
Embedded Field Stalk Detection Algorithm for Digging–Pulling Cassava Harvester Intelligent Clamping and Pulling Device


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Production
2.1.1. Image Acquisition
2.1.2. Data Pre-Processing
2.2. Classical Model
2.2.1. YOLOv4
2.2.2. Evaluation Metrics
- (1)
- Precision, Recall, and Average Precision (AP)
- (2)
- Detection rate FPS
2.3. Proposed Model
2.3.1. Anchor Box Clustering Analysis Based on the K-Means Algorithm
2.3.2. Multi-Scale Scaling
2.3.3. Network Lightweighting
2.4. Training Platform and Environment
2.5. Training Strategy
2.5.1. Training Strategy for K-Means Clustering
2.5.2. Training Strategy for Lightweight Networks
2.6. Ablation Study and Comparison Test
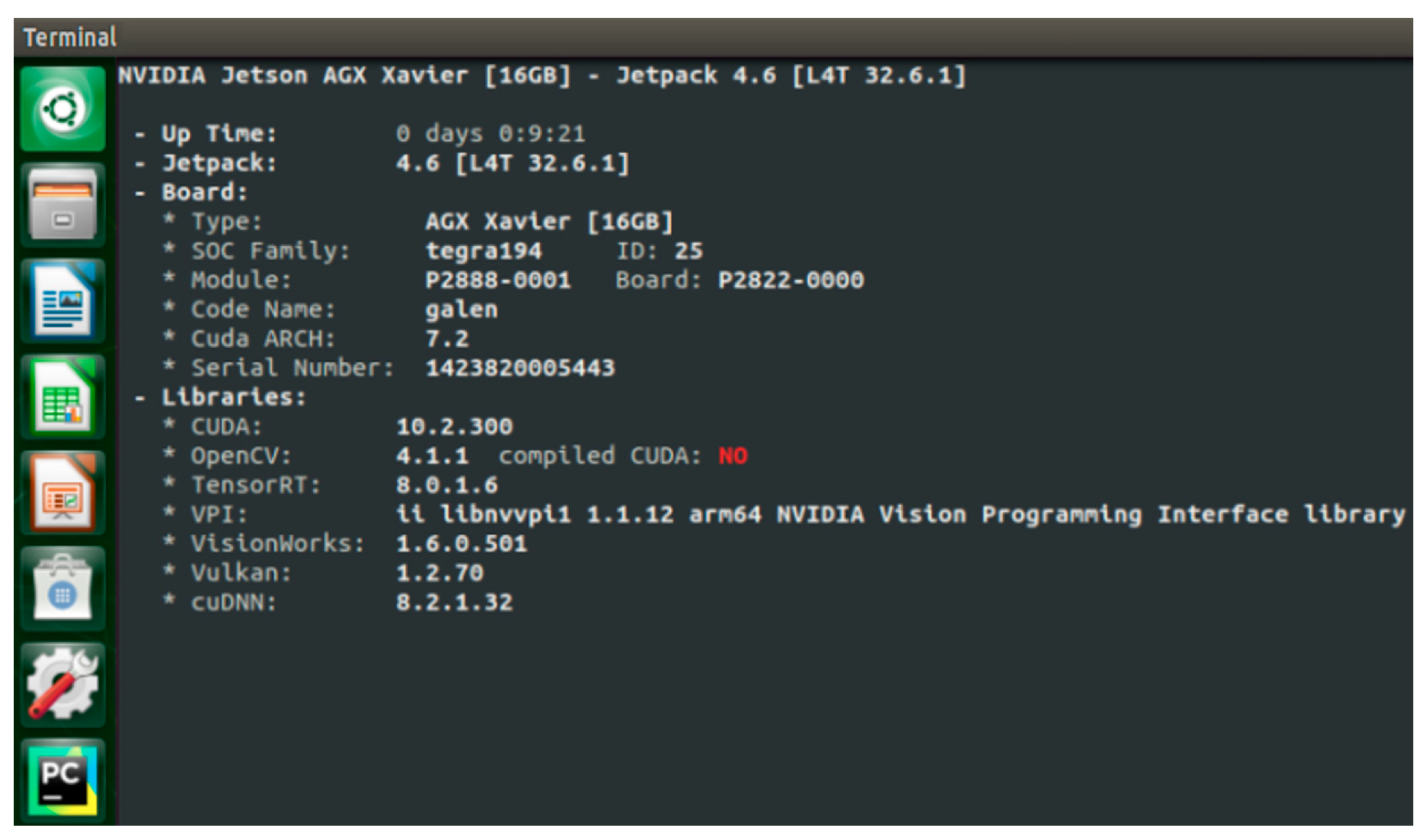
2.7. Model Deployment
3. Experiment Results and Discussion
3.1. Analysis of Training Results
3.1.1. Representation of Multi-Scale Anchor Boxes
3.1.2. Representation of Improved Network
3.1.3. Validation of the Network Model
Analysis of KMC-YOLO Test Results
Results and Analysis of Ablation Studies and Comparison Tests
3.2. Field Validation Trials
4. Conclusions
- (1)
- For the lightweight design of the YOLOv4 model, the KMC-YOLO network was constructed by incorporating the MobileNetV2 + CA module. The AP of the model was tested to be 98.2%, with detection speeds of 33.6 fps and model size reductions of 53.08%. The KMC-YOLO network is suitable for deployment on the Xavier development board.
- (2)
- By deploying the KMC-YOLO network on the NVIDIA Jetson AGX Xavier with TensorRT acceleration, the detection speed of the network on the development board increased to 39.3 fps, which is 83.64% higher than the non-accelerated speed, satisfying the requirement of real-time detection in the field.
- (3)
- The field test validation under different illumination conditions shows that the detection success rate of the model was above 95% under all illumination values tested, demonstrating that the algorithm met the detection requirements of the digging–pulling cassava harvester.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Brown, A.L.; Cavagnaro, T.R.; Gleadow, R.; Miller, R.E. Interactive effects of temperature and drought on cassava growth and toxicity: Implications for food security? Glob. Chang. Biol. 2016, 22, 3461–3473. [Google Scholar] [CrossRef] [PubMed]
- Parmar, A.; Sturm, B.; Hensel, O. Crops that feed the world: Production and improvement of cassava for food, feed, and industrial uses. Food Secur. 2017, 9, 907–927. [Google Scholar] [CrossRef]
