1. Introduction
Maize (
Zea mays L.) is a significant fundamental agricultural product for the economies and markets of countries. With the development of society, the widespread use of biotechnology has improved maize breeding technologies and accelerated the renewal and iteration of varieties. However, the increasing number of varieties of maize seed and their color characteristics overlap to make it more challenging to classify seeds after harvest [
1]. In addition, the phenomenon of seeds being mixed may occur during production activities such as planting, harvesting, transportation, and storage [
2]. Therefore, variety identification plays a crucial role in the production, processing, and marketing of seeds. It will provide markets and consumers with pure seeds that will ensure yields and stabilize their market value.
Traditionally, there are many methods for variety identification [
3]. Morphological identification is limited by the range of morphological characteristics, the interference of human and environmental factors, and the impact of testing period or cost, which will decrease the accuracy of identification. Biochemical identification enables the recognition of seeds with different genetic characteristics, but it is difficult to identify closely related varieties. Molecular identification through DNA markers has the advantage of genetic stability and is independent of environmental conditions. But the cost of primer design is high, and the identification process can damage the sample [
4]. In summary, these detection methods are difficult to adapt to be online detection in the seed processing industry [
5] and cannot complete the sorting of samples during processing. Therefore, it is necessary to develop non-destructive, rapid, and efficient methods for the variety identification and classification of maize seeds.
Machine vision is the method of image processing adapted to multi-classification, which has been successfully applied in several fields. As for seed classification, the non-destructive nature hereof is undoubtedly a better choice than traditional detection methods. This method extracts color, texture, and shape features from seed images for classification. In [
6], 12 color features were extracted to distinguish between the different types of damage in maize, with an accuracy of 74.76% for classifying normal and six damaged maize. In [
7], 16 morphological features were extracted to classify dry beans, and the overall correct classification rate of SVM was 93.13%. In [
8], developed a machine that automatically extracts shape, color, and texture feature data of cabbage seeds and uses them to classify the quality of seeds. The research of maize seeds has focused on bioactivity screening and quality inspection. However, an additional issue that demands consideration is the classification of maize seeds of different varieties [
9].
Deep learning techniques have developed rapidly. The convolutional neural network (CNN) is a part of them, which has strong self-learning ability, adaptability, and generalization [
2,
10,
11]. It has achieved considerable success in image classification, object detection, and face recognition [
12]. CNN is a deep feedforward network inspired by the receptive field mechanism, which has the properties of local-connectivity, weight sharing, and aggregation in structure [
13,
14]. The network was composed of an input layer, convolution layers, pooling layers, fully connected layers, and an output layer [
15]. CNN models have emerged since 2012, such as AlexNet [
16], GoogLeNet [
17], VGGNet [
18], ResNet [
19], DenseNet [
20], MobileNet [
21], ShuffleNet [
22], EfficientNet [
23], and more.
Machine vision has also been combined with deep learning to classify seeds [
2,
24]. In [
15], used a CNN to automatically identify haploid and diploid maize seeds through a transfer learning approach. The experiment showed that the CNN model achieved good results, significantly outperforming machine learning-based methods and traditional manual selection. In [
25], a wheat recognition system was developed based on VGG16, and the classification accuracy was 98.19%, which could adequately distinguish between different types of wheat grains. In [
26], they used their self-designed CNN and ResNet models to identify seven cotton seed varieties, and it achieved good results, with 80% accuracy of the model identification. Reference [
27] determined HSI images of 10 representative high-quality rice varieties in China and established a rice variety determination model using the PCANet, with a classification accuracy of 98.66%. In [
24], used the CNN-ANN model to classify maize seeds, completing a test of 2250 instances in 26.8 s, with a classification accuracy of 98.1%.
Many studies have combined deep learning with machine vision because of its high accuracy, speed, and reliability. However, the increasing number of seed varieties and consumption are placing new demands on these studies, and the applicability of previous research methods has diminished. Therefore, inspired by the successful classification of agricultural products by deep CNNs, this paper studied the classification of maize seeds of different varieties. It is an in-depth exploration from another perspective based on the reference [
9]. Specifically, this research used maize seed images from [
9] and increased the number of samples by data augmentation. The proposed CNN network and transfer learning were used to study this classification task to obtain the best classification performance. This study not only extends [
9], but its distinction lies in the attempt to automatically obtain deeper features from the data to achieve end-to-end problem-solving.
