

Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease




Abstract
:1. Introduction
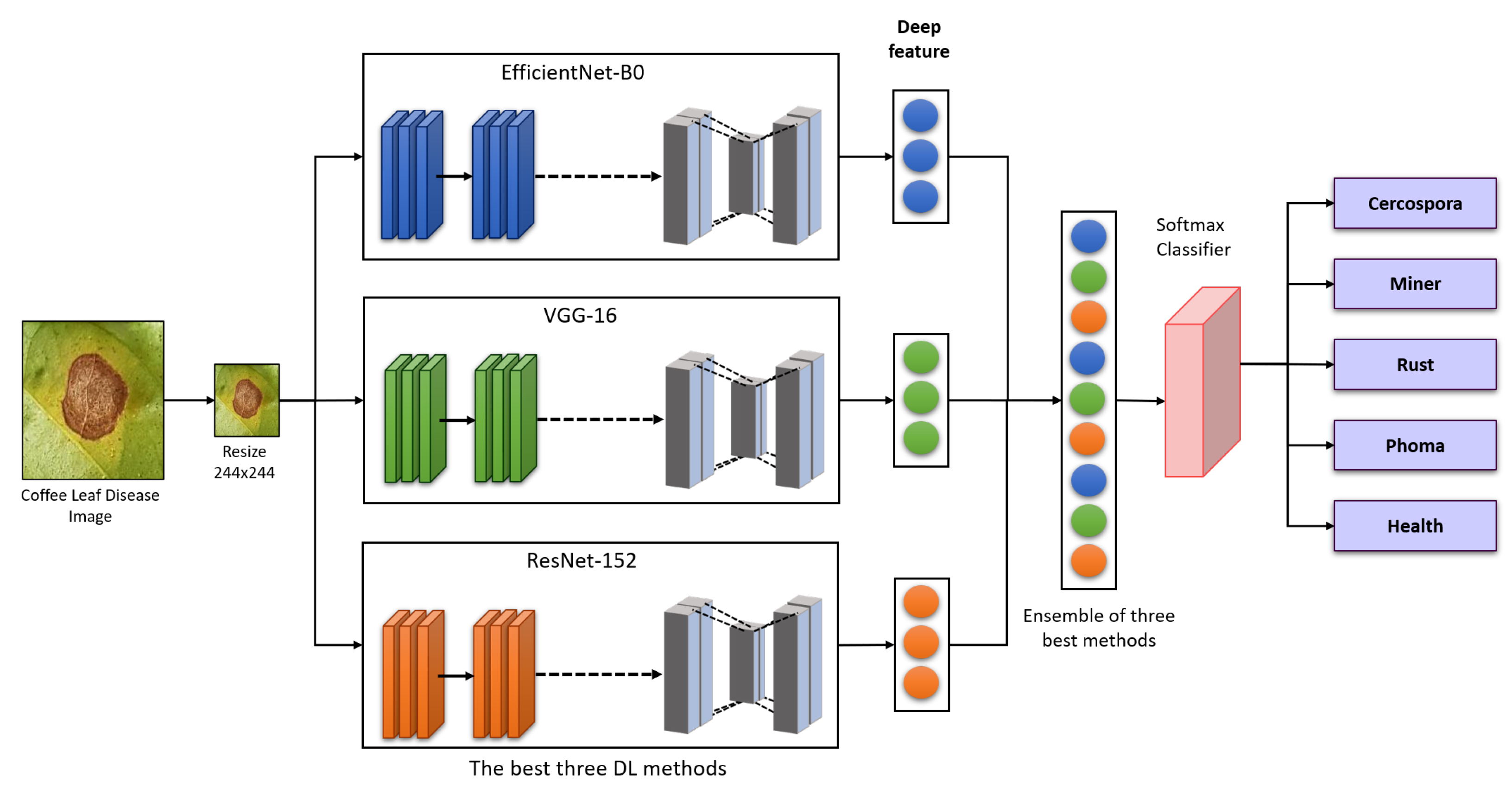
- We develop a collaborative ensemble architecture to classify the diseases in coffee plants. The proposed strategy is based on re-training the pre-trained DL models using the coffee disease dataset and combining the weights of the three best-performing algorithms to make an ensemble architecture for better disease detection in coffee leaf.
- The pre-trained DL models utilized in this study are fine-tuned using our proposed layers, which can replace traditional disease detection in plants and improve overall classification accuracy.
- A data pre-processing and data augmentation strategy is employed to improve the poor image quality of the training data and increase the diversity in input data to generate better outcomes on small datasets.
- The effectiveness of the proposed architecture is assessed with several hyper-parameters such as activation functions, batch size, learning rate, and L2 regularizer, to increase classification accuracy. This ablation study demonstrates how our architecture outperforms the previous state-of-the-art studies in detecting coffee leaf diseases.
