
DepthFormer: A High-Resolution Depth-Wise Transformer for Animal Pose Estimation

Abstract
:1. Introduction
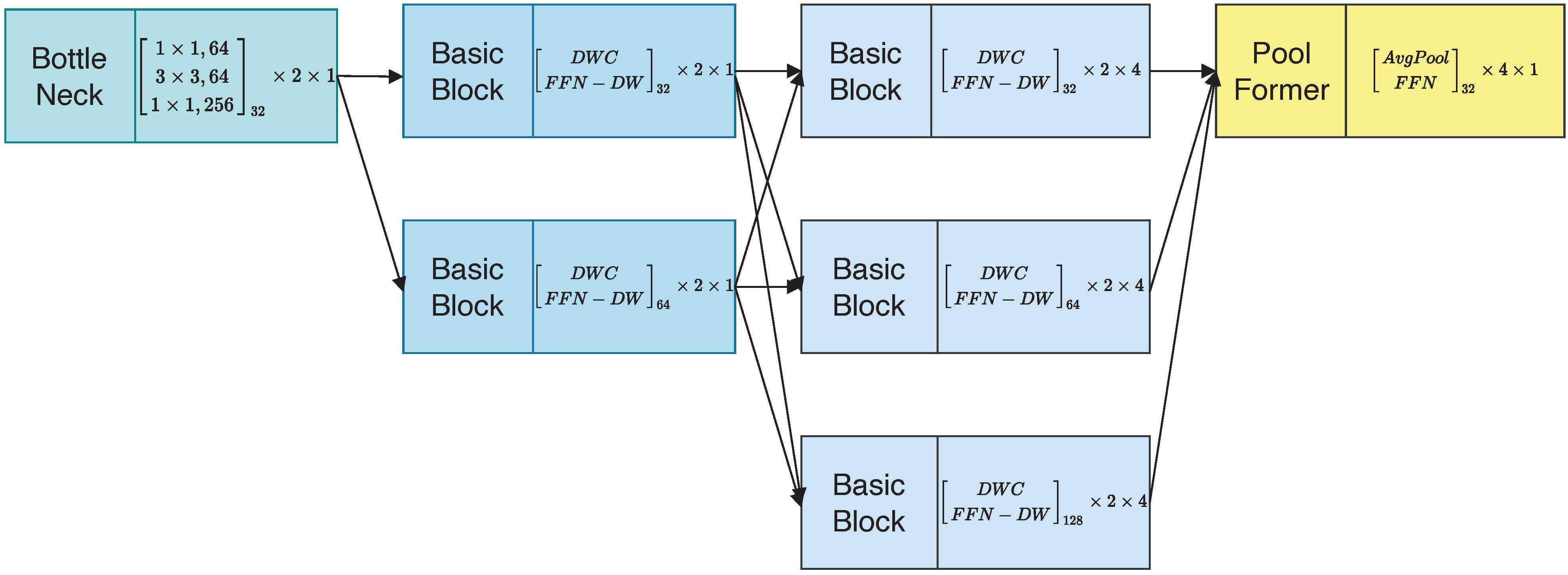
- We propose DepthFormer, which is designed by utilizing three-stage parallel branches with the idea of multi-scale representation fusion. The network keeps rich spatial information from start to end.
