1. Introduction
Laryngeal cancer is one of the most debilitating forms of malignancy, with an average incidence of 3.3 per 100,000 from 2012 to 2016 in the USA [
1]. In 2019, there were 12,370 new cases diagnosed in the USA alone. Despite the rising incidence, early diagnosis remains challenging, resulting in delayed treatment [
2,
3]. With a delay of diagnosis, laryngeal cancer may lead to the most severe debilitating disabilities in phonation, swallowing [
4] and overall quality of life. An automated voice analysis tool could advance the time of diagnosis regardless of patients’ location, in line with the idea of telemedicine. Though voice changes can indicate the first clinical signs of disease, subjective perception of early voice changes can be listener dependent and subject to intrajudge variations [
5].
Image analysis based on the use of computational algorithms in radiology is now expanding to signal processing in other fields such as electrodiagnosis [
6]. Furthermore, the popularity of these new techniques has led to the use of automated detection of pathological voices using machine and deep learning algorithms. A voice pathology detection was reported successful using a deep learning model [
7]. Algorithms based on feature extraction, such as the Mel-frequency cepstral coefficients (MFCCs) from the acoustic signals have been used for many years to detect vocal fold disorders and dysphonia [
8,
9,
10]. For example, Chuang et al. [
9] have used normalized MFCCs features and have shown that a deep neural network (DNN) can detect abnormal voice changes in voice disorders. Another study by Fang et al. [
10], which included laryngeal cancer data, have reported that the results of a DNN were superior to other machine learning algorithms.
However, in past studies, the number of cancer patients was either too small [
10,
11] or often assessed as a single group together with other voice disorders. Most recent studies that investigated the role of automatic detection of voice disorders [
8,
9,
10] were based on open voice databases such as the Massachusetts Eye and Ear Infirmary Database [
12] or Saarbrucken Voice Database [
13], and laryngeal cancer voices were rated together as one group in combination with other voice disorders. In addition, past algorithms have not been validated against the clinicians’ judgement of voice change. Subjective perception of early voice changes can be difficult [
5]. The possibility of an algorithm that can distinguish pathological voice changes at the early stages in laryngeal cancer from normal healthy voices with the potential to overcome the limitations imposed by inter-subject human perception remains to be explored.
Therefore, this study aims to investigate the role of computational algorithms including a support vector machine (SVM), extreme gradient boosting (XGBoost) and the recent popular convolutional neural network (CNN) in distinguishing voice signals of patients with laryngeal cancer against those obtained from healthy subjects. We also compared the performance levels of these algorithms to those obtained by four human raters who rated the same voice files.
2. Materials and Methods
2.1. Study Subjects
A retrospective review of medical records was performed at a single university center from July 2015 to June 2019. We identified patients who had undergone voice assessments at the time of laryngeal cancer diagnosis. Only the preoperative records were collected, whereas those obtained postoperatively or after radiotherapy were excluded.
Normal voice samples were acquired from otherwise healthy subjects who had undergone voice assessments for the evaluation of their vocal cords prior to general anesthesia for surgical procedures involving sites other than the head and neck region, such as the hands or legs. Any subject subsequently diagnosed with any benign laryngeal disease, sulcus vocalis, or one-sided vocal palsy were excluded from the data analysis of the healthy subjects. Any additional diagnosis of voice disorders was excluded by a detailed review of patients’ medical records.
Patients’ demographic information, including gender, age, and smoking history, were collected. In those diagnosed with laryngeal cancer, additional clinical information such as the TNM (Tumor Node Metastases Classification of Malignant Tumors) stage, a global standard for classifying the anatomical extent of tumor cancers, was recorded. The study protocols were approved by our institutional review board [HC19RES10098].
2.2. Datasets from Voice Files
The dataset comprises recordings of normal subjects and cancer patients. Voice samples were recorded with a Kay Computer Speech Lab (CSL) (Model 4150B; KayPENTAX, Lincoln Park, NJ, USA) supported by a personal computer, including a Shure-Prolog SM48 microphone with Shure digital amplifier, located at a distance of 10–15 cm from the mouth and an angle of 90°. Background noise was controlled below 45 dB. Analysis of a voice sample, directly recorded using digital technology and with a sampling frequency of 50,000 Hz, was carried out using MDVP 515 software (version 2.3). Patients phonated vowel sound /a:/ for over 4 s at a comfortable level of loudness (about 55–65 dB). The operator’s experience dates back to 2011, and the voice testing protocol in the hospital was established in 2015.
2.3. Experimental Setups
The study used a NVIDIA GeForce RTX2080 Ti (11GB) graphic card. We examined the normal and cancer voice signal classification and tested the performance of the SVM, XGBoost, light gradient boosted machine (LightGBM), artificial neural network (ANN), one-dimensional convolutional neural network (1D-CNN), and 2D-CNN. The performance was evaluated via five-fold cross-validation. The accuracy, sensitivity, specificity, and area under the curve (AUC) values were used as performance metrics. This study strictly used male voice samples to exclude gender effects in that all laryngeal cancer cases were male and that male and female voices have different frequency range. Otherwise, some factors that are not directly related to cancerous voice can undermine the integrity of the study design.
2.4. Feature Extraction
In this study, two common features in speech analysis were selected. First, a term named after the word “talk” in Dutch, PRAAT is a speech analysis program (Paul Boersma and David Weenink, Institute for Phonetic Sciences, University of Amsterdam, The Netherlands) in phonetics designed to extract key features in the voice [
14]. The raw voice input was 4 s of 50,000 Hz signal. The PRAAT features were extracted under a minimum value of 10 Hz and a maximum value of 8000 Hz to account for the spectral range of a human voice. Fourteen audio features include mean and standard deviation of the fundamental frequency, harmonic to noise ratio (HNR), and jitter and shimmer variants. The HNR denotes the degree of acoustic periodicity in the aspect of energy. The last two sets of features are measures of perturbation in acoustic analysis, where jitter demonstrates the frequency instability, whereas shimmer represents the amplitude instability of a signal. In other words, jitter refers to the frequency variation from cycle to cycle, and the shimmer represents the amplitude variation of the sound wave. Following is a description of the jitter and shimmer variants [
14]. The localJitter is the average absolute difference between consecutive intervals, divided by the average interval, and localabsolutejitter uses absolute difference. The rapJitter is the relative average perturbation of itself and the two adjacent, and ppq5jitter accounts for four neighbors. Ddpjitter is the difference between differences of consecutive difference. In a similar fashion, six shimmer variants were defined: localshimmer, localdbshimmer, apq3shimmer, apq5shimmer, apq11shimmer, and ddashimmer.
