1. Introduction
Emotions are the key to people’s feelings and thoughts. Online social media, such as Twitter and Facebook, have changed the language of communication. Currently, people can communicate facts, opinions, emotions, and emotion intensities on different kinds of topics in short texts. Analyzing the emotions expressed in social media content has attracted researchers in the natural language processing research field. It has a wide range of applications in commerce, public health, social welfare, etc. For instance, it can be used in public health [
1,
2], public opinion detection about political tendencies [
3,
4], brand management [
5], and stock market monitoring [
6]. Emotion analysis is the task of determining the attitude towards a target or topic. The attitude can be the polarity (positive or negative) or an emotional state such as joy, anger, or sadness [
7].
Recently, the multi-label classification problem has attracted considerable interest due to its applicability to a wide range of domains, including text classification, scene and video classification, and bioinformatics [
8]. Unlike the traditional single-label classification problem (i.e., multi-class or binary), where an instance is associated with only one label from a finite set of labels, in the multi-label classification problem, an instance is associated with a subset of labels.
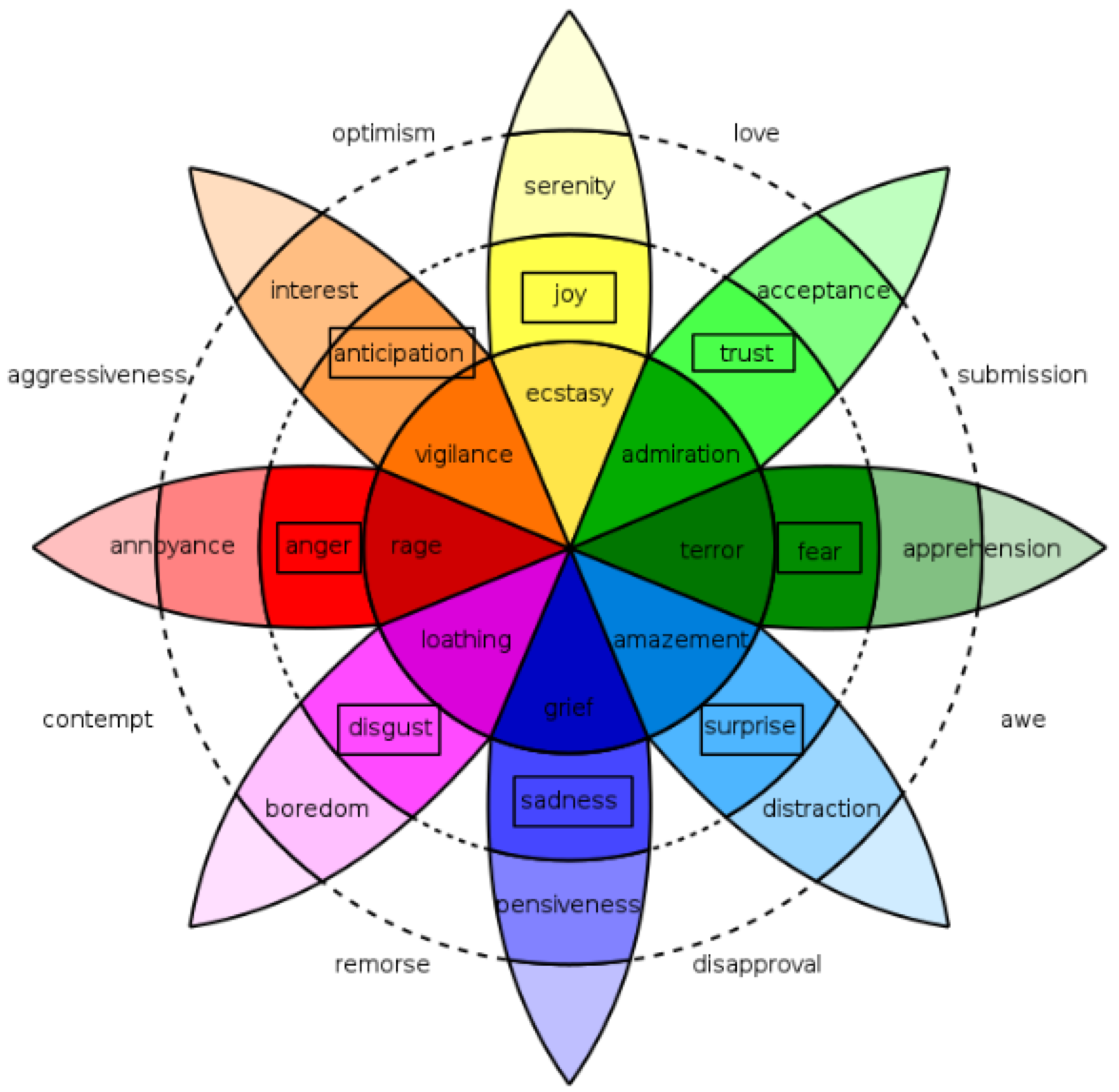
Most previous work on sentiment and emotion analysis has only focused on single-label classification. Hence, in this article, we focus on the multi-label emotion classification task, which aims to develop an automatic system to determine the existence in a text of none, one, or more out of eleven emotions: the eight Plutchik [
9] categories (joy, sadness, anger, fear, trust, disgust, surprise, and anticipation) that are shown in
Figure 1, plus optimism, pessimism, and love.
