1. Introduction
Retinal vascular diseases are common causes of visual impairment [
1]. A major cause of visual morbidity is retinal capillary non-perfusion (CNP), as it triggers the release of vascular endothelial growth factor, which in turn results in macular oedema and retinal neovascularisation. Fluorescein angiography (FA) is the standard tool used for diagnosing CNP. Areas of CNP are identified as a loss of normal texture of the greyscale of the background fluorescence, that may range from a mild loss of greyness to a complete dark area of hypofluorescence, based on the density of drop out of the superficial capillary plexus [
2]. Accurate identification of CNP is challenging due to the subjectivity of assessing the gradations of the grayscale. In addition, CNP area may range from single or multiple small areas to large confluent regions and the manual quantification of CNP is time-consuming and not practical in clinical practice. With the advent of ultra-wide field (UWF) imaging system, FA done on UWF (UWF-FA) has become the standard diagnostic tool for understanding the extent of CNP area, despite the fact that grading far periphery for CNP remains challenging.
Although some of the constraints of FA in assessing CNP were resolved by the recent introduction of optical coherence tomography angiography (OCT-A), these images do not provide information on associated retinal leakage, and artefacts remain a challenge. Wide-angled OCT-A is still in its infancy, costly, not widely used, and is riddled with artefacts, as the retina is scanned from central retina to periphery. Additionally, we have over fifty years of knowledge on FA that we do not have with OCT-A.
With the advent of new investigational products aimed to prevent or reverse CNP, it is now useful to quantify CNP topographically as an end-point in clinical trials, and for routine clinical assessment. We have developed a reliable concentric ring method to quantify the area of CNP, by dividing the gradable retina into 72 segments (6 rings, each divided into 12 segments) [
3]. This methodology allows one to record CNP location by graders labelling each segment as perfused or non-perfused. However, we remain reliant on graders to grade the perfused and non-perfused areas, decreasing the reliability of quantification of CNP.
Deep learning-based tools have showcased a range of potential benefits, and a wealth of challenges in assessing retinal diseases [
4,
5,
6,
7]. Nevertheless, the accurate assessment and location of CNP areas has attracted less attention. Jasiobedzki et al. reported an algorithm to detect non-perfused regions on FA images, based on mathematical morphology [
8]. The image was initially over-segmented in primary regions, where texture, as a measure of the size and number of capillaries, was analysed. The authors reported agreement with an ophthalmologist in a single image. Buchanan et al. presented a method to locate ischemic regions in Optos UWF-FA images based on contextual knowledge [
9]. Multiple classifiers were implemented to detect different pathology signs (distance from vessel bifurcations, density of vessels, presence of leakages and microaneyrysms), and collected evidence was combined by an AdaBoost algorithm. The authors used 16 UWF-FA sequences (9 ischaemic) of 15 to 60 frames. Other methods relied on modelling CNP regions as intensity valleys [
10,
11]. Their performance strongly depends on illumination correction techniques to account for non-uniformities, homomorphic filtering and camera-model based solutions. Zheng et al. proposed a texture segmentation framework which combined an unsupervised step to identify candidate regions and a supervised weighted AdaBoost classifier [
12]. The framework was separately trained and validated on 40 malarial retinopathy patients, and reported 73.0% sensitivity and 90.8% specificity for best parameters and 10 FA images from diabetic retinopathy patients reporting 72.6% sensitivity, 82.1% and specificity for best parameters.
The aim of our study was to develop a reliable methodology to quantify CNP topographically in UWF-FA images, so that subjectivity induced by human graders can be avoided (Source code available at
https://github.com/RViMLab/JCM2020-Non-Perfusion-Segmentation). The methodology involved two stages. First, we used a fully convolutional deep learning method to provide CNP dense segmentation. Then, the concentric grid method was used to quantify the topographical distribution.
2. Materials and Methods
2.1. Dataset
This secondary analysis of anonymised FA images captured on UWF was performed from January 2017 to March 2020. The images were obtained from two multicentre randomised clinical trials on diabetic retinopathy [
13,
14]. Ethical approval was obtained to use these images from clinical trials without further informed consent for this study. Institutional review board approval was obtained from the London-Westminster Research Ethics Committee for analysis of anonymised data, and the study was conducted in accordance with the tenets of the Declaration of Helsinki.
