Bio-Inspired Structure and Behavior of Self-Recovery Quadruped Robot with a Limited Number of Functional Legs


Abstract
:1. Introduction
2. Development of Quadruped Robots
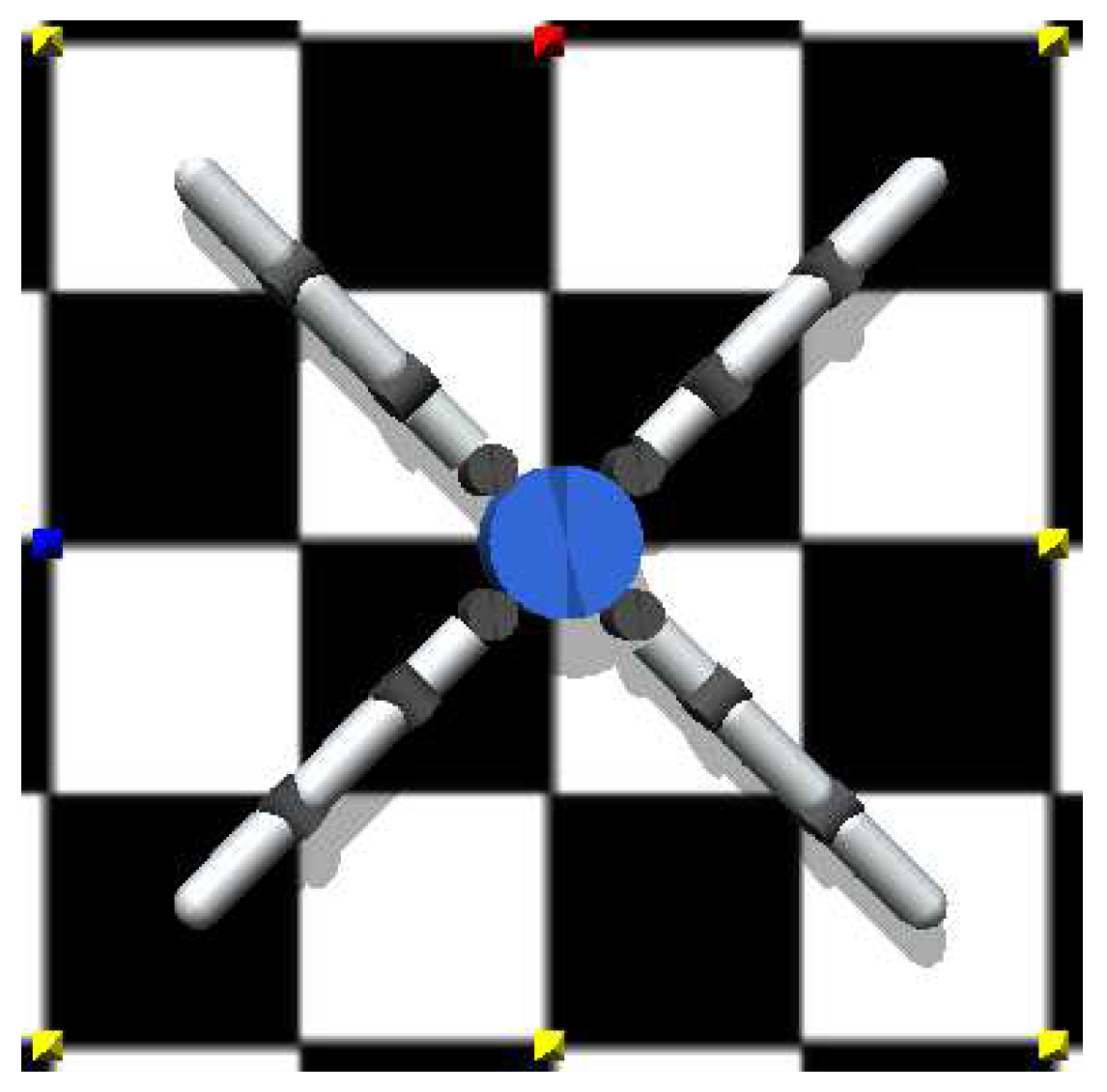
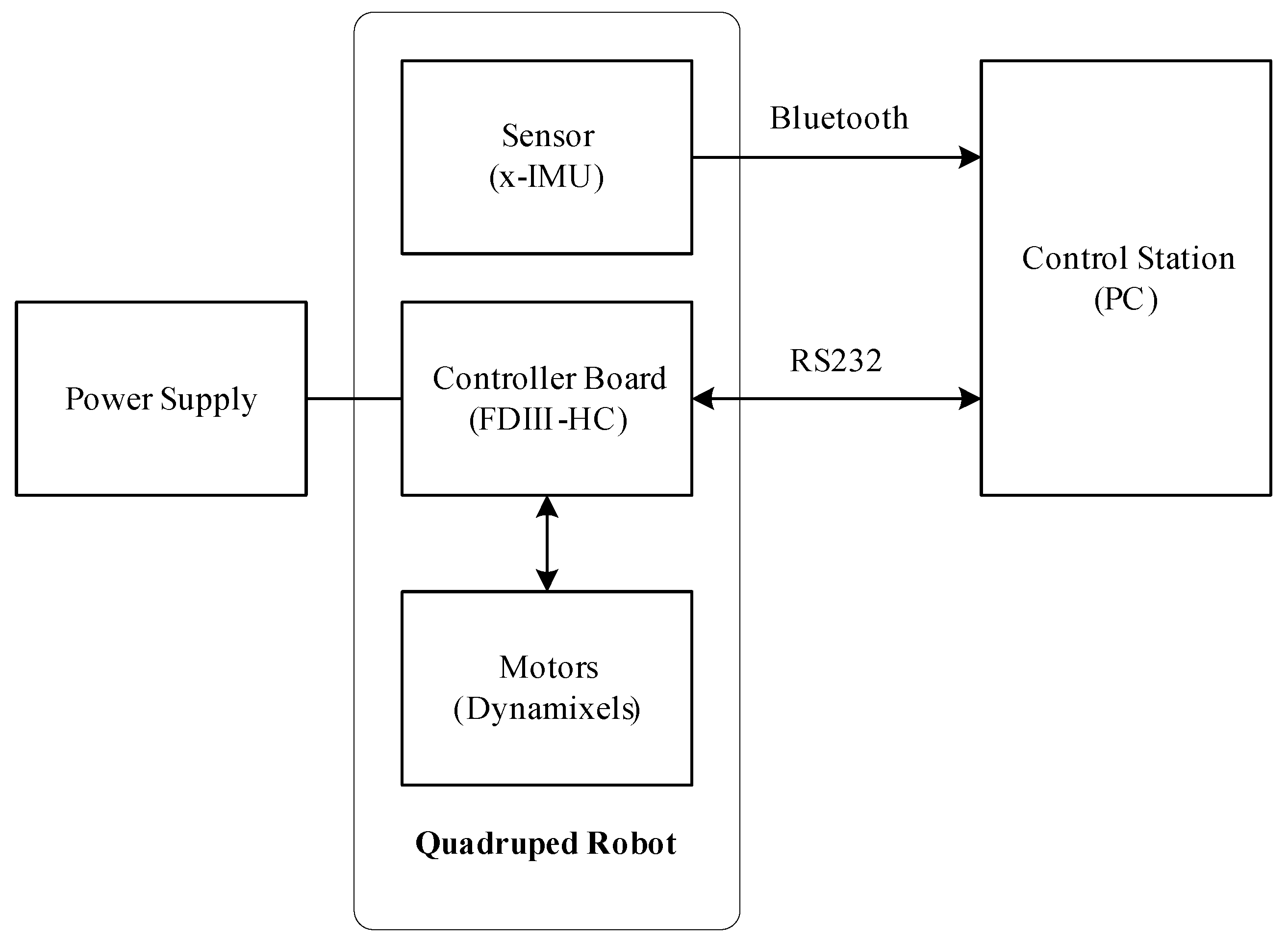
2.1. System Description and Robot Model
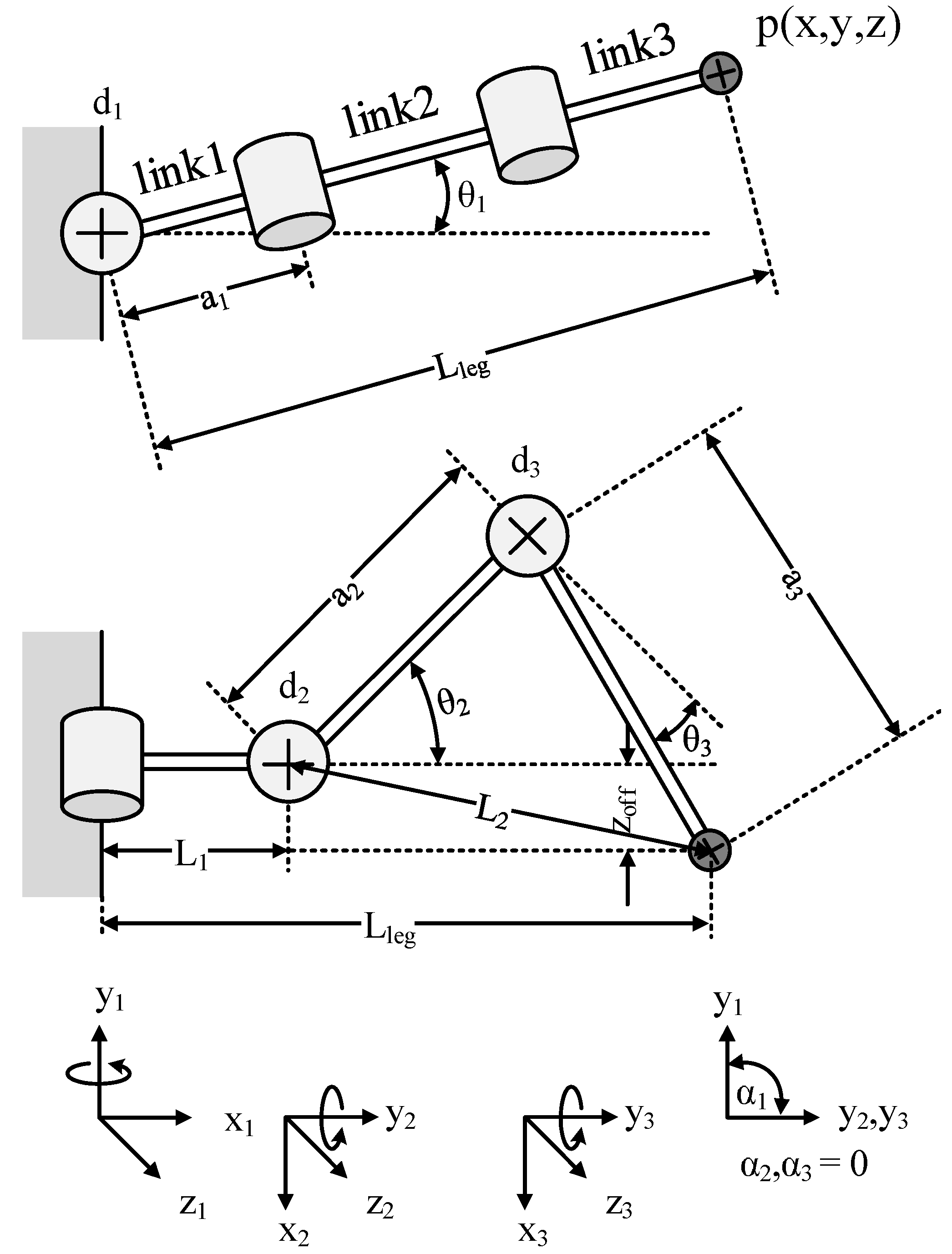
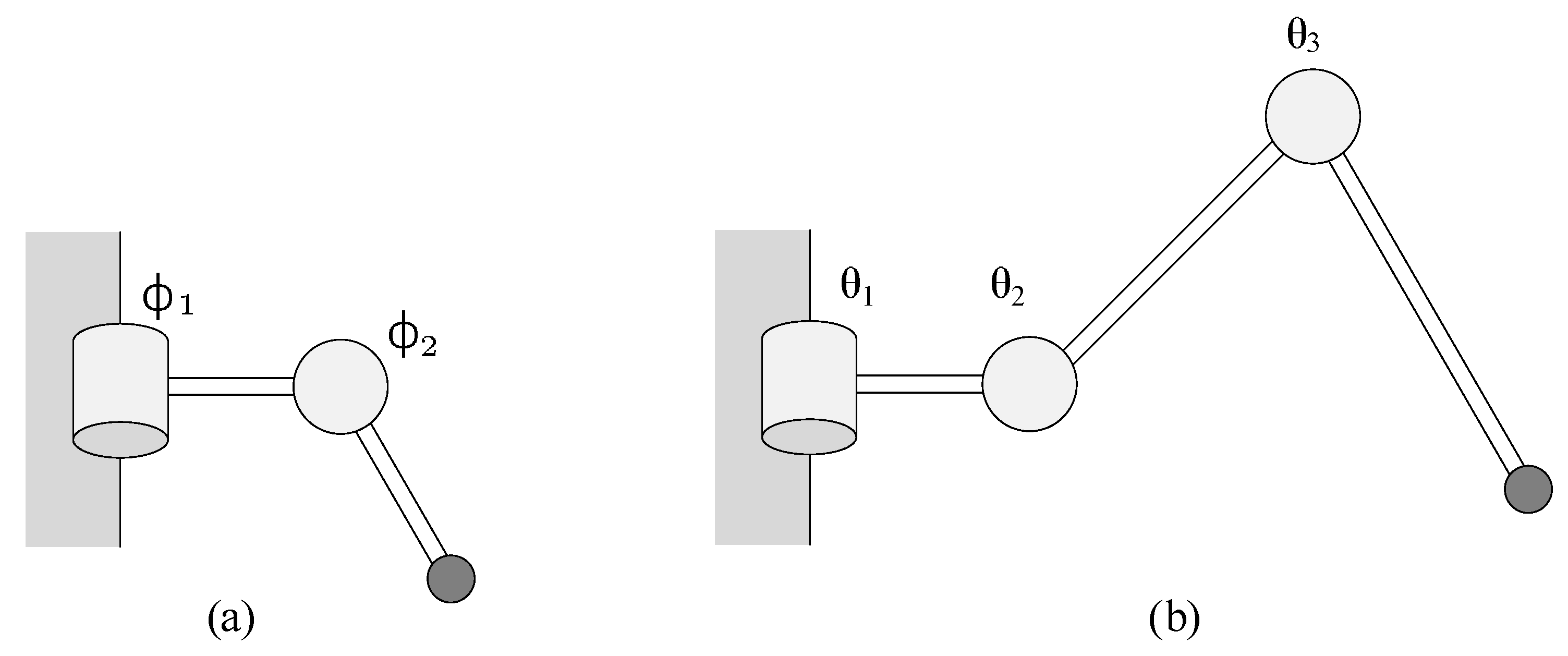
2.1.1. Forward Kinematics of Robot Legs
- (joint displacement):length between the two joints.
- (joint angle): angle measured between the orthogonal of the common normals. This parameter is variable for revolute joint while the other parameters remain constant.
- (link length): mathematical link length (distance between common normals).
- (link twist): angle measured between the orthogonal of the joint axes. For a prismatic joint, the other parameters are fixed, but this parameter is variable.