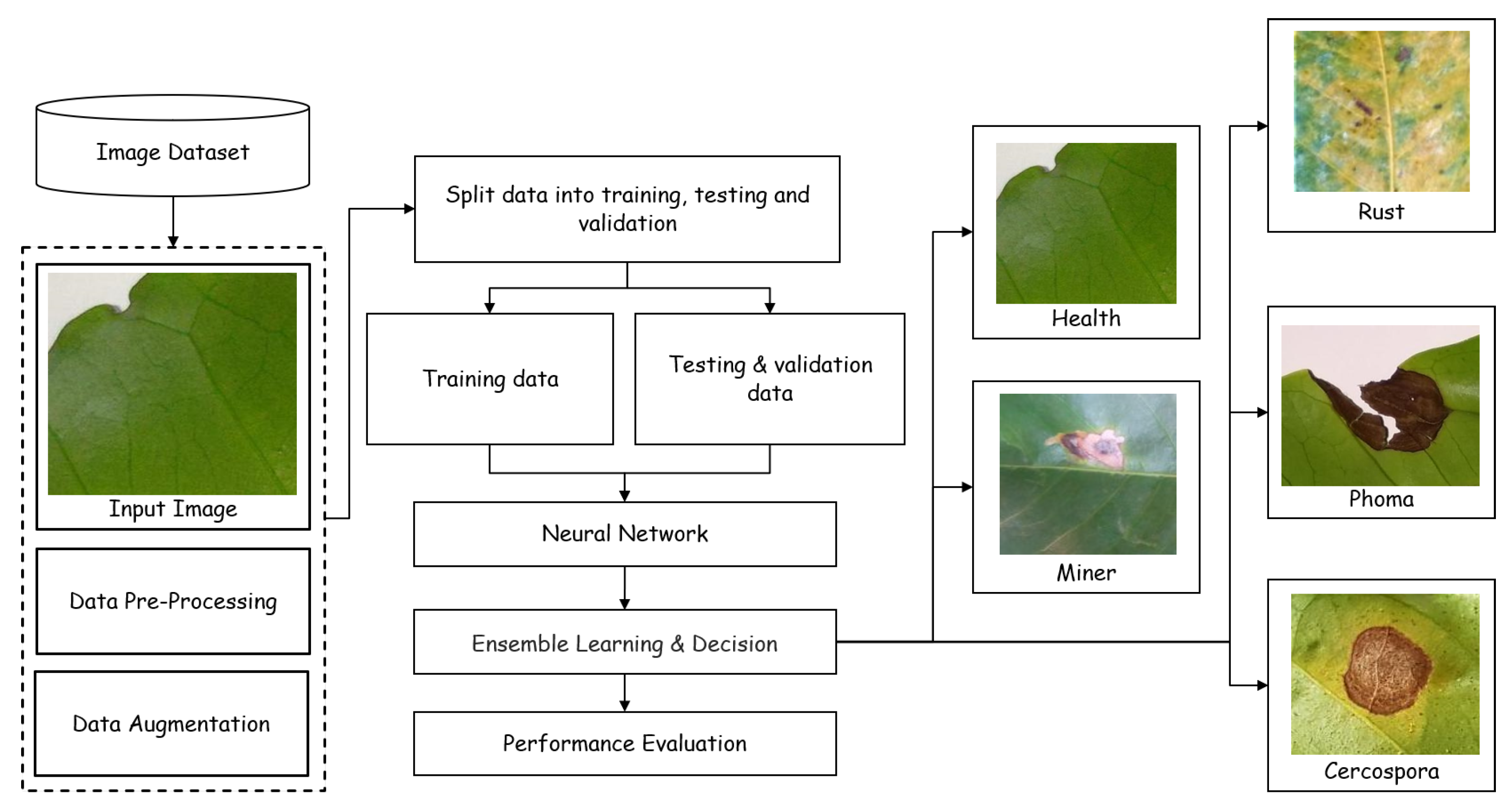
2. Materials and Methods
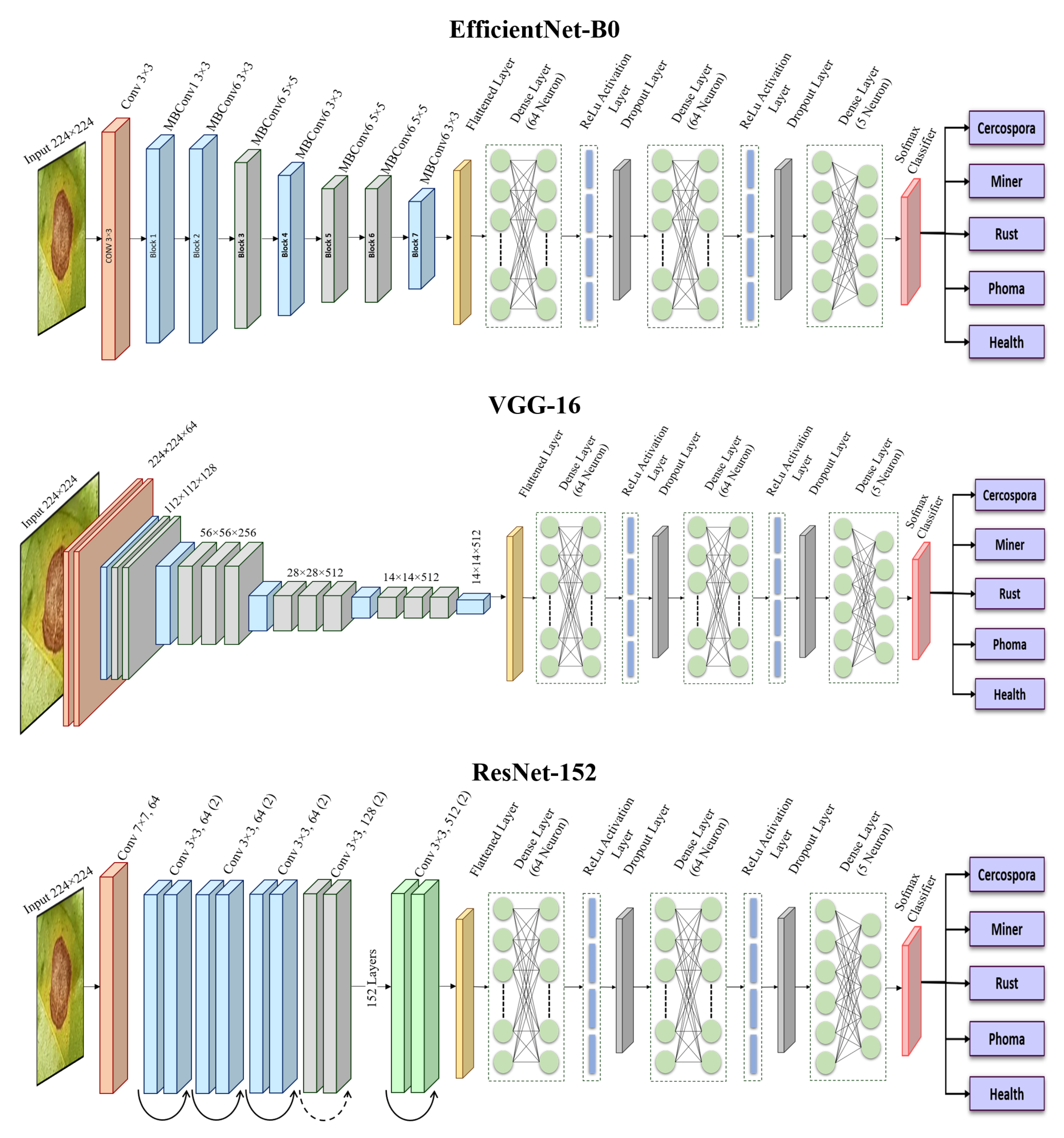
2.1. Ensemble Method
2.2. Fine Tuning and Transfer Learning
2.3. Loss Function and Hyper-Parameter
2.4. Dataset
2.5. Data Preprocessing and Augmentation
2.6. Experimental Setup
2.7. Performance Evaluation Metrics
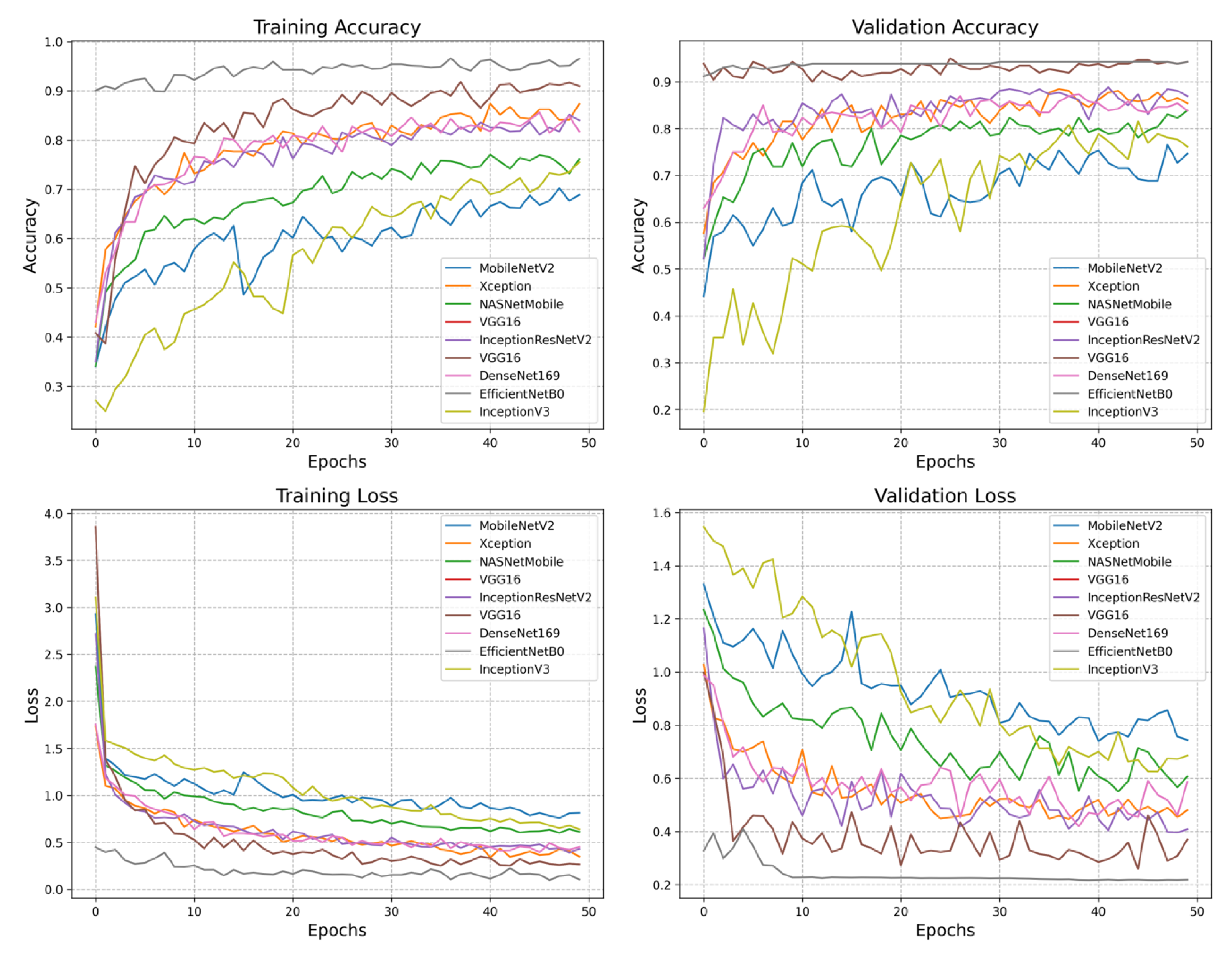
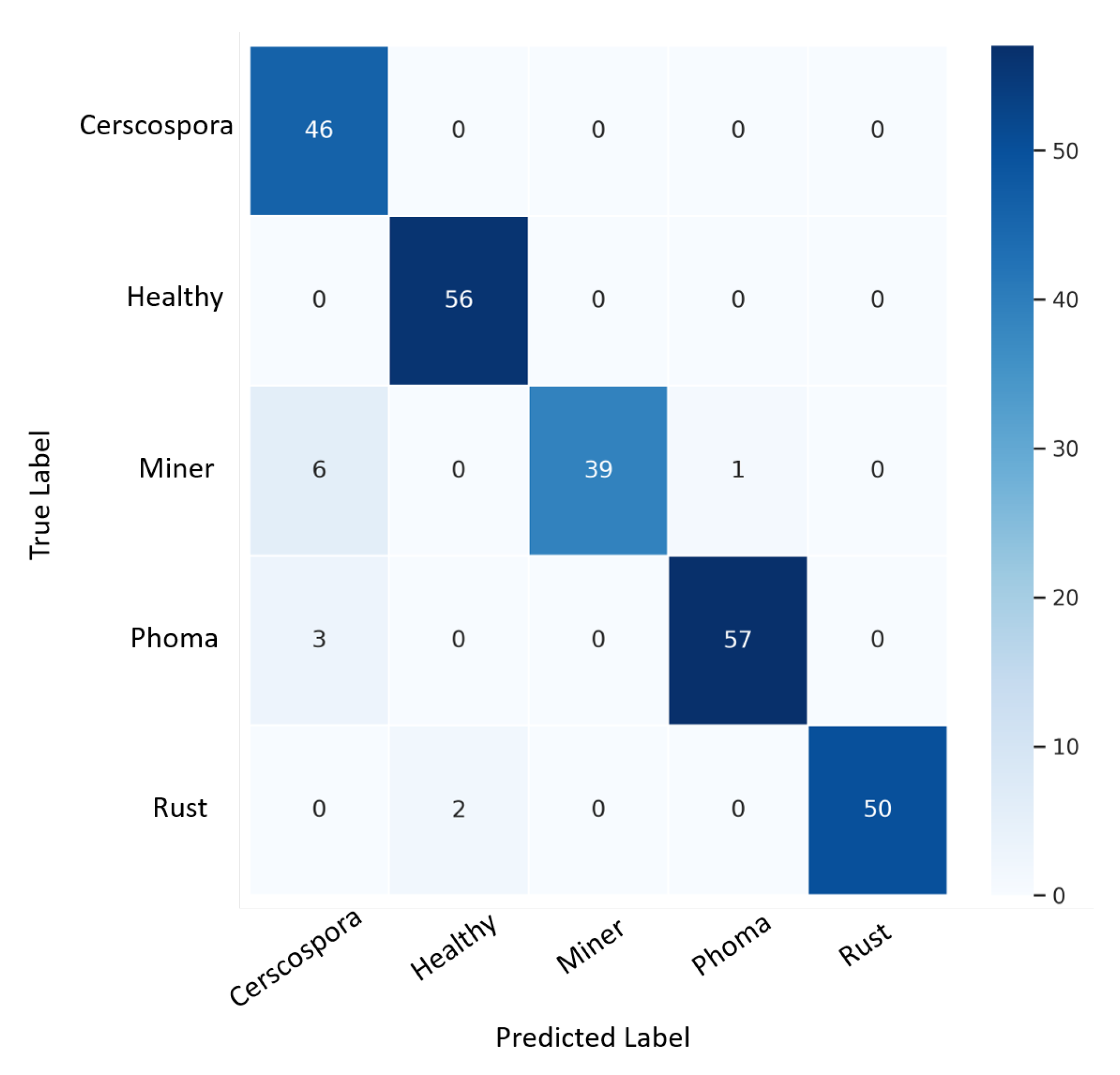
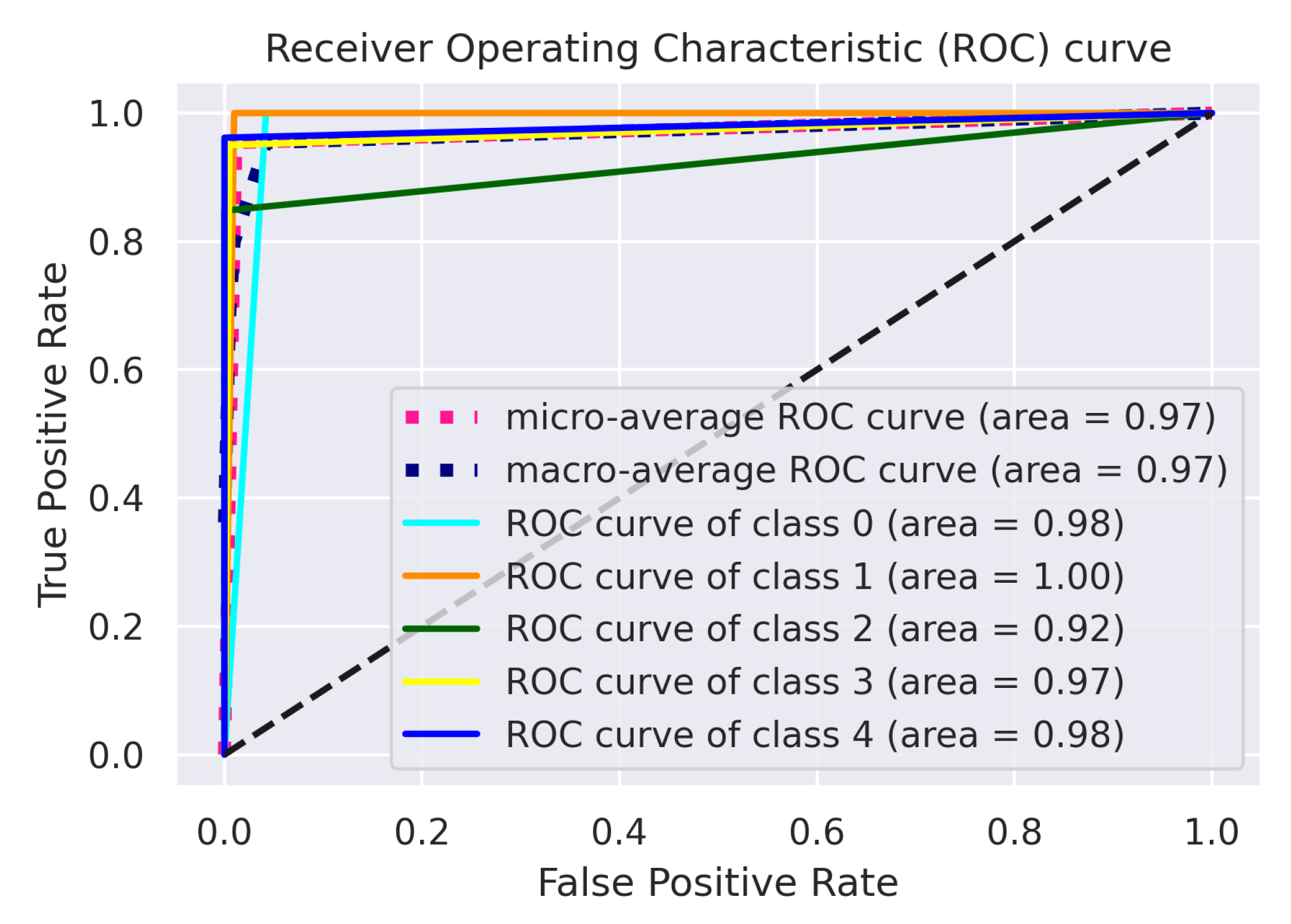
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep learning |
| CNN | Convolutional neural networks |
| TP | True positive |
| TN | True negative |
| FP | False positive |
| FN | False negative |
| PR | Precision |
| SN | Sensitivity |
| SP | Specificity |
| F1 | F1-score |
| ACC | Accuracy |
References
- Voora, V.; Bermúdez, S.; Larrea, C. Global Market Report: Coffee; IISD: Winnipeg, MB, Canada, 2019. [Google Scholar]
- Esgario, J.G.; de Castro, P.B.; Tassis, L.M.; Krohling, R.A. An app to assist farmers in the identification of diseases and pests of coffee leaves using deep learning. Inf. Process. Agric. 2022, 9, 38–47. [Google Scholar] [CrossRef]
- Kranz, J. Measuring plant disease. In Experimental Techniques in Plant Disease Epidemiology; Springer: Berlin/Heidelberg, Germany, 1988; pp. 35–50. [Google Scholar]
- Sabrina, S.A.; Maki, W.F.A. Klasifikasi Penyakit Pada Tanaman Kopi Robusta Berdasarkan Citra Daun Menggunakan Convolutional Neural Network. eProc. Eng. 2022, 3, 1919. [Google Scholar]
- Hoosain, M.S.; Paul, B.S.; Ramakrishna, S. The Impact of 4IR Digital Technologies and Circular Thinking on the United Nations Sustainable Development Goals. Sustainability 2020, 12, 10143. [Google Scholar] [CrossRef]
- Dhanaraju, M.; Chenniappan, P.; Ramalingam, K.; Pazhanivelan, S.; Kaliaperumal, R. Smart Farming: Internet of Things (IoT)-Based Sustainable Agriculture. Agriculture 2022, 12, 1745. [Google Scholar] [CrossRef]