All images were captured by an Optos 200Tx (Optos, Plc, Dumferline, Scotland). UWF-FA images were attained using a standard protocol after intravenous bolus infusion of 5 mL of 20% fluorescein sodium. The protocol used in the clinical trials mirrors the procedure used in clinical practice and consisted of acquiring images in the transit phase (up to 20 s), arteriovenous phase (up to 45 s–1 min), and late frames, at 3–4 min and 7–8 min.
Researchers can apply to Moorfields Research Management Committee for access to the data for use in an ethics approved project on
[email protected].
2.2. Curation of Dataset
Two investigators, P.S. and A.B., curated a 75-representative FA image dataset encompassing different degrees and characteristics of retinas affected by CNP, due to diabetic retinopathy. Images in the early arteriovenous phase were selected, ranging approximately between 25 and 55 s of transit time since dye injection, to allow the images to reach the peak phase of maximal fluorescence, while precluding the appearance of staining and leakage that would hinder the visualization of CNP regions.
The informative area of the image was defined as the gradable retinal region. There, all anatomical structures were sufficiently visible alongside the regions of CNP on the selected angiogram frame. Non-informative regions, usually found in the periphery, present a contrast that is insufficient to visualise CNP with an acceptable certainty.
One expert grader (P.S.) with medical retina fellowship manually demarcated the outer boundary of the gradable retina. Within its boundary, CNP regions were manually segmented, and pixel-level masks were created (
Figure 1). Areas within the gradable retina were considered to be perfused if they showed the normal ground-glass appearance on FA. Contrary, areas of CNP were defined as hypofluorescent areas of lesser grayscale than the normal ground-glass appearance associated with the absence of retinal arterioles and/or capillaries and pruned appearance of adjacent arteriole [
15]. To assess inter-grader variability, CNP was also segmented in 20 images by a second retinal fellowship trained grader (R.R.).
2.3. Automated CNP Segmentation
2.3.1. Pre-Processing
Each image was pre-processed to decrease computational demand and ease network convergence by resizing the central 2000 × 2000 region to 448 × 448, and normalizing pixel values to 0.5 mean and 1.0 standard deviation. To augment the training set and tackle deep learning networks’ tendency to overfit on training data, resized cropped images underwent random contrast shift ((, was the original value, was the average contrast, was a factor between 0.8 and 1.2) and brightness shift (scaling by a random positive factor <0.1), horizontal and vertical flipping, and smooth shear deformations (defined by random values of rotation angle and shearing factors between (−0.25, 0.25) to achieve physiologically plausible images). The resulting images were cropped to a patch keeping over 63% of their area to increase data, while keeping most of the gradable region (random axis ratios of up to 0.7). All random values were extracted from a uniform distribution. Bilinear interpolation was used in any transformation requiring resampling.
2.3.2. Network
The developed network’s architecture follows the U-net symmetric encoding-decoding structure [
16]. The network combines a downsampling path that extracts spatial features from the input image, and an upsampling path to construct the dense segmentation map. The downsampling path consists of the repeated application of blocks, including two 3 × 3 convolutions and a max pooling operation layer, with a pooling size of 2 × 2 and stride of 2. This sequence is repeated four times, doubling the number of feature channels at each step, and connected to the upsampling path by blocks, including two 3 × 3 convolution operations. The upsampling path also consists of four repetitions of identical blocks, including an upsampling operation. A 1 × 1 convolution is added after the final upsampling block, to generate the desired number of classes from the last 64-channel feature map.
The downsampling and upsampling paths are connected by similar blocks including two 3 × 3 convolutions and a drop-out layer [
17]. Moreover, the corresponding downsampling and upsampling blocks are connected by skip connections. The feature maps resulting from the second convolution in the upsampling blocks are concatenated to the feature maps resulting from the upsampling operation in the corresponding upsampling block (
Figure 2).
