Going Beyond Conventional Mammographic Density to Discover Novel Mammogram-Based Predictors of Breast Cancer Risk

 , ,
, ,
Abstract
:1. Introduction
2. OPERA: A Measure of the Ability of a Risk Factor to Identify Future Cases on a Population Basis
3. Wolfe and Beyond
4. Redefining Mammographic Density in Terms of Brightness: Cumulus, Altocumulus and Cirrocumulus
5. Revisiting Texture using Agnostic Machine Learning: Cirrus
6. What Happens When the New Measures are Fitted Together with the Conventional Measure?
6.1. Cirrocumulus and Altocumulus
6.2. Cirrus
7. Some Other New Mammogram-Based Measures of Breast Cancer Risk
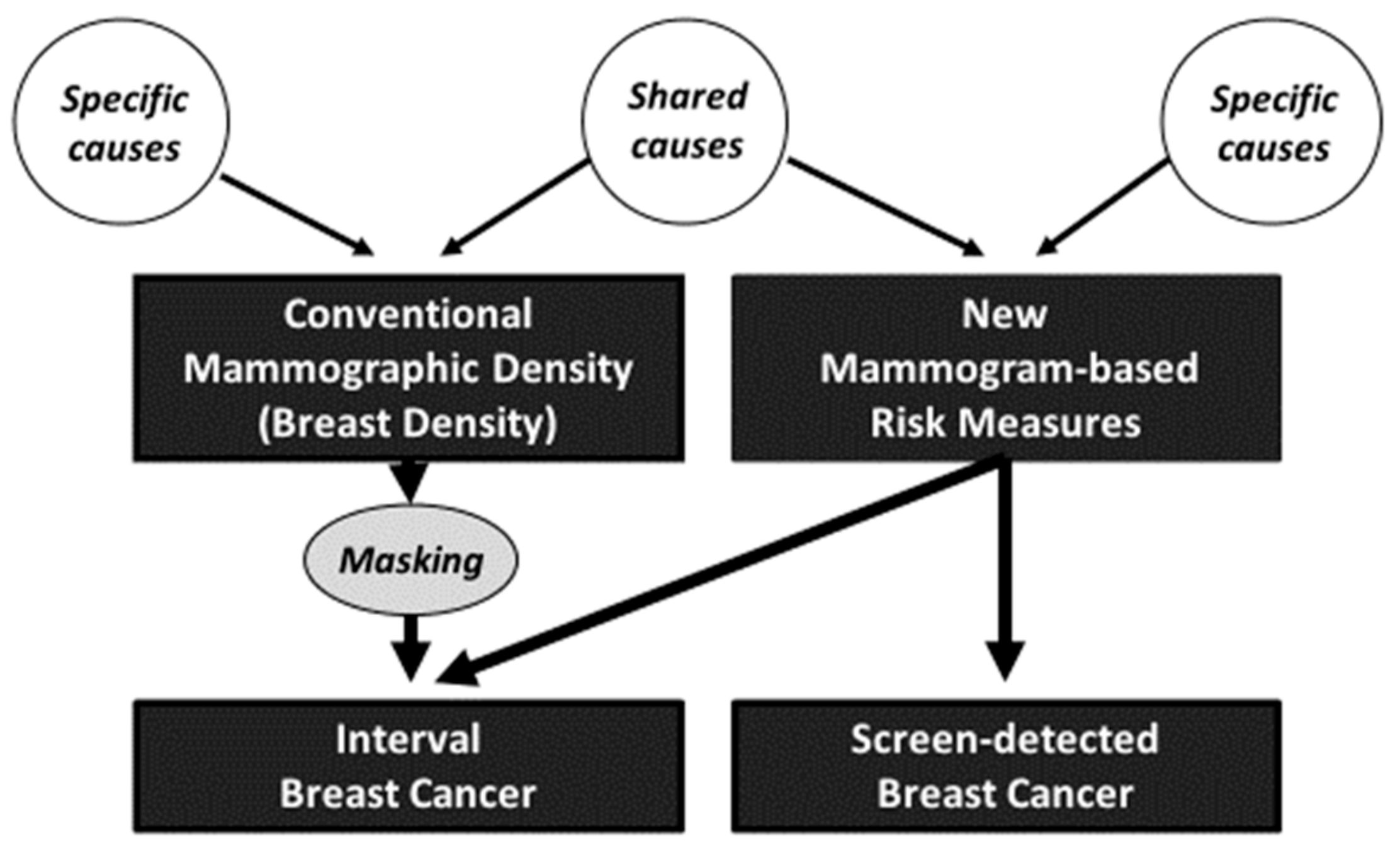
8. Interpretation
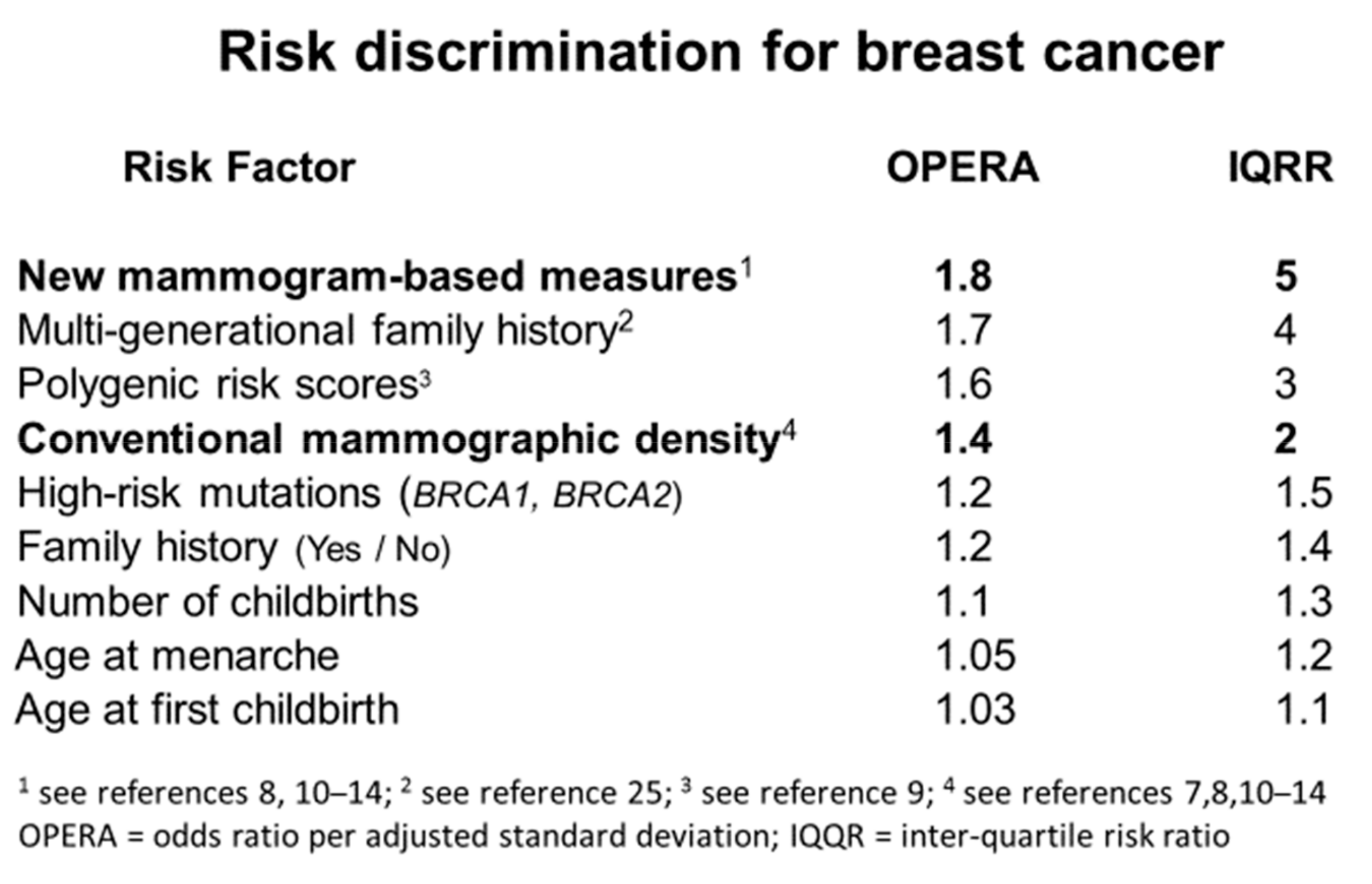
9. Importance of Mammogram-Based Risk Factors as Breast Cancer Risk Predictors
10. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Byng, J.W.; Yaffe, M.J.; Jong, R.A.; Shumak, R.S.; Lockwood, G.A.; Tritchler, D.L.; Boyd, N.F. Analysis of mammographic density and breast cancer risk from digitized mammograms. Radiographics 1998, 18, 1587–1598. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krishnan, K.; Baglietto, L.; Stone, J.; Simpson, J.A.; Severi, G.; Evans, C.F.; MacInnis, R.J.; Giles, G.G.; Apicella, C.; Hopper, J.L. Longitudinal Study of Mammographic Density Measures That Predict Breast Cancer Risk. Cancer Epidemiol. Biomarkers Prev. 2017, 26, 651–660. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shia, W.C.; Wu, H.K.; Huang, Y.L.; Lin, L.S.; Chen, D.R. Mammographic Density Distribution of Healthy Taiwanese Women and its Naturally Decreasing Trend with Age. Sci. Rep. 2018, 8, 14937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hopper, J.L.; Dite, G.S.; MacInnis, R.J.; Liao, Y.; Zeinomar, N.; Knight, J.A.; Southey, M.C.; Milne, R.L.; Chung, W.K.; Giles, G.G.; et al. Age-specific breast cancer risk by body mass index and familial risk: Prospective family study cohort (ProF-SC). Breast Cancer Res. 2018, 20, 132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, T.L.; Schmidt, D.F.; Makalic, E.; Dite, G.S.; Stone, J.; Apicella, C.; Bui, M.; Macinnis, R.J.; Odefrey, F.; Cawson, J.N.; et al. Explaining variance in the cumulus mammographic measures that predict breast cancer risk: A twins and sisters study. Cancer Epidemiol. Biomarkers Prev. 2013, 22, 2395–2403. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eng, A.; Gallant, Z.; Shepherd, J.; McCormack, V.; Li, J.; Dowsett, M.; Vinnicombe, S.; Allen, S.; dos-Santos-Silva, I. Digital mammographic density and breast cancer risk: A case-control study of six alternative density assessment methods. Breast Cancer Res. 2014, 16, 439. [Google Scholar] [CrossRef] [Green Version]
- Hopper, J.L. Odds per adjusted standard deviation: Comparing strengths of associations for risk factors measured on different scales and across diseases and populations. Am. J. Epidemiol. 2015, 182, 863–867. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, D.F.; Makalic, E.; Goudey, B.; Dite, G.S.; Stone, J.; Nguyen, T.L.; Dowty, J.G.; Baglietto, L.; Southey, M.C.; Maskarinec, G.; et al. Cirrus: An automated mammography-based measure of breast cancer risk based on textural features. JNCI Cancer Spectrum 2018, 2. [Google Scholar] [CrossRef]
- Mavaddat, N.; Michailidou, K.; Dennis, J.; Lush, M.; Fachal, L.; Lee, A.; Tyrer, J.P.; Chen, T.H.; Wang, Q.; Bolla, M.K.; et al. Polygenic Risk Scores for Prediction of Breast Cancer and Breast Cancer Subtypes. Am. J. Hum. Genet 2019, 104, 21–34. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.L.; Aung, Y.K.; Evans, C.F.; Yoon-Ho, C.; Jenkins, M.A.; Sung, J.; Hopper, J.L.; Song, Y.M. Mammographic density defined by higher than conventional brightness threshold better predicts breast cancer risk for full-field digital mammograms. Breast Cancer Res. 2015, 17, 142. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.L.; Aung, Y.K.; Evans, C.F.; Dite, G.S.; Stone, J.; MacInnis, R.J.; Dowty, J.G.; Bickerstaffe, A.; Aujard, K.; Rommens, J.M.; et al. Mammographic density defined by higher than conventional brightness thresholds better predicts breast cancer risk. Int. J. Epidemiol. 2017, 46, 652–661. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, T.L.; Choi, Y.H.; Aung, Y.K.; Evans, C.F.; Trinh, N.H.; Li, S.; Dite, G.S.; Kim, M.S.; Brennan, P.C.; Jenkins, M.A.; et al. Breast cancer risk associations with digital mammographic density by pixel brightness threshold and mammographic system. Radiology 2018, 286, 433–442. