In-Ear EEG Based Attention State Classification Using Echo State Network

Abstract
:1. Introduction
2. Materials and Methods
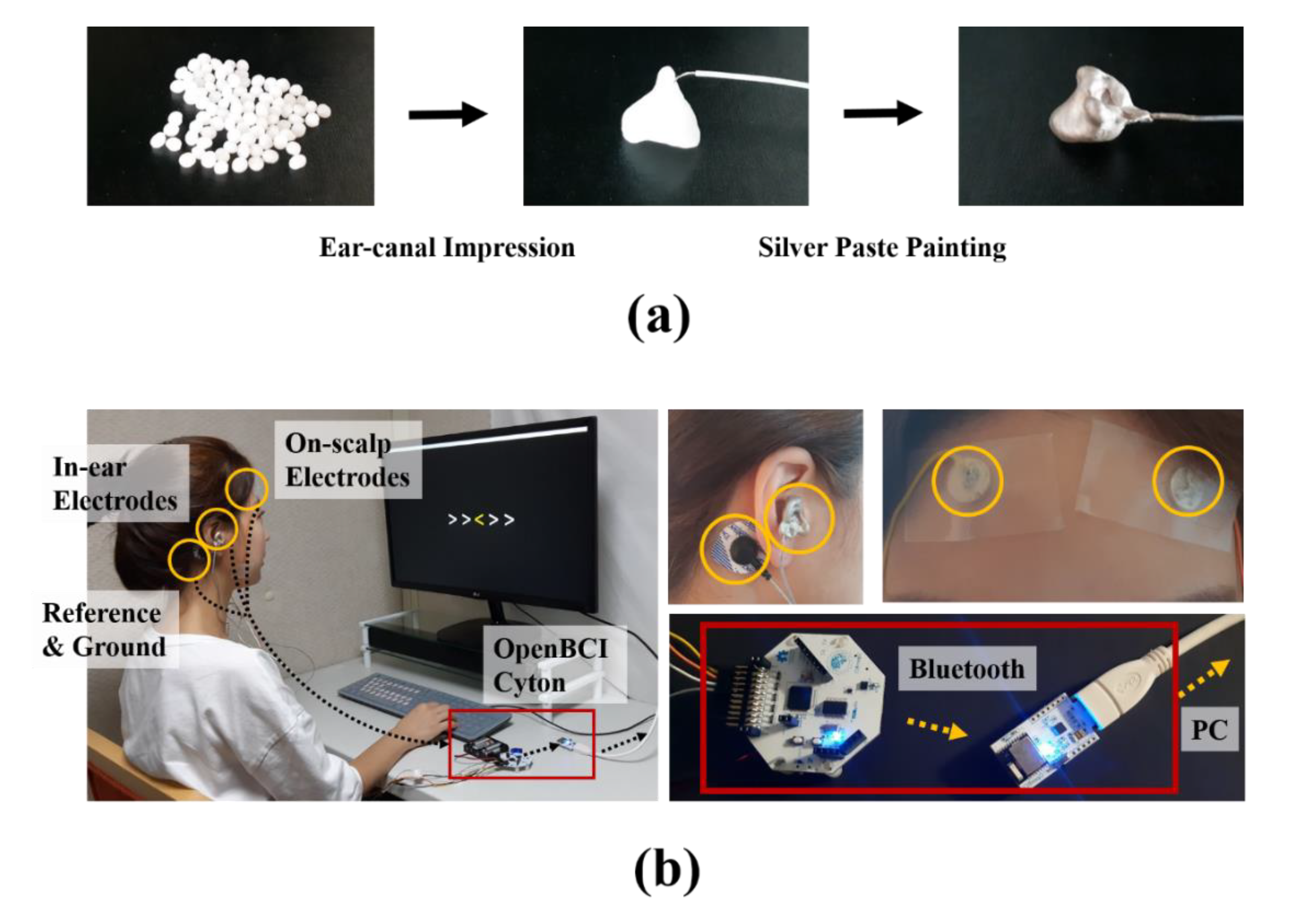
2.1. Data Acquisition
2.2. Participants
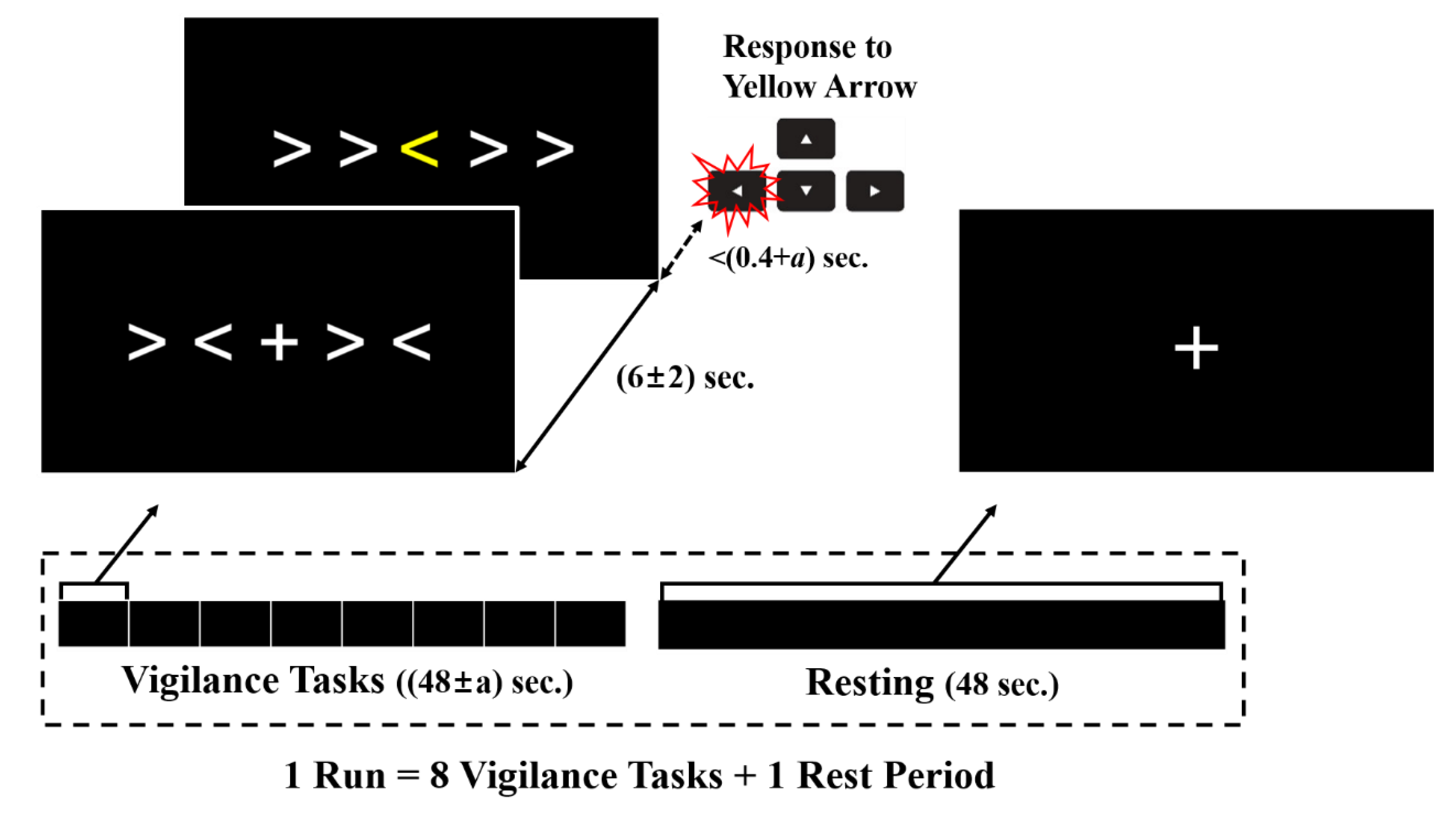
2.3. Experimental Stimuli and Protocol
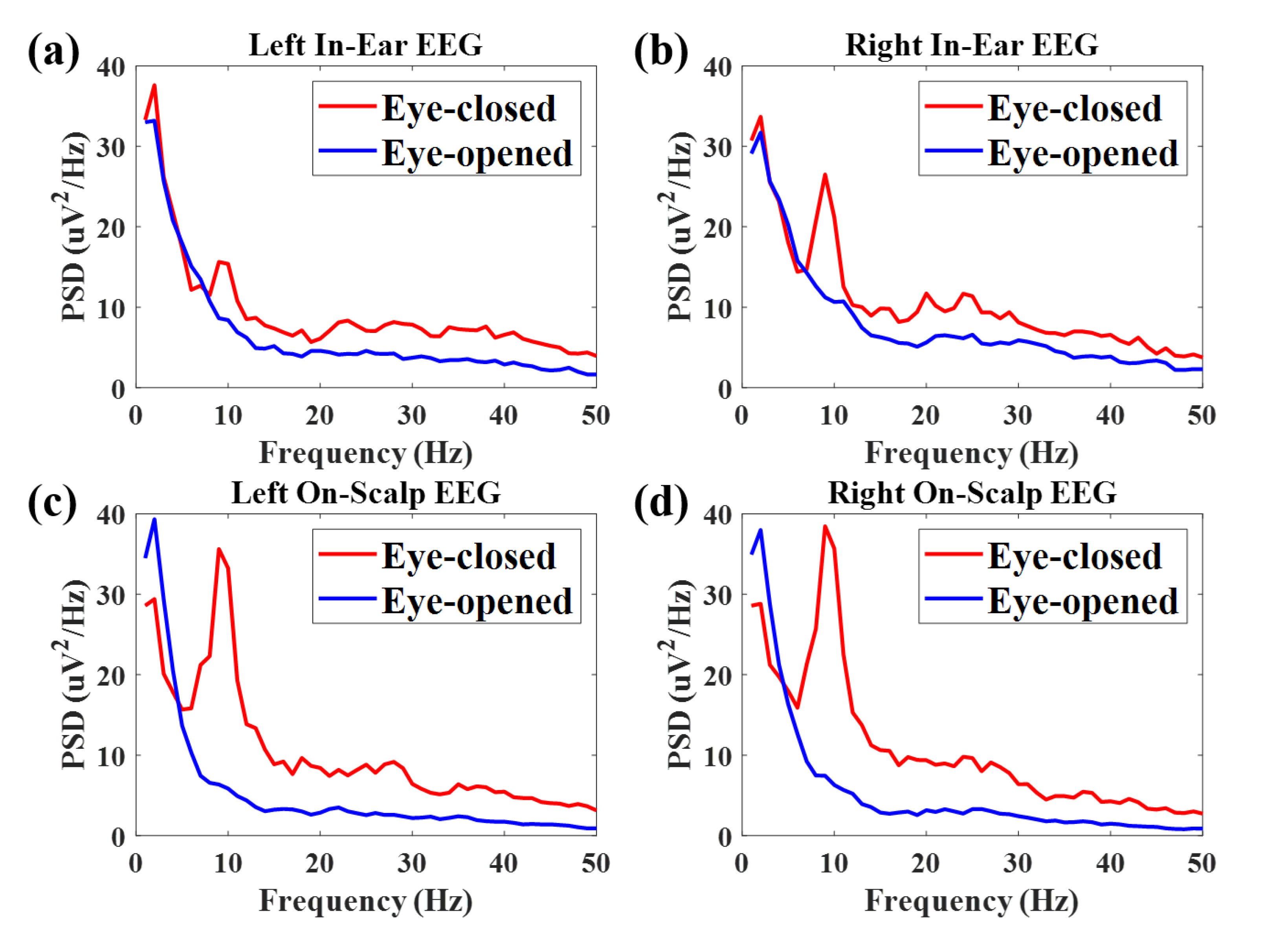
2.4. EEG Preprocessing and Feature Extraction
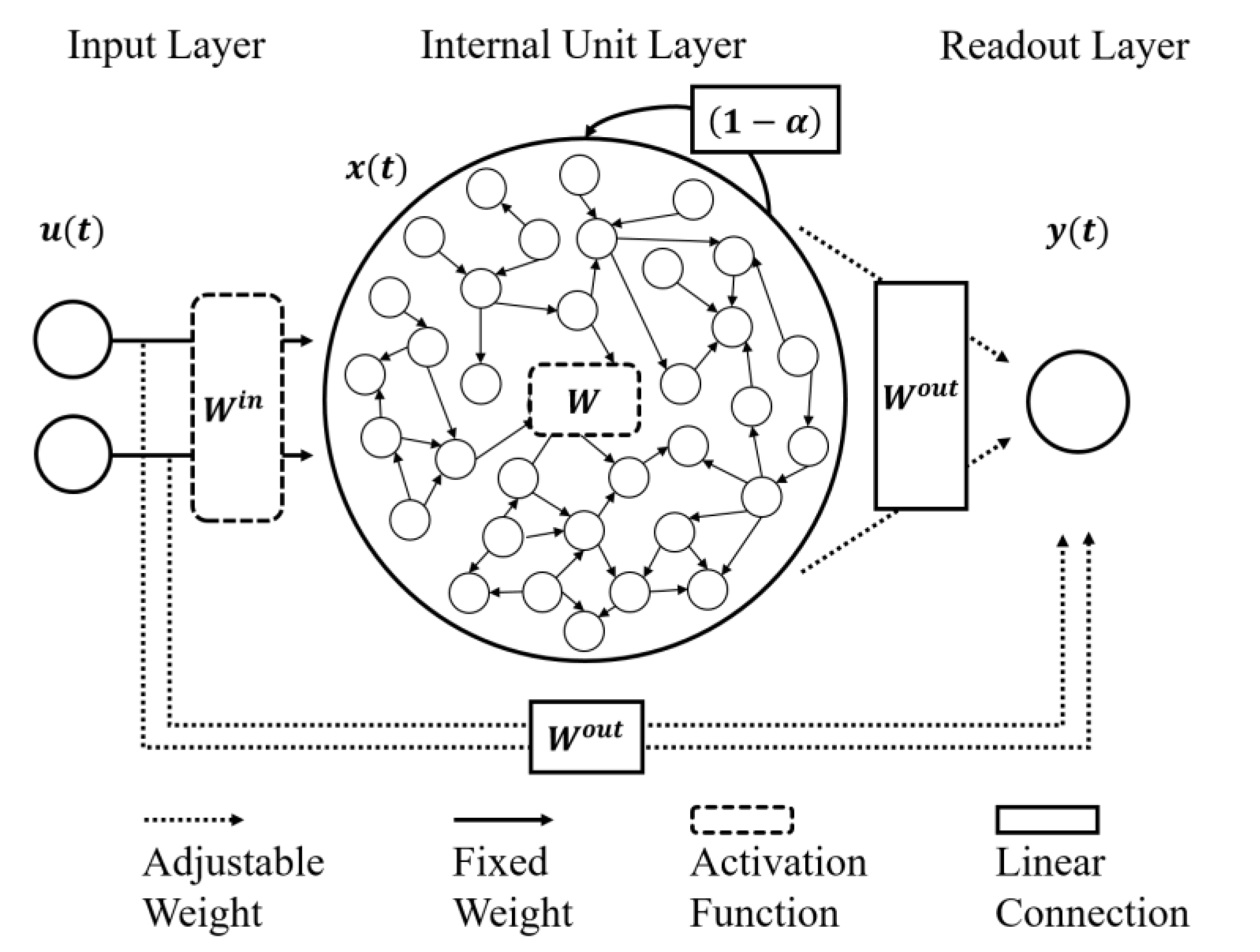
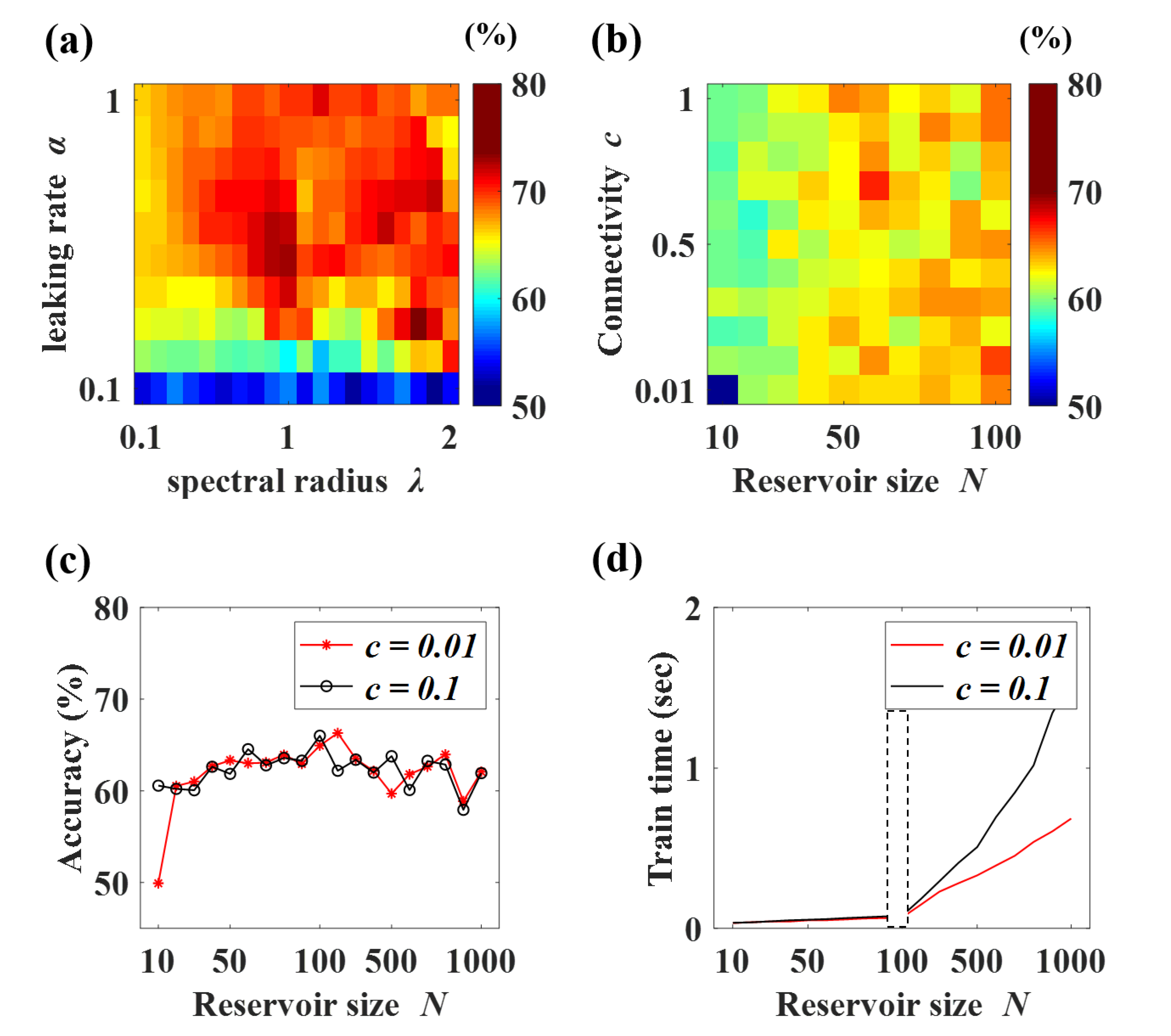
2.5. Echo State Network (ESN)
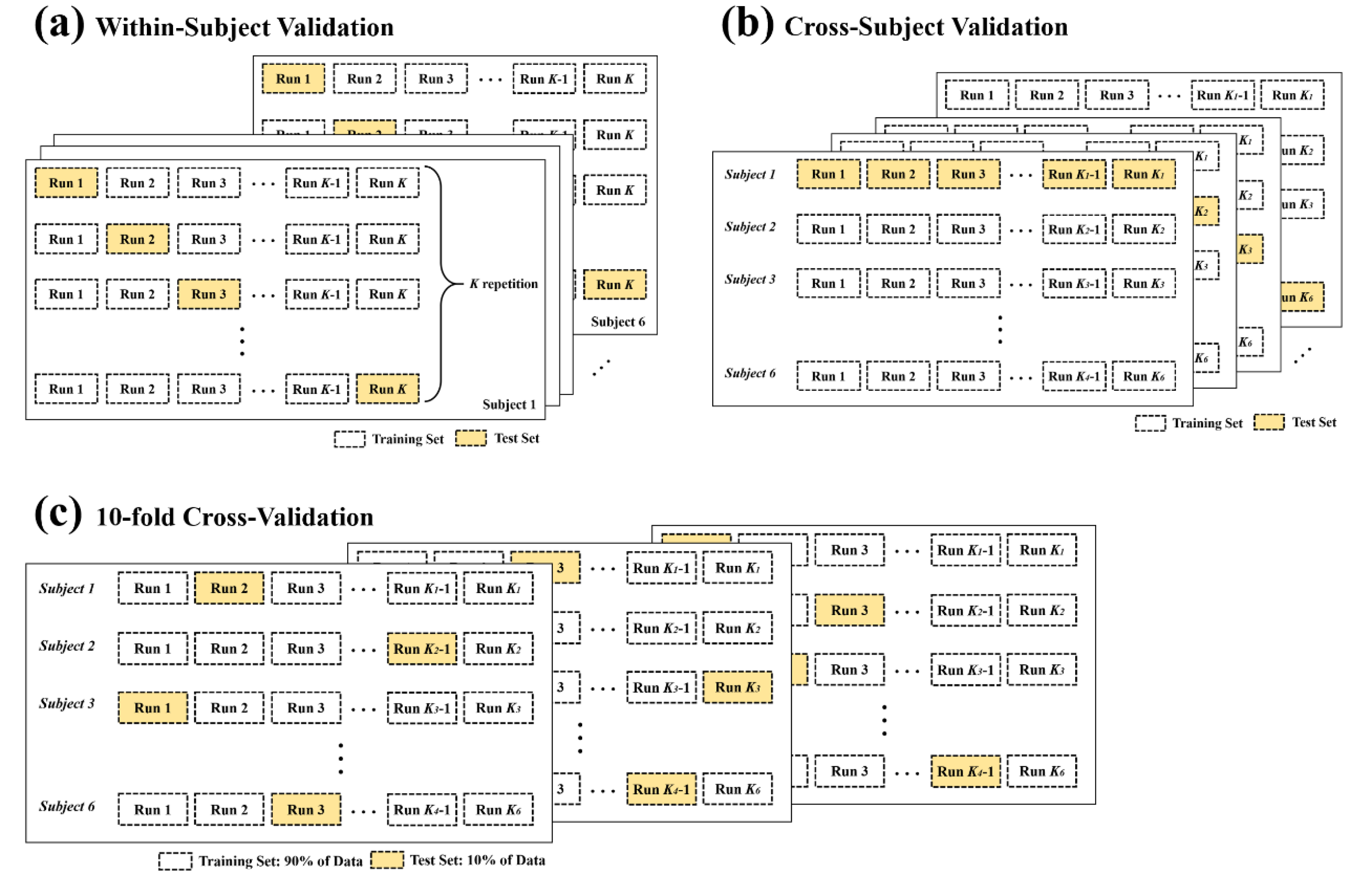
2.6. Data Separation and Evaluation
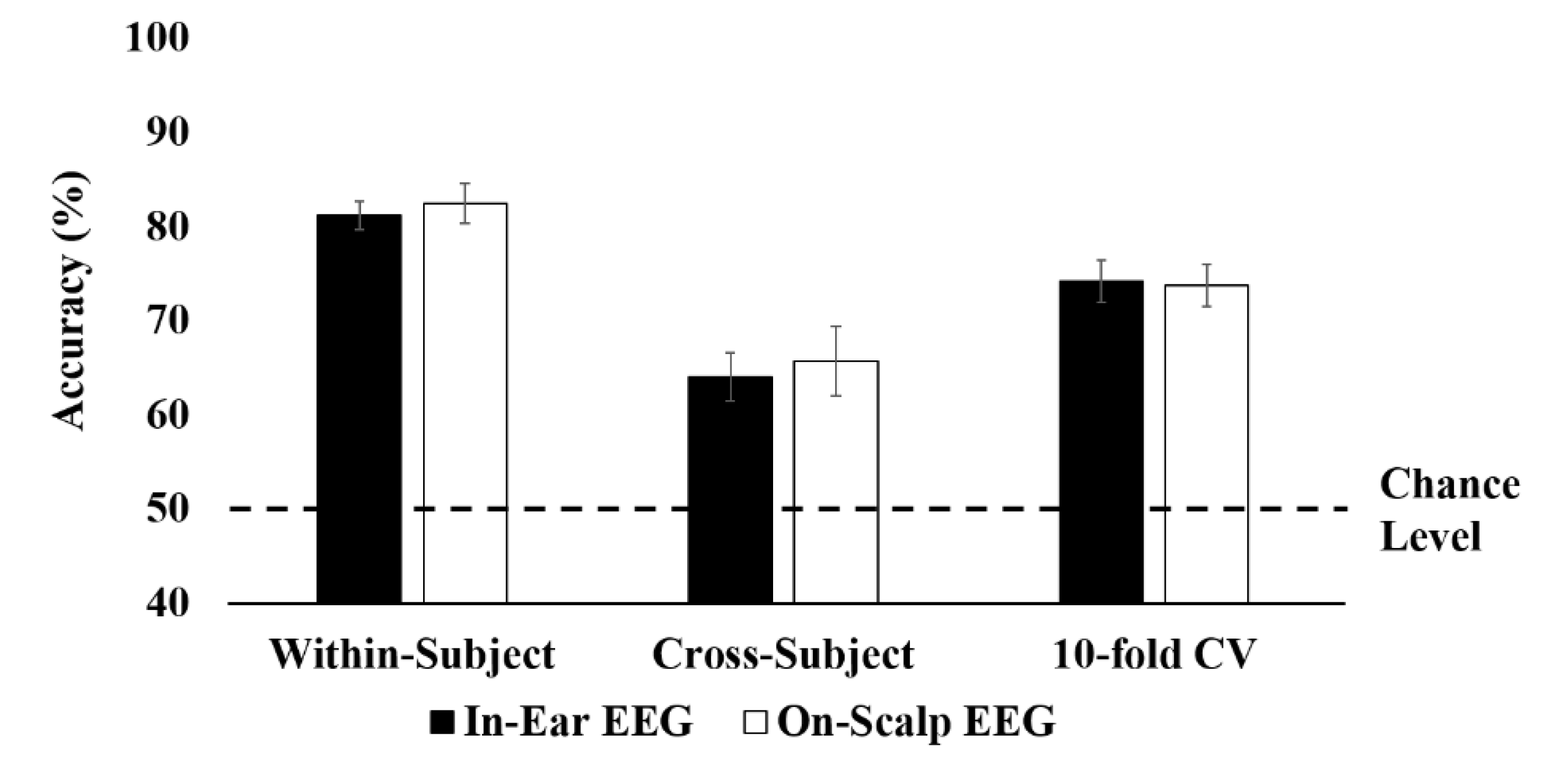
3. Results
3.1. Classification Results
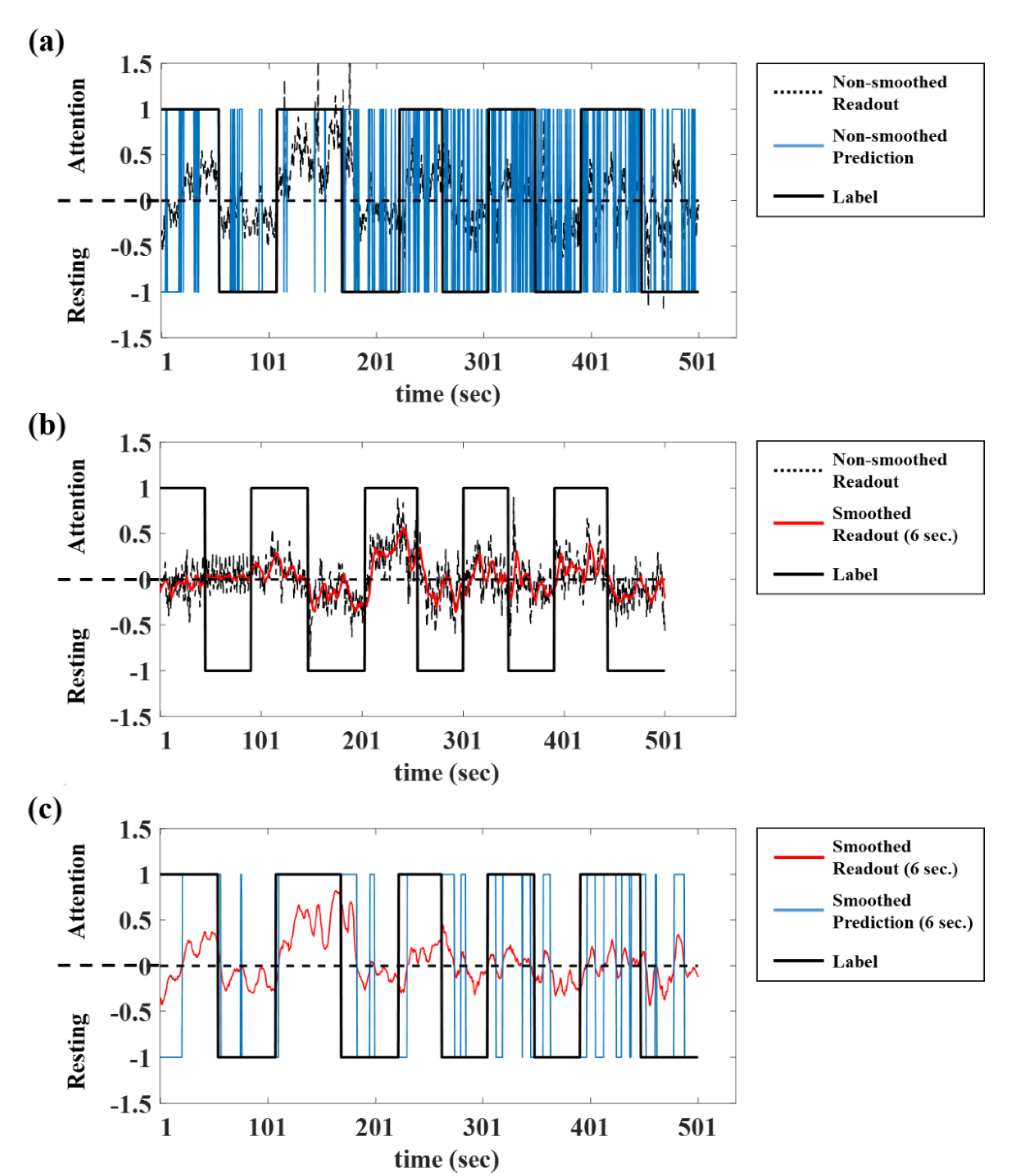
3.2. Smoothing
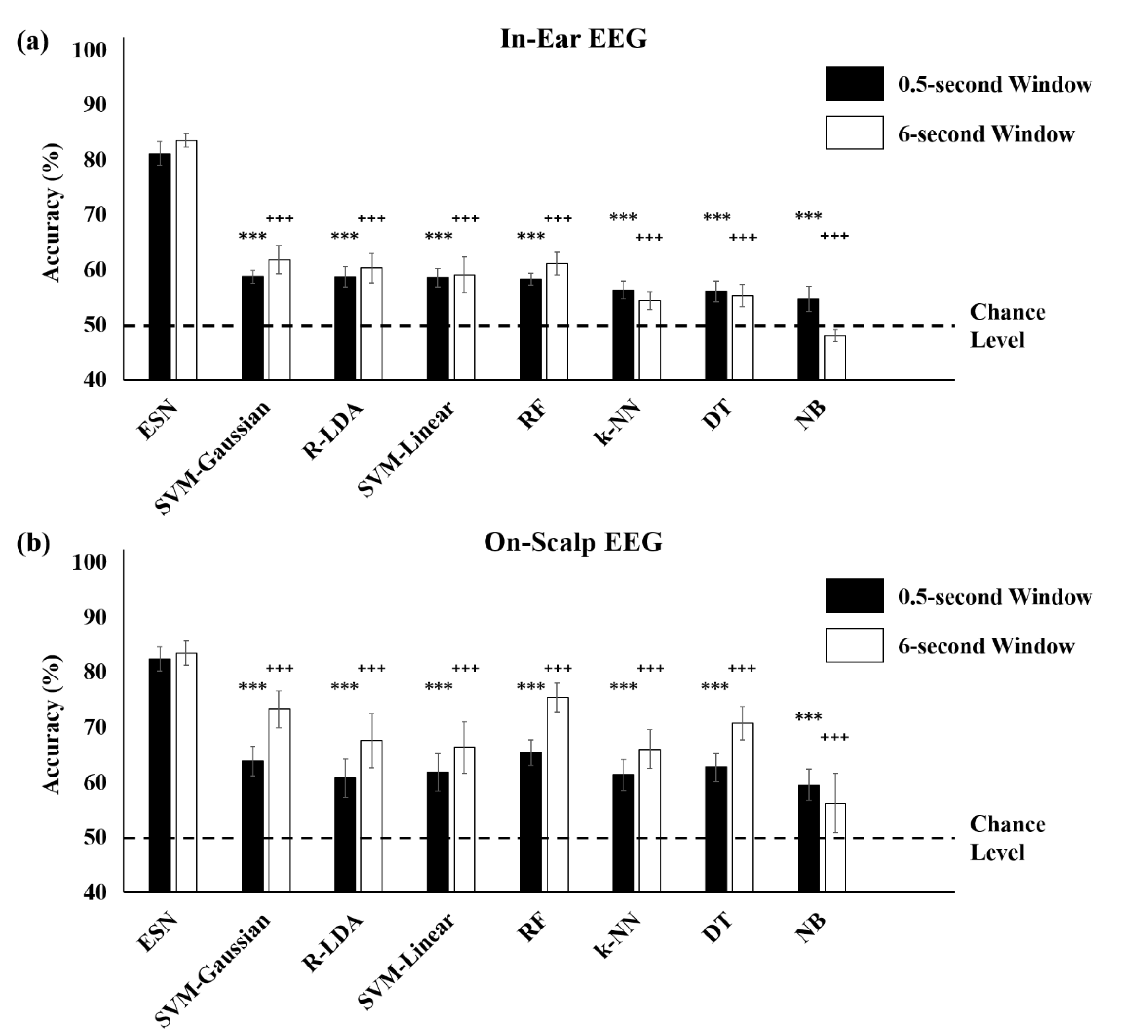
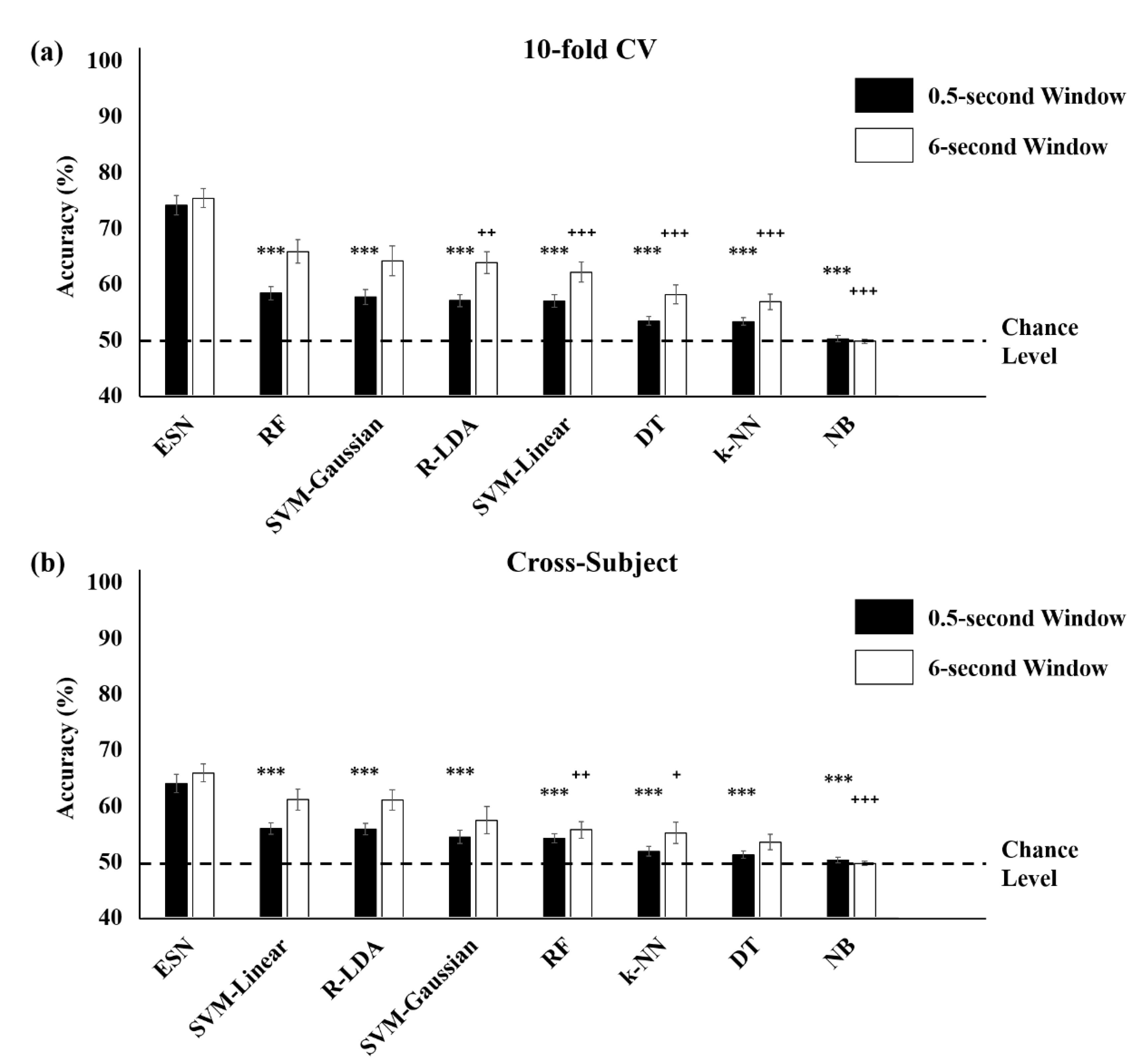
3.3. Comparison with Conventional Machine Learning Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

Appendix B
Appendix C

References
- Mackworth, N.H. The breakdown of vigilance during prolonged visual search. Q. J. Exp. Psychol. 1948, 1, 6–21. [Google Scholar] [CrossRef]
- Helton, W.S.; Hollander, T.D.; Warm, J.S.; Tripp, L.D.; Parsons, K.; Matthews, G.; Dember, W.N.; Parasuraman, R.; Hancock, P.A. The abbreviated vigilance task and cerebral hemodynamics. J. Clin. Exp. Neuropsychol. 2007, 29, 545–552. [Google Scholar] [CrossRef] [PubMed]
- Warm, J.S.; Matthews, G.; Finomore, V.S., Jr. Vigilance, Workload, and Stress. In Performance Under Stress; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Young, M.S.; Robinson, S.; Alberts, P. Students pay attention!: Combating the vigilance decrement to improve learning during lectures. Act. Learn. High. Educ. 2009, 10, 41–55. [Google Scholar] [CrossRef]
- Taylor-Phillips, S.; Elze, M.C.; Krupinski, E.A.; Dennick, K.; Gale, A.G.; Clarke, A.; Mello-Thoms, C. Retrospective Review of the Drop in Observer Detection Performance Over Time in Lesion-enriched Experimental Studies. J. Digit. Imaging 2014, 28, 32–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Atchley, P.; Chan, M. Potential benefits and costs of concurrent task engagement to maintain vigilance: A driving simulator investigation. Hum. Factors 2011, 53, 3–12. [Google Scholar] [CrossRef] [Green Version]
