Fault Diagnosis for Rolling Bearing Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy


Abstract
:1. Introduction
2. Fundamental Theories
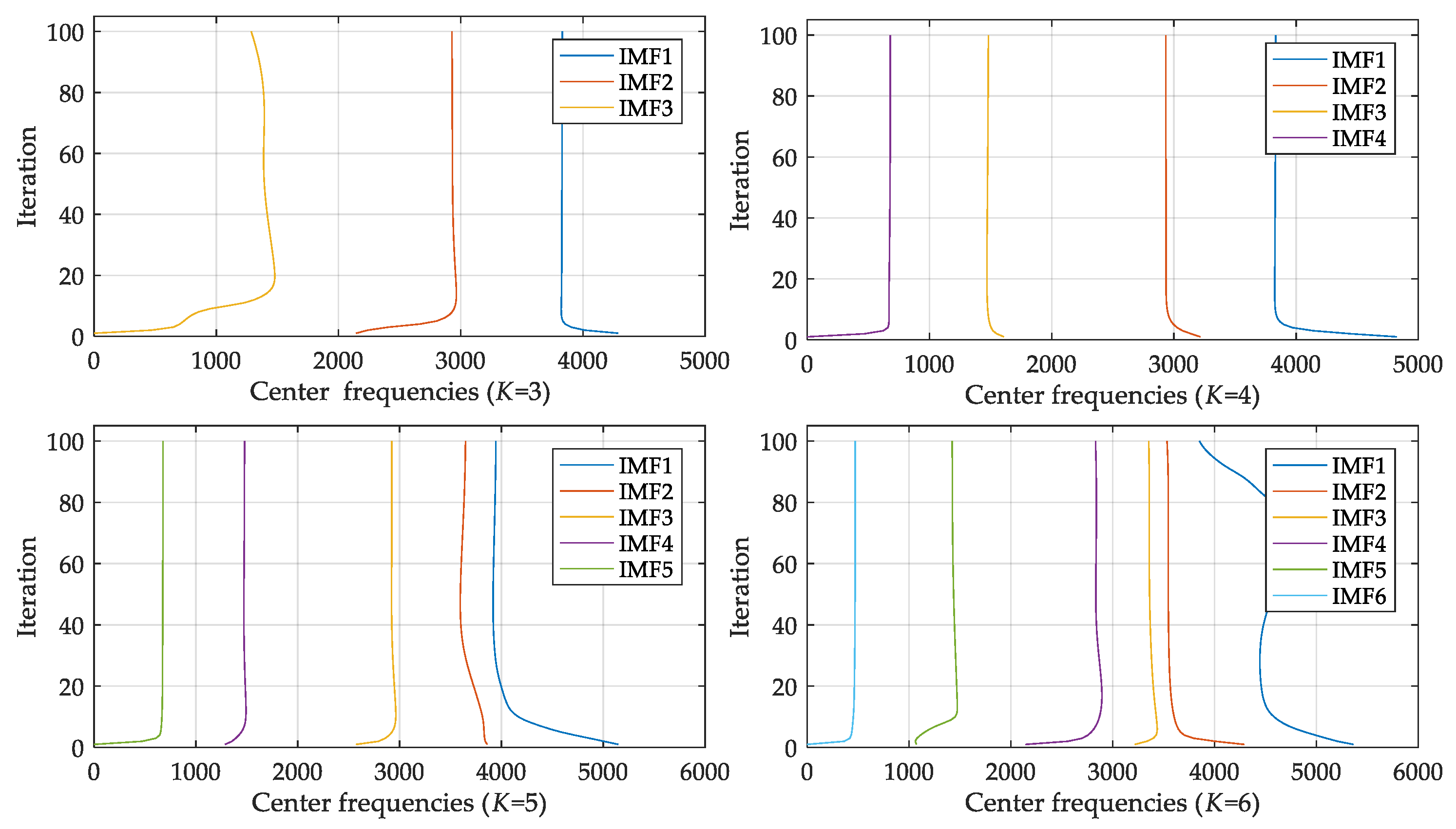
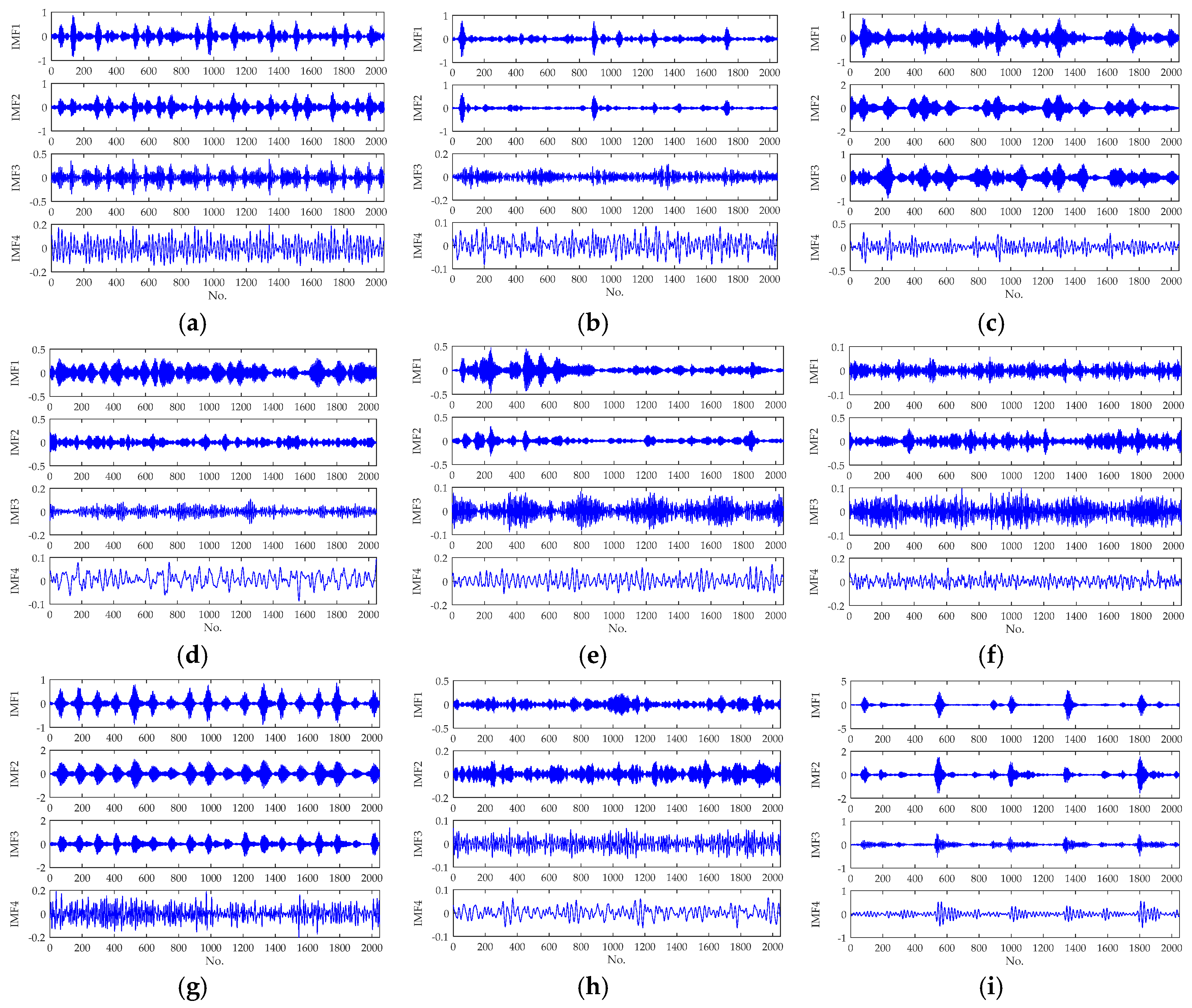
2.1. Variational Mode Decomposition
2.2. Fuzzy Entropy
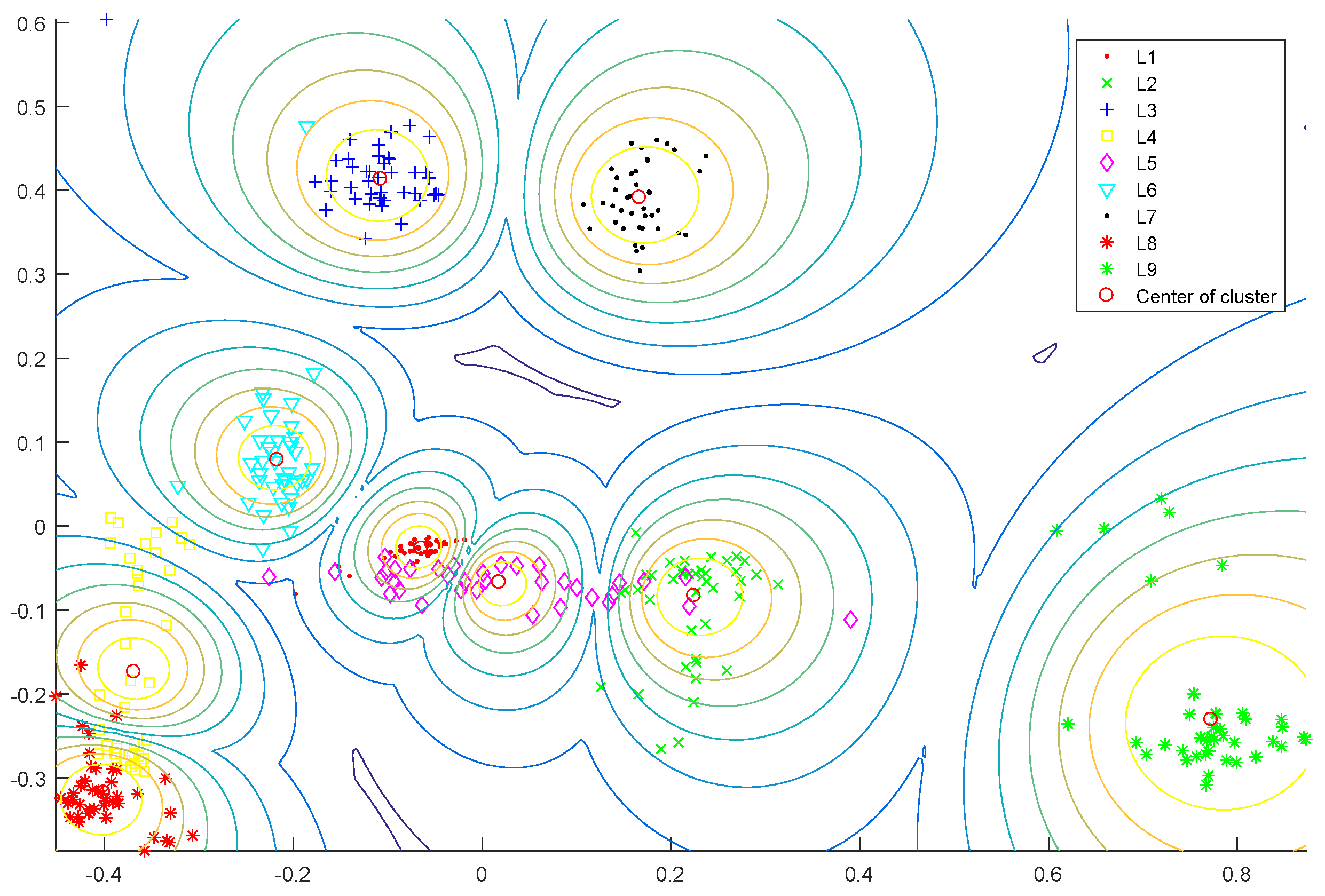
2.3. Semi-Supervised Fuzzy C-Means Clustering
2.4. Support Vector Data Description
3. Fault Diagnosis Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy
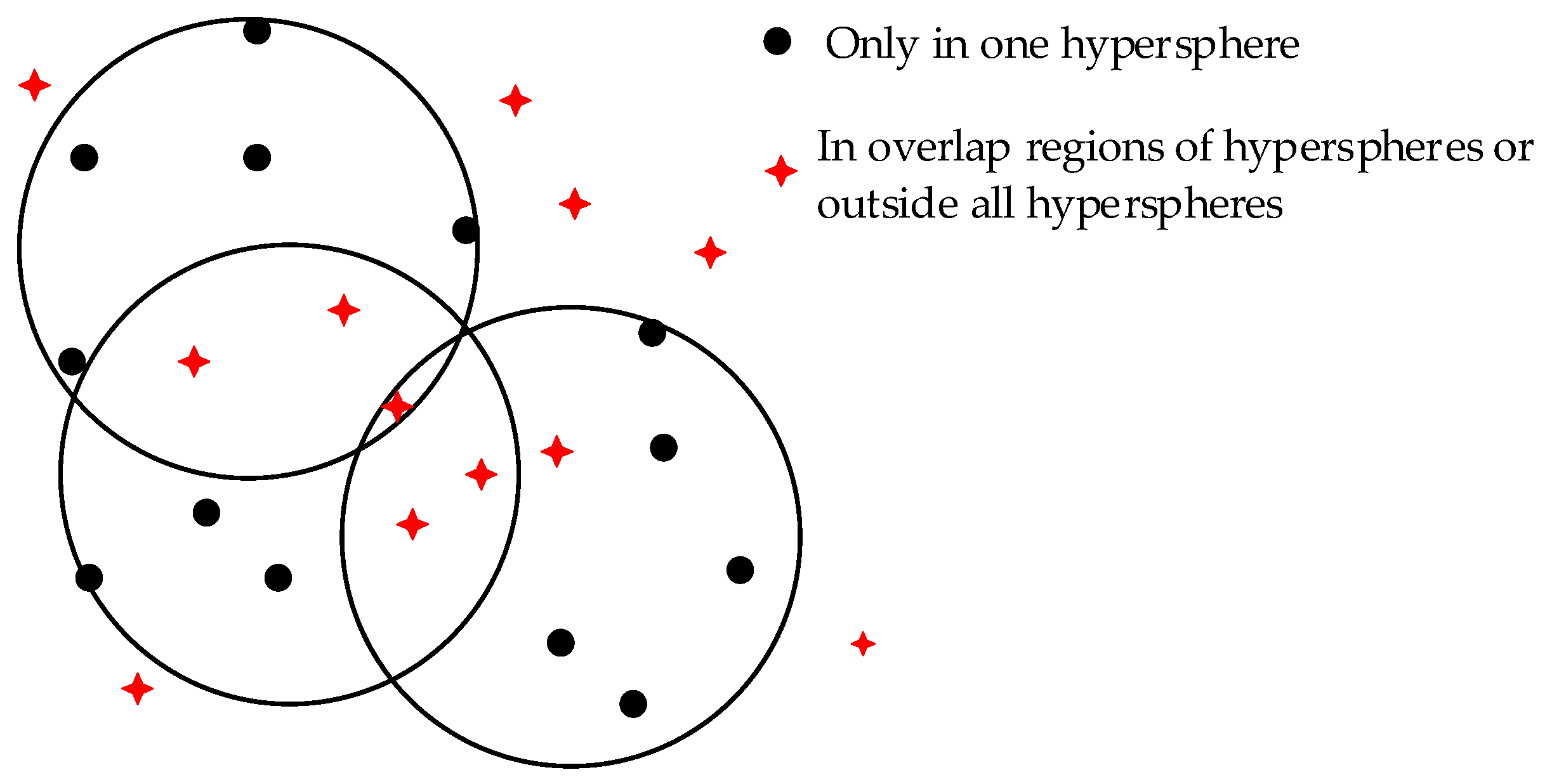
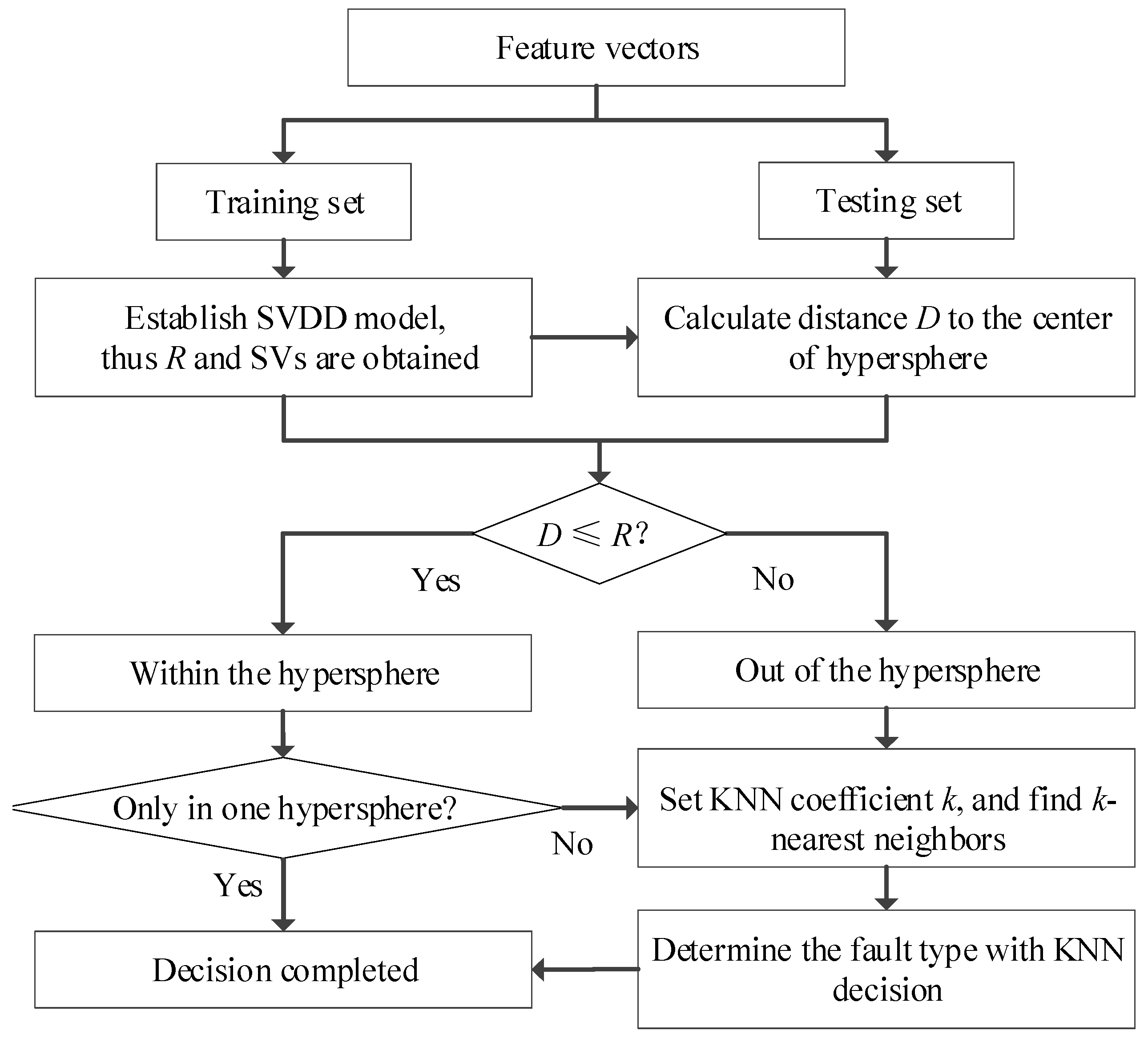
3.1. Improved Decision Strategy
3.2. Adaptive Parameter Optimization
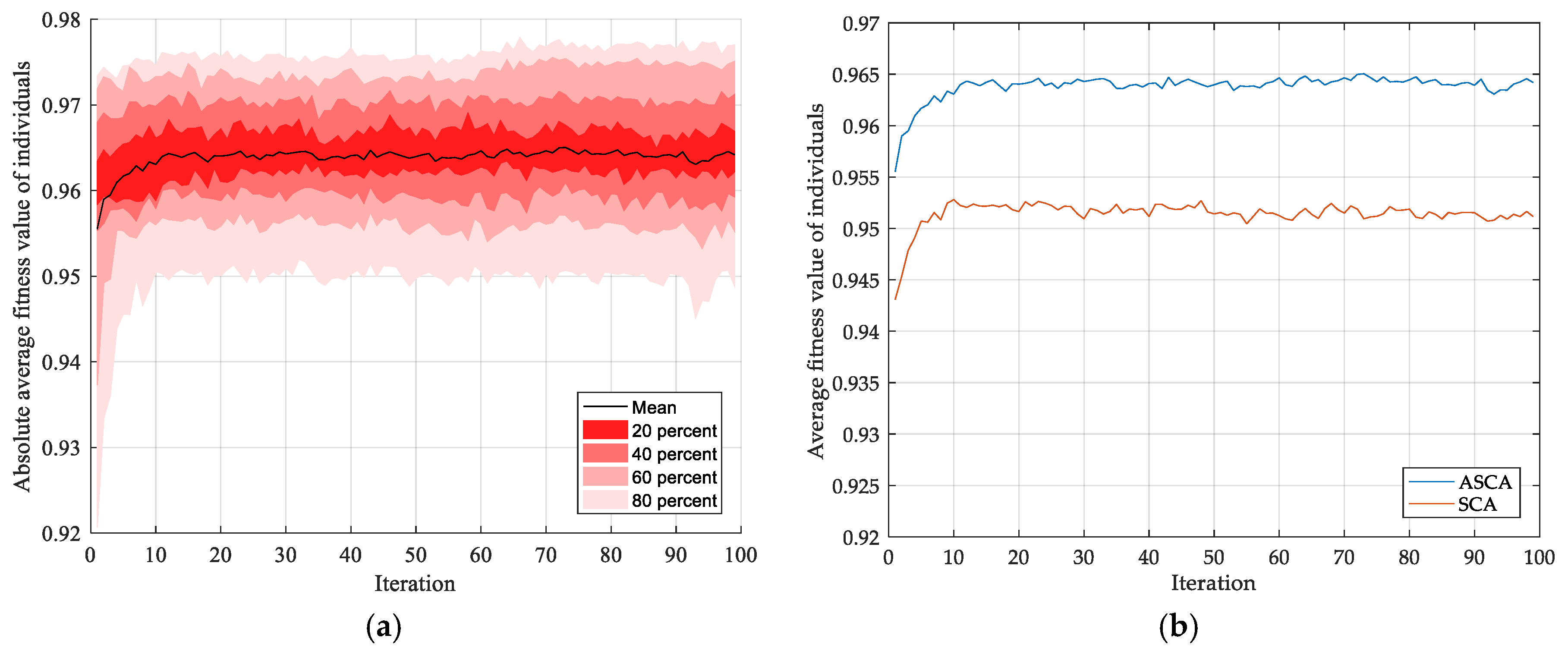
3.2.1. Sine Cosine Algorithm
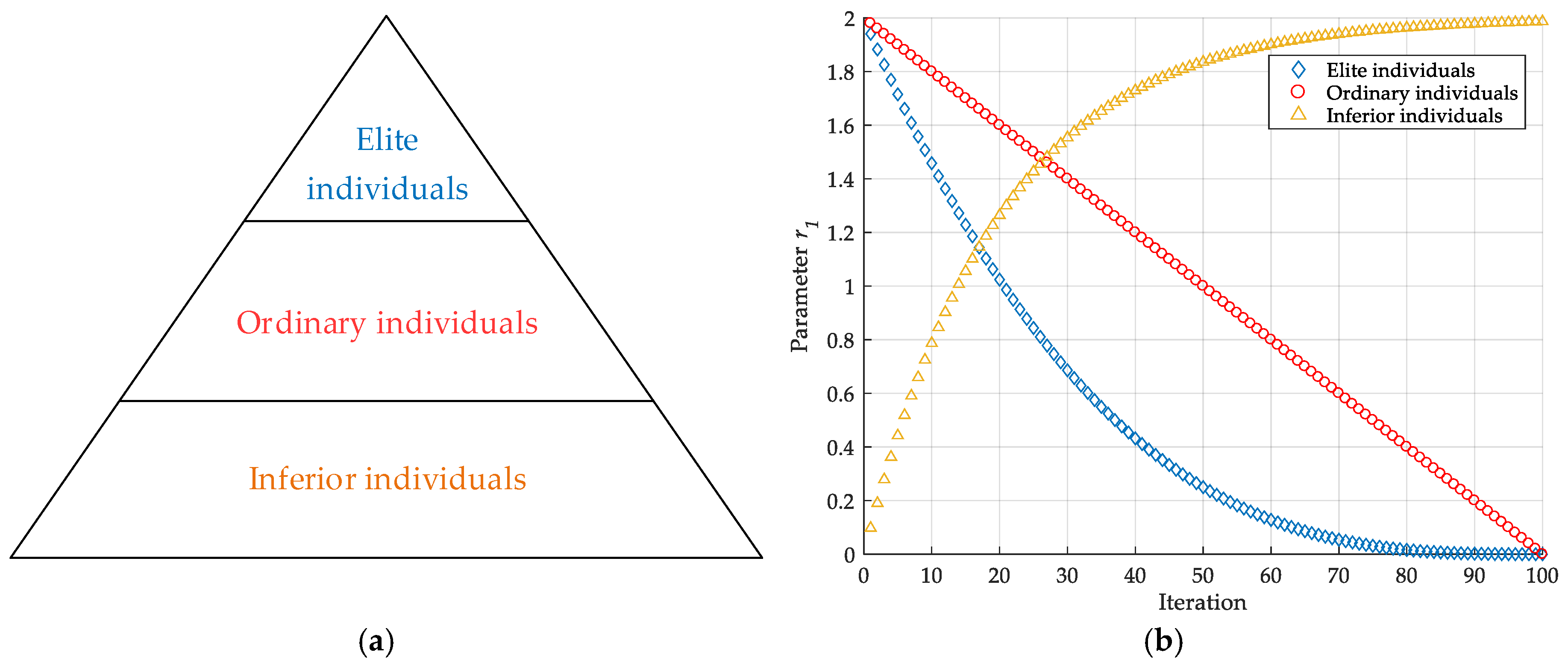
3.2.2. Adaptive Sine Cosine Algorithm
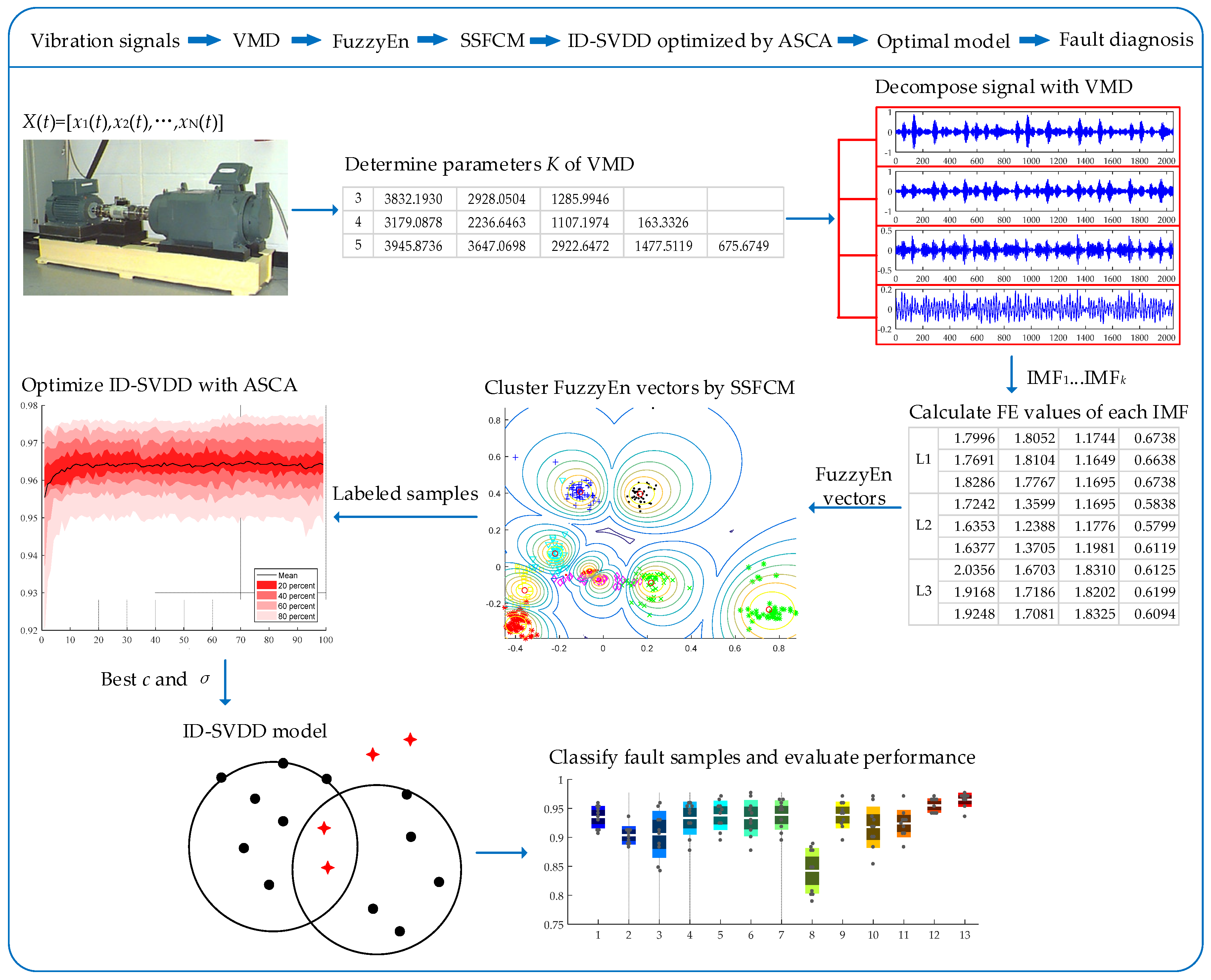
3.3. Fault Diagnosis Based on SSFCM and ID-SVDD Optimized by ASCA
4. Engineering Application
4.1. Data Collection
4.2. Application to Fault Diagnosis of Rolling Bearing
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yi, C.; Lv, Y.; Xiao, H.; You, G.; Dang, Z. Research on the blind source separation method based on regenerated phase-shifted sinusoid-assisted EMD and its application in diagnosing rolling-bearing faults. Appl. Sci. 2017, 7, 414. [Google Scholar] [CrossRef]
- Riaz, S.; Elahi, H.; Javaid, K.; Shahzad, T. Vibration feature extraction and analysis for fault diagnosis of rotating machinery-a literature survey. Asia Pac. J. Multidiscip. Res. 2017, 5, 103–110. [Google Scholar]