- Hitimana, E.; Gwun, O. Automatic estimation of live coffee leaf infection based on image processing techniques. arXiv 2014, arXiv:1402.5805. [Google Scholar]
- Kouadio, L.; Deo, R.C.; Byrareddy, V.; Adamowski, J.F.; Mushtaq, S.; Nguyen, V.P. Artificial intelligence approach for the prediction of Robusta coffee yield using soil fertility properties. Comput. Electron. Agric. 2018, 155, 324–338. [Google Scholar] [CrossRef]
- Shah, H.A.; Saeed, F.; Yun, S.; Park, J.H.; Paul, A.; Kang, J.M. A Robust Approach for Brain Tumor Detection in Magnetic Resonance Images Using Finetuned EfficientNet. IEEE Access 2022, 10, 65426–65438. [Google Scholar] [CrossRef]
- Mendieta, M.; Neff, C.; Lingerfelt, D.; Beam, C.; George, A.; Rogers, S.; Ravindran, A.; Tabkhi, H. A Novel Application/Infrastructure Co-design Approach for Real-time Edge Video Analytics. In Proceedings of the 2019 SoutheastCon, Huntsville, AL, USA, 11–14 April 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Montalbo, F.J.; Hernandez, A. Classifying Barako coffee leaf diseases using deep convolutional models. Int. J. Adv. Intell. Inform. 2020, 6, 197–209. [Google Scholar] [CrossRef]
- Dutta, L.; Rana, A.K. Disease Detection Using Transfer Learning In Coffee Plants. In Proceedings of the 2021 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 1–3 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Montalbo, F.J.P.; Hernandez, A.A. An Optimized Classification Model for Coffea Liberica Disease using Deep Convolutional Neural Networks. In Proceedings of the 2020 16th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), Langkawi, Malaysia, 28–29 February 2020; pp. 213–218. [Google Scholar] [CrossRef]
- Lee, S.H.; Goëau, H.; Bonnet, P.; Joly, A. New perspectives on plant disease characterization based on deep learning. Comput. Electron. Agric. 2020, 170, 105220. [Google Scholar] [CrossRef]
