
Classification of Fine-Grained Crop Disease by Dilated Convolution and Improved Channel Attention Module

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Set Acquisition and Analysis
2.2. Loss Function for Uneven Sample Distribution
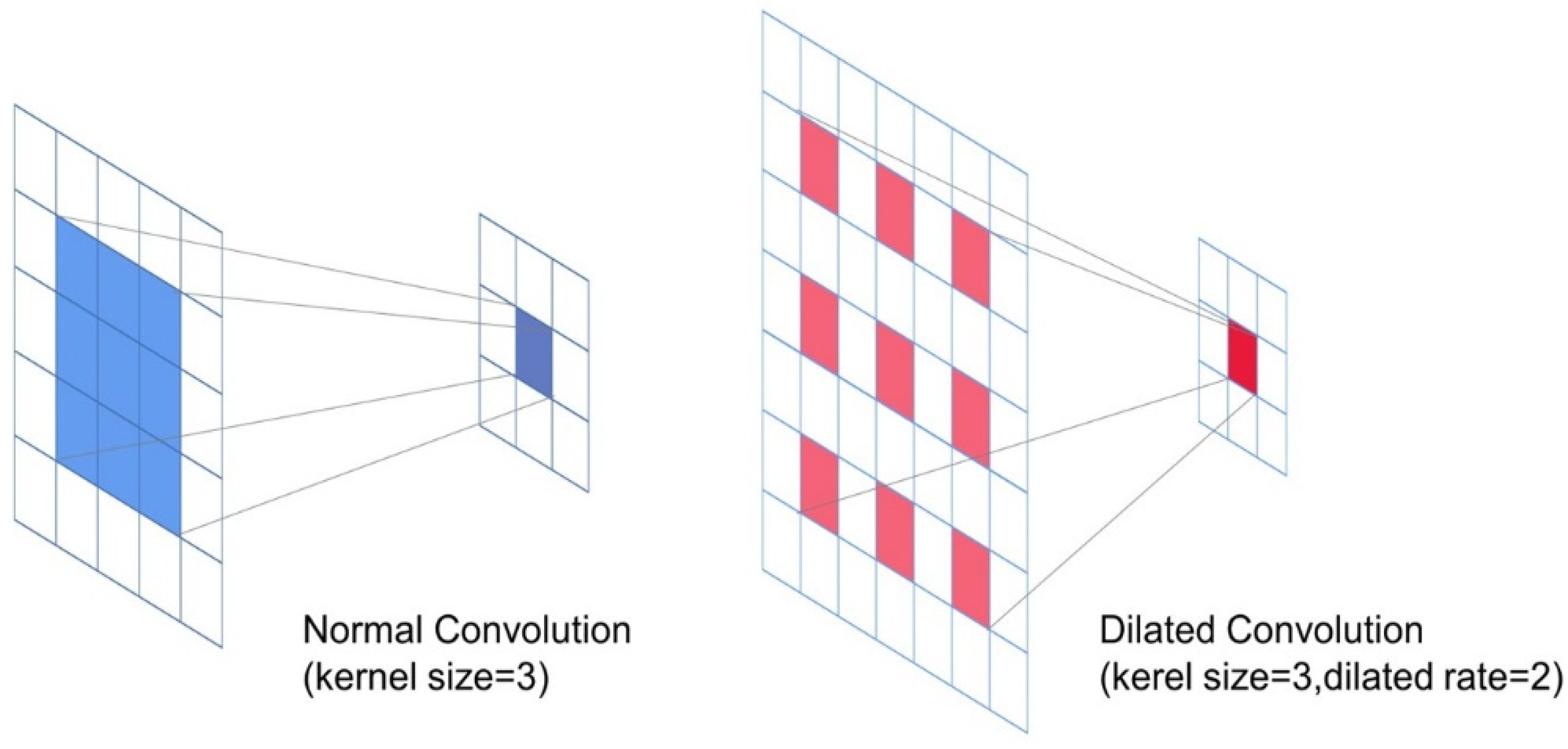
2.3. Dilated Convolution
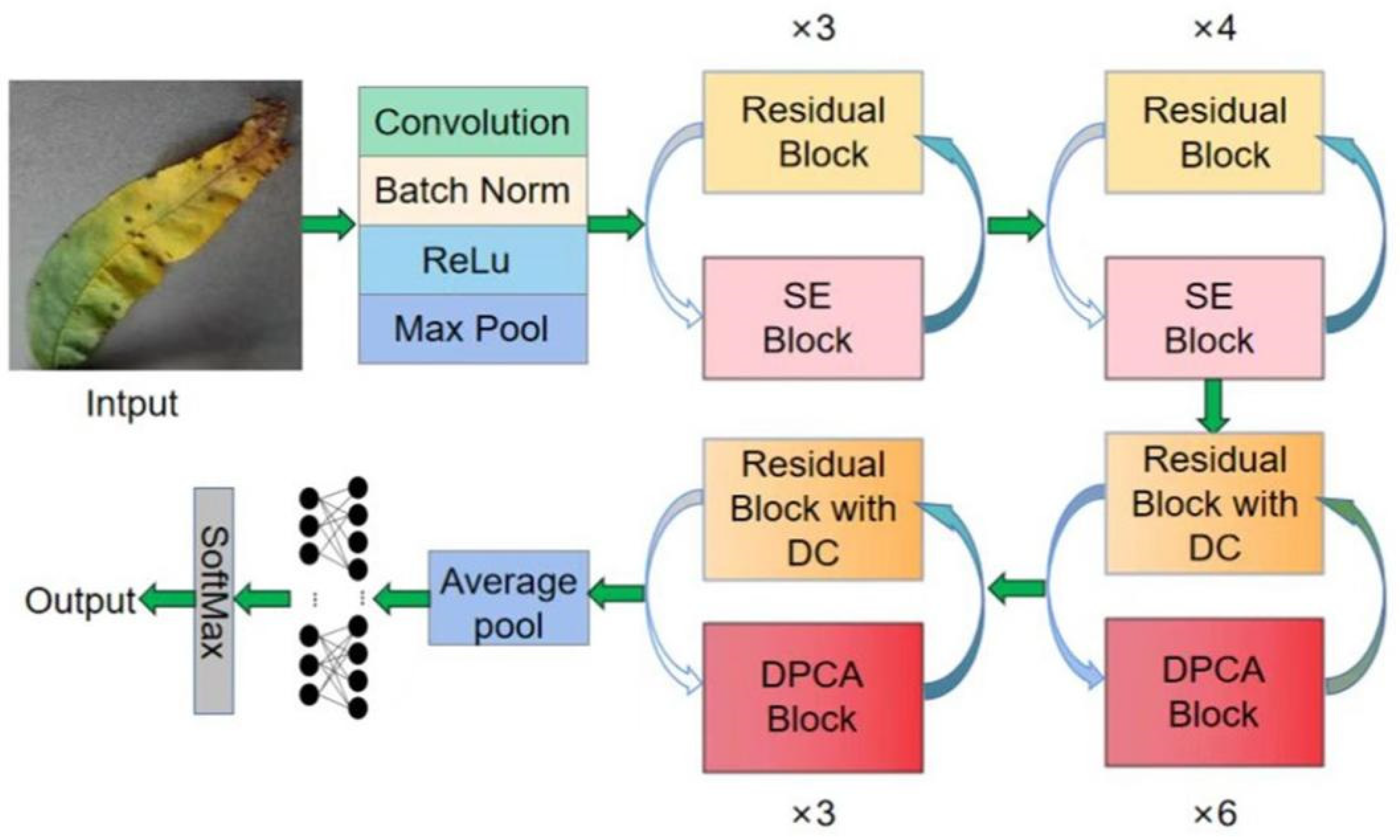
2.4. DC-DPCA Module
2.5. Experimental Setup
2.6. Evaluation Metrics
3. Results
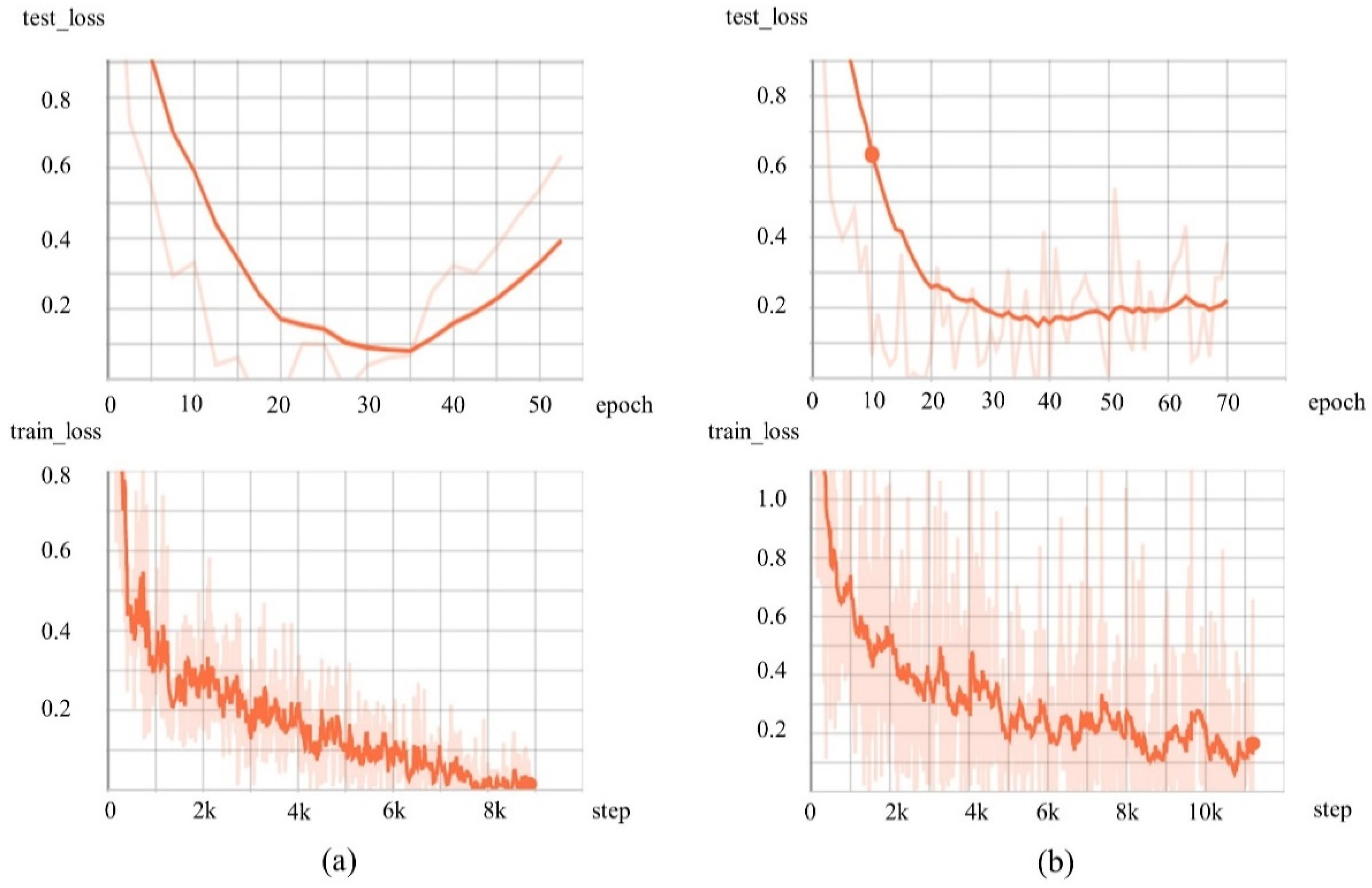
3.1. The Impact of L-Balance Loss Function
3.2. Ablation Experiments
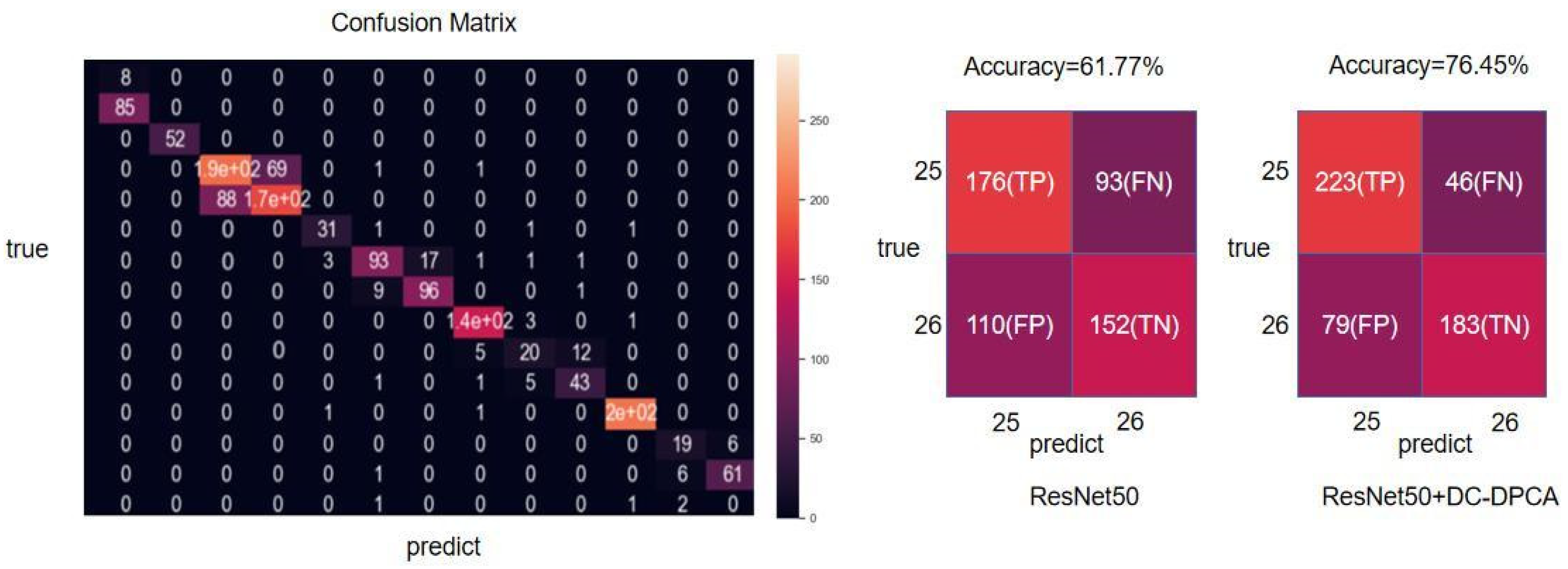
3.3. Experiments on Different Networks
3.4. Visual Verification
3.4.1. Visualization of the Effective Receptive Field
3.4.2. T-SNE Visualization
3.4.3. Grad-CAM Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Lu, J.Z.; Tan, L.J.; Jiang, H.Y. Review on Convolutional Neural Network (CNN) Applied to Plant Leaf Disease Classification. Agriculture 2021, 11, 707. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Peng, Y.; Liu, J.Z.; Wu, S. Tomato Leaf Disease Diagnosis Based on Improved Convolution Neural Network by Attention Module. Agriculture 2021, 11, 651. [Google Scholar] [CrossRef]
- Bhujel, A.; Kim, N.E.; Arulmozhi, E.; Basak, J.K.; Kim, H.T. A Lightweight Attention-Based Convolutional Neural Networks for Tomato Leaf Disease Classification. Agriculture 2022, 12, 228. [Google Scholar] [CrossRef]
- Das, V.J.; Sharma, S.; Kaushik, A. Views of Irish Farmers on Smart Farming Technologies: An Observational Study. AgriEngineering 2019, 1, 164–187. [Google Scholar]
