

A Large Video Set of Natural Human Actions for Visual and Cognitive Neuroscience Studies and Its Validation with fMRI


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Stimulus Set
2.2. Post-Processing of the Videos
2.3. Data Validation
2.3.1. fMRI Experiment
2.3.2. fMRI Data Acquisition
2.3.3. fMRI Data Preprocessing
Anatomical Data Preprocessing
Functional Data Preprocessing
2.3.4. Activation Maps for Observed Actions
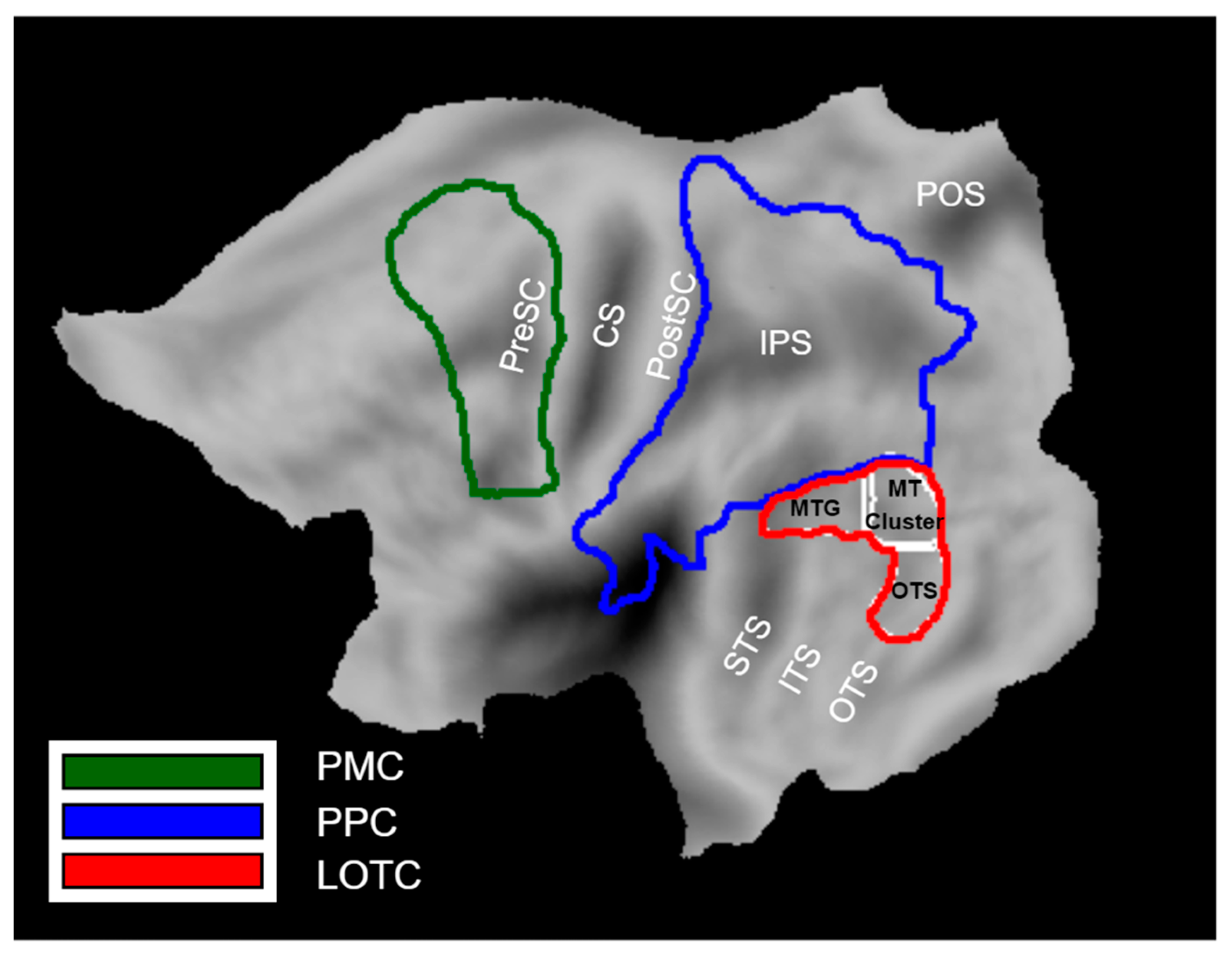
2.3.5. Definition of ROIs
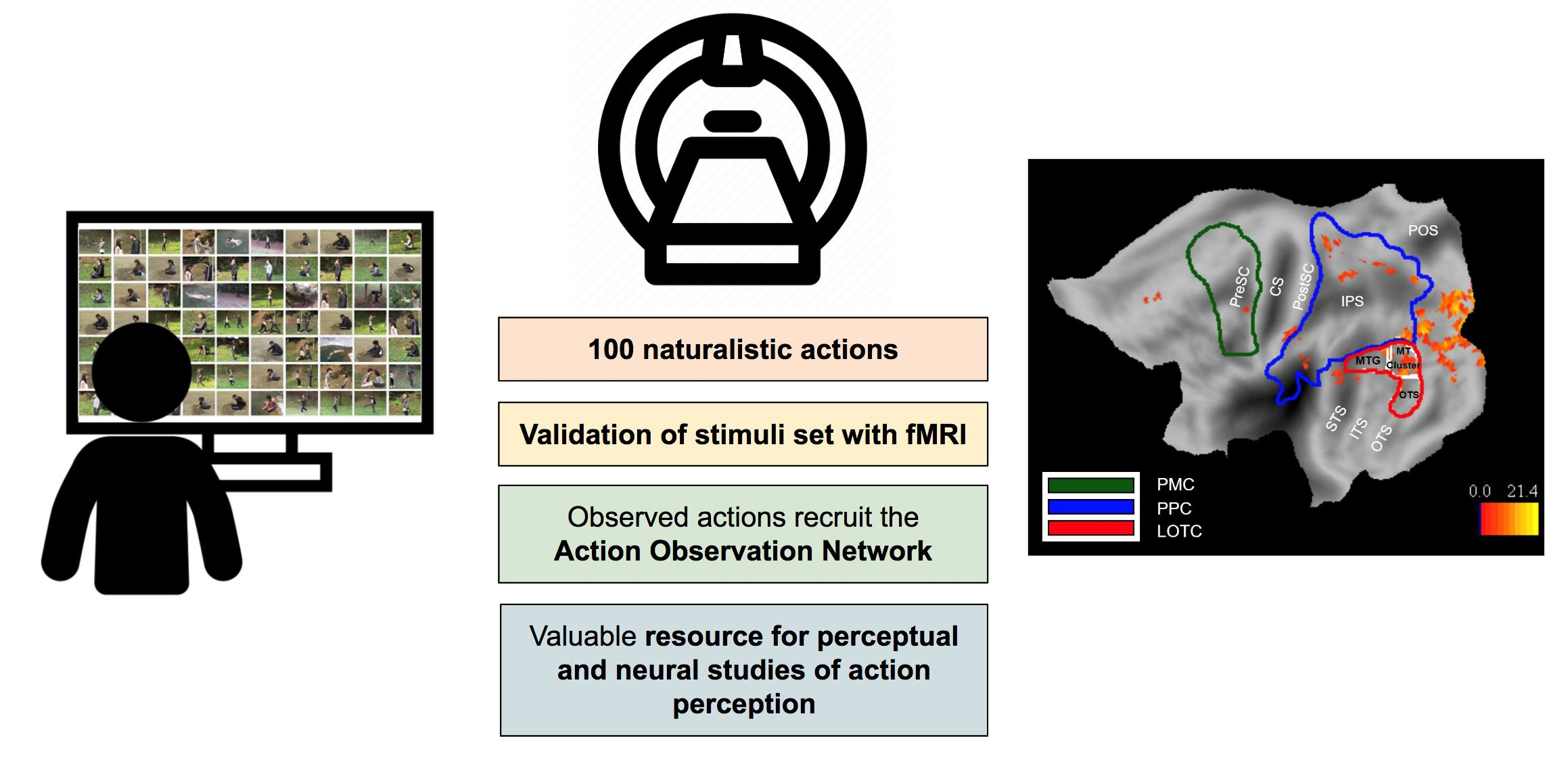
3. Results
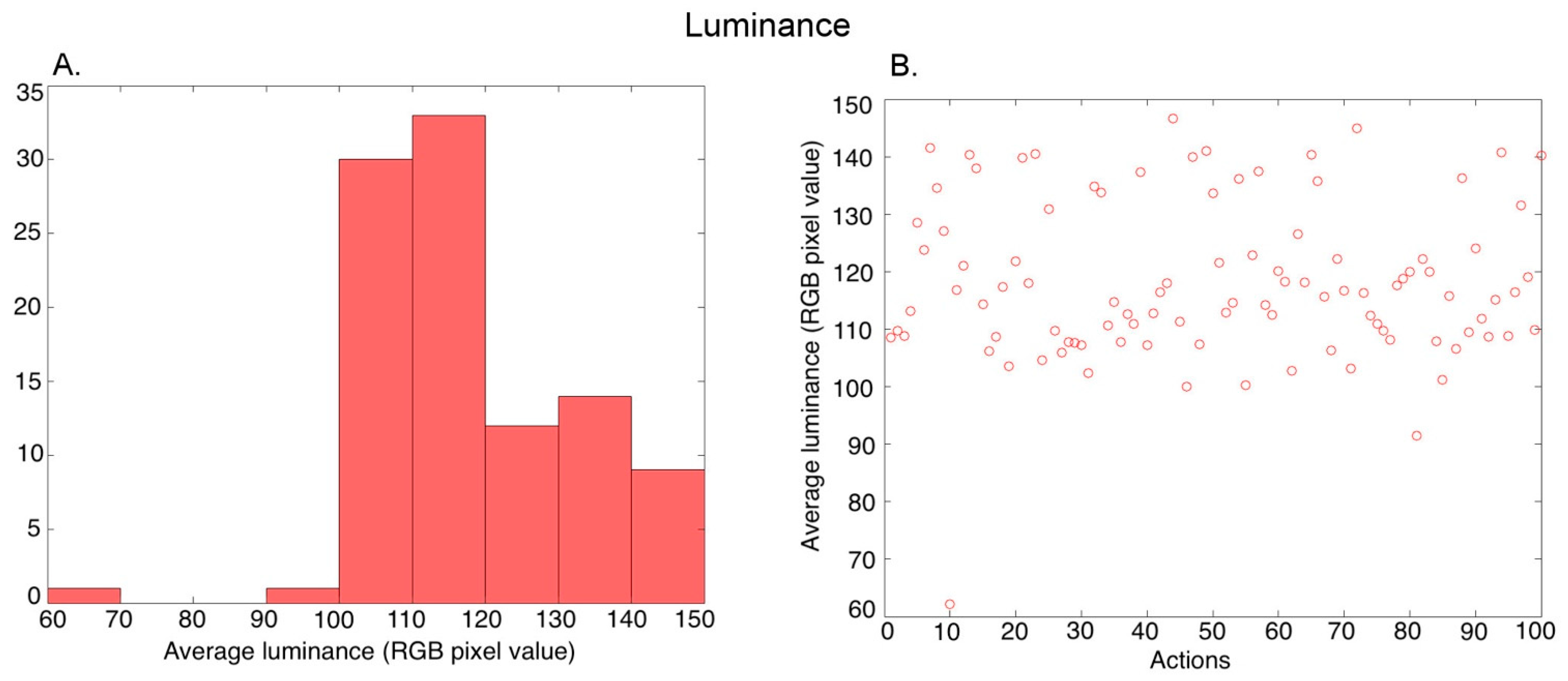
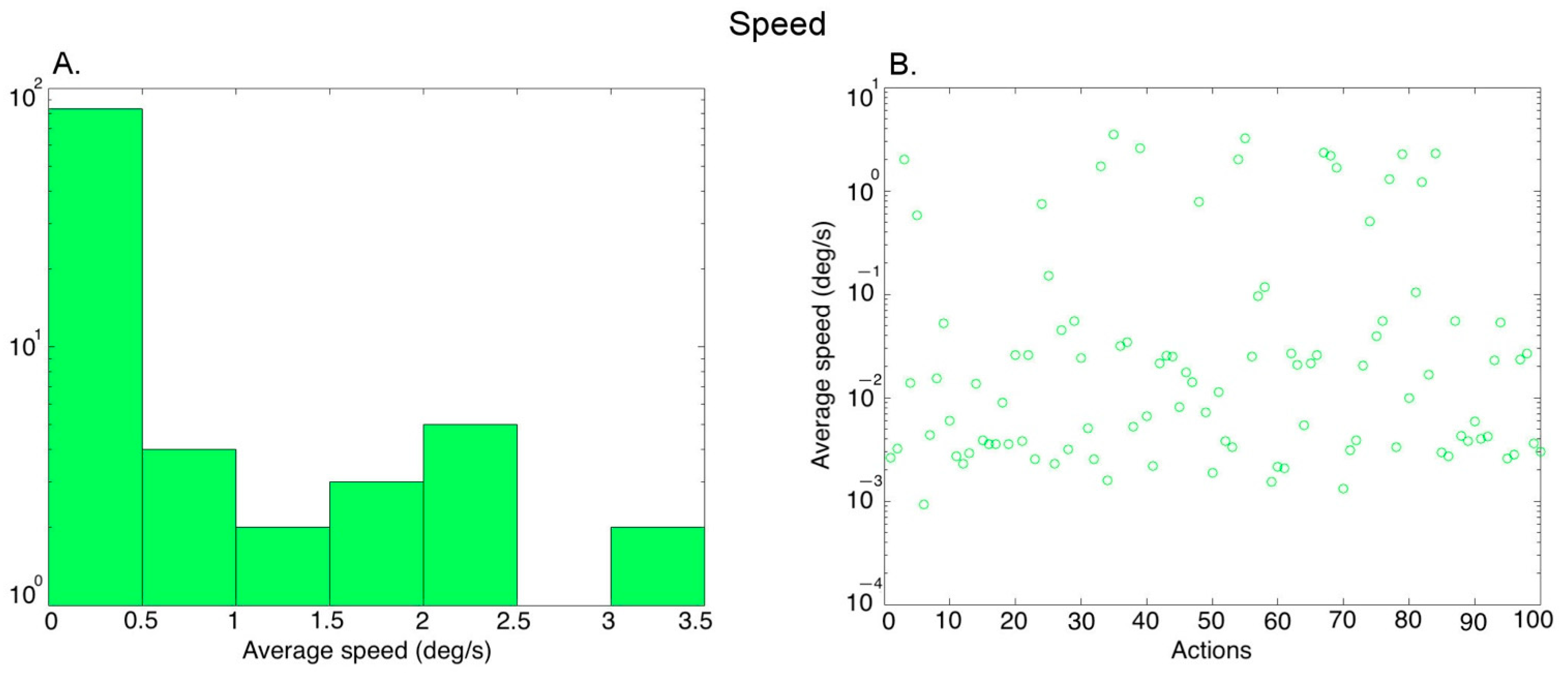
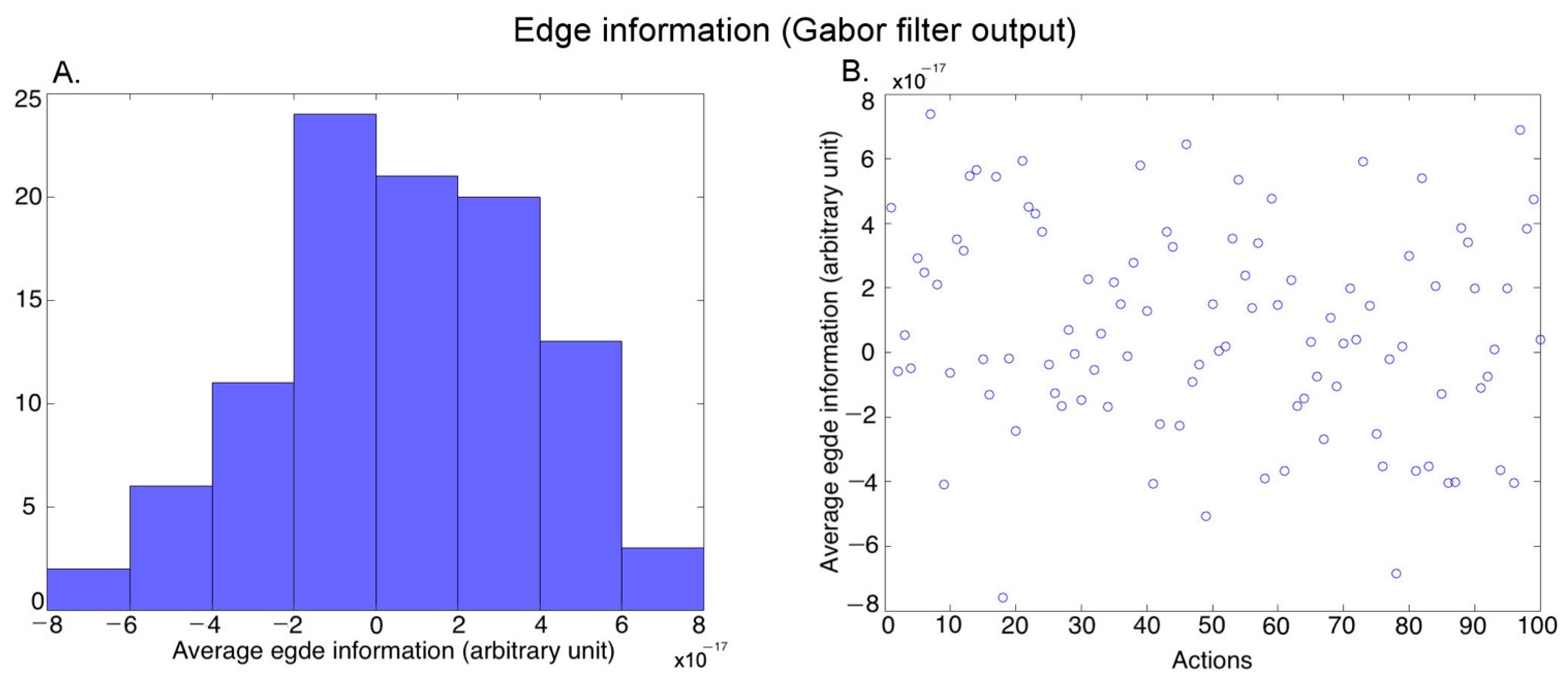
3.1. Post-Processing of Video Stimuli
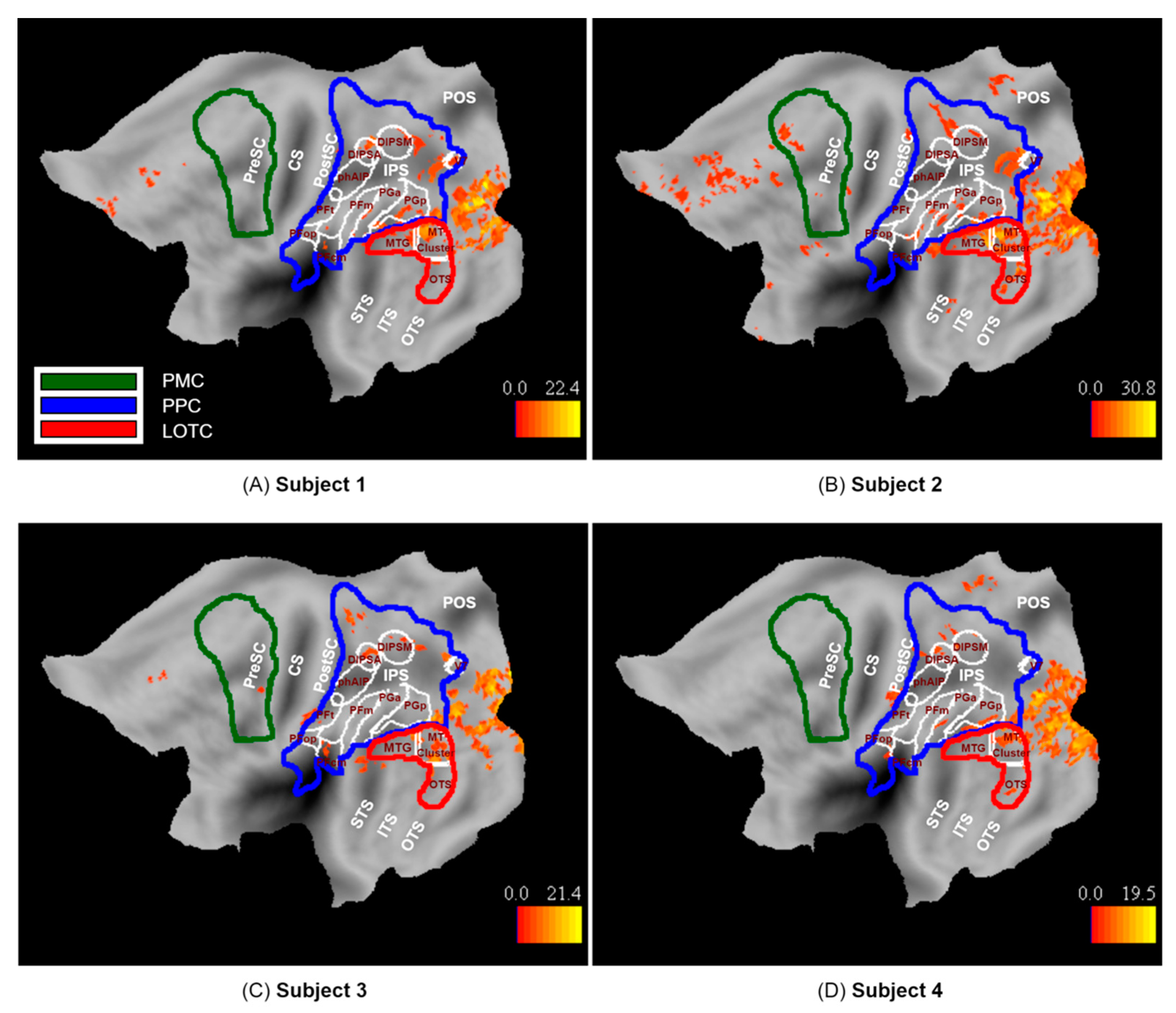
3.2. fMRI Activation Maps
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Caspers, S.; Zilles, K.; Laird, A.R.; Eickhoff, S.B. ALE meta-analysis of action observation and imitation in the human brain. Neuroimage 2010, 50, 1148–1167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdollahi, R.O.; Jastorff, J.; Orban, G.A. Common and Segregated Processing of Observed Actions in Human SPL. Cereb. Cortex 2012, 23, 2734–2753. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferri, S.; Rizzolatti, G.; Orban, G.A. The organization of the posterior parietal cortex devoted to upper limb actions: An fMRI study. Hum. Brain Mapp. 2015, 36, 3845–3866. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corbo, D.; Orban, G.A. Observing Others Speak or Sing Activates Spt and Neighboring Parietal Cortex. J. Cogn. Neurosci. 2017, 29, 1002–1021. [Google Scholar] [CrossRef]
- Urgen, B.A.; Orban, G.A. The unique role of parietal cortex in action observation: Functional organization for communicative and manipulative actions. NeuroImage 2021, 237, 118220. [Google Scholar] [CrossRef]
- Sonkusare, S.; Breakspear, M.; Guo, C. Naturalistic Stimuli in Neuroscience: Critically Acclaimed. Trends Cogn. Sci. 2019, 23, 699–714. [Google Scholar] [CrossRef]
- Nastase, S.A.; Goldstein, A.; Hasson, U. Keep it real: Rethinking the primacy of experimental control in cognitive neuroscience. Neuroimage 2020, 222, 117254. [Google Scholar] [CrossRef]
