Complex Human–Object Interactions Analyzer Using a DCNN and SVM Hybrid Approach



Abstract
:Featured Application
Abstract
1. Introduction
2. Related Works
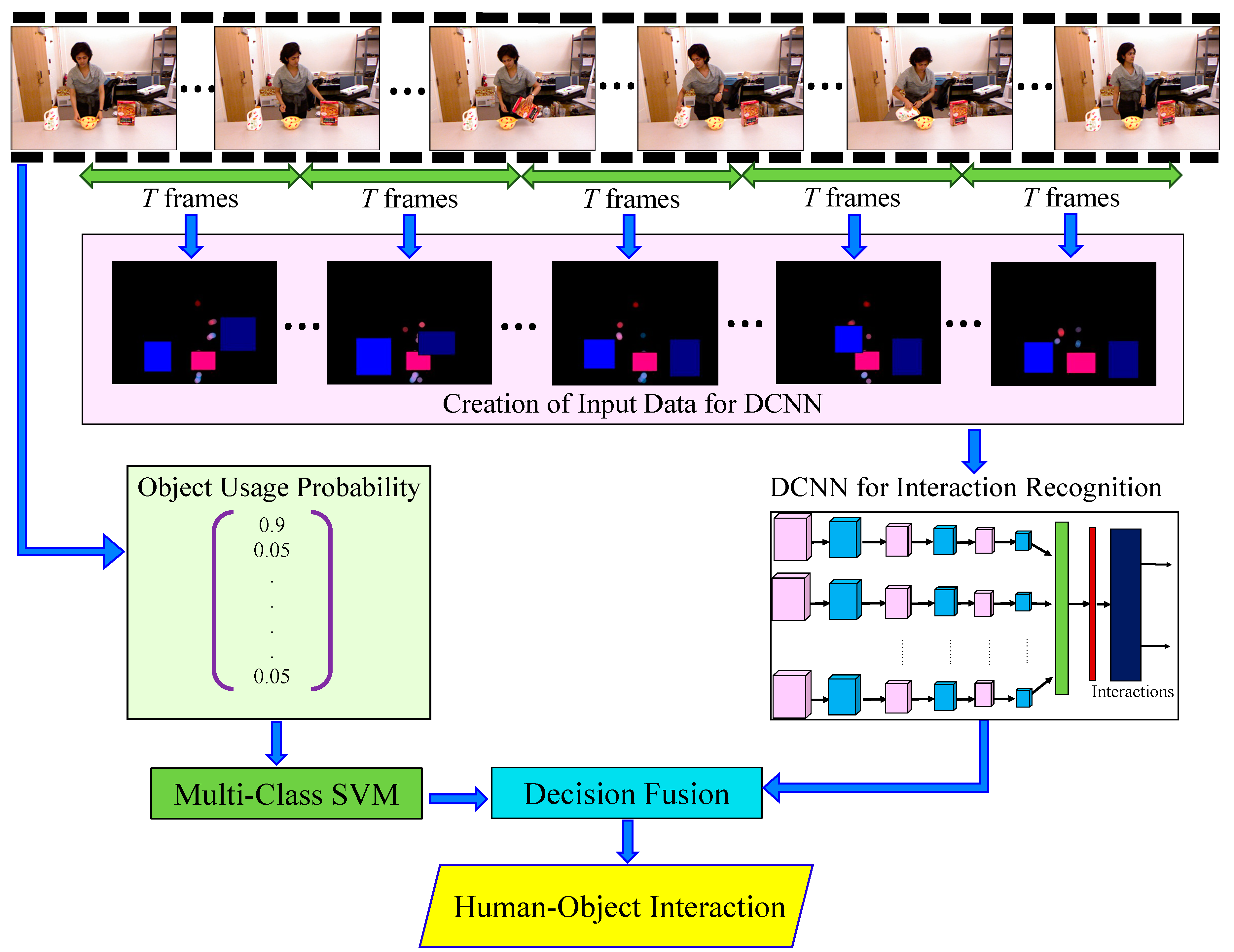
3. Proposed System
- Recognition of human–object interactions in which humans interact with different objects in order to complete desired tasks, such as making cereal or microwaving food.