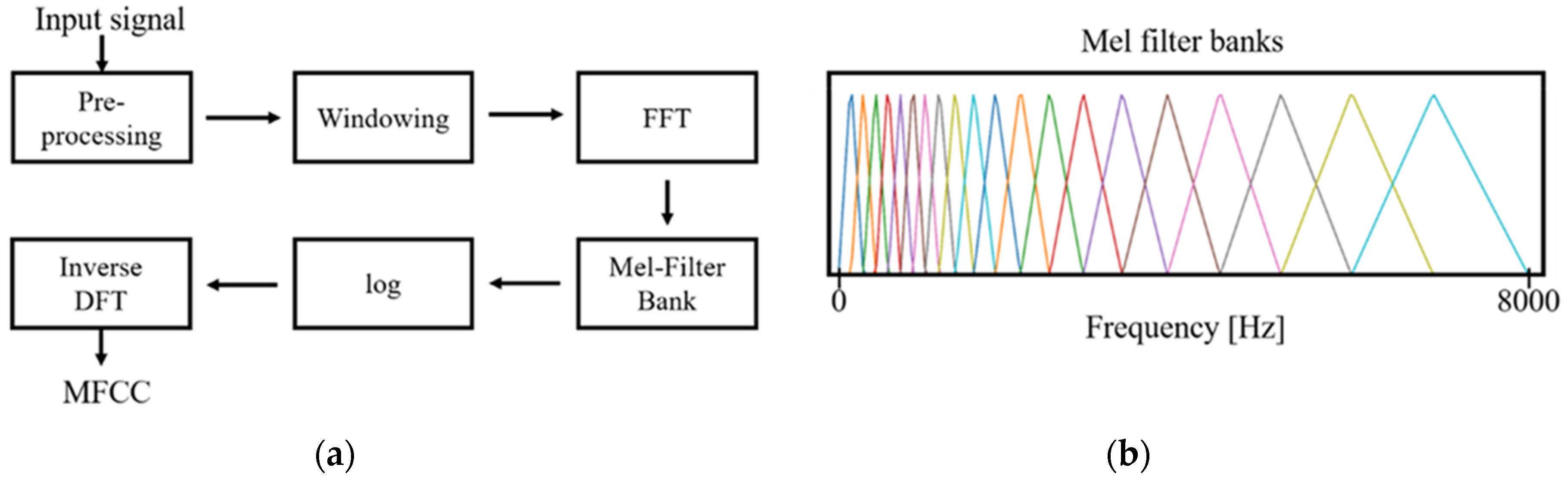
Second, MFCCs, a collection of numerical values resulting from the transformation of time series data, were obtained [
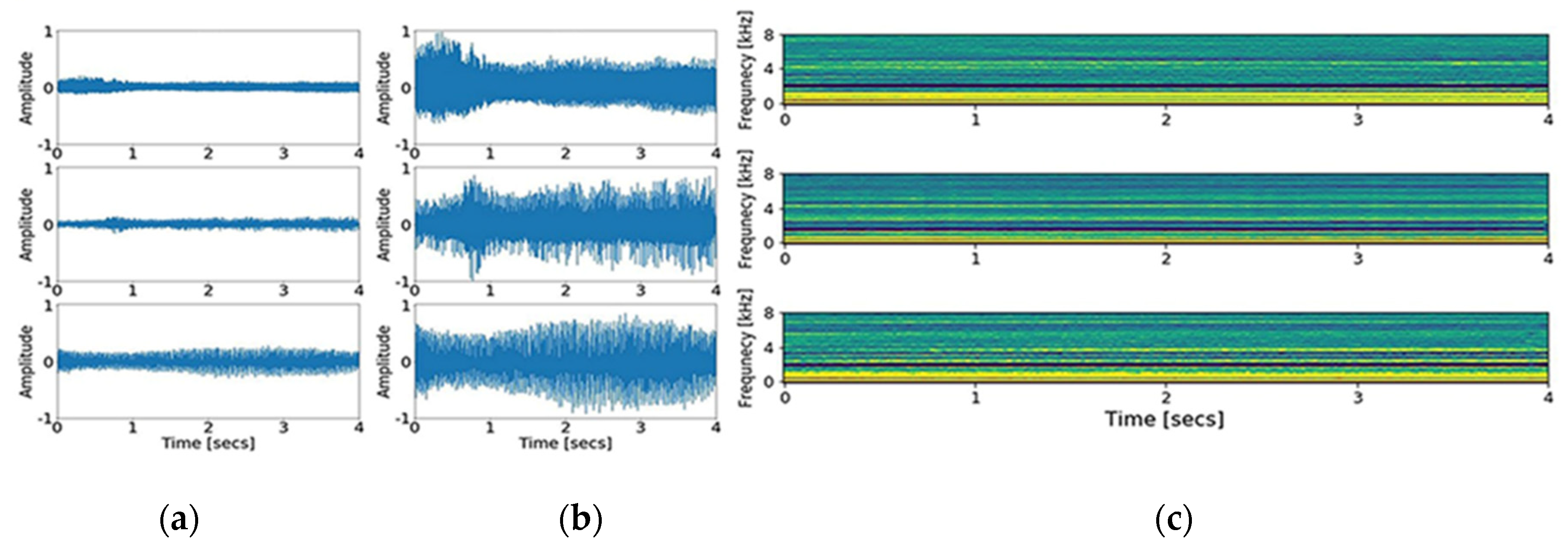
15]. The principle of MFCCs is based on a short-time Fourier transform and additional consideration for the distinct nature of a human voice in the lower frequency range, set by the biased bandpass filter design. Forty triangular bandpass filters were used. Initially, we down sampled the input signal to 16,000 Hz, accounting for the Nyquist frequency of the human voice range. As a result of the transformation, 200,000 data points of the input signal were converted to 64,000 points, and then into a 40 × 126-time spectral image. The graphic presentation of down sampling, normalization, and MFCCs transformation is shown in
Figure 1 and
Figure 2. In addition, short time Fourier transform (STFT), another common time-spectral representation, was obtained for comparative evaluation. For this conversion, we down sampled the input signal to 4000 Hz and processed with a frame size of 0.02 without overlap, in order to match with the height size of the MFCCs. As a result, a 40 × 199-time spectral image was produced.
