

Agricultural IoT Data Storage Optimization and Information Security Method Based on Blockchain

Abstract
:1. Introduction
- The Merkle tree is reconstructed, and a Merkle ordered tree is formulated to achieve ordered arrangement of leaf nodes.
- Transaction patterns are established, and a transaction batch writing method is proposed to optimize data read and write speeds.
- The block generation rules are modified, and a “one transaction, one block” storage strategy is proposed to improve the data storage performance.
2. Related Works
3. Materials and Methods
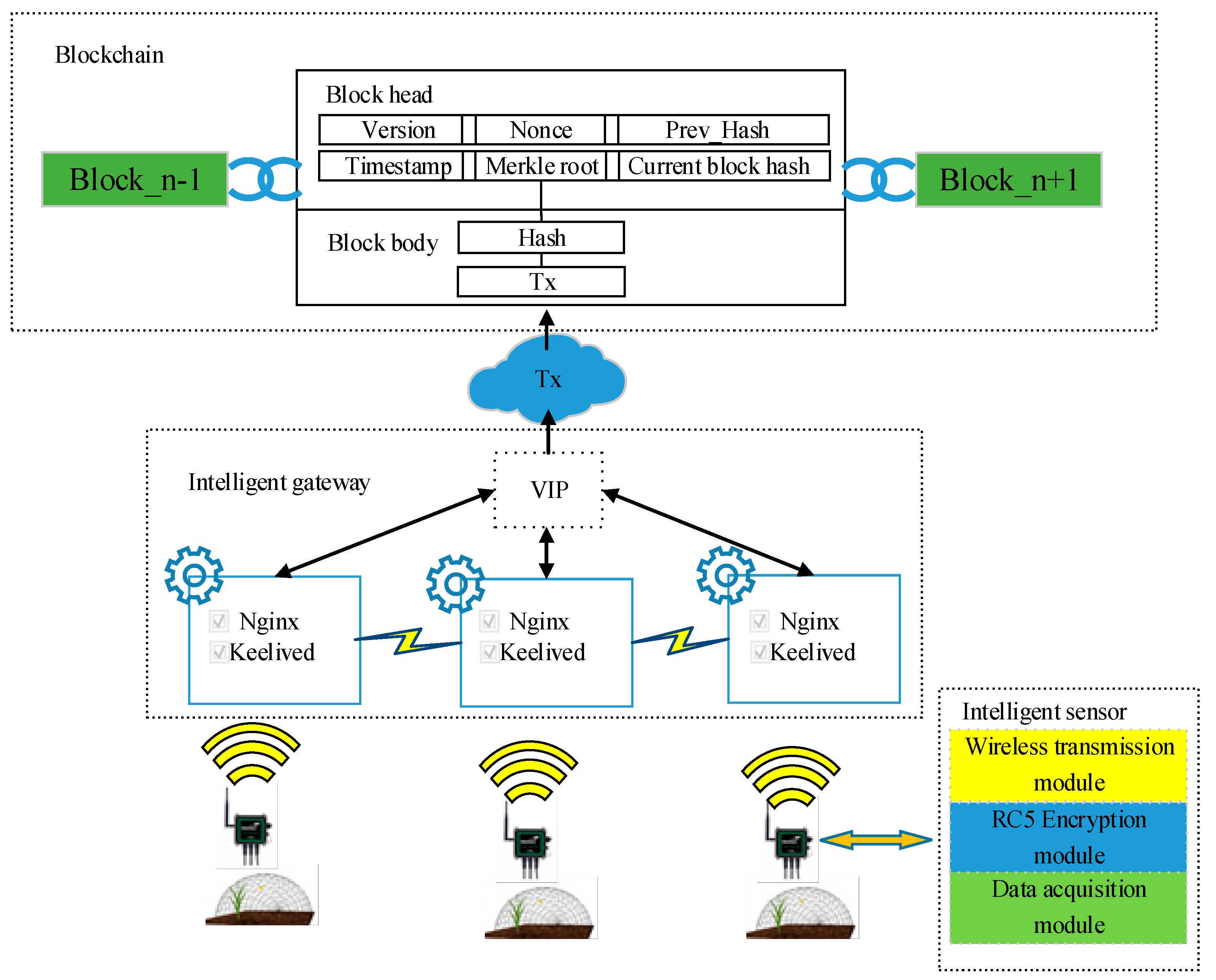
3.1. Framework Design
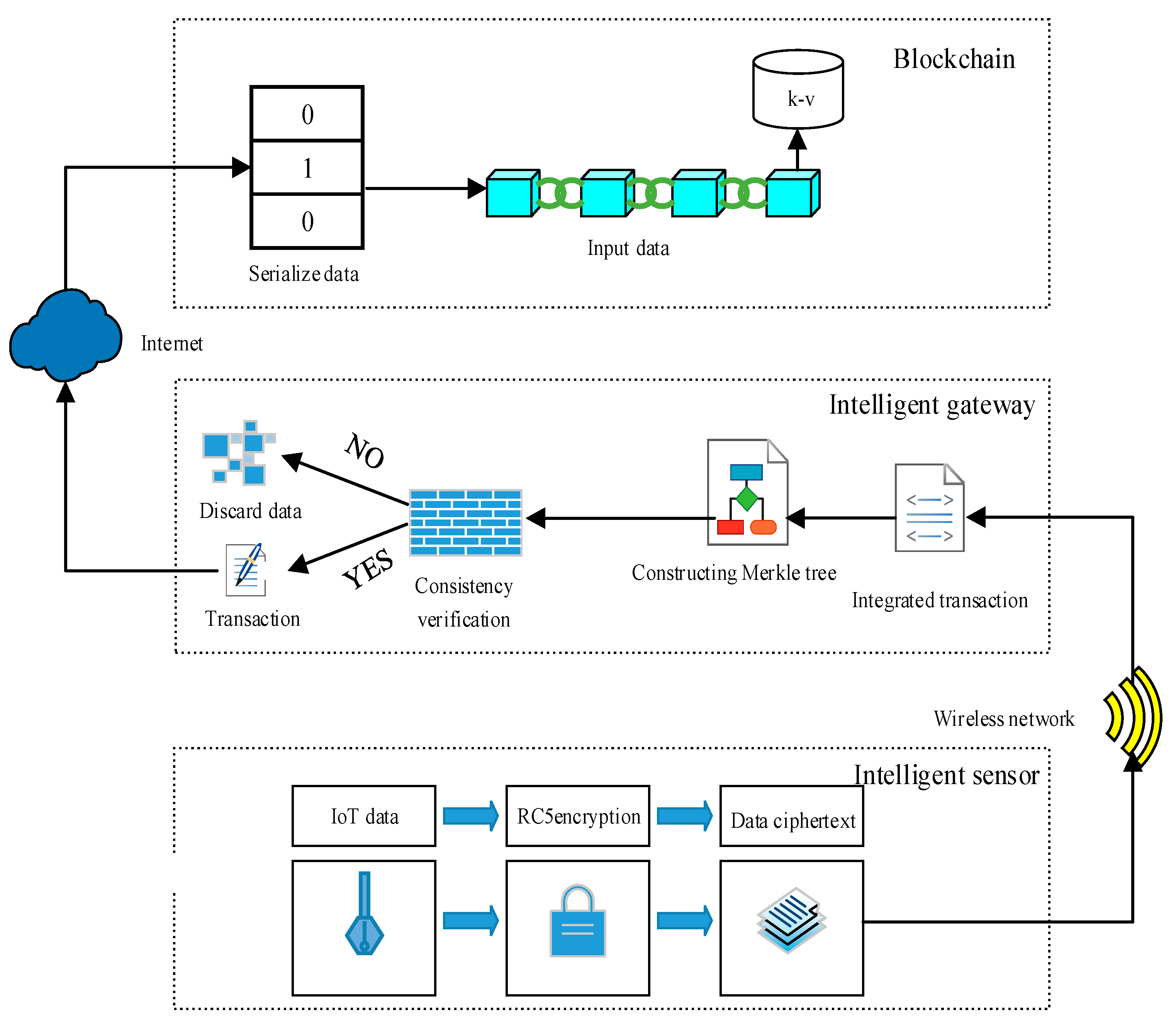
3.2. Data Processing
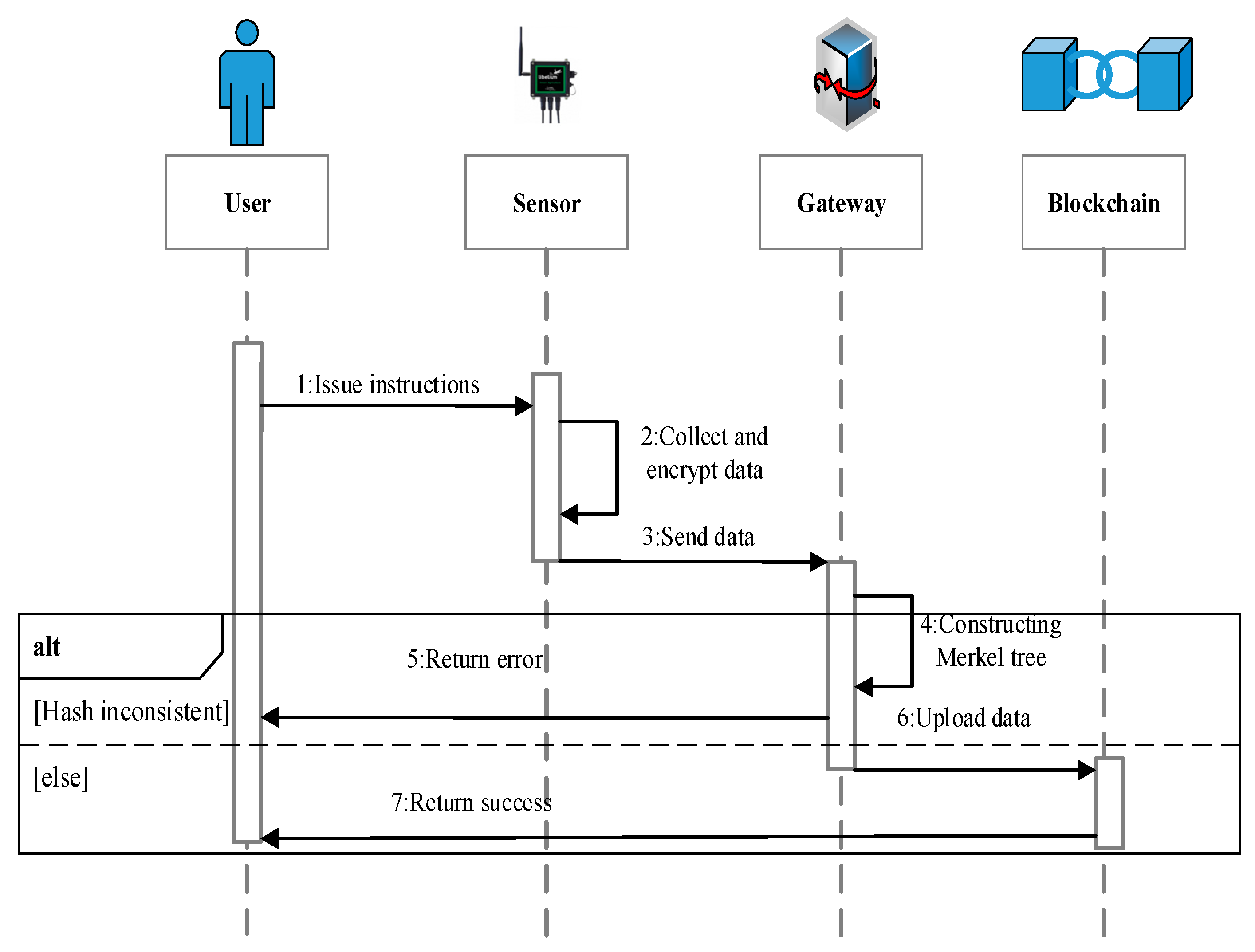
3.3. Data Interaction Process
3.4. Detailed System Design
3.4.1. Intelligent Sensor Module
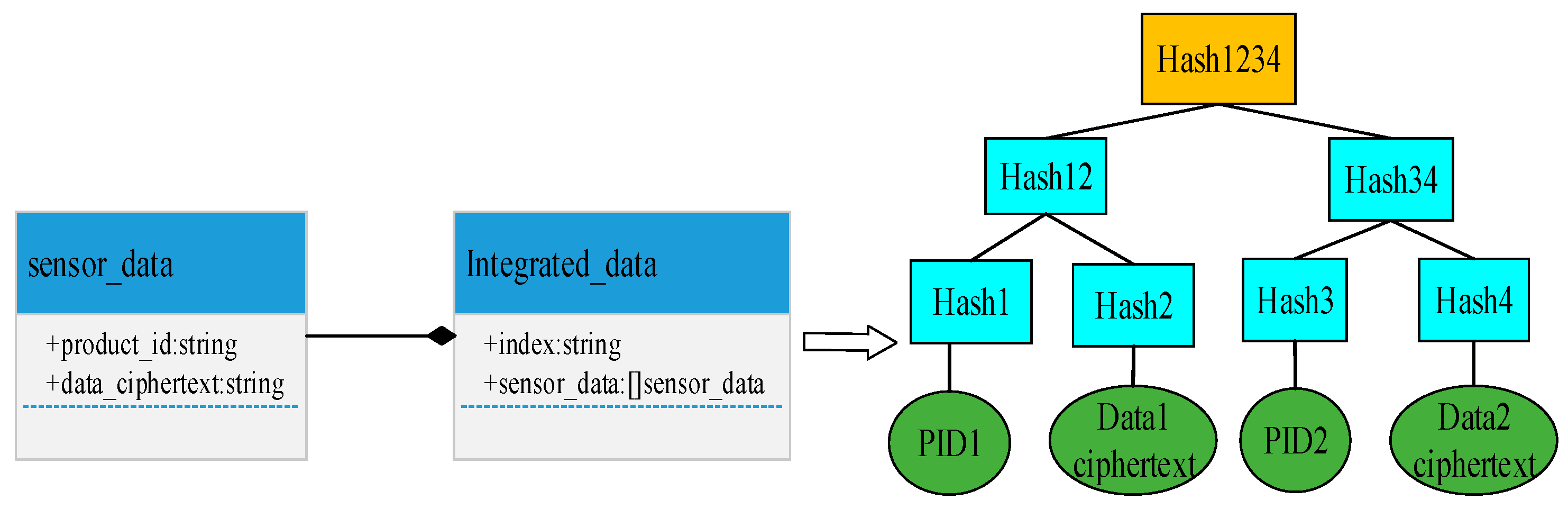
3.4.2. Merkle Ordered Tree