- Kamzanova, A.T.; Kustubayeva, A.M.; Matthews, G. Use of EEG workload indices for diagnostic monitoring of vigilance decrement. Hum. Factors 2014, 56, 1136–1149. [Google Scholar] [CrossRef]
- Clayton, M.S.; Yeung, N.; Cohen Kadosh, R. The roles of cortical oscillations in sustained attention. Trends Cogn. Sci. 2015, 19, 188–195. [Google Scholar] [CrossRef]
- Looney, B.D.; Kidmose, P.; Park, C.; Ungstrup, M.; Rank, M.L.; Rosenkranz, K. The in-the-ear recording concept: User-centered and wearable brain monitoring. IEEE Pulse 2012, 3, 32–42. [Google Scholar] [CrossRef]
- Hoon Lee, J.; Min Lee, S.; Jin Byeon, H.; Sook Hong, J.; Suk Park, K.; Lee, S.-H. CNT/PDMS-based canal-typed ear electrodes for inconspicuous EEG recording. J. Neural Eng. 2014, 11, 046014. [Google Scholar] [CrossRef]
- Bleichner, M.G.; Lundbeck, M.; Selisky, M.; Minow, F.; Jäger, M.; Emkes, R.; Debener, S.; De Vos, M. Exploring miniaturized EEG electrodes for brain–computer interfaces. An EEG you do not see? Physiol. Rep. 2015, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Mikkelsen, K.B.; Kappel, S.L.; Mandic, D.P.; Kidmose, P. EEG recorded from the ear: Characterizing the Ear-EEG Method. Front. Neurosci. 2015, 9, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goverdovsky, V.; Looney, D.; Kidmose, P.; Mandic, D.P. In-Ear EEG from Viscoelastic Generic Earpieces: Robust and Unobtrusive 24/7 Monitoring. IEEE Sens. J. 2016, 16, 271–277. [Google Scholar] [CrossRef]
- Mikkelsen, K.B.; Kidmose, P.; Hansen, L.K. On the Keyhole Hypothesis: High Mutual Information between Ear and Scalp EEG. Front. Hum. Neurosci. 2017, 11, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kappel, S.L.; Looney, D.; Mandic, D.P.; Kidmose, P. Physiological artifacts in scalp EEG and ear-EEG. Biomed. Eng. Online 2017, 16, 103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kappel, S.L.; Rank, M.L.; Toft, H.O.; Andersen, M.; Kidmose, P. Dry-Contact Electrode Ear-EEG. IEEE Trans. Biomed. Eng. 2019, 66, 150–158. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.W.; Ku, Y.; Kim, D.Y.; Sohn, J.; Kim, J.-H.; Kim, H.C. Wearable in-the-ear EEG system for SSVEP-based brain–computer interface. Electron. Lett. 2018, 54, 413–414. [Google Scholar] [CrossRef]