- Kriegeskorte, N.; Mur, M.; Bandettini, P.A. Representational similarity analysis—Connecting the branches of systems neuroscience. Front. Syst. Neurosci. 2008, 2, 4. [Google Scholar] [CrossRef] [Green Version]
- Bidet-Ildei, C.; Francisco, V.; Decatoire, A.; Pylouster, J.; Blandin, Y. PLAViMoP database: A new continuously assessed and collaborative 3D point-light display dataset. Behav. Res. Methods 2022, 1–22. [Google Scholar] [CrossRef]
- Reddy, K.K.; Shah, M. Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 2012, 24, 971–981. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A Large Video Database for Human Motion Recognition. In Proceedings of the 2011 International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. AVA: A Video Dataset of Spatio-Temporally Localized Atomic Visual Actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Huth, A.G.; Nishimoto, S.; Vu, A.T.; Gallant, J.L. A Continuous Semantic Space Describes the Representation of Thousands of Object and Action Categories across the Human Brain. Neuron 2012, 76, 1210–1224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jastorff, J.; Begliomini, C.; Destro, M.F.; Rizzolatti, G.; Orban, G. Coding Observed Motor Acts: Different Organizational Principles in the Parietal and Premotor Cortex of Humans. J. Neurophysiol. 2010, 104, 128–140. [Google Scholar] [CrossRef] [PubMed]
- Shahdloo, M.; Çelik, E.; Urgen, B.A.; Gallant, J.L.; Çukur, T. Task-Dependent Warping of Semantic Representations during Search for Visual Action Categories. J. Neurosci. 2022, 42, 6782–6799. [Google Scholar] [CrossRef] [PubMed]
- Tustison, N.J.; Avants, B.B.; Cook, P.A.; Zheng, Y.; Egan, A.; Yushkevich, P.A.; Gee, J.C. N4ITK: Improved N3 bias correction. IEEE Trans. Med. Imaging 2010, 29, 1310–1320. [Google Scholar] [CrossRef] [Green Version]
- Avants, B.; Epstein, C.; Grossman, M.; Gee, J. Symmetric diffeomorphic image registration with cross-correlation: Evaluating automated labeling of elderly and neurodegenerative brain. Med. Image Anal. 2008, 12, 26–41. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 2001, 20, 45–57. [Google Scholar] [CrossRef]
- Reuter, M.; Rosas, H.D.; Fischl, B. Highly accurate inverse consistent registration: A robust approach. Neuroimage 2010, 53, 1181–1196. [Google Scholar] [CrossRef] [Green Version]