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, T.L.; Aung, Y.K.; Li, S.; Trinh, N.H.; Evans, C.F.; Baglietto, L.; Krishnan, K.; Dite, G.S.; Stone, J.; English, D.R.; et al. Predicting interval and screen-detected breast cancers from mammographic density defined by different brightness thresholds. Breast Cancer Res. 2018, 20, 152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nguyen, T.L.; Li, S.; Dite, G.S.; Aung, Y.K.; Evans, C.F.; Trinh, H.N.; Baglietto, L.; Stone, J.; Song, Y.M.; Sung, J.; et al. Interval breast cancer risk associations with breast density, family history and breast tissue aging. Int. J. Cancer 2019. [Google Scholar] [CrossRef] [Green Version]
- Wolfe, J.N. Risk for breast cancer development determined by mammographic parenchymal pattern. Cancer 1976, 37, 2486–2492. [Google Scholar] [CrossRef]
- Rafferty, E.A. Mammographic breast density: From Wolfe and beyond. Menopause 2014, 21, 920–921. [Google Scholar] [CrossRef] [PubMed]
- Byng, J.W.; Boyd, N.F.; Fishell, E.; Jong, R.A.; Yaffe, M.J. The quantitative analysis of mammographic densities. Phys. Med. Biol. 1994, 39, 1629–1638. [Google Scholar] [CrossRef]
- Boyd, N.F.; Guo, H.; Martin, L.J.; Sun, L.; Stone, J.; Fishell, E.; Jong, R.A.; Hislop, G.; Chiarelli, A.; Minkin, S.; et al. Mammographic density and the risk and detection of breast cancer. N. Engl. J. Med. 2007, 356, 227–236. [Google Scholar] [CrossRef] [Green Version]
- Baglietto, L.; Krishnan, K.; Stone, J.; Apicella, C.; Southey, M.C.; English, D.R.; Hopper, J.L.; Giles, G.G. Associations of mammographic dense and nondense areas and body mass index with risk of breast cancer. Am. J. Epidemiol. 2014, 179, 475–483. [Google Scholar] [CrossRef] [Green Version]
- Krishnan, K.; Baglietto, L.; Apicella, C.; Stone, J.; Southey, M.C.; English, D.R.; Giles, G.G.; Hopper, J.L. Mammographic density and risk of breast cancer by mode of detection and tumor size: A case-control study. Breast Cancer Res. 2016, 18, 63. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Brentnall, A.R.; Cuzick, J.; Harkness, E.F.; Evans, D.G.; Astley, S. Exploring the prediction performance for breast cancer risk based on volumetric mammographic density at different thresholds. Breast Cancer Res. 2018, 20, 49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dembrower, K.; Liu, Y.; Azizpour, H.; Eklund, M.; Smith, K.; Lindholm, P.; Strand, F. Comparison of a Deep Learning Risk Score and Standard Mammographic Density Score for Breast Cancer Risk Prediction. Radiology 2020, 294, 265–272. [Google Scholar] [CrossRef] [PubMed]