2.5. Preprocessing
A series of preprocessing steps are introduced for the effective representation of the signal. The recordings represent continuous sounds. Normalization was performed to change the value of numerical voice signals to a common scale, because the magnitudes vary depending on the measuring distance of the record. Each signal was divided by the maximum absolute value of the recording per patient while taking account of the peak outliers.
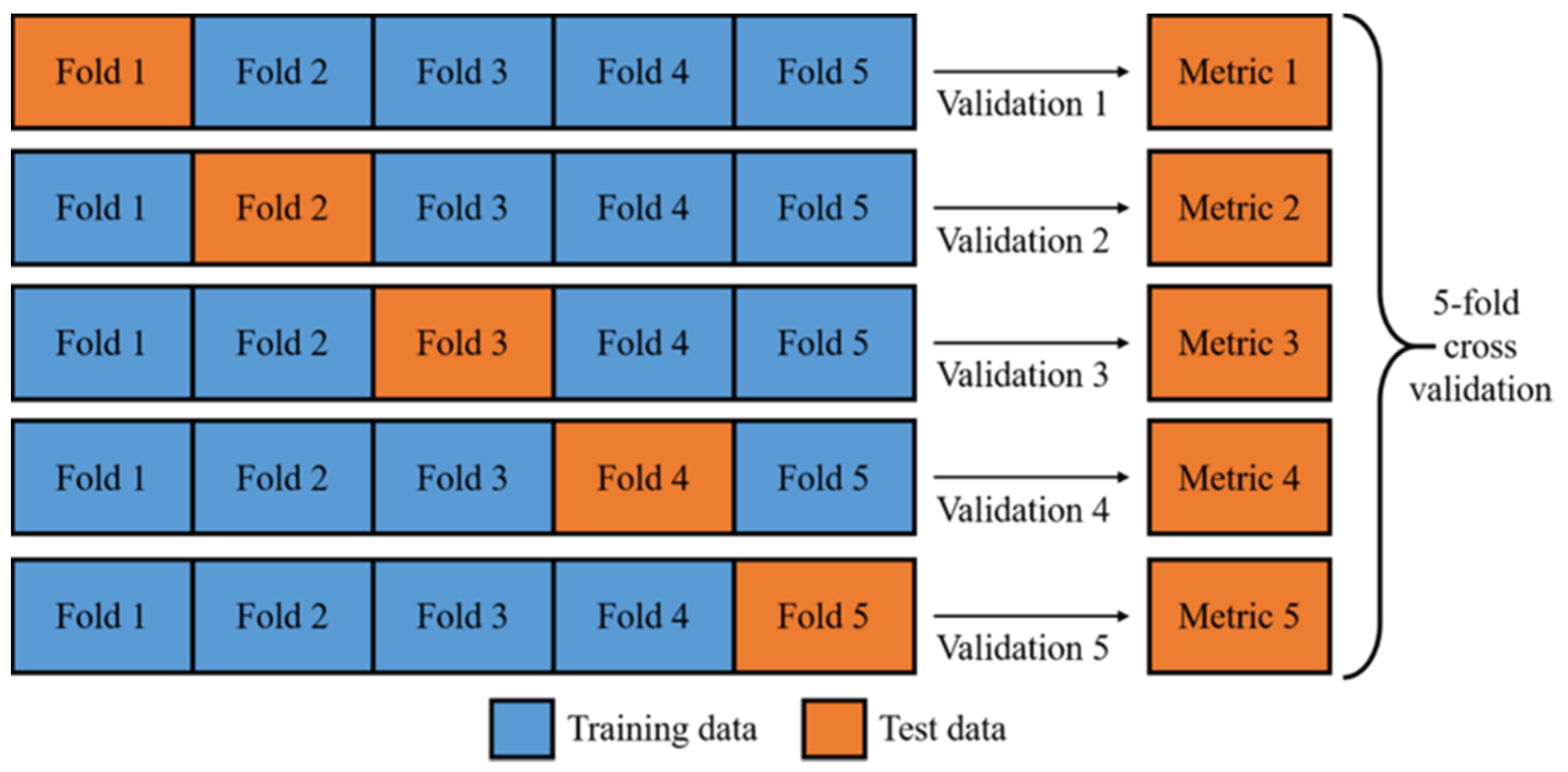
For accurate validation, the data set was divided into two parts in each validation: one for training and another for testing. Performance metrics were only calculated with the testing dataset, the signals that the model did not process during its training. A five-fold validation method is used for reliable results, which divides the dataset into five subsets. For each validation fold, four subsets were used to train a model for appropriate representation and generalization power, and the model was validated with the remaining subset. Overall, five validations were conducted, and the performance matrix represented the average of all results. The process can be seen in
Figure 3.
2.6. Machine Learning Algorithms
We tested three machine learning algorithms: SVM, XGBoost, LightGBM, and ANN. The SVM is the most frequently practiced method used in the classification task. The SVM resolves the classification task by drawing a decision boundary hyperplane that divides space with the maximum distance from each class. However, not all cases can be resolved similarly, as clusters often require a non-linear boundary. The kernel trick facilitates by warping spaces. In machine learning, the hyper-parameter is a high-level configurator empirically chosen to control complexity, conservativeness, and overfitting of a model before training the networks [
16]. The governing decision-making equation and its classification decision is shown in the equations below, where
and
represent bias and weights of the boundary.