One of the most common approaches to addressing the problem of multi-label classification is the problem transformation. With this approach, a multi-label problem is transformed into one or more single-label (i.e., binary or multi-class) problems. Specifically, single-label classifiers are learned and employed; after that, the classifiers’ predictions are transformed into multi-label predictions.
Different transformation methods have been proposed in the multi-label literature. The most common method is called
binary relevance [
10,
11]. The idea of the binary relevance method is simple and intuitive. A multi-label problem is transformed into multiple binary problems, one problem for each label. Then, an independent binary classifier is trained to predict the relevance of one of the labels. Although binary relevance is popular in the literature, due to its simplicity, it suffers from directly modeling correlations that may exist between labels. However, it is highly resistant to overfitting label combinations, since it does not expect examples to be associated with previously-observed combinations of labels.
In this article, we propose a novel transformation method, called
-pair-set, for the multi-label classification problem. Unlike binary relevance methods, our method transforms the problem into only one binary classification problem as described in
Section 3. Additionally, we exploit the successes of deep learning models, especially the word2vecmethods’ family [
12] and the recurrent neural networks [
13,
14] and attention models [
15,
16], to develop a system that solves the transformed binary classification problem. The critical component of our system is the embedding module, which uses three embedding models and an attention function to model the relationship between the input and the label.
To summarize, the contribution of this work is four-fold.
We propose a novel transformation mechanism for the multi-label classification problem.
We propose a novel, attentive deep learning system, which we call Binary Neural Network (BNet), which works on the new transformation method. Our system is a data-driven, end-to-end neural-based model, and it does not rely on external resources such as parts of speech taggers and sentiment or emotion lexicons.
We evaluate the proposed system on the challenging multi-label emotion classification dataset of SemEval-2018 Task1: Affect in Tweets.
The experimental results show that our system outperforms the state-of-the-art systems.
The rest of the article is structured as follows. In
Section 2, we overview the related work on multi-label problem transformation methods and Twitter sentiment and emotion analysis. In
Section 3, we explain in detail the methodology. In
Section 4, we report the experimental results. In
Section 5, the conclusions and the future work are presented.
2. Related Works
In this section, we overview the most popular research studies related to this work. In
Section 2.1, we summarize the most common multi-label problem transformation methods.
Section 2.2 gives an overview of the state-of-the-art works on the problem of multi-label emotion classification on Twitter.
2.1. Problem Transformation Methods
Let
be the set of all instances and
be the set of all labels. We can define the set of data:
In this expression, D is called a supervised multi-label dataset.
The task of multi-label classification is challenging because the number of label sets grows exponentially as the number of class labels increases. One common strategy to address this issue is to transform the problem into a traditional classification problem. The idea is to simplify the learning process by exploiting label correlations. Based on the order of the correlations, we can group the existing transformation methods into three approaches [
17,
18], namely first-order approaches, second-order approaches, and high-order approaches.
First-order approaches decompose the problem into some independent binary classification problems. In this case, one binary classifier is learned for each possible class, ignoring the co-existence of other labels. Thus, the number of independent binary classifiers needed is equal to the number of labels. For each multi-label training example
,
, we construct a binary classification training set,
as the following:
will be regarded as one positive example if
and one negative example otherwise. In the first case, we will get a training example in the form
, which will be
in the second case. Thus, for all labels
,
m training sets
are constructed. Based on that, for each training set
, one binary classifier can be learned with popular learning techniques such as AdaBoost [
19], k-nearest neighbor [
20], decision trees, random forests [
21,
22], etc. The main advantage of first-order approaches is their conceptual simplicity and high efficiency. However, these approaches can be less effective due to their ignorance of label correlations.