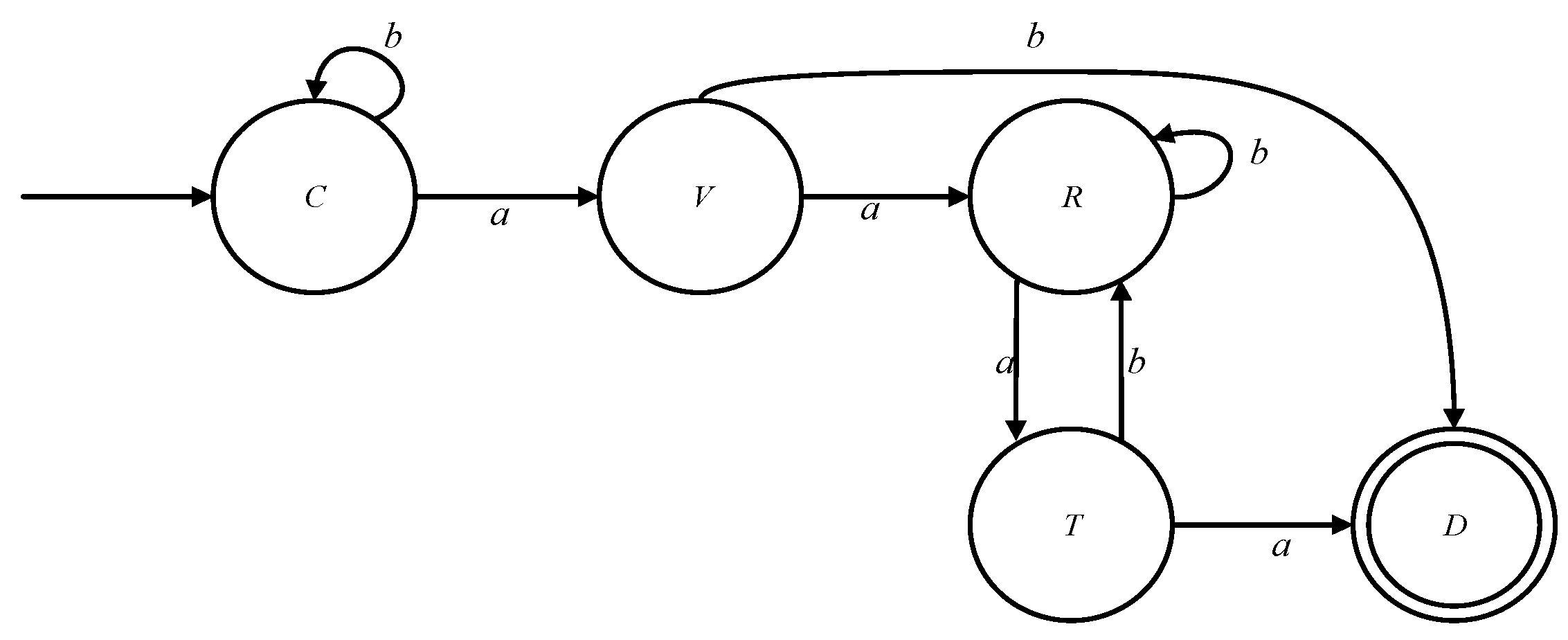
3.4.3. Finite State Machine Model of the Off-Chain Markel Tree
3.5. Algorithm Description
- Input plaintext A and B, the number of encryption rounds r, and w-bit circular key array S; perform the addition operation for A with the first key in S; perform the addition operation for B with the second key in S; and obtain the new A and B.
- Perform the following operations r times: perform bitwise xor for A and B; perform ring shift left by B bits for the obtained values; perform the addition operation for the processed results with the key whose subscript is twice that of the current cycle index in array S and eventually reassign it to A; process B the same as A, only change the ring shift left by A bits; the key of the addition operation is the value in the array S whose index is two times the number of cycles i plus 1.
