


Deep Learning for Improving the Effectiveness of Routine Prenatal Screening for Major Congenital Heart Diseases

 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
- To propose a DL model for classifying eight-class of congenital heart diseases; seven CHDs, such as ASD, VSD, AVSD, EA, TOF, TGA, HLHS, and one control as Normal;
- To extract relevant frames from the normal control (NC) and CHD US video based on an apical four-chamber view (4CV) standard plane;
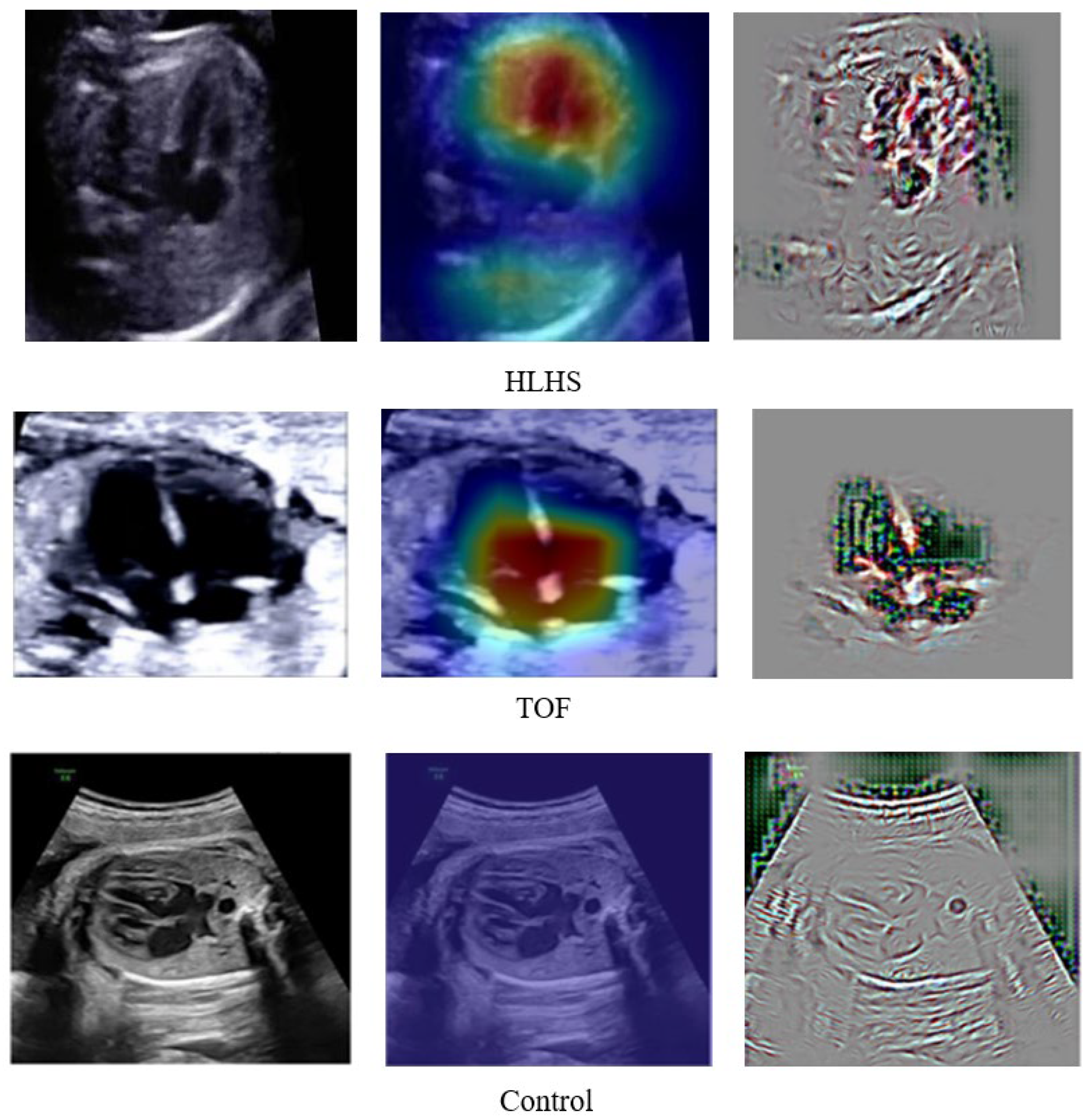
- To produce the explainable classification result with a combination of gradient activation mapping and guided backpropagation;
- To compare the prediction performance of the proposed model against three expert fetal cardiologist’s interpretations;
- To evaluate the DL model with intra-patient and inter-patient scenarios.
