




Convolutional Neural Network with a Topographic Representation Module for EEG-Based Brain—Computer Interfaces

Abstract
:1. Introduction
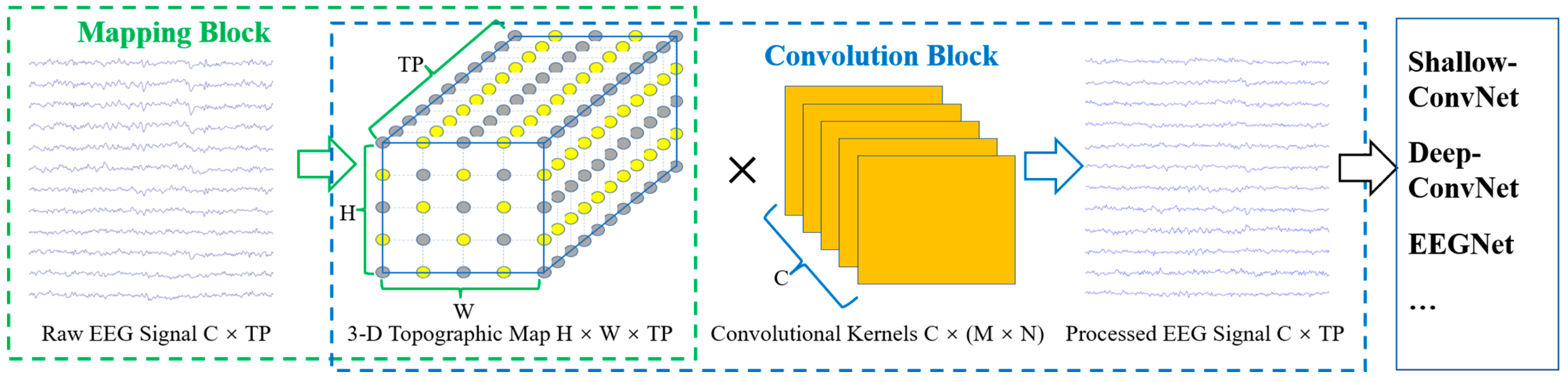
- The TRM is designed, and the dimension and size of EEG signals remain unchanged after passing through the TRM.
- The TRM can be embedded into a CNN using the raw EEG signals as input without any adjustment to the network structure, which enables TRM to use the existing excellent EEG classification network.
- The classification results show that with TRM, the results of three commonly used CNNs on two public datasets are better than those of the original network, indicating that TRM has the potential to improve CNN classification performance by learning EEG topological information.
2. Materials and Methods
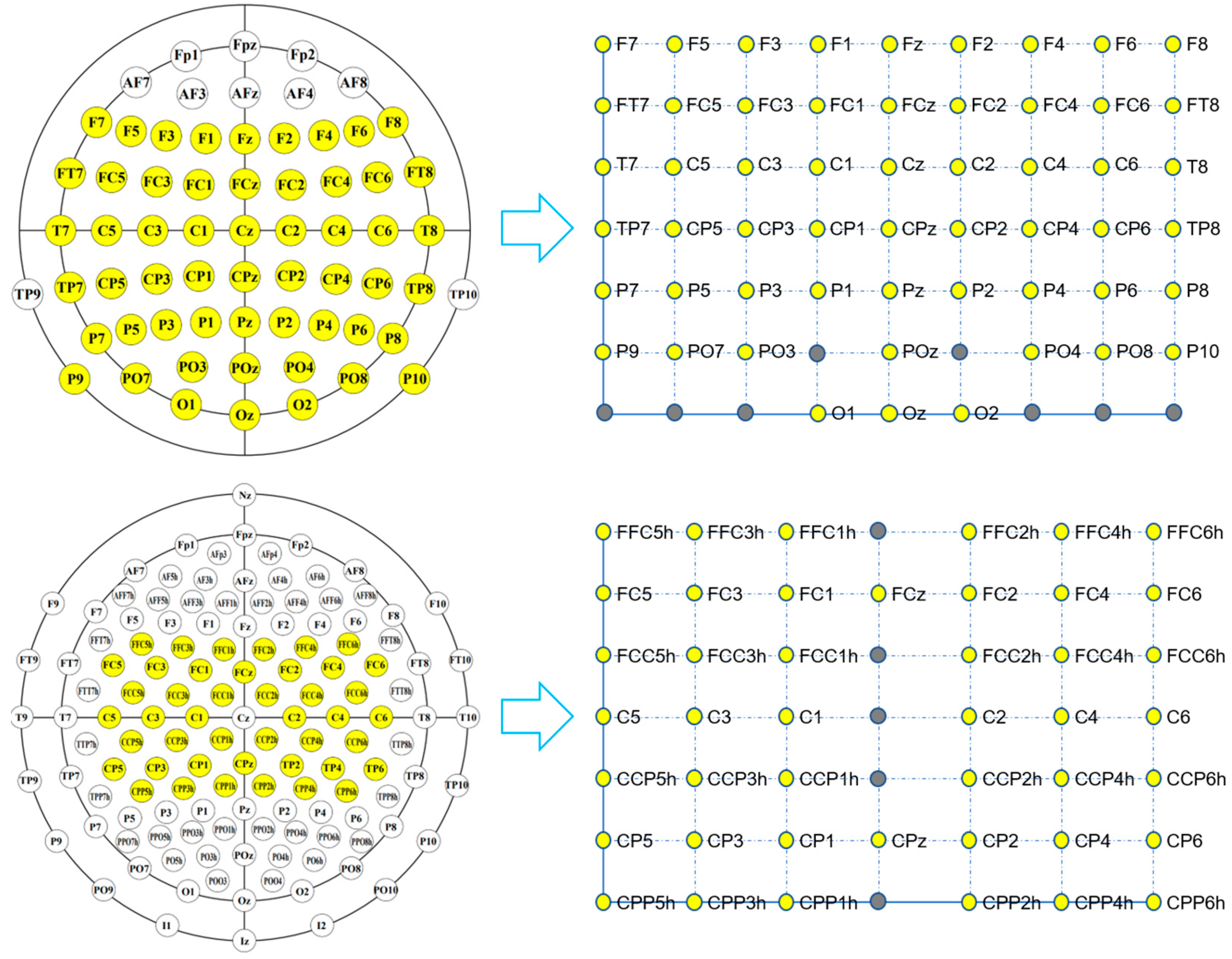
2.1. Datasets
2.2. Classification Algorithms
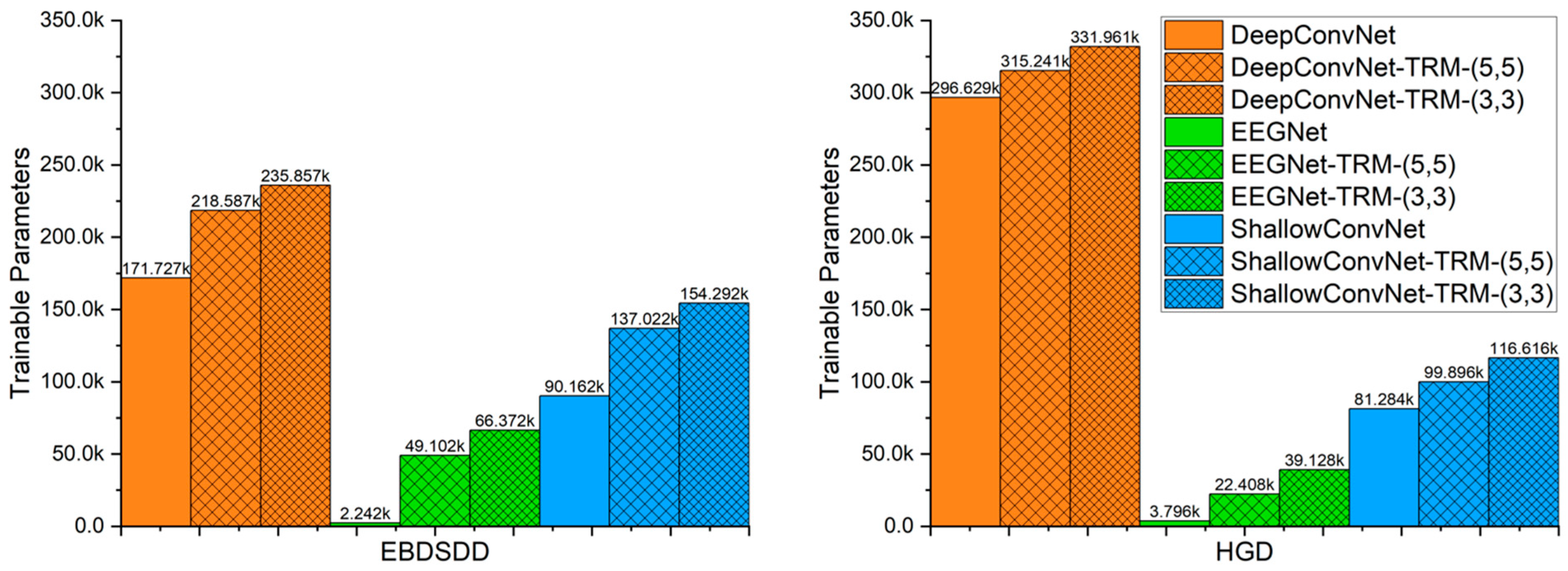
2.3. TRM
2.4. Implementation Details
- The Adam optimizer is used with a weight decay of 0.001, and the remaining parameters are set to their default values.
- The cross-entropy loss is used as a criterion.
- The batch size is set to 32.
- The number of training epochs is set to 300, and the minimum validation loss strategy is used. The network is trained on the training set and validated on the validation set. After each training, the loss on the validation set is compared with the previous loss, and the model with reduced validation loss is saved. The algorithm model with the lowest loss on the validation set is saved for testing.
- Both ShallowConvNet and EEGNet are trained and tested on both datasets using the codes officially provided by BrainDecode [17]. On the HGD, we use the code of DeepConvNet provided by BrainDecode, while on the EBDSDD, we adjust DeepConvNet with the settings recommended by [39] since the size of the input data does not meet the minimum length requirement of the original DeepConvNet.
2.5. Evaluation Metrics
3. Results
3.1. Classification Accuracy
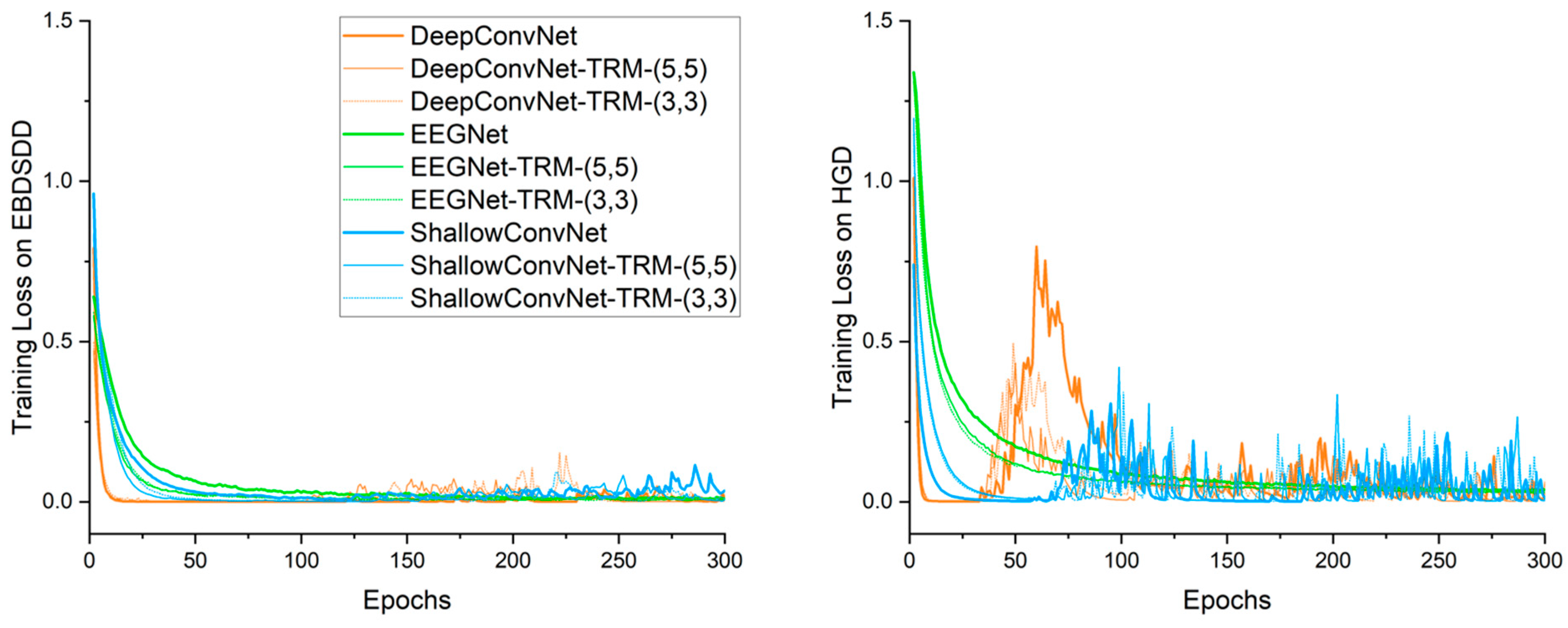
3.2. Training Loss
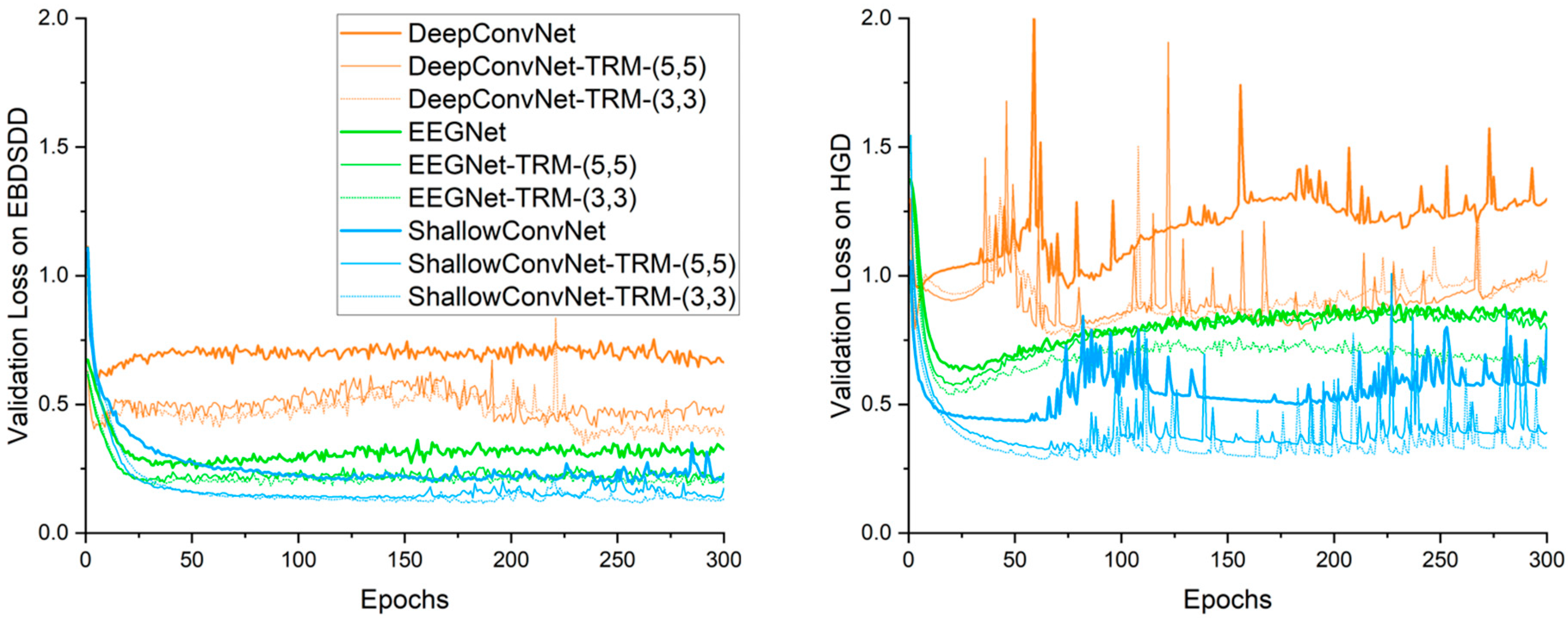
3.3. Validation Loss
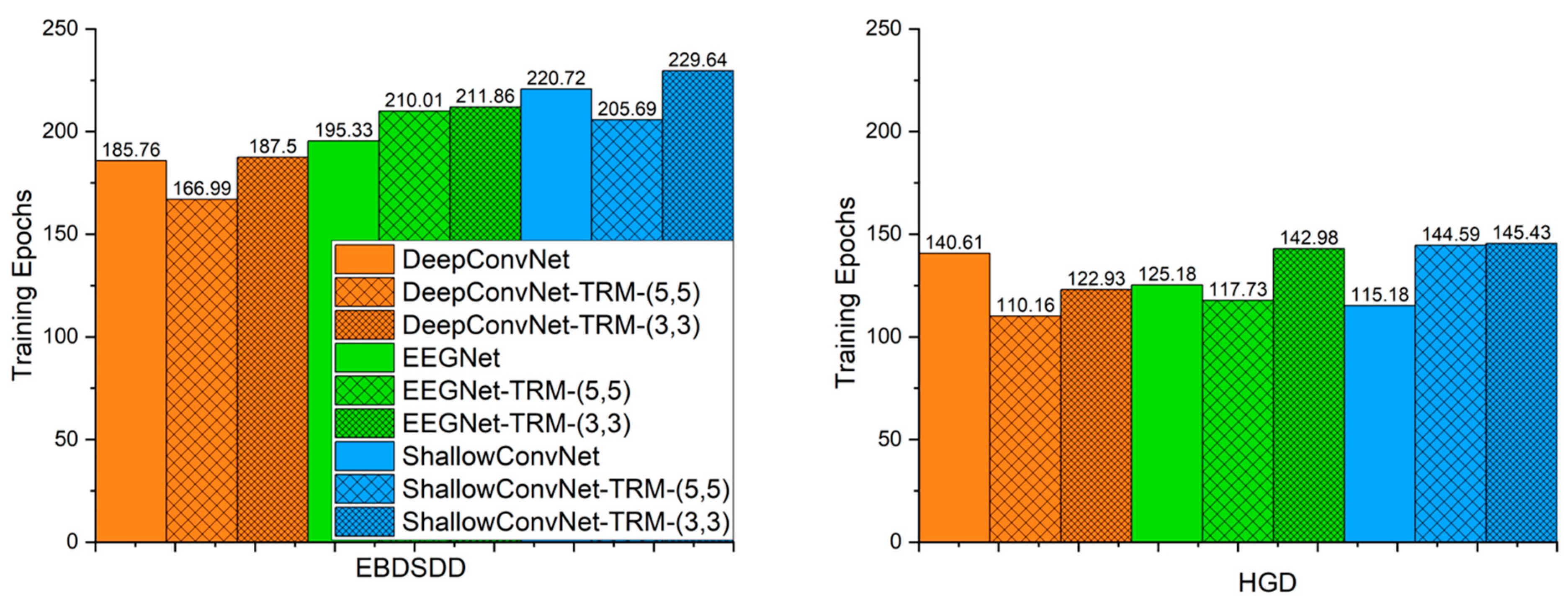
3.4. The Number of Training Epochs That Yields the Lowest Validation Loss
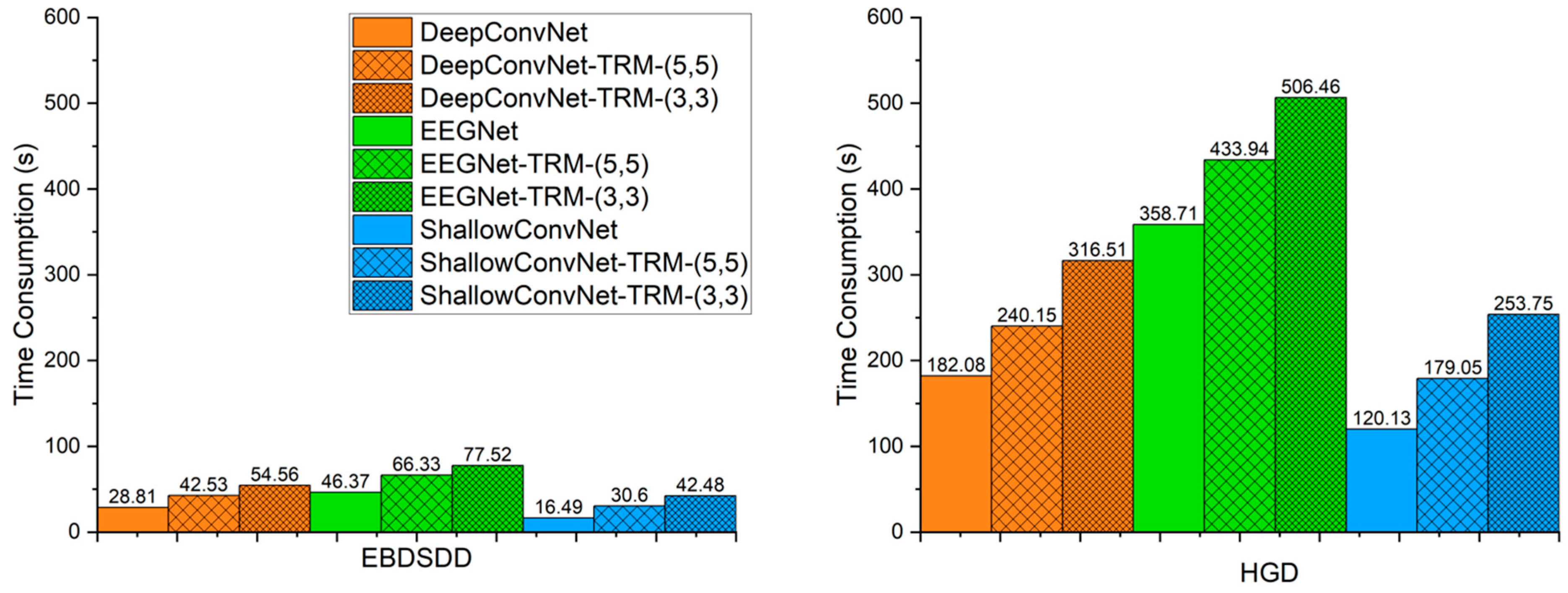
3.5. Time Consumption Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | TRM-(5,5) | TRM-(3,3) | ||
|---|---|---|---|---|
| Filter/(Kernel Size) | Output | Filter/(Kernel Size) | Output | |