2.1.2. Inverse Kinematics of Robot Legs
2.1.3. Robot Components
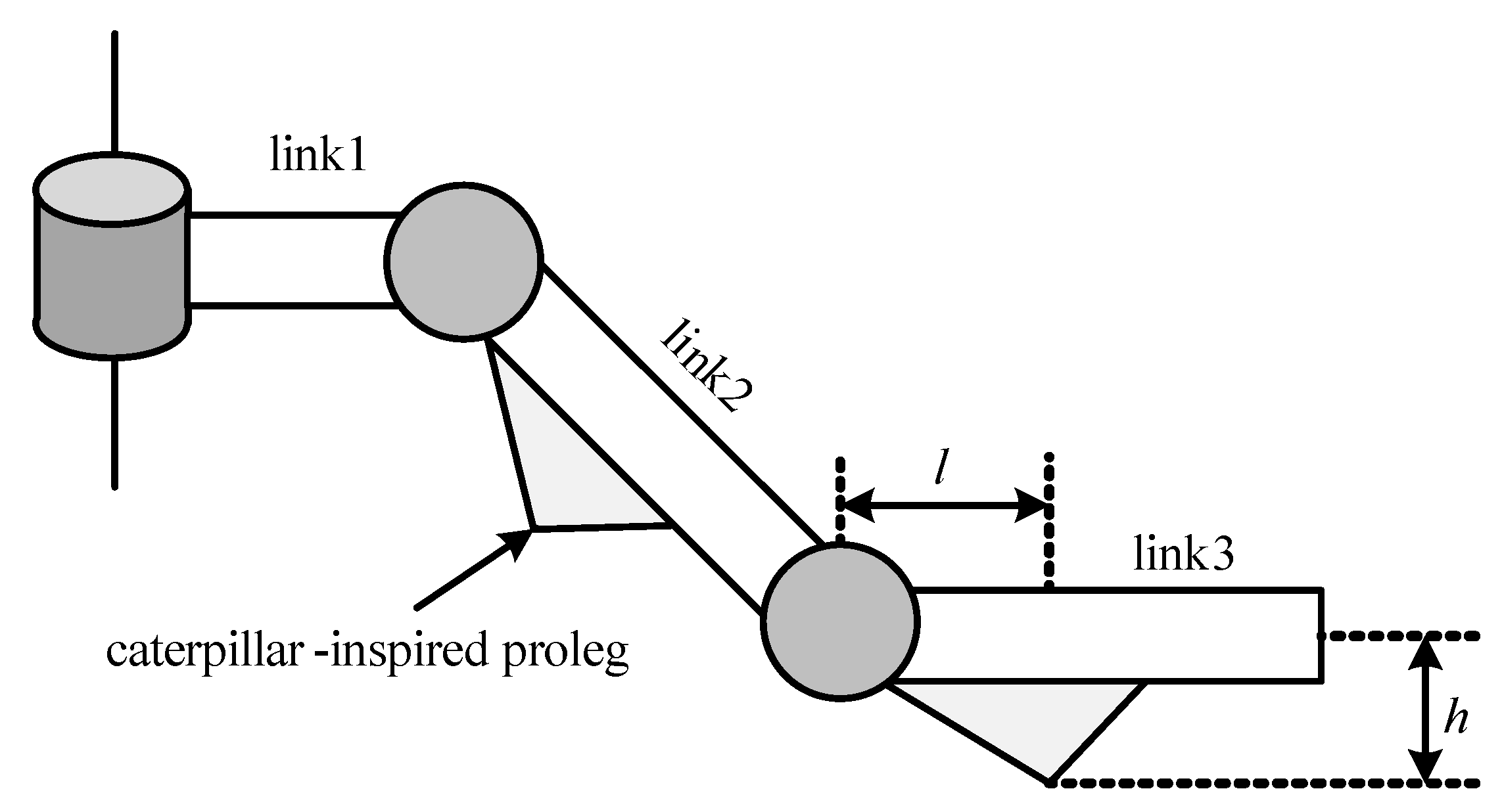
2.2. Caterpillar-Inspired Structure
2.3. Optimization of Robot Structure
3. Self-Recovery Method
3.1. Conventional Self-Recovery Method
3.1.1. Movement Sequence Coding
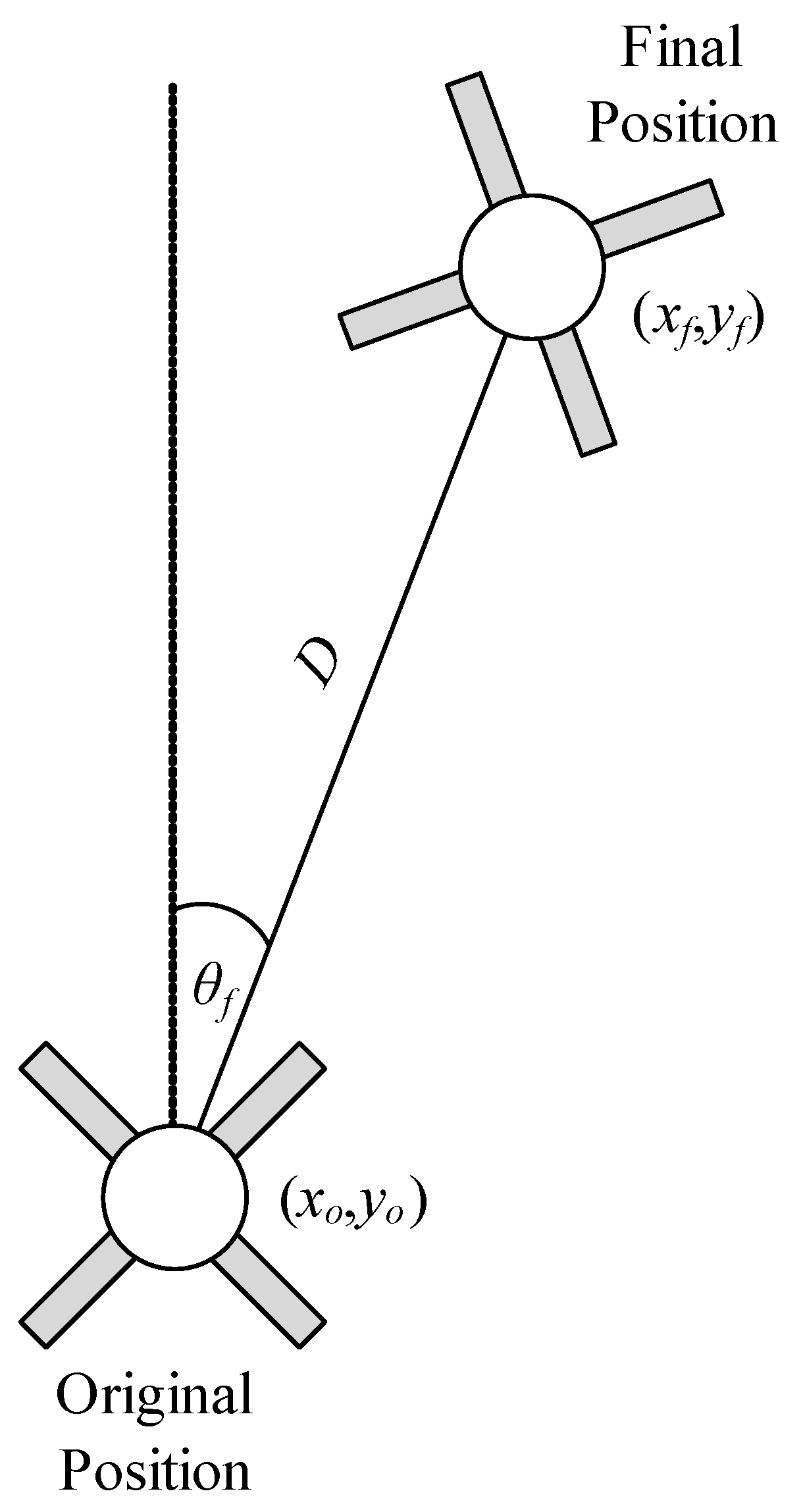
3.1.2. Objective Function
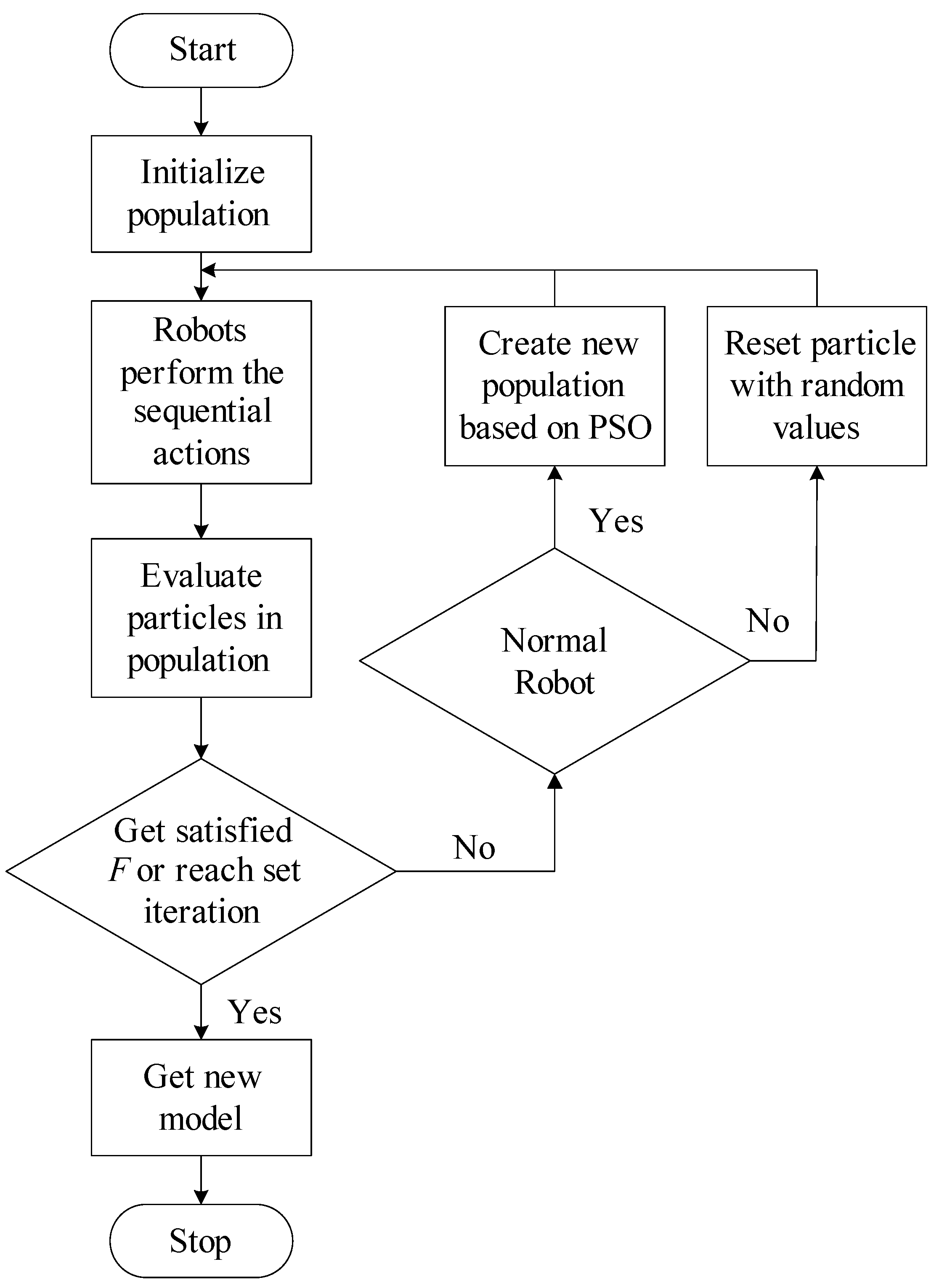
3.1.3. Evolutionary Process
- Normal: If a particle is allocated to this state, the action parameter will be updated according to the PSO rule.
- Capsizing: In practice, the robot attitude should be considered because sensors and loads, e.g., camera, are generally integrated on top of the robot. If the robot flips over during