2. Materials and Methods
2.1. Data Preparation
2.2. Characteristics of the Research Subject
2.3. Proposed CHD Classification Architecture
2.4. Model Evaluation
3. Results and Discussion
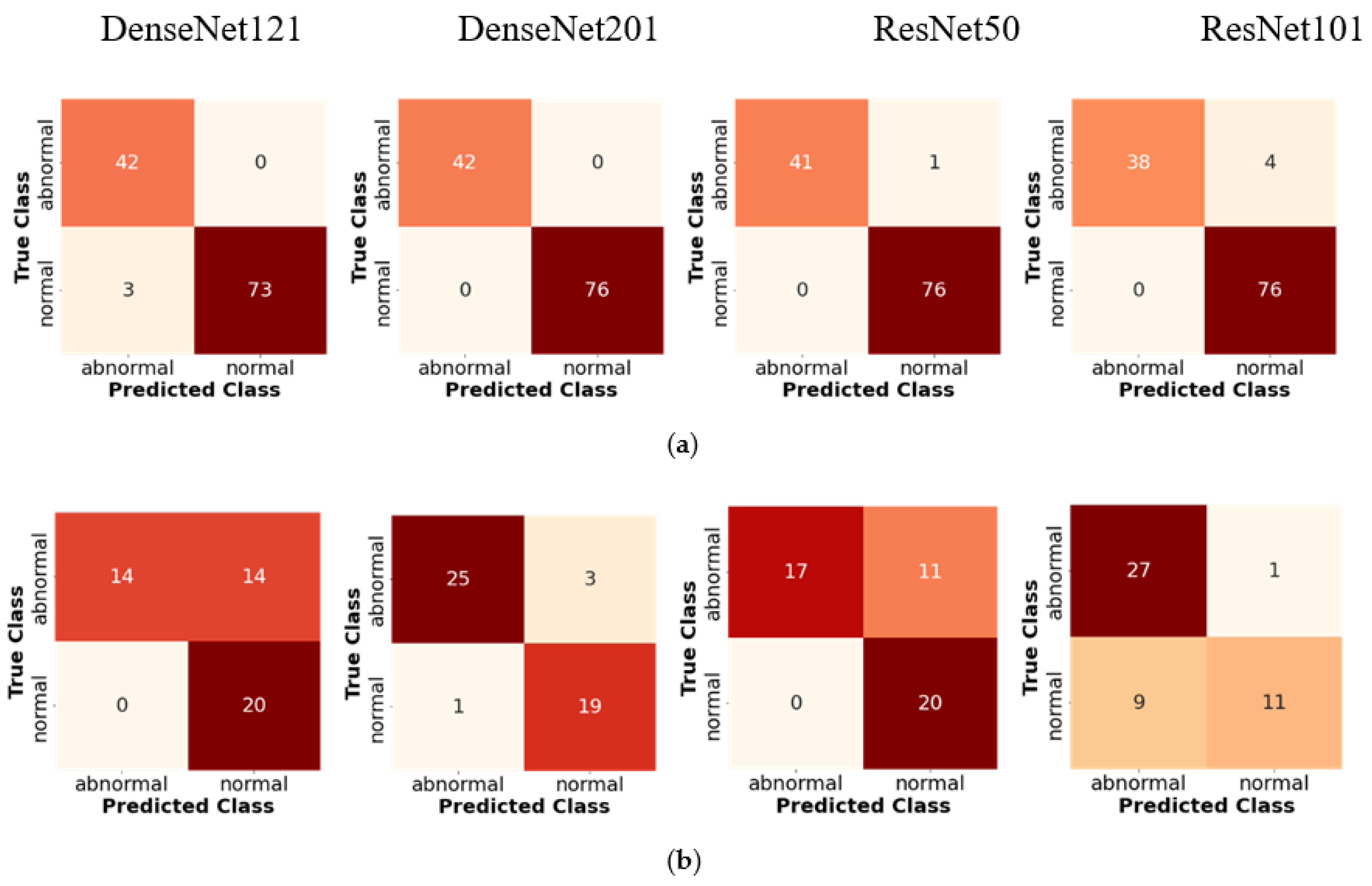
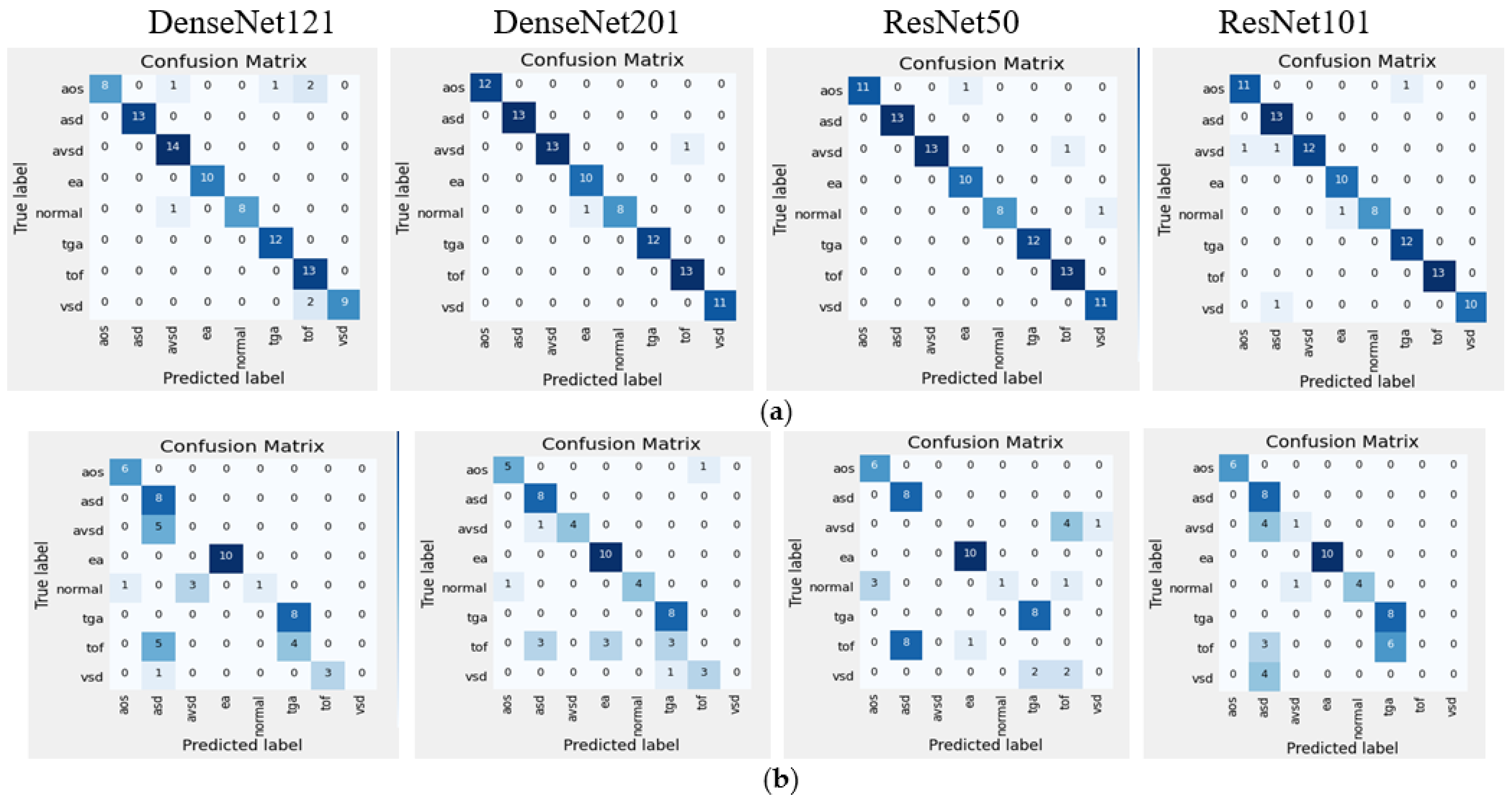
3.1. The Classifier Performance
3.2. Improving Classifier Performance by Data Augmentation
3.3. Deep Learning against Fetal Expert Cardiologists
3.4. Proposed DenseNet201 Model against State-of-the-Art
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, Y.; McGeoch, L. Fetal anomaly screening for detection of congenital heart defects. J. Neonatal. Biol. 2016, 5, 100e115. [Google Scholar] [CrossRef] [Green Version]
- Yoon, S.A.; Hong, W.H.; Cho, H.J. Congenital heart disease diagnosed with echocardiogram in newborns with asymptomatic cardiac murmurs: A systematic review. BMC Pediatr. 2020, 20, 322. [Google Scholar] [CrossRef] [PubMed]
- Puri, K.; Allen, H.D.; Qureshi, A.M. Congenital Heart Disease. Pediatr. Rev. 2017, 38, 471–486. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Backer, C.L.; Eltayeb, O.; Mongé, M.C.; Mazwi, M.L.; Costello, J.M. Shunt Lesions Part I: Patent Ductus Arteriosus, Atrial Septal Defect, Ventricular Septal Defect, and Atrioventricular Septal Defect. Pediatr. Crit. Care Med. 2016, 17 (Suppl. 1), S302–S309. [Google Scholar] [CrossRef]
- Norton, M.E. Callen’s Ultrasonography in Obstetrics and Gynecology; Elsevier Health Sciences: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Donofrio, M.T.; Moon-Grady, A.J.; Hornberger, L.K.; Copel, J.A.; Sklansky, M.S.; Abuhamad, A.; Cuneo, B.F.; Huhta, J.C.; Jonas, R.A.; Krishnan, A.; et al. Diagnosis and treatment of fetal cardiac disease: A scientific statement from the American Heart Association. Circulation 2014, 129, 2183–2242. [Google Scholar] [CrossRef] [Green Version]