- Zibrandtsen, I.; Kidmose, P.; Otto, M.; Ibsen, J.; Kjaer, T.W. Case comparison of sleep features from ear-EEG and scalp-EEG. Sleep Sci. 2016, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Mikkelsen, K.B.; Villadsen, D.B.; Otto, M.; Kidmose, P. Automatic sleep staging using ear-EEG. Biomed. Eng. Online 2017, 16, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Nakamura, T.; Goverdovsky, V.; Morrell, M.J.; Mandic, D.P.; Mandic, D.P. Point-of-Care Technologies Automatic Sleep Monitoring Using Ear-EEG. IEEE J. Transl. Eng. Health Med. 2017, 5, 1–8. [Google Scholar] [CrossRef]
- Fiedler, L.; Wöstmann, M.; Graversen, C.; Brandmeyer, A.; Lunner, T.; Obleser, J. Single-channel in-ear-EEG detects the focus of auditory attention to concurrent tone streams and mixed speech. J. Neural Eng. 2017, 14, 036020. [Google Scholar] [CrossRef] [Green Version]
- Denk, F.; Grzybowski, M.; Ernst, S.M.A.; Kollmeier, B.; Debener, S.; Bleichner, M.G. Event-Related Potentials Measured From In and Around the Ear Electrodes Integrated in a Live Hearing Device for Monitoring Sound Perception. Trends Hear. 2018, 22, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christensen, C.B.; Kappel, S.L.; Kidmose, P. Auditory Steady-State Responses across Chirp Repetition Rates for Ear-EEG and Scalp EEG. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1376–1379. [Google Scholar]
- Hong, S.; Kwon, H.; Choi, S.H.; Park, K.S. Intelligent system for drowsiness recognition based on ear canal electroencephalography with photoplethysmography and electrocardiography. Inf. Sci. 2018, 453, 302–322. [Google Scholar] [CrossRef]
- Nakamura, T.; Alqurashi, Y.D.; Morrell, M.J.; Mandic, D.P. Automatic detection of drowsiness using in-ear EEG. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; 2018; 2018, pp. 1–6. [Google Scholar]
- Kuatsjah, E.; Zhang, X.; Khoshnam, M.; Menon, C. Two-channel in-ear EEG system for detection of visuomotor tracking state: A preliminary study. Med. Eng. Phys. 2019, 68, 25–34. [Google Scholar] [CrossRef] [PubMed]