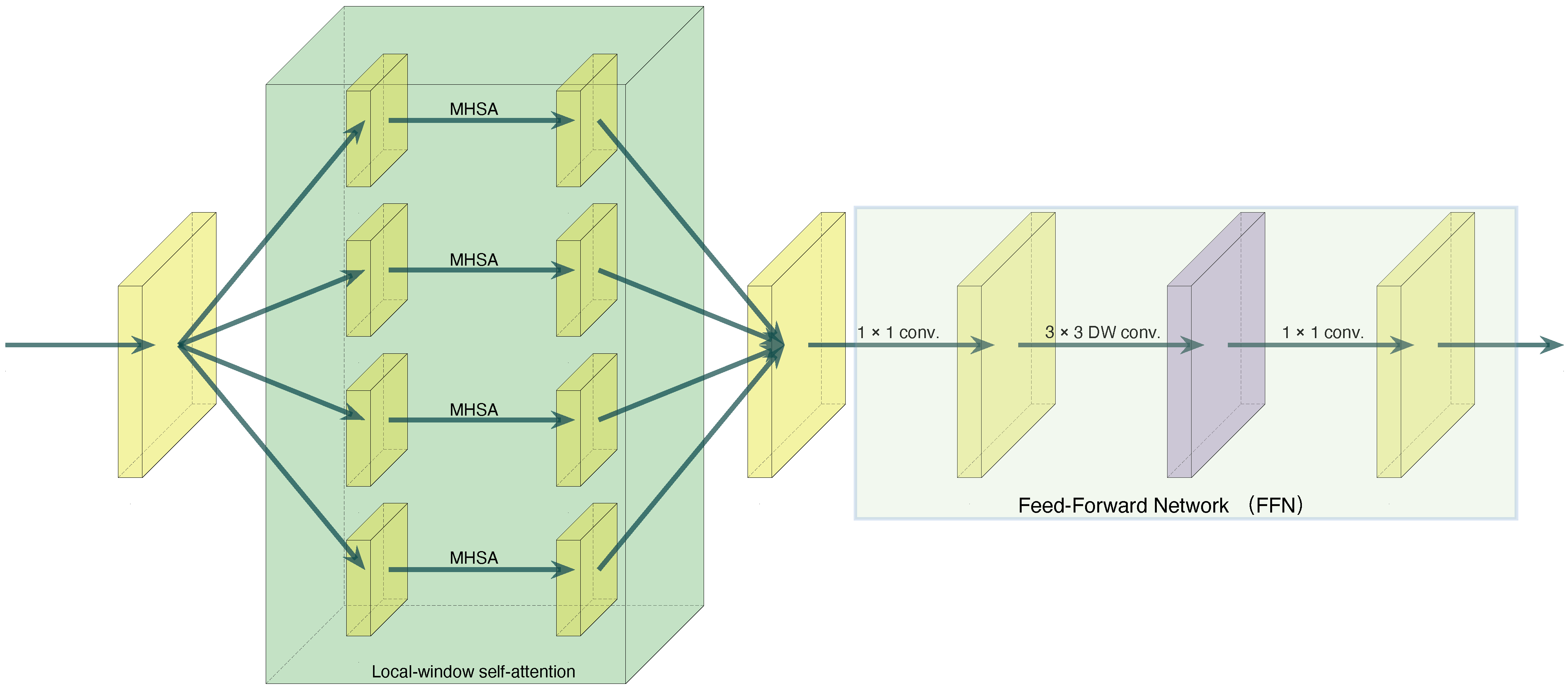
- Based on two similarities (sparse connectivity and weight sharing) between self-attention and depthwise convolution, we rely on a structure with Transformer that has strong power and representative batch normalization, which could strengthen the representation of specific instances to design a new basic block. The purpose of this is to reduce the quantity of parameters and calculation.