- Sekar, P.; Heydarian, H.C.; Cnota, J.F.; Hornberger, L.K.; Michelfelder, E.C. Diagnosis of congenital heart disease in an era of universal prenatal ultrasound screening in southwest Ohio. Cardiol. Young 2015, 25, 35–41. [Google Scholar] [CrossRef]
- Friedberg, M.; Silverman, N.H.; Moon-Grady, A.J.; Tong, E.; Nourse, J.; Sorenson, B.; Lee, J.; Hornberger, L.K. Prenatal detection of congenital heart disease. J. Pediatr. 2009, 155, 26–31. [Google Scholar] [CrossRef]
- Arnaout, R.; Curran, L.; Zhao, Y.; Levine, J.C.; Chinn, E.; Moon-Grady, A.J. An ensemble of neural networks provides expert-level prenatal detection of complex congenital heart disease. Nat. Med. 2021, 27, 882–891. [Google Scholar] [CrossRef]
- Burgos-Artizzu, X.P.; Coronado-Gutiérrez, D.; Valenzuela-Alcaraz, B.; Bonet-Carne, E.; Eixarch, E.; Crispi, F.; Gratacós, E. Evaluation of deep convolutional neural networks for automatic classification of common maternal fetal ultrasound planes. Sci. Rep. 2020, 10, 10200. [Google Scholar] [CrossRef]
- Nurmaini, S.; Rachmatullah, M.N.; Sapitri, A.I.; Darmawahyuni, A.; Tutuko, B.; Firdaus, F.; Partan, R.U.; Bernolian, N. Deep Learning-Based Computer-Aided Fetal Echocardiography: Application to Heart Standard View Segmentation for Congenital Heart Defects Detection. Sensors 2021, 21, 8007. [Google Scholar] [CrossRef]
- Nurmaini, S.; Rachmatullah, M.N.; Sapitri, A.I.; Darmawahyuni, A.; Jovandy, A.; Firdaus, F.; Tutuko, B.; Passarella, R. Accurate Detection of Septal Defects With Fetal Ultrasonography Images Using Deep Learning-Based Multiclass Instance Segmentation. IEEE Access 2020, 8, 196160–196174. [Google Scholar] [CrossRef]
- Qiao, S.; Pang, S.; Luo, G.; Pan, S.; Yu, Z.; Chen, T.; Lv, Z. RLDS: An explainable residual learning diagnosis system for fetal congenital heart disease. Futur. Gener. Comput. Syst. 2022, 128, 205–218. [Google Scholar] [CrossRef]
- Ammirato, P.; Berg, A.C. A Mask-RCNN Baseline for Probabilistic Object Detection. arXiv 2019, arXiv:1908.03621. [Google Scholar]