- Kensert, A.; Harrison, P.J.; Spjuth, O. Transfer Learning with Deep Convolutional Neural Networks for Classifying Cellular Morphological Changes. SLAS Discov. Adv. Sci. Drug Discov. 2019, 24, 466–475. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Costa, A.; Rodrigues, D.; Castro, M.; Assis, S.; Oliveira, H.P. The effect of augmentation and transfer learning on the modelling of lower-limb sockets using 3D adversarial autoencoders. Displays 2022, 74, 102190. [Google Scholar] [CrossRef]
- George, A.; Ravindran, A. Scalable Approximate Computing Techniques for Latency and Bandwidth Constrained IoT Edge. In Science and Technologies for Smart Cities; Paiva, S., Lopes, S.I., Zitouni, R., Gupta, N., Lopes, S.F., Yonezawa, T., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 274–292. [Google Scholar]
- Ahmed, M.J.; Saeed, F.; Paul, A.; Jan, S.; Seo, H. A new affinity matrix weighted k-nearest neighbors graph to improve spectral clustering accuracy. PeerJ Comput. Sci. 2021, 7, e692. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Hui, J.; Qin, Q.; Sun, Y.; Zhang, T.; Sun, H.; Li, M. Transfer-learning-based approach for leaf chlorophyll content estimation of winter wheat from hyperspectral data. Remote Sens. Environ. 2021, 267, 112724. [Google Scholar] [CrossRef]
- Marcos, A.P.; Silva Rodovalho, N.L.; Backes, A.R. Coffee Leaf Rust Detection Using Genetic Algorithm. In Proceedings of the 2019 XV Workshop de Visão Computacional (WVC), Sao Paulo, Brazil, 9–11 September 2019; pp. 16–20. [Google Scholar] [CrossRef]
- Gutte, V.S.; Gitte, M.A. A survey on recognition of plant disease with help of algorithm. Int. J. Eng. Sci. 2016, 6, 7100. [Google Scholar]
- Mengistu, A.D.; Alemayehu, D.M.; Mengistu, S.G. Ethiopian Coffee Plant Diseases Recognition Based on Imaging and Machine Learning Techniques. Int. J. Database Theory Appl. 2016, 9, 79–88. [Google Scholar] [CrossRef]