recovery, the sensor or loads may break. Therefore, the particles that cause the robot to flip over should reset all of their parameters randomly.
- Moving Backward: If the particles cause the robot to move backwards, their parameters should be set as random values, likewise.
- Mutant: Given the probability , a few particles should be mutated to avoid the local maximum.
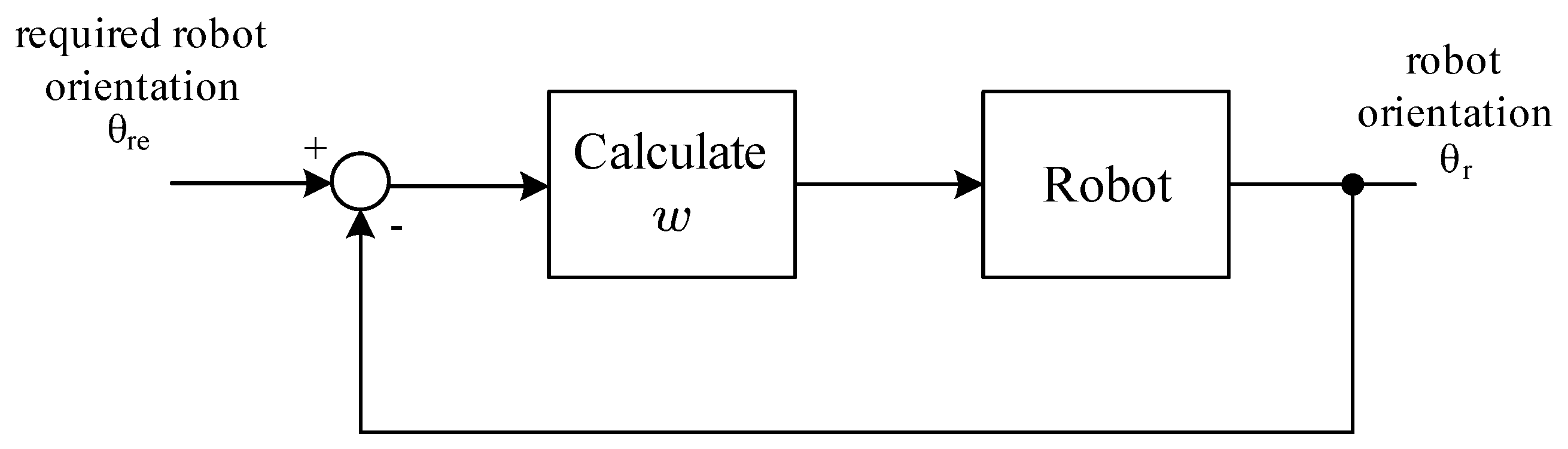
3.2. Mudskipper-Inspired Behavior
Mudskipper Behavior
3.3. Self-Learning Mudskipper-Inspired Crawling Algorithm (SLMIC)
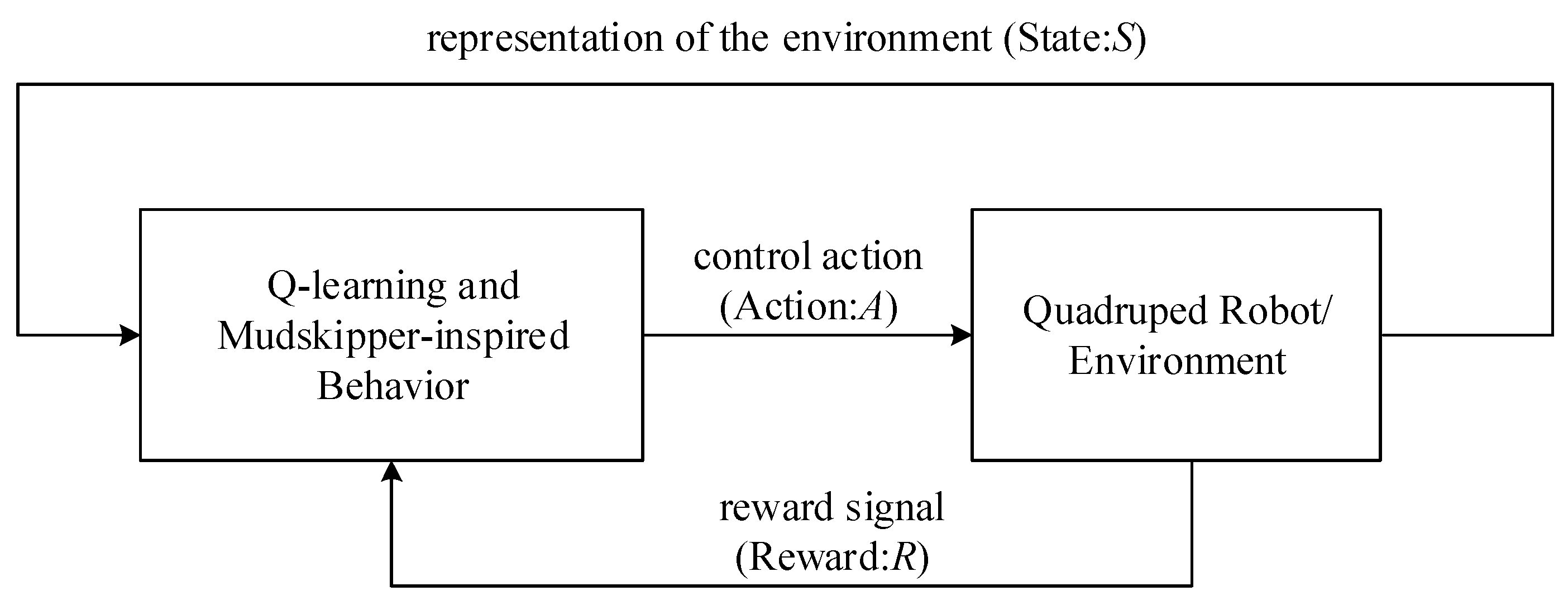
3.3.1. Q-Learning Algorithm
- State (S): It is defined as the current scenario of a system, for instance, the position of the robot.