- Gong, Y.; Zhang, Y.; Zhu, H.; Lv, J.; Cheng, Q.; Zhang, H.; He, H.Z.Y.; Wang, S. Fetal Congenital Heart Disease Echocardiogram Screening Based on DGACNN: Adversarial One-Class Classification Combined with Video Transfer Learning. IEEE Trans. Med. Imaging 2019, 39, 1206–1222. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Liu, Z.; Du, M.; Wang, Z. Artificial intelligence in obstetric ultrasound: An update and future applications. Front. Med. 2021, 1431. [Google Scholar] [CrossRef]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Sakai, A.; Komatsu, M.; Komatsu, R.; Matsuoka, R.; Yasutomi, S.; Dozen, A.; Shozu, K.; Arakaki, T.; Machino, H.; Asada, K.; et al. Medical professional enhancement using explainable artificial intelligence in fetal cardiac ultrasound screening. Biomedicines 2022, 10, 551. [Google Scholar] [CrossRef]
- Nurmaini, S.; Tama, B.A.; Rachmatullah, M.N.; Darmawahyuni, A.; Sapitri, A.I.; Firdaus, F.; Tutuko, B. An improved semantic segmentation with region proposal network for cardiac defect interpretation. Neural Comput. Appl. 2022, 34, 13937–13950. [Google Scholar] [CrossRef]
- Morris, S.A.; Lopez, K.N. Deep learning for detecting congenital heart disease in the fetus. Nat. Med. 2021, 27, 764–765. [Google Scholar] [CrossRef]
- Garcia-Canadilla, P.; Sanchez-Martinez, S.; Crispi, F.; Bijnens, B. Machine Learning in Fetal Cardiology: What to Expect. Fetal Diagn. Ther. 2020, 47, 363–372. [Google Scholar] [CrossRef]
- Zhang, C.; Benz, P.; Argaw, D.M.; Lee, S.; Kim, J.; Rameau, F.; Bazin, J.C.; Kweon, I.S. Resnet or densenet? introducing dense shortcuts to resnet. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 3550–3559. [Google Scholar]
- Van der Velden, B.H.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med. Image Anal. 2022, 102470. [Google Scholar] [CrossRef] [PubMed]