- When the cycle ends, merge the obtained A and B, which are the two parts of the ciphertext, and obtain the final, complete ciphertext.
| Algorithm 1: RC5 Encryption |
| Input: A, B, r, S |
| Output: a, b |
| 1: A ← A+S [0]; |
| 2: B ← B+S[1]; |
| 3: for i=1 to r do |
| 4: A ←((A⊕B)<<<B) +S[2i]; |
| 5: B ←((B⊕A)<<<A) +S[2i+1]; |
| 6: i ←i+1; |
| 7: end for |
| 8: return a←A, b←B; |
- Hash the data in the leaf nodes to generate a hash value with a fixed length.
- Execute the hash merging algorithm operation circularly until the current hash node is unique.
- After the cycle ends, obtain the hash value, which is the Merkle root, and thus complete the Merkle tree generation.
| Algorithm 2: Generate Merkle tree |
| Input: IoTData |
| Output: rootHash |
| 1: dataHash ← Hash(IoTData); |
| 2: while dataHash.length ≠ 1 do |
| 3: dataHash ← getNewDataHash(dataHash); |
| 4: end while |
| 5: return rootHash ← dataHash[0]; |
- Set the array index, where the initial value is 0.
- Perform the following operations in the cycle continuously: take the hash value of the array corresponding to the current index as the left node, increase the index value by 1, assign the value of the right node to an empty string, and determine whether the current index is equal to the length of the current array; if not equal, take the hash value corresponding to the current index as the right node; afterwards, the hash values corresponding to the left and right nodes are connected in series, and the hash algorithm is adopted to generate a new hash and store it into the new hash array; then, increase the current index value by 1 and end this cycle.
- When the index value is not less than the length of the hash array, end the cycle, and the obtained new array hash is the result of the combination of the input array hashes.