- Li, C.; Dong, G.; Bian, M.; Liu, X.; Gong, J.; Hao, J.; Wang, W.; Li, K.; Ou, W.; Xia, T. Brewing rich2-phenylethanol beer from cassava and its producing metabolisms in yeast. J. Sci. Food Agric. 2021, 101, 4050–4058. [Google Scholar] [CrossRef] [PubMed]
- Amponsah, S.K.; Sheriff, J.T.; Byju, G. Comparative evaluation of manual cassava harvesting techniques in Kerala, India. Agric. Eng. Int. CIGR J. 2014, 16, 41–52. [Google Scholar]
- Yang, W.; Yang, J.; Zheng, X.T.; Jia, F.Y. Current Research and Development Trends of Cassava Root Harvest Machinery and Technology. J. Agric. Mech. Res. 2012, 34, 230–235. [Google Scholar]
- Xue, Z.; Huang, H.; Li, M.; Di, Z.F.; Gao, W.W.; Cui, Z.D. Study on 4UMS-390 II cassava harvester. J. Agric. Mech. Res. 2010, 32, 79–81. [Google Scholar]
- Bobobee, E.Y.H.; Yakanu, P.N.; Marenya, M.O.; Ochanda, J.P.O. Development in Ghana—Challenges, opportunities and prospects for cassava production in Africa. J. Eng. Agric. Environ. 2019, 5, 41–60. [Google Scholar]
- Ospina, B.; Cadavid, L.F.; Garcia, M.; Alcalde, C. Mechanization of cassava production in Colombia. In Cassava Research and Development in Asia; Centro Internactional de Agricultura Tropical: Bangkok, Thailand, 2002; pp. 277–287. [Google Scholar]
- Gupta, C.P.; Stevens, W.F.; Paul, S. Development of a vibrating cassava root harvester. Agric. Mech. Asia Afr. Lat. Am. 1999, 30, 51–55. [Google Scholar]
- Akhir, H.M.; Sukra, A.B. Mechanization possibilities for cassava production in Malaysia. In Cassava Research and Development in Asia: Exploring New Opportunities for an Ancient Crop, Proceedings of the 7th Asian Cassavaresearch Workshop, Bangkok, Thailand, 28 October—1 November 2002; International Center for Tropical Agriculture (CIAT): Bangkok, Thailand, 2002; pp. 271–276. [Google Scholar]
- Li, G.J.; Deng, G.R.; Wu, H.Z.; Zheng, S.; Cui, Z.D.; Huang, J. Design and experiment of 4UMZ—1400 rear-collected type cassava combined harvester. J. Chin. Agric. Mech. 2022, 43, 1–8. [Google Scholar]
- Mo, Q.G.; Huang, M.A. Development and application of 4UM-160 cassava harvester. Guang Xi Agric. Mech. 2012, 25, 20–22. [Google Scholar]
- Amponsah, S.K.; Addo, A.; Gangadharan, B. Review of various harvesting options for cassava. In Cassava; Waisundara, V.Y., Ed.; IntechOpen: London, UK, 2018; pp. 291–304. [Google Scholar]
- Liao, Y.L.; Sun, Y.P.; Liu, S.H.; Cheng, D.P.; Wang, G.P. Development and prototype trial of digging-pulling style cassava harvester. Trans. Chin. Soc. Agric. Eng. 2012, 28, 29–35. [Google Scholar]
- Yang, W.; Yang, R.; Li, J.; Wei, L.; Yang, J. Optimized tuber-lifting velocity model for cassava harvester design. Adv. Mech. Eng. 2018, 10, 2072049174. [Google Scholar] [CrossRef]