- Keller, B.M.; Chen, J.; Daye, D.; Conant, E.F.; Kontos, D. Preliminary evaluation of the publicly available Laboratory for Breast Radiodensity Assessment (LIBRA) software tool: Comparison of fully automated area and volumetric density measures in a case-control study with digital mammography. Breast Cancer Res. 2015, 17, 117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wanders, J.O.P.; van Gils, C.H.; Karssemeijer, N.; Holland, K.; Kallenberg, M.; Peeters, P.H.M.; Nielsen, M.; Lillholm, M. The combined effect of mammographic texture and density on breast cancer risk: A cohort study. Breast Cancer Res. 2018, 20, 36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dite, G.S.; MacInnis, R.J.; Bickerstaffe, A.; Dowty, J.G.; Allman, R.; Apicella, C.; Milne, R.L.; Tsimiklis, H.; Phillips, K.A.; Giles, G.G.; et al. Breast cancer risk prediction using clinical models and 77 independent risk-associated SNPs for women aged under 50 years: Australian breast cancer family registry. Cancer Epidemiol. Biomarkers Prev. 2016, 25, 359–365. [Google Scholar] [CrossRef] [Green Version]
- Boyd, N.F.; Dite, G.S.; Stone, J.; Gunasekara, A.; English, D.R.; McCredie, M.R.; Giles, G.G.; Trichler, D.; Chiarelli, A.; Yaffe, M.J.; et al. Heritability of mammographic density, a risk factor for breast cancer. N. Engl. J. Med. 2002, 347, 886–894. [Google Scholar] [CrossRef]
- Martin, L.J.; Melnichouk, O.; Guo, H.; Chiarelli, A.M.; Hislop, T.G.; Yaffe, M.J.; Minkin, S.; Hopper, J.L.; Boyd, N.F. Family history, mammographic density, and risk of breast cancer. Cancer Epidemuiol. Biomakers Prev. 2010, 19, 456–463. [Google Scholar] [CrossRef] [Green Version]
- Stone, J.; Thompson, D.J.; Dos Santo Silva, I.; Scott, C.; Tamimi, R.M.; Lindstrom, S.; Kraft, P.; Hazra, A.; Li, J.; Eriksson, L.; et al. Novel assocaitions between common breast cancer susceptibility variants and risk-predicting mammographic density measures. Cancer Res. 2015, 75, 2457–2467. [Google Scholar] [CrossRef] [Green Version]
- Lindstrom, S.; Thompson, D.J.; Paterson, A.D.; Li, J.; Gierach, G.L.; Scott, C.; Stone, J.; Douglas, J.A.; dos Santos-Silva, I.; Fernando-Navarro, O.; et al. Genome-wide association study identifies multiple loci associated with both mammographic density and breast cancer risk. Nat. Commun. 2014, 5, 5303. [Google Scholar] [CrossRef] [Green Version]