2.3.3. Training Methodology
The network was trained using a Tensorflow distributed machine learning system [
18]. Stochastic gradient descent was used to update the parameters and batch size 1, to contribute to regularization. The networks at each fold were trained for 33K epochs to prevent overfitting, starting with a learning rate of 0.05, with 0.9 decay rate every 1000 epochs, in conjunction with a momentum of 0.9 [
19]. The dropout ratio was set to 0.5. The experiments were performed on a NVidia Quadro P6000 GPU. Training was carried out with the goal of optimising the inverse of generalized dice coefficient as the objective function, defined at pixel level as:
where
are the reference pixel values,
are the probabilistic predicted values and
provides invariance to imbalanced label set distributions, by correcting the contribution of each label,
, by the inverse of its size [
20].
2.4. Quantification of Capillary Non-Perfusion
We used a validated concentric rings method to quantify the topographical representation of CNP on UWF-FA [
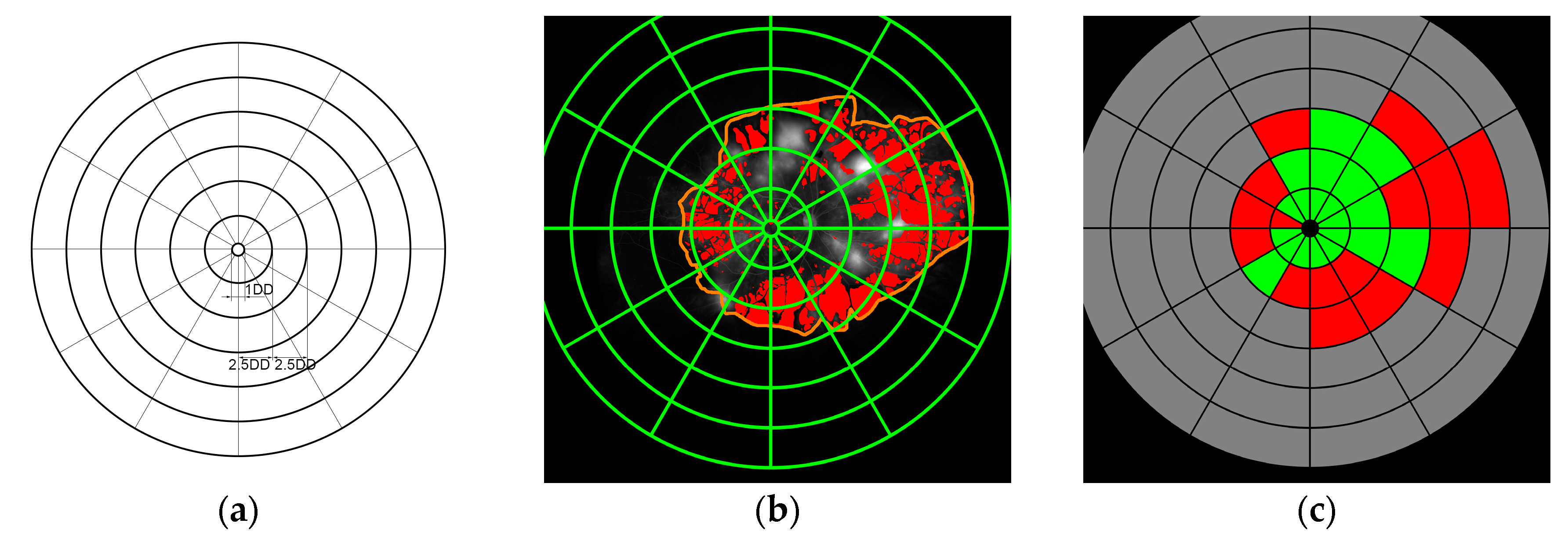
3]. The concentric ring template consists of a central circle and 6 rings, with diameters measured in disc diameters (DD). The innermost circle was centred on the fovea and had a diameter of 1 DD. The first ring, the macular ring, was 2.5 DD in radius, and each subsequent ring’s radius was incremented by 2.5 DD. All rings were divided into 12 segments subtending 30 degrees (
Figure 1) [
3]. The innermost circle, corresponding to the FAZ, was excluded from grading. The ring template was superimposed on each UWF-FA image, and each segment was graded as one of the following two possibilities: “perfused” (P), “non-perfused” (N), if more than 50% of the segment was considered to be within the same category. The second grader graded all images for the purpose of inter-grader agreement evaluation. These measured the subjective assessment of CNP by human graders. For the purpose of automatic assessment, the circular grid was placed on the automated segmentation, and evaluated using the same procedure. Each segment where the ratio of CNP pixels surpassed 30% was labelled as non-perfused (example in
Figure 1). The threshold value was object of experimentation and established empirically. We evaluated 3 different thresholds: 30%, 40% and 50%, and observed that 30% was the best threshold where the graders tended to “see” more CNP when grading the grid.
