1. Introduction
Field management zones in precision agriculture (PA) are defined as “the sub-regions within the same piece of land showing similar yield influencing factors within which different crop management practices are carried out at the right time and place to optimize crop productivity and minimize adverse environmental impact” [
1]. Well delineated homogenous areas should have the same yield trend across years and different cultivated crops [
2]. These management zones are not only used for site-specific, real-time crop management, but also for soil sampling to characterize the soil nutrient levels for variable rate fertilization [
3]. Under uniform crop management practices, fertilizer use efficiency is quite low [
4,
5]. Therefore, efficient fertilizer management practices as those under PA are expected to enhance the efficiency of nutrients supplied with fertilizers, as a premise for improved crop yield. Specifically, crop input rates, i.e., fertilizers, should be applied based on the crop requirements, estimated through the information of within-field spatial variability, such as nutrient status or productivity potential, within a specific region of the field [
6,
7]. It is recognized that there is often high spatial variability within the same field, due to nutrients or other factors or interaction among them, which influence the final crop yield. The high or low yield factors could be soil, environmental, topographical, anthropogenic, or biological entities [
8]. Specifically, the interaction of various factors makes it more complex to understand the real story behind them. Therefore, efficient methods should be used to measure the within-field spatial variability in an appropriate way for delineating site-specific zones [
9].
Geostatistical analysis has been extensively used to estimate the spatial variability of crop yields, soil, and remote sensing data using different kriging methods with small to larger size grids [
10]. Generally, geostatistics is used to estimate the spatial autocorrelation within a dataset in terms of variogram parameters and spatial mapping. More to this, spatial variability within a dataset is estimated through best-fit modelling [
11].
Various methods have been developed to measure the within-field spatial variability for delineating management zones. Most of them rely on single types of data for analysis of multiple year yield mapping [
12,
13,
14], various soil properties [
15,
16,
17], remotely sensed data [
12,
18,
19,
20,
21], topographic factors [
22], and soil apparent electrical conductivity (ECa) [
23,
24]. All these methods, directly or indirectly, are related to crop productivity [
25]. As PA continuously evaluates the different methods for setting spatial management zones, and no generally accepted method exists yet, cluster analysis may be a basis for unresolved questions in delineating management zones [
26]. This statistical cluster analysis uses various types of data sources to develop within-field areas at similar characteristics (soil and crop-related parameters or environmental impact) for the quantification of spatial variability trends and to optimize crop productivity through site-specific crop management practices [
27]. Franzen and Kitchen (1999) [
28] used different typologies of data such as topography, satellite imagery, soil electrical conductivity, crop yields, and soil properties, to develop potential zones for variable nitrogen rates. However, delineating management zones based on crop yields, soil, and satellite data have all been considered as logical methods in PA [
2,
29,
30].
Based on this, in a field subjected to arable cropping with a georeferenced record of crop yield data for a number of years, the objectives of this study were: (1) to characterize the spatial variability of crop yields, soil properties, and remotely sensed NDVI data influencing crop productivity through geostatistical analysis; (2) to delineate feasible crop management zones with a fuzzy clustering method, using previous crop yields, soil properties, and NDVI data; (3) to interpret the obtained management zones for site-specific management in view of future crop management practices.
4. Discussion
The seven annual crops surveyed in this work across the last two decades represent a good example of the georeferenced yield data that are increasingly being archived, as PA practices are extending to relatively small farmers. It does not often occur that the reliability and potential uses of such data are sufficiently understood by potential beneficiaries, who remain uncertain how to manage them. Therefore, experiments such as that carried out in this work, serve as good examples of the approach that may be followed in dealing with yield data, soil and vegetational properties, and the resulting outcomes.