- Dale, A.M.; Fischl, B.; Sereno, M.I. Cortical surface-based analysis. I. Segmentation and surface reconstruction. NeuroImage 1999, 9, 179–194. [Google Scholar] [CrossRef]
- Klein, A.; Ghosh, S.S.; Bao, F.S.; Giard, J.; Häme, Y.; Stavsky, E.; Lee, N.; Rossa, B.; Reuter, M.; Neto, E.C.; et al. Mindboggling morphometry of human brains. PLoS Comput. Biol. 2017, 13, e1005350. [Google Scholar] [CrossRef] [Green Version]
- Fonov, V.; Evans, A.; McKinstry, R.; Almli, C.; Collins, D. Unbiased nonlinear average age-appropriate brain templates from birth to adulthood. Neuroimage 2009, 47, S102. [Google Scholar] [CrossRef]
- Greve, D.N.; Fischl, B. Accurate and robust brain image alignment using boundary-based registration. Neuroimage 2009, 48, 63–72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jenkinson, M.; Bannister, P.; Brady, M.; Smith, S. Improved Optimization for the Robust and Accurate Linear Registration and Motion Correction of Brain Images. Neuroimage 2002, 17, 825–841. [Google Scholar] [CrossRef] [PubMed]
- Cox, R.W.; Hyde, J.S. Software Tools for Analysis and Visualization of fMRI Data. NMR Biomed. Int. J. Devoted Dev. Appl. Magn. Reson. In Vivo 1997, 10, 171–178. [Google Scholar] [CrossRef]
- Power, J.D.; Mitra, A.; Laumann, T.O.; Snyder, A.Z.; Schlaggar, B.L.; Petersen, S.E. Methods to detect, characterize, and remove motion artifact in resting state fMRI. Neuroimage 2014, 84, 320–341. [Google Scholar] [CrossRef] [Green Version]
- Behzadi, Y.; Restom, K.; Liau, J.; Liu, T.T. A component based noise correction method (CompCor) for BOLD and perfusion based fMRI. Neuroimage 2007, 37, 90–101. [Google Scholar] [CrossRef] [Green Version]
- Satterthwaite, T.D.; Wolf, D.H.; Ruparel, K.; Erus, G.; Elliott, M.A.; Eickhoff, S.B.; Gennatas, E.D.; Jackson, C.; Prabhakaran, K.; Smith, A.; et al. Heterogeneous impact of motion on fundamental patterns of developmental changes in functional connectivity during youth. Neuroimage 2013, 83, 45–57. [Google Scholar] [CrossRef] [Green Version]
- Lanczos, C. Evaluation of noisy data. J. Soc. Ind. Appl. Math. Ser. B Numer. Anal. 1964, 1, 76–85. [Google Scholar] [CrossRef]