| Input | ----- | (C = 55, TP = 280) | ----- | (C = 55, TP = 280) |
| Mapping | ----- | (7, 9, 280) | ----- | (7, 9, 280) |
| Resize | ----- | (280, 1, 7, 9) | ----- | (280, 1, 7, 9) |
| Conv3D | 55/(5, 5) | (280, 55, 3, 5) | 55/(3, 3) | (280, 55, 5, 7) |
| Conv3D | 55/(3, 5) | (280, 55, 1, 1) | 55/(3, 3) | (280, 55, 3, 5) |
| Conv3D | ----- | (280, 55, 1, 1) | 55/(3, 3) | (280, 55, 1, 3) |
| Conv3D | ----- | (280, 55, 1, 1) | 55/(1, 3) | (280, 55, 1, 1) |
| BatchNorm | ----- | (280, 55, 1, 1) | ----- | (280, 55, 1, 1) |
| Resize | ----- | (55, 280) | ----- | (55, 280) |
| Layer | TRM-(5,5) | TRM-(3,3) | ||
|---|---|---|---|---|
| Filter/(Kernel Size) | Output | Filter/(Kernel Size) | Output | |
| Input | ----- | (C = 44, TP = 1000) | ----- | (C = 44, TP = 1000) |
| Mapping | ----- | (7, 7, 1000) | ----- | (7, 7, 1000) |
| Resize | ----- | (1000, 1, 7, 7) | ----- | (1000, 1, 7, 7) |
| Conv3D | 44/(5, 5) | (1000, 44, 3, 3) | 44/(3, 3) | (1000, 44, 5, 5) |
| Conv3D | 44/(3, 3) | (1000, 44, 1, 1) | 44/(3, 3) | (1000, 44, 3, 3) |
| Conv3D | ----- | (1000, 44, 1, 1) | 44/(3, 3) | (1000, 44, 1, 1) |
| BatchNorm | ----- | (1000, 44, 1, 1) | ----- | (1000, 44, 1, 1) |
| Resize | ----- | (44, 1000) | ----- | (44, 1000) |
References
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain-computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef]
- Islam, M.S.; Hussain, I.; Rahman, M.M.; Park, S.J.; Hossain, M.A. Explainable Artificial Intelligence Model for Stroke Prediction Using EEG Signal. Sensors 2022, 22, 9859. [Google Scholar] [CrossRef]
- Hussain, I.; Park, S.J. HealthSOS: Real-Time Health Monitoring System for Stroke Prognostics. IEEE Access 2020, 8, 213574–213586. [Google Scholar] [CrossRef]
- Hussain, I.; Park, S.J. Quantitative Evaluation of Task-Induced Neurological Outcome after Stroke. Brain Sci. 2021, 11, 900. [Google Scholar] [CrossRef] [PubMed]
- Hussain, I.; Young, S.; Park, S.J. Driving-Induced Neurological Biomarkers in an Advanced Driver-Assistance System. Sensors 2021, 21, 6985. [Google Scholar] [CrossRef]
- Hussain, I.; Hossain, M.A.; Jany, R.; Bari, M.A.; Uddin, M.; Kamal, A.R.M.; Ku, Y.; Kim, J.S. Quantitative Evaluation of EEG-Biomarkers for Prediction of Sleep Stages. Sensors 2022, 22, 3079. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Wang, X.; Monaghan, J.; McAlpine, D.; Zhang, Y. A survey on deep learning-based non-invasive brain signals: Recent advances and new frontiers. J. Neural Eng. 2021, 18, 031002. [Google Scholar] [CrossRef]
