of a spatial weight matrix in spatial econometrics: Application to a spatial hedonic approach. Reg. Sci. Urban Econ. 2013, 43, 429–444. [Google Scholar] [CrossRef]
- Getis, A. Spatial interaction and spatial autocorrelation: A cross-product approach. Environ. Plan. A Econ. Space 1991, 23, 1269–1277. [Google Scholar] [CrossRef]
- Liu, H.; Wang, J. Vulnerability assessment for cascading failure in the highway traffic system. Sustainability 2018, 10, 2333. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Huang, R.; Chen, X.; Xie, Z.; Liang, Y.; Lv, W.; Ma, J. Active CTDaaS: A data service framework based on transparent IoD in city traffic. IEEE Trans. Comput. 2016, 65, 3524–3536. [Google Scholar] [CrossRef]
- Tobler, W. On the First Law of Geography: A Reply. Ann. Assoc. Am. Geogr. 2004, 94, 304–310. [Google Scholar] [CrossRef]
- Kumari, M.; Sarma, K.; Sharma, R. Using Moran’s I and GIS to study the spatial pattern of land surface temperature in relation to land use/cover around a thermal power plant in Singrauli district, Madhya Pradesh, India. Remote Sens. Appl. Soc. Environ. 2019, 15, 100239. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. OpenStreetMap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Aghajani, M.A.; Dezfoulian, R.S.; Arjroody, A.R.; Rezaei, M. Applying GIS to Identify the Spatial and Temporal Patterns of Road Accidents Using Spatial Statistics (case study: Ilam Province, Iran). Transp. Res. Procedia 2017, 25, 2126–2138. [Google Scholar] [CrossRef]
- Estiri, H. Tracking Urban Sprawl: Applying Moran’s I Technique in Developing Sprawl Detection Models. In Proceedings of the 43rd Annual Conference of the Environmental Design Research Association EDRA, Seattle, WA, USA, 30 May–2 June 2012; pp. 47–53. [Google Scholar]
- Zheng, Z.; Ahn, S.; Chen, D.; Laval, J. Applications of wavelet transform for analysis of freeway traffic: Bottlenecks, transient traffic, and traffic oscillations. Transp. Res. Part B Methodol. 2011, 45, 372–384. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Zhou, W.; Liu, C.; Cui, Y.; Xiong, H. Transit pattern detection using tensor factorization. Inf. J. Comput. 2019, 31, 193–206. [Google Scholar] [CrossRef]
- Ma, X.; Luan, S.; Du, B.; Yu, B. Spatial copula model for imputing traffic flow data from remote microwave sensors. Sensors 2017, 17, 2160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, B.; Song, G.; Mo, Y. Embedded piezoelectric lead-zirconate-titanate-based dynamic internal normal stress sensor for concrete under impact. J. Intell. Mater. Syst. Struct. 2017, 28, 2659–2674. [Google Scholar] [CrossRef]
- Peng, J.; Hu, S.; Zhang, J.; Cai, C.S.; Li, L. Influence of cracks on chloride diffusivity in concrete: A five-phase mesoscale model approach. Constr. Build. Mater. 2019, 197, 587–596. [Google Scholar] [CrossRef]
- Li, W.; Xu, C.; Ho, S.; Wang, B.; Song, G. Monitoring concrete deterioration due to reinforcement corrosion by integrating acoustic emission and fbg strain measurements. Sensors 2017, 17, 657. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Xiao, L.; Zhang, J.; Cai, C.S.; Wang, L. Flexural behavior of corroded HPS beams. Eng. Struct. 2019, 195, 274–287. [Google Scholar] [CrossRef]
- Kong, Q.; Wang, R.; Song, G.; Yang, Z.J.; Still, B. Monitoring the soil freeze-thaw process using piezoceramic-based smart aggregate. J. Cold Reg. Eng. 2014, 28, 06014001. [Google Scholar] [CrossRef]