- Mbo’O, C.P.; Hameyer, K. Fault diagnosis of bearing damage by means of the linear discriminant analysis of stator current features from the frequency selection. IEEE Trans. Ind. Appl. 2016, 52, 3861–3868. [Google Scholar] [CrossRef]
- Yuan, R.; Lv, Y.; Song, G. Fault diagnosis of rolling bearing based on a novel adaptive high-order local projection denoising method. Complexity 2018, 2018, 3049318. [Google Scholar] [CrossRef]
- Fu, W.; Tan, J.; Li, C.; Zou, Z.; Li, Q.; Chen, T. A hybrid fault diagnosis approach for rotating machinery with the fusion of entropy-based feature extraction and SVM optimized by a chaos quantum sine cosine algorithm. Entropy 2018, 20, 626. [Google Scholar] [CrossRef]
- Adamczak, S.; Stepien, K.; Wrzochal, M. Comparative study of measurement systems used to evaluate vibrations of rolling bearings. Procedia Eng. 2017, 192, 971–975. [Google Scholar] [CrossRef]
- Kankar, P.K.; Sharma, S.C.; Harsha, S.P. Rolling element bearing fault diagnosis using wavelet transform. Neurocomputing. 2011, 74, 1638–1645. [Google Scholar] [CrossRef]
- Ali, J.B.; Fnaiech, N.; Saidi, L.; Chebel-Morello, B.; Fnaiech, F. Application of empirical mode decomposition and artificial neural network for automatic bearing fault diagnosis based on vibration signals. Appl. Acoust. 2015, 89, 16–27. [Google Scholar]
- Fu, W.; Zhou, J.; Zhang, Y.; Zhu, W.; Xue, X.; Xu, Y. A state tendency measurement for a hydro-turbine generating unit based on aggregated EEMD and SVR. Meas. Sci. Technol. 2015, 26, 125008. [Google Scholar] [CrossRef]
- Li, K.; Su, L.; Wu, J.; Wang, H.; Chen, P. A rolling bearing fault diagnosis method based on variational mode decomposition and an improved kernel extreme learning machine. Appl. Sci. 2017, 7, 1004. [Google Scholar] [CrossRef]