- Creation of input data for a DCNN, which can accurately represent interactions between humans and objects.
- Calculation of object usage probability (OUP) and training OUP using a multi-class SVM to improve the performance of recognizing the human–object interactions.
- Fusing the result of DCNN and multi-class SVM (decision fusion) for generating better and more accurate results.
3.1. Input Data Acquisition
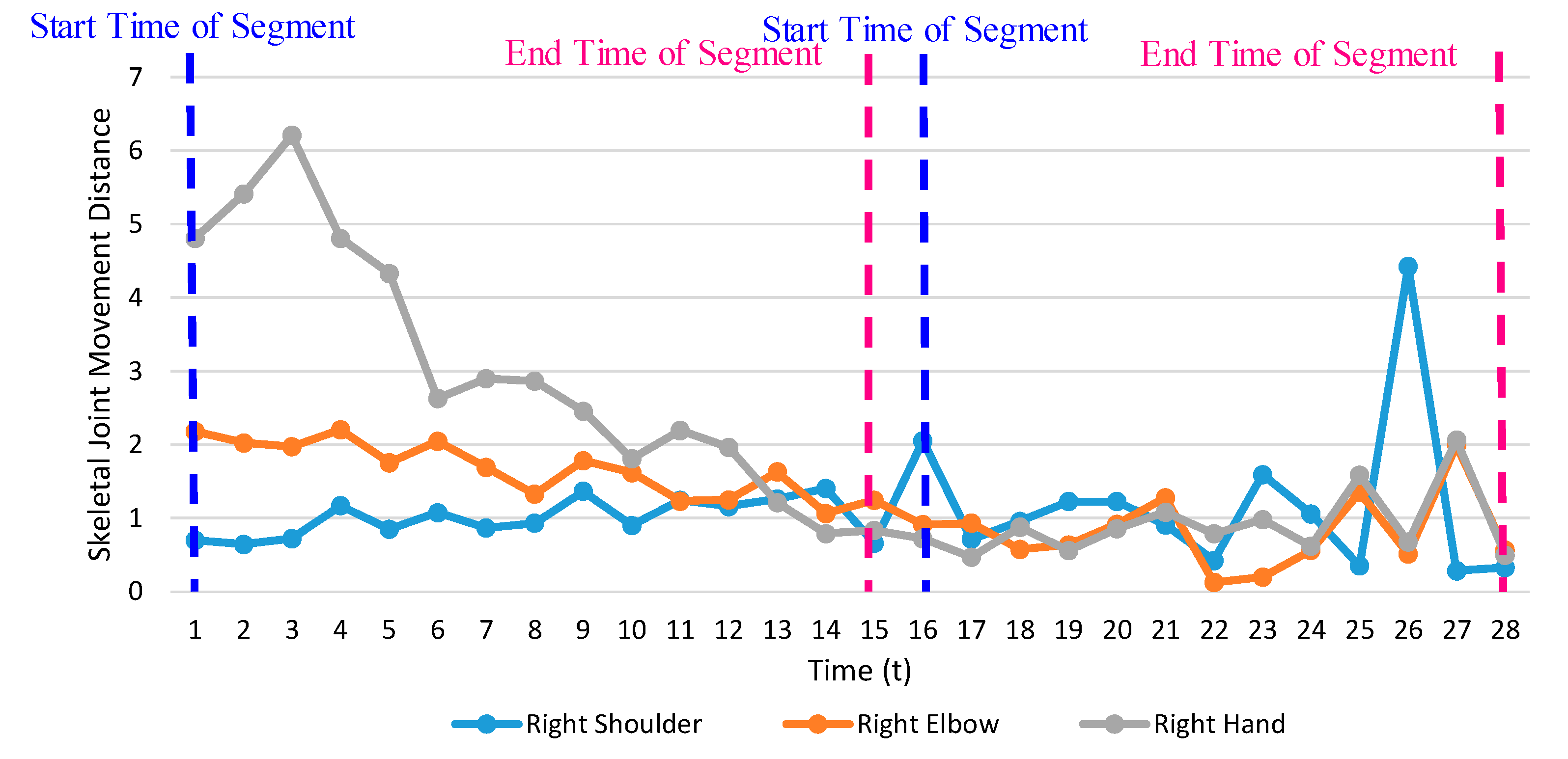
3.2. Temporal Segmentation