The LightGBM and XGBoost are classifiers derived from a decision tree family known to perform best in many practices. The decision tree is named after its shape comprising of a series of dividing rules. The model learns the optimal rules based on information gain and entropy. Information gain is a quantified value based on information generated by a certain event. Entropy is a relative degree of disorder [
17]. Since a signal decision tree can easily overfit, a series of techniques are implemented to boost performance such as bagging, boosting, tree-pruning, and parallel processing. The techniques effectively combine predictions from multiple trees and multiple sequential models.
An ANN is a basic form of a DNN. A series of fully connected layers constitute an ANN. The model predicts the label of input data with trained weights and biases through a forward propagation. We consider this ANN model to be a machine learning model since the input is hand-crafted feature and the propagation mostly performs classification tasks only.
2.7. Deep Learning Algorithms
The human voice exhibits distinct characteristics in the lower frequency range, so biased filters are used in the MFCCs. Although a recent study has shown that MFCCs are consistent metric constraints [
18], an inevitable information loss occurs at the conversion. Ten pieces of size 40 × 40 are randomly cropped per image to lower the computational cost and to elicit a data augmentation effect. In a similar fashion, ten pieces of size 40 × 40 segments from a STFT spectrogram are prepared from each signal.
Zero padding and down sampling are implemented for the 1D-CNN. Zero padding ensures stable frequency conversion and provides better resolution. Further, a recent study showed that the most contributive bands in both detection and classification ranged between 1000 and 8000 Hz [
7]. Down sampling is set at 22,050 Hz for 1D-CNN and 16,000 for 2D-CNN preprocessing.
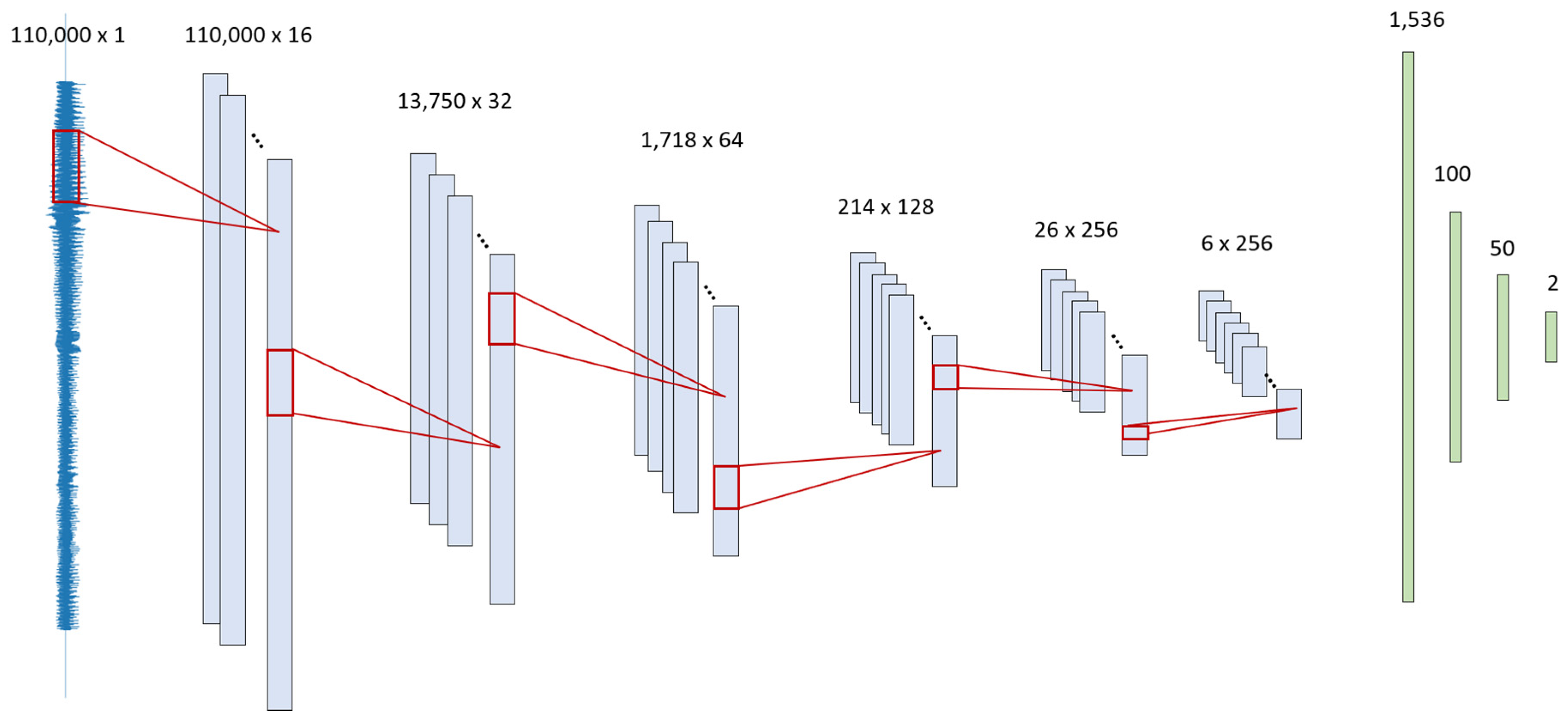
The 1D-CNN structure is composed of six convolution blocks and three fully connected layers (
Figure 2). The number of kernels is 16, 32, 64, 128, and 256. A kernel is equivalent to a filter. For example, the first layer represents the filtered signals from 16 kernels. Max pooling sizes used are 8, 8, 8, 8, and 4 to compress the long signal, which choose the maximum single value from a given window size to progressively reduce the spatial size and to provide abstract representation. The dense layer is composed of 1536, 100, 50, and 2 nodes. Batch normalization and ReLU activation are used for faster and stable training [
19]. The detailed structure of the algorithm is shown in
Figure 4.
