2. Related Works
Some methods present in the literature are used to automatically classify fruits and are used for different classification techniques. Some approaches use machine learning to learn farmers’ experiences, such as using acoustic data to classify fruits, while other approaches analyze the properties of the fruits, to find the differences between the different categories labeled by farmers.
Weangchai Kharamat et al. checked the ripeness of the durian via acoustic data [
5]. The durians were separated into three categories, ripe, mid-ripe, and unripe. Using acoustic is the most common way to classify durians. The sound is made by sweeping rubber-tipped sticks on the durians. The authors collected data from 30 durians. They used a smartphone to record 0.3 s of audio. As for the smartphone settings: the sampling frequency was 16 kHz, with 16-bits mono audio. Finally, they obtained 300 data points for each category.
After collecting the data, the authors extracted the features by using Mel frequency cepstral coefficients (MFCCs) [
6]. To get Mel frequency cepstral coefficients, there are four steps. First, use the Fourier transform to make the sound change to a frequency domain. Second, apply the triangular overlapping window and mapping to the Mel scale. Third, take the logs of power at each Mel frequency. Finally, transform the Mel log powers by a discrete cosine transform. The results of the Mel frequency cepstral coefficients are used as inputs of the convolutional neural network. The authors also applied a 25% dropout on layers two and four and a 50% dropout on the fully connected layer. The model was optimized by the Adam optimization algorithm. The model reached the highest testing accuracy, 0.89, with 150 epochs.
Arturo Baltazar et al. [
7] classified tomatoes by the concept of data fusion. Data fusion [
8] involves combining multiple data collected by different sensors. The authors collected three features of tomatoes—color, acoustic, and firmness. For color, they used a colorimeter; for acoustic, they designed a machine to hit tomatoes and record sound data. The firmness can be acquired by the nondestructive method if it is calculated by 2.1.
Sc in the stiffness coefficient,
f is the dominant frequency obtained from acoustic data, and
m is the bulk mass of the fruit. The color and firmness data would be collected in specific intervals. Because the ranges of data are different, the authors used min–max normalization to limit the data in the range of 0 to 1 [
9]. To classify tomatoes, the authors used a Bayesian classifier [
10]. The classification error was reduced when the number of features rose.
Puneet Mishra et al. used near-infrared to analyze content in the pear [
11]. Soluble solid content (SSC) and moisture content (MC) play an important role in fruit maturity and quality [
12]. The authors used near-infrared to detect the content, which is a standard technology used in this field. The authors used the parameters of near-infrared in the spectral range of 310–1135 nm with a spectral resolution of 8–13 nm. They scanned at the bellies of the pears, calculating the average of six scans. To predict soluble solid content and moisture content, the authors used two common chemometric algorithms. One was interval partial least squares regression (iPLS2R) [
13], which is used for predicting in a subset of continuous wavelengths, and the other was covariate selection (CovSel), which can select discrete wavelengths related to the content [
14].
The authors also used model updating, which uses a few data from the new batch to improve the model. In the experiment, the authors selected 5, 10, and 20 samples by the Kennard–Stone (KS) sample partition technique from Batch 2 to recalibrate the model built from Batch 1. The Q2 of iPLS2R in soluble solid content improved from 0.71 to 0.76 with 5 and 10 samples; in moisture content, it improved from 0.84 to 0.87 with 20 samples. The Q2 of CovSel in soluble solid content improved from 0.73 to 0.77 with any number of sample selections; in moisture content, it improved from 0.84 to 0.85 with 5 and 20 samples.
R.P. Haff et al. used an X-ray to detect translucency in pineapples [
15]. Translucency is a physiological disorder of pineapple. By using X-rays, the authors can get the internal image of a pineapple from the side. The pineapples were divided into five levels after cutting and examining the section. For the first level, there was no translucency in the pineapple. For the second level, there was less than 25% translucency. For the third level, there was 25–50% translucency. For the fourth level, there was 50–75% translucency. For the fifth level, there was more than 75% translucency. The first and second levels were considered good pineapples, and the others as bad. The X-ray pictures were used as the input of the logistic regression [
16]. The output of the logistic regression was 1 and 0, which means the pineapples were good or bad. The
R2 of the model was 0.96.
Siwalak Pathaveer et al. [
17] used multivariate data collected by nondestructive methods to analyze pineapple maturity and compared the results (i.e., with and without destructive methods). The non-destructive data were the specific gravity and acoustic impulses. The destructive data were flesh firmness (FF), soluble solid content (SSC), and titratable acidity (TA). The pineapples were separated into three classes—class A, Class B, and class C. Class A represented greater than 50% translucent yellow. Class B represented 25–50% translucent yellow. Class C represented less than 25% translucent yellow.
In the latest research from the Taiwan Agriculture Research Institute Council of Agriculture, Executive Yuan [
18], the authors designed a product [
19] that classified pineapples by resistance. They found that the difference between the drum sound pineapple and the meat sound pineapple might not be caused by the percentage of water, but by the distribution of water. As a result, using resistance to quantify the pineapple would be a better way than using capacitance. However, their product needs to be adjusted before being implemented in different batches.