- Yadav, S.; Kaushik, A.; Sharma, M.; Sharma, S. Disruptive Technologies in Smart Farming: An Expanded View with Sentiment Analysis. AgriEngineering 2022, 4, 424–460. [Google Scholar] [CrossRef]
- Kaur, S.; Pandey, S.; Goel, S. Plants Disease Identification and Classification Through Leaf Images: A Survey. Arch. Comput. Method Eng. 2019, 26, 507–530. [Google Scholar] [CrossRef]
- Guan, Z.; Tang, J.; Yang, B.; Zhou, Y.; Fan, D.; Yao, Q. Study on Recognition Method of Rice Disease Based on Image. Chin. J. Rice Sci. 2010, 24, 497–502. [Google Scholar]
- Jiang, L.; Lu, S.; Feng, R.; Guo, Y. A Plant Pests and Diseases Detection Method Based on Multi-Features Fusion and Svm Classifier. Comput. Appl. Softw. 2014, 31, 186–190. [Google Scholar]
- Huang, L.S.; Liu, Y.; Huang, W.J.; Dong, Y.Y.; Ma, H.Q.; Wu, K.; Guo, A.T. Combining Random Forest and XGBoost Methods in Detecting Early and Mid-Term Winter Wheat Stripe Rust Using Canopy Level Hyperspectral Measurements. Agriculture 2022, 12, 74. [Google Scholar] [CrossRef]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Wang, X.W. Plant diseases and pests detection based on deep learning: A review. Plant Methods 2021, 17, 18. [Google Scholar] [CrossRef] [PubMed]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Comput. Intell. Neurosci. 2016, 2016, 11. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Yi, S.J.; Zeng, N.Y.; Liu, Y.R.; Zhang, Y. Identification of rice diseases using deep convolutional neural networks. Neurocomputing 2017, 267, 378–384. [Google Scholar] [CrossRef]