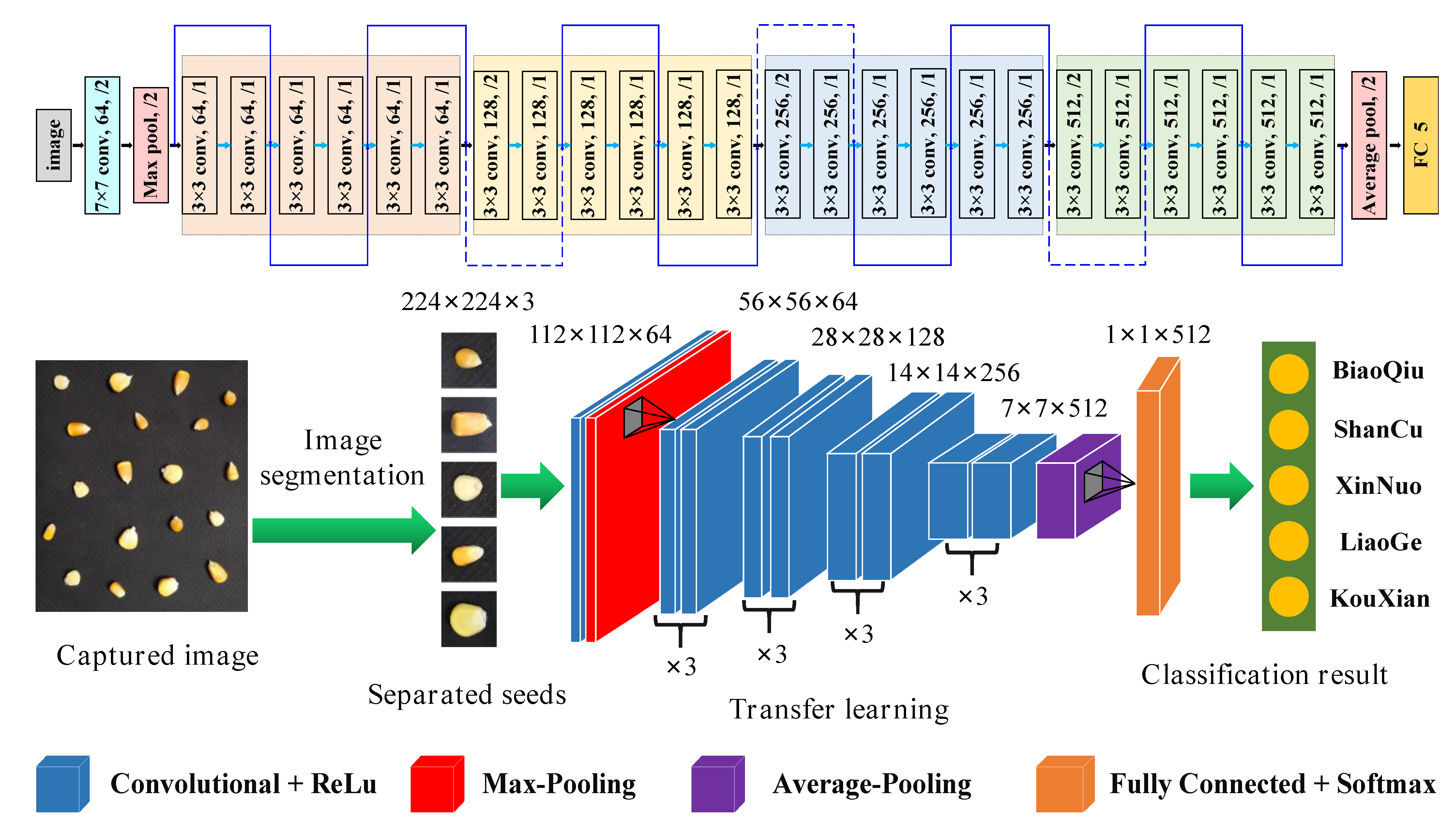
In summary, the objective of this study was to propose a non-destructive method for the automatic identification and classification of different varieties of maize seeds from images, thus overcoming the time-consuming and inefficient problems of traditional identification methods. We would pursue this study objective by: (1) implementing machine vision combined with deep learning by applying a CNN network with P-ResNet architecture for varietal detection; (2) establishing a seed dataset and dividing it into training and validation sets in the ratio of 8:2 for experiments; as well as (3) evaluating and comparing the classification performance of the models and using visualization to validate the results. In addition, we address the following specific hypotheses: (1) transfer learning can acquire knowledge learned in other Settings and be used to complete similar tasks in deep learning, thus helping to save the training time of the model; and (2) compared with manual feature extraction methods, the CNN model can be used to automatically extract more depth features from images, thus improving the classification performance.