- Athavipach, C.; Pan-Ngum, S.; Israsena, P. A wearable in-ear EEG device for emotion monitoring. Sensors 2019, 19, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Prater, A. Spatiotemporal signal classification via principal components of reservoir states. Neural Netw. 2017, 91, 66–75. [Google Scholar] [CrossRef]
- Gong, C.; Tao, D.; Chang, X.; Yang, J. Ensemble Teaching for Hybrid Label Propagation. IEEE Trans. Cybern. 2019, 49, 388–402. [Google Scholar] [CrossRef] [Green Version]
- Lacy, S.E.; Smith, S.L.; Lones, M.A. Using echo state networks for classification: A case study in Parkinson’s disease diagnosis. Artif. Intell. Med. 2018, 86, 53–59. [Google Scholar] [CrossRef]
- Yang, C.; Qiao, J.; Han, H.; Wang, L. Design of polynomial echo state networks for time series prediction. Neurocomputing 2018, 290, 148–160. [Google Scholar] [CrossRef]
- Sun, L.; Jin, B.; Yang, H.; Tong, J.; Liu, C.; Xiong, H. Unsupervised EEG feature extraction based on echo state network. Inf. Sci. 2019, 475, 1–17. [Google Scholar] [CrossRef]
- Bozhkov, L.; Koprinkova-Hristova, P.; Georgieva, P. Learning to decode human emotions with Echo State Networks. Neural Netw. 2016, 78, 112–119. [Google Scholar] [CrossRef] [PubMed]
- Bozhkov, L.; Koprinkova-Hristova, P.; Georgieva, P. Reservoir computing for emotion valence discrimination from EEG signals. Neurocomputing 2017, 231, 28–40. [Google Scholar] [CrossRef]
- Kim, H.H.; Jeong, J. Decoding electroencephalographic signals for direction in brain–computer interface using echo state network and Gaussian readouts. Comput. Biol. Med. 2019, 110, 254–264. [Google Scholar] [CrossRef]
- Dinges, D.F.; Powell, J.W. Microcomputer analyses of performance on sustained operations. Behav. Res. Methods 1985, 17, 652–655. [Google Scholar] [CrossRef]
- Eriksen, B.A.; Eriksen, C.W. Effects of noise letters upon the identification of a target letter in a nonsearch task. Percep. Psychophys. 1974, 16, 143–149. [Google Scholar] [CrossRef] [Green Version]
- Basner, M.; Dinges, D.F. Maximizing sensitivity of the Psychomotor Vigilance Test (PVT) to sleep loss. Sleep 2011, 34, 581–591. [Google Scholar] [CrossRef]
- Sprajcer, M.; Jay, S.M.; Vincent, G.E.; Vakulin, A.; Lack, L.; Ferguson, S.A. How the chance of missing the alarm during an on-call shift affects pre-bed anxiety, sleep and next day cognitive performance. Biol. Psychol. 2018, 137, 133–139. [Google Scholar] [CrossRef]