3.3. Creation of Input Data for a Deep Convolutional Neural Network
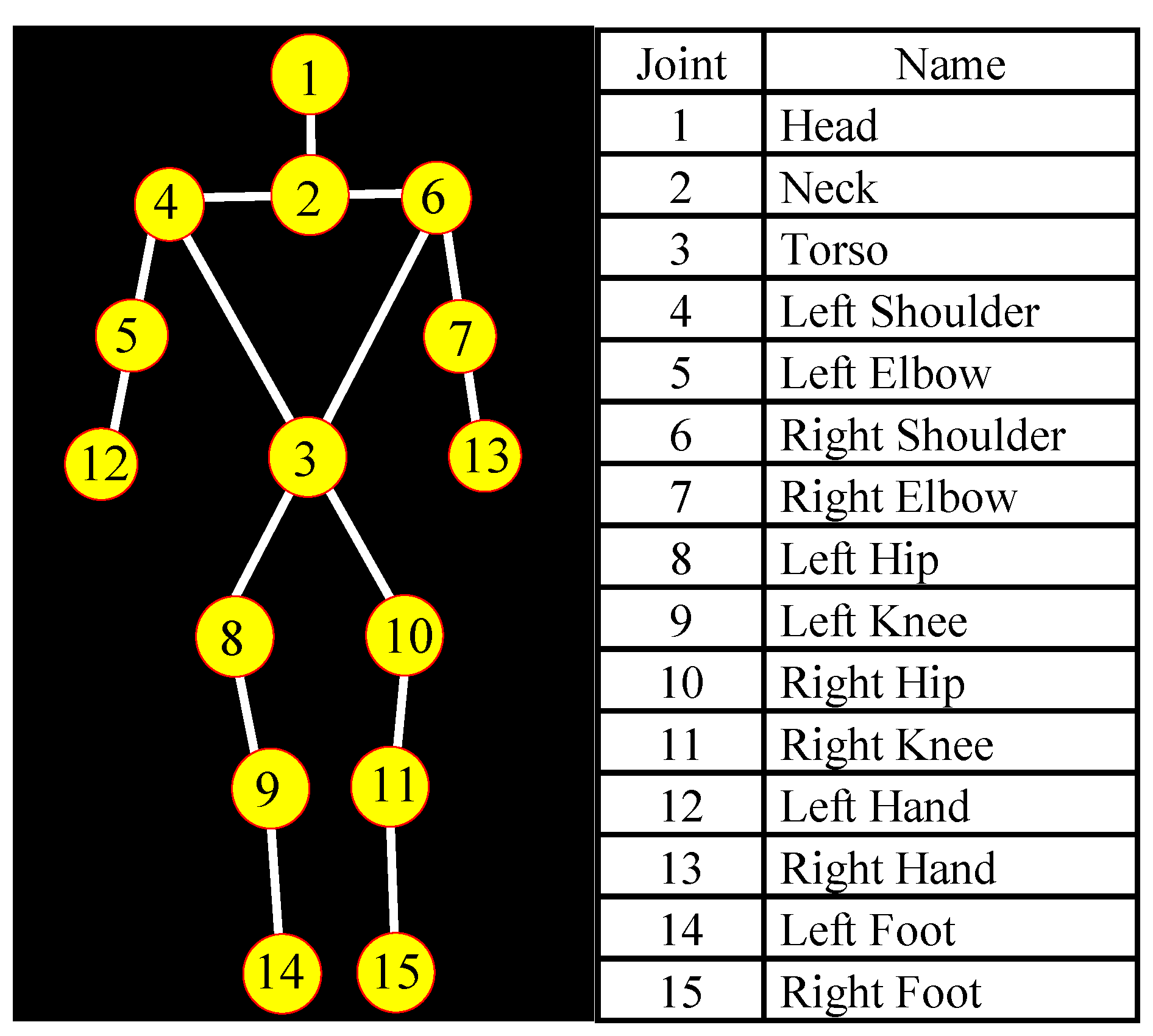
3.3.1. Extraction of Skeletal Joint Movement Features
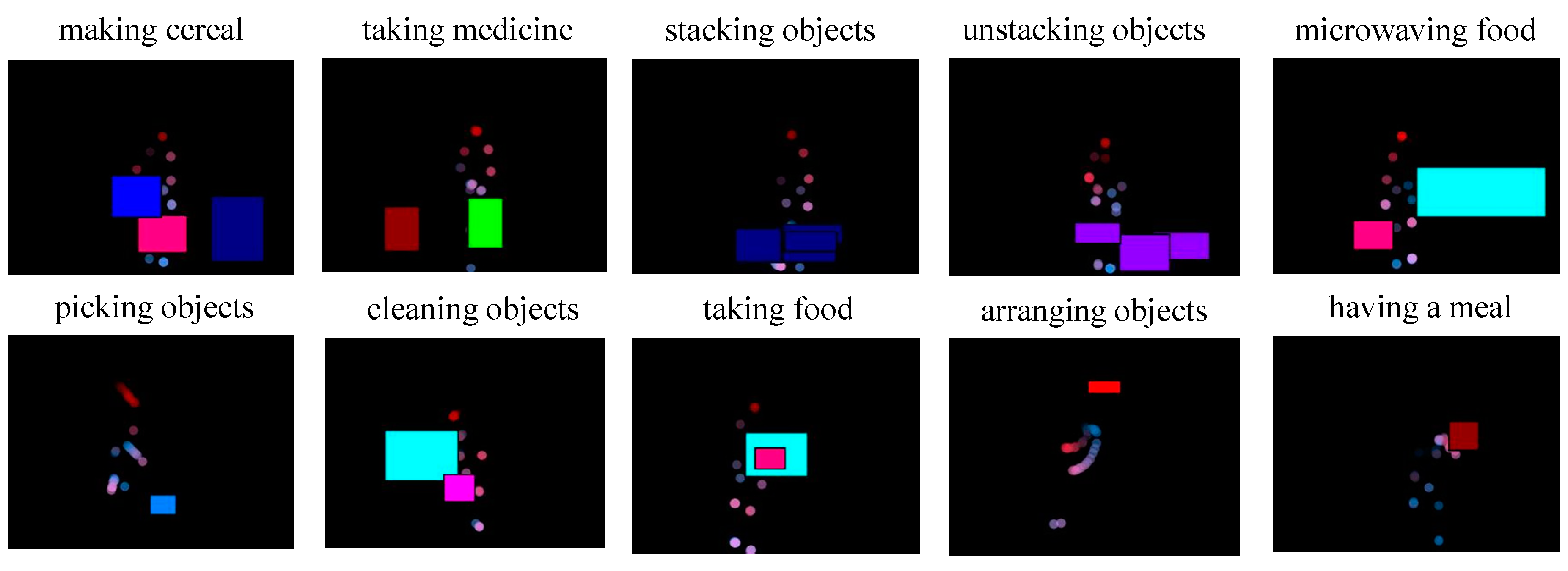
3.3.2. Creation of an Object Representation Image
3.4. Interaction Recognition using a Deep Convolutional Neural Network (DCNN)
3.5. Extracting the Object Usage Probability
3.6. Training and Recognizing Interactions Based on OUP Using a Multi-Class Support Vector Machine
3.7. Decision Fusion and Human–Objects Interaction Recognition
4. Experimental Results
5. Conclusions
6. Discussion and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Microsoft Kinect. 2013. Available online: https://developer.microsoft.com/en-us/windows/kinect (accessed on 1 June 2017).
- ASUS Xtion PRO LIVE. 2013. Available online: https://www.asus.com/3D-Sensor/Xtion_PRO/ (accessed on 28 October 2017).
- Cornell Activity Dataset. Available online: http://pr.cs.cornell.edu/humanactivities/data.php (accessed on 1 March 2018).