- Bashashati, A.; Fatourechi, M.; Ward, R.K.; Birch, G.E. A survey of signal processing algorithms in brain-computer interfaces based on electrical brain signals. J. Neural Eng. 2007, 4, R32–R57. [Google Scholar] [CrossRef] [PubMed]
- Mcfarland, D.J.; Anderson, C.W.; Muller, K.R.; Schlogl, A.; Krusienski, D.J. BCI meeting 2005-workshop on BCI signal processing: Feature extraction and translation. IEEE Trans. Neural Syst. Rehabil. Eng. 2006, 14, 135–138. [Google Scholar] [CrossRef]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain-computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.-r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; He, F.; Wang, F.; Zhang, D.; Xia, Y.; Li, X. A Novel Simplified Convolutional Neural Network Classification Algorithm of Motor Imagery EEG Signals Based on Deep Learning. Appl. Sci. 2020, 10, 1605. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain-computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [PubMed]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Waytowich, N.; Lawhern, V.J.; Garcia, J.O.; Cummings, J.; Faller, J.; Sajda, P.; Vettel, J.M. Compact Convolutional Neural Networks for Classification of Asynchronous Steady-state Visual Evoked Potentials. J. Neural Eng. 2018, 15, 66031. [Google Scholar] [CrossRef]
- Liu, M.; Wu, W.; Gu, Z.; Yu, Z.; Qi, F.; Li, Y. Deep learning based on Batch Normalization for P300 signal detection. Neurocomputing 2018, 275, 288–297. [Google Scholar] [CrossRef]
- Riyad, M.; Khalil, M.; Adib, A. MI-EEGNET: A novel convolutional neural network for motor imagery classification. J. Neurosci. Methods 2021, 353, 109037. [Google Scholar] [CrossRef]
- Li, M.A.; Han, J.F.; Duan, L.J. A Novel MI-EEG Imaging with the Location Information of Electrodes. IEEE Access 2020, 8, 3197–3211. [Google Scholar] [CrossRef]
- Tang, Z.; Li, C.; Sun, S. Single-trial EEG classification of motor imagery using deep convolutional neural networks. Optik 2017, 130, 11–18. [Google Scholar] [CrossRef]
- Liu, T.; Yang, D. A Densely Connected Multi-Branch 3D Convolutional Neural Network for Motor Imagery EEG Decoding. Brain Sci. 2021, 11, 197. [Google Scholar] [CrossRef]
- Liu, X.; Shen, Y.; Liu, J.; Yang, J.; Xiong, P.; Lin, F. Parallel Spatial-Temporal Self-Attention CNN-Based Motor Imagery Classification for BCI. Front. Neurosci. 2020, 14, 587520. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Li, P.; Li, C.; Yao, D.; Zhang, R.; Xu, P. Separated channel convolutional neural network to realize the training free motor imagery BCI systems. Biomed. Signal Process. Control 2019, 49, 396–403. [Google Scholar] [CrossRef]