- Arnaout, R.; Curran, L.; Zhao, Y.; Levine, J.C.; Chinn, E.; Moon-Grady, A.J. Expert-level prenatal detection of complex congenital heart disease from screening ultrasound using deep learning. medRxiv 2020. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Data | Seven Diseases | Normal | Total |
|---|---|---|---|
| Unique patient | 31 | 45 | 76 |
| Frames for training (intra-patient) | 812 | 157 | 969 |
| Frames for testing (intra-patient) | 140 | 20 | 160 |
| Frames for testing (inter-patient) | 50 | 5 | 55 |
| Normal Control | Cases | |||
|---|---|---|---|---|
| Frequency (n) | Percentage (%) | |||
| Age | ||||
| 20–35 year | 19 | 79.17 | 45 | 80.36 |
| >35 years | 5 | 20.83 | 11 | 19.64 |
| Body Massa index (BMI) | ||||
| Normoweight | 5 | 20.83 | 12 | 21.43 |
| Abnormal weight | 19 | 79.17 | 44 | 78.57 |
| Trimester | ||||
| second | 13 | 54.2 | 22 | 39.3 |
| third | 11 | 45.8 | 34 | 60.7 |
| Gestation | ||||
| 1–4 | 23 | 95.83 | 46 | 82.14 |
| >4 | 1 | 4.17 | 10 | 17.86 |
| Parity | ||||
| 0 | 9 | 37.5 | 13 | 23.21 |
| 1–4 | 15 | 62.5 | 40 | 71.43 |
| >4 | 0 | 0 | 3 | 5.36 |
| Metrics | Class | Performance (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DenseNet121 | DenseNet201 | ResNet50 | ResNet101 | ||||||
| Intra | Inter | Intra | Inter | Intra | Inter | Intra | Inter | ||
| Accuracy | CHDs | 97 | 67 | 100 | 93 | 99 | 76 | 95 | 84 |
| Normal | 98 | 74 | 100 | 90 | 99 | 78 | 97 | 69 | |
| Sensitivity | CHDs | 93 | 100 | 100 | 96 | 98 | 100 | 90 | 96 |
| Normal | 100 | 59 | 100 | 86 | 100 | 61 | 100 | 55 | |
| Specificity | CHDs | 100 | 50 | 100 | 89 | 100 | 65 | 100 | 75 |
| Normal | 96 | 100 | 100 | 95 | 99 | 100 | 95 | 92 | |
| Metrics | Average Performance (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| DenseNet121 | DenseNet201 | ResNet50 | ResNet101 | |||||
| Intra | Inter | Intra | Inter | Intra | Inter | Intra | Inter | |
| Accuracy | 97 | 71 | 100 | 92 | 97 | 77 | 97 | 79 |