- Fu, W.; Wang, K.; Li, C.; Li, X.; Li, Y.; Zhong, H. Vibration trend measurement for a hydropower generator based on optimal variational mode decomposition and an LSSVM improved with chaotic sine cosine algorithm optimization. Meas. Sci. Technol. 2019, 30, 015012. [Google Scholar] [CrossRef]
- Fu, W.; Wang, K.; Zhou, J.; Xu, Y.; Tan, J.; Chen, T. A hybrid approach for multi-step wind speed forecasting based on multi-scale dominant ingredient chaotic analysis, KELM and synchronous optimization strategy. Sustainability 2019, 11, 1804. [Google Scholar] [CrossRef]
- Xie, H.; Sivakumar, B.; Boonstra, T.W.; Mengersen, K. Fuzzy entropy and its application for enhanced subspace filtering. IEEE Trans. Fuzzy Syst. 2018, 26, 1970–1982. [Google Scholar] [CrossRef]
- Li, Y.; Xu, M.; Wang, R.; Huang, W. A fault diagnosis scheme for rolling bearing based on local mean decomposition and improved multiscale fuzzy entropy. J. Sound Vib. 2016, 360, 277–299. [Google Scholar] [CrossRef]
- Zhu, X.; Zheng, J.; Pan, H.; Bao, J.; Zhang, Y. Time-shift multiscale fuzzy entropy and laplacian support vector machine based rolling bearing fault diagnosis. Entropy 2018, 20, 602. [Google Scholar] [CrossRef]
- Fu, W.; Tan, J.; Zhang, X.; Chen, T.; Wang, K. Blind parameter identification of MAR model and mutation hybrid GWO-SCA optimized SVM for fault diagnosis of rotating machinery. Complexity 2019, 2019, 3264969. [Google Scholar] [CrossRef]