- Zheng, X. Virtual Design and Simulation for Pulling Speed Controlled Cassava Harvest Machine. Master’s Thesis, Guangxi University, Nanning, China, 2012. [Google Scholar]
- Park, Y.; Son, H.I. A Sensor Fusion-Based Cutting Device Attitude Control to Improve the Accuracy of Korean Cabbage Harvesting. J. ASABE 2022, 65, 1387–1396. [Google Scholar] [CrossRef]
- Montoya-Cavero, L.; Díaz De León Torres, R.; Gómez-Espinosa, A.; Escobedo Cabello, J.A. Vision systems for harvesting robots: Produce detection and localization. Comput. Electron. Agric. 2022, 192, 106562. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Song, Z.; Fu, L.; Wu, J.; Liu, Z.; Li, R.; Cui, Y. Kiwifruit detection in field images using Faster R-CNN with VGG16. IFAC-PapersOnLine 2019, 52, 76–81. [Google Scholar] [CrossRef]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Peng, H.X.; Huang, B.; Shao, Y.Y.; Li, Z.S.; Zhang, C.W.; Chen, Y.; Xiong, J.T. General improved SSD model for picking object recognition of multiple fruits in natural environment. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2018, 34, 155–162. [Google Scholar]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
- Quan, L.; Feng, H.; Lv, Y.; Wang, Q.; Zhang, C.; Liu, J.; Yuan, Z. Maize seedling detection under different growth stages and complex field environments based on an improved Faster R–CNN. Biosyst. Eng. 2019, 184, 1–23. [Google Scholar] [CrossRef]
- Junos, M.H.; Mohd Khairuddin, A.S.; Thannirmalai, S.; Dahari, M. Automatic detection of oil palm fruits from UAV images using an improved YOLO model. Vis. Comput. 2022, 38, 2341–2355. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J.; Chen, Y.; Yang, W.; Zhang, W.; He, Y. Real-time strawberry detection using deep neural networks on embedded system (rtsd-net): An edge AI application. Comput. Electron. Agric. 2022, 192, 106586. [Google Scholar] [CrossRef]
- Fu, L.; Yang, Z.; Wu, F.; Zou, X.; Lin, J.; Cao, Y.; Duan, J. Yolo-Banana: A lightweight neural network for rapid detection of banana bunches and stalks in the natural environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Wong, A.; Shafiee, M.J.; Li, F.; Chwyl, B. Tiny SSD: A tiny single-shot detection deep convolutional neural network for real-time embedded object detection. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8 May 2018; pp. 95–101. [Google Scholar]
- García-Santillán, I.D.; Montalvo, M.; Guerrero, J.M.; Pajares, G. Automatic detection of curved and straight crop rows from images in maize fields. Biosyst. Eng. 2017, 156, 61–79. [Google Scholar] [CrossRef]