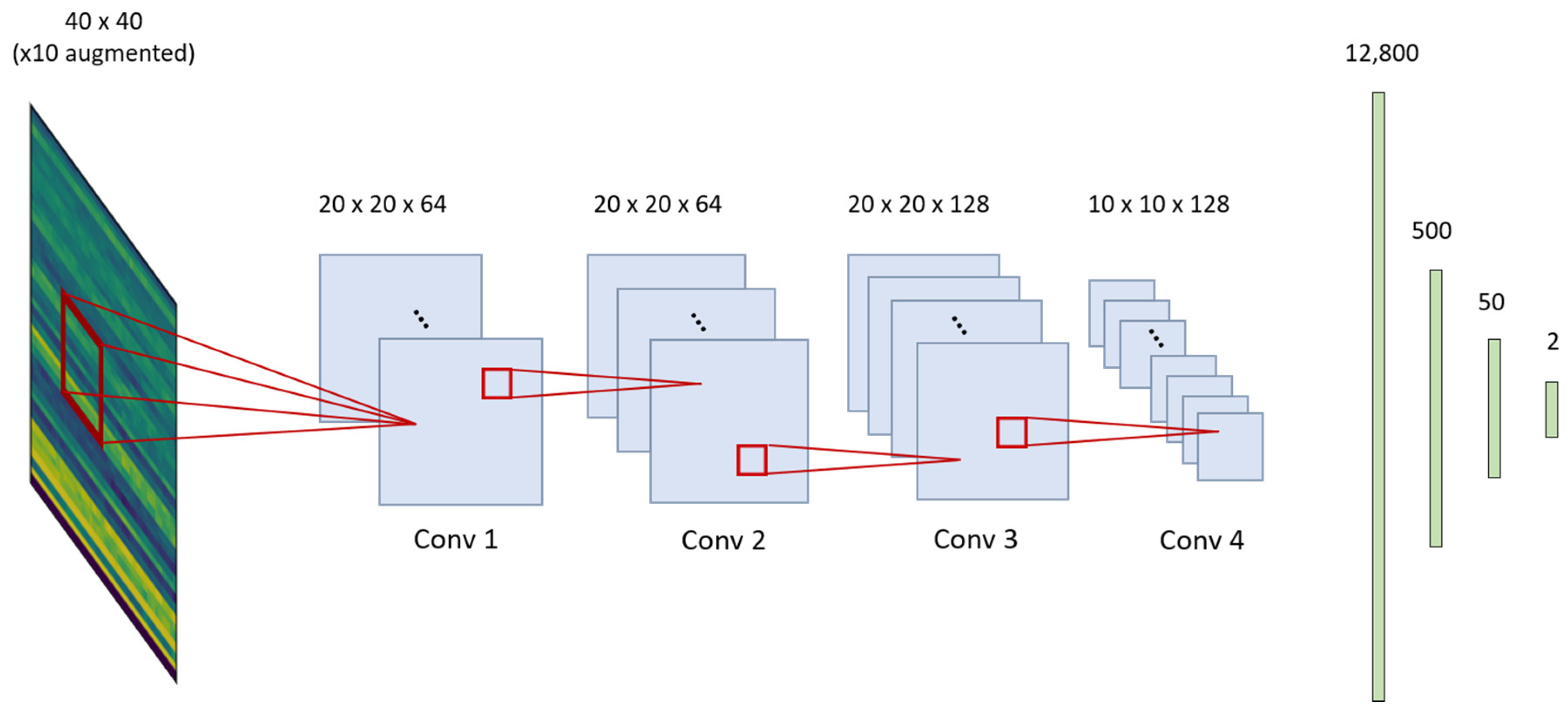
The 2D-CNN structure is composed of three convolution blocks and three fully connected layers. The number of kernels is 64, 64, and 128. The dense layer is composed of 500, 50, and 2 nodes. A dropout of 0.3 is used twice at a dense layer to prevent overfitting. A Glorot uniform initializer and ReLU activations are used [
20]. Maximum pooling is done conservatively, only once, because the input image is already small. The detailed structure of the algorithm is shown in
Figure 5.
2.8. Human Interpretation
Two laryngologists with 3–10 years of experience in laryngoscopy and laryngeal cancer were asked to listen to the same files and classify the voice sounds as either normal or abnormal. In addition, two volunteers with no medical background were asked to perform the same tasks. All volunteers were informed that abnormal voices are from laryngeal cancer patients, prior to the evaluation. No prior demographic information was provided. All volunteers were allowed to hear the voice files multiple times. The diagnostic parameters obtained from the four volunteers were calculated.
2.9. Statistical Analysis
Data are expressed as mean ± standard deviation for continuous data and as counts (%) for categorical data. Bivariate analyses were conducted using a two-tailed Student’s t-test for continuous data and a two-tailed χ2 or Fisher’s exact test for categorical data when appropriate.
All these statistical analyses were performed using IBM SPSS Statistics 20.0 (IBM Corp., Armonk, NY, USA), and p-values less than 0.05 were considered to indicate statistical significance.