- Wang, Y.; Tan, Y.; Guo, M.; Wang, X. Influence of Emulsified Asphalt on the Mechanical Property and Microstructure of Cement-Stabilized Gravel under Freezing and Thawing Cycle Conditions. Materials 2017, 10, 504. [Google Scholar] [CrossRef] [Green Version]
- Mao, X.; Wang, J.; Yuan, C.; Yu, W.; Gan, J. A Dynamic Traffic Assignment Model for the Sustainability of Pavement Performance. Sustainability 2018, 11, 170. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Huang, R.; Xie, Z.; Ma, J.; Lv, W. KID model-driven things-edge-cloud computing paradigm for traffic data as a service. IEEE Netw. 2018, 32, 34–41. [Google Scholar] [CrossRef]
- García, F.; García, J.; Ponz, A.; de la Escalera, A.; Armingol, J.M. Context aided pedestrian detection for danger estimation based on laser scanner and computer vision. Expert Syst. Appl. 2014, 41, 6646–6661. [Google Scholar] [CrossRef] [Green Version]
- García, F.; Jiménez, F.; Anaya, J.; Armingol, J.; Naranjo, J.; de la Escalera, A. Distributed pedestrian detection alerts based on data fusion with accurate localization. Sensors 2013, 13, 11687–11708. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | File Type | Format Type | Feature Type | Description |
|---|---|---|---|---|
| Road | Input | Shapefile | Line | The feature file of road centerlines |
| Crash | Input | Shapefile | Point | The feature file of crashes |
| Boundary | Input | Shapefile | Region | The Boundary of study Area |
| Traffic Database | Intermediate | PostGreSQL Database | Line/Point/Region | The spatial database converted from input shapefiles |
| SWMR file | Output | GWT File | / | ASCII encoded SWM File of road |
| Road clusters and outliers | Output | Shapefile | Line | The result of cluster and outlier analysis |
| First Row: ID (Unique Identifier Field) | |||||||
|---|---|---|---|---|---|---|---|
| Row No. | IDSi | IDSj | Wij | Row No. | IDSi | IDSj | Wij |
| 1 | 23970 | 2125 | 1 | 2 | 23970 | 17352 | 1 |
| 3 | 24103 | 3951 | 1 | 4 | 24103 | 23512 | 1 |
| 5 | 24103 | 23817 | 1 | 6 | 24103 | 27191 | 1 |
| 7 | 3833 | 2125 | 1 | 8 | 3833 | 26956 | 1 |
| 9 | 3950 | 23817 | 1 | 10 | 3950 | 26957 | 1 |
| Input Parameter | Input Value |
|---|---|
| Input Feature Class | road_polk |
| Input Field | crash_count |
| Output Feature Class | c:\data\myproject.gdb\road_clustersoutliers |
| Conceptualization of Spatial Relationships | get_spatial_weights_from_file |
| Standardization | none |
| Distance Band or Threshold Distance | none |
| Weights Matrix File | c:\data\swmr.gwt |
| Apply False Discovery Rate Correction | no_fdr |
| Id | Fclass | Name | Ref | Crash_Count | Local Moran I | z-Score | p-Value | Cotype |
|---|---|---|---|---|---|---|---|---|
| 24305 | motorway | I 35 | 492 | 209.13 | 94.51 | 0.00 | HH | |
| 17387 | motorway | I 235 | 343 | 141.99 | 54.23 | 0.00 | HH | |
| 24483 | secondary | Fleur Drive | 295 | 422.79 | 70.28 | 0.00 | HH | |
| 26939 | motorway | I 235 | 290 | 8.57 | 3.06 | 0.00 | HH | |
| 26629 | motorway | I 80; I 35 | 267 | 10.70 | 4.41 | 0.00 | HH | |
| 27435 | motorway | I 80; US 6 | 262 | 141.85 | 58.53 | 0.00 | HH | |
| 26612 | primary | South Ankeny Boulevard | US 69 | 252 | 242.99 | 59.57 | 0.00 | HH |
| 26533 | motorway | I 80; I 35 | 250 | 141.82 | 82.74 | 0.00 | HH | |
| 26381 | primary | Douglas Avenue | US 6 | 246 | 751.06 | 90.18 | 0.00 | HH |
| 24779 | secondary | University Avenue | 241 | 1570.78 | 229.30 | 0.00 | HH | |
| 26953 | motorway | I 35 | 230 | 130.27 | 49.76 | 0.00 | HH | |
| 26621 | motorway | I 235 | 209 | 107.74 | 62.86 | 0.00 | HH | |