3. Results
The parameters given in
Table 4 were selected for transfer learning. The prepared dataset was trained using AlexNet, VGGNet, P-ResNet, GoogLeNet, MobileNet, DenseNet, ShuffleNet, and EfficientNet. The optimal parameters in
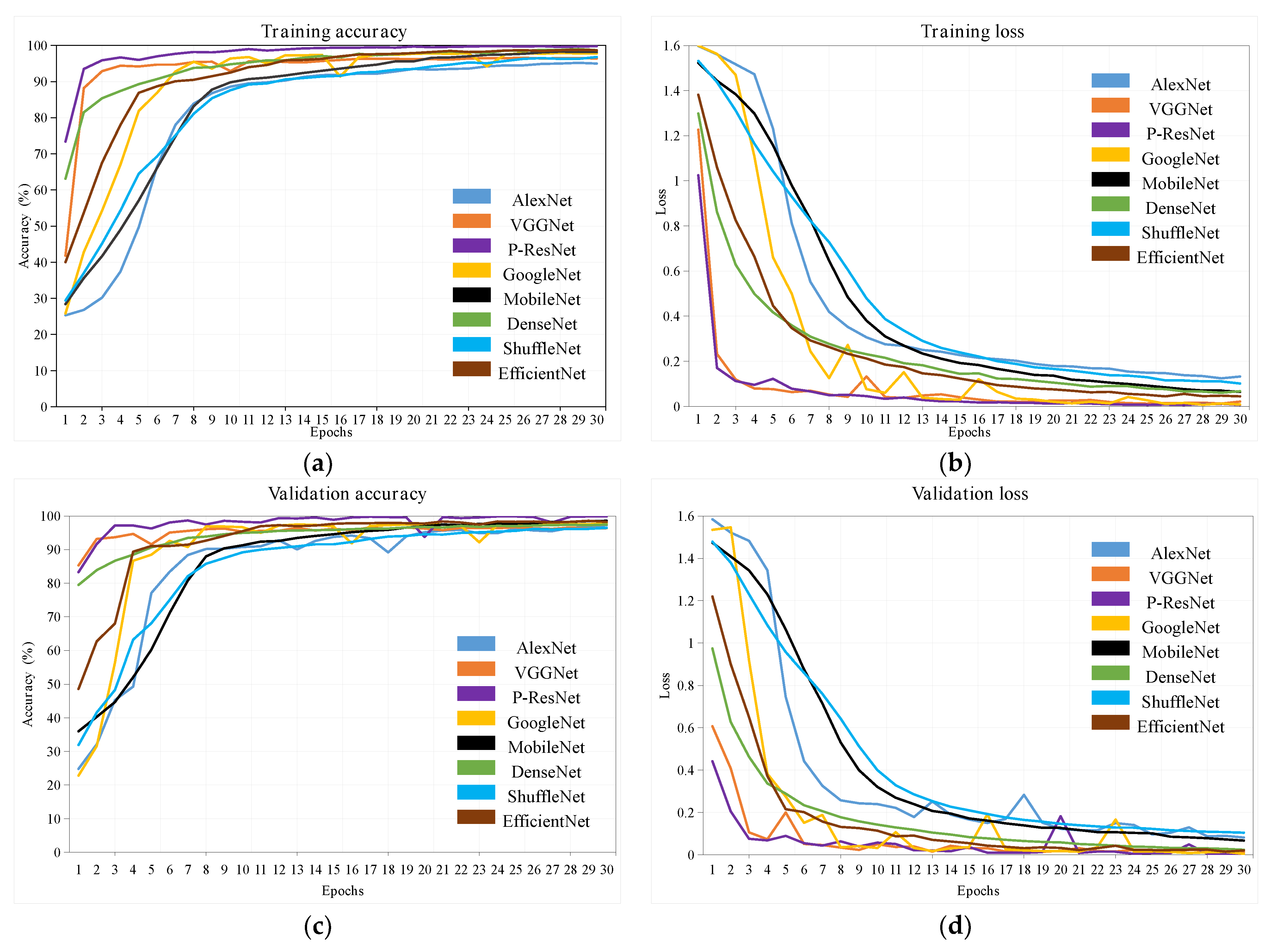
Table 4 were used to prevent over-fitting during training and avoid spending more time. All networks have been trained for 30 epochs. The accuracy and loss of the training and validation data for each epoch are shown in
Figure 4. In the initial phase (1–10 epochs), the loss values declined sharply, but the accuracy improved dramatically. Finally, the CNN models reached an accuracy of over 92% in the training phase, and the loss of models was steady below 0.15, indicating that these are very robust and dependable. Also, the model achieved the convergence procedure in approximately 15 epochs. As can be depicted in
Figure 4, after this period, the validation accuracy and loss curves smoothed out, and the difference between the accuracy and loss values of the validation and training data decreased. There, for the fact, was some fluctuation with accuracy and loss for GoogLeNet. This condition suggests that the model is not stable until the 25 epochs, possibly because some of the varieties were easily confounded. There are gaps in GoogLeNet’s handling of the dataset for this study compared to other models. Nevertheless, even in the worst case, the metrics were above 90% or below 0.2. This result indicates that the classifier’s performance is satisfactory and did not prevent it from achieving its final classification purpose.