- Abraham, A.; Pedregosa, F.; Eickenberg, M.; Gervais, P.; Mueller, A.; Kossaifi, J.; Gramfort, A.; Thirion, B.; Varoquaux, G. Machine learning for neuroimaging with scikit-learn. Front. Neuroinform. 2014, 8, 14. [Google Scholar] [CrossRef] [Green Version]
- Tootell, R.; Reppas, J.; Kwong, K.; Malach, R.; Born, R.; Brady, T.; Rosen, B.; Belliveau, J. Functional analysis of human MT and related visual cortical areas using magnetic resonance imaging. J. Neurosci. 1995, 15, 3215–3230. [Google Scholar] [CrossRef]
- Kolster, H.; Peeters, R.; Orban, G.A. The Retinotopic Organization of the Human Middle Temporal Area MT/V5 and Its Cortical Neighbors. J. Neurosci. 2010, 30, 9801–9820. [Google Scholar] [CrossRef]
- Jastorff, J.; Popivanov, I.D.; Vogels, R.; Vanduffel, W.; Orban, G.A. Integration of shape and motion cues in biological motion processing in the monkey STS. Neuroimage 2012, 60, 911–921. [Google Scholar] [CrossRef] [PubMed]
- Nelissen, K.; Borra, E.; Gerbella, M.; Rozzi, S.; Luppino, G.; Vanduffel, W.; Rizzolatti, G.; Orban, G. Action Observation Circuits in the Macaque Monkey Cortex. J. Neurosci. 2011, 31, 3743–3756. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caspers, S.; Geyer, S.; Schleicher, A.; Mohlberg, H.; Amunts, K.; Zilles, K. The human inferior parietal cortex: Cytoarchitectonic parcellation and interindividual variability. Neuroimage 2006, 33, 430–448. [Google Scholar] [CrossRef] [PubMed]
- Eickhoff, S.B.; Grefkes, C.; Zilles, K.; Fink, G.R. The Somatotopic Organization of Cytoarchitectonic Areas on the Human Parietal Operculum. Cereb. Cortex 2006, 17, 1800–1811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, H.-J.; Zilles, K.; Mohlberg, H.; Schleicher, A.; Fink, G.R.; Armstrong, E.; Amunts, K. Cytoarchitectonic identification and probabilistic mapping of two distinct areas within the anterior ventral bank of the human intraparietal sulcus. J. Comp. Neurol. 2006, 495, 53–69. [Google Scholar] [CrossRef] [Green Version]
- Scheperjans, F.; Eickhoff, S.B.; Hömke, L.; Mohlberg, H.; Hermann, K.; Amunts, K.; Zilles, K. Probabilistic Maps, Morphometry, and Variability of Cytoarchitectonic Areas in the Human Superior Parietal Cortex. Cereb. Cortex 2008, 18, 2141–2157. [Google Scholar] [CrossRef]