| Algorithm 3: Get a new DataHash |
| Input: dataHash |
| Output: newDataHash |
| 1: index ← 0; |
| 2: while index < dataHash.length do |
| 3: left ← dataHash[index]; |
| 4: index ← index + 1; |
| 5: right ← 0; |
| 6: if index ≠ dataHash[index] then |
| 7: right ← dataHash.length; |
| 8: else |
| 9: continue; |
| 10: end if |
| 11: sha2HexValue ← getSHA2HexValue(right + left); |
| 12: newDataHash.add(sha2HexValue); |
| 13: index ← index + 1; |
| 14: end while |
| 15: return newDataHash; |
4. Results and Discussion
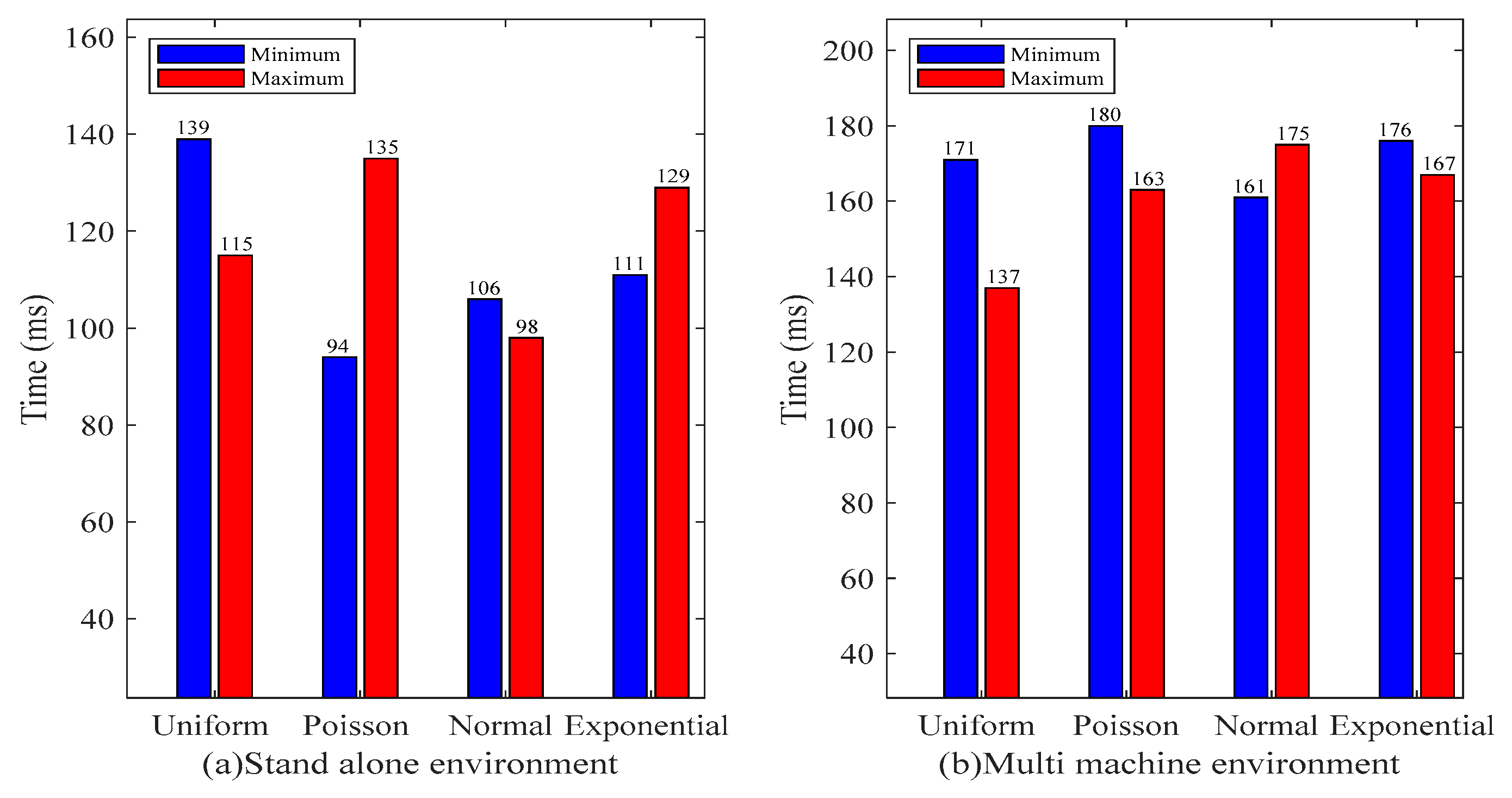
4.1. Experimental Environment
4.2. Data Sources
4.3. Experimental Scheme
4.4. Evaluation Method
4.5. Experiment Result
4.6. Security Analysis
- Confidentiality: the RC5 cryptographic module is loaded in the intelligent sensor to realize the confidentiality of the whole data process, from collection, transmission, and storage to reading.
- Integrity: the Merkle root of the collected data is calculated on multiple edge devices to ensure the integrity of data in the process of transmission, and the tamper-proof feature of the blockchain ensures the integrity of data in the process of data storage.
- Availability: using Hyperledger Fabric consortium blockchain architecture, any organization or node can only access the network if authorized by a CA, ensuring data availability.
- Controllability: data are not secure only when 51% or more of nodes in a blockchain are controlled. The more nodes in the network, the stronger the attack resistance. Generally, the system is under a legitimate user’s effective control.