- Action (A): In one system, several actions would be required to be conducted in each state. In wheel-based robots, the actions can be moving forward, turning left, and turning right.
- Reward (R): It depends on the current state and action. It can be positive, negative, or zero for the win, lose, and draw scenarios, respectively. For example, when a robot encounters an obstacle, it needs to avoid the obstacle. If the robot decides to move forward and hit an obstacle, it will get a negative outcome in the form of a punishment. On the contrary, if the robot avoids an obstacle properly, it will receive a positive reward.
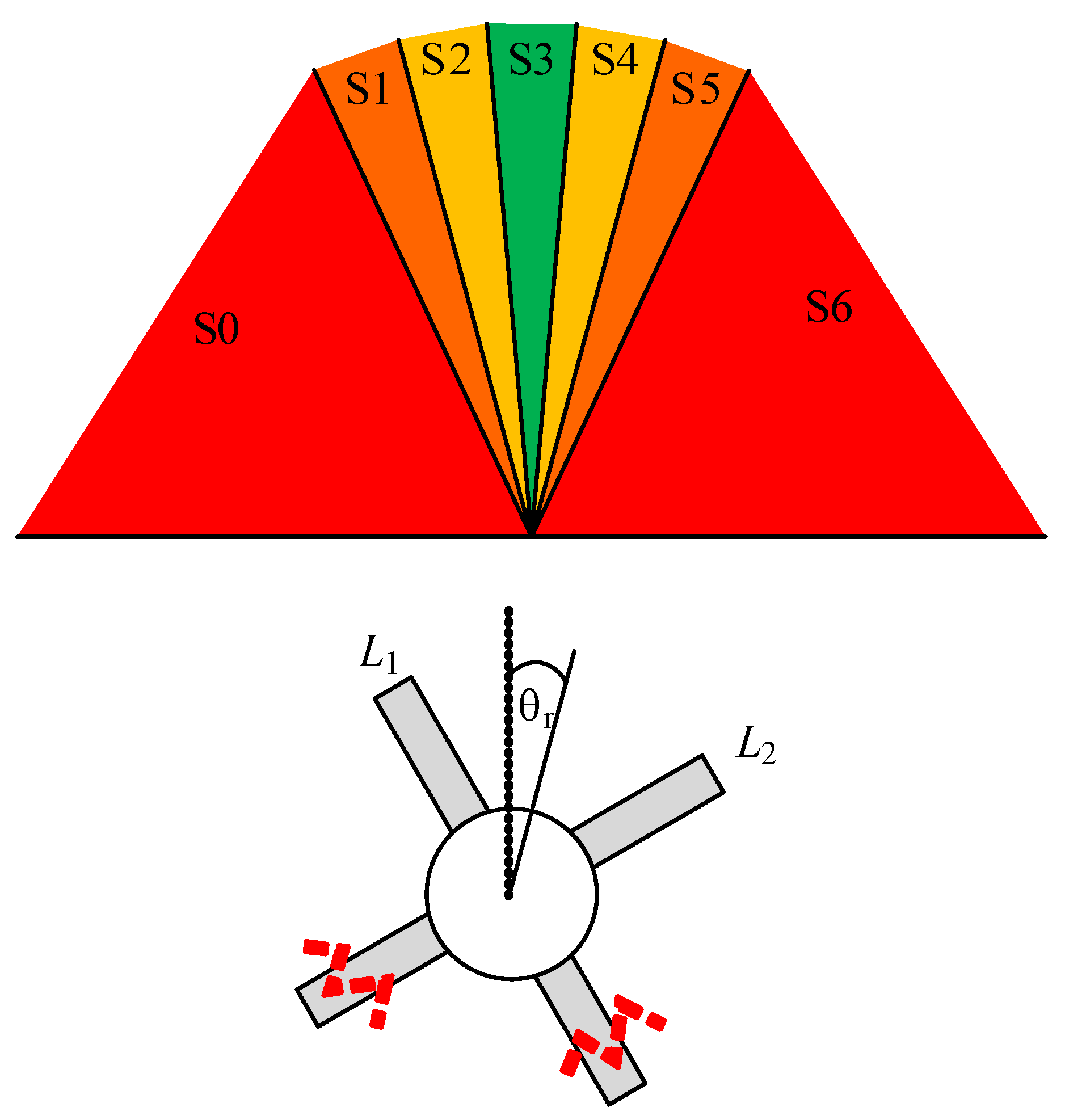