Second-order approaches try to address the lack of modeling label correlations by exploiting pairwise relationships between the labels. One way to consider pairwise relationships is to train one binary classifier for each
pair of labels [
23]. Although second-order approaches perform well in several domains, they are more complicated than the first-order approaches in terms of the number of classifiers. Their complexity is quadratic, as the number of classifiers needed is
. Moreover, in real-world applications, label correlations could be more complex and go beyond second-order.
High-order approaches tackle the multi-label learning problem by exploring high-order relationships among the labels. This can be fulfilled by assuming linear combinations [
24], a nonlinear mapping [
25,
26], or a shared subspace over the whole label space [
27]. Although high-order approaches have stronger correlation-modeling capabilities than their first-order and second-order counterparts, these approaches are computationally demanding and less scalable.
Our transformation mechanism, shown in
Section 3.1, is a simple as the first-order approaches and can model, implicitly, high-order relationships among the labels if some requirements, detailed in
Section 3.1, are fulfilled. It requires only one binary classifier, and the number of training examples grows polynomially in terms of the number of instances and the number of labels. If the number of training examples in the multi-label training dataset is
n and the number of the labels is
m, then the number of the training examples in the transformed binary training set is
.
2.2. Emotion Classification in Tweets
Various machine learning approaches have been proposed for traditional emotion classification and multi-label emotion classification. Most of the existing systems solve the problem as a text classification problem. Supervised classifiers are trained on a set of annotated corpora using a different set of hand-engineered features. The success of such models is based on two main factors: a large amount of labeled data and the intelligent design of a set of features that can distinguish between the samples. With this approach, most studies have focused on engineering a set of efficient features to obtain a good classification performance [
28,
29,
30]. The idea is to find a set of informative features to reflect the sentiments or the emotions expressed in the text. Bag-of-Words (BoW) and its variation, n-grams, is the representation method used in most text classification problems and emotion analysis. Different studies have combined the BoW features with other features such as the parts of speech tags, the sentiment and the emotion information extracted from lexicons, statistical information, and word shapes to enrich the text representation.
Although BoW is a popular method in most text classification systems, it has some drawbacks. Firstly, it ignores the word order. That means that two documents may have the same or a very close representation as far as they have the same words, even though they carry a different meaning. The n-gram method resolves this disadvantage of BoW by considering the word order in a context of length n. However, it suffers from sparsity and high dimensionality. Secondly, BoW is scarcely able to model the semantics of words. For example, the words beautiful, wonderful and view have an equal distance in BoW, where the word beautiful is closer to the word wonderful than the word view in the semantic space.
Sentiment and emotion lexicons play an essential role in developing efficient sentiment and emotion analysis systems. However, it is difficult to create such lexicons. Moreover, finding the best combination of lexicons in addition to the best set of statistical features is a time-consuming task.
Recently, deep learning models have been utilized to develop end-to-end systems in many tasks including speech recognition, text classification, and image classification. It has been shown that such systems automatically extract high-level features from raw data [
31,
32].
Baziotis et al. [
33], the winner of the multi-label emotion classification task of SemEval-2018 Task1: Affect in Tweets, developed a bidirectional Long Short-Term Memory (LSTM) with a deep attention mechanism. They trained a word2vec model with 800,000 words derived from a dataset of 550 million tweets. The second place winner of the SemEval leaderboard trained a word-level bidirectional LSTM with attention, and it also included non-deep learning features in its ensemble [
34]. Ji Ho Park et al. [
35] trained two models to solve this problem: regularized linear regression and logistic regression classifier chain [
11]. They tried to exploit labels’ correlation to perform multi-label classification. With the first model, the authors formulated the multi-label classification problem as a linear regression with label distance as the regularization term. In their work, the logistic regression classifier chain method was used to capture the correlation of emotion labels. The idea is to treat the multi-label problem as a sequence of binary classification problems by taking the prediction of the previous classifier as an extra input to the next classifier.
In this work, we exploited the deep learning-based approach to develop a system that can extract a high-level representation of the tweets and model an implicit high-order relationship among the labels. We used the proposed system alongside the proposed transformation method to train a function that can solve the problem of multi-label emotion classification in tweets. The next section explains the details of our proposed system.
3. Methodology
This section shows the methodology of this work. First, we explain in
Section 3.1 the proposed transformation method,
-pair-set. Afterwards, we describe the proposed system in
Section 3.2.