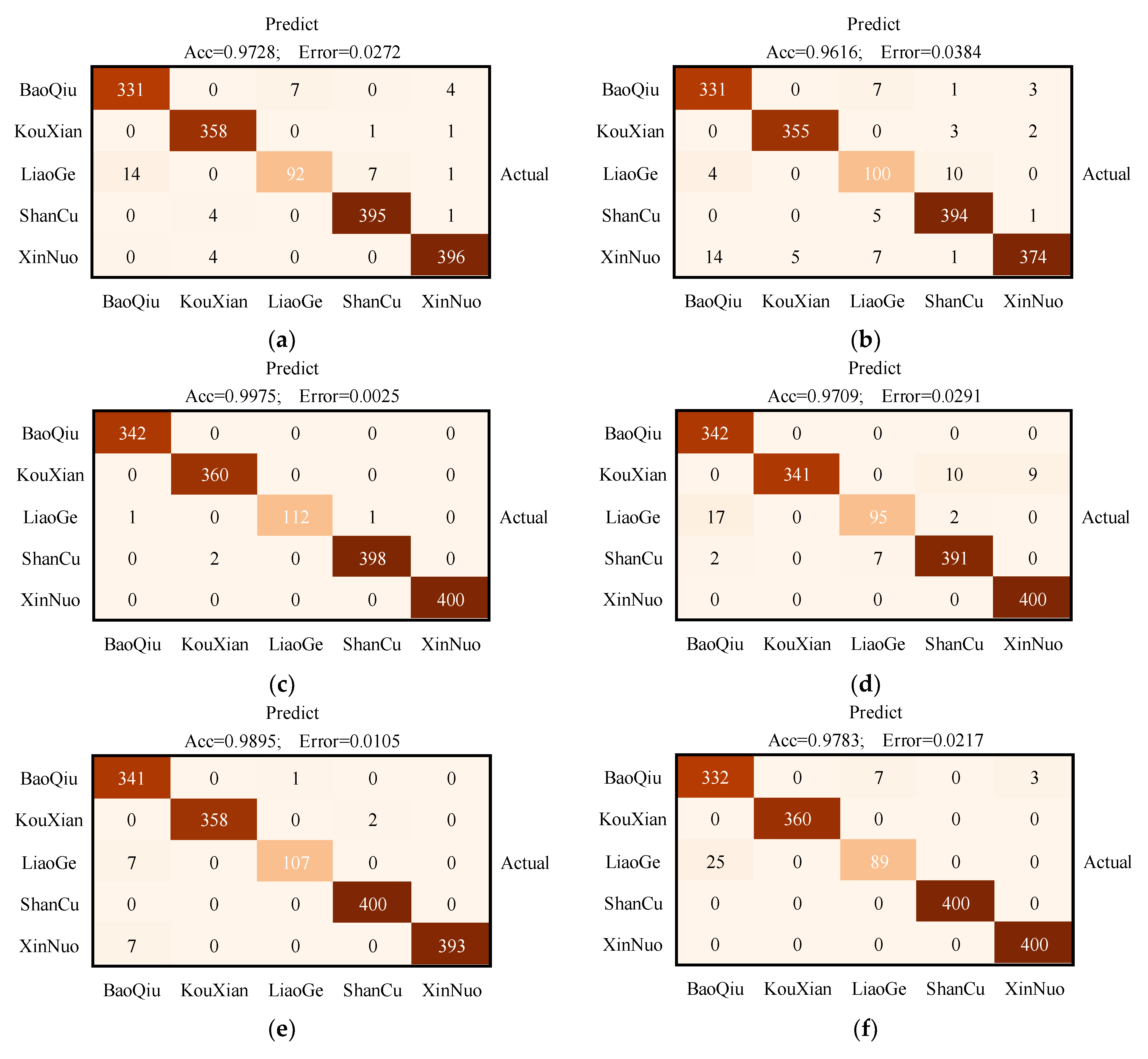
After the training, a confusion matrix was created for each classification algorithm, and performance evaluation was visualized using the values on the confusion matrix (TP, TN, FP, FN). The confusion matrices for the validation set of the CNN model are depicted in
Figure 5. In addition, the performance metrics depicted from the confusion matrix are presented in
Table 6, including their mean values for precision, specificity, sensitivity, accuracy, and f1 scoring. In this experiment, all CNN models can identify five classes of maize seeds, and all had an accuracy rate of over 92%. The highest accuracy was obtained by P-ResNet (99.70%), followed by AlexNet (97.91%), VGGNet (96.44%), GoogLeNet (97.84%), MobileNet (98.58%), DenseNet (97.13%), ShuffleNet (96.59%), and EfficientNet (98.28%). Even though these models were trained with images from self-made datasets, fine-tuning these models can achieve similar results to using the end-to-end models in datasets with limited samples. This situation will make image acquisition more convenient and fast, will save effort and time, and will thus improve efficiency. Besides, the confusion matrix and classification results also prove that P-ResNet has excellent performance. This result also illustrates that the presented network can catch the detailed information of the samples. These can provide relatively high accuracy classification under complex datasets, which is beneficial for transferring it to similar classification tasks. The experimental results also demonstrate that enhancing the data used for training has a positive impact on the performance of the presented model on datasets with a small number of samples. In particular, these include datasets with low sample sizes. At the same time, the deep learning-based feature extraction method can effectively preserve information about the maize seeds, reduce the loss of information due to manual feature extraction.