| Sensitivity | 97 | 79 | 100 | 91 | 95 | 80 | 95 | 76 |
| Specificity | 98 | 75 | 100 | 92 | 98 | 82 | 96 | 83 |
| Metrics | Average Performance (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| DenseNet121 | DenseNet201 | ResNet50 | ResNet101 | |||||
| Intra | Inter | Intra | Inter | Intra | Inter | Intra | Inter | |
| Accuracy | 93 | 60 | 98 | 71 | 97 | 60 | 95 | 67 |
| Sensitivity | 87 | 49 | 90 | 62 | 88 | 48 | 89 | 56 |
| Specificity | 90 | 53 | 98 | 68 | 97 | 53 | 95 | 62 |
| Metrics | DenseNet201′s Performance (%) | |||
|---|---|---|---|---|
| Before Augmentation | After Augmentation | |||
| Intra-Patient | Inter-Patient | Intra-Patient | Inter-Patient | |
| Accuracy | 98 | 71 | 100 | 99 |
| Sensitivity | 90 | 62 | 100 | 97 |
| Specificity | 98 | 68 | 100 | 98 |
| Interpretation | Actual Label | Total | Kappa Value | ||
|---|---|---|---|---|---|
| CHDs | Normal | ||||
| Expert 1 | CHDs | 765 (99.74%) | 2 (0.26%) | 767 | 0.912 |
| Normal | 69 (8.27%) | 766 (91.73%) | 835 | ||
| Expert 2 | CHDs | 709 (92.43%) | 58 (7.57%) | 767 | 0.540 |
| Normal | 318 (37.77%) | 524 (62.23%) | 842 | ||
| Expert 3 | CHDs | 748 (97.52%) | 19 (2.48%) | 767 | 0.669 |
| Normal | 250 (29.69%) | 592 (70.31%) | 842 | ||
| Method | Class | Data Validation | Performance (%) | ||
|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | |||
| Ensemble Neural Network [9] | 2 classes (normal vs. and HLHS) | intra-patient | - | 89 | 92 |
| 2 classes (normal vs. TOF) | intra-patient | - | 71 | 89 | |
| Residual learning [13] | 2 classes (normal vs. CHDs including HRHS, HLHS, highly RAS) | intra-patient | 93 | 93 | - |
| 2 classes (normal vs. CHDs including HRHS, HLHS, highly RAS) | inter-patient | 91 | 91 | - | |
| Deep learning model [14] | 2 classes (normal vs. TOF) | intra-patient | - | 75 | 76 |
| 2 classes (normal vs. HLHS) | intra-patient | - | 100 | 90 | |
| DGACNN [15] | 2 classes (normal vs. CHD) | intra-patient | 85 | - | - |