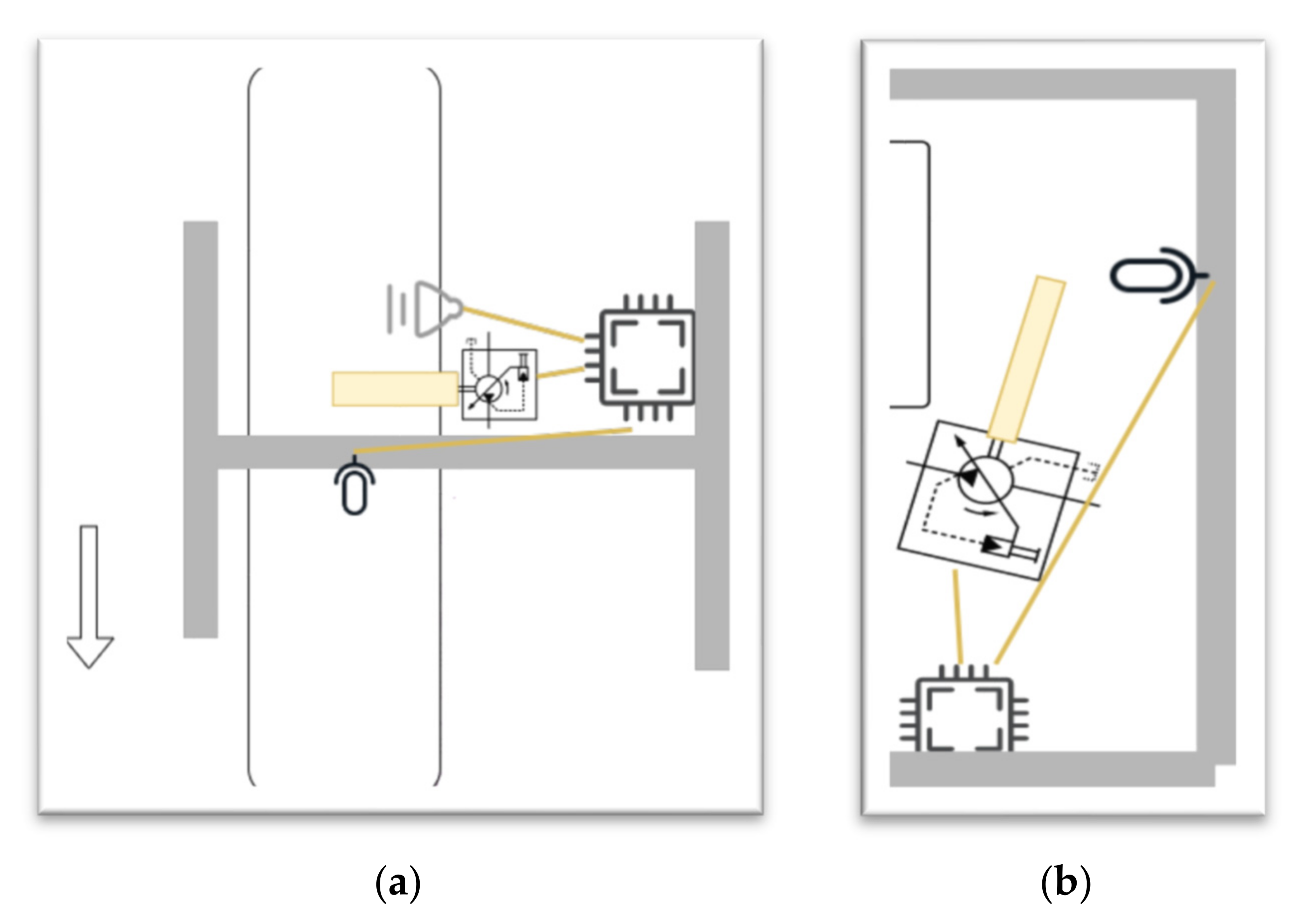
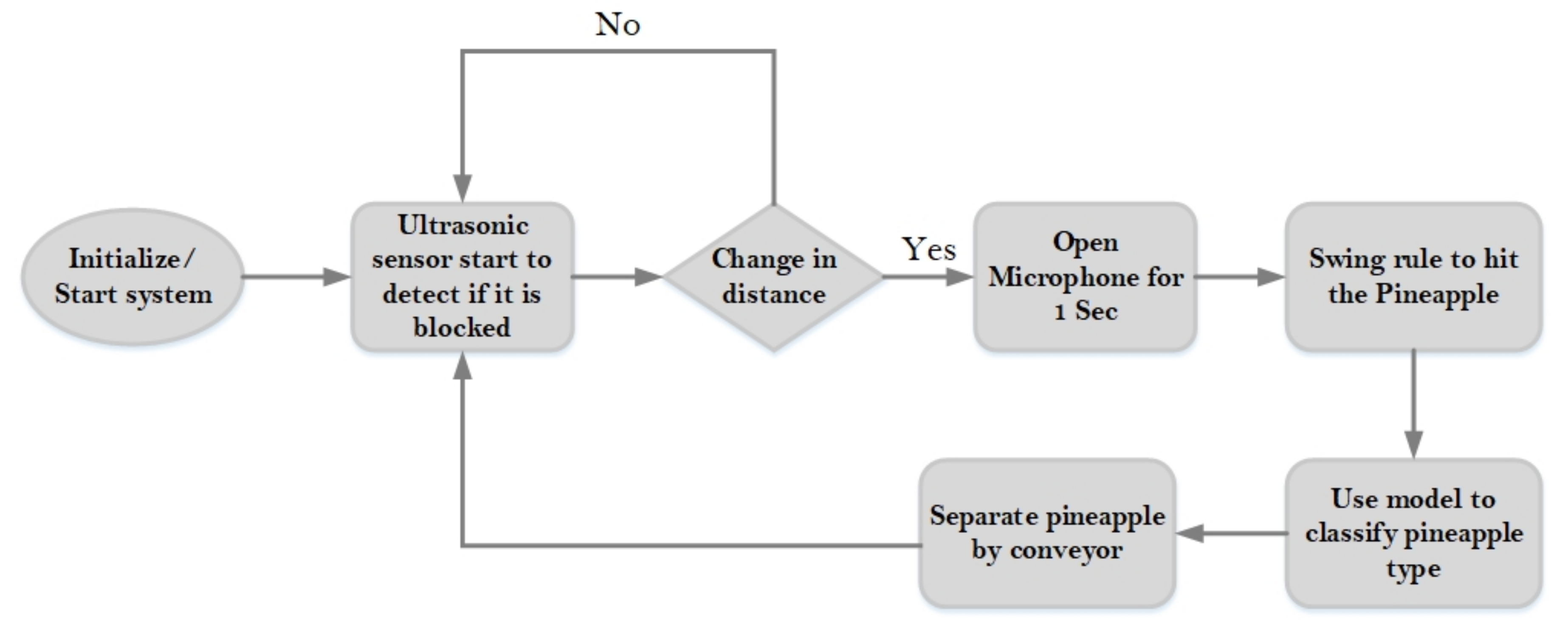
The existing models in the literature can be improved in different ways. First, when using technology to analyze fruits, it should make the analysis accurate and help farmers reduce their work. Most previous works could not work automatically; some used high price devices. In this work, we designed an automatic classification machine that could distinguish between pineapple types and separate pineapples automatically, based on acoustic data. We also used our model to test different batches of pineapples collected in different conditions.