| 26230 | primary | Southeast 14th Street | US 69 | 200 | 455.77 | 88.67 | 0.00 | HH |
| 26884 | motorway | I 80 | 199 | 91.34 | 46.15 | 0.00 | HH | |
| 27436 | tertiary | Ingersoll Avenue | 199 | 39.29 | 4.36 | 0.00 | HH | |
| 26954 | motorway | I 35 | 198 | 39.23 | 14.99 | 0.00 | HH | |
| 24841 | motorway | I 35; I 80 | 193 | 7.77 | 3.93 | 0.00 | HH | |
| 24971 | motorway | I 80; I 35 | 188 | 160.12 | 72.36 | 0.00 | HH | |
| 24800 | primary | Southeast 14th Street | US 69 | 181 | 438.95 | 87.03 | 0.00 | HH |
| 24845 | motorway | I 80 | 180 | 14.64 | 10.46 | 0.00 | HH | |
| 26781 | secondary | University Avenue | 179 | 133.61 | 27.01 | 0.00 | HH | |
| 24918 | primary | Southeast 14th Street | US 69 | 177 | 132.56 | 50.64 | 0.00 | HH |
| 26558 | motorway | I 80; I 35 | 172 | 7.82 | 4.56 | 0.00 | HH | |
| 24782 | primary | Northeast 14th Street | US 69 | 167 | 78.74 | 18.26 | 0.00 | HH |
| 25995 | secondary | Martin Luther King Jr. Parkway | 161 | 378.83 | 102.33 | 0.00 | HH | |
| 24849 | motorway | I 80; I 35 | 155 | 72.62 | 51.89 | 0.00 | HH |
| Id | Fclass | Name | Crash_Count | Local Moran i | z-Score | p-Value | Cotype |
|---|---|---|---|---|---|---|---|
| 1970 | residential | Willowmere Drive | 0 | −4.91 | −2.48 | 0.01 | LH |
| 23513 | tertiary | Watrous Avenue | 0 | −5.11 | −2.58 | 0.01 | LH |
| 24306 | residential | Wakonda Drive | 0 | −4.89 | −2.02 | 0.04 | LH |
| 2749 | secondary | University Avenue | 0 | −4.60 | −3.28 | 0.00 | LH |
| 15523 | residential | Southwest 16th Street | 0 | −3.86 | −2.25 | 0.02 | LH |
| 1670 | residential | Southlawn Drive | 0 | −4.95 | −2.89 | 0.00 | LH |
| 911 | tertiary | Porter Avenue | 0 | −4.99 | −2.52 | 0.01 | LH |
| 13993 | residential | Northeast 69th Place | 0 | −2.58 | −2.61 | 0.01 | LH |
| 14706 | tertiary | Maury Street | 0 | −4.46 | −2.02 | 0.04 | LH |
| 23514 | secondary | Indianola Avenue | 0 | −8.43 | −3.48 | 0.00 | LH |
| 12238 | residential | Hart Avenue | 0 | −5.87 | −3.42 | 0.00 | LH |
| 10097 | residential | Hackley Avenue | 0 | −4.86 | −2.01 | 0.04 | LH |
| 23676 | tertiary | East Watrous Avenue | 0 | −6.39 | −3.23 | 0.00 | LH |
| 4286 | tertiary | Cowles Drive | 0 | −4.49 | −2.03 | 0.04 | LH |
| 4770 | secondary | Bell Avenue | 0 | −4.63 | −2.09 | 0.04 | LH |
| 8815 | tertiary | Aurora Avenue | 0 | −5.08 | −2.10 | 0.04 | LH |
| 14734 | residential | 41st Street | 0 | −3.98 | −2.32 | 0.02 | LH |
| 1970 | residential | Willowmere Drive | 0 | −4.91 | −2.48 | 0.01 | LH |
| 23513 | tertiary | Watrous Avenue | 0 | −5.11 | −2.58 | 0.01 | LH |
| 24789 | motorway | I 35 | 100 | −3.59 | −2.09 | 0.04 | HL |
| 27604 | secondary | University Avenue | 119 | −19.65 | −4.68 | 0.00 | HL |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Ming, Y.; Song, G. Identify Road Clusters with High-Frequency Crashes Using Spatial Data Mining Approach. Appl. Sci. 2019, 9, 5282. https://doi.org/10.3390/app9245282
Zhang Z, Ming Y, Song G. Identify Road Clusters with High-Frequency Crashes Using Spatial Data Mining Approach. Applied Sciences. 2019; 9(24):5282. https://doi.org/10.3390/app9245282
Chicago/Turabian StyleZhang, Zhonggui, Yi Ming, and Gangbing Song. 2019. "Identify Road Clusters with High-Frequency Crashes Using Spatial Data Mining Approach" Applied Sciences 9, no. 24: 5282. https://doi.org/10.3390/app9245282
APA StyleZhang, Z., Ming, Y., & Song, G. (2019). Identify Road Clusters with High-Frequency Crashes Using Spatial Data Mining Approach. Applied Sciences, 9(24), 5282. https://doi.org/10.3390/app9245282