- Hedge, C.; Powell, G.; Sumner, P. The reliability paradox: Why robust cognitive tasks do not produce reliable individual differences. Behav. Res. Methods 2018, 50, 1166–1186. [Google Scholar] [CrossRef]
- Beaton, L.E.; Azma, S.; Marinkovic, K. When the brain changes its mind: Oscillatory dynamics of conflict processing and response switching in a flanker task during alcohol challenge. PLoS ONE 2018, 13, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Jaeger, H.; Haas, H. Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farkaš, I.; Bosák, R.; Gergeľ, P. Computational analysis of memory capacity in echo state networks. Neural Netw. 2016, 83, 109–120. [Google Scholar] [CrossRef] [PubMed]
- Oztuik, M.C.; Xu, D.; Principe, J.C. Analysis and design of echo state networks. Neural Comput. 2007, 19, 111–138. [Google Scholar] [CrossRef] [PubMed]
- Cui, H.; Liu, X.; Li, L. The architecture of dynamic reservoir in the echo state network. Chaos 2012, 22. [Google Scholar] [CrossRef] [PubMed]
- Inubushi, M.; Yoshimura, K. Reservoir Computing beyond Memory-Nonlinearity Trade-off. Sci. Rep. 2017, 7, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Dominey, P.F. Biological Cybernetics on recurrent state representation and reinforcement learning. J. Comp. Neurol. 1995, 274, 265–274. [Google Scholar]
- Dominey, P.F.; Hoen, M.; Blanc, J.M.; Lelekov-Boissard, T. Neurological basis of language and sequential cognition: Evidence from simulation, aphasia, and ERP studies. Brain Lang. 2003, 86, 207–225. [Google Scholar] [CrossRef] [Green Version]
- Dominey, P.F.; Hoen, M.; Inui, T. A neurolinguistic model of grammatical construction processing. J. Cogn. Neurosci. 2006, 18, 2088–2107. [Google Scholar] [CrossRef] [Green Version]
- Jaeger, H. The “Echo State” Approach to Analysing and Training Recurrent Neural Networks, GMD Report; GMD—German National Research Institute for Computer Science: Darmstadt, Germany, 2001; Volume 148. [Google Scholar]
- Jaeger, H.; Lukoševičius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky- integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef]