- Bhatt, P.; Sarangi, S.; Shivhare, A.; Singh, D.; Pappula, S. Identification of Diseases in Corn Leaves using Convolutional Neural Networks and Boosting. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Prague, Czech Republic, 19–21 February 2019; Scitepress: Prague, Czech Republic, 2019; pp. 894–899. [Google Scholar]
- Yang, G.F.; He, Y.; Yang, Y.; Xu, B.B. Fine-Grained Image Classification for Crop Disease Based on Attention Mechanism. Front. Plant Sci. 2020, 11, 600854. [Google Scholar] [CrossRef] [PubMed]
- Gao, R.; Wu, H.; Sun, X.; Gu, J. Crop Disease Recognition Method Based on Improved Channel Attention Mechanism. In Proceedings of the 2021 International Conference on Intelligent Computing, Automation and Applications, ICAA 2021, Nanjing, China, 25–27 June 2021; Institute of Electrical and Electronics Engineers Inc.: Nanjing, China, 2021; pp. 537–541. [Google Scholar]
- Chen, Z.; Cao, M.; Ji, P.; Ma, F. Research on Crop Disease Classification Algorithm Based on Mixed Attention Mechanism. In Proceedings of the 2021 International Conference on Computer Engineering and Innovative Application of VR, ICCEIA VR 2021, Guangzhou, China, 11–13 June 2021; IOP Publishing Ltd.: Guangzhou, China, 2021. [Google Scholar]
- Wang, M.; Wu, Z.; Zhou, Z. Fine-grained Identification Research of Crop Pests and Diseases Based on Improved CBAM via Attention. Trans. Chin. Soc. Agric. Mach. 2021, 52, 239–247. [Google Scholar]