- Pitzalis, S.; Sereno, M.I.; Committeri, G.; Fattori, P.; Galati, G.; Patria, F.; Galletti, C. Human V6: The Medial Motion Area. Cereb. Cortex 2010, 20, 411–424. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, R.O.; Kolster, H.; Glasser, M.F.; Robinson, E.C.; Coalson, T.S.; Dierker, D.; Jenkinson, M.; Van Essen, D.C.; Orban, G.A. Correspondences between retinotopic areas and myelin maps in human visual cortex. NeuroImage 2014, 99, 509–524. [Google Scholar] [CrossRef] [Green Version]
- Ferri, S.; Pauwels, K.; Rizzolatti, G.; Orban, G.A. Stereoscopically Observing Manipulative Actions. Cereb. Cortex 2016, 26, 3591–3610. [Google Scholar] [CrossRef]
- Jastorff, J.; Abdollahi, R.O.; Fasano, F.; Orban, G.A. Seeing biological actions in 3D: An fMRI study. Hum. Brain Mapp. 2016, 37, 213–219. [Google Scholar] [CrossRef]
- Van Essen, D.C.; Drury, H.A.; Dickson, J.; Harwell, J.; Hanlon, D.; Anderson, C.H. An integrated software suite for surface-based analyses of cerebral cortex. J. Am. Med. Inform. Assoc. 2001, 8, 443–459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pauwels, K.; Van Hulle, M.M. Optic flow from unstable sequences through local velocity constancy maximization. Image Vis. Comput. 2009, 27, 579–587. [Google Scholar] [CrossRef]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Haghighat, M.; Zonouz, S.; Abdel-Mottaleb, M. CloudID: Trustworthy cloud-based and cross-enterprise biometric identification. Expert Syst. Appl. 2015, 42, 7905–7916. [Google Scholar] [CrossRef]
- Georgieva, S.; Peeters, R.; Kolster, H.; Todd, J.T.; Orban, G.A. The processing of three-dimensional shape from disparity in the human brain. J. Neurosci. 2009, 29, 727–742. [Google Scholar] [CrossRef] [Green Version]
- Keefe, B.D.; Villing, M.; Racey, C.; Strong, S.L.; Wincenciak, J.; Barraclough, N.E. A database of whole-body action videos for the study of action, emotion, and untrustworthiness. Behav. Res. Methods 2014, 46, 1042–1051. [Google Scholar] [CrossRef] [Green Version]
- Platonov, A.; Orban, G.A. Action observation: The less-explored part of higher-order vision. Sci. Rep. 2016, 6, 36742. [Google Scholar] [CrossRef] [Green Version]