- Cerrada, M.; Sánchez, R.; Li, C.; Pacheco, F.; Cabrera, D.; José, V.D.O.; Vásquez, R.E. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Pedrycz, W. Algorithms of fuzzy clustering with partial supervision. Pattern Recognit. Lett. 1985, 3, 13–20. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, P.; Ren, G.; Fu, J. Engine wear fault diagnosis based on improved semi-supervised fuzzy C-means clustering. J. Mech. Eng. 2011, 47, 55. [Google Scholar] [CrossRef]
- Arshad, A.; Riaz, S.; Jiao, L. Semi-supervised deep fuzzy c-mean clustering for imbalanced mulit-class classification. IEEE Access 2019, 7, 28100–28112. [Google Scholar] [CrossRef]
- Yao, B.; Su, J.; Wu, L.; Guan, Y. Modified local linear embedding algorithm for rolling element bearing fault diagnosis. Appl. Sci. 2017, 7, 1178. [Google Scholar] [CrossRef]
- Raj, N.; Jagadanand, G.; George, S. Fault detection and diagnosis in asymmetric multilevel inverter using artificial neural network. Int. J. Electron. 2017, 105, 559–571. [Google Scholar] [CrossRef]
- Chen, H.; Wang, J.; Li, J.; Tang, B. A texture-based rolling bearing fault diagnosis scheme using adaptive optimal kernel time frequency representation and uniform local binary patterns. Meas. Sci. Technol. 2017, 28, 035903. [Google Scholar] [CrossRef]
- Wang, H.; Chen, J. Performance degradation assessment of rolling bearing based on bispectrum and support vector data description. J. Vib. Control 2014, 20, 2032–2041. [Google Scholar] [CrossRef]
- Tax, D.M.J.; Duin, R.P.W. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Zhou, J.; Fu, W.; Zhang, Y.; Xiao, H.; Xiao, J.; Zhang, C. Fault diagnosis based on a novel weighted support vector data description with fuzzy adaptive threshold decision. Trans. Inst. Measure. Control 2018, 40, 71–79. [Google Scholar] [CrossRef]