- Luo, W.J.; Li, Y.J.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; Neural Information Processing Systems (Nips): Barcelona, Spain, 2016. [Google Scholar]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Huang, Y.; Wang, Q.Q.; Jia, W.J.; Lu, Y.; Li, Y.X.; He, X.J. See more than once: Kernel-sharing atrous convolution for semantic segmentation. Neurocomputing 2021, 443, 26–34. [Google Scholar] [CrossRef]
- Li, Y.H.; Chen, Y.T.; Wang, N.Y.; Zhang, Z.X. Scale-Aware Trident Networks for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 11–17 October 2021; IEEE: Seoul, Korea, 2019; pp. 6053–6062. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 14–19 June 2020; IEEE Computer Society: New York, NY, USA, 2020; pp. 11531–11539. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE Computer Society: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Pan, S.J.; Yang, Q.A. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; ICLR: Toulon, France, 2017. [Google Scholar]
- Wang, P.Q.; Chen, P.F.; Yuan, Y.; Liu, D.; Huang, Z.H.; Hou, X.D.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 18th IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Manhattan, NY, USA, 2018; pp. 1451–1460. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015; ICLR: San Diego, CA, USA, 2015. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; IEEE: Seattle, WA, USA, 2016; pp. 2818–2826. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 618–626. [Google Scholar]
- Sun, W.; Wang, R.; Gao, R.; Li, Q.; Wu, H.; Feng, L. Crop Disease Recognition Based on Visible Spectrum and Improved Attention Module. Spectrosc. Spectr. Anal. 2022, 42, 1572–1580. [Google Scholar]