- Lukoševičius, M.; Jaeger, H. Reservoir computing approaches to recurrent neural network training. Comput. Sci. Rev. 2009, 3, 127–149. [Google Scholar] [CrossRef]
- Hermans, M.; Schrauwen, B. Memory in Reservoirs for High Dimensional Input. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–7. [Google Scholar]
- Verstraeten, D.; Schrauwen, B.; D’Haene, M.; Stroobandt, D. An experimental unification of reservoir computing methods. Neural Netw. 2007, 20, 391–403. [Google Scholar] [CrossRef] [PubMed]
- Gallicchio, C.; Micheli, A.; Pedrelli, L. Deep reservoir computing: A critical experimental analysis. Neurocomputing 2017, 268, 87–99. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of Ill-Posed Problems; Winston and Sons: Washington, DC, USA, 1977. [Google Scholar]
- Monastra, V.J.; Lynn, S.; Linden, M.; Lubar, J.F.; Gruzelier, J.; La Vaque, T.J. Electroencephalographic biofeedback in the treatment of attention-deficit/hyperactivity disorder. J. Neurother. 2006, 9, 5–34. [Google Scholar] [CrossRef] [Green Version]
- Schmeling, A.; Olze, A.; Reisinger, W.; König, M.; Geserick, G. Statistical analysis and verification of forensic age estimation of living persons in the Institute of Legal Medicine of the Berlin University Hospital Charité. Proces. Leng. Nat. 2003, 2, 3–5. [Google Scholar]
- Duchek, J.M.; Hunt, L.; Ball, K.; Buckles, V.; Morris, J.C. Attention and Driving Performance in Alzheimer’s Disease. J. Gerontol. Ser. B Psychol. Sci. Soc. Sci. 1998, 53, 130–141. [Google Scholar] [CrossRef] [Green Version]
- Rapp, M.A.; Reischies, F.M. Attention and executive control predict Alzheimer disease in late life: Results from the Berlin Aging Study (BASE). Am. J. Geriatr. Psychiatry 2005, 13, 134–141. [Google Scholar] [CrossRef]
- Pirzanski, C.; Berge, B. Ear canal dynamics: Facts versus perception. Hear. J. 2005, 58, 50–58. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Guo, Y.; Hastie, T.; Tibshirani, R. Regularized linear discriminant analysis and its application in microarrays. Biostatistics 2007, 8, 86–100. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Skurichina, M.; Duin, R. Bagging, Boosting and the Random Subspace Method for Linear Classifiers. Pattern Anal. Appl. 2002, 5, 121–135. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EEG Bands | Freq. Range | Spectral Feature | Temporal Features | ||||