5. Conclusions
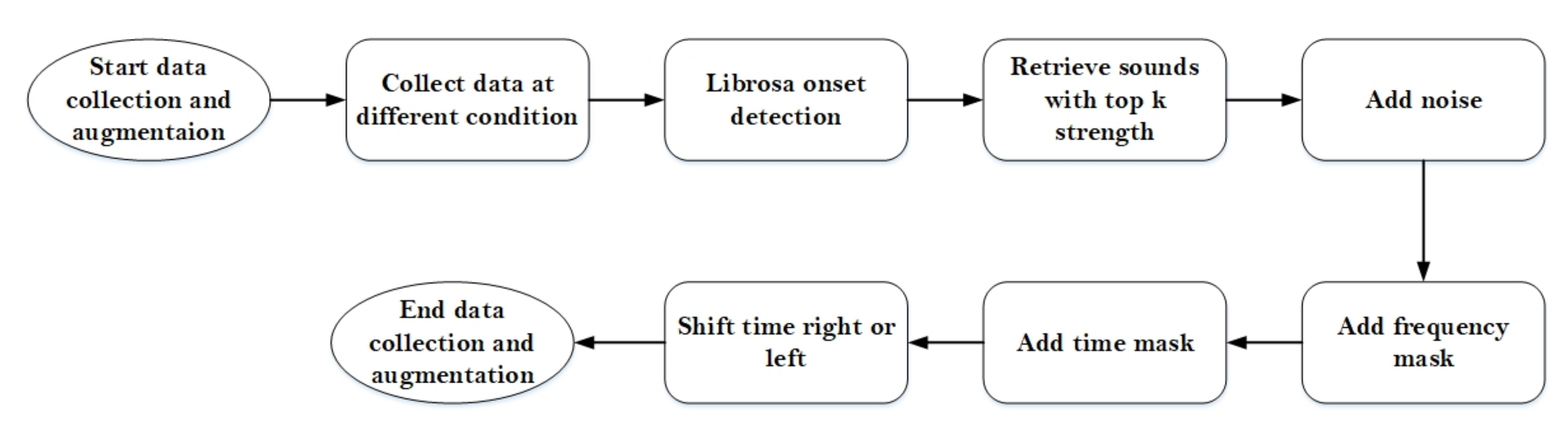
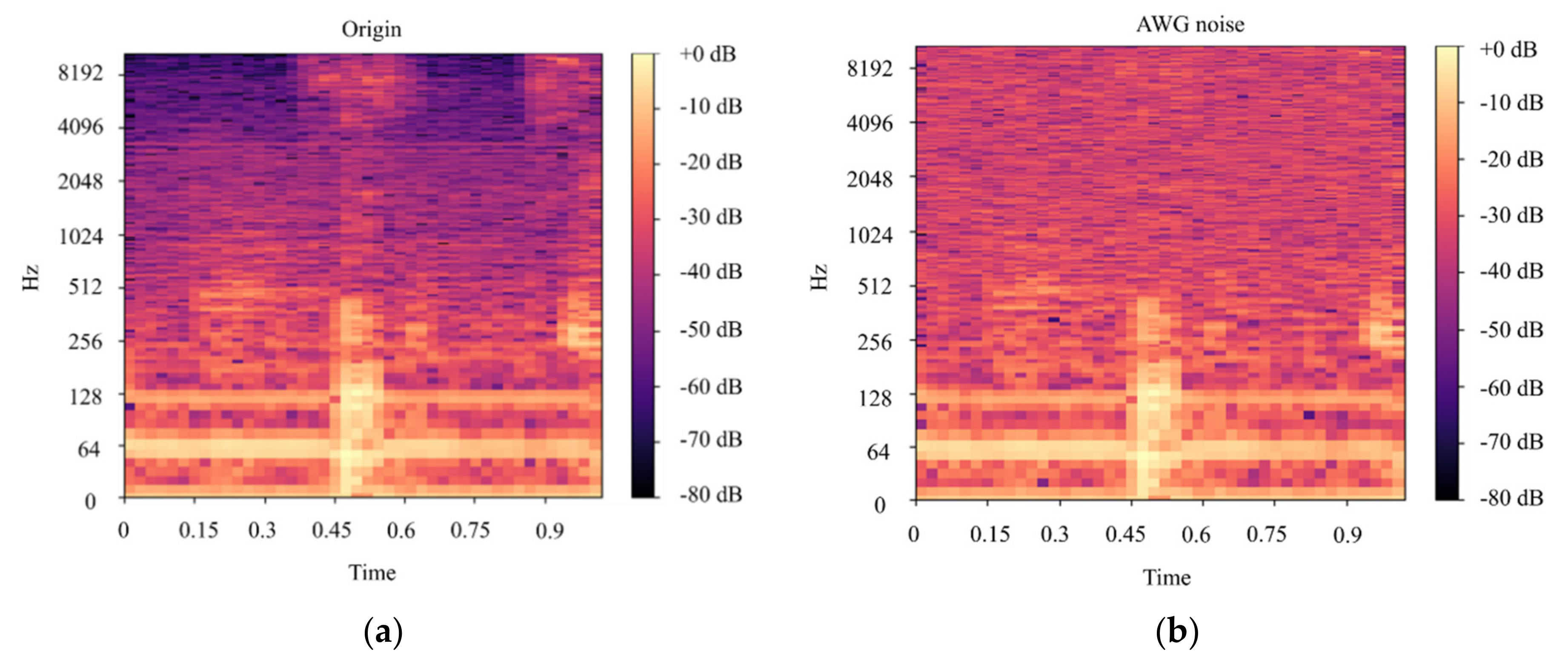
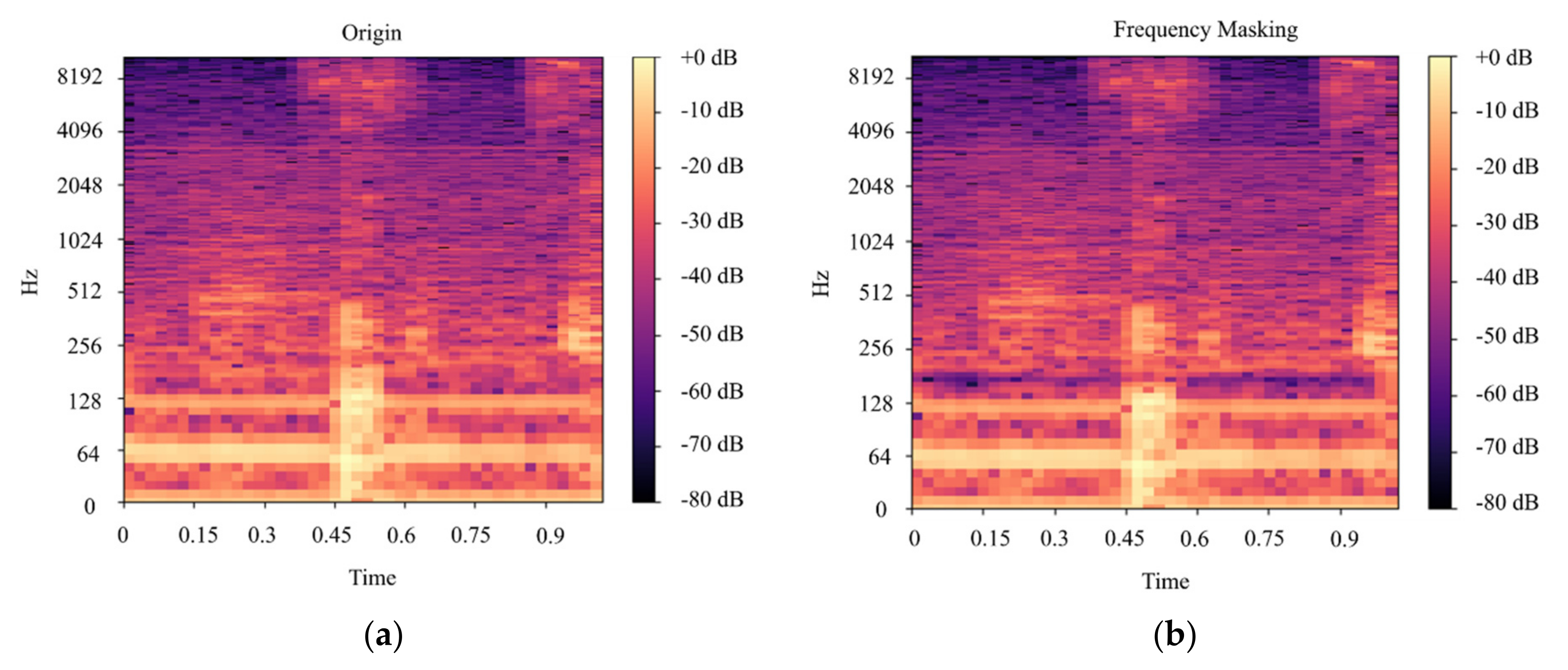
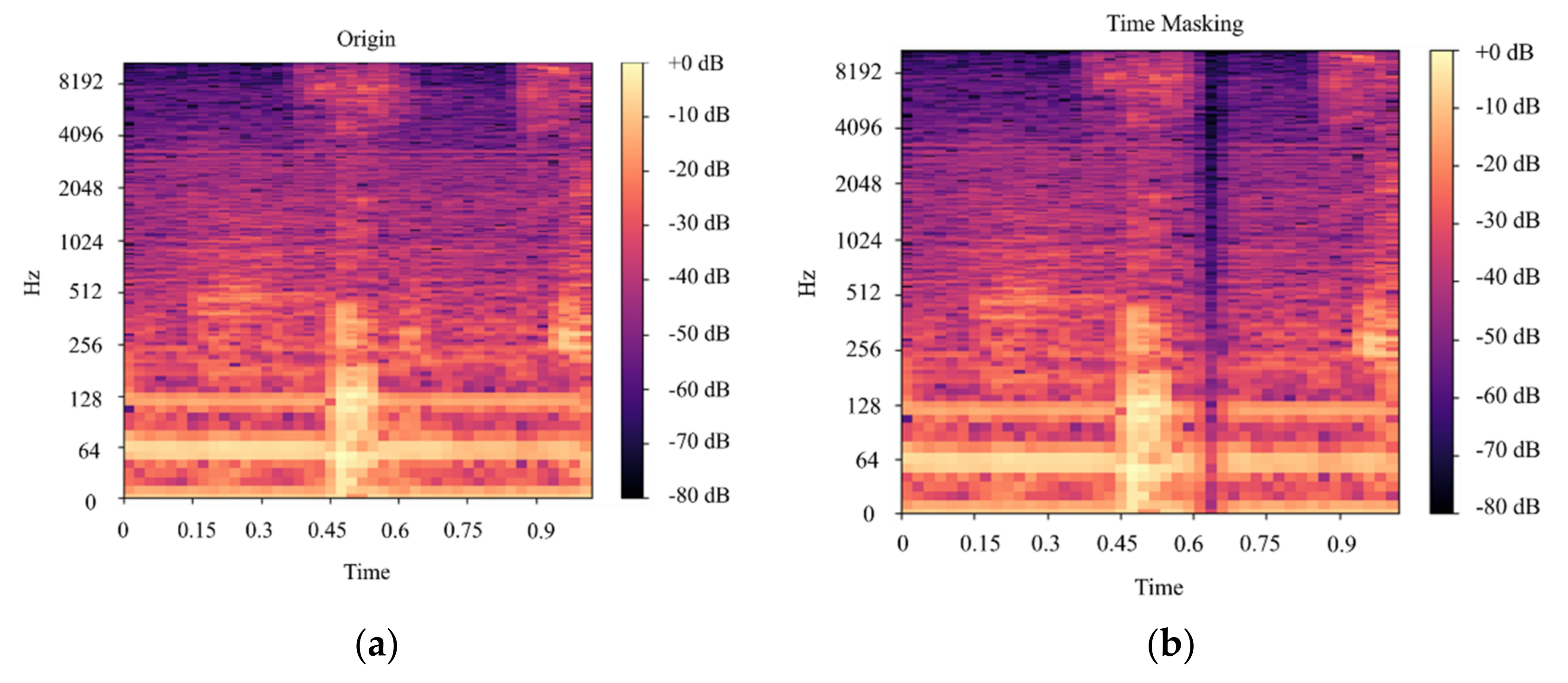
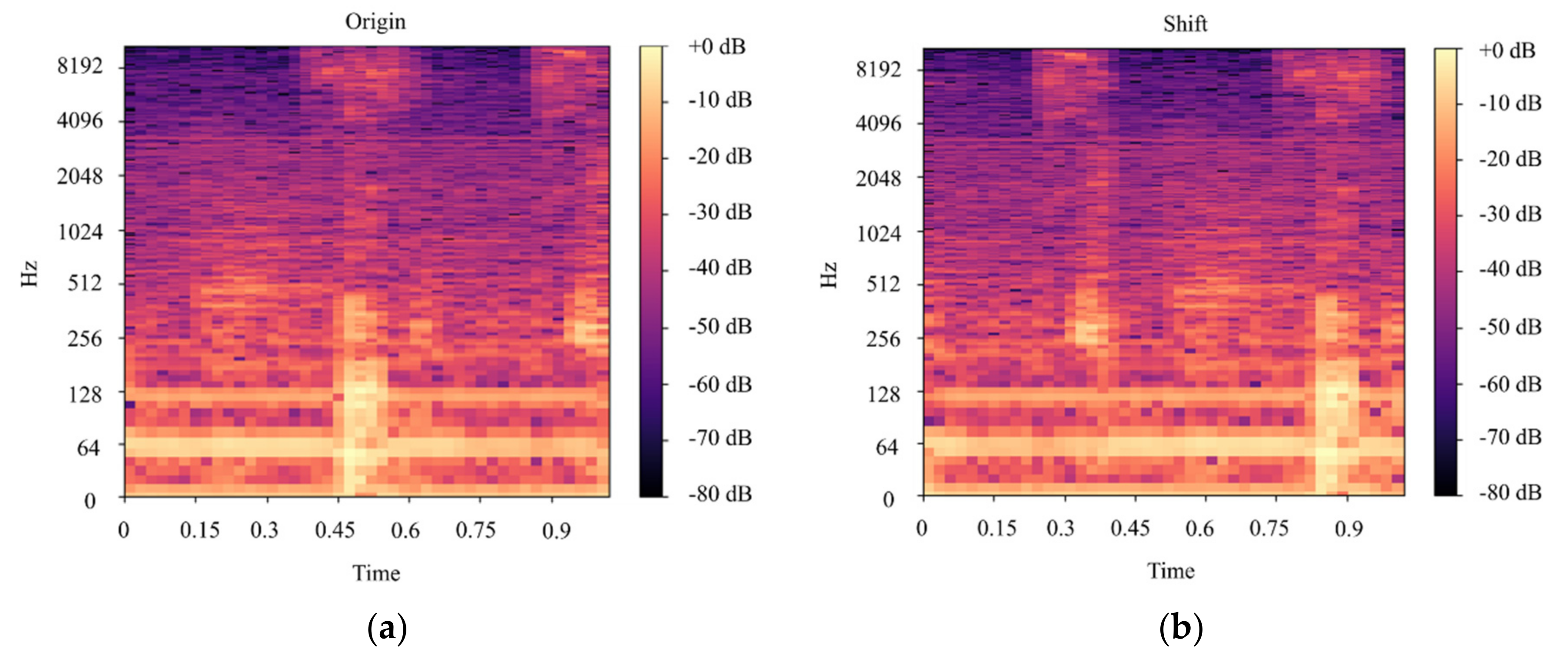
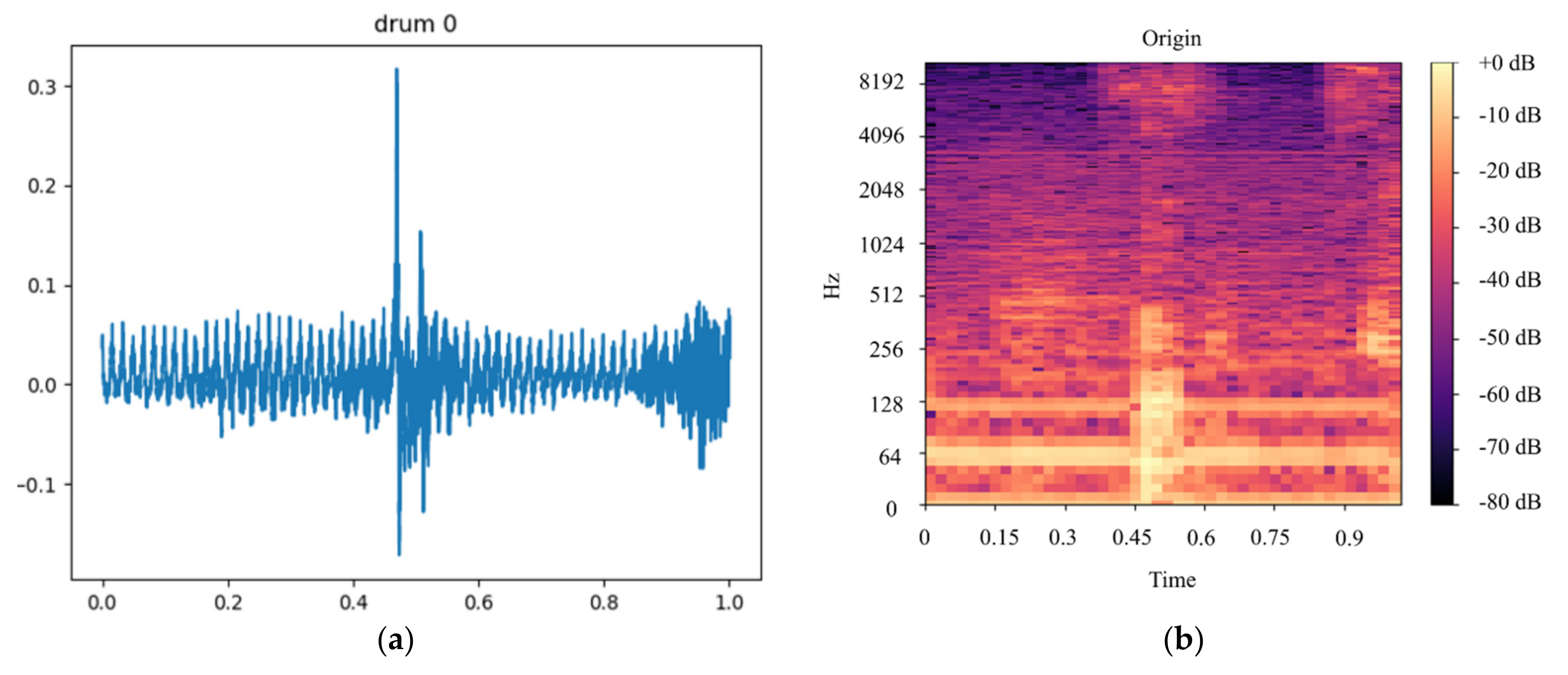
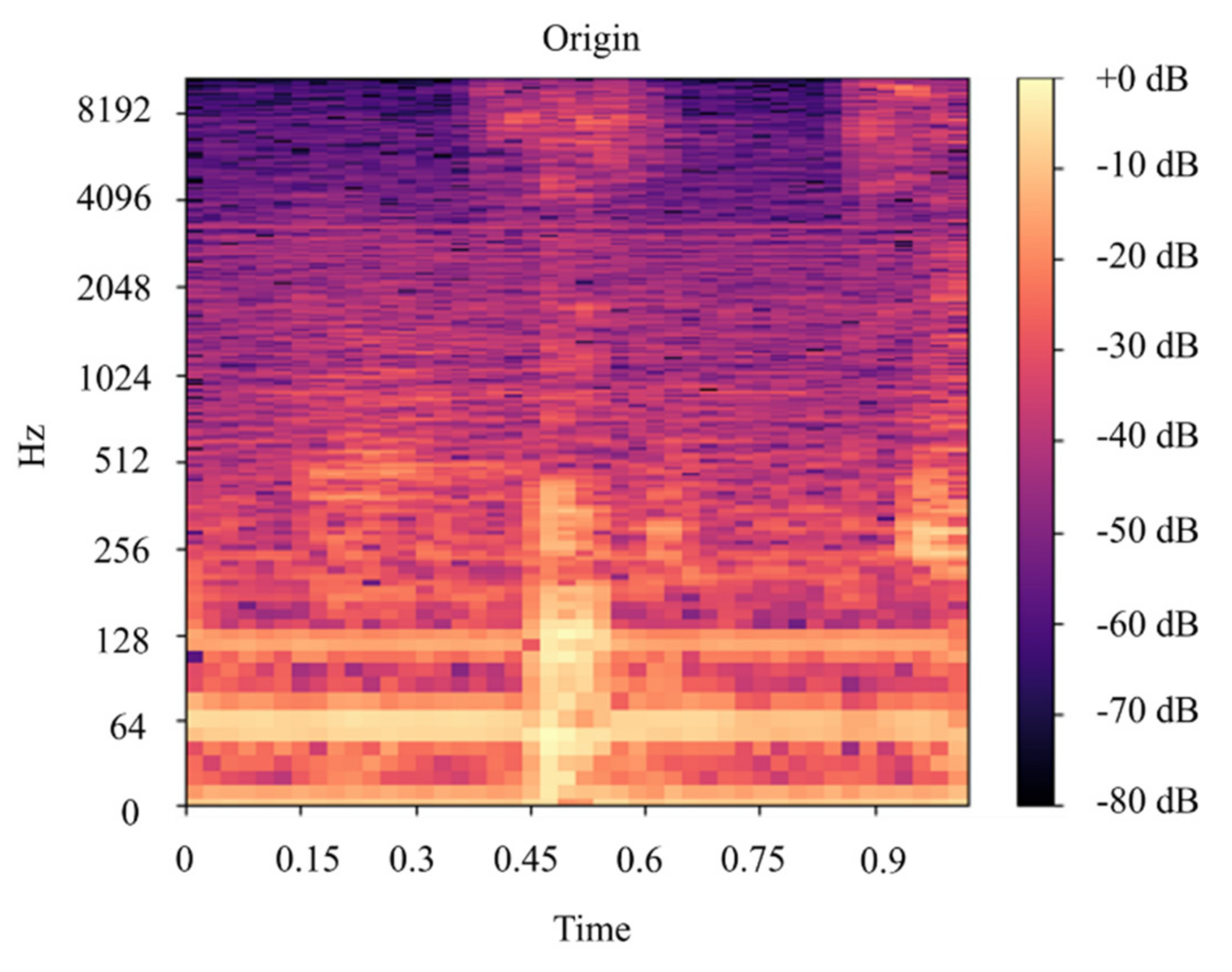
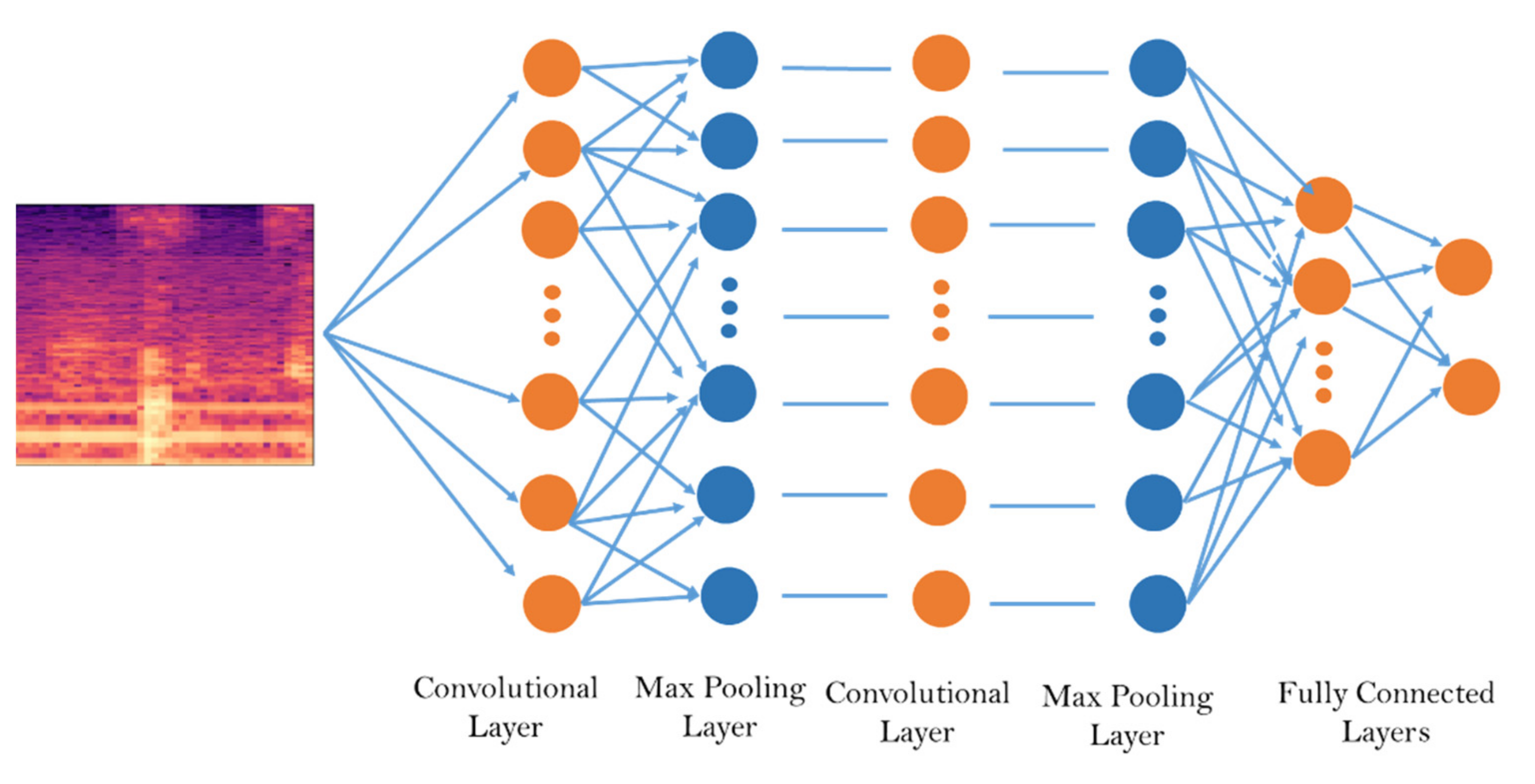
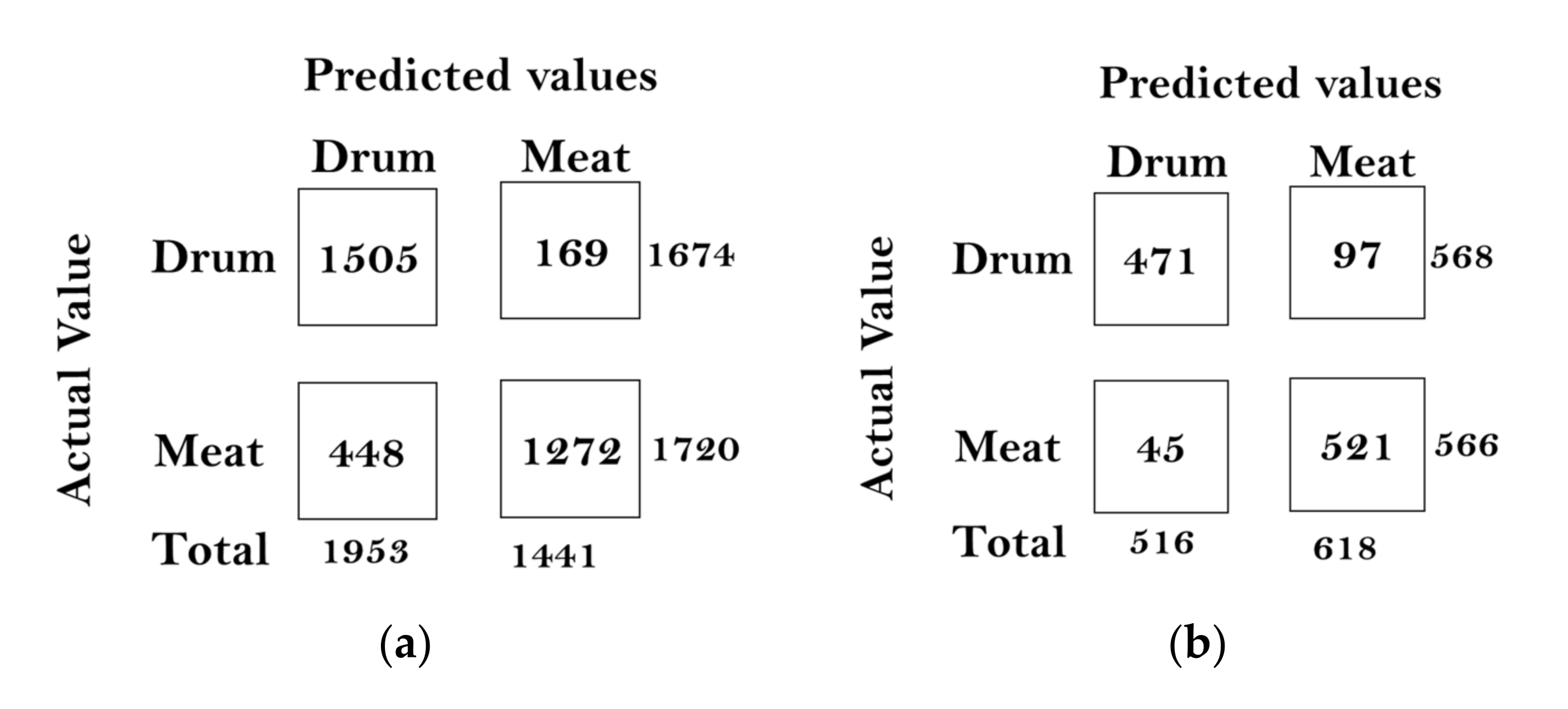
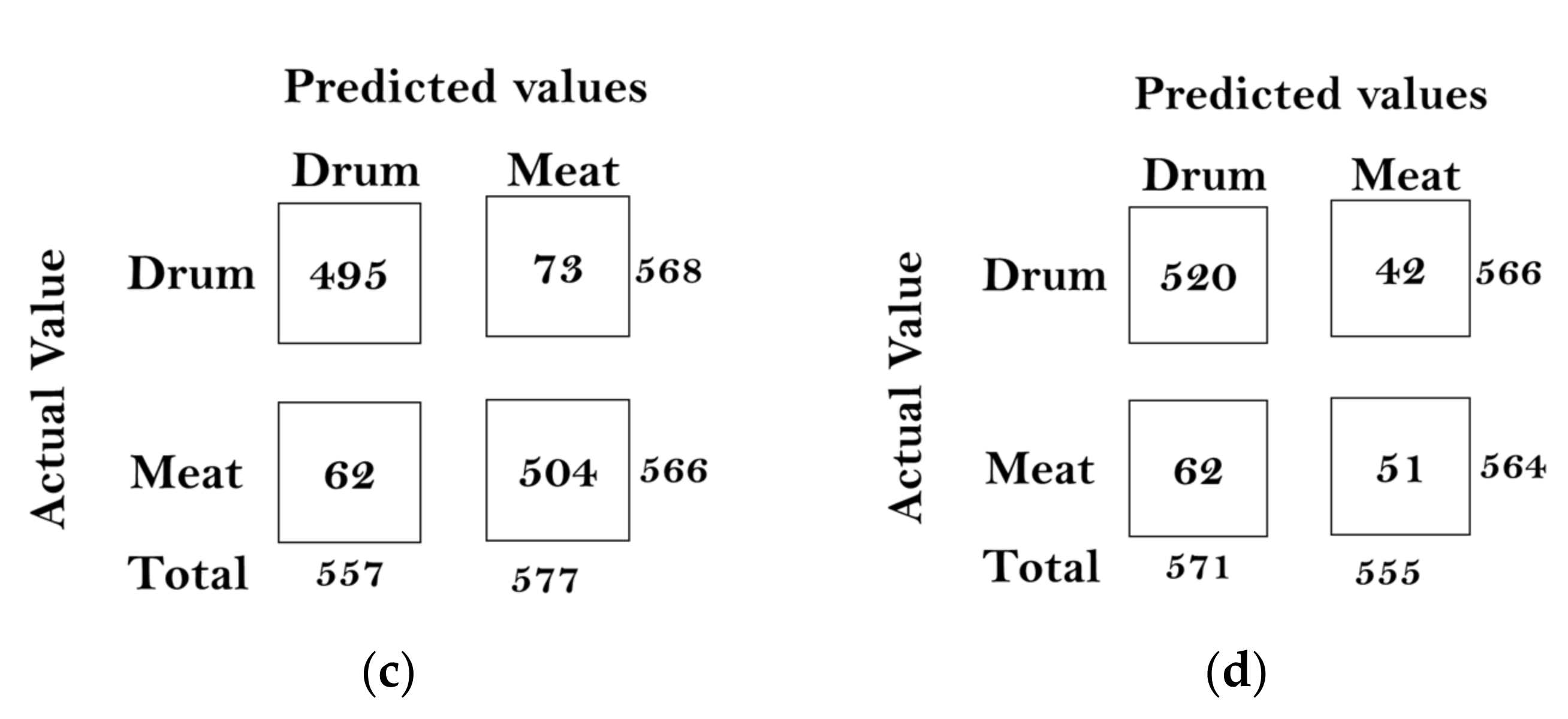
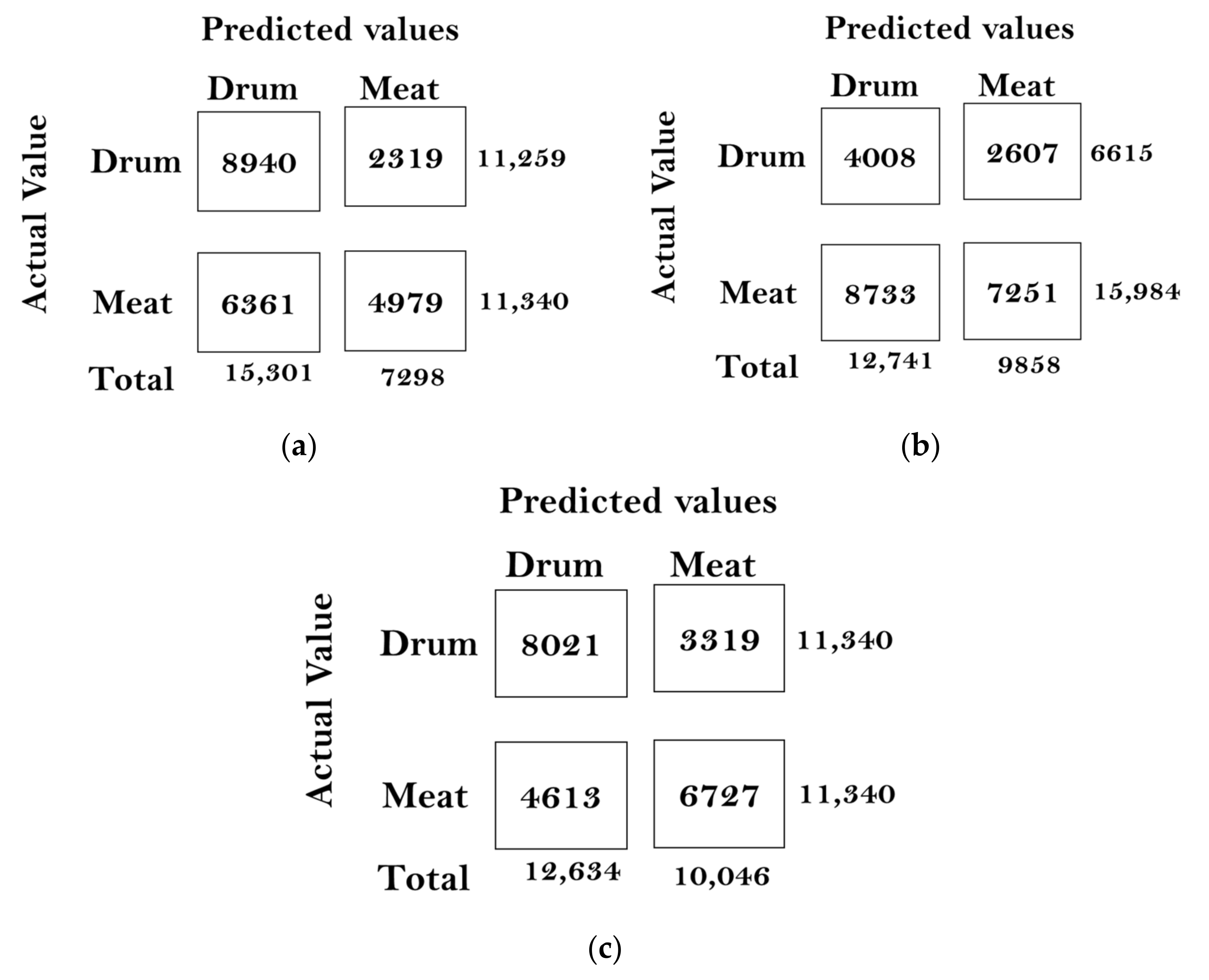
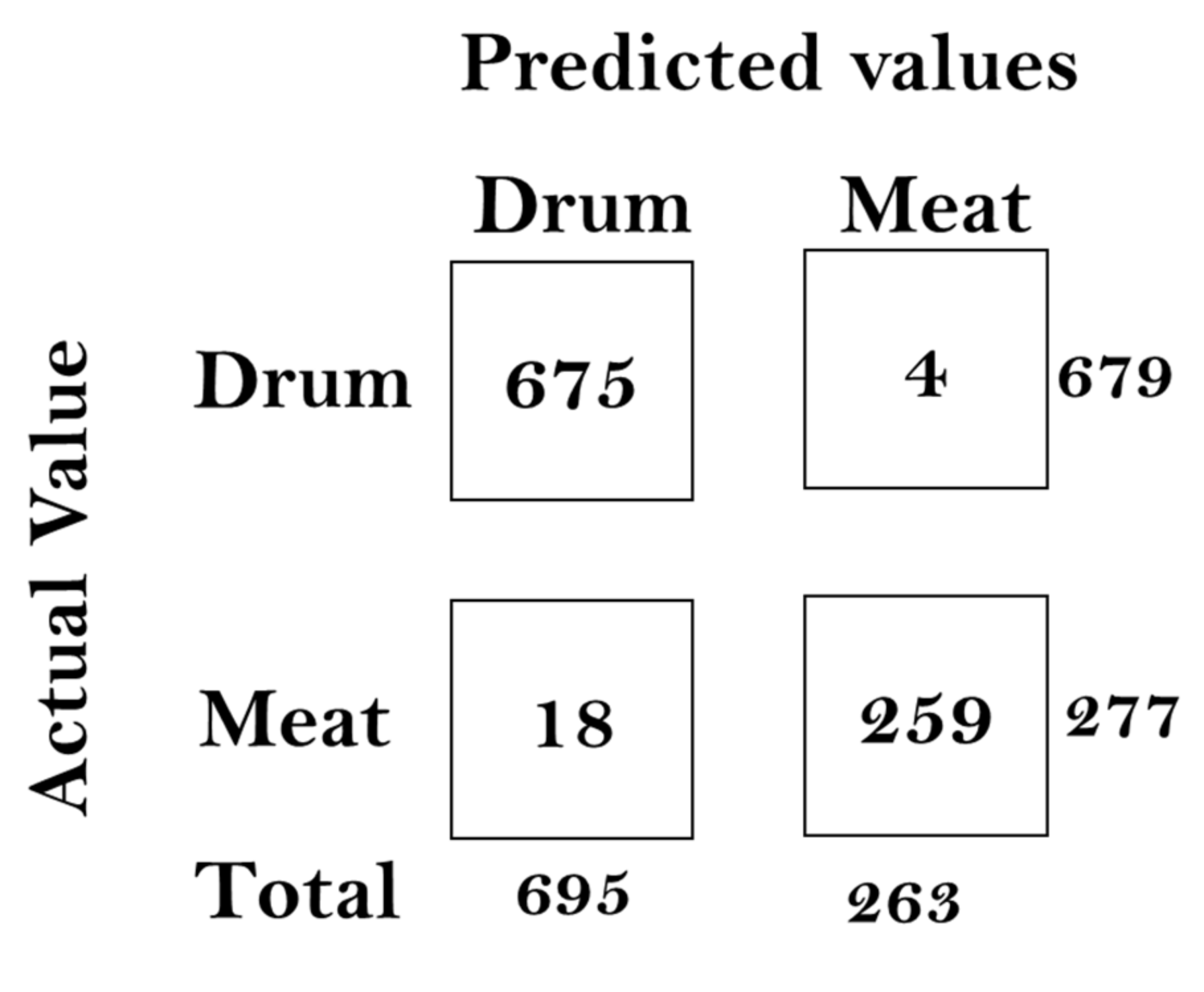