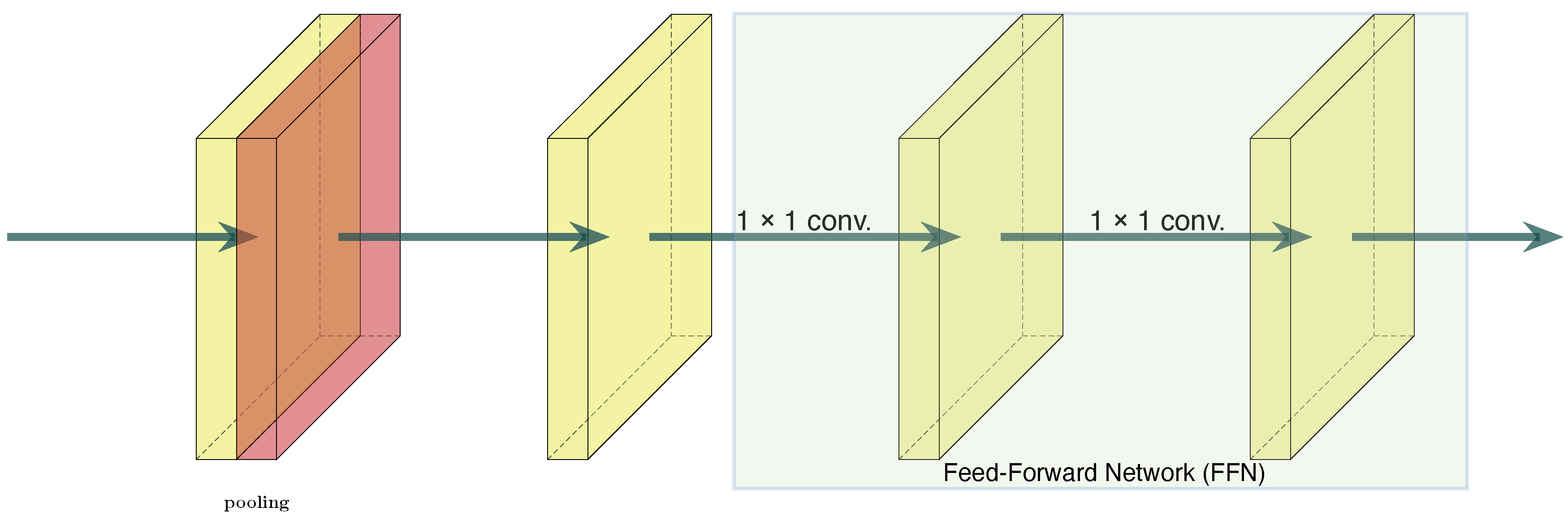
- For balancing the contradiction between the computation and performance of the model, we add four PoolFormer blocks after the parallel network, improving performance with minimal additional computing costs.
- DepthFormer is state-of-the-art in terms of computing cost and performance tradeoff on the AP-10K benchmark, outperforming ShuffleNet, HRFormer-T, and Lite-HRNet.
2. Materials and Methods
2.1. AP-10K Dataset
2.2. Methods
2.2.1. Multi-Branch Neural Network
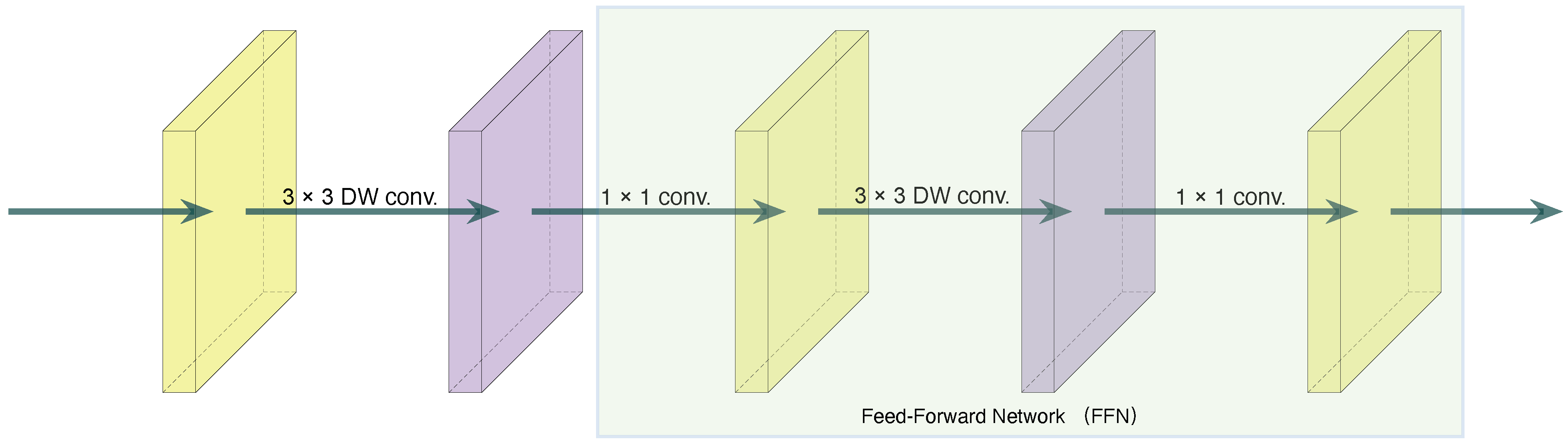
2.2.2. Depthwise Convolution
2.2.3. DepthFormer Block
2.2.4. PoolFormer Block
2.2.5. Representative Batch Normalization
2.2.6. Instantiation
2.3. Evaluation Indicators and Experimental Environment
2.3.1. Evaluation Metric
2.3.2. Experimental Settings
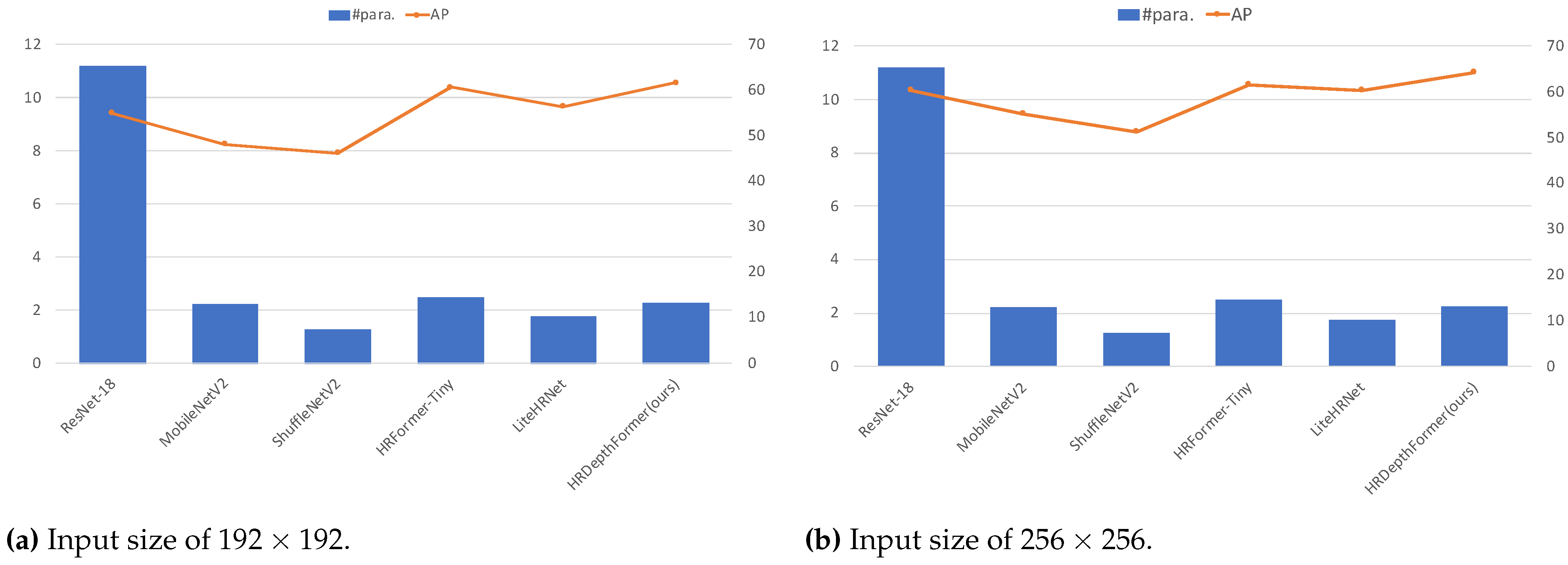
3. Results
3.1. Results on the Val Set
3.2. Results on the Test Set
3.3. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FFN | Feed-Forward Network |
| ViT | Vision Transformer |
| MHSA | Multihead Self-Attention |
| W-MSA | Window-Based Multi-head Self-Attention |
| FFN-DW | Feed-Forward Network with a 3 × 3 Depth-wise Convolution |
| HRFormer | High-Resolution Transformer |
| HRNet | High-Resolution Network |
| HSC | Horizontal Shortcut Connections |
References
- Arac, A.; Zhao, P.; Dobkin, B.H.; Carmichael, S.T.; Golshani, P. DeepBehavior: A Deep Learning Toolbox for Automated Analysis of Animal and Human Behavior Imaging Data. Front. Syst. Neurosci. 2019, 13, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Padilla-Coreano, N.; Batra, K.; Patarino, M.; Chen, Z.; Rock, R.R.; Zhang, R.; Hausmann, S.B.; Weddington, J.C.; Patel, R.; Zhang, Y.E.; et al. Cortical ensembles orchestrate social competition through hypothalamic outputs. Nature 2022, 603, 667–671. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Li, J.; Tang, H.; Qian, R.; Lin, W. ATRW: A Benchmark for Amur Tiger Re-identification in the Wild. In Proceedings of the MM: International Multimedia Conference, Seattle, WA, USA, 12–16 October 2020; pp. 2590–2598. [Google Scholar] [CrossRef]
- Harding, E.J.; Paul, E.S.; Mendl, M. Cognitive bias and affective state. Nature 2004, 427, 312. [Google Scholar] [CrossRef] [PubMed]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef] [PubMed]