2.5. Data Analysis
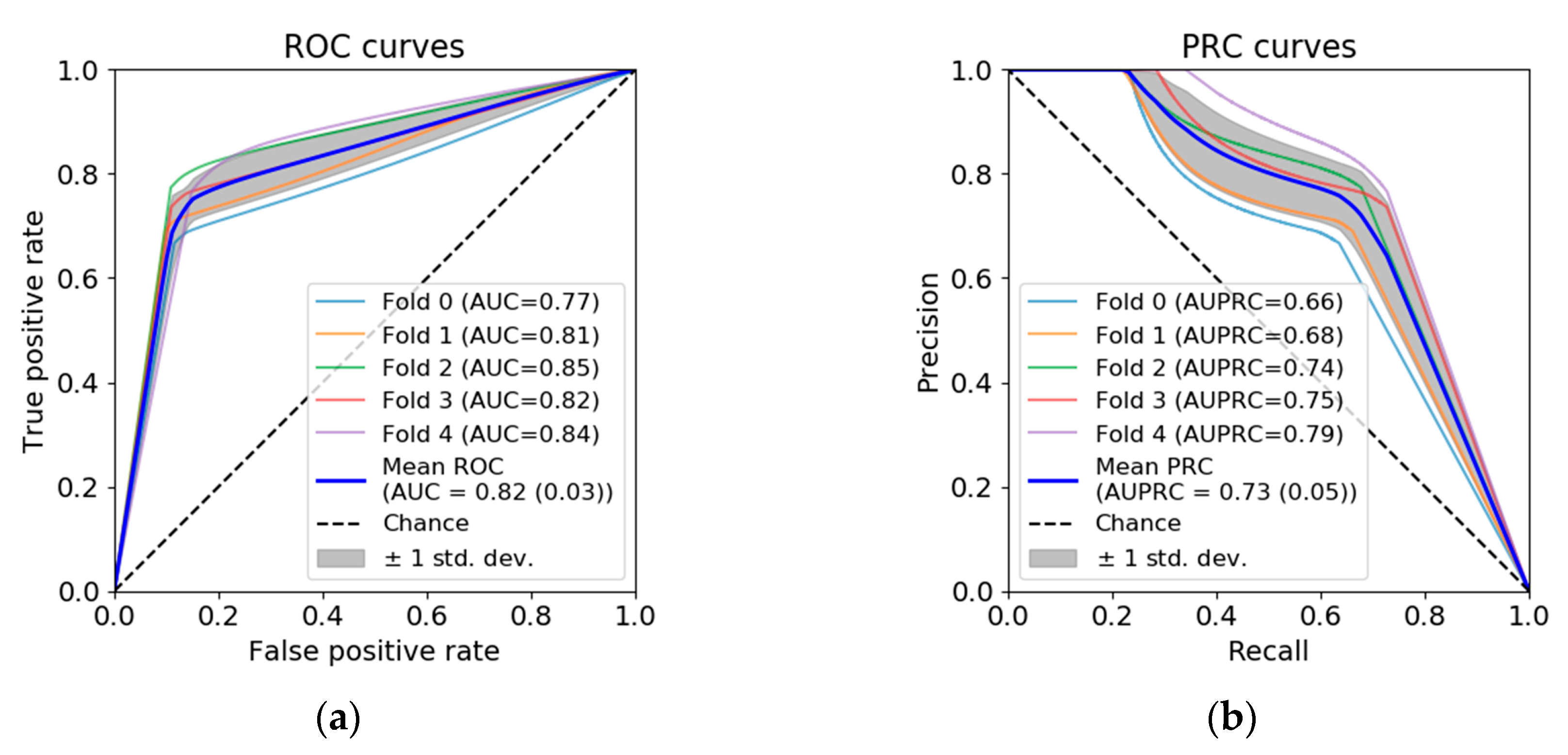
To test the robustness of the segmentation, the model was five-fold cross-validated, using randomly created folds from the 75 UWF-FA dataset. The performance of the different folds was evaluated using AUC (area under the receiving operating characteristic, ROC) and AUPRC (area under precision-recall curves, PCR). ROC curves illustrate the relation between the true positive rate (TPR, a.k.a. sensitivity or recall) and the false positive rate (FPR) when the discrimination threshold of the model is varied. PCR curves similarly describe the relation between precision (PR) and recall (RC). Precision (resp. recall) is the measure of effectiveness in identifying positive pixels among all pixels identified as positives (resp. all pixels labelled as positives). Thus, PRC curves are commonly suggested for class imbalanced data. Curves for the different folds were averaged, and the corresponding AUC and AUPRC were studied.