- Gao, R.H.; Wang, R.; Feng, L.; Li, Q.F.; Wu, H.R. Dual-branch, efficient, channel attention-based crop disease identification. Comput. Electron. Agric. 2021, 190, 10. [Google Scholar] [CrossRef]
- Lin, J.W.; Chen, X.Y.; Pan, R.Y.; Cao, T.B.; Cai, J.T.; Chen, Y.; Peng, X.S.; Cernava, T.; Zhang, X. GrapeNet: A Lightweight Convolutional Neural Network Model for Identification of Grape Leaf Diseases. Agriculture 2022, 12, 887. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameter |
|---|---|
| System | Windows 10 |
| CPU | Intel(R) Core (TM) i5-6200U CPU |
| GPU | NVIDIA GeForce RTX 1080Ti |
| Deep learning framework | Pytorch 1.10.0 + cuda toolkit 10.1 |
| Programming language | Python 3.7.0 |
| Environment construction | Anaconda 3 |
| Loss Function | Accuracy |
|---|---|
| Cross-entropy | 83.66% |
| L-balance | 85.38% |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| ResNet50 | 85.38% | 85.13% | 84.80% | 85.06% |
| ResNet50 + SE | 85.70% | 85.21% | 85.77% | 85.48% |
| ResNet50 + DC-CA | 86.25% | 86.20% | 86.43% | 86.33% |
| ResNet50 + DPCA | 86.28% | 85.54% | 86.32% | 86.13% |
| ResNet50 + DC-DPCA | 87.14% | 87.17% | 87.07% | 87.10% |
| Original Model | Attention Module | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| VGG16 | --- | 83.22% | 82.93% | 83.25% | 82.96% |
| SE | 85.42% | 84.72% | 85.40% | 85.22% | |
| DC-DPCA | 86.26% | 85.76% | 86.41% | 86.20% | |
| MobileNetV2 | --- | 83.85% | 83.77% | 83.93% | 83.80% |
| SE | 85.18% | 85.02% | 85.29% | 85.16% | |
| DC-DPCA | 86.24% | 86.35% | 86.22% | 86.23% | |