- Graving, J.M.; Chae, D.; Naik, H.; Li, L.; Koger, B.; Costelloe, B.R.; Couzin, I.D. DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. eLife 2019, 8, e47994. [Google Scholar] [CrossRef]
- Labuguen, R.; Matsumoto, J.; Negrete, S.B.; Nishimaru, H.; Nishijo, H.; Takada, M.; Go, Y.; Inoue, K.i.; Shibata, T. MacaquePose: A Novel “In the Wild” Macaque Monkey Pose Dataset for Markerless Motion Capture. Front. Behav. Neurosci. 2021, 14, 581154. [Google Scholar] [CrossRef]
- Yu, H.; Xu, Y.; Zhang, J.; Zhao, W.; Guan, Z.; Tao, D. AP-10K: A Benchmark for Animal Pose Estimation in the Wild. arXiv 2021, arXiv:2108.12617. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Computer Vision–ECCV 2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11210, pp. 472–487. [Google Scholar] [CrossRef] [Green Version]
- Nie, X.; Feng, J.; Zhang, J.; Yan, S. Single-Stage Multi-Person Pose Machines. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6950–6959. [Google Scholar] [CrossRef] [Green Version]
- Kreiss, S.; Bertoni, L.; Alahi, A. PifPaf: Composite Fields for Human Pose Estimation. arXiv 2019, arXiv:1903.06593. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping. arXiv 2017, arXiv:1611.05424. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5385–5394. [Google Scholar] [CrossRef]
- Li, K.; Wang, S.; Zhang, X.; Xu, Y.; Xu, W.; Tu, Z. Pose Recognition with Cascade Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1944–1953. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef] [Green Version]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Computer Vision–ECCV 2016; Lecture Notes in Computer, Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9912, pp. 483–499. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. CoRR 2017, 30. arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. arXiv 2022, arXiv:2107.00652. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer is Actually What You Need for Vision. arXiv 2021, arXiv:2111.11418. [Google Scholar]
- Andreoli, J.M. Convolution, attention and structure embedding. arXiv 2020, arXiv:1905.01289. [Google Scholar]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the Relationship between Self-Attention and Convolutional Layers. arXiv 2020, arXiv:1911.03584. [Google Scholar]