3.3.2. State
3.3.3. Action
3.3.4. Reward
4. Results and Discussion
4.1. Results of Caterpillar-Inspired Quadruped Robot (CIQR)
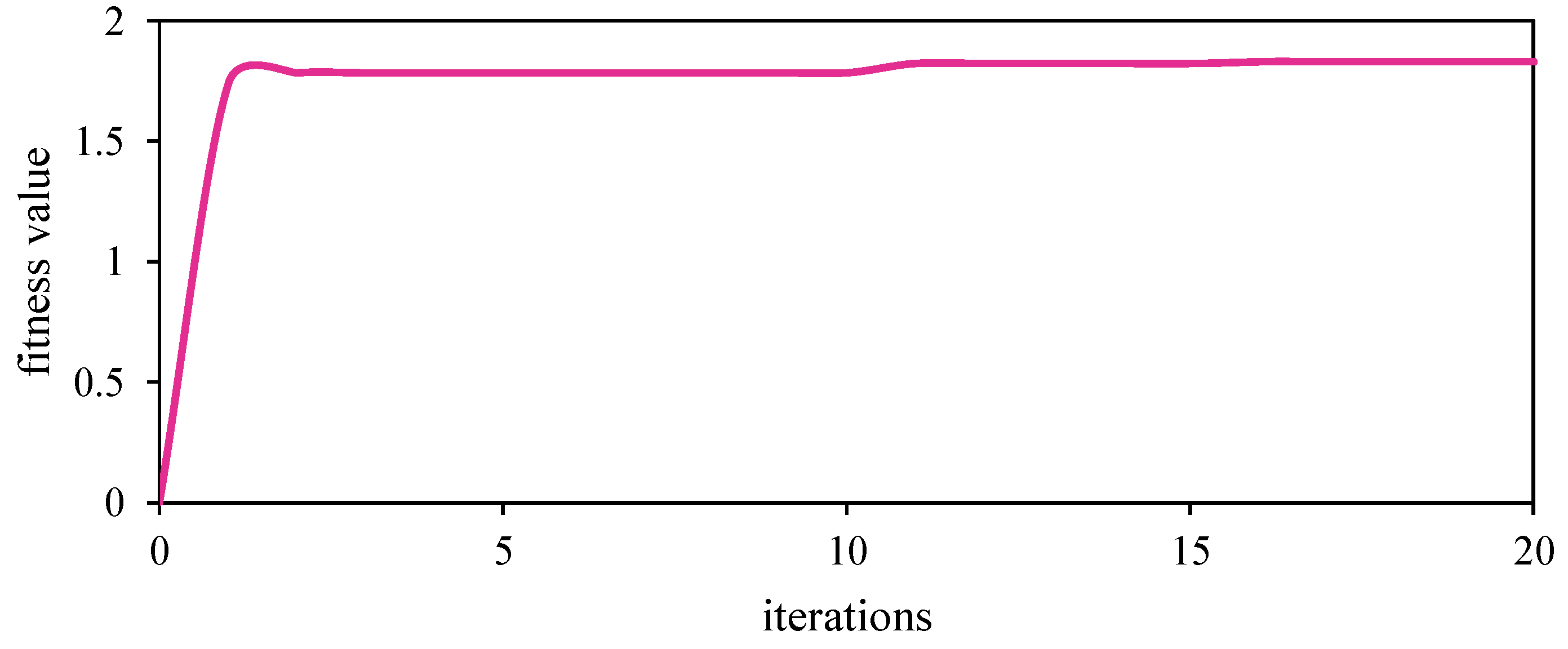
4.1.1. Optimization of Robotic Structure
4.1.2. Simulation Experiments of CIQR with Conventional Recovery Methods
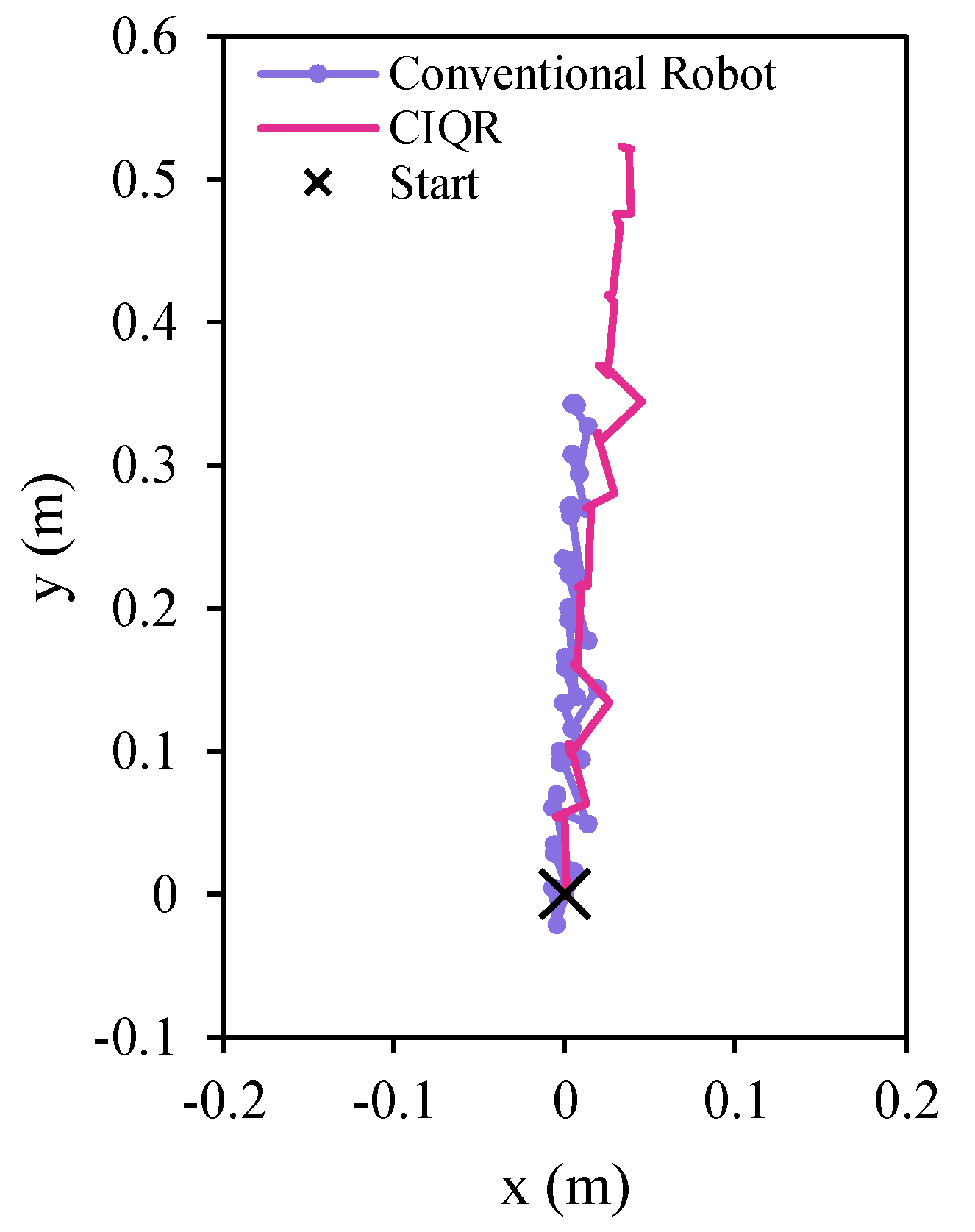
4.1.3. Experimental Results with Caterpillar-Inspired Crawling Behavior
4.2. Evaluation of Self-Learning Mudskipper-Inspired Crawling Method (SLMIC)
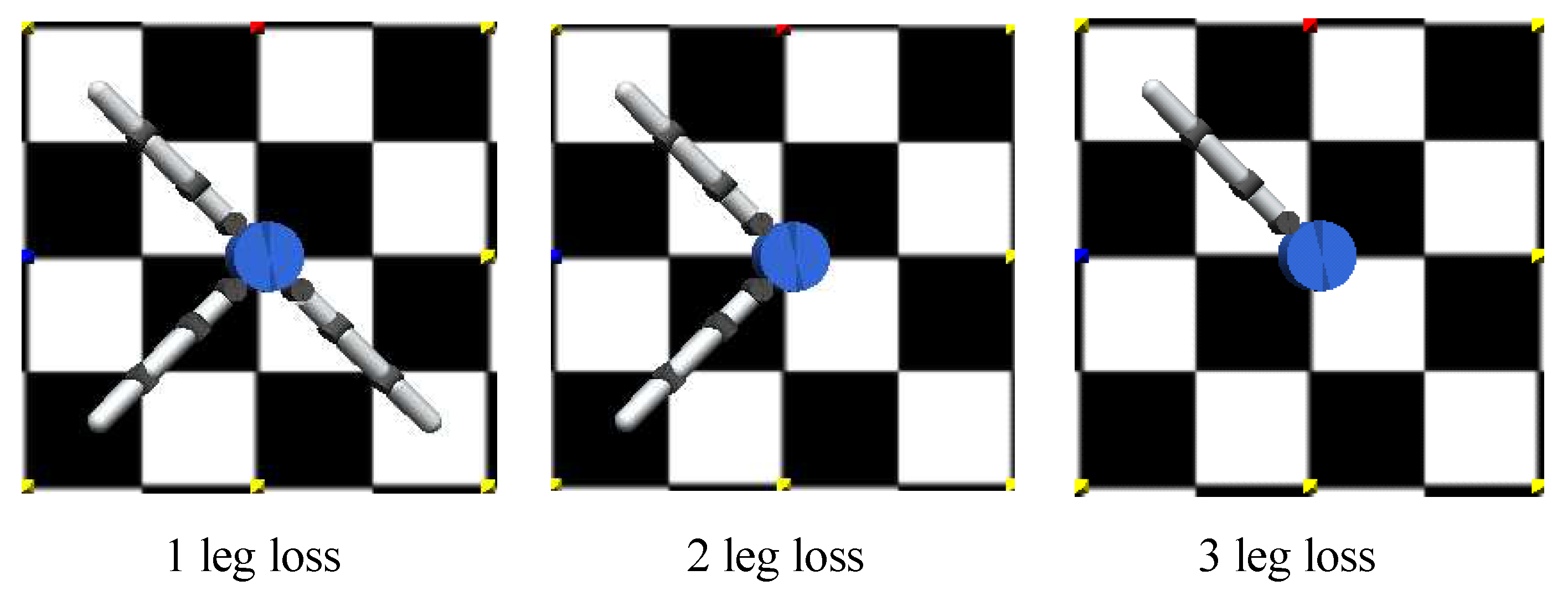
- case A: one leg lost,
- case B: two adjacent legs lost,
- case C: two diagonal legs lost,
- case D: two adjacent legs and one limb lost.