- Platonov, A.; Orban, G.A. Not all observed actions are perceived equally. Sci. Rep. 2017, 7, 17084. [Google Scholar] [CrossRef] [Green Version]
- Orban, G.A.; Sepe, A.; Bonini, L. Parietal maps of visual signals for bodily action planning. Anat. Embryol. 2021, 226, 2967–2988. [Google Scholar] [CrossRef]
- Zhuang, C.; Yan, S.; Nayebi, A.; Schrimpf, M.; Frank, M.C.; DiCarlo, J.J.; Yamins, D.L. Unsupervised neural network models of the ventral visual stream. Proc. Natl. Acad. Sci. USA 2021, 118, e2014196118. [Google Scholar] [CrossRef]
- Giese, M.A.; Poggio, T. Neural mechanisms for the recognition of biological movements. Nat. Rev. Neurosci. 2003, 4, 179–192. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.; Singer, J.M.; Serre, T.; Sheinberg, D.; Poggio, T. Neural Representation of Action Sequences: How Far Can a Simple Snippet-Matching Model Take Us? In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 593–601. [Google Scholar]
- Fleischer, F.; Caggiano, V.; Thier, P.; Giese, M.A. Physiologically Inspired Model for the Visual Recognition of Transitive Hand Actions. J. Neurosci. 2013, 33, 6563–6580. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Theusner, S.; De Lussanet, M.; Lappe, M. Action Recognition by Motion Detection in Posture Space. J. Neurosci. 2014, 34, 909–921. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Exemplar No | Action Exemplar Name | Actors |
|---|---|---|
| 1 | Measuring with fingers | F1, F2, M1 |
| 2 | Shouting | F1, M1, M2 |
| 3 | Carrying with head and hands | F1, M1, M2 |
| 4 | Caressing another person | F1, F2, M1 |
| 5 | Free style swimming | F2, M1, M2 |
| 6 | Kicking wood with feet | F2, M1, M2 |
| 7 | Dragging | F1, F2, M2 |
| 8 | Reaching | F1, F2, M2 |
| 9 | Measuring a long distance with feet | F1, F2, M1 |
| 10 | Crushing a leaf with fingers | F1, F2, M2 |
| 11 | Fanning with leaf | F1, F2, M2 |
| 12 | Pushing a small stone | F1, F2, M2 |
| 13 | Dropping a small stone | F1, F2, M2 |
| 14 | Ridiculing another person | F1, F2, M1 |
| 15 | Massaging own cheek | F1, F2, M2 |
| 16 | Scratching own cheek | F1, F2, M2 |
| 17 | Swallowing | F1, F2, M1 |
| 18 | Yawning with hand | F1, F2, M2 |
| 19 | Licking an orange | F1, F2, M2 |
| 20 | Gazing at an object | F1, F2, M1 |
| 21 | Peeling a fruit | F1, F2, M1 |