|---|---|---|---|---|---|---|---|
| Delta | 1–4 Hz | Delta power | Mean amplitude | Standard Deviation | Peak to Peak | Skewness | Kurtosis |
| Theta | 4–8 Hz | Theta power | Mean amplitude | Standard Deviation | Peak to Peak | Skewness | Kurtosis |
| Alpha | 8–13 Hz | Alpha power | Mean amplitude | Standard Deviation | Peak to Peak | Skewness | Kurtosis |
| Beta | 13–30 Hz | Beta power | Mean amplitude | Standard Deviation | Peak to Peak | Skewness | Kurtosis |
| Gamma | 30–50 Hz | Gamma power | Mean amplitude | Standard Deviation | Peak to Peak | Skewness | Kurtosis |
| Total number of features (in single channel) | 5 | 25 | |||||
| In-Ear EEG | On-Scalp EEG | |||
|---|---|---|---|---|
| Subject # | Training Accuracy (%) | Test Accuracy (%) | Training Accuracy (%) | Test Accuracy (%) |
| 1 (M) | 92.77 ± 2.14 | 81.42 ± 4.18 | 98.14 ± 0.54 | 91.23 ± 2.13 |
| 2 (M) | 91.59 ± 1.49 | 75.89 ± 2.91 | 88.25 ± 2.26 | 78.52 ± 2.84 |
| 3 (M) | 94.11 ± 1.34 | 83.28 ± 2.88 | 92.06 ± 1.64 | 80.64 ± 2.79 |
| 4 (M) | 93.97 ± 1.76 | 79.34 ± 3.39 | 96.25 ± 0.67 | 85.73 ± 3.82 |
| 5 (F) | 91.25 ± 3.47 | 79.46 ± 5.01 | 92.24 ± 1.07 | 83.05 ± 4.47 |
| 6 (F) | 92.00 ± 2.09 | 87.59 ± 3.25 | 90.74 ± 1.45 | 75.46 ± 3.40 |
| Avg. | 92.62 ± 0.45 | 81.16 ± 2.20 | 92.95 ± 2.19 | 82.44 ± 2.24 |
| In-Ear EEG | On-Scalp EEG | ||||
|---|---|---|---|---|---|
| Validation Method | Subject # | Training Accuracy (%) | Test Accuracy (%) | Training Accuracy (%) | Test Accuracy (%) |
| Cross-Subject Validation | 1 (M) | 73.46 | 62.65 | 77.17 | 79.54 |
| 2 (M) | 63.55 | 58.36 | 74.56 | 60.12 | |
| 3 (M) | 66.00 | 54.59 | 61.46 | 55.31 | |
| 4 (M) | 81.16 | 65.39 | 83.33 | 76.35 | |
| 5 (F) | 83.55 | 69.52 | 72.88 | 58.63 | |
| 6 (F) | 85.08 | 73.47 | 78.73 | 64.24 | |
| Avg. | 75.46 ± 3.44 | 64.00 ± 2.60 | 74.69 ± 2.77 | 65.70 ± 3.71 | |
| 10-fold Cross-Validation | Avg. | 80.89 ± 1.93 | 74.15 ± 2.20 | 78.42 ± 2.19 | 73.73 ± 2.24 |
| Within-Subject | Cross-Subject | 10-fold CV | ||||
|---|---|---|---|---|---|---|
| Smoothing Window (second) | In-Ear EEG (%) | On-Scalp EEG (%) | In-Ear EEG (%) | On-Scalp EEG (%) | In-Ear EEG (%) | On-Scalp EEG (%) |