- Marx, C.; Pastrana, J.C.; Hustedt, M.; Kaierle, S.; Walter, J.; Haferkamp, H.; Rath, T. Entwicklung und Aufbau eines Lasersystemprototyps auf Bildanalysebasis zur Unkrautbekämpfung. In Proceedings of the 17 und 18 Workshop Computer-Bildanalyse in der Landwirtschaft Computerised Image Analysis in Agriculture, Osnabrück, Germany, 9 May 2012; p. 102. [Google Scholar]
- Zhang, B.H.; Huang, W.Q.; Li, J.B.; Zhao, C.J.; Liu, C.L.; Huang, D.F. On-line Identification of Defect on Apples Using Lightness Correction and AdaBoost Methods. Trans. Chin. Soc. Agric. Mach. 2014, 45, 221–226. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Choi, J.; Chun, D.; Kim, H.; Lee, H. Gaussian YOLOv3: An accurate and fast object detector using localization uncertainty for autonomous driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019; pp. 502–511. [Google Scholar]
- Liang, R. Research and Application of Driverless Oriented Traffic Signal Detection and Recognition Method. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2021. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20 January 2021; pp. 13708–13717. [Google Scholar]
- Donahue, J.; Jia, Y.Q.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. Int. Conf. Mach. Learn. 2014, 32, 647–655. [Google Scholar]
- Song, G.H. Image Annotation Method Based on Transfer Learning and Deep Convolutional Feature. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2017. [Google Scholar]
- Burford, A.; Calder, A.C.; Carlson, D.; Chapman, B.; Coskun, F.; Curtis, T.; Feldman, C.; Harrison, R.J.; Kang, Y.; Michalow-Icz, B.; et al. Ookami: Deployment and initial experiences. In Practice and Experience in Advanced Research Computing; Cornell University Library: Ithaca, NY, USA, 2021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Carrier | Computing Platform | Camera/Lens |
|---|---|---|
| Lovol M504-E tractor | NVIDIA Jetson AGX Xavier | Alvium 1800 U-508M/ KOWA LM8JC5MC |
| Confusion Matrix | Predicted Position | Negative | |
|---|---|---|---|
| Actual | Positive | True Positive (TP) | True Negative (TN) |
| Negative | False Positive (FP) | False Negative (FN) | |
| Name | Versions |
|---|---|
| Operating System | Ubuntu18.04 |
| CPU | Inter Core (TM) i5-7500 CPU @ 3.40 GHz, RAM:8.00 GB |
| GPU | NVIDIA GeForce GTX 2060-Super, RAM:8.00 GB |
| Compiler Environment | Pycharm |
| OpenCv | 4.1.0.25 |
| PyTorch | 1.7.0 |
| Python | 3.8 |
| CUDA, CUDNN | 11.0, 8.05 |
| Receptive Field | COCO Anchors | IOU Anchors | CIOU Anchors |
|---|---|---|---|
| Large | (116 × 90), (156 × 198), (373 × 326) | (78 × 77), (72 × 72), (75 × 61) | (140 × 114), (124 × 124), (156 × 154) |