| 22 | Filling a hole with hand | F1, F2, M1 |
| 23 | Hitting own cheek | F1, F2, M1 |
| 24 | Swimming back style | F1, M1, M2 |
| 25 | Displacing wood | F1, F2, M2 |
| 26 | Weighing an object with one hand | F1, F2, M2 |
| 27 | Climbing down a tree | F1, F2, M1 |
| 28 | Whistling | F2, M1, M2 |
| 29 | Measuring with hands | F1, F2, M1 |
| 30 | Picking a fruit from a tree | F2, M1, M2 |
| 31 | Kicking horizontally | F2, M1, M2 |
| 32 | Kicking vertically | F2, M1, M2 |
| 33 | Carrying with head | F1, M1, M2 |
| 34 | Blowing a leaf | F1, M1, M2 |
| 35 | Chasing another person | F1, M1, M2 |
| 36 | Struggling | F2, M1, M2 |
| 37 | Waving goodbye | F1, M1, M2 |
| 38 | Beating with a piece of wood | F1, M1, M2 |
| 39 | Carrying with shoulder and hand | F1, F2, M2 |
| 40 | Reprimanding a person | F2, M1, M2 |
| 41 | Biting a banana | F2, M1, M2 |
| 42 | Fighting with another person | F2, M1, M2 |
| 43 | Washing own body | F2, M1, M2 |
| 44 | Foraging | F1, M1, M2 |
| 45 | Stretching own body | F1, M1, M2 |
| 46 | Writing with fingers | F1, M1, M2 |
| 47 | Charging to attack | F1, F2, M1 |
| 48 | Diving | F2, M1, M2 |
| 49 | Pointing nearby | F2, M1, M2 |
| 50 | Squeezing an orange | F1, F2, M2 |
| 51 | Forbidding with fingers | F2, M1, M2 |
| 52 | Wrapping a stone | F1, M1, M2 |
| 53 | Grasping | F2, M1, M2 |
| 54 | Carrying on shoulder | F1, F2, M1 |
| 55 | Running | F1, F2, M2 |
| 56 | Burying in the sand | F2, M1, M2 |
| 57 | Stopping a person | F1, F2, M2 |
| 58 | Pushing a person | F1, M1, M2 |
| 59 | Kissing a person | F1, F2, M1 |
| 60 | Throwing and catching a small piece of wood | F1, M1, M2 |
| 61 | Caressing own cheek | F2, M1, M2 |
| 62 | Overtaking an obstacle | F1, F2, M1 |
| 63 | Touching another person on the shoulder | F1, F2, M2 |
| 64 | Building pyramid from sand | F1, F2, M1 |
| 65 | Hiding an object behind back | F2, M1, M2 |
| 66 | Washing fruit | F1, F2, M1 |
| 67 | Carrying with hands | F1, F2, M2 |
| 68 | Walking | F1, F2, M2 |
| 69 | Marching | F1, F2, M1 |
| 70 | Rubbing own cheek | F1, M1, M2 |
| 71 | Throwing nearby | F1, M1, M2 |
| 72 | Masticating | F2, M1, M2 |
| 73 | People meeting | F2, M1, M2 |
| 74 | Climbing up a tree | F1, F2, M2 |
| 75 | Dancing with another person | F2, M1, M2 |