3.1. -Pair-Set: Problem Transformation
The proposed transformation method
-pair-set transforms a multi-label classification dataset
D into a supervised binary dataset
as follows:
Algorithm 1 explains the implementation of the proposed transformation method. It takes as inputs a multi-label dataset
D (Equation (
1)) and a set of labels
Y, and it returns a transformed binary dataset. We show next an illustrative example.
| Algorithm 1:-pair-set algorithm. |
![Applsci 09 01123 i001]() |
Let , and . The output of the binary relevance transformation method is a set of three independent binary datasets, one for each label. That is, , , and . In contrast, the output of our transformation method is a single binary dataset .
The task in this case, unlike the traditional supervised binary classification algorithms, is to develop a learning algorithm to learn a function
. The success of such an algorithm is based on three requirements: (1) an encoding method to represent an instance
as a high-dimensional vector
, (2) a method to encode a label
as a vector
, and (3) a method to represent the relation between the instance
x and the label
y. These three conditions make
g able to capture the relationships inputs-to-labels and labels-to-labels. In this work, we take advantage of the successes of deep learning models to fulfill the three requirements listed above. We empirically show the success of our system with respect to these conditions as reported in
Section 4.6 and
Section 4.7.
3.2. BNet: System Description
This subsection explains the proposed system to solve the transformed binary problem mentioned above.
Figure 2 shows the graphical depiction of the system’s architecture. It is composed of three parts: the embedding module, the encoding module, and the classification module. We explain in detail each of them below.
3.2.1. Embedding Module
Let be the pair of inputs to our system, where is the set of the words in a tweet and y is the label corresponding to an emotion. The goal of the embedding module is to represent each word by a vector and the label by a vector .
Our embedding module can be seen as a function that maps a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. The query is the trainable label embedding, ; the keys are the pretrained words embeddings, ; and the values are the trainable words embeddings, .
As shown in
Figure 2, we used the output of
and
as inputs to the attention model to find the alignments, i.e., the weights
, between the label
y and the words
W of the input tweet. This step models the relation between the input and the label. As soon as the weights were obtained, we then multiplied each word’s vector that came from the embedding
by its corresponding weight. Given that, the final representation of a word
is given as the following:
The function
is an attention-based model, which finds the strength of the relationship between the word
and the label
y based on their semantic similarity. That is,
is a value based on the distance
between
and
y as:
Here,
is a scalar score that represents the similarity between the word
and the label
y:
It is worth noting that
and:
3.2.2. Encoding Module
The goal of the encoding module is to map the sequence of word representations
that is obtained from the embedding module to a single real-valued dense vector. In this work, we used a Recurrent Neural Network (RNN) to design our encoder. RNN reads the input sequence of vectors in a forward direction (left-to-right) starting from the first symbol
to the last one
. Thus, it processes sequences in temporal order, ignoring the future context. However, for many tasks on sequences, it is beneficial to have access to future, as well as to past information. For example, in text processing, decisions are usually made after the whole sentence is known. The Bidirectional Recurrent Neural Network (BiRNN) variant [
13] proposed a solution for making predictions based on both past and future information.
A BiRNN consists of forward and backward RNNs. The first one reads the input sequence in a forward direction and produces a sequence of forward hidden states , whereas the former reads the sequence in the reverse order , resulting in a sequence of backward hidden states .
We obtained a representation for each word
by concatenating the corresponding forward hidden state
and the backward one
. The following equations illustrate the main ideas:
The final input representation of the sequence is:
We simply chose F to be the last hidden state (i.e., ).
In this work, we used two Gated Recurrent Units (GRUs) [
14], one as
and the other as
. This kind of RNN was designed to have more persistent memory, making them very useful to capture long-term dependencies between the elements of a sequence.
Figure 3 shows a graphical depiction of a gated recurrent unit.
A GRU has reset () and update () gates. The former can completely reduce the past hidden state if it finds that it is irrelevant to the computation of the new state, whereas the later is responsible for determining how much of should be carried forward to the next state .
The output
of a GRU depends on the input
and the previous state
, and it is computed as follows:
In these expressions, and denote the reset and update gates, is the candidate output state, and is the actual output state at time t. The symbol ⊙ stands for element-wise multiplication; is a sigmoid function; and; stands for the vector-concatenation operation. and are the parameters of the reset and update gates, where is the dimension of the hidden state and d is the dimension of the input vector.
3.2.3. Classification Module
Our classifier was composed of two feed-forward layers with the activation function followed by a Sigmoid unit.