- Alwasiti, H.; Yusoff, M.Z.; Raza, K. Motor Imagery Classification for Brain Computer Interface Using Deep Metric Learning. IEEE Access 2020, 8, 109949–109963. [Google Scholar] [CrossRef]
- Dai, G.; Zhou, J.; Huang, J.; Wang, N. HS-CNN: A CNN with hybrid convolution scale for EEG motor imagery classification. J. Neural Eng. 2020, 17, 016025. [Google Scholar] [CrossRef]
- Lee, B.H.; Jeong, J.H.; Lee, S.W. SessionNet: Feature Similarity-Based Weighted Ensemble Learning for Motor Imagery Classification. IEEE Access 2020, 8, 134524–134535. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Z.; He, H. Hierarchical Convolutional Neural Networks for EEG-Based Emotion Recognition. Cogn. Comput. 2018, 10, 368–380. [Google Scholar] [CrossRef]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2021, 1–42. [Google Scholar] [CrossRef]
- Yang, J.; Ma, Z.; Wang, J.; Fu, Y. A Novel Deep Learning Scheme for Motor Imagery EEG Decoding Based on Spatial Representation Fusion. IEEE Access 2020, 8, 202100–202110. [Google Scholar] [CrossRef]
- Jeong, J.-H.; Lee, B.-H.; Lee, D.-H.; Yun, Y.-D.; Lee, S.-W. EEG Classification of Forearm Movement Imagery Using a Hierarchical Flow Convolutional Neural Network. IEEE Access 2020, 8, 66941–66950. [Google Scholar] [CrossRef]
- Fan, C.C.; Yang, H.; Hou, Z.G.; Ni, Z.L.; Chen, S.; Fang, Z. Bilinear neural network with 3-D attention for brain decoding of motor imagery movements from the human EEG. Cogn. Neurodyn. 2021, 15, 181–189. [Google Scholar] [CrossRef]
- Li, D.; Xu, J.; Wang, J.; Fang, X.; Ji, Y. A Multi-Scale Fusion Convolutional Neural Network Based on Attention Mechanism for the Visualization Analysis of EEG Signals Decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2615–2626. [Google Scholar] [CrossRef]
- Amin, S.U.; Alsulaiman, M.; Muhammad, G.; Mekhtiche, M.A.; Shamim Hossain, M. Deep Learning for EEG motor imagery classification based on multi-layer CNNs feature fusion. Future Gener. Comput. Syst. 2019, 101, 542–554. [Google Scholar] [CrossRef]
- Wu, H.; Niu, Y.; Li, F.; Li, Y.; Fu, B.; Shi, G.; Dong, M. A Parallel Multiscale Filter Bank Convolutional Neural Networks for Motor Imagery EEG Classification. Front. Neurosci. 2019, 13, 1275. [Google Scholar] [CrossRef] [PubMed]