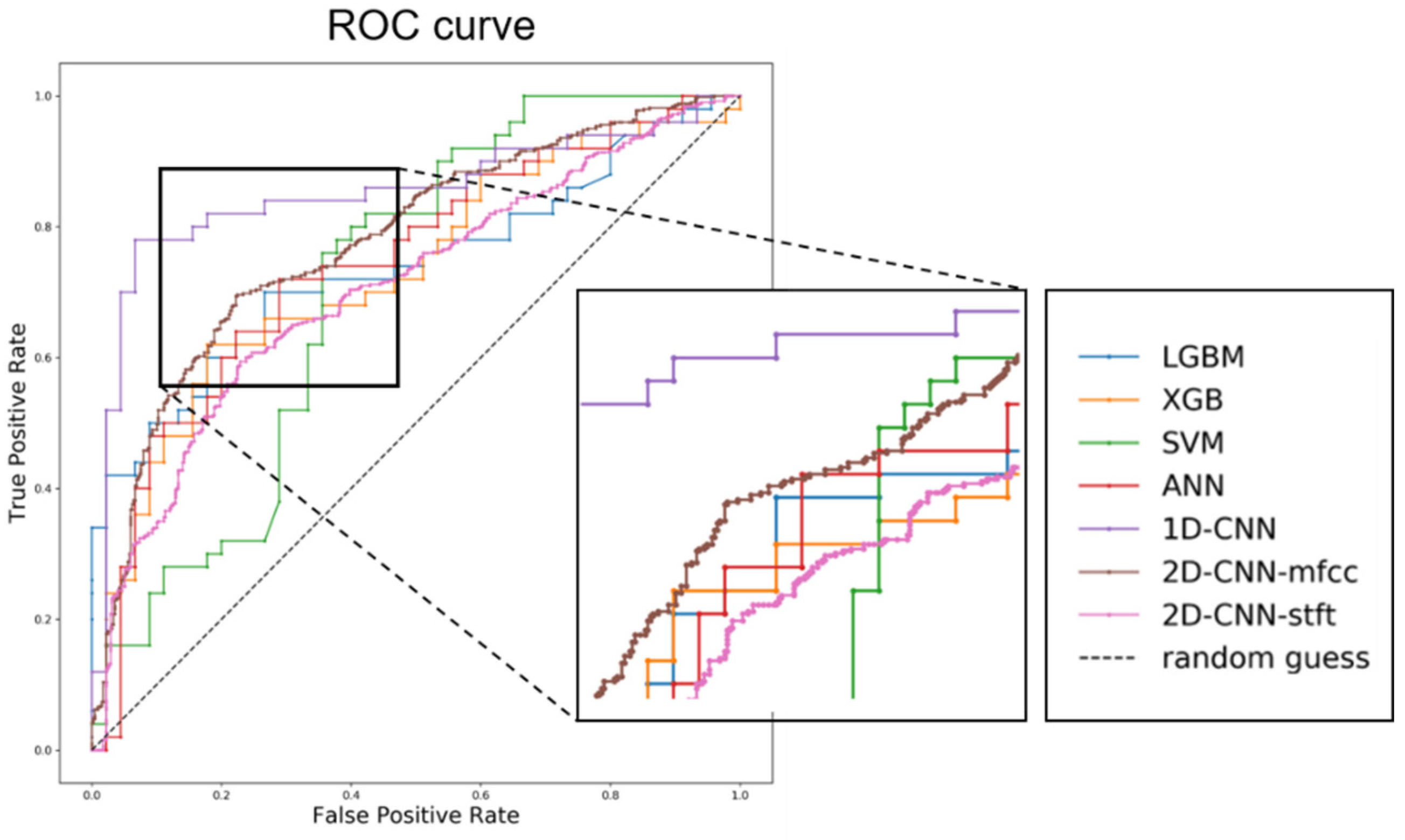
Group differences between patients with cancer and healthy participants were determined using non-parametric tests. The AUC values, which reflect the diagnostic accuracy and predictive ability, were calculated for each parameter. The performance of laryngeal cancer classification was evaluated with an AUC of receiver operating characteristic (ROC) curves using roc_curve and auc functions of the Scikit-learn library and the matplotlib library in the Python 3.5.2. and R 2.15.3 package software (R Foundation for Statistical Computing, Vienna, Austria).
4. Discussion
The results of our study provide high accuracy levels of automated algorithms using machine learning and deep learning techniques that assess voice change in laryngeal cancer. The results are promising since the majority of the cancer subjects (84%) were at early stages of cancer. Among the algorithms, the 1D-CNN showed better performance than other algorithms, with accuracy levels of 85%. All the other computational algorithms showed promising levels of performance and some showed higher accuracy levels compared with the results obtained from two laryngologists, who showed sensitivity levels of 44%. To the best of our knowledge, this is one of the first studies that has compared the performance of automated algorithms against those performed by both clinicians and non-clinicians. Based on our results, automatic detection using the 1D-CNN and other computational algorithms may be considered as potential supplementary tools to distinguish abnormal voice changes in patients with laryngeal cancer.
Past studies have already used several machine learning techniques in attempts to distinguish pathological voice disorders in laryngeal cancer. Gavidia-Ceballos and Hansen [
22] demonstrated accuracy levels of 88.7% in patients with vocal fold cancer, but their sample was limited to 20 glottic cancer and 10 healthy subjects. Previous studies employed an ANN in laryngeal cancer with accuracy levels of 92% [
9]. However, their data included patients who were recovering from laryngeal cancer, mostly following surgery. The voice signals in the present study were obtained from laryngeal cancer patients preoperatively, and thus, our results are more appropriate for assistance in screening laryngeal cancer rather than detection of postoperative voice changes. The results are even more promising since our study also provided detailed clinical information about laryngeal cancer, mostly at the early stages.
Our results are also in accordance with previous studies that have suggested better performance of DNNs in some datasets compared with a SVM or Gaussian mixture model (GMM) in detecting pathological voice samples [
9,
10,
23]. An unexpected finding was that the 1D-CNN showed better performance than the 2D-CNN, a more sophisticated algorithm. The processed signals contained 64,000 (4 [s] × 16000 [Hz]) data points representing acoustic information, whereas the MFCCs carried 15,640 (40 × 391) points. In addition, the 2D-CNN model has a limited scope of 40 by 40 kernel windows at a time. Through a series of feature conversion and windowing, the 2D-CNN method leads to unfortunate information loss. Thus, the 1D-CNN is associated with a higher resolution than the 2D-CNN in the presence of appropriate hyper parameters such as learning rate, kernel size, and the number of layers. Although the 1D-CNN is more difficult to optimize, higher resolution implies higher learning capacity. Although our results are consistent with recent studies that showed the superior performance of the 1D-CNN compared with the 2D-CNN in a heart sound classification study [
24], one has to be conscious of the fact that performance of these algorithms may change depending on the nature of the data.