4. Experiments and Results
In this section, we first describe the experimental details, and then, we describe the dataset and the pre-processing we used. Afterwards, we introduce the state-of-the-art systems we compared our system with, and finally, we report the empirical validation proving the effectiveness of our system.
4.1. Experimental Details
Table 1 shows the hyperparameters of our system, which was trained using Adam [
36], with a learning rate of 0.0001,
= 0.5, and a mini-batch size of 32 to minimize the binary cross-entropy loss function:
where,
is the predicted value,
is the real value, and
is the model’s parameters.
The hyperparameters of our system were obtained by applying Bayesian optimization [
37]. We used the development set as a validation set to fine-tune those parameters.
4.2. Dataset
In our experiments, we used the multi-label emotion classification dataset of SemEval-2018 Task1: Affect in Tweets [
30]. It contains 10,983 samples divided into three splits: training set (6838 samples), validation set (886 samples), and testing set (3259 samples). For more details about the dataset, we refer the reader to [
38]. We trained our system on the training set and used the validation set to fine-tune the parameters of the proposed system. We pre-processed each tweet in the dataset as follows:
Tokenization: We used an extensive list of regular expressions to recognize the following meta information included in tweets: Twitter markup, emoticons, emojis, dates, times, currencies, acronyms, hashtags, user mentions, URLs, and words with emphasis.
As soon as the tokenization was done, we lowercased words and normalized the recognized tokens. For example, URLs were replaced by the token “<URL>”, and user mentions were replaced by the token “<USER>”. This step helped to reduce the size of the vocabulary without losing information.
4.3. Comparison with Other Systems
We compared the proposed system with the state-of-the-art systems used in the task of multi-label emotion classification, including:
SVM-unigrams: a baseline support vector machine system trained using just word unigrams as features [
30].
NTUA-SLP: the system submitted by the winner team of the SemEval-2018 Task1:E-cchallenge [
33].
TCS: the system submitted by the second place winner [
34].
PlusEmo2Vec: the system submitted by the third place winner [
35].
Transformer: a deep learning system based on large pre-trained language models developed by the NVIDIA AI lab [
39].
4.4. Evaluation Metrics
We used multi-label accuracy (or Jaccard index), the official competition metric used by the organizers of SemEval-2018 Task 1: Affect in Tweets, for the E-c sub task, which can be defined as the size of the intersection of the predicted and gold label sets divided by the size of their union.
In this expression, is the set of the gold labels for tweet t, is the set of the predicted labels for tweet t, and T is the set of tweets. Additionally, we also used the micro-averaged F-score and the macro-averaged F-score.
Let
denote the number of samples correctly assigned to the label
l,
the number of samples assigned to
l, and
the number of actual samples in
l. The micro-averaged F1-score is calculated as follows:
Thus, is the micro-averaged precision score, and is the micro-averaged recall score.
Let
,
, and
denote the precision score, recall score, and the F1-score of the label
l. The macro-averaged F1-score is calculated as follows:
4.5. Results
We submitted our system’s predictions to the SemEval Task1:E-C challenge. The results were computed by the organizers on a golden test set, for which we did not have access to the golden labels.
Table 2 shows the results of our system and the results of the compared models (obtained from their associated papers). As can be observed from the reported results, our system achieved the top Jaccard index accuracy and macro-averaged F1 scores among all the state-of-the-art systems, with a competitive, but slightly lower score for the micro-average F1.
To get more insight about the performance of our system, we calculated the precision score, the recall score, and the F1 score of each label. The results of this analysis are shown in
Figure 4. We found that our system gave the best performance on the “joy” label followed by the “anger”, “fear”, “disgust”, and “optimism” labels. The obtained F1-score of these labels was above 70%. The worst performance was obtained on the “trust”, “surprise”, “anticipation”, and “pessimism” labels. In most cases, our system gave a recall score higher than the precision score. It seems that the system was aggressive against the emotions “trust”, “surprise”, “anticipation”, and “pessimism” (i.e., the system associated a low number of samples to these labels). This can be attributed to the low number of training examples for these emotions and to the Out-Of-Vocabulary (OOV) problem.