- Wu, F.; Fan, A.; Baevski, A.; Dauphin, Y.N.; Auli, M. Pay Less Attention with Lightweight and Dynamic Convolutions. arXiv 2019, arXiv:1901.10430. [Google Scholar]
- Tay, Y.; Dehghani, M.; Gupta, J.P.; Aribandi, V.; Bahri, D.; Qin, Z.; Metzler, D. Are Pretrained Convolutions Better than Pretrained Transformers? In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (ACL), Bangkok, Thailand, 1–6 August 2021; pp. 4349–4359. [Google Scholar] [CrossRef]
- Han, Q.; Fan, Z.; Dai, Q.; Sun, L.; Cheng, M.M.; Liu, J.; Wang, J. On the Connection between Local Attention and Dynamic Depth-wise Convolution. arXiv 2022, arXiv:2106.04263. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Vision Transformer for Dense Predict. In Proceedings of the NeurIPS 2021, Virtual, 13 December 2021. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. UniFormer: Unifying Convolution and Self-attention for Visual Recognition. arXiv 2022, arXiv:2201.09450. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef] [Green Version]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Computer Vision–ECCV 2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11218, pp. 122–138. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-HRNet: A Lightweight High-Resolution Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10435–10445. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Luo, Y.; Ou, Z.; Wan, T.; Guo, J.M. FastNet: Fast high-resolution network for human pose estimation. Image Vis. Comput. 2022, 119, 104390. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. arXiv 2018, arXiv:1808.00897. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar] [CrossRef]
- Laurent, S. Rigid-Motion Scattering For Image Classification. Ph.D. Thesis, Ecole Polytechnique, Palaiseau, France, 2014. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- Zhu, A.; Liu, L.; Hou, W.; Sun, H.; Zheng, N. HSC: Leveraging horizontal shortcut connections for improving accuracy and computational efficiency of lightweight CNN. Neurocomputing 2021, 457, 141–154. [Google Scholar] [CrossRef]
