Author Contributions
Data curation, K.Ř.; Formal analysis, M.K.D.; Methodology, M.K., R.B., V.U. and M.K.D.; Software, M.K. and V.U.; Supervision, R.B.; Visualization, K.Ř.; Writing—original draft, M.K.
Figure 1.
Example of MRI sagittal brain scan slice (left) and CT transversal thoracic scan slice (right)—tissue segmented with our system is highlighted in yellow.
Figure 1.
Example of MRI sagittal brain scan slice (left) and CT transversal thoracic scan slice (right)—tissue segmented with our system is highlighted in yellow.
Figure 2.
Example of brain dataset sagittal image slice (left) and according ground truth mask (right).
Figure 2.
Example of brain dataset sagittal image slice (left) and according ground truth mask (right).
Figure 3.
Example transversal image slice from spine dataset (left) with according ground truth mask (right).
Figure 3.
Example transversal image slice from spine dataset (left) with according ground truth mask (right).
Figure 4.
Example of data before adding linear noise (left), with added linear noise (middle) and after denoising by neural network (right).
Figure 4.
Example of data before adding linear noise (left), with added linear noise (middle) and after denoising by neural network (right).
Figure 5.
Example of training (upper) and testing data batch overlapping (lower) for brain dataset. Numbers show which slices of the scan each batch contains.
Figure 5.
Example of training (upper) and testing data batch overlapping (lower) for brain dataset. Numbers show which slices of the scan each batch contains.
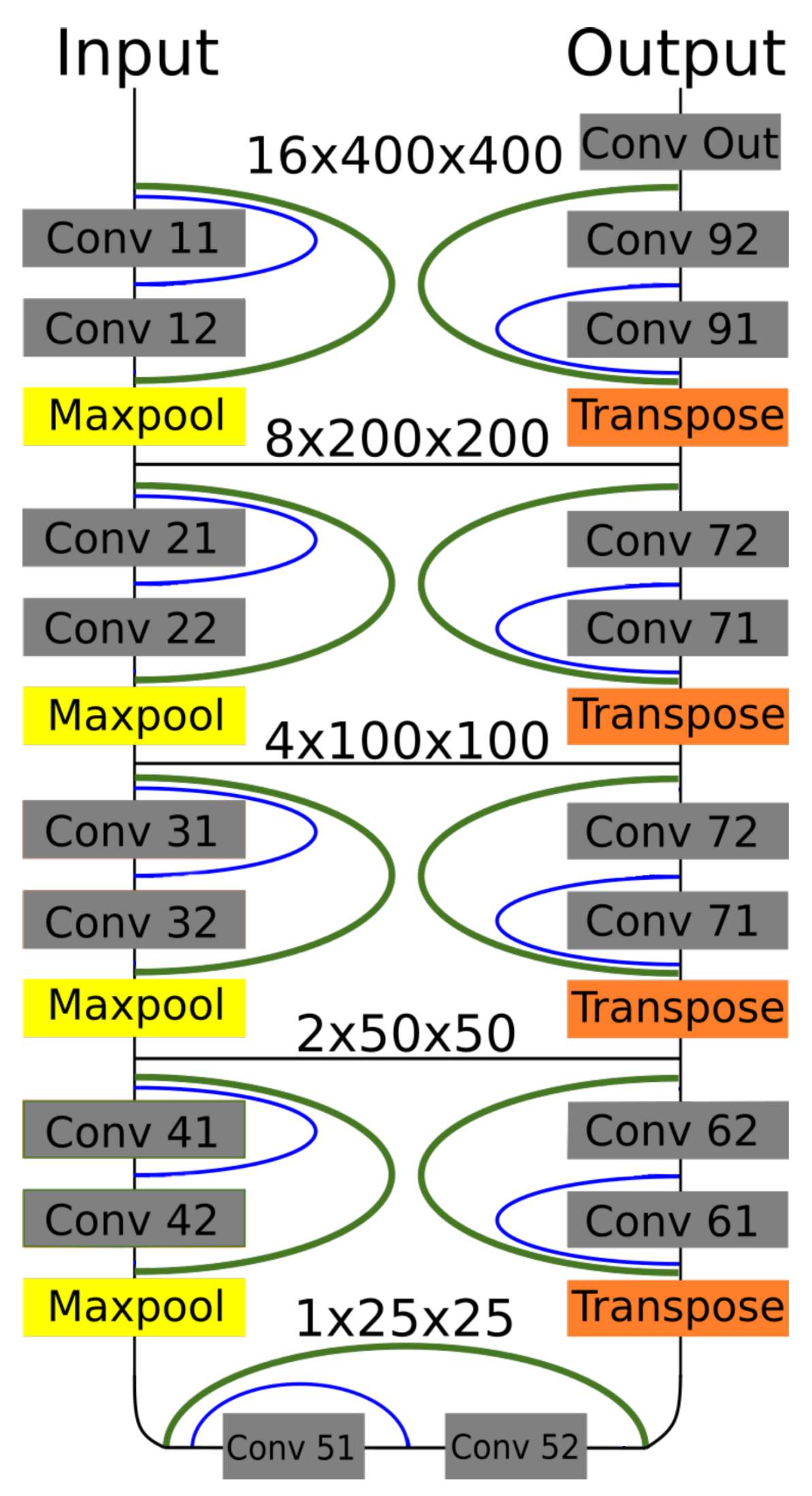
Figure 6.