We defined the automated segmentation at the centred operating point (middle discriminative threshold) as an independent grader. Performance results were computed independently for all images in every test fold, and averaged through the whole dataset. Both dense segmentation and concentric grid assessment were evaluated, as well as inter-grader agreement. Reduced consensus regarding the gradable retina region led us to limit the assessment of inter-grader variability to CNP segmentation within the gradable retina provided by the first grader.
For quantitative analysis of the experimental results on dense segmentation, precision, recall, and dice coefficient, that (DSC) combines PR and RC notions, were studied. Using values of true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN), the metrics are defined as , and .
Cohen’s kappa coefficient was used to evaluate concordance between circular grid assessments. We used Cohen’s kappa coefficient as a measure of agreement for categorical data that considers agreement by chance [
21,
22]. The concordance between human graders (inter-grader reliability) and automated assessments of dense segmentations (automated dense segmentation and human grander manual segmentations) were evaluated. Following standard protocols in perfusion inter-rater assessment, kappa statistics were independently evaluated for each image, and averaged through the entire dataset (standard error is also reported) [
23]. Unweighted kappa values were used to equally emphasize different kinds of disagreement.
We also investigated the concordance between the average number of perfused and non-perfused segments identified by the automated methodology and grader 1. As a measure of agreement between quantitative measurements, intraclass correlation coefficients (ICC), and 95% confidence intervals (CI), were evaluated [
24]. The number of perfused and non-perfused segments by both grader 1 and the automated methodology were also independently investigated for each of the six rings demarcated by the grid.
4. Discussion
In our study, we explored the viability of deep learning-based quantification of CNP, and propose an implementation that demonstrates this technology can be used to diagnose and monitor CNP progression. Our implementation uses a fully convolutional deep learning method to extract a CNP dense segmentation. Subsequently, an automatic grid assessment is performed, to provide a repeatable description of the topographical distribution of the CNP regions.
Developing and validating deep learning algorithms is a rapidly advancing field in medicine, with a desire to rapidly translate to practice, to ease the pressures of the exponential increase in clinic appointments in all health sectors. Whilst most of these algorithms are developed to diagnose conditions that can be already well-ascertained by clinicians, they also have a role in situations where clinicians face challenges in accurately measuring pathological findings, even if time factor is not an issue. Here, we report a cautious approach of development and validation of a supervised deep learning algorithm in such a scenario, and enumerate the challenges faced and the proposed solutions. The study is performed on a newly created dataset limited to 75 UWF-FA images, manually segmented and graded by experts. Please note that the dataset’s size compares favorably with complementary datasets (DRIVE, STARE) used for assessing retinal vessel segmentation algorithms [
25,
26].