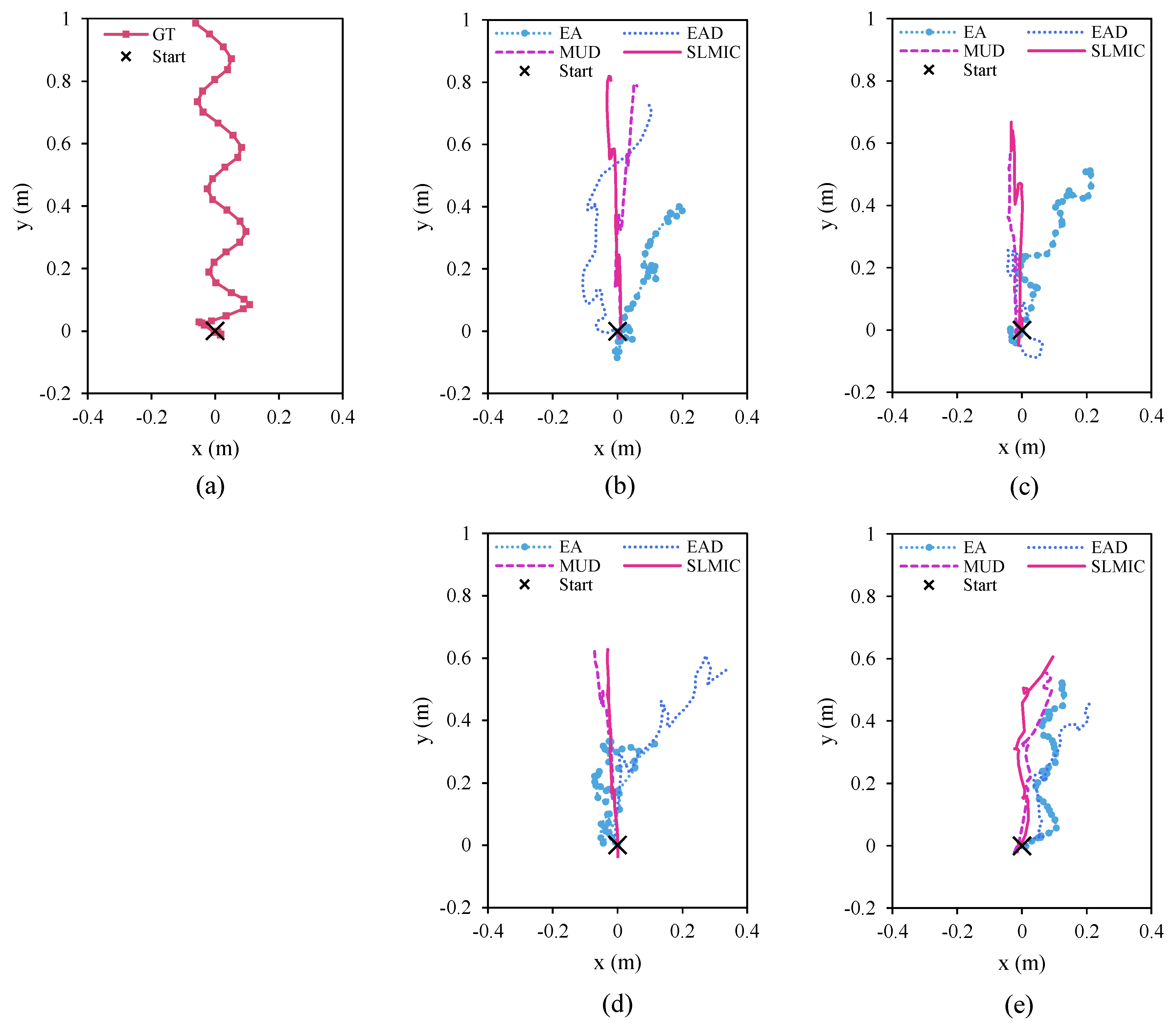
4.2.1. Simulation Results of SLMIC Vis-à-Vis Other Methods
- case A: The results show that all methods used in the simulation allowed the robot to be able to move again. With one leg lost, it was easy for the robot to travel with three functional legs. However, not all methods provided the acceptable results. EA helps the robot move the shortest distance compared with other methods, as shown in Figure 19b. EAD helps the robot move longer than EA but it lost out to the MUD and SLMIC methods. By employing the specific actions of mudskippers, both MUD and SLMIC help the robot travel longer distances. However, SLMIC provided the best result in this test because it helped the robot learn to move forward faster.
- case B: The robot programmed using EA traveled faster than the robot programmed using EAD, as shown in Figure 19c. However, EAD provided the better result in terms of direction. It seemed that, with EAD, the robot optimized multiple objectives, namely, distance traveled and direction of travel. As a result, the robot assigned more importance to direction in optimization, which reduced the distance traveled. MUD and SLMIC provided decent results in terms of distance traveled and direction of travel. Once again, SLMIC provided the best performance.
- case C: Similar to the two cases in the experiments, with MUD and SLMIC, the robot covered longer distances. However, SLMIC performed better in terms of direction of travel. Opposite to case B, EAD could deal with only the distance traveled. At this time, EAD attempted to optimize the distance traveled by the robot, but it failed to optimize the direction of travel, and thus the robot failed to move straight ahead. With EA, the robot could not perform well because the two diagonal legs affected its balance. The robot flipped over during the recovery process which limited its ability to move. As a result, the robot programmed using EA could travel properly, as shown in Figure 19d.
- case D: This experiment was the most challenging because of the limited number of functional legs and actuators, as shown in the results in Figure 19e. Given the extremities, the robot programmed using SLMIC could learn to recovery itself with SLMIC and provided the best results in terms of direction and distance. MUD with its specific control method was the second best performer in this experiment. EAD exhibited the worst performance owning to the same reason as in case B, and EA achieved a fair level of performance.
4.2.2. Comparison of Experimental Results Obtained Using Previous Control Method and SLMIC
- case A: The results of this test case clearly show that with SLMIC the robot could recover itself to reach the goal, as shown in Figure 20b. Compared to the ground truth (in Figure 20a), the robot programmed with SLMIC almost traveled the same distance as the healthy robot. By contrast, the robot could not move well when the previous control method (trotting gait controller) was employed. It caused the robot to move back and fourth around a single point in a certain working area.
- case B: In this case, SLMIC with the damaged robot achieved the same result as the healthy robot. However, the robot moved slightly towards the right part of the working space. By contrast, the robot with two adjacent legs-lost and programmed by the previous method could not perform well, traveling only around the starting point, as shown in Figure 20c.
- case C: As shown in Figure 20d, with the trotting gait, the broken robot could not function properly and moved backwards during the experiment. This can be one of the reasons why the recovery method is significant for multiple-legged robots. By contrast, the proposed method provided good performance with the learning process. According to the trajectory traveled by the robot programmed with the proposed method, it moved towards the right at the beginning, but it returned to the predetermined direction with the passage of time.
- case D: Similar to results of the simulation in the previous section, the robot with two adjacent legs and one limb lost found it difficult to achieve the same performance as the healthy robot. However, SLMIC made a big difference compared to the previous controller. Even so, it could not help the robot recover fully, but it did help the damaged robot cover more than half the distance covered by the healthy robot.