- Gao, S.H.; Han, Q.; Li, D.; Cheng, M.M.; Peng, P. Representative Batch Normalization with Feature Calibration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8665–8675. [Google Scholar] [CrossRef]
- Stoffl, L.; Vidal, M.; Mathis, A. End-to-End Trainable Multi-Instance Pose Estimation with Transformers. arXiv 2021, arXiv:2103.12115. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keypoint | Definition | Keypoint | Definition |
|---|---|---|---|
| 1 | Left Eye | 10 | Right Elbow |
| 2 | Right Eye | 11 | Right Front Paw |
| 3 | Nose | 12 | Left Hip |
| 4 | Neck | 13 | Left Knee |
| 5 | Root of Tail | 14 | Left Back Paw |
| 6 | Left Shoulder | 15 | Right Hip |
| 7 | Left Elbow | 16 | Right Knee |
| 8 | Left Front Paw | 17 | Right Back Paw |
| 9 | Right Shoulder |
| Methods | Input Size | #param. | GFLOPs | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|
| SimpleBaseline-18 | 192 × 192 | 11.17 M | 1.33 | 56.6 | 87.2 | 59.6 | 45.4 | 56.9 | 60.3 |
| SimpleBaseline-18 | 256 × 256 | 11.17 M | 2.37 | 62.4 | 89.3 | 66.4 | 37.0 | 62.9 | 66.6 |
| ShuffleNetV2 | 192 × 192 | 1.25 M | 0.10 | 47.1 | 82.6 | 45.3 | 33.2 | 47.5 | 52.0 |
| ShuffleNetV2 | 256 × 256 | 1.25 M | 0.19 | 53.2 | 85.3 | 54.0 | 38.3 | 53.5 | 59.1 |
| MobileNetV2 | 192 × 192 | 2.22 M | 0.22 | 49.5 | 84.0 | 48.0 | 40.3 | 49.8 | 53.9 |
| MobileNetV2 | 256 × 256 | 2.22 M | 0.40 | 56.1 | 86.4 | 56.6 | 50.0 | 56.4 | 61.3 |
| Lite-HRNet | 192 × 192 | 1.76 M | 0.30 | 58.0 | 89.0 | 61.1 | 52.1 | 58.2 | 62.3 |
| Lite-HRNet | 256 × 256 | 1.76 M | 0.54 | 60.7 | 90.1 | 63.3 | 53.7 | 61.0 | 65.5 |
| HRFormer-Tiny | 192 × 192 | 2.49 M | 1.03 | 61.7 | 90.9 | 65.9 | 55.8 | 62.0 | 65.6 |
| HRFormer-Tiny | 256 × 256 | 2.49 M | 1.89 | 62.2 | 91.6 | 67.8 | 47.8 | 62.6 | 67.1 |
| DepthFormer | 192 × 192 | 2.27 M | 1.50 | 63.5 | 91.0 | 67.5 | 51.5 | 63.8 | 67.3 |
| DepthFormer | 256 × 256 | 2.27 M | 2.67 | 65.4 | 92.2 | 70.6 | 52.9 | 65.8 | 70.0 |
| Methods | Input Size | #param. | GFLOPs | AP | AP50 | AP75 | APM | APL | AR |
|---|---|---|---|---|---|---|---|---|---|
| SimpleBaseline-18 | 192 × 192 | 11.17 M | 1.33 | 54.9 | 86.2 | 56.6 | 38.7 | 55.5 | 59.4 |
| SimpleBaseline-18 | 256 × 256 | 11.17 M | 2.37 | 60.3 | 88.5 | 63.0 | 48.1 | 61.1 | 65.2 |