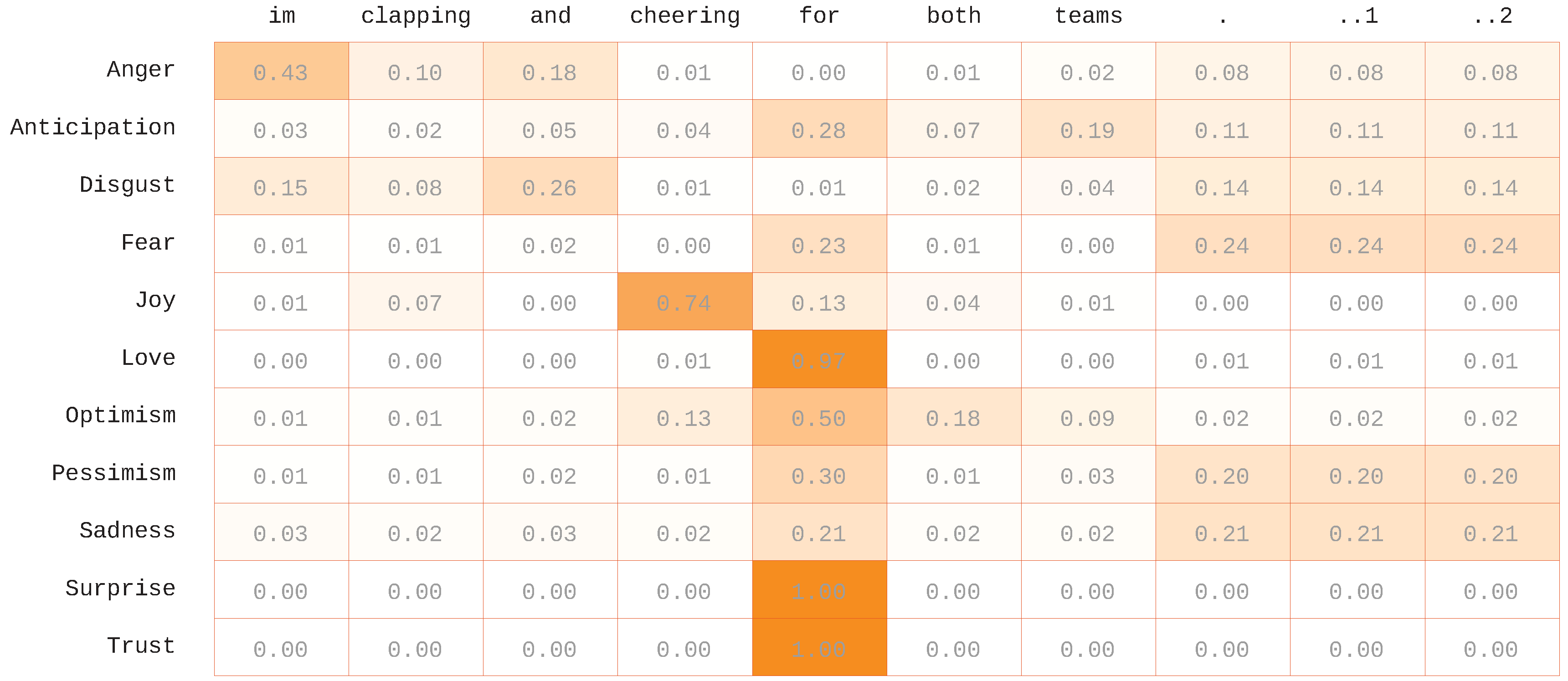
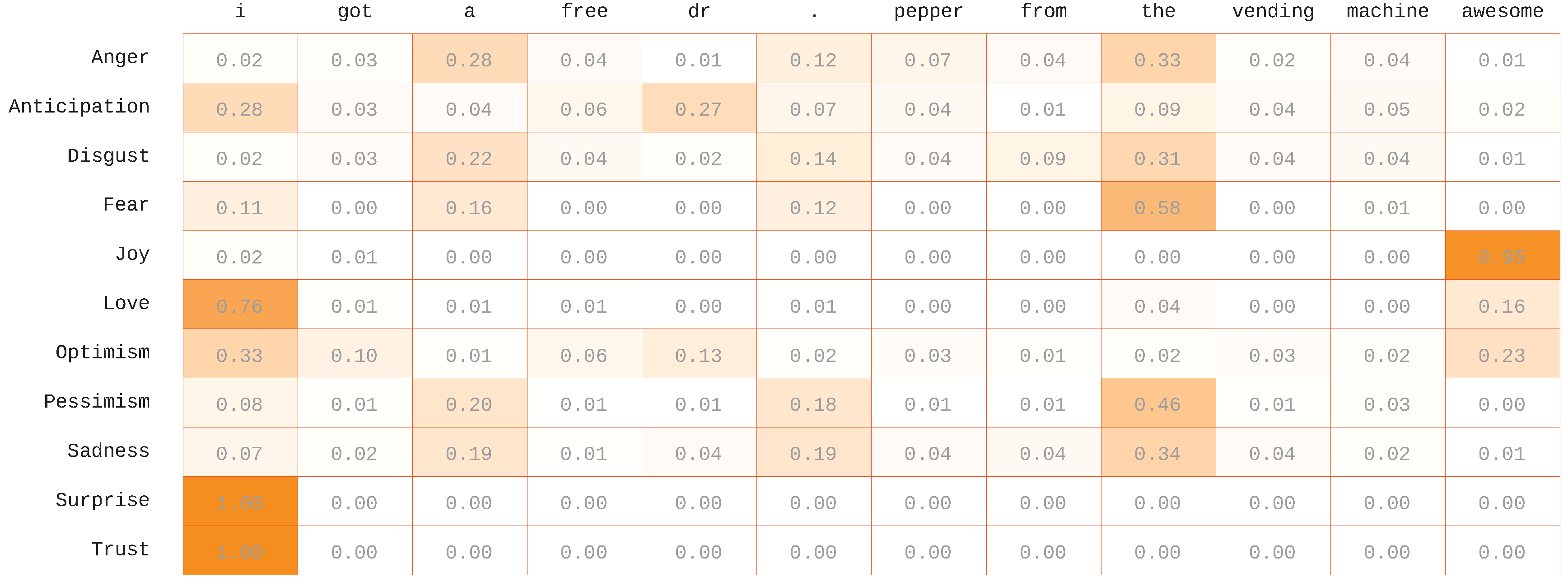
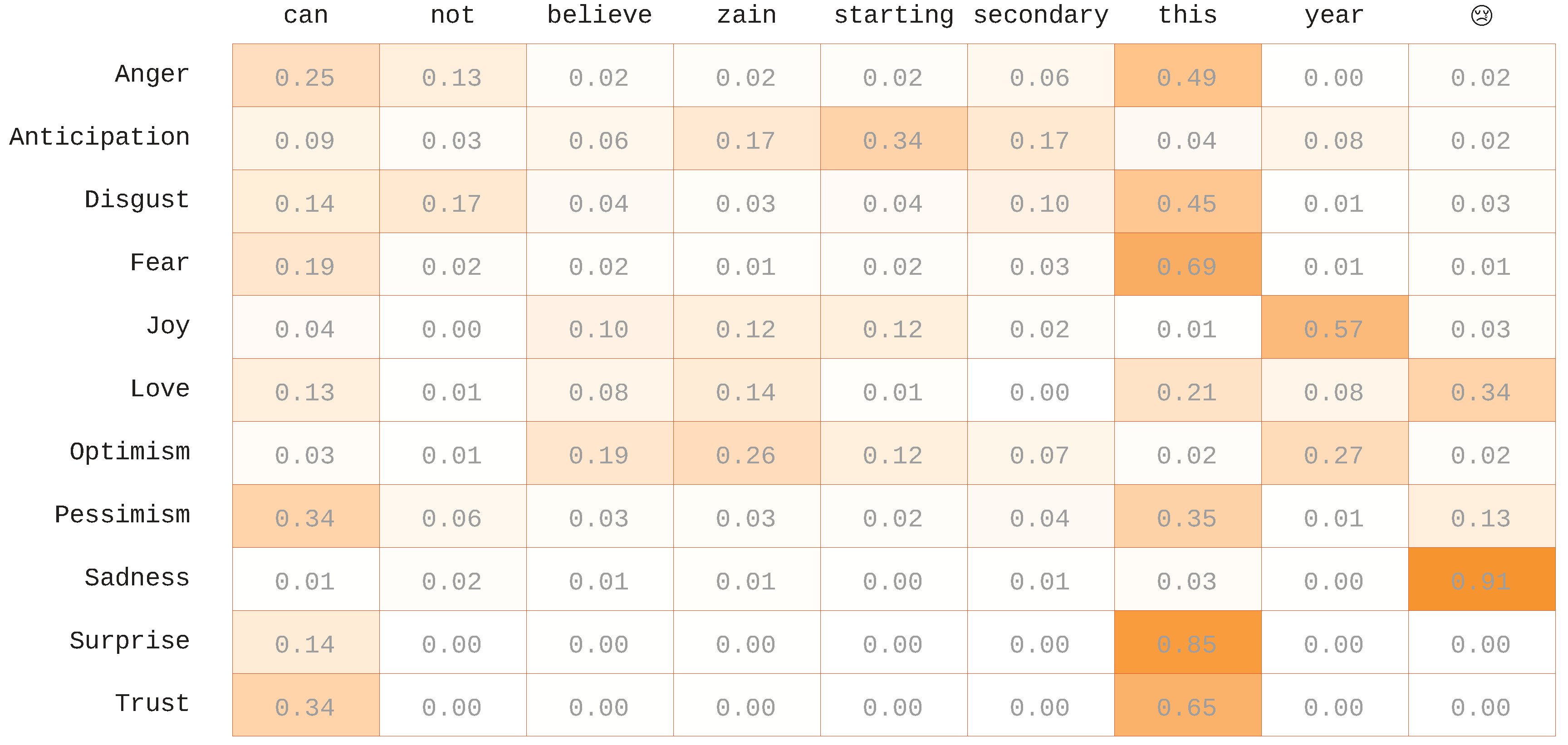
4.6. Attention Visualizations
We visualized the attention weights to get a better understanding of the performance of our system. The results are described in
Figure 5,
Figure 6,
Figure 7 and
Figure 8, which show heat-maps of the attention weights on the top four example tweets from the validation set. The color intensity refers to the weight given to each word by the attention model. It represents the strength of the relationship between the word and the emotion, which reflects the importance of this word in the final prediction. We can see that the attention model gave the important weights to the common words, such as the stop words, in case the tweet was not assigned to the emotion; for example, the word “for” in
Figure 5 and the word “this” in
Figure 7 and the token “<user>” in
Figure 8. Moreover, it also gives a high weight for the words and the emojis related to emotions (e.g., “cheering” and “awesome” for joy, “birthday” for love, etc.). An interesting observation is that when emojis were present, they were almost always selected as important if they were related to the emotion. For instance, we can see in
Figure 7 that the sadness emotion relied heavily on the emoji. We also found that considering only one word to model the relation between the tweet and the emotions was not enough. In some cases, the emotion of a word may be flipped based on the context. For instance, consider the following tweet as an example: “When being #productive (doing the things that NEED to be