- Dutta, V.; Zielinska, T. Predicting Human Actions Taking into Account Object Affordances. J. Intell. Robot. Syst. 2018, 93, 745–761. [Google Scholar] [CrossRef]
- Koppula, H.S.; Saxena, A. Anticipating human activities using object affordances for reactive robotic response. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 14–29. [Google Scholar] [CrossRef] [PubMed]
- Qi, S.; Huang, S.; Wei, P.; Zhu, S.C. Predicting human activities using stochastic grammar. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1173–1181. [Google Scholar]
- Ren, S.; Sun, Y. Human-object-object-interaction affordance. In Proceedings of the 2013 IEEE Workshop on Robot Vision (WORV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 1–6. [Google Scholar]
- Kim, S.; Kavuri, S.; Lee, M. Intention recognition and object recommendation system using deep auto-encoder based affordance model. In Proceedings of the 1st International Conference on Human-Agent Interaction, II-1-2, Sapporo, Japan, 7–9 August 2013; pp. 1–6. [Google Scholar]
- Koppula, H.S.; Gupta, R.; Saxena, A. Learning human activities and object affordances from rgb-d videos. Int. J. Robot. Res. 2013, 32, 951–970. [Google Scholar] [CrossRef]
- Koppula, H.; Saxena, A. Learning spatio-temporal structure from rgb-d videos for human activity detection and anticipation. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 792–800. [Google Scholar]
- Selmi, M.; El-Yacoubi, M.A. Multimodal sequential modeling and recognition of human activities. In Proceedings of the International Conference on Computers Helping People with Special Needs, Linz, Austria, 13–15 July 2016; pp. 541–548. [Google Scholar]
- Sun, S.W.; Mou, T.C.; Fang, C.C.; Chang, P.C.; Hua, K.L.; Shih, H.C. Baseball Player Behavior Classification System Using Long Short-Term Memory with Multimodal Features. Sensors 2019, 19, 1425. [Google Scholar] [CrossRef] [PubMed]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In Proceedings of the International Workshop on Human Behavior Understanding, Amsterdam, The Netherlands, 16 November 2011; pp. 29–39. [Google Scholar]
- Liu, Z.; Zhang, C.; Tian, Y. 3D-based deep convolutional neural network for action recognition with depth sequences. Image Vis. Comput. 2016, 55, 93–100. [Google Scholar] [CrossRef]
- Phyo, C.N.; Zin, T.T.; Tin, P. Skeleton motion history based human action recognition using deep learning. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronic (GCCE 2017), Nagoya, Japan, 24–27 October 2017; pp. 784–785. [Google Scholar]
- Phyo, C.N.; Zin, T.T.; Tin, P. Deep Learning for Recognizing Human Activities using Motions of Skeletal Joints. IEEE Trans. Consum. Electron. 2019, 65, 243–252. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Caffe. Available online: http://caffe.berkeleyvision.org (accessed on 16 December 2017).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time (i) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | - |
| R value | 18 | 36 | 55 | 73 | 91 | 109 | 128 | 146 | 164 | 182 | 200 | 219 | 237 | 255 | - |
| Joint (j) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| G value | 17 | 34 | 51 | 68 | 85 | 102 | 119 | 136 | 153 | 170 | 187 | 204 | 221 | 238 | 255 |