The seven crops, intrinsically, do not have a high degree of similarity: three years of winter wheat; two years of maize for biomass production, one of which was cultivated as second crop in a season after a winter grass crop; the remaining two years with a summer oilseed (sunflower) and cereal (grain sorghum). They represent the variability that is normally met in mixed-cropping systems at intermediate latitudes, such as in the case of the investigated field. The missing years in the series are due to lack of equipment for georeferenced yield mapping, as in the case of the 2011–2017 gap, when a biogas plant built in the proximity commenced to be fed with biomass grown in this field, and a maize cutter-chopper provided with yield mapping was available only in 2018. However, such gaps may occur also in other cases; thus, the procedure we followed to gather the available years of data and use them all as a dataset, buffered by different ambient conditions and crop types, may be of general interest.
The mixed-cropping systems are seldom surveyed in the literature addressing the use of multiple-year yield data in spatial and temporal variability assessment, despite the fact that mixed-cropping systems are more common than mono-cropping systems, and they are supported by funding schemes in the European Union and elsewhere in the world. More often, multiple-year yield data of a specific crop are used in spatial and temporal variability assessment [
4,
40,
41,
42]. Alternatively, yield data from cropping systems with the same crop type as spring grain crops are also used [
43]. When compared to these, the mixed-cropping systems involving different crop types in terms of harvested plant portions (grain vs. biomass/forage), environmental requirements (autumn- vs. spring-sown crops), or some other feature, represent a more challenging case. A recent work addressing such a case [
44] envisaged the establishment of four classes of yield level and stability combined, using data from grain crops and pastures cultivated on the same fields in different years. The production stability index originating from this approach could discriminate field areas suited for different management, indicating, as in our case, the feasibility of mixed-cropping data fusion for interpreting field variability.
The seven crops staged a yield variation which was lower than observed in a previous study of ours’ [
14]: average SD, which in standardized data (means = 100) corresponds to the coefficient of variation, was 11.4% across the seven years (