done), #anxiety level decreases and #love level increases. #personalsexuality”, the word “anxiety” is highly related to the emotion fear, but in this context, it shows optimism and trust emotions. However, our system misassociated this example with the fear emotion.
4.7. Correlation Analysis
Figure 9 shows the correlation analysis of emotion labels in the validation set. Each cell in the figure represents the correlation score of each pair of emotion labels. The reported values show exciting findings. Our system captured the relations among the emotion labels. The correlation scores of the predicted labels were almost identical to the ground-truth. There was an exception in the surprise and trust emotions. Our system was unsuccessful in capturing the relationships between these two emotions and the inputs or the other emotions. We attribute this apparent lack of correlation to the low number of training examples of these two emotions.
Moreover, there was always a positive correlation between related emotions such as “joy” and “optimism” (the score from the ground truth labels and from the predicted labels was 0.74). On the other side, we can see that there was a negative correlation between unlinked emotions like “anger” and “love”. The scores were −0.27 and −0.3, respectively.
This result further strengthened our hypothesis that the proposed system was able to, implicitly, model the relationships between the emotion labels.
5. Conclusions
In this work, we presented a new approach to the multi-label emotion classification task. First, we proposed a transformation method to transform the problem into a single binary classification problem. Afterwards, we developed a deep learning-based system to solve the transformed problem. The key component of our system was the embedding module, which used three embedding models and an attention function. Our system outperformed the state-of-the-art systems, achieving a Jaccard (i.e., multi-label accuracy) score of 0.59 on the challenging SemEval2018 Task 1:E-c multi-label emotion classification problem.
We found that the attention function can model the relationships between the input words and the labels, which helps to improve the system’s performance. Moreover, we showed that our system is interpretable by visualizing the attention weights and analyzing them. However, some limitations have been identified. Our system does not model the relationships between the phrases and the labels. Phrases play a key role in determining the most appropriate set of emotions that must be assigned to a tweet. For instance, an emotion word that reflects “sadness” can be flipped in a negated phrase or context. Thus, in our future work, we plan to work on solving this drawback. One possible solution is to adapt the attention function to model the relationships between different
n-gram tokens and labels. Structured attention networks [
40] can also be adapted and used to address this issue.
Moreover, we plan to work on developing a non-aggressive system that performs robustly and equally on all the emotion labels by experimenting with different ideas like using data augmentation to enrich the training data or using transfer learning.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}