Dense-U-Net network model. Residual interconnections are in green color, dense interconnections in blue. Feature sizes are valid for batches of images from brain dataset.
Figure 6.
Dense-U-Net network model. Residual interconnections are in green color, dense interconnections in blue. Feature sizes are valid for batches of images from brain dataset.
Figure 7.
Visualisation of predictions from 3D benchmark brain models and FSL segmentation. From left to right—Dense-U-Net, Residual-U-Net, U-Net, FSL.
Figure 7.
Visualisation of predictions from 3D benchmark brain models and FSL segmentation. From left to right—Dense-U-Net, Residual-U-Net, U-Net, FSL.
Figure 8.
Comparison of ground truth brain model (left) and brain model segmented by Dense-U-Net (right) after the final phase of training.
Figure 8.
Comparison of ground truth brain model (left) and brain model segmented by Dense-U-Net (right) after the final phase of training.
Figure 9.
Visualisation of segmented spine models from the benchmark training phase. From left to right—Dense-U-Net, Residual-U-Net, U-Net. Please notice that the abnormal vertebrae adhesions exist also in original ground truth masks as can be seen in
Figure 10.
Figure 9.
Visualisation of segmented spine models from the benchmark training phase. From left to right—Dense-U-Net, Residual-U-Net, U-Net. Please notice that the abnormal vertebrae adhesions exist also in original ground truth masks as can be seen in
Figure 10.
Figure 10.
Comparison of ground truth model (left) and model segmented by Dense-U-Net network (right) after the fine-tuning phase of training. Notice difference on top of the figure—the first cervical vertebra and abnormal vertebrae adhesions that exist also in the original ground truth mask.
Figure 10.
Comparison of ground truth model (left) and model segmented by Dense-U-Net network (right) after the fine-tuning phase of training. Notice difference on top of the figure—the first cervical vertebra and abnormal vertebrae adhesions that exist also in the original ground truth mask.
Table 1.
Number of neurons in each layers.
Table 1.
Number of neurons in each layers.
| Input | Output |
|---|
| Layers | Neurons | Layers | Neurons |
|---|
| 11,12 | 32 | 91,92 | 32 |
| 21,22 | 64 | 81,82 | 64 |
| 31,32 | 128 | 71,72 | 128 |
| 41,42 | 256 | 61,62 | 256 |
| 51,52 | 512 | 51,52 | 512 |
| Bridge block—Convolutions 51,52—512 |
Table 2.
Parameters of network layers—their convolution kernel size, strides and activation function.
Table 2.
Parameters of network layers—their convolution kernel size, strides and activation function.
| Downsampling Block |
| Type | Kernel (Pool) Size | Strides | Activation |
| Convolution 3D | 3,3,3 | 0,0,0 | Relu |
| Convolution 3D | 3,3,3 | 0,0,0 | Relu |
| Maxpooling 3D | 2(1),2,2 | 2,2,2 | - |
| Upsampling Block Block |
| Type | Kernel (Pool) Size | Strides | Activation |
| Transpose Conv.3D | 2,2,2 | 2(1),2,2 | - |
| Convolution 3D | 3,3,3 | 0,0,0 | Relu |
| Convolution 3D | 3,3,3 | 0,0,0 | Relu |
| Bridge Block |
| Type | Kernel (Pool) Size | Strides | Activation |
| Convolution 3D | 3,3,3 | 0,0,0 | Relu |
| Convolution 3D | 3,3,3 | 0,0,0 | Relu |
| Output Convolution |
| Type | Kernel (Pool) Size | Strides | Activation |
| Convolution 3D | 1,1,1 | 0,0,0 | Sigmoid |
Table 3.