| freqj | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | - |
| B value | 18 | 36 | 55 | 73 | 91 | 109 | 128 | 146 | 164 | 182 | 200 | 219 | 237 | 255 | - |
| Joint (j) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dist1,j | 0.55 | 0.69 | 0.73 | 0.7 | 0.89 | 0.7 | 2.18 | 0.74 | 0.74 | 0.77 | 1.1 | 0.09 | 4.81 | 0.72 | 1.22 |
| Dist2,j | 0.59 | 0.64 | 0.62 | 0.62 | 0.57 | 0.65 | 2.02 | 0.63 | 0.63 | 0.66 | 1.03 | 1.89 | 5.41 | 0.64 | 1.2 |
| Dist3,j | 0.97 | 0.77 | 0.69 | 0.83 | 0.67 | 0.72 | 1.97 | 0.56 | 32.6 | 0.67 | 1.04 | 1.25 | 6.21 | 52.8 | 1.22 |
| Dist4,j | 1.1 | 1 | 0.91 | 0.86 | 5.93 | 1.17 | 2.2 | 0.78 | 10.6 | 1.11 | 1.28 | 7.11 | 4.81 | 20.5 | 1.44 |
| Dist5,j | 0.86 | 0.85 | 0.79 | 0.89 | 4.65 | 0.85 | 1.75 | 0.76 | 5.74 | 0.7 | 0.98 | 4.73 | 4.33 | 6.48 | 1.21 |
| Dist6,j | 0.78 | 1.11 | 1.31 | 1.15 | 2.24 | 1.08 | 2.05 | 1.05 | 9.81 | 2.06 | 2.33 | 2.14 | 2.63 | 12.7 | 2.58 |
| Dist7,j | 0.81 | 0.89 | 1.17 | 0.95 | 1.46 | 0.87 | 1.69 | 1.43 | 2.1 | 1.47 | 1.74 | 1.52 | 2.9 | 2.16 | 1.97 |
| Dist8,j | 0.95 | 0.9 | 0.98 | 0.84 | 1.55 | 0.93 | 1.33 | 1.27 | 8.22 | 0.99 | 1.13 | 0.61 | 2.87 | 8.22 | 1.31 |
| Dist9,j | 1.45 | 1.37 | 1.38 | 1.32 | 1.34 | 1.37 | 1.78 | 1.48 | 3.79 | 1.32 | 1.39 | 0.96 | 2.46 | 3.85 | 1.5 |
| Dist10,j | 0.94 | 0.81 | 0.7 | 0.81 | 2 | 0.9 | 1.62 | 0.63 | 3.33 | 0.65 | 0.76 | 1.96 | 1.81 | 3.33 | 0.93 |
| Dist11,j | 1.09 | 0.88 | 0.73 | 0.62 | 2.02 | 1.24 | 1.23 | 0.41 | 2.64 | 1.01 | 1 | 2.14 | 2.19 | 2.7 | 1.05 |
| Dist12,j | 0.93 | 0.74 | 0.58 | 0.58 | 2.69 | 1.16 | 1.25 | 0.31 | 18.1 | 1.08 | 1.06 | 3.19 | 1.96 | 18 | 1.07 |
| Dist13,j | 1.26 | 1 | 0.67 | 0.91 | 2.22 | 1.26 | 1.63 | 0.14 | 7.84 | 0.69 | 0.74 | 2.66 | 1.21 | 7.85 | 0.81 |
| Dist14,j | 1.47 | 1.23 | 0.82 | 1.21 | 1.06 | 1.41 | 1.07 | 0.32 | 5.25 | 0.83 | 0.84 | 1.7 | 0.79 | 5.22 | 0.95 |
| mj | 0.98 | 0.92 | 0.86 | 0.88 | 2.09 | 1.02 | 1.7 | 0.75 | 7.96 | 1 | 1.17 | 2.28 | 3.17 | 10.4 | 1.32 |
| sdj | 0.28 | 0.21 | 0.26 | 0.22 | 1.52 | 0.25 | 0.37 | 0.42 | 8.5 | 0.4 | 0.42 | 1.8 | 1.66 | 13.7 | 0.46 |
| mj + (sdj*0.5) | 1.12 | 1.02 | 0.99 | 0.99 | 2.85 | 1.15 | 1.88 | 0.96 | 12.2 | 1.2 | 1.38 | 3.18 | 4 | 17.2 | 1.55 |
| freqj | 3 | 3 | 3 | 3 | 2 | 6 | 5 | 4 | 2 | 3 | 3 | 3 | 5 | 3 | 2 |
| Objects | R | G | B | Color | Objects | R | G | B | Color |
|---|---|---|---|---|---|---|---|---|---|
| medicine box | 0 | 255 | 0 | cloth | 255 | 0 | 255 | ||
| microwave | 0 | 255 | 255 | bowl | 255 | 0 | 128 | ||
| remote control | 0 | 128 | 255 | book | 255 | 0 | 0 | ||
| milk | 0 | 0 | 255 | cup | 128 | 0 | 0 | ||
| plate | 128 | 0 | 255 | box | 0 | 0 | 128 |
| Medicine Box | Microwave | Remote Control | Milk | Plate | Cloth | Bowl | Book | Cup | Box | Null | Total Frames (TF) | Interaction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k | Description | ||||||||||||
| 0 | 0 | 0 | 137 | 0 | 0 | 87 | 0 | 0 | 254 | 42 | 520 | 1 | making cereal |
| 177 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 131 | 0 | 163 | 471 | 2 | taking medicine |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 436 | 113 | 549 | 3 | stacking objects |
| 0 | 0 | 0 | 0 | 376 | 0 | 0 | 0 | 0 | 0 | 113 | 489 | 4 | unstacking objects |