- Pertuz, S.; Sassi, A.; Holli-Helenius, K.; Kamarainen, J.; Rinta-Kiikka, I.; Laaperi, A.L.; Arponen, O. Clinical evaluation of a fully-automated parenchymal analysis software for breast cancer risk assessment: A pilot study in a Finnish sample. Eur. J. Radiol. 2019, 121, 108710. [Google Scholar] [CrossRef]
- Tan, M.; Mariapun, S.; Yip, C.H.; Ng, K.H.; Teo, S.H. A novel method of determining breast cancer risk using parenchymal textural analysis of mammography images on an Asian cohort. Phys. Med. Biol. 2019, 64, 035016. [Google Scholar] [CrossRef] [PubMed]
- Yala, A.; Lehman, C.; Schuster, T.; Portnoi, T.; Barzilay, R. A Deep Learning Mammography-based Model for Improved Breast Cancer Risk Prediction. Radiology 2019, 292, 60–66. [Google Scholar] [CrossRef] [Green Version]
- Dench, E.; Bond-Smith, D.; Darcey, E.; Lee, G.; Aung, Y.K.; Chan, A.; Cuzick, J.; Ding, Z.Y.; Evans, C.F.; Harvey, J.; et al. Measurement challenge: Protocol for international case-control comparison of mammographic measures that predict breast cancer risk. BMJ Open 2019, 9, e031041. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, S.; Wong, E.M.; Bui, M.; Nguyen, T.L.; Joo, J.E.; Stone, J.; Dite, G.S.; Dugue, P.A.; Milne, R.L.; Giles, G.G.; et al. Inference about causation between body mass index and DNA methylation in blood from a twin family study. Int. J. Obes. 2019, 43, 243–252. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Dugue, P.A.; Baglietto, L.; Severi, G.; Wong, E.M.; Nguyen, T.L.; Stone, J.; English, D.R.; Southey, M.C.; Giles, G.G.; et al. Genome-wide association study of peripheral blood DNA methylation and conventional mammographic density measures. Int. J. Cancer 2019, 145, 1768–1773. [Google Scholar] [CrossRef] [Green Version]
- Glasziou, P.P.; Jones, M.A.; Pathirana, T.; Barratt, A.L.; Bell, K.J. Estimating the magnitude of cancer overdiagnosis in Australia. Med. J. Aust. 2019. [Google Scholar] [CrossRef] [Green Version]
- Hopper, J.L. Genetics for population and public health. Int. J. Epidemiol. 2017, 46, 8–11. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| Univariable | Multivariable | ||
|---|---|---|---|
| Cirrocumulus | 1.73 (1.52–1.97) | 1.41 (1.21–1.65) | 1.44 (1.20–1.72) |
| Altocumulus | 1.74 (1.53–1.99) | 1.43 (1.22–1.68) | 1.48 (1.21–1.81) |