| Non (0.5 s) | 81.16 | 82.44 | 64.00 | 65.70 | 74.15 | 73.73 |
| 2 (1 s) | 81.32 | 82.73 | 64.64 | 65.78 | 74.75 | 73.63 |
| 4 (2 s) | 82.33 | 83.56 | 65.86 | 65.73 | 75.07 | 73.89 |
| 6 (3 s) | 82.90 | 83.74 | 65.84 | 65.64 | 75.32 | 74.01 |
| 8 (4 s) | 83.24 | 83.81 | 66.09 | 65.36 | 75.36 | 74.22 |
| 10 (5 s) | 83.24 | 83.70 | 65.97 | 65.73 | 75.34 | 74.54 |
| 12 (6 s) | 83.62 | 83.47 | 65.85 | 65.44 | 75.41 | 74.46 |
| Authors | Mental States (Classes) | Window (Seconds) | Methods | Validation | Accuracy |
|---|---|---|---|---|---|
| Hong et al. (2018) [24] | Drowsiness (5 levels) | 10 | RF | 5-fold CV | 0.780 (kappa value) |
| Nakamura et al. (2018) [25] | Drowsiness (Wake vs. N1) | 30 | SVM | Leave-one trial-out (all subjects) | 80% |
| 10-fold CV (all subjects) | 82.9% | ||||
| Kuatsjah et al. (2019) [26] | Mental workload (Visuomotor task vs. Rest) | 5 | The best among various ML approaches | Across-trial for each subject | 68% (approx.) |
| 25 | 79.30% | ||||
| 5 | NN | 5-fold CV for each subject | 71.50% | ||
| Athavipach et al. (2019) [27] | Emotion (Valence) | 30 | SVM | 10-fold CV for each subject | 73.01% |
| Emotion (Arousal) | 75.70% | ||||
| Emotion (Valence+Arousal) | 59.23% | ||||
| This Study | Attention (Vigilance task vs. Rest) | 0.5 | ESN | Across-trial for each subject | 81.16% |
| 10-fold CV (all subjects) | 74.15% | ||||
| Cross-subject | 64.00% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, D.-H.; Jeong, J. In-Ear EEG Based Attention State Classification Using Echo State Network. Brain Sci. 2020, 10, 321. https://doi.org/10.3390/brainsci10060321
Jeong D-H, Jeong J. In-Ear EEG Based Attention State Classification Using Echo State Network. Brain Sciences. 2020; 10(6):321. https://doi.org/10.3390/brainsci10060321
Chicago/Turabian StyleJeong, Dong-Hwa, and Jaeseung Jeong. 2020. "In-Ear EEG Based Attention State Classification Using Echo State Network" Brain Sciences 10, no. 6: 321. https://doi.org/10.3390/brainsci10060321
APA StyleJeong, D. -H., & Jeong, J. (2020). In-Ear EEG Based Attention State Classification Using Echo State Network. Brain Sciences, 10(6), 321. https://doi.org/10.3390/brainsci10060321