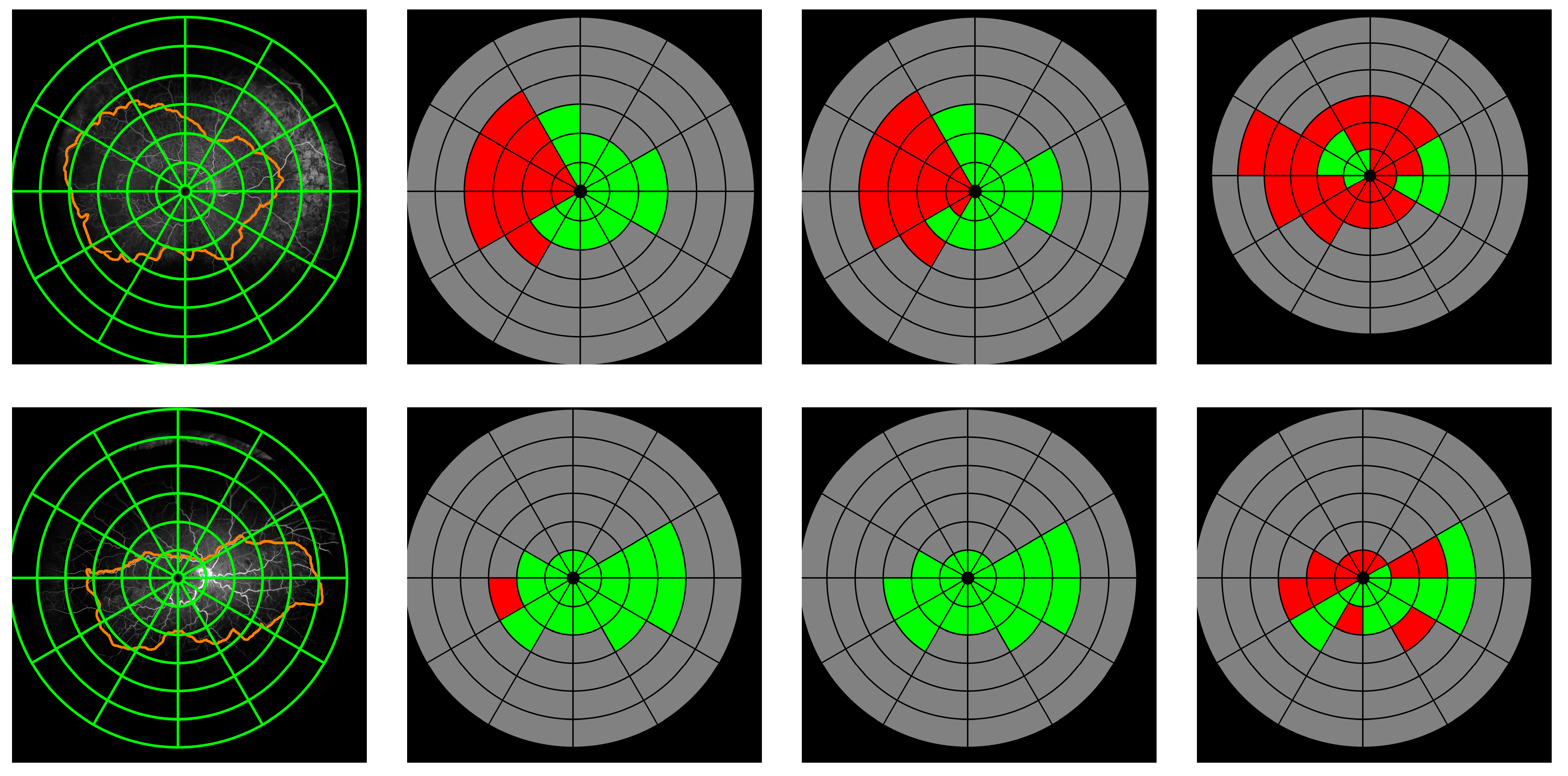
We have shown that dense segmentation of CNP regions is a challenging task for both human graders and deep learning-based models. The performance reached by the fully convolutional network was similar to that obtained by human grader agreement. That behaviour has been confirmed when investigating the distribution of CNP in the concentric rings. Intergrader agreement has shown second grader had identified more regions as non-perfused, annotating 36.33% (12.93) of the gradable retina, compared to grader 1 annotation of 25.63% (12.81). Nonetheless, as reflected by recall value, some CNP regions remained unidentified by second grader, which confirmed the differences cannot simply be explained by a less strict threshold in CNP identification and demonstrate the variability and complexity of the task.
We have introduced a second stage in the automated methodology, that has demonstrated the potential of an automatic grid-based assessment to describe retinal CNP topology. The automated methodology, with an averaged kappa value of 0.55, demonstrates higher agreement than the second grader, reaching 0.43. ICC values on the numbers of perfused and nonperfused segments confirm the same trend, though showing much higher agreement in both cases. Furthermore, similar values of the ICC measure have been shown when independently assessed within the different rings. This suggests the strength of the automated algorithm, despite contrast and illumination challenges in different areas of the retina.