| Cumulus | 1.62 (1.42–1.83) | – | 0.95 (0.76–1.18) |
| Univariable | Multivariable | ||
|---|---|---|---|
| Cirrocumulus | 1.32 (1.18–1.48) | 1.19 (1.06–1.34) | 1.19 (1.04–1.36) |
| Altocumulus | 1.25 (1.12–1.40) | – | 0.99 (0.85–1.14) |
| Cumulus | 1.25 (1.12–1.40) | 0.98 (0.87–1.10) | 0.99 (0.85–1.15) |
| Univariable | Multivariable | ||
|---|---|---|---|
| Cirrocumulus | 2.06 (1.67–2.54) | – | 1.10 (0.90–1.36) |
| Altocumulus | 1.92 (1.55–2.36) | 0.88 (0.72–1.07) | - |
| Cumulus | 2.33 (1.85–2.92) | 1.67 (1.36–2.07) | 1.48 (1.19–1.95) |
| Univariable | Multivariable | ||
|---|---|---|---|
| Cirrus | 1.90 (1.73–2.09) | 1.76 (1.59–1.95) | 1.74 (1.57–1.93) |
| Cumulus (absolute) | 1.34 (1.25–1.43) | 1.16 (1.08–1.24) | – |
| Cumulus (percent) | 1.38 (1.29–1.48) | – | 1.16 (1.07–1.25) |
| Univariable | Multivariable | ||
|---|---|---|---|
| DL | 1.56 (1.48–1.64) | 1.52 (1.42–1.59) | 1.55 (1.47–1.64) |
| Dense area | 1.31 (1.24–1.38) | 1.15 (1.09–1.22) | - |
| Percent density | 1.18 (1.11–1.25) | - | 1.02 (0.95–1.08) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hopper, J.L.; Nguyen, T.L.; Schmidt, D.F.; Makalic, E.; Song, Y.-M.; Sung, J.; Dite, G.S.; Dowty, J.G.; Li, S. Going Beyond Conventional Mammographic Density to Discover Novel Mammogram-Based Predictors of Breast Cancer Risk. J. Clin. Med. 2020, 9, 627. https://doi.org/10.3390/jcm9030627
Hopper JL, Nguyen TL, Schmidt DF, Makalic E, Song Y-M, Sung J, Dite GS, Dowty JG, Li S. Going Beyond Conventional Mammographic Density to Discover Novel Mammogram-Based Predictors of Breast Cancer Risk. Journal of Clinical Medicine. 2020; 9(3):627. https://doi.org/10.3390/jcm9030627
Chicago/Turabian StyleHopper, John L, Tuong L Nguyen, Daniel F Schmidt, Enes Makalic, Yun-Mi Song, Joohon Sung, Gillian S Dite, James G Dowty, and Shuai Li. 2020. "Going Beyond Conventional Mammographic Density to Discover Novel Mammogram-Based Predictors of Breast Cancer Risk" Journal of Clinical Medicine 9, no. 3: 627. https://doi.org/10.3390/jcm9030627
APA StyleHopper, J. L., Nguyen, T. L., Schmidt, D. F., Makalic, E., Song, Y. -M., Sung, J., Dite, G. S., Dowty, J. G., & Li, S. (2020). Going Beyond Conventional Mammographic Density to Discover Novel Mammogram-Based Predictors of Breast Cancer Risk. Journal of Clinical Medicine, 9(3), 627. https://doi.org/10.3390/jcm9030627