Table 4), whereas it was 34% across five years in the cited work. This points out the strong diversity that may be observed between fields of similar size (~10 ha), shape, and topography (flat surface with underground pipe drainage) in the same area as the Po River floodplain in Northern Italy. This, in turn, was reflected in only two clusters as the optimum number in this work (
Table 3), based on the principle of minimizing data dispersion. Therefore, no more than two different management zones would be needed to account for the existing variability, and this figure, based on seven-year average yield, was assumed as the reference number also for soil traits and remote NDVI data, in view of subsequent comparisons.
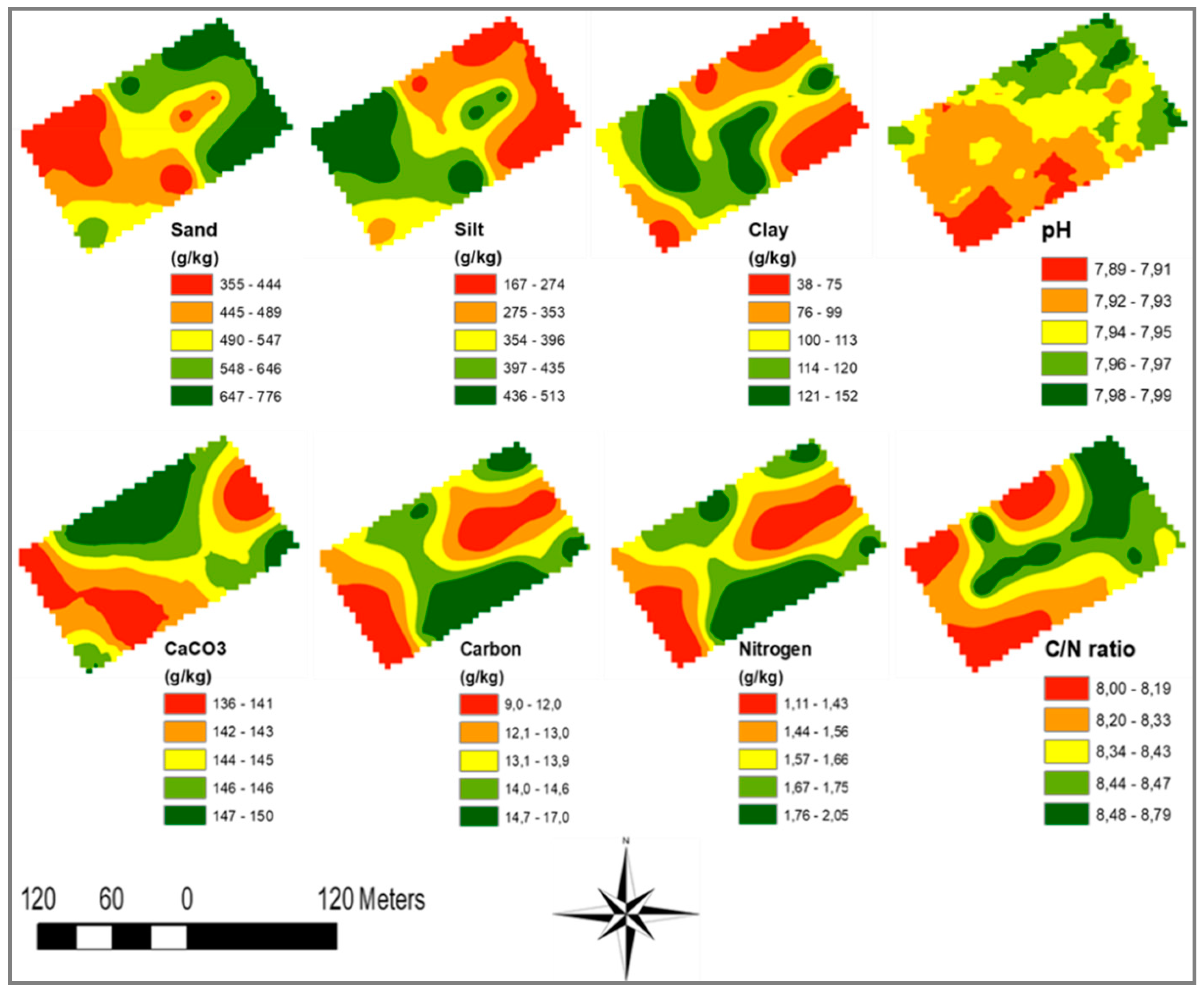
Despite the above-discussed modest variation, all the yield, soil, and NDVI datasets were fitted with good accuracy by semi-variogram models of various types: the stable model prevailed in yield fitting (
Table 5 and
Figure S1), while the exponential model prevailed in soil traits (
Table 7 and
Figure S5) and NDVI data (
Table 11 and
Figure S2). More to this, the fitted semi-variograms featured a generally strong spatial dependence, i.e., a nugget value that was modest, if not negligible, with respect to the total sill (
Table 5,
Table 7 and
Table 11). This is a good premise for undertaking precision crop management, as the differences in, say, fertilizer dose that are associated with spatial distance, can be more reliably trusted [
35]. For the same reason, a long range would be desirable, as it ensures that the control distance used for a site-specific operation, e.g., fertilizer spreading, falls in an area of relative uniformity, and the switch between different doses is sufficiently rapid to account for spatial variation in fertilizer needs. Based on the principle that the upper limit of cell size, i.e., the resolution, for a site-specific intervention should not exceed the length of half the range, to avoid excess heterogeneity within the cell [
45,
46], it results that the soil traits and NDVI data in our study have ranges long enough, in general, for a dose variation to be successfully implemented in real-time (
Table 7 and
Table 11). It is assumed that a vast majority of the ranges for soil and crop properties falls between 20 and 110 m [
47]; therefore, comparing the range resulting from the semi-variogram analysis with the distance required by a specific implement to switch doses can be suggested as a preliminary check in view of variable crop input application.