- Zhou, J.; Guo, H.; Zhang, L.; Xu, Q.; Li, H. Bearing performance degradation assessment using lifting wavelet packet symbolic entropy and SVDD. Shock Vib. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Wang, H. Fault diagnosis of rolling element bearing compound faults based on sparse no-negative matrix factorization-support vector data description. J. Vib. Control 2018, 24, 272–282. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Zhang, Z.; Yao, L.; Wang, C.; Mo, L.; Ouyang, S.; Li, J. A region search evolutionary algorithm for many-objective optimization. Inform. Sci. 2019. [Google Scholar] [CrossRef]
- Fu, W.; Tan, J.; Xu, Y.; Wang, K.; Chen, T. Fault diagnosis for rolling bearings based on fine-sorted dispersion entropy and SVM optimized with mutation SCA-PSO. Entropy 2019, 21, 404. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, T.; Li, C.; Fu, W.; Xia, X.; Xue, X. Multiobjective optimization of a fractional-order PID controller for pumped turbine governing system using an improved NSGA-III algorithm under multiworking conditions. Complexity 2019, 2019, 5826873. [Google Scholar] [CrossRef]
- Duan, L.; Xie, M.; Bai, T.; Wang, J. A new support vector data description method for machinery fault diagnosis with unbalanced datasets. Expert Syst. Appl. 2016, 64, 239–246. [Google Scholar] [CrossRef]
- Xu, Y.; Zheng, Y.; Du, Y.; Yang, W.; Peng, X.; Li, C. Adaptive condition predictive-fuzzy PID optimal control of start-up process for pumped storage unit at low head area. Energy Convers. Manag. 2018, 177, 592–604. [Google Scholar] [CrossRef]