The experimental analysis showed that the deep learning architecture with updated weights and fine-tuning had good generalization capability in the maize seed dataset. Compared with the networks in the literature, the proposed P-ResNet has relatively better performance and higher accuracy. It also found that the value of the maximum difference in classification accuracy between all models was no more than 3%. Although there were differences between them, they performed similarly for multi-classification. Therefore, an improved ResNet-based network has been used for transfer learning in the study. Due to its better classification results, it confirms that the idea of balancing its depth and width when designing the network is feasible. It would also increase the complexity of the model and consume more computation time. As can be observed in
Table 3, the P-ResNet proposed generates a relatively small number of parameters (17.96 Million) and memory (32.83 MB). VGGNet has 7.6 times as many parameters as it does, while the memory footprint is close to GoogLeNet. The FLOPs value (2.75 G) is approximately the same as that of DenseNet and EfficientNet, indicating the low complexity of the model. It also demonstrates the potential for the network to be lightweight and mobile. With the continuous improvement of the model, a version more suitable for mobile and embedded devices can be achieved.
Figure 6 shows a comparison of the performance of the CNN models tested, from which it can be seen that the training time of the proposed network is comparable to that of the lightweight networks (MobileNet and ShuffleNet). AlexNet had the shortest training time (14 min) and VGGNet the longest (62 min). It is important to note that the time required for training the network depends on the hardware resources. The use of advanced GPU can reduce the training time of CNN. However, when time and model complexity were considered, P-ResNet’s training time was only 4 min slower than AlexNet, and the values for Parameters, FLOPs, and total memory were relatively better. This situation is because of the use of Adam optimizer in the proposed model, which minimizes error loss, and transforms the training and validation data for each epoch. In this work, when the region of interest of seeds was extracted from the image and applied to the deep learning model, the processing time of training can be reduced.
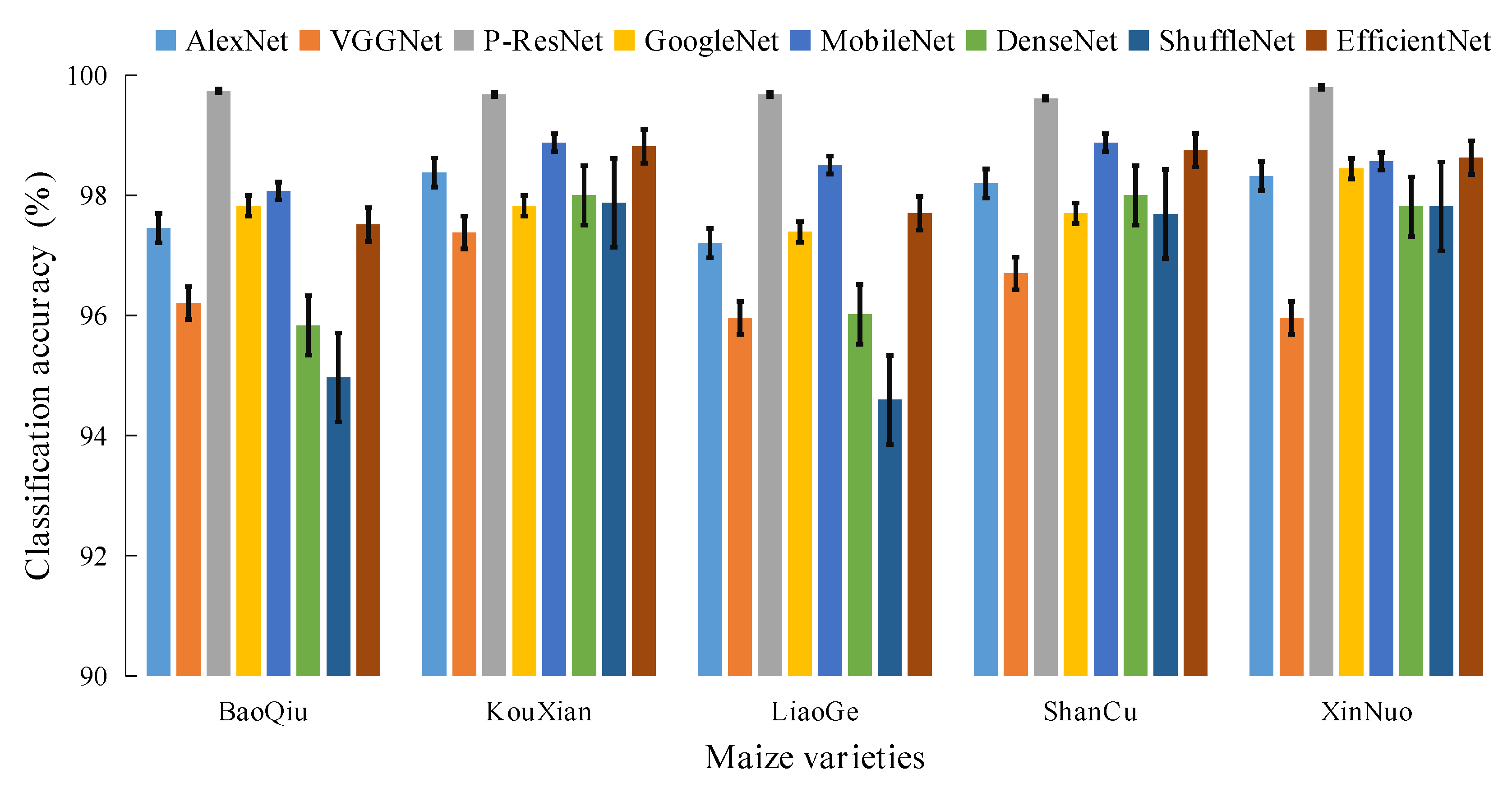
The classification results for all varieties of maize seeds in the different models were shown in
Table 7, and this statistic clearly shows how the model performance stays in general and as a whole. As can be seen from