In this paper, we built a model that could classify pineapples, and we built an automatic machine to conduct the whole process. To classify pineapples, we proposed a method related to acoustic spectrograms, which use acoustic data to generate spectrograms. We used our machine to hit pineapples and recorded the hitting sounds to generate spectrograms from the acoustic data. The hitting sounds were transformed from amplitude/time domain to frequency/time domain by the short Fourier transform to create the spectrograms. The spectrograms were used as input to the CNN. Seven different data groups with different conditions and factors were collected from different pineapple batches in farm and factory environments. The highest accuracy of the CNN reached around 0.97 for data Group V when we divided one data group into a training and testing data set; however, when we used the trained from one group and tested the model by another set, the accuracy dropped to 0.54. The accuracy of the developed CNN model is 0.91 for data Group I, 0.88 for data Group II, 0.83 for data group III, 0.87 for data group IV, 0.97 for data Group V, and 0.87 for combined data Groups VI and VII. From the model accuracy and confusion matrices of the developed model, we found that the batches are essential factors for pineapple classification. The sounds of hitting pineapples would change if the data were collected on different days. The developed model reduces the time and cost of the pineapple classification process and increases the accuracy of classification by automating the process of differentiating the drum and meat sound pineapples. Thus, it helps farmers to classify pineapples efficiently. The developed hitting machine, along with the artificial intelligence model, would be significant for farmers around the world, regarding the classification of pineapples
Our current model works on one batch of pineapples and produces less accuracy on another batch. To overcome this, we need to collect more data to make the model more generalized. Our classification machine is still a prototype, which cannot be used as such in farms as it can be damaged easily, so we need to make it more stable. Moreover, according to the latest research by the Taiwan Agriculture Research Institute Council of Agriculture, Executive Yuan [
18], the distribution of water might be another reason making the drum sound pineapple and the meat sound pineapple different. We could also train our quantification model with resistance data.



 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}