Laryngeal cancer is known to show a skewed gender distribution [
25,
26] with an approximately four- to six-fold higher risk in males [
27] and poor prognosis compared with females [
28]. Based on this gender difference, we assessed the performance levels of these algorithms when the analysis of voice features in laryngeal cancer was limited to males. In such gender-restricted analysis, the 1D-CNN showed good performance with accuracy levels of 85.2%. This phenomenon is discrepant to those observed by Fang et al. [
10], who showed that the SVM outscored the GMM and ANN when the data were analyzed separately without the female subjects. Therefore, it was unexpected that the 1D-CNN performed well even with the limited sample of male voices. Despite our results favoring the 1D-CNN, due to the uneven gender distribution in laryngeal cancer, the gender composition of the data should be considered with caution when developing future deep learning algorithms since the female voice has broader distributions in cepstral domain analysis [
29]. Furthermore, one has to be mindful that the performance of these algorithms may be different depending on the feature selection and amount of data, and therefore, caution is needed before making direct comparison of which algorithm is superior to the other.
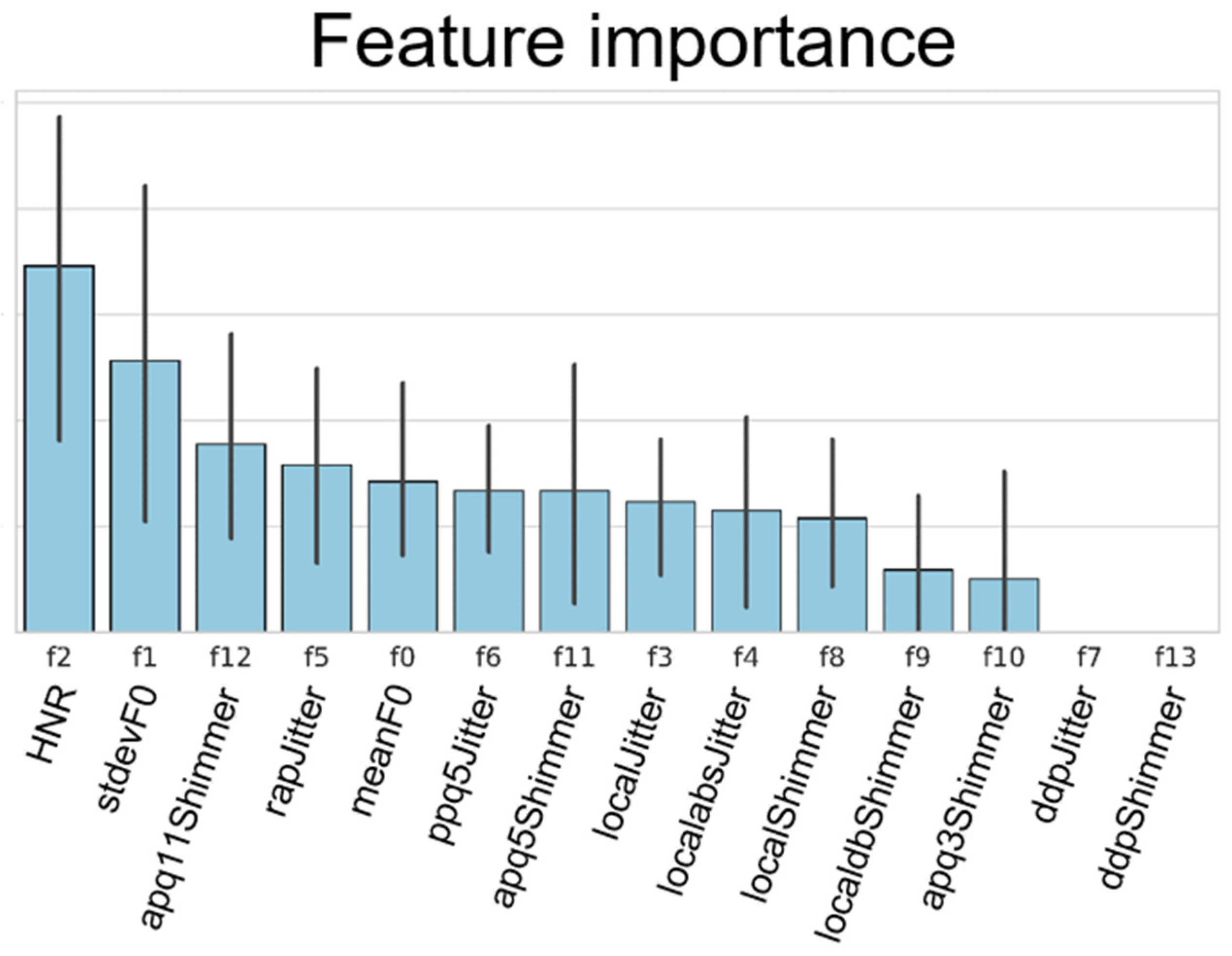
In this study, among the many PRAAT features that played significant roles in helping to classify the voice changes, of interest, the HNR was shown to be an essential feature, followed by the F0 standard deviation and apq11shimmer from the XGBoost algorithms. Past studies [
30,
31] have shown changes in some acoustic parameters including the HNR, jitter, and shimmer in laryngeal cancer due to the structural effects on the vibration and wave movement of the vocal cord mucosa but have not shown which parameter contributes more than the other in the classification of laryngeal cancer. Abnormal HNR values reflect an asthenic voice and dysphonia [
32], which may be expected with the mass effects. Controversies surrounding the role of fundamental frequencies exist, with some suggesting these values decrease in laryngeal cancer and smokers [
31], compared to healthy groups [
33]. Instead, this feature is a more prominent marker in voice change observed in smokers [
34]. Of interest is that no study has yet emphasized the role of the apq11shimmer values in classifying these voice changes with high accuracy. The clinical implication of the apq11shimmer value in combination with changes of the F0 standard deviation, which reflects changes in voice tone, needs to be verified with future studies, including those related to other voice disorders.