- Non-repudiation: the traceable feature of blockchain ensures that every transaction is undeniable.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liao, Y.; Xu, K. Traceability system of agricultural product based on block-chain and application in tea quality safety management. J. Phys. Conf. Ser. 2019, 1288, 012062. [Google Scholar] [CrossRef]
- Salah, K.; Nizamuddin, N.; Jayaraman, R.; Omar, M. Blockchain-based soybean traceability in agricultural supply chain. IEEE Access 2019, 7, 73295–73305. [Google Scholar] [CrossRef]
- Neethirajan, S.; Kemp, B. Digital livestock farming. Sens. Bio-Sens. Res. 2021, 32, 100408. [Google Scholar] [CrossRef]
- Yang, X.; Shu, L.; Chen, J.; Ferrag, M.A.; Wu, J.; Nurellari, E.; Huang, K. A survey on smart agriculture: Development modes, technologies, and security and privacy challenges. IEEE/CAA J. Autom. Sin. 2021, 8, 273–302. [Google Scholar] [CrossRef]
- Farooq, M.S.; Riaz, S.; Abid, A.; Abid, K.; Naeem, M.A. A Survey on the Role of IoT in Agriculture for the Implementation of Smart Farming. IEEE Access 2019, 7, 156237–156271. [Google Scholar] [CrossRef]
- Li, Z.; Wang, J.; Higgs, R.; Zhou, L.; Yuan, W. Design of an Intelligent Management System for Agricultural Greenhouses Based on the Internet of Things. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; pp. 154–160. [Google Scholar]
- Navulur, S.; Prasad, M.G. Agricultural management through wireless sensors and internet of things. Int. J. Electr. Comput. Eng. 2017, 7, 3492. [Google Scholar] [CrossRef] [Green Version]
- Gao, D.; Sun, Q.; Hu, B.; Zhang, S. A framework for agricultural pest and disease monitoring based on internet-of-things and unmanned aerial vehicles. Sensors 2020, 20, 1487. [Google Scholar] [CrossRef] [Green Version]
- Gupta, M.; Abdelsalam, M.; Khorsandroo, S.; Mittal, S. Security and privacy in smart farming: Challenges and opportunities. IEEE Access 2020, 8, 34564–34584. [Google Scholar] [CrossRef]
- Yi, W.; Huang, X.; Yin, H.; Dai, S. Blockchain-based approach to achieve credible traceability of agricultural product transactions. J. Phys. Conf. Ser. 2021, 1864, 012115. [Google Scholar] [CrossRef]
- Li, Q.; Yi, W.; Zhao, X.; Zhao, Y.; Yin, H.; Xu, Y. Design and Evaluation of a High-Performance Support System for Credibility Tracing of Agricultural Products. In Proceedings of the 2021 IV International Conference on Control in Technical Systems (CTS), Saint Petersburg, Russia, 21–23 September 2021; pp. 15–18. [Google Scholar]
- Weber, I.; Lu, Q.; Tran, A.B.; Deshmukh, A.; Gorski, M.; Strazds, M. A Platform Architecture for Multi-Tenant Blockchain-Based Systems. In Proceedings of the 2019 IEEE International Conference on Software Architecture (ICSA), Hamburg, Germany, 25–29 March 2019; pp. 101–110. [Google Scholar]
- Yang, X.; Li, M.; Yu, H.; Wang, M.; Xu, D.; Sun, C. A trusted blockchain-based traceability system for fruit and vegetable agricultural products. IEEE Access 2021, 9, 36282–36293. [Google Scholar] [CrossRef]
- Xie, C.; Sun, Y.; Luo, H. Secured Data Storage Scheme Based on Block Chain for Agricultural Products Tracking. In Proceedings of the 2017 3rd International Conference on Big Data Computing and Communications (BIGCOM), Chengdu, China, 10–11 August 2017; pp. 45–50. [Google Scholar]
- Liu, Z.; Huang, W.; Wang, D. Functional agricultural monitoring data storage based on sustainable block chain technology. J. Cleaner Prod. 2021, 281, 124078. [Google Scholar]
- Fan, L.; Gil-Garcia, J.R.; Werthmuller, D.; Burke, G.B.; Hong, X. Investigating Blockchain as a Data Management Tool for IoT Devices in Smart City Initiatives. In Proceedings of the 19th Annual International Conference on Digital Government Research: Governance in the Data Age, Delft, Netherlands, 30 May–1 June 2018; pp. 1–2. [Google Scholar]
- Yánez, W.; Mahmud, R.; Bahsoon, R.; Zhang, Y.; Buyya, R. Data allocation mechanism for Internet-of-Things systems with blockchain. IEEE Internet Things J. 2020, 7, 3509–3522. [Google Scholar] [CrossRef]
- Li, R.; Song, T.; Mei, B.; Li, H.; Cheng, X.; Sun, L. Blockchain for large-scale internet of things data storage and protection. IEEE Trans. Serv. Comput. 2018, 12, 762–771. [Google Scholar] [CrossRef]
- Androutsellis-Theotokis, S.; Spinellis, D. A survey of peer-to-peer content distribution technologies. ACM Comput. Surv. (CSUR) 2004, 36, 335–371. [Google Scholar] [CrossRef] [Green Version]
- Benet, J. Ipfs-content addressed, versioned, p2p file system. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Zyskind, G.; Nathan, O. Decentralizing Privacy: Using Blockchain to Protect Personal Data. In Proceedings of the 2015 IEEE Security and Privacy Workshops, San Jose, CA, USA, 21–22 May 2015; pp. 180–184. [Google Scholar]
- Maymounkov, P.; Mazieres, D. Kademlia: A Peer-to-Peer Information System Based on the Xor metric. In International Workshop on Peer-to-Peer Systems; Springer: Berlin/Heidelberg, Germany, 2002; pp. 53–65. [Google Scholar]