- Manso, G.L.; Knidel, H.; Krohling, R.A.; Ventura, J.A. A smartphone application to detection and classification of coffee leaf miner and coffee leaf rust. arXiv 2019, arXiv:1904.00742. [Google Scholar]
- Babu, M.S.P.; Rao, B.S. Leaves Recognition Using Back Propagation Neural Network-Advice for Pest & Disease Control on Crops. Available online: https://www.researchgate.net/publication/238770565_Leaves_recognition_using_back_propagation_neural_network-advice_for_pest_and_disease_control_on_crops (accessed on 23 October 2022).
- Marcos, A.P.; Silva Rodovalho, N.L.; Backes, A.R. Coffee Leaf Rust Detection Using Convolutional Neural Network. In Proceedings of the 2019 XV Workshop de Visão Computacional (WVC), Sao Paulo, Brazil, 9–11 September 2019; pp. 38–42. [Google Scholar] [CrossRef]
- Javierto, D.P.P.; Martin, J.D.Z.; Villaverde, J.F. Robusta Coffee Leaf Detection based on YOLOv3- MobileNetv2 model. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 28–30 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ramcharan, A.; McCloskey, P.; Baranowski, K.; Mbilinyi, N.; Mrisho, L.; Ndalahwa, M.; Legg, J.; Hughes, D.P. A Mobile-Based Deep Learning Model for Cassava Disease Diagnosis. Front. Plant Sci. 2019, 10, 272. [Google Scholar] [CrossRef] [Green Version]
- Aravind, K.R.; Raja, P. Automated disease classification in (Selected) agricultural crops using transfer learning. Automatika 2020, 61, 260–272. [Google Scholar] [CrossRef]
- Esgario, J.G.; Krohling, R.A.; Ventura, J.A. Deep learning for classification and severity estimation of coffee leaf biotic stress. Comput. Electron. Agric. 2020, 169, 105162. [Google Scholar] [CrossRef] [Green Version]
- Ray, A.; Ray, H. Study of Overfitting through Activation Functions as a Hyper-parameter for Image Clothing Classification using Neural Network. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Dogo, E.M.; Afolabi, O.J.; Nwulu, N.I.; Twala, B.; Aigbavboa, C.O. A Comparative Analysis of Gradient Descent-Based Optimization Algorithms on Convolutional Neural Networks. In Proceedings of the 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belgaum, India, 21–22 December 2018; pp. 92–99. [Google Scholar] [CrossRef]