Voice changes that do not improve within two weeks are known to be one of the earliest signs of laryngeal cancer and mandate a visit to the laryngologist. Our results indicated that the average time from onset of voice change to the first visit to the laryngologist was 16 weeks. Though most patients in our study were in the early stages of cancer, in reality, patients failed to consult with the laryngologist within the initial month when the voice changes develop. Subjective perception of voice change can be challenging and our results from the ratings by the four volunteers showed that half of the early stage cases could also be missed by the human ear, even by expert laryngologists. The diagnostic parameters from the four volunteers showed overall high specificity levels, which indicate good performance levels in discerning those with normal voices. However, the low sensitivity levels indicate that human perception of subtle voice changes within the short 4 s voice file may be insufficient to discern the initial voice changes in laryngeal cancer. Though the two experts showed better performance than the two non-experts, the low sensitivity levels of this latter group are of concern and reflect real-world situations where the patients may misjudge and miss the initial changes as normal. Voice change can be the only first symptom, and if not considered as a serious sign, it can inadvertently result in a delay when making the initial visit to the laryngologist. Automated algorithms may be used to alert the “non-expert” patients when these voice changes appear to seek medical advice. Higher sensitivity levels are ideal for screening tools. Therefore, the higher sensitivity levels from the deep learning algorithms may support the use of these automated voice algorithms in the detection of voice changes in early glottic cancer. Though based on a limited number of data, our results show the potential of future applications of these algorithms in digital health care and telemedicine.
One interesting point to consider is that the 1D-CNN showed good accuracy levels, even when most were at the early stages. In addition, the inclusion of these supraglottic cancer patients who usually remain asymptomatic in the early stages and are difficult to diagnose [
35] may be clinically relevant. Voice changes in advanced laryngeal cancer stages can be evident because of the involvement of the vocal cord or thyroid cartilage. By contrast, in the T1 stage, these changes may be too subtle and may go unnoticed. The encouraging results of classifying those, even in the early laryngeal cancer stages, show the opportunity of automatic voice signal analysis to be used as part of future digital health tools for the noninvasive and objective detection of subtle voice changes at the early stages of laryngeal cancer. Future studies with more detailed separate analysis among the different tumor types and stages could be promising.
Significant new work has been reported recently using artificial intelligence techniques in the early detection of cancer, including skin and gastric cancer [
36,
37]. Similar attempts have also been made in oropharyngeal cancer with mixed results. A few studies have used features associated with hypernasalance in oropharyngeal cancer [
38] and glottal flow in glottic cancer [
39] and employed ANNs with mixed results. Recent studies have shown that the CNN can be used to predict the outcome automatically [
40] or detect laryngeal cancer based on laryngoscope images with accuracy levels of 86% [
41], which are similar to our accuracy levels of 85.2%. Our work differs from these past studies in that we employed voice signals rather than imaging data and compared the accuracy levels of the 1D-CNN to those rated by the human ear.
The algorithms presented in this study showed promising results. However, a few limitations remain to be addressed. First is the non-inclusion of other voice disorders such as those related to more common benign disorders, such as, vocal polyps or vocal fold palsies. The main objective was to determine the accuracy of various algorithms including the 1D-CNN against those performed by human raters. The use of these algorithms to classify other voice disorders may require rebuilding the algorithm structure based on additional hyper parameters. Ongoing studies by our research group are currently attempting to design new CNN algorithms that may be used to distinguish voice changes in cancer patients from other various voice disorders, such as those related to vocal palsy or polyps. Another factor to consider is the limited number of cancer cases. Machine learning requires a large amount of processed data, and its performance depends heavily on how well the feature is crafted. The limited number of data is a problem often encountered in medical data acquired from sources other than image files. It is even more challenging to obtain voice data from patients with laryngeal cancer during the preoperative period. However, the number of cancer patients was similar to past studies [
9,
10,
11] that employed automated algorithms in voice pathologies. The voice, a signal carrying infinite information, can be represented in a simpler form by introducing digital signal processing tools such as PRAAT or MFCCs, which improves optimization potential despite the small datasets [
15]. Second, the proposed algorithms performed well for datasets comprising only males. The inclusion of females in the analysis may inadvertently provide a clue to the model with all cancer data comprising male subjects and therefore excluded female data. Although our results supported the high-performance levels of the 1D-CNN, the model proposed in this study may lose its diagnostic power when female cancer patients are included. Therefore, our algorithms require re-validation when adequate data are collected from female patients in the future. Furthermore, prospective studies are needed for large-scale validation of our model. Third, since the cancer group showed more elderly males with a higher proportion of smokers, one could question whether our algorithm classified voice changes related to the presence of laryngeal cancer or related to smoking and old age. Smoking and old age are the cardinal risk factors of laryngeal cancer. However, these two conditions manifest in distinctive voice changes. For example, according to a recent meta-analysis study [
34] voice changes in smoking are manifested mostly in the fundamental frequency (F0). Likewise, voice changes in elderly males are characterized by an increase of jitter values [
42]. Had our algorithms classified based solely on senile and smoking changes, these two features would have been the two most important features. Instead, other features, which may reflect the tumor effects on the voice, played a more prominent role. Nevertheless, the skewed distribution of gender, age, and smoking status are important factors to consider in future studies that intend to employ artificial intelligence in voice disorders that include laryngeal cancer. Finally, our results are by no means intended to replace current diagnostic tools and future studies using voice signals as a supplementary screening tool in the age of telemedicine in conjunction with current laryngoscope studies in laryngeal cancer are warranted.
The results presented in our study demonstrate the ability of the proposed computational algorithms to distinguish voice changes in early laryngeal cancer from healthy voices in normal participants. However, this study did not include other voice disorders, which may be more common in clinical practice than laryngeal cancer patients. Therefore, a high degree of prudence is required in interpreting the results. Nevertheless, the application of voice signals to digital algorithms as alternative methods to assess patients at difficult times [
43] when direct physical contact with the laryngologist is not feasible may have important social implications in the future.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}