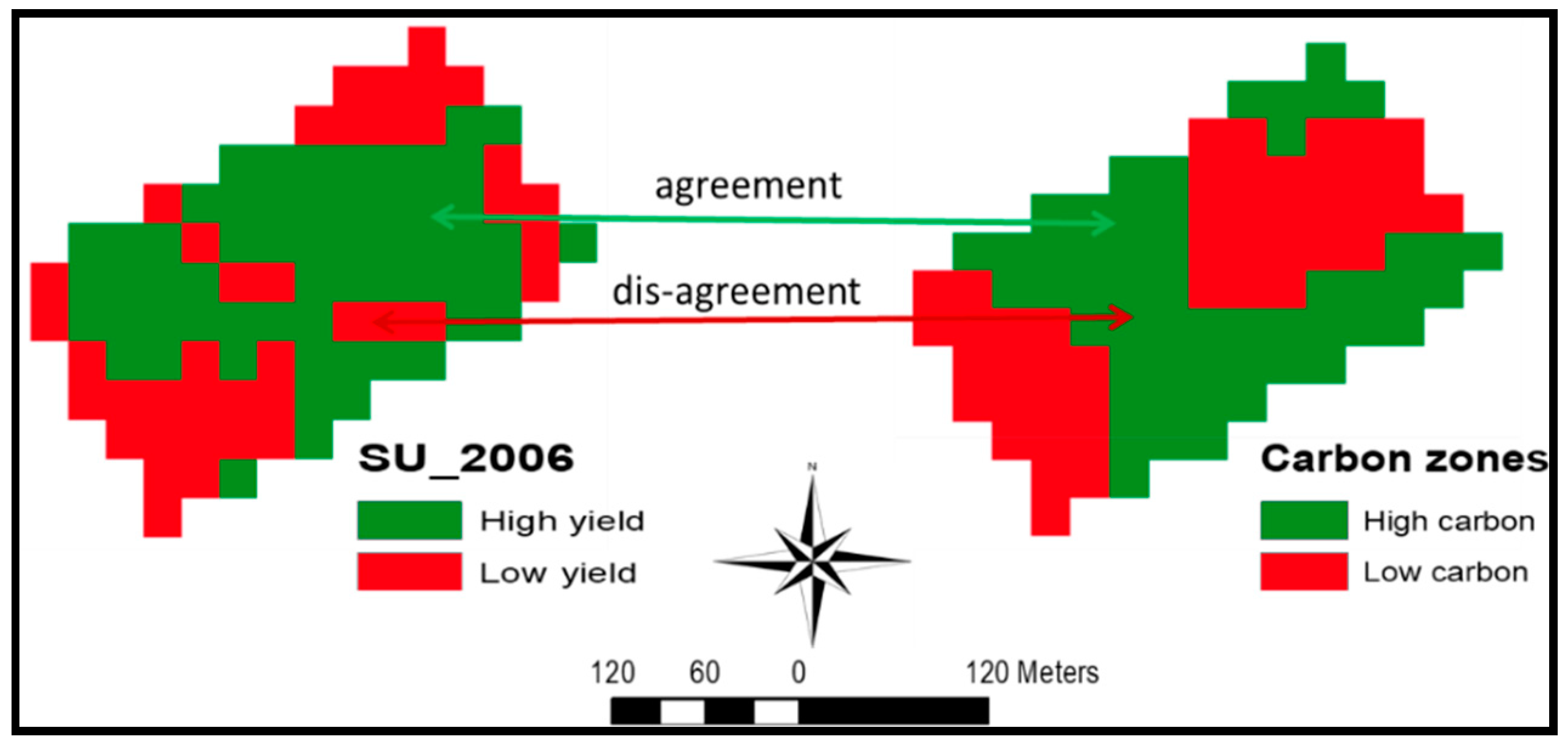
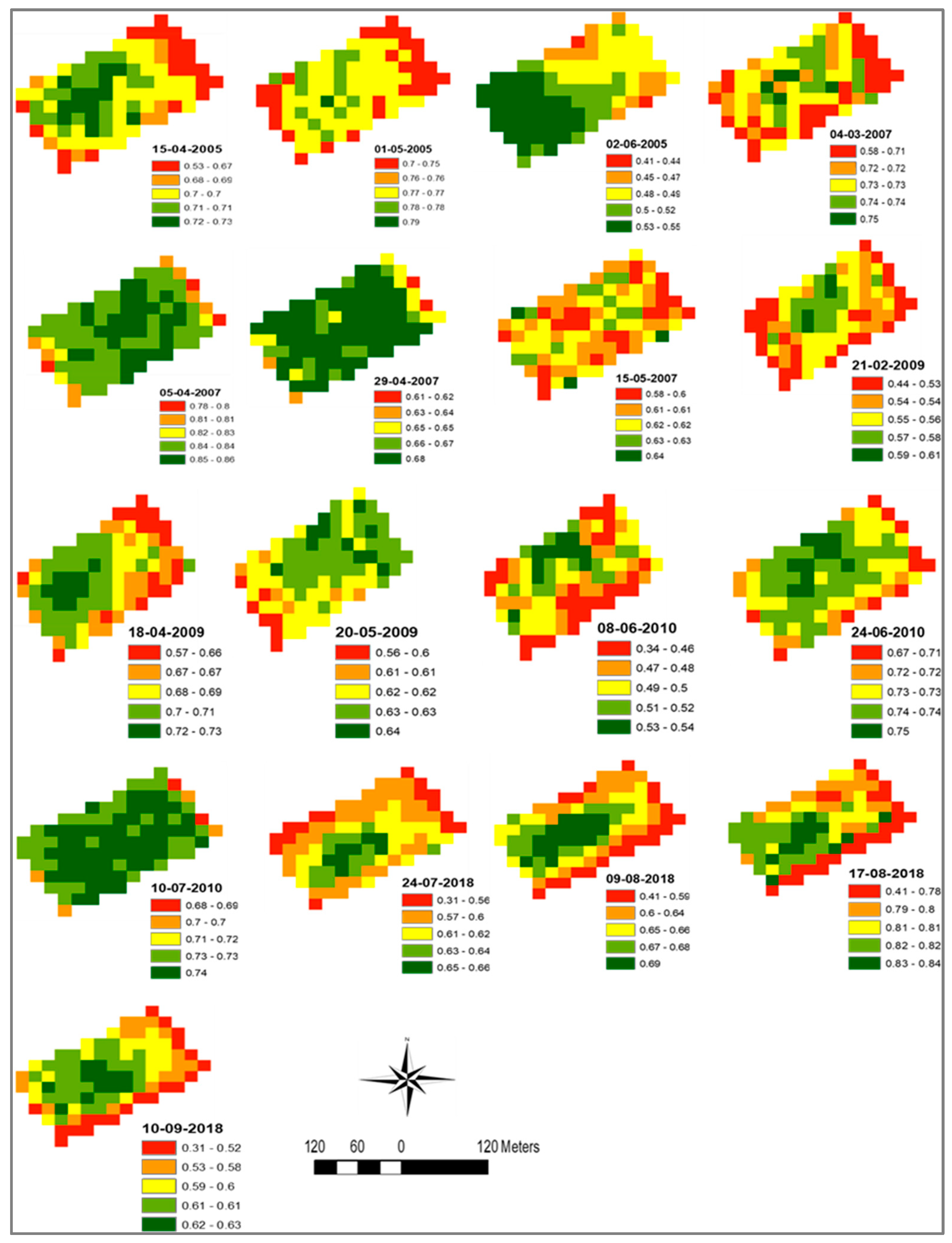
In this respect, it is evidenced that the two-zone maps of soil properties, NDVI values, and multiple yields (
Figure 6 and
Figure 7) have pixels of sufficient size (30 m) for dose variations to be implemented when passing from the low to the high zone, and vice versa. This is associated with modest patchiness of the two-zone maps (
Figure 6 and