- George, A. Distributed Messaging System for the IoT Edge. Ph.D. Thesis, The University of North Carolina at Charlotte, Charlotte, NC, USA, 2020. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Ting, K.M. Confusion matrix. In Encyclopedia of Machine Learning and Data Mining; Springer: Berlin/Heidelberg, Germany, 2017; Volume 260. [Google Scholar]
- Singh, P.; Singh, N.; Singh, K.K.; Singh, A. Chapter 5—Diagnosing of disease using machine learning. In Machine Learning and the Internet of Medical Things in Healthcare; Singh, K.K., Elhoseny, M., Singh, A., Elngar, A.A., Eds.; Academic Press: Cambridge, MA, USA, 2021; pp. 89–111. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Model | Strength | Weakness |
|---|---|---|---|
| [20] | Genetic Algorithm |
|
|
| [21] | Support Vector Machines |
|
|
| [23] | Extreme Learning Machine |
|
|
| [24] | Deep Convolutional Networks |
|
|
| [25] | Convolutional Neural Network | Simple morphology erosion improves the detection | Has a long runtime |
| [26] | YOLOv3-MobileNetv2 |
|
|
| [27] | Single-Shot Multibox (SSD) with MobileNet |
|
|
| [28] | ResNet101, VGG16, DenseNet201, GoogLeNet, AlexNet, and VGG19 |
|
|
| [29] | A Multi-task System Based on CNN |
|
|
| Ours | Ensemble Learning Technique |
|
|
| Models | Adam | SGD | RMSProp |
|---|---|---|---|
| VGG-16 | 94.2 | 93.1 | 93.9 |
| Inception-V3 | 83.9 | 83.8 | 78.6 |
| ResNet-152 | 93.8 | 93.8 | 90.3 |
| Xception | 85.4 | 85.1 | 85.3 |
| MobileNet-V2 | 74.6 | 64.6 | 74.5 |
| DenseNet | 83.8 | 83.7 | 84.6 |
| InceptionResNet-V2 | 86.9 | 85.8 | 86.7 |
| NASNetMobile | 83.8 | 82.3 | 81.5 |
| EfficientNet-B0 | 95 | 91.9 | 94.23 |
| No. | Hyper-Parameters | Values |
|---|---|---|
| 1 | Reduced LR | |