Segmentation alogorithms comparison based on their computation time when ran on gtx 1080ti GPU.
Table 3.
Segmentation alogorithms comparison based on their computation time when ran on gtx 1080ti GPU.
| Segmentation Algorithm | Prediction Time | Training Time [50 epochs] |
|---|
| U-Net—brain dataset | 8 s | 6 h |
| U-Net—spine dataset. | 23 s | 9 h |
| Res-U-Net—brain dataset | 12 s | 10 h |
| Res-U-Net—spine dataset | 32 s | 16 h |
| Dense-U-Net—brain dataset | 21 s | 12 h |
| Dense-U-Net—spine dataset | 43 s | 21 h |
| FSL—brain dataset | 3 s | - |
Table 4.
Comparison of tested U-Net versions on brain dataset in benchmark training phase versus Human expert and FMRIB’s Automated Segmentation Tool. Used metrics—pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
Table 4.
Comparison of tested U-Net versions on brain dataset in benchmark training phase versus Human expert and FMRIB’s Automated Segmentation Tool. Used metrics—pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
| 3D Networks | |
|---|
| Metric | Dense-U-Net | Res-U-Net | U-Net | Human | FSL |
|---|
| P.A. | 0.99703 | 0.99662 | 0.99619 | 0.99489 | 0.94289 |
| Dice c. | 0.98843 | 0.98686 | 0.98514 | 0.98033 | 0.79698 |
| I.o.U. | 0.97713 | 0.97407 | 0.97072 | 0.96141 | 0.66248 |
| A.H.D. [voxel] | 0.01334 | 0.01911 | 0.02427 | 0.02479 | 4.58848 |
| A.u.R.C. | 0.99439 | 0.99353 | 0.99205 | 0.98325 | 0.96696 |
| 2D Networks | |
| Metric | Dense-U-Net | Res-U-Net | U-Net | Human | FSL |
| P.A. | 0.99576 | 0.99639 | 0.99636 | 0.99489 | 0.94289 |
| Dice c. | 0.98344 | 0.98357 | 0.98574 | 0.98033 | 0.79698 |
| I.o.U. | 0.96743 | 0.96768 | 0.97189 | 0.96141 | 0.66248 |
| A.H.D. [voxel] | 0.09477 | 0.09130 | 0.05632 | 0.02479 | 4.58848 |
| A.u.R.C. | 0.99647 | 0.99639 | 0.99663 | 0.98325 | 0.96696 |
Table 5.
Fine-tuned model trained using 3-folds cross-validation, results includes standard deviation. Used neural network is Dense-U-Net network. Achieved results are compared to another human expert results. For evaluation, several metrics were used: pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
Table 5.
Fine-tuned model trained using 3-folds cross-validation, results includes standard deviation. Used neural network is Dense-U-Net network. Achieved results are compared to another human expert results. For evaluation, several metrics were used: pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
| Metric | Dense-U-Net | Human |
|---|
| P.A. | | |
| Dice c. | | |
| I.o.U. | | |
| A.H.D. [voxel] | | |
| A.u.R.C. | | |
Table 6.
Comparison of tested 3D U-Net versions on spine dataset in benchmark training phase. The training was limited by 50 epochs for each. Used metrics for evaluation are: pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
Table 6.
Comparison of tested 3D U-Net versions on spine dataset in benchmark training phase. The training was limited by 50 epochs for each. Used metrics for evaluation are: pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
| Metric | Dense-U-Net | Res-U-Net | U-Net |
|---|
| P.A. | 0.99732 | 0.99727 | 0.99721 |
| Dice c. | 0.96784 | 0.96733 | 0.96635 |
| I.o.U. | 0.93770 | 0.93672 | 0.93490 |
| A.H.D. [voxel] | 0.21982 | 0.08754 | 0.09226 |
| A.u.R.C. | 0.98589 | 0.98539 | 0.98262 |
Table 7.
Segmentation results using Dense-U-Net and spine dataset in the fine-tuning phase. Results includes standard deviation of 3-folds cross-validation. Used metrics are: pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
Table 7.
Segmentation results using Dense-U-Net and spine dataset in the fine-tuning phase. Results includes standard deviation of 3-folds cross-validation. Used metrics are: pixel accuracy, Dice coefficient, intersection over union, average Hausdorff distance [voxel] and area under ROC curve.
| Metric | Dense-U-Net |
|---|
| P.A. | |
| Dice c. | |
| I.o.U. | |
| A.H.D. | |
| A.u.R.C. | |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}