- Haufe, S.; Treder, M.S.; Gugler, M.F.; Sagebaum, M.; Curio, G.; Blankertz, B. EEG potentials predict upcoming emergency brakings during simulated driving. J. Neural Eng. 2011, 8, 056001. [Google Scholar] [CrossRef] [PubMed]
- Avilov, O.; Rimbert, S.; Popov, A.; Bougrain, L. Optimizing Motor Intention Detection with Deep Learning: Towards Management of Intraoperative Awareness. IEEE Trans. Biomed. Eng. 2021, 68, 3087–3097. [Google Scholar] [CrossRef]
- Xu, L.; Xu, M.; Ma, Z.; Wang, K.; Jung, T.P.; Ming, D. Enhancing transfer performance across datasets for brain-computer interfaces using a combination of alignment strategies and adaptive batch normalization. J. Neural Eng. 2021, 18, 0460e5. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Meng, L.; Zhang, X.; Fang, W.; Wu, D. Universal adversarial perturbations for CNN classifiers in EEG-based BCIs. J. Neural Eng. 2021, 18, 0460a4. [Google Scholar] [CrossRef]
- Gemein, L.A.W.; Schirrmeister, R.T.; Chrabaszcz, P.; Wilson, D.; Boedecker, J.; Schulze-Bonhage, A.; Hutter, F.; Ball, T. Machine-learning-based diagnostics of EEG pathology. Neuroimage 2020, 220, 117021. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Liu, Y.; Zhou, Z.; Yu, Y.; Liang, X. Decoding Visual Motions from EEG Using Attention-Based RNN. Appl. Sci. 2020, 10, 5662. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, Y.; Lu, J.; Li, P. EEGNet With Ensemble Learning to Improve the Cross-Session Classification of SSVEP Based BCI From Ear-EEG. IEEE Access 2021, 9, 15295–15303. [Google Scholar] [CrossRef]
- Shi, R.; Zhao, Y.; Cao, Z.; Liu, C.; Kang, Y.; Zhang, J. Categorizing objects from MEG signals using EEGNet. Cogn. Neurodyn. 2021, 16, 365–377. [Google Scholar] [CrossRef]
- Zhao, H.; Yang, Y.; Karlsson, P.; McEwan, A. Can recurrent neural network enhanced EEGNet improve the accuracy of ERP classification task? An exploration and a discussion. Health Technol. 2020, 10, 979–995. [Google Scholar] [CrossRef]
- Tsukahara, A.; Anzai, Y.; Tanaka, K.; Uchikawa, Y. A design of EEGNet-based inference processor for pattern recognition of EEG using FPGA. Electron. Commun. Jpn. 2020, 104, 53–64. [Google Scholar] [CrossRef]
- Kostas, D.; Rudzicz, F. Thinker invariance: Enabling deep neural networks for BCI across more people. J. Neural Eng. 2020, 17, 056008. [Google Scholar] [CrossRef] [PubMed]
- Topic, A.; Russo, M. Emotion recognition based on EEG feature maps through deep learning network. Eng. Sci. Technol. Int. J. 2021, 24, 1442–1454. [Google Scholar] [CrossRef]