- Xu, Y.; Li, C.; Wang, Z.; Zhang, N.; Peng, B. Load frequency control of a novel renewable energy integrated micro-grid containing pumped hydropower energy storage. IEEE Access 2018, 6, 29067–29077. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Fu, W.; Wang, K.; Li, C.; Tan, J. Multi-step short-term wind speed forecasting approach based on multi-scale dominant ingredient chaotic analysis, improved hybrid GWO-SCA optimization and ELM. Energy Convers. Manag. 2019, 187, 356–377. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Oliva, D.; Xiong, S. An improved opposition-based sine cosine algorithm for global optimization. Expert Syst. Appl. 2017, 90, 484–500. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Chan, R.H.; Tao, M.; Yuan, X. Constrained total variation deblurring models and fast algorithms based on alternating direction method of multipliers. SIAM J. Imaging Sci. 2013, 6, 680–697. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Phys. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of surface EMG signal based on fuzzy entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c -means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Wu, H.; Zhu, C.; Chang, B.; Liu, J. Adaptive genetic algorithm to improve group premature convergence. J. Xi’an Jiaotong Univ. 1999, 33, 27–30. (In Chinese) [Google Scholar]
- Bearing Data Center of the Case Western Reserve University. Available online: http://csegroups.case.edu/bearingdatacenter/pages/download-data-file (accessed on 28 September 2018).