| 76 | Getting up | F1, M1, M2 |
| 77 | Crawling | F1, M1, M2 |
| 78 | Spitting a piece of banana | F1, F2, M1 |
| 79 | Doing gymnastics with both feet and arms | F1, F2, M2 |
| 80 | Pushing a large object | F2, M1, M2 |
| 81 | Rolling body sidewise | F1, F2, M1 |
| 82 | Walking on hand and knees | F1, M1, M2 |
| 83 | Laughing together with another person | F2, M1, M2 |
| 84 | Carrying with one hand | F1, F2, M1 |
| 85 | Singing a song | F1, F2, M1 |
| 86 | Weighing an object with two hands | F1, M1, M2 |
| 87 | Pointing distantly | F1, F2, M2 |
| 88 | Drinking with hands | F2, M1, M2 |
| 89 | Massaging another person | F1, F2, M1 |
| 90 | Drinking with mouth | F1, F2, M2 |
| 91 | Measuring height with own body | F1, M1, M2 |
| 92 | Pinching off piece of banana | F1, F2, M1 |
| 93 | Erasing | F1, F2, M2 |
| 94 | Hugging a person (passive) | F1, M1, M2 |
| 95 | Speaking with another person | F1, F2, M1 |
| 96 | Rotating a stone | F2, M1, M2 |
| 97 | Measuring a short distance with feet | F1, M1, M2 |
| 98 | Hugging each other | F1, M1, M2 |
| 99 | Digging a hole with a hand | F2, M1, M2 |
| 100 | Throwing far | F1, F2, M1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Urgen, B.A.; Nizamoğlu, H.; Eroğlu, A.; Orban, G.A. A Large Video Set of Natural Human Actions for Visual and Cognitive Neuroscience Studies and Its Validation with fMRI. Brain Sci. 2023, 13, 61. https://doi.org/10.3390/brainsci13010061
Urgen BA, Nizamoğlu H, Eroğlu A, Orban GA. A Large Video Set of Natural Human Actions for Visual and Cognitive Neuroscience Studies and Its Validation with fMRI. Brain Sciences. 2023; 13(1):61. https://doi.org/10.3390/brainsci13010061
Chicago/Turabian StyleUrgen, Burcu A., Hilal Nizamoğlu, Aslı Eroğlu, and Guy A. Orban. 2023. "A Large Video Set of Natural Human Actions for Visual and Cognitive Neuroscience Studies and Its Validation with fMRI" Brain Sciences 13, no. 1: 61. https://doi.org/10.3390/brainsci13010061
APA StyleUrgen, B. A., Nizamoğlu, H., Eroğlu, A., & Orban, G. A. (2023). A Large Video Set of Natural Human Actions for Visual and Cognitive Neuroscience Studies and Its Validation with fMRI. Brain Sciences, 13(1), 61. https://doi.org/10.3390/brainsci13010061