- Ali, M. Trust-to-Trust Design of a New Internet. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2017. [Google Scholar]
- Liang, X.; Zhao, J.; Shetty, S.; Li, D. Towards Data Assurance and Resilience in IoT Using Blockchain. In Proceedings of the MILCOM 2017-2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 261–266. [Google Scholar]
- Kaneko, Y.; Asaka, T. DHT Clustering for Load Balancing Considering Blockchain Data Size. In Proceedings of the 2018 Sixth International Symposium on Computing and Networking Workshops (CANDARW), Takayama, Japan, 27–30 November 2018; pp. 71–74. [Google Scholar]
- Yoo, H.; Yim, J.; Kim, S. The Blockchain for Domain Based Static Sharding. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science And Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1689–1692. [Google Scholar]
- Chen, H.; Wang, Y. Sschain: A full sharding protocol for public blockchain without data migration overhead. Pervasive Mob. Comput. 2019, 59, 101055. [Google Scholar] [CrossRef]
- Kokoris-Kogias, E.; Jovanovic, P.; Gasser, L.; Gailly, N.; Syta, E.; Ford, B. Omniledger: A Secure, Scale-Out, Decentralized Ledger via Sharding. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 583–598. [Google Scholar]
- Francati, D.; Ateniese, G.; Faye, A.; Milazzo, A.M.; Perillo, A.M.; Schiatti, L.; Giordano, G. Audita: A Blockchain-Based Auditing Framework for Off-Chain Storage. In Proceedings of the Ninth International Workshop on Security in Blockchain and Cloud Computing, Hong Kong, China, 7 June 2021; pp. 5–10. [Google Scholar]
- Miyachi, K.; Mackey, T.K. hOCBS: A privacy-preserving blockchain framework for healthcare data leveraging an on-chain and off-chain system design. Inf. Process. Manag. 2021, 58, 102535. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, C.; Xu, J.; Pei, J. SlimChain: Scaling blockchain transactions through off-chain storage and parallel processing. Proc. VLDB Endow. 2021, 14, 2314–2326. [Google Scholar] [CrossRef]
- Miles, B.; Bourennane, E.-B.; Boucherkha, S.; Chikhi, S. A study of LoRaWAN protocol performance for IoT applications in smart agriculture. Comput. Commun. 2020, 164, 148–157. [Google Scholar] [CrossRef]
- Vellidis, G.; Tucker, M.; Perry, C.; Kvien, C.; Bednarz, C. A real-time wireless smart sensor array for scheduling irrigation. Comput. Electron. Agric. 2008, 61, 44–50. [Google Scholar] [CrossRef]
- Saini, H.; Bhushan, B.; Arora, A.; Kaur, A. Security vulnerabilities in Information communication technology: Blockchain to the rescue (A survey on Blockchain Technology). In Proceedings of the 2019 2nd International Conference on Intelligent Computing, Instrumentation and Control Technologies (ICICICT), Kannur, India, 5–6 July 2019; pp. 1680–1684. [Google Scholar]
- Shrestha, R.; Bajracharya, R.; Shrestha, A.P.; Nam, S.Y. A new type of blockchain for secure message exchange in VANET. Digit. Commun. Netw. 2020, 6, 177–186. [Google Scholar] [CrossRef]
- Rivest, R.L. The RC5 Encryption Algorithm. In International Workshop on Fast Software Encryption; Springer: Berlin/Heidelberg, Germany, 1994; pp. 86–96. [Google Scholar]
- Shahzadi, R.; Anwar, S.M.; Qamar, F.; Ali, M.; Rodrigues, J.J. Chaos based enhanced RC5 algorithm for security and integrity of clinical images in remote health monitoring. IEEE Access 2019, 7, 52858–52870. [Google Scholar] [CrossRef]
- Baliga, A.; Solanki, N.; Verekar, S.; Pednekar, A.; Kamat, P.; Chatterjee, S. Performance Characterization of Hyperledger Fabric. In Proceedings of the 2018 Crypto Valley Conference on Blockchain Technology (CVCBT), Zug, Switzerland, 20–22 June 2018; pp. 65–74. [Google Scholar]
- Sukhwani, H.; Wang, N.; Trivedi, K.S.; Rindos, A. Performance Modeling of Hyperledger Fabric (Permissioned Blockchain Network). In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018; pp. 1–8. [Google Scholar]
- Zhang, H.; Han, W.; Xu, K.; Zhang, Y.; Lu, Y.; Nie, Z.; Du, Y.; Zhu, J.; Huang, W. Metallic sandwiched-aerogel hybrids enabling flexible and stretchable intelligent sensor. Nano Lett. 2020, 20, 3449–3458. [Google Scholar] [CrossRef]
- Guerrero-Ibáñez, J.; Zeadally, S.; Contreras-Castillo, J. Sensor technologies for intelligent transportation systems. Sensors 2018, 18, 1212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khalaf, O.I.; Abdulsahib, G.M. Energy efficient routing and reliable data transmission protocol in WSN. Int. J. Advance Soft Compu. Appl. 2020, 12, 45–53. [Google Scholar]
- Xu, J.; Wei, L.; Zhang, Y.; Wang, A.; Zhou, F.; Gao, C.-Z. Dynamic fully homomorphic encryption-based merkle tree for lightweight streaming authenticated data structures. J. Netw. Comput. Appl. 2018, 107, 113–124. [Google Scholar] [CrossRef]
- Cachin, C. Architecture of the Hyperledger Blockchain Fabric. In Workshop on Distributed Cryptocurrencies and Consensus Ledgers; held in conjunction with ACM Symposium on Principles of Distributed Computing, PODC 2016; Chicago, IL, USA, 25-29 July 2016.