Figure 7, the classification accuracy of 8 different models for five maize seeds was over 90%. The P-ResNet network had the best classification performance, with 99.74, 99.68, 99.68, 99.61, and 99.80% accuracy for the BaoQiu, KouXian, LiaoGe, ShanCu, and XinNuo, respectively. However, BaoQiu and LiaoGe had lesser classification performance among all models, and the lowest values were 94.97 and 94.60%, respectively. These results indicated that VGGNet, DenseNet, and ShuffleNet models were not the best adapted for these two varieties. It also revealed that there probably is overlap in features between BaoQiu and LiaoGe and the other three varieties, resulting in poor distinction. In addition, the low number of LiaoGe in the dataset may also have contributed to this situation. Through, their classification results were still very encouraging.
In this experiment, given the different methods, datasets, and classification criteria employed, relevant studies cannot be compared in detail. Nevertheless, it compared some applications in agricultural classification tasks, and the results are shown in
Table 8. These comparisons considered several criteria, such as dataset size, application, the method used, and accuracy. The results showed that the accuracy for the different classification tasks was above 95%, which indicated that the CNN model proposed in this paper and the pre-training method using transfer learning were feasible. It can provide a reference for the classification of agricultural products. The five types of maize seeds utilized in the research are relatively common in China, with a wide distribution of planting areas. In this situation, the credibility of this study has been enhanced. Although the P-ResNet model achieved good results, maize seeds may vary depending on storage time and cultivation conditions (soil or climate). These conditions lead to changes in the dataset, which may influence its accuracy in distinguishing the target varieties. Therefore, it will be necessary to update the algorithm in the future, and the aim is to retain the classification precision and robustness of the model.
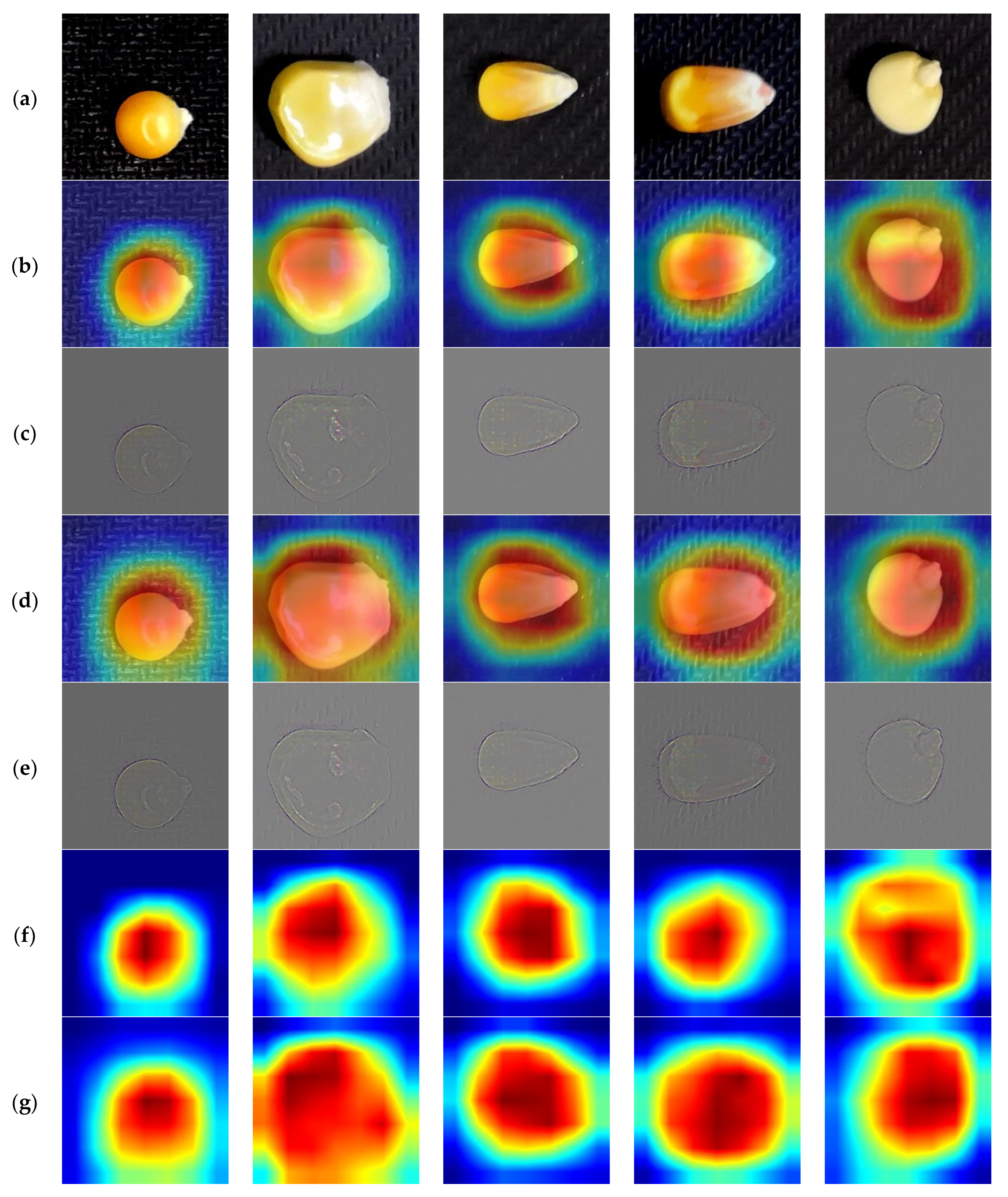
These results were obtained using the Gradient-weighted Class Activation Mapping (Grad-CAM) technique to visualize the used regions of a random input image to extract features for image classification prediction [
35]. The gradient of any target feature through the last convolution layer produces a roughly local feature map, highlighting the regions of the image that are important for it.
Figure 8 shows the achieved results of the implementation of this method on maize seed images. It can be shown that the image locations for seeds were accurately calculated, with the class activation heat map indicating the importance rank and similarity of the location relative to the particular variety.
4. Discussion