| 0 | 315 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 248 | 85 | 648 | 5 | microwaving food |
| 0 | 0 | 0 | 0 | 0 | 0 | 113 | 0 | 0 | 0 | 46 | 159 | 6 | bending |
| 0 | 235 | 0 | 0 | 0 | 247 | 0 | 0 | 0 | 0 | 111 | 593 | 7 | cleaning objects |
| 0 | 179 | 0 | 0 | 0 | 0 | 0 | 0 | 110 | 0 | 115 | 404 | 8 | taking food |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 252 | 110 | 362 | 9 | arranging objects |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 193 | 0 | 306 | 499 | 10 | having breakfast |
| Medicine Box | Microwave | Remote Control | Milk | Plate | Cloth | Bowl | Book | Cup | Box | Null | Interaction |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.26 | 0 | 0 | 0.17 | 0 | 0 | 0.49 | 0.08 | making cereal |
| 0.38 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.28 | 0 | 0.35 | taking medicine |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.79 | 0.21 | stacking objects |
| 0 | 0 | 0 | 0 | 0.77 | 0 | 0 | 0 | 0 | 0 | 0.23 | unstacking objects |
| 0 | 0.49 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.38 | 0.13 | microwaving food |
| 0 | 0 | 0 | 0 | 0 | 0 | 0.71 | 0 | 0 | 0 | 0.29 | bending |
| 0 | 0.4 | 0 | 0 | 0 | 0.42 | 0 | 0 | 0 | 0 | 0.19 | cleaning objects |
| 0 | 0.44 | 0 | 0 | 0 | 0 | 0 | 0 | 0.27 | 0 | 0.28 | taking food |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.7 | 0.3 | arranging objects |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.39 | 0 | 0.61 | having breakfast |
| Recognized Actions | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Making Cereal | Taking Medicine | Stacking objects | Unstacking Objects | Microwaving Food | Picking Objects | Cleaning Objects | Taking Food | Arranging Objects | Having a Meal | ||
| Actual Actions | making cereal | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| taking medicine | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| stacking objects | 0 | 0 | 91.67 | 0 | 0 | 0 | 0 | 0 | 8.33 | 0 | |
| unstacking objects | 0 | 0 | 0 | 91.67 | 0 | 0 | 0 | 0 | 8.33 | 0 | |
| microwaving food | 0 | 0 | 0 | 0 | 91.67 | 0 | 0 | 8.33 | 0 | 0 | |
| picking objects | 0 | 0 | 0 | 0 | 0 | 83.33 | 0 | 0 | 8.33 | 8.33 | |
| cleaning objects | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| taking food | 0 | 0 | 0 | 0 | 8.33 | 8.33 | 0 | 83.33 | 0 | 0 | |
| arranging objects | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 91.67 | 0 | |
| having a meal | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phyo, C.N.; Zin, T.T.; Tin, P. Complex Human–Object Interactions Analyzer Using a DCNN and SVM Hybrid Approach. Appl. Sci. 2019, 9, 1869. https://doi.org/10.3390/app9091869
Phyo CN, Zin TT, Tin P. Complex Human–Object Interactions Analyzer Using a DCNN and SVM Hybrid Approach. Applied Sciences. 2019; 9(9):1869. https://doi.org/10.3390/app9091869
Chicago/Turabian StylePhyo, Cho Nilar, Thi Thi Zin, and Pyke Tin. 2019. "Complex Human–Object Interactions Analyzer Using a DCNN and SVM Hybrid Approach" Applied Sciences 9, no. 9: 1869. https://doi.org/10.3390/app9091869
APA StylePhyo, C. N., Zin, T. T., & Tin, P. (2019). Complex Human–Object Interactions Analyzer Using a DCNN and SVM Hybrid Approach. Applied Sciences, 9(9), 1869. https://doi.org/10.3390/app9091869