- Potdar, A.M.; Narayan, D.; Kengond, S.; Mulla, M.M. Performance evaluation of docker container and virtual machine. Procedia Comput. Sci. 2020, 171, 1419–1428. [Google Scholar] [CrossRef]
- Xu, X.; Sun, G.; Luo, L.; Cao, H.; Yu, H.; Vasilakos, A.V. Latency performance modeling and analysis for hyperledger fabric blockchain network. Inf. Process. Manag. 2021, 58, 102436. [Google Scholar] [CrossRef]
- Xu, Z.; Han, S.; Chen, L. CUB, a Consensus Unit-Based Storage Scheme for Blockchain System. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 173–184. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Storage Methods | Storage Mediums | Characteristics |
|---|---|---|---|
| [21] | Storage data hash on-chain | DHT | Good for data retrieval |
| [23] | Storage data hash on-chain | IPFS | Avoids data center-based management |
| [24] | Storage data hash on-chain | Cloud | Low storage pressure |
| [25,26,27,28] | Storage data on-chain | Blockchain | Data security independence |
| [29] | Storage nodes | Audita | Reliable data storage |
| [30] | On-chain and off-chain storage | hOCBS | Good data sharing |
| [31] | Off-chain storage nodes | SlimChain | Good system scalability |
| Experimental Environment | Experimental Platform | Consensus Algorithm | Number of Servers |
|---|---|---|---|
| Stand-alone environment | Hyperledger Fabric | Solo | 1 |
| Multi-machine environment | Hyperledger Fabric | Raft | 2 |
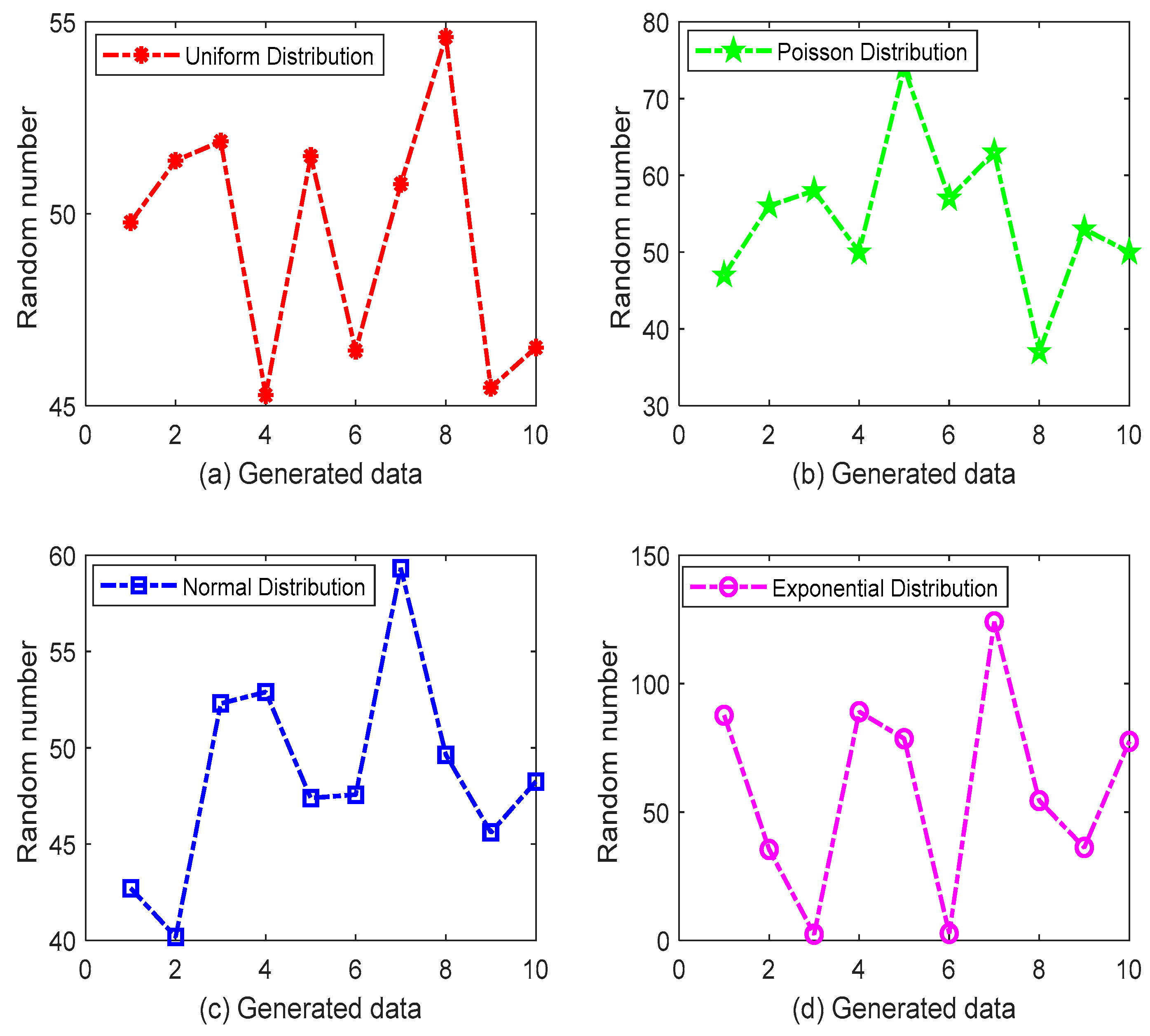
| Distribution Function | Expectation | Variance | Upper Limit | Lower Limit |
|---|---|---|---|---|
| Uniform | - | - | 55 | 45 |
| Poisson | 50 | - | - | - |
| Normal | 50 | 5 | - | - |
| Exponential | 50 | - | - | - |
| Experimental Scheme | Comparison | Number