Figure 7): only some single NDVI maps (e.g., 24-06-2010 in
Figure 6) denote a patchy distribution that could pose problems in the differential application of some factor doses. However, the multiple soil and NDVI map (
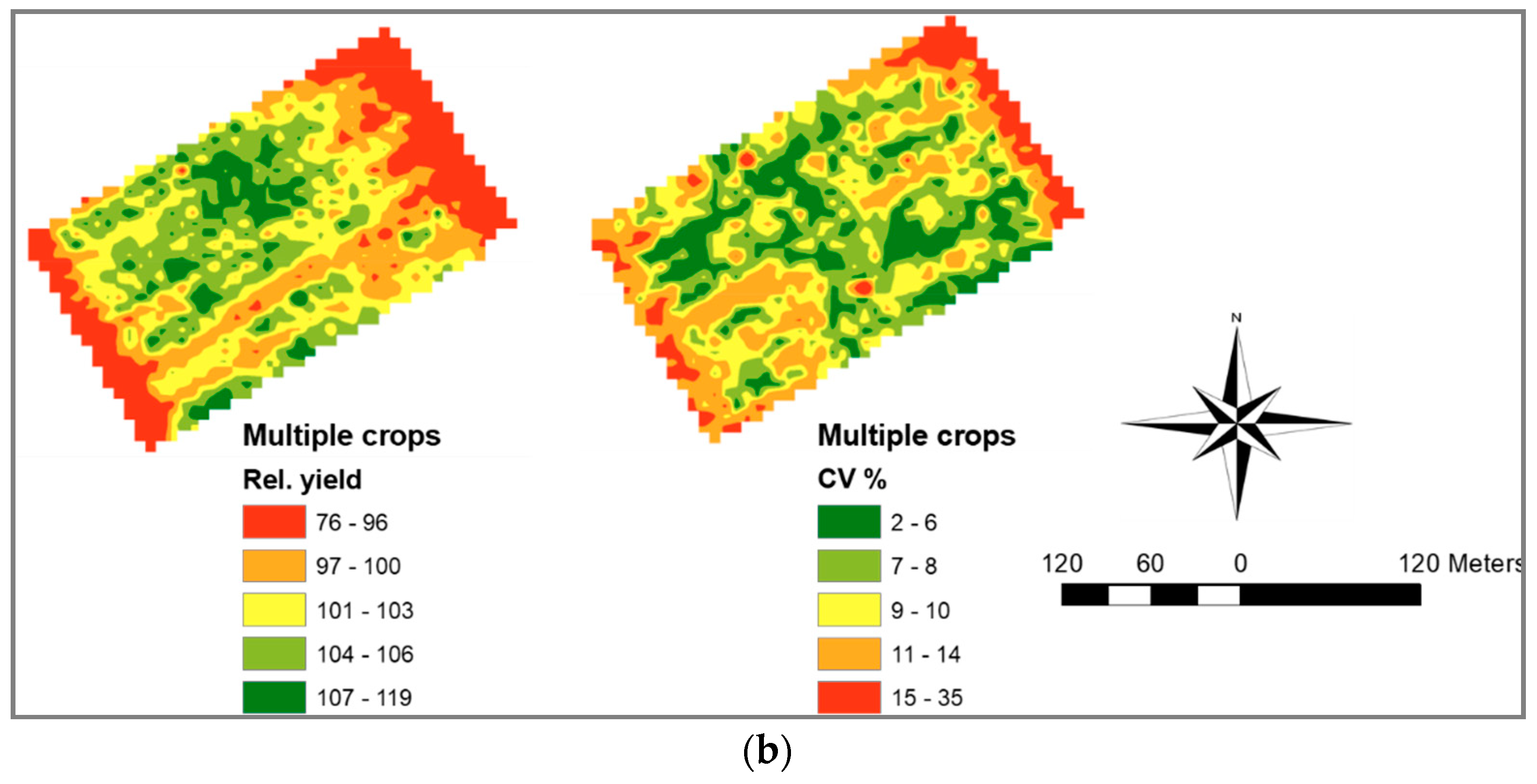
Figure 7) was not affected by this drawback, as the eight single parameters contributing to the multiple soil and NDVI maps provided the buffering that is a desired characteristic in a map intended for future use. The multiple yield two-zone map (
Figure 7) is an equally well-buffered map, as it originates from the multiple crops relative yield map (
Figure 3b). The good agreement between the multiple soil and NDVI map, and multiple yield map (83% in
Table 13), is a good premise for differential management of soil- and NDVI-based two zones in future cropping seasons.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}