- Chao, H.; Dong, L.; Liu, Y.; Lu, B. Emotion Recognition from Multiband EEG Signals Using CapsNet. Sensors 2019, 19, 2212. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, H.; Zhu, G.; You, F.; Kuang, S.; Sun, L. A Multi-Branch 3D Convolutional Neural Network for EEG-Based Motor Imagery Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 2164–2177. [Google Scholar] [CrossRef] [PubMed]
- Liao, J.J.; Luo, J.J.; Yang, T.; So, R.Q.Y.; Chua, M.C.H. Effects of local and global spatial patterns in EEG motor-imagery classification using convolutional neural network. Brain Comput. Interfaces 2020, 7, 47–56. [Google Scholar] [CrossRef]
- Li, Y.; Huang, J.; Zhou, H.; Zhong, N. Human Emotion Recognition with Electroencephalographic Multidimensional Features by Hybrid Deep Neural Networks. Appl. Sci. 2017, 7, 1060. [Google Scholar] [CrossRef]
- Xu, M.; Yao, J.; Zhang, Z.; Li, R.; Yang, B.; Li, C.; Li, J.; Zhang, J. Learning EEG topographical representation for classification via convolutional neural network. Pattern Recognit. 2020, 105, 107390. [Google Scholar] [CrossRef]







| Subject | DeepConvNet | EEGNet | ShallowConvNet | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Original | TRM-(5,5) | TRM-(3,3) | Original | TRM-(5,5) | TRM-(3,3) | Original | TRM-(5,5) | TRM-(3,3) | |
| VPae | 75.82 ± 4.10 | 84.78 ± 4.78 | 82.61 ± 3.20 | 90.22 ± 2.35 | 92.93 ± 4.21 | 94.02 ± 3.26 | 86.96 ± 3.97 | 91.85 ± 2.59 | 91.85 ± 2.08 |
| VPbad | 88.51 ± 2.79 | 95.27 ± 2.88 | 96.17 ± 1.35 | 95.05 ± 2.14 | 97.97 ± 1.35 | 97.97 ± 1.54 | 93.02 ± 4.79 | 97.75 ± 2.27 | 98.65 ± 0.52 |
| VPbax | 83.77 ± 2.09 | 91.89 ± 2.99 | 93.64 ± 1.95 | 90.57 ± 2.52 | 92.32 ± 1.50 | 94.74 ± 1.89 | 94.74 ± 1.60 | 95.39 ± 1.81 | 94.30 ± 1.68 |
| VPbba | 55.82 ± 9.58 | 78.42 ± 3.24 | 83.22 ± 7.53 | 88.70 ± 4.53 | 91.44 ± 1.72 | 91.44 ± 3.60 | 84.93 ± 4.88 | 90.75 ± 1.72 | 91.10 ± 2.37 |
| VPdx | 81.19 ± 3.70 | 91.09 ± 3.13 | 96.78 ± 1.69 | 91.83 ± 3.74 | 94.55 ± 0.99 | 93.32 ± 2.20 | 93.32 ± 1.49 | 96.29 ± 3.47 | 97.03 ± 2.91 |
| VPgaa | 94.70 ± 3.81 | 97.67 ± 1.07 | 98.09 ± 1.07 | 98.94 ± 0.42 | 98.52 ± 0.42 | 98.09 ± 1.60 | 97.25 ± 1.45 | 98.52 ± 0.81 | 98.09 ± 0.81 |
| VPgab | 88.89 ± 2.51 | 93.98 ± 1.60 | 94.21 ± 2.19 | 94.91 ± 1.93 | 96.30 ± 0.76 | 94.68 ± 2.87 | 96.99 ± 1.58 | 97.92 ± 1.17 | 96.99 ± 1.17 |
| VPgac | 91.52 ± 3.14 | 95.09 ± 0.89 | 95.54 ± 2.19 | 96.88 ± 1.15 | 97.77 ± 0.89 | 97.77 ± 0.52 | 97.32 ± 1.63 | 97.99 ± 1.69 | 97.99 ± 1.12 |
| VPgae | 87.28 ± 3.69 | 88.82 ± 4.14 | 89.47 ± 3.43 | 90.57 ± 4.38 | 92.98 ± 2.48 | 91.89 ± 4.01 | 86.84 ± 2.77 | 87.28 ± 2.09 | 91.45 ± 3.68 |