| 2 | Initial LR | |
| 3 | Optimizer | Adam |
| 4 | Loss function | Categorical cross-entropy |
| 5 | Epoch | 50 |
| 6 | Batch size | 32 |
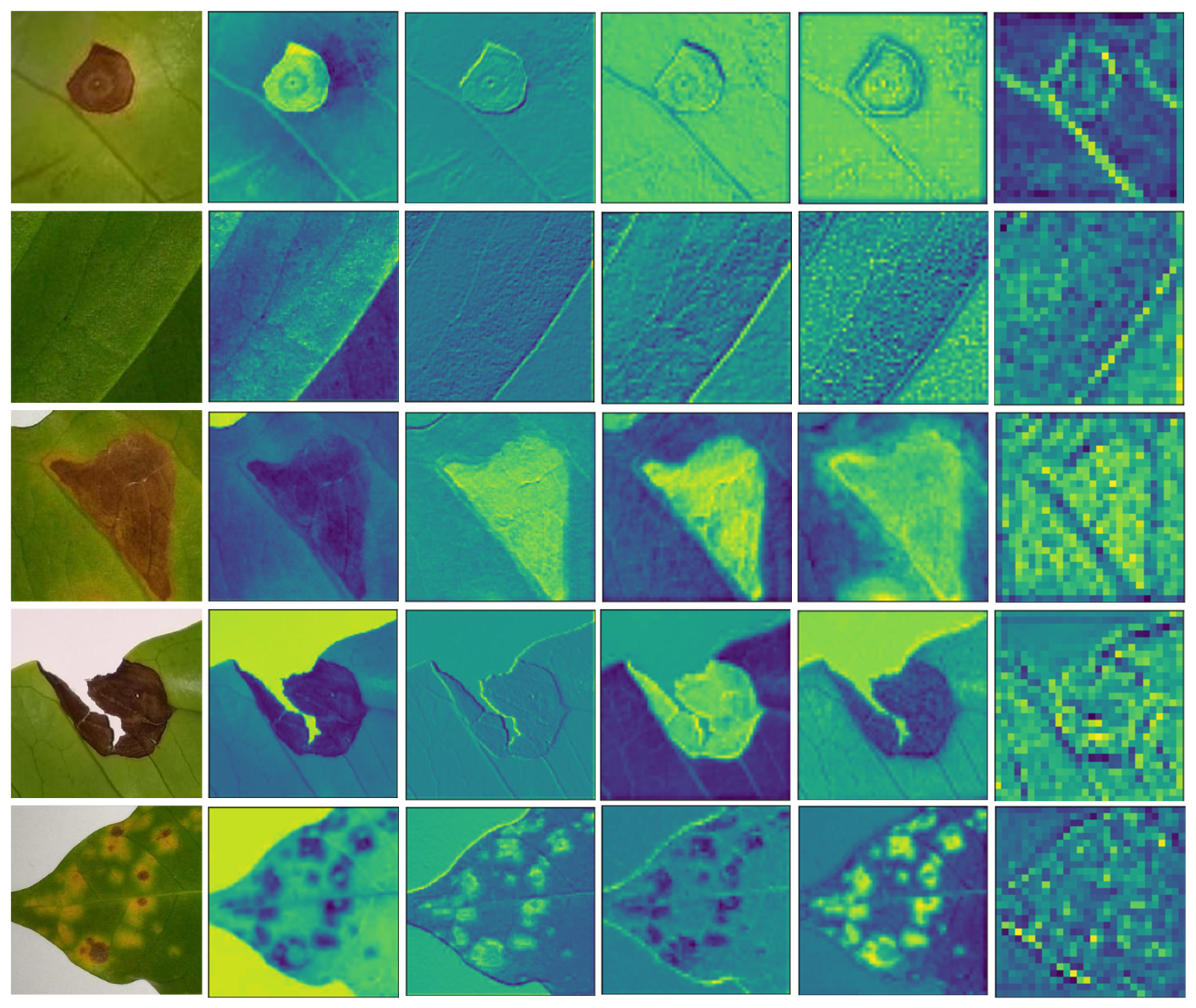
| Type of Leaf | Description |
|---|---|
| Healthy | Green without any spots or damage of any kind. |
| Miner (Peri Leucoptera coffee) | Large, wavy dark patches on the leaf’s upper surface. Rubbing an area or bending a leaf causes the upper epidermis to break, revealing tiny white caterpillars in the new mines. |
| Phoma (Phoma costaricensis) | A leaf that turns brown and dies starting from the tip area. |
| Cercospora (Cercospora coffeicola) | Dry areas that are brown in color with a border in the shape of a bright halo around it. |
| Rust (Hemileia vastatrix) | Features patches that resemble a halo that ranges in color from yellow to brown. |
| No. | Name | Parameter |
|---|---|---|
| 1 | Development tool | Python 3.7 |
| 2 | CPU | Intel Core i5-11400, 2.60 GHz |
| 3 | GPU | Nvidia RTX A5000 GDDR6 24 GB |
| 4 | Memory | 16 GB |
| 5 | Library | TensorFlow |
| 6 | System type | Windows 10, 64 bit |
| Models | PR% | SN% | SP% | F1% | ACC% |
|---|---|---|---|---|---|
| VGG-16 | 94.4 | 94 | 98.6 | 94.1 | 94.2 |
| Inception-V3 | 83.5 | 85.1 | 96.3 | 83.5 | 83.9 |
| ResNet-152 | 94 | 93.2 | 98.5 | 93.3 | 93.8 |
| Xception | 85.5 | 85.3 | 96.6 | 85.2 | 85.4 |
| MobileNet-V2 | 76.8 | 74.1 | 94.5 | 73.5 | 74.6 |
| DenseNet | 84.7 | 83.2 | 96.3 | 83.3 | 83.8 |
| InceptionResNet-V2 | 86.7 | 86 | 97 | 86.1 | 86.9 |
| NASNetMobile | 85.1 | 83.1 | 96.3 | 83.3 | 83.8 |
| EfficientNet-B0 | 95.2 | 94.8 | 98.8 | 94.9 | 95 |
| Ensemble Model (ours) | 95.7 | 95.2 | 98.9 | 95.1 | 97.3 |
| Models | Class 0 | Class 1 | Class 2 | Class 3 | Class 4 | Micro-Average | Macro-Average |
|---|---|---|---|---|---|---|---|
| DenseNet | 0.90 | 0.89 | 0.83 | 0.95 | 0.91 | 0.90 | 0.90 |
| NASNetMobile | 0.91 | 0.89 | 0.83 | 0.96 | 0.90 | 0.90 | 0.90 |