| Medium | (36 × 75), (76 × 55), (72 × 146) | (65 × 67), (62 × 61), (64 × 50) | (83 × 65), (72 × 71), (88 × 91) |
| Small | (12 × 16), (19 × 36), (40 × 28) | (53 × 43), (48 × 50), (55 × 55) | (26 × 21), (35 × 48), (36 × 36) |
| Anchors | mAP (%) |
|---|---|
| COCO anchors | 92% |
| IOU anchors | 93.5% |
| CIOU anchors | 95.6% |
| Network Model | Backbone | Precision/% | Model Size/M | Detection Speed under GPU/fps |
|---|---|---|---|---|
| K-YOLO | CSPDarknet53 | 95.6 | 245.3 | 19.23 |
| KM1-YOLO | MobileNetV1 | 91.2 | 51.1 | 30.7 |
| KM2-YOLO | MobileNetV2 | 93.1 | 113.2 | 33.4 |
| KM3-YOLO | MobileNetV3 | 94.8 | 114.2 | 28.5 |
| KM3-YOLO (small) | MobileNetV3-small | 94.0 | 110.6 | 34.5 |
| KMC-YOLO | MobileNetV2 + CA | 98.2 | 115.1 | 33.6 |
| YOLOv3-SPP | Darknet53 | 86.2 | 71.6 | 25.3 |
| YOLOv4-tiny | CSPDarknet53-tiny | 71.4 | 22.4 | 48.5 |
| YOLOX-tiny | CSPDarknet53-tiny | 86.43 | 19.4 | 48.6 |
| YOLOv5s | CSP + Focus | 89.5 | 14.8 | 52.4 |
| Faster R-CNN | ResNet50 + FPN | 84.6 | 137 | 18.5 |
| Weather | Environmental Temperature | Relative Humidity | Average Surface Soil Moisture Content | Cassava Variety |
|---|---|---|---|---|
| Sunny | 8–15 °C | 71% | 17.22% | GR891, Bread Cassava No.1 |
| Detection Time | Number of Stalks Tested | Number of Correct Detections | Number of Non-Detects | Number of Error Detection | Success Rate/% |
|---|---|---|---|---|---|
| Morning | 268 | 257 | 11 | 0 | 95.8 |
| Noon | 306 | 295 | 0 | 11 | 96.4 |
| Evening | 253 | 241 | 12 | 0 | 95.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Xi, J.; Wang, Z.; Lu, Z.; Zheng, X.; Zhang, D.; Huang, Y. Embedded Field Stalk Detection Algorithm for Digging–Pulling Cassava Harvester Intelligent Clamping and Pulling Device. Agriculture 2023, 13, 2144. https://doi.org/10.3390/agriculture13112144
Yang W, Xi J, Wang Z, Lu Z, Zheng X, Zhang D, Huang Y. Embedded Field Stalk Detection Algorithm for Digging–Pulling Cassava Harvester Intelligent Clamping and Pulling Device. Agriculture. 2023; 13(11):2144. https://doi.org/10.3390/agriculture13112144
Chicago/Turabian StyleYang, Wang, Junhui Xi, Zhihao Wang, Zhiheng Lu, Xian Zheng, Debang Zhang, and Yu Huang. 2023. "Embedded Field Stalk Detection Algorithm for Digging–Pulling Cassava Harvester Intelligent Clamping and Pulling Device" Agriculture 13, no. 11: 2144. https://doi.org/10.3390/agriculture13112144
APA StyleYang, W., Xi, J., Wang, Z., Lu, Z., Zheng, X., Zhang, D., & Huang, Y. (2023). Embedded Field Stalk Detection Algorithm for Digging–Pulling Cassava Harvester Intelligent Clamping and Pulling Device. Agriculture, 13(11), 2144. https://doi.org/10.3390/agriculture13112144