| VPgag | 89.95 ± 4.19 | 96.81 ± 2.70 | 98.04 ± 0.80 | 95.83 ± 2.58 | 98.04 ± 1.39 | 98.04 ± 1.39 | 95.83 ± 1.47 | 97.06 ± 0.80 | 97.79 ± 0.94 |
| VPgah | 81.45 ± 4.92 | 86.56 ± 4.16 | 89.52 ± 7.97 | 91.13 ± 2.22 | 92.47 ± 3.04 | 92.74 ± 3.09 | 91.13 ± 2.69 | 93.55 ± 2.15 | 91.94 ± 1.39 |
| VPgal | 80.69 ± 2.97 | 84.90 ± 1.87 | 89.60 ± 2.49 | 93.81 ± 2.73 | 94.06 ± 0.81 | 92.82 ± 2.04 | 94.31 ± 1.25 | 94.80 ± 1.69 | 95.30 ± 1.69 |
| VPgam | 84.52 ± 3.05 | 90.95 ± 2.96 | 91.43 ± 3.21 | 92.86 ± 2.96 | 94.76 ± 3.16 | 93.81 ± 2.27 | 92.38 ± 3.01 | 95.71 ± 1.23 | 95.48 ± 0.91 |
| VPih | 81.37 ± 8.49 | 89.86 ± 3.64 | 91.04 ± 3.57 | 93.63 ± 1.94 | 95.05 ± 2.36 | 96.70 ± 1.81 | 95.05 ± 2.82 | 95.52 ± 1.61 | 96.23 ± 0.77 |
| VPii | 95.91 ± 1.29 | 97.63 ± 1.29 | 97.84 ± 0.50 | 97.63 ± 0.83 | 98.92 ± 0.43 | 99.35 ± 0.83 | 98.28 ± 0.70 | 98.71 ± 0.50 | 98.49 ± 0.83 |
| VPja | 89.56 ± 3.91 | 91.99 ± 3.21 | 93.45 ± 3.30 | 93.20 ± 2.38 | 95.87 ± 2.43 | 95.87 ± 0.93 | 95.87 ± 0.93 | 96.60 ± 2.02 | 95.15 ± 2.10 |
| VPsaj | 94.44 ± 2.62 | 95.14 ± 2.66 | 93.98 ± 1.20 | 95.37 ± 0.76 | 96.99 ± 1.58 | 95.60 ± 1.91 | 96.76 ± 0.93 | 97.45 ± 1.17 | 97.69 ± 1.60 |
| VPsal | 70.43 ± 7.21 | 82.69 ± 5.03 | 80.77 ± 3.42 | 89.90 ± 2.29 | 91.11 ± 1.98 | 93.03 ± 1.98 | 86.78 ± 5.79 | 91.83 ± 2.29 | 91.35 ± 1.36 |
| Average | 84.21 | 90.75 | 91.97 | 93.39 | 95.11 | 95.10 | 93.21 | 95.28 | 95.38 |
| p value | ----- | 4.54 × 10−5 | 5.71 × 10−5 | ----- | 3.90 × 10−7 | 1.71 × 10−4 | ----- | 2.43 × 10−4 | 6.69 × 10−4 |
| Subject | DeepConvNet | EEGNet | ShallowConvNet | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Original | TRM-(5,5) | TRM-(3,3) | Original | TRM-(5,5) | TRM-(3,3) | Original | TRM-(5,5) | TRM-(3,3) | |
| S1 | 57.81 ± 3.70 | 62.81 ± 3.77 | 63.91 ± 1.56 | 54.84 ± 6.28 | 58.75 ± 3.31 | 56.72 ± 5.87 | 67.34 ± 1.72 | 72.66 ± 1.72 | 77.81 ± 4.22 |
| S2 | 70.78 ± 2.19 | 69.84 ± 2.62 | 73.91 ± 1.72 | 71.72 ± 3.44 | 73.13 ± 2.34 | 77.34 ± 2.41 | 79.53 ± 1.56 | 82.97 ± 1.80 | 81.25 ± 2.22 |
| S3 | 83.13 ± 7.09 | 90.16 ± 1.48 | 92.03 ± 3.20 | 92.81 ± 1.57 | 95.31 ± 0.81 | 96.72 ± 1.29 | 95.16 ± 1.07 | 95.31 ± 0.81 | 95.00 ± 1.53 |
| S4 | 84.06 ± 4.64 | 90.00 ± 2.75 | 87.34 ± 6.52 | 93.44 ± 1.88 | 95.47 ± 1.29 | 97.50 ± 1.35 | 96.09 ± 0.60 | 97.03 ± 1.29 | 97.81 ± 0.81 |
| S5 | 62.97 ± 5.16 | 67.66 ± 5.14 | 82.50 ± 7.12 | 70.16 ± 8.53 | 72.97 ± 4.55 | 81.88 ± 8.52 | 81.25 ± 4.89 | 90.16 ± 1.29 | 89.06 ± 2.31 |