There are two primary methods for training CNN models using sample data: (1) starting from zero; and (2) transfer learning. In practice, while training a CNN model from the ground up gives us the best active control concerning the network, it may not have enough data and time to train in some cases, or the data to create the markers may be difficult to obtain. Moreover, over-fitting and convergence states are also potential problems. In such cases, transfer learning can be applied to gain knowledge gained in other settings. It is a convenient and effective method of knowledge adaptation [
31], which is usually more efficient than training a new neural network since all parameter values are not required to start from zero. In higher-layers networks, some features are more applicable to a specific task. However, there are many similar features like color and texture for the lower layers of the network. These can be transferred to other tasks and are very helpful for performing similar tasks in deep learning.
P-ResNet was designed based on the principle of balancing the width and depth of the network according to the specific task, which has a better architecture than GoogLeNet, DenseNet, and EfficientNet. It can reduce parameters for computation and avoid gradient disappearance and gradient explosion during training. Meanwhile, it does not need to crop or scale the input image like AlexNet and VGGNet, which can maximally protect the information integrity. In addition, the underlying implementation of this network was simplified to make it more lightweight as possible as MobileNet and ShuffleNet. Since only images are required, which can be produced by low-cost digital cameras, this approach can be widely deployed and disseminated in intelligent agriculture. Machine vision can only obtain phenotypic information of seeds, while spectral information can reflect the internal quality of seeds. The combination of CNN-based machine vision and spectroscopic techniques for seed classification and detection was considered in the follow-up work.
The proposed method has been compared with related work based on the unification of the research objectives (classification or identification) and the object of study (maize seeds). In
Table 7, it can be seen that automatic extraction of image features for recognition using CNN is better than manual extraction, and these results illustrate that deep learning is more effective than traditional machine learning methods in cultivar classification. However, the variety and number of samples collected in this study are limited and cannot represent all maize seeds within China. Therefore, the number of samples should be increased to improve its applicability to the model. Moreover, this experiment only considered the classification effects of seed samples from the same year, so the impact of different planting years, growing regions, and climatic conditions on the classification of seeds of the same variety can be compared in subsequent studies.