| Proposed | 2 classes (normal vs. CHDs including ASD, VSD, AVSD, EA, TOF, TGA, HLHS) | intra-patient | 100 | 100 | 100 |
| 2 classes (normal vs. CHDs ASD, VSD, AVSD, EA, TOF, TGA, HLHS) | inter-patient | 92 | 91 | 92 | |
| 8 classes (normal, CHDs ASD, VSD, AVSD, EA, TOF, TGA, HLHS) | inter-patient before augmentation | 71 | 62 | 68 | |
| 8 classes (normal, CHDs ASD, VSD, AVSD, EA, TOF, TGA, HLHS) | Inter-patient after augmentation | 99 | 97 | 98 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nurmaini, S.; Partan, R.U.; Bernolian, N.; Sapitri, A.I.; Tutuko, B.; Rachmatullah, M.N.; Darmawahyuni, A.; Firdaus, F.; Mose, J.C. Deep Learning for Improving the Effectiveness of Routine Prenatal Screening for Major Congenital Heart Diseases. J. Clin. Med. 2022, 11, 6454. https://doi.org/10.3390/jcm11216454
Nurmaini S, Partan RU, Bernolian N, Sapitri AI, Tutuko B, Rachmatullah MN, Darmawahyuni A, Firdaus F, Mose JC. Deep Learning for Improving the Effectiveness of Routine Prenatal Screening for Major Congenital Heart Diseases. Journal of Clinical Medicine. 2022; 11(21):6454. https://doi.org/10.3390/jcm11216454
Chicago/Turabian StyleNurmaini, Siti, Radiyati Umi Partan, Nuswil Bernolian, Ade Iriani Sapitri, Bambang Tutuko, Muhammad Naufal Rachmatullah, Annisa Darmawahyuni, Firdaus Firdaus, and Johanes C. Mose. 2022. "Deep Learning for Improving the Effectiveness of Routine Prenatal Screening for Major Congenital Heart Diseases" Journal of Clinical Medicine 11, no. 21: 6454. https://doi.org/10.3390/jcm11216454
APA StyleNurmaini, S., Partan, R. U., Bernolian, N., Sapitri, A. I., Tutuko, B., Rachmatullah, M. N., Darmawahyuni, A., Firdaus, F., & Mose, J. C. (2022). Deep Learning for Improving the Effectiveness of Routine Prenatal Screening for Major Congenital Heart Diseases. Journal of Clinical Medicine, 11(21), 6454. https://doi.org/10.3390/jcm11216454