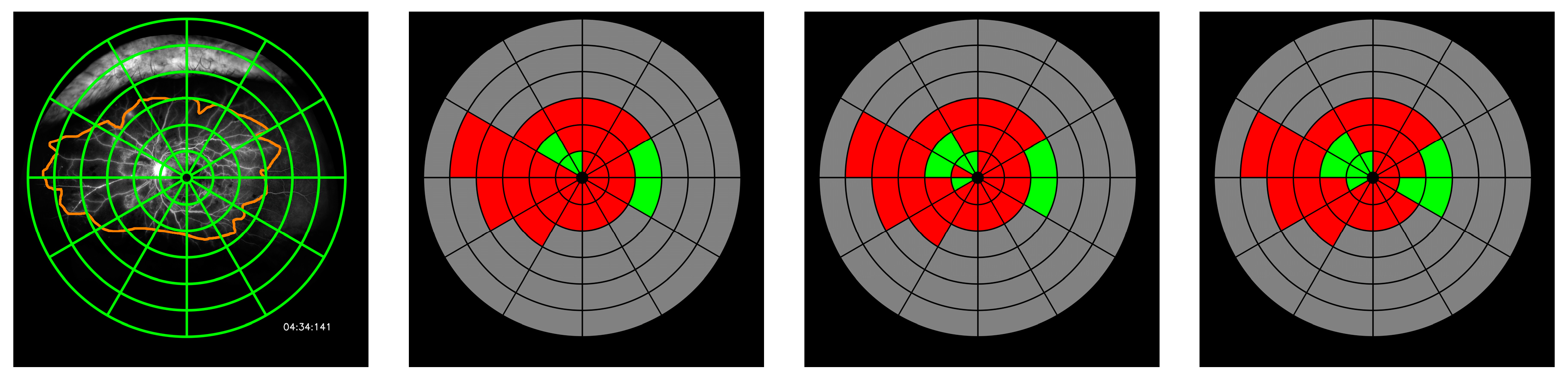
Cohen’s kappa values have proved to be a very strict measure, due to its consideration of agreement by chance. When kappa is measured independently for each image, agreement by chance is computed from that specific image. Similar annotations on mostly perfused (or non-perfused) retinas can result in low kappa values, because of the high agreement by chance. That case is illustrated by the bottom example in
Figure 5, in which similar kappa values are achieved by the automated system and grader 1, despite important annotating differences.
The challenges in quantifying CNP on UWF-FA of the retina are as follows. Firstly, although UWF captures 200 degrees of the retina, only about 100 degrees of the retina is gradable for CNP, because of artefacts such as eyelashes obscuring the view, especially in the superior and inferior retina; the peripheral retina is normally non-vascularised in some areas in some patients and it is challenging to distinguish normal retinal non-perfusion from pathology. Therefore, we need to first identify the boundary of the gradable retina (region of interest). This boundary may not be the same in consecutive visits, so it is more pragmatic to only concentrate in changes in the posterior retina. Posterior retinal CNP is also a marker of increasing disease severity [
27]. In order to ensure that, we measure the same area in consecutive visits, we used the validated concentric grid and named each sector or zone in the gradable retina to ensure we only compare the same gradable retina in both visits.
Secondly, the quality of fundus images may be influenced by eye movement, non-alignment or poor focus of the camera, small pupil or uneven illumination. This requires image pre-processing. Deep learning on pre-processed images introduces challenges in translation to clinical practice. Moreover, there are significant variations in gradations in the ground glass appearance of CNP, so, even in gradable zones, there is a tendency to ignore small areas of CNP that are difficult to define manually. This study is an evidence of the low intra-grader and intergrader agreement. Here, we chose to train the deep learning on the images, where several subtle areas of CNP were missed to resemble as closely as possible to clinical practice. One could argue that the algorithm should be developed on the images in which all tiny areas of CNP were identified by the human grader, but we believe this will possibly result in the over fitting of the algorithm.
Whilst a rough global estimate of CNP was sufficient previously when no treatment was available, novel therapies are being evaluated to prevent progression or reverse CNP, and so a more accurate measure of CNP is required. This study shows that the agreement between deep learning algorithm and human grader is similar to human grader agreement, highlighting the potential use of this algorithm as an outcome measure in clinical trials and a decision tool in clinical practice.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}