5. Conclusions
In this work, a combination of deep learning algorithms and machine vision has been used to automatically classify five varieties of maize seeds using a CNN model. In terms of classification, the model architecture developed can be applied to different regions and types of seeds to ensure the provision of high-quality seeds for agricultural production. Also, the method has application potential in identifying varieties of seeds, and the developed variety classification model can be applied to seed sorting machinery to provide an idea and reference for real-time industrial detection. This study proposes an improved model, P-ResNet, and compares it with AlexNet, VGGNet, GoogLeNet, MobileNet, DenseNet, ShuffleNet, and EfficientNet models. The results showed that the P-ResNet model achieved the best accuracy to classify maize seeds in a non-destructive, fast, and efficient manner. These results highlight the advantages of transfer learning and its potential to work with deep learning using a few quantities of training samples. In addition, the Grad-CAM has been used to visualize the regions of use of the input seed images, making this work more efficient and productive. This machine vision technology based on CNN with high accuracy and reliability can also be applied in other intelligent agricultural equipment to facilitate the analysis of seeds or other crops to save cost, labor, and time.
Based on the work presented in this paper, further studies on more varieties of maize seeds and the environment in which they are grown would be appropriate, and it is in order to optimize the stability of the proposed model. Considering that each seed in maize has its genetic characteristics, grouping seeds of selected varieties might avoid natural variability in seedlings. Given the real-time nature of the data, that helps to develop an integrated and intelligent automated seed sorting system for the food industry and smartphone-based applications used by consumers.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
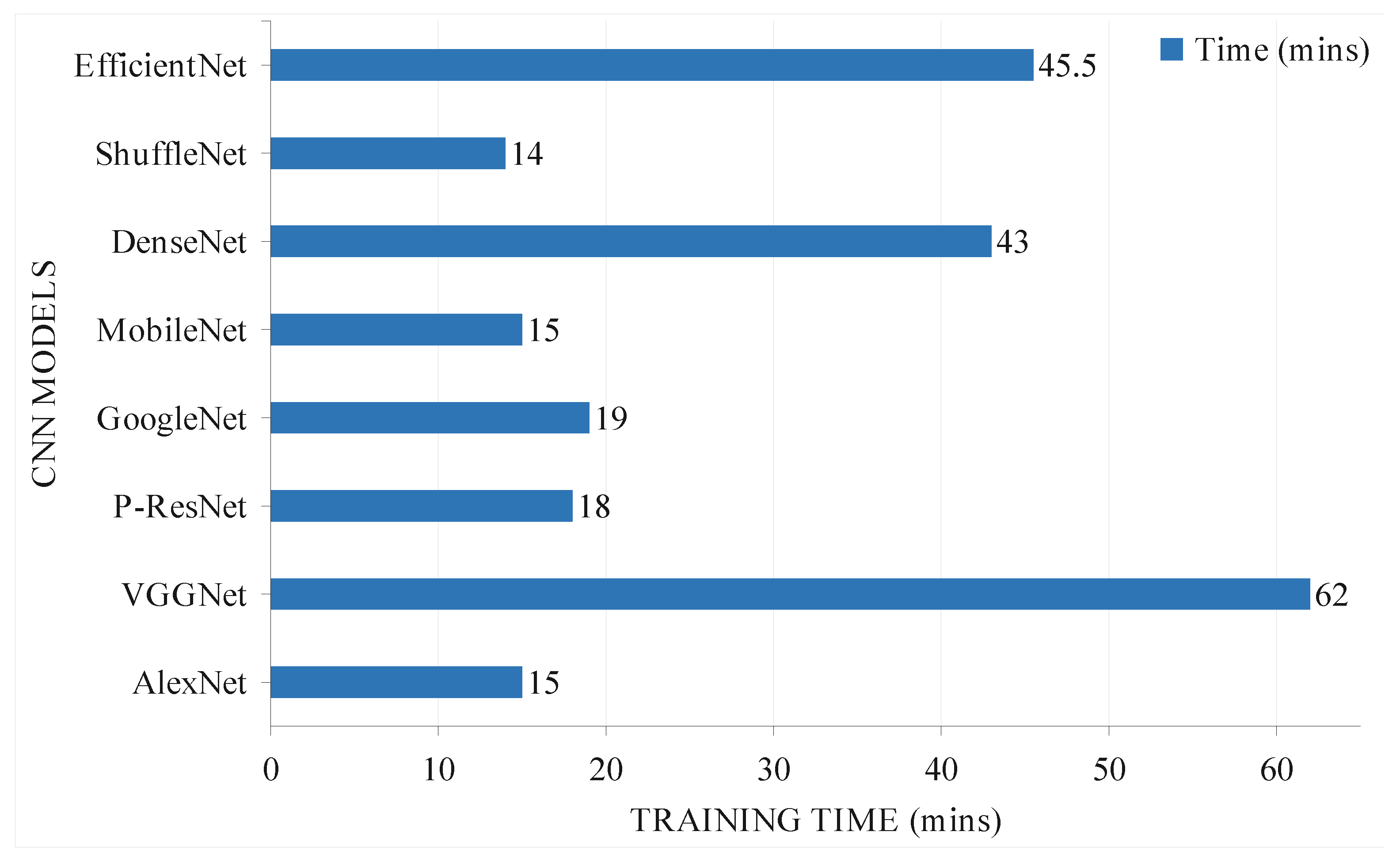{kind=link}
{kind=link}
{kind=link}