| InceptionV3 | --- | 84.60% | 84.30% | 84.58% | 84.34% |
| SE | 85.84% | 85.83% | 85.48% | 85.59% | |
| DC-DPCA | 86.77% | 86.73% | 86.70% | 86.72% |
| Paper | Model | Classification | Accuracy | Parameter | Time |
|---|---|---|---|---|---|
| Wang et al. [19] | InResV2 + I_CBAM | 61-class | 86.98% | 122.47 MB | 13.4 ms |
| Sun et al. [35] | SMLP_ResNet18 | 61-class | 86.93% | 48.6 MB | 4.8 ms |
| Gao et al. [36] | DECA_ResNet50 | 61-class | 86.35% | 26.16 MB | 2.3 ms |
| Lin et al. [37] | GrapeNet | 7-class | 86.29% | 2.15 MB | 1.9 ms |
| Ours | DC-DPCA + ResNet | 59-class | 87.14% | 26.13 MB | 2.2 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Gao, H.; Wan, L. Classification of Fine-Grained Crop Disease by Dilated Convolution and Improved Channel Attention Module. Agriculture 2022, 12, 1727. https://doi.org/10.3390/agriculture12101727
Zhang X, Gao H, Wan L. Classification of Fine-Grained Crop Disease by Dilated Convolution and Improved Channel Attention Module. Agriculture. 2022; 12(10):1727. https://doi.org/10.3390/agriculture12101727
Chicago/Turabian StyleZhang, Xiang, Huiyi Gao, and Li Wan. 2022. "Classification of Fine-Grained Crop Disease by Dilated Convolution and Improved Channel Attention Module" Agriculture 12, no. 10: 1727. https://doi.org/10.3390/agriculture12101727
APA StyleZhang, X., Gao, H., & Wan, L. (2022). Classification of Fine-Grained Crop Disease by Dilated Convolution and Improved Channel Attention Module. Agriculture, 12(10), 1727. https://doi.org/10.3390/agriculture12101727