| ShuffleNetV2 | 192 × 192 | 1.25 M | 0.10 | 46.2 | 79.1 | 45.1 | 36.7 | 46.8 | 51.0 |
| ShuffleNetV2 | 256 × 256 | 1.25 M | 0.19 | 51.3 | 83.7 | 50.3 | 38.7 | 52.0 | 57.4 |
| MobileNetV2 | 192 × 192 | 2.22 M | 0.22 | 48.1 | 81.0 | 47.6 | 40.3 | 48.6 | 53.0 |
| MobileNetV2 | 256 × 256 | 2.22 M | 0.40 | 55.1 | 86.3 | 55.8 | 43.8 | 55.7 | 60.5 |
| Lite-HRNet | 192 × 192 | 1.76 M | 0.30 | 56.4 | 87.1 | 59.2 | 47.7 | 56.9 | 60.9 |
| Lite-HRNet | 256 × 256 | 1.76 M | 0.54 | 60.2 | 88.7 | 62.7 | 50.0 | 60.8 | 65.3 |
| HRFormer-Tiny | 192 × 192 | 2.49 M | 1.03 | 60.6 | 88.8 | 65.7 | 48.0 | 61.3 | 65.1 |
| HRFormer-Tiny | 256 × 256 | 2.49 M | 1.89 | 61.5 | 90.0 | 66.6 | 47.3 | 62.2 | 66.9 |
| DepthFormer | 192 × 192 | 2.27 M | 1.50 | 62.1 | 89.1 | 67.0 | 51.9 | 66.7 | 66.3 |
| DepthFormer | 256 × 256 | 2.27 M | 2.67 | 64.1 | 89.5 | 69.3 | 55.4 | 64.7 | 69.0 |
| No. | Baseline | DWC | RBN | 2 Blocks | 4 Blocks | 6 Blocks | #Param. | GFLOPs | AP | AR |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | √ | 2.197 | 1.352 | 60.2 | 64.7 | |||||
| 2 | √ | √ | 2.216 | 1.363 | 60.6 | 65.1 | ||||
| 3 | √ | √ | 2.197 | 1.357 | 60.5 | 64.9 | ||||
| 4 | √ | √ | √ | 2.216 | 1.368 | 61.6 | 65.9 | |||
| 5 | √ | √ | √ | √ | 2.259 | 1.466 | 61.7 | 65.9 | ||
| 6 | √ | √ | √ | √ | 2.275 | 1.502 | 62.1 | 66.3 | ||
| 7 | √ | √ | √ | √ | 2.292 | 1.543 | 61.8 | 66.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Fan, Q.; Liu, S.; Zhao, C. DepthFormer: A High-Resolution Depth-Wise Transformer for Animal Pose Estimation. Agriculture 2022, 12, 1280. https://doi.org/10.3390/agriculture12081280
Liu S, Fan Q, Liu S, Zhao C. DepthFormer: A High-Resolution Depth-Wise Transformer for Animal Pose Estimation. Agriculture. 2022; 12(8):1280. https://doi.org/10.3390/agriculture12081280
Chicago/Turabian StyleLiu, Sicong, Qingcheng Fan, Shanghao Liu, and Chunjiang Zhao. 2022. "DepthFormer: A High-Resolution Depth-Wise Transformer for Animal Pose Estimation" Agriculture 12, no. 8: 1280. https://doi.org/10.3390/agriculture12081280
APA StyleLiu, S., Fan, Q., Liu, S., & Zhao, C. (2022). DepthFormer: A High-Resolution Depth-Wise Transformer for Animal Pose Estimation. Agriculture, 12(8), 1280. https://doi.org/10.3390/agriculture12081280