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| DOFs | Degrees of Freedom |
| GA | Genetic Algorithm |
| PSO | Particle Swarm Optimization |
| DH | Denavit–Hartenberg |
| CIQR | Caterpillar-Inspired Quadruped Robot |
| EA | Evolutionary Algorithm |
| EAD | Evolutionary Algorithm with Direction |
| MUD | Mudskipper-Inspired Movement |
| SLMIC | Self-Learning Mudskipper-Inspired Crawling |
| TGC | Trotting Gait Controller |
References
- González-de Santos, P.; Garcia, E.; Estremera, J. Quadrupedal Locomotion: An Introduction to the Control of Four-Legged Robots; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Liu, M.; Li, M.; Pang, J. Fault-tolerant gait implementation of hexapod robot based on finite state automata. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 6800–6805. [Google Scholar]
- Gao, Z.; Ma, L.; Wang, J. Fault tolerant control method for displacement sensor fault of wheel-legged robot based on deep learning. In Proceedings of the 2018 WRC Symposium on Advanced Robotics and Automation (WRC SARA), Beijing, China, 16 August 2018; pp. 147–152. [Google Scholar]
- Dubrova, E. Fault-Tolerant Design; Springer Publishing Company: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Yang, J.M.; Park, Y.K.; Kim, J.G. Fault-Tolerant Gait Planning of Multi-Legged Robots. In Mobile Robotics, Moving Intelligence; Buchli, J., Ed.; IntechOpen: Rijeka, Croatia, 2006; Chapter 28. [Google Scholar] [Green Version]
- Murakami, M. Task-based Dynamic Fault Tolerance for Humanoid Robots. In Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; Volume 3, pp. 2197–2202. [Google Scholar]
- Bongard, J.; Zykov, V.; Lipson, H. Resilient Machines Through Continuous Self-Modeling. Science 2006, 314, 1118–1121. [Google Scholar] [CrossRef] [PubMed]
- Qiu, G.Y.; Wu, S.H. The Evolutionary Locomotion of Tripedal and Quadrupedal Biomorphic Robots. In Proceedings of the 2011 International Conference on Technologies and Applications of Artificial Intelligence, Las Vegas, NV, USA, 18–21 July 2011; pp. 45–50. [Google Scholar]
- Liang, J.; Xue, C. Self identification and control of four-leg robot based on biological evolutionary mechanisms. In Proceedings of the 2010 5th IEEE Conference on Industrial Electronics and Applications, Taichung, Taiwan, 15–17 June 2010; pp. 958–961. [Google Scholar]
- Koos, S.; Cully, A.; Mouret, J.B. Fast damage recovery in robotics with the T-resilience algorithm. Int. J. Robot. Res. 2013, 32, 1700–1723. [Google Scholar] [CrossRef] [Green Version]
- Cully, A.; Clune, J.; Tarapore, D.; Mouret, J.B. Robots that can adapt like animals. Nature 2015, 512, 503–507. [Google Scholar] [CrossRef] [PubMed]
- Ren, G.; Chen, W.; Dasgupta, S.; Kolodziejski, C.; Wörgötter, F.; Manoonpong, P. Multiple chaotic central pattern generators with learning for legged locomotion and malfunction compensation. Inf. Sci. 2015, 294, 666–682. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, W.; Gupta, M.M. Resilient Robots: Concept, Review, and Future Directions. Robotics 2017, 6. [Google Scholar] [CrossRef]
- Geva, Y.; Shapiro, A. A Novel Design of a Quadruped Robot for Research Purposes. Int. J. Adv. Robot. Syst. 2014, 11, 95. [Google Scholar] [CrossRef] [Green Version]
- Atique, M.M.U.; Ahad, M.A.R. Inverse Kinematics solution for a 3DOF robotic structure using Denavit–Hartenberg Convention. In Proceedings of the 2014 International Conference on Informatics, Electronics Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; pp. 1–5. [Google Scholar]
- Spong, M.; Hutchinson, S.; Vidyasagar, M. Robot Modeling and Control; Wiley: New York, NY, USA, 2005. [Google Scholar]
- Trimmer, B.A.; Takesian, A.E.; Sweet, B.M.; Rogers, C.B.; Hake, D.C.; Rogers, D.J. Caterpillar locomotion: A new model for soft- bodied climbing and burrowing robots. In Proceedings of the 7th International Symposium on Technology and the Mine Problem, Monterey, CA, USA, 2–5 May 2006. [Google Scholar]
- Wei, W.; Dawei, X. A new design and analysis of compliant spine mechanism for caterpillar climbing robot. In Proceedings of the 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; pp. 790–795. [Google Scholar]
- Darici, O.; Yalcin, M.K.; Temeltas, H. Comparison of gait generation methods in Quadruped walking. In Proceedings of the 2008 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Xi’an, China, 2–5 July 2008; pp. 1–6. [Google Scholar]
- Zhang, H.; Gonzalez-Gomez, J.; Zhang, J. A new application of modular robots on analysis of caterpillar-like locomotion. In Proceedings of the 2009 IEEE International Conference on Mechatronics, Malaga, Spain, 14–17 April 2009; pp. 1–6. [Google Scholar]
- Wang, L.; Xu, M.; Liu, B.; Jiang, T.; Zhang, S.; Yang, J. Experimental study on morphology and kinematics of mudskipper in amphibious environments. In Proceedings of the 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, China, 12–14 December 2013; pp. 1095–1100. [Google Scholar]
- McInroe, B.; Astley, H.C.; Gong, C.; Kawano, S.M.; Schiebel, P.E.; Rieser, J.M.; Choset, H.; Blob, R.W.; Goldman, D.I. Tail use improves performance on soft substrates in models of early vertebrate land locomotors. Science 2016, 353, 154–158. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Wu, F.; Zhao, J. Simplified online Q-learning for LEGO EV3 robot. In Proceedings of the 2015 IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 28–30 November 2015; pp. 77–80. [Google Scholar]
- Lin, J.L.; Hwang, K.S.; Jiang, W.C.; Chen, Y.J. Gait Balance and Acceleration of a Biped Robot Based on Q-Learning. IEEE Access 2016, 4, 2439–2449. [Google Scholar] [CrossRef]
- Yamaguchi, A.; Takamatsu, J.; Ogasawara, T. DCOB: Action space for reinforcement learning of high DOF robots. Autono. Robot. 2013, 34, 327–346. [Google Scholar] [CrossRef]
- Kohl, N.; Stone, P. Policy gradient reinforcement learning for fast quadrupedal locomotion. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (ICRA ’04), Barcelona, Spain, 26 April–1 May 2004; Volume 3, pp. 2619–2624. [Google Scholar]
- Bellman, R. A Markovian Decision Process. Indiana Univ. Math. J. 1957, 6, 679–684. [Google Scholar] [CrossRef] [Green Version]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall Series in Artifi; Prentice Hall: Englewood Cliffs, NJ, USA, 2010. [Google Scholar]
- Gao, H.; Wang, T.; Liang, J.; Zhou, Y. Model adaptive gait scheme based on evolutionary algorithm. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 316–321. [Google Scholar]
- Guangyou, Y. A Modified Particle Swarm Optimizer Algorithm. In Proceedings of the 2007 8th International Conference on Electronic Measurement and Instruments, Xi’an, China, 16–18 August 2007; pp. 675–679. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Link | ||||
|---|---|---|---|---|
| 1 | 0 | 90 | ||
| 2 | 0 | 0 | ||
| 3 | 0 | 0 |
| Algorithm: Q-learining Algorithm | |
| 1: 2: 3: 4: 5: | observes its current state . selects and perform an action . observes the subsequent state . receives an immediate reward . adjust it value using Equation (20) |
| State | Region | Reward |
|---|---|---|
| S0 S1 S2 S3 S4 S5 S6 | −10 −5 −1 0 −1 −5 −10 |
| Action | (Leg ) | (Leg ) |
|---|---|---|
| A0 A1 A2 A3 A4 A5 A6 | 4 3 2 1 1 1 1 | 1 1 1 1 2 3 4 |
| Iteration | l (cm) | h (cm) |
|---|---|---|
| 0 | 4.50 | 3.50 |
| 5 | 3.67 | 3.38 |
| 10 | 3.67 | 3.38 |
| 15 | 5.41 | 3.46 |
| 20 | 5.47 | 3.33 |
| Number of Legs Lost | Normal Robot (cm) | CIQR (cm) |
|---|---|---|
| 1 | 48.68 | 51.67 |
| 2 | 92.42 | 85.41 |
| 3 | 17.08 | 131.73 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chattunyakit, S.; Kobayashi, Y.; Emaru, T.; Ravankar, A.A. Bio-Inspired Structure and Behavior of Self-Recovery Quadruped Robot with a Limited Number of Functional Legs. Appl. Sci. 2019, 9, 799. https://doi.org/10.3390/app9040799
Chattunyakit S, Kobayashi Y, Emaru T, Ravankar AA. Bio-Inspired Structure and Behavior of Self-Recovery Quadruped Robot with a Limited Number of Functional Legs. Applied Sciences. 2019; 9(4):799. https://doi.org/10.3390/app9040799
Chicago/Turabian StyleChattunyakit, Sarun, Yukinori Kobayashi, Takanori Emaru, and Ankit A. Ravankar. 2019. "Bio-Inspired Structure and Behavior of Self-Recovery Quadruped Robot with a Limited Number of Functional Legs" Applied Sciences 9, no. 4: 799. https://doi.org/10.3390/app9040799
APA StyleChattunyakit, S., Kobayashi, Y., Emaru, T., & Ravankar, A. A. (2019). Bio-Inspired Structure and Behavior of Self-Recovery Quadruped Robot with a Limited Number of Functional Legs. Applied Sciences, 9(4), 799. https://doi.org/10.3390/app9040799