- Basu, S.; Banerjee, A.; Mooney, R.J. Semi-supervised clustering by seeding. In Proceedings of the Nineteenth International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002; pp. 19–26. [Google Scholar]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Lai, X.; Li, C.; Zhou, J.; Zhang, N. Multi-objective optimization for guide vane shutting based on MOASA. Renew. Energy 2019, 139, 302–312. [Google Scholar] [CrossRef]
- Li, C.; Wang, W.; Chen, D. Multi-objective complementary scheduling of hydro-thermal-RE power system via a multi-objective hybrid grey wolf optimizer. Energy 2019, 171, 241–255. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Mo, L.; Wang, Y.; Chen, D.; Pang, S.; Yin, X. Hierarchical flood operation rules optimization using multi-objective cultured evolutionary algorithm based on decomposition. Water Resour. Manag. 2019, 33, 337–354. [Google Scholar] [CrossRef]
- Jiang, L.; Xuan, J.; Shi, T. Feature extraction based on semi-supervised kernel marginal fisher analysis and its application in bearing fault diagnosis. Mech. Syst. Signal Process. 2013, 41, 113–126. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Location | Diameter (inches) | Fault Label | Number of Samples |
|---|---|---|---|
| Inner race | 0.007 | L1 | 59 |
| Inner race | 0.014 | L2 | 59 |
| Inner race | 0.021 | L3 | 59 |
| Ball | 0.007 | L4 | 59 |
| Ball | 0.014 | L5 | 59 |
| Ball | 0.021 | L6 | 59 |
| Outer race | 0.007 | L7 | 59 |
| Outer race | 0.014 | L8 | 59 |
| Outer race | 0.021 | L9 | 59 |
| Number of Modes | Center Frequencies (Hz) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2903.44 | 1166.73 | |||||||
| 3 | 3832.19 | 2928.05 | 1285.99 | ||||||
| 4 | 3179.09 | 2236.65 | 1107.20 | 163.33 | |||||
| 5 | 3945.87 | 3647.07 | 2922.65 | 1477.51 | 675.67 | ||||
| 6 | 3952.42 | 3672.88 | 3042.01 | 2756.44 | 1465.45 | 668.06 | |||
| 7 | 4079.22 | 3835.39 | 3547.95 | 2921.58 | 1597.69 | 1263.47 | 633.97 | ||
| 8 | 4088.98 | 3848.10 | 3573.75 | 3040.86 | 2762.20 | 1583.65 | 1255.25 | 632.93 | |
| 9 | 5175.26 | 4031.42 | 3821.29 | 3562.16 | 3040.24 | 2761.83 | 1583.05 | 1254.80 | 633.18 |
| Fault Label | Sample Number | Fuzzy Entropy for Different IMFs | |||
|---|---|---|---|---|---|
| IMF1 | IMF2 | IMF3 | IMF4 | ||
| L1 | 1 | 1.7996 | 1.8052 | 1.1744 | 0.6738 |
| 2 | 1.7691 | 1.8104 | 1.1649 | 0.6638 | |
| 3 | 1.8286 | 1.7767 | 1.1695 | 0.6738 | |
| L2 | 1 | 1.7242 | 1.3599 | 1.1695 | 0.5838 |
| 2 | 1.6353 | 1.2388 | 1.1776 | 0.5799 | |
| 3 | 1.6377 | 1.3705 | 1.1981 | 0.6119 | |
| L3 | 1 | 2.0356 | 1.6703 | 1.8310 | 0.6125 |
| 2 | 1.9168 | 1.7186 | 1.8202 | 0.6199 | |
| 3 | 1.9248 | 1.7081 | 1.8325 | 0.6094 | |
| L4 | 1 | 2.2160 | 2.0236 | 0.9334 | 0.3960 |
| 2 | 2.2282 | 2.0723 | 0.9072 | 0.3288 | |
| 3 | 2.2025 | 2.0116 | 0.9650 | 0.5454 | |
| L5 | 1 | 1.7123 | 1.6451 | 1.2169 | 0.4758 |
| 2 | 1.9905 | 1.6487 | 1.1966 | 0.4806 | |
| 3 | 1.9124 | 1.6921 | 1.1990 | 0.4936 | |
| L6 | 1 | 1.7338 | 2.0930 | 1.2618 | 0.6195 |
| 2 | 2.1333 | 1.9824 | 1.2164 | 0.6141 | |
| 3 | 2.1229 | 1.9946 | 1.2435 | 0.6438 | |
| L7 | 1 | 1.2859 | 1.7536 | 1.5843 | 0.9124 |
| 2 | 1.2313 | 1.7508 | 1.6109 | 0.8821 | |
| 3 | 1.3335 | 1.7556 | 1.6099 | 1.0993 | |
| L8 | 1 | 2.1004 | 2.0725 | 0.8502 | 0.4750 |