| S6 | 57.97 ± 2.19 | 70.63 ± 5.66 | 65.47 ± 4.19 | 74.84 ± 3.83 | 85.47 ± 1.72 | 78.28 ± 9.39 | 86.09 ± 1.39 | 91.88 ± 0.88 | 92.03 ± 1.56 |
| S7 | 59.69 ± 3.48 | 67.66 ± 4.69 | 68.28 ± 1.93 | 65.31 ± 6.05 | 69.53 ± 4.00 | 71.41 ± 5.26 | 75.16 ± 0.94 | 81.09 ± 5.74 | 84.38 ± 4.27 |
| S8 | 72.66 ± 2.00 | 75.47 ± 2.57 | 74.69 ± 3.33 | 75.16 ± 1.39 | 82.81 ± 5.92 | 83.75 ± 5.47 | 81.25 ± 3.78 | 87.34 ± 3.69 | 92.19 ± 2.58 |
| S9 | 47.51 ± 7.98 | 69.84 ± 4.00 | 70.00 ± 3.99 | 76.56 ± 8.50 | 68.75 ± 6.88 | 84.84 ± 8.07 | 78.75 ± 2.10 | 76.88 ± 2.98 | 85.63 ± 2.93 |
| S10 | 78.91 ± 1.39 | 84.22 ± 0.79 | 76.09 ± 3.12 | 84.22 ± 3.80 | 87.34 ± 2.30 | 86.88 ± 3.02 | 85.47 ± 2.99 | 89.69 ± 0.81 | 89.22 ± 0.31 |
| S11 | 62.66 ± 2.99 | 60.00 ± 5.71 | 68.28 ± 6.38 | 73.44 ± 6.30 | 75.66 ± 7.45 | 79.38 ± 8.12 | 78.28 ± 3.97 | 96.72 ± 1.07 | 95.31 ± 1.80 |
| S12 | 80.94 ± 4.69 | 78.91 ± 0.60 | 79.69 ± 4.13 | 82.19 ± 5.27 | 85.16 ± 2.86 | 86.88 ± 3.85 | 88.59 ± 2.86 | 92.03 ± 1.64 | 91.09 ± 0.31 |
| S13 | 59.38 ± 4.59 | 65.63 ± 3.35 | 67.81 ± 3.17 | 75.78 ± 1.18 | 80.94 ± 4.75 | 77.81 ± 6.30 | 79.06 ± 3.77 | 87.66 ± 1.56 | 85.47 ± 3.48 |
| S14 | 60.78 ± 5.96 | 71.09 ± 5.04 | 75.78 ± 7.15 | 80.31 ± 4.10 | 81.72 ± 8.83 | 82.19 ± 6.13 | 73.59 ± 4.96 | 76.09 ± 3.48 | 77.34 ± 2.72 |
| Average | 67.09 | 73.14 | 74.70 | 76.48 | 79.50 | 81.54 | 81.83 | 86.97 | 88.11 |
| p value | ----- | 3.73 × 10−3 | 1.75 × 10−3 | ----- | 0.015 | 1.95 × 10−5 | ----- | 1.72 × 10−3 | 2.04 × 10−4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, X.; Liu, Y.; Yu, Y.; Liu, K.; Liu, Y.; Zhou, Z. Convolutional Neural Network with a Topographic Representation Module for EEG-Based Brain—Computer Interfaces. Brain Sci. 2023, 13, 268. https://doi.org/10.3390/brainsci13020268
Liang X, Liu Y, Yu Y, Liu K, Liu Y, Zhou Z. Convolutional Neural Network with a Topographic Representation Module for EEG-Based Brain—Computer Interfaces. Brain Sciences. 2023; 13(2):268. https://doi.org/10.3390/brainsci13020268
Chicago/Turabian StyleLiang, Xinbin, Yaru Liu, Yang Yu, Kaixuan Liu, Yadong Liu, and Zongtan Zhou. 2023. "Convolutional Neural Network with a Topographic Representation Module for EEG-Based Brain—Computer Interfaces" Brain Sciences 13, no. 2: 268. https://doi.org/10.3390/brainsci13020268
APA StyleLiang, X., Liu, Y., Yu, Y., Liu, K., Liu, Y., & Zhou, Z. (2023). Convolutional Neural Network with a Topographic Representation Module for EEG-Based Brain—Computer Interfaces. Brain Sciences, 13(2), 268. https://doi.org/10.3390/brainsci13020268