| InceptionResNet-V2 | 0.85 | 0.97 | 0.84 | 0.92 | 0.98 | 0.92 | 0.91 |
| MobileNet-V2 | 0.94 | 0.82 | 0.81 | 0.95 | 0.67 | 0.84 | 0.84 |
| Xception | 0.95 | 0.90 | 0.86 | 0.91 | 0.92 | 0.91 | 0.91 |
| Inception-V3 | 0.86 | 0.74 | 0.83 | 0.93 | 0.88 | 0.85 | 0.85 |
| VGG-16 | 0.97 | 0.97 | 0.95 | 0.98 | 0.95 | 0.96 | 0.96 |
| Resnet-152 | 0.98 | 0.99 | 0.90 | 0.97 | 0.97 | 0.96 | 0.96 |
| Efficientnet-B0 | 0.98 | 0.99 | 0.93 | 0.96 | 0.98 | 0.97 | 0.97 |
| Ensemble (ours) | 0.98 | 1.00 | 0.92 | 0.97 | 0.98 | 0.97 | 0.97 |
| Models | Average Train Time | Average Test Time |
|---|---|---|
| VGG-16 | 8 s | 1 s |
| Inception-V3 | 8 s | 23 ms |
| ResNet-152 | 9 s | 1 |
| Xception | 8 s | 1 s |
| MobileNet-V2 | 8 s | 20 ms |
| DenseNet | 8 s | 43 ms |
| InceptionResNet-V2 | 8 s | 1 s |
| NASNetMobile | 8 s | 34 ms |
| EfficientNet-B0 | 8 s | 24 ms |
| Ensemble model (ours) | 6.3 s | 1 s |
| Models | Parameters (M) |
|---|---|
| VGG-16 | 14 |
| Inception-V3 | 21 |
| ResNet-152 | 58 |
| Xception | 20 |
| MobileNet-V2 | 2 |
| DenseNet | 12 |
| InceptionResNet-V2 | 54 |
| NASNetMobile | 4 |
| EfficientNet-B0 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Novtahaning, D.; Shah, H.A.; Kang, J.-M. Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease. Agriculture 2022, 12, 1909. https://doi.org/10.3390/agriculture12111909
Novtahaning D, Shah HA, Kang J-M. Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease. Agriculture. 2022; 12(11):1909. https://doi.org/10.3390/agriculture12111909
Chicago/Turabian StyleNovtahaning, Damar, Hasnain Ali Shah, and Jae-Mo Kang. 2022. "Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease" Agriculture 12, no. 11: 1909. https://doi.org/10.3390/agriculture12111909
APA StyleNovtahaning, D., Shah, H. A., & Kang, J. -M. (2022). Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease. Agriculture, 12(11), 1909. https://doi.org/10.3390/agriculture12111909