| 2 | 2.1927 | 2.1651 | 0.7906 | 0.4937 | |
| 3 | 2.1565 | 2.1261 | 0.9207 | 0.5691 | |
| L9 | 1 | 0.7437 | 0.9596 | 0.9206 | 0.4920 |
| 2 | 0.6916 | 1.0609 | 1.2533 | 0.5486 | |
| 3 | 0.9297 | 0.9185 | 0.9081 | 0.5329 | |
| Parameter | Description | Method | Value |
|---|---|---|---|
| K | mode number | VMD | 4 |
| m | fractal dimension | FuzzyEn | 2 |
| r | positive real number | FuzzyEn | 0.2 |
| w | weighting parameter | SSFCM | 2 |
| α | balance coefficient | SSFCM | 1/0.3 and 1/0.5 |
| M | number of individuals | ASCA | 30 |
| T | iteration times | ASCA | 100 |
| C | penalty factor | SVDD | 0.1177 and 0.1523 |
| σ | kernel parameter | SVDD | 26.7073 and 0.0011 |
| k | number of nearest neighbors | KNN | 3 |
| Processing Methods (Labeled Ratio) | C | σ (g) | Result Evaluation | |
|---|---|---|---|---|
| Normalized Mutual Information (NMI) | Accuracy (ACC) | |||
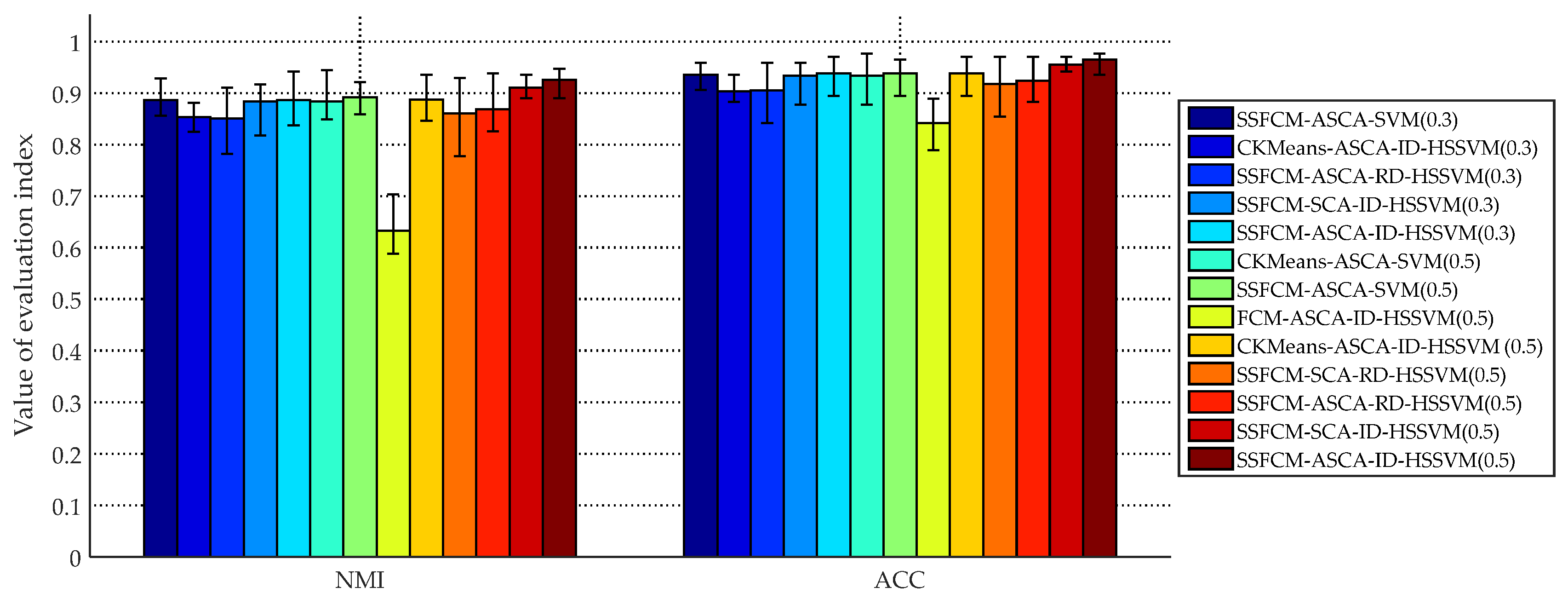
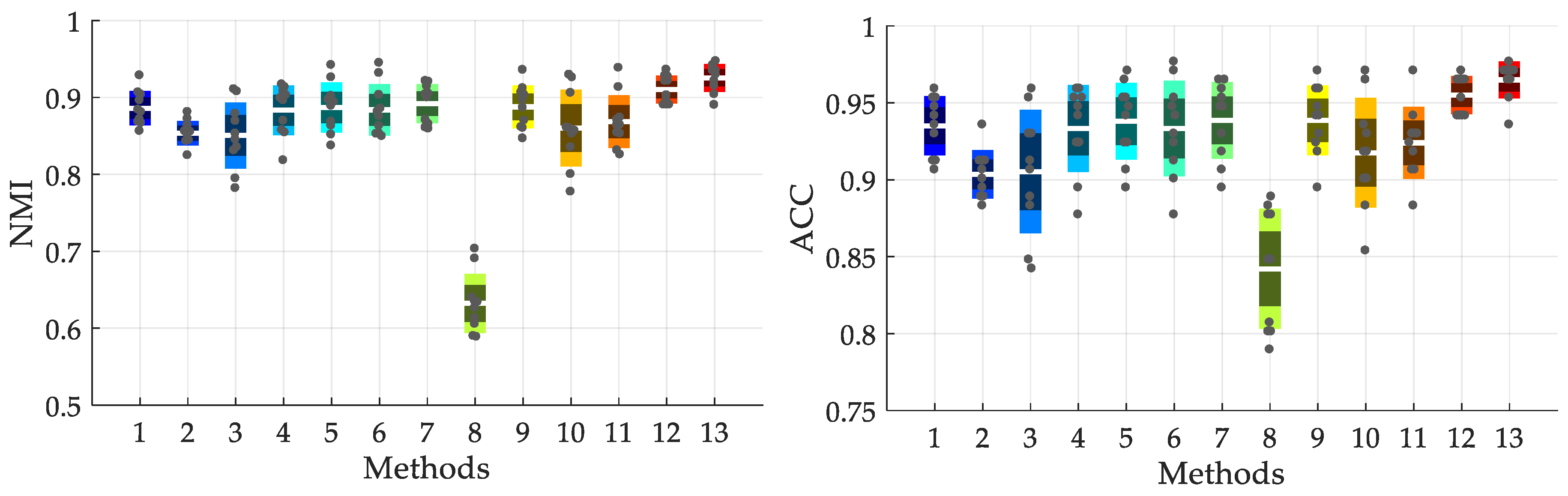
| SSFCM-ASCA-SVM (0.3) | 39.8545 | 3.4262 | 0.8860, [−0.030, 0.042] | 0.9351, [−0.029, 0.024] |
| CK-means-ASCA-ID-SVDD (0.3) | 0.0983 | 72.2803 | 0.8534, [−0.029, 0.027] | 0.9035, [−0.020, 0.032] |
| SSFCM-ASCA-RD-SVDD (0.3) | 0.0323 | 1024.0000 | 0.8505, [−0.069,0.060] | 0.9053, [−0.063, 0.054] |
| SSFCM-SCA-ID-SVDD (0.3) | 0.9560 | 29.5815 | 0.8833, [−0.065, 0.033] | 0.9333, [−0.056, 0.026] |
| SSFCM-ASCA-ID-SVDD (0.3) | 0.1177 | 26.7073 | 0.8868, [−0.050, 0.055] | 0.9380, [−0.043, 0.033] |
| CK-means-ASCA-SVM (0.5) | 31.4351 | 1.2567 | 0.8838, [−0.035, 0.061] | 0.9333, [−0.056, 0.043] |
| SSFCM-ASCA-SVM (0.5) | 73.4361 | 0.2825 | 0.8919, [−0.044, 0.071] | 0.9386, [−0.044, 0.026] |
| FCM-ASCA-ID-SVDD (0.5) | 0.9892 | 1005.0437 | 0.6323, [−0.044, 0.071] | 0.8421, [−0.053, 0.047] |
| CK-means-ASCA-ID-SVDD (0.5) | 0.0303 | 0.0025 | 0.8877, [−0.041, 0.048] | 0.9386, [−0.044, 0.032] |
| SSFCM-SCA-RD-SVDD (0.5) | 0.5104 | 0.1006 | 0.8601, [−0.083, 0.069] | 0.9175, [−0.064, 0.053] |
| SSFCM-ASCA-RD-SVDD (0.5) | 0.2456 | 18.3967 | 0.8686, [−0.043, 0.070] | 0.9240, [−0.041, 0.047] |
| SSFCM-SCA-ID-SVDD (0.5) | 0.8195 | 51.0377 | 0.9102, [−0.020, 0.026] | 0.9550, [−0.013, 0.016] |
| SSFCM-ASCA-ID-SVDD (0.5) | 0.1523 | 0.0011 | 0.9254, [−0.036, 0.021] | 0.9649, [−0.029, 0.012] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.; Fu, W.; Wang, K.; Xue, X.; Hu, W.; Shan, Y. Fault Diagnosis for Rolling Bearing Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy. Appl. Sci. 2019, 9, 1676. https://doi.org/10.3390/app9081676
Tan J, Fu W, Wang K, Xue X, Hu W, Shan Y. Fault Diagnosis for Rolling Bearing Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy. Applied Sciences. 2019; 9(8):1676. https://doi.org/10.3390/app9081676
Chicago/Turabian StyleTan, Jiawen, Wenlong Fu, Kai Wang, Xiaoming Xue, Wenbing Hu, and Yahui Shan. 2019. "Fault Diagnosis for Rolling Bearing Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy" Applied Sciences 9, no. 8: 1676. https://doi.org/10.3390/app9081676
APA StyleTan, J., Fu, W., Wang, K., Xue, X., Hu, W., & Shan, Y. (2019). Fault Diagnosis for Rolling Bearing Based on Semi-Supervised Clustering and Support Vector Data Description with Adaptive Parameter Optimization and Improved Decision Strategy. Applied Sciences, 9(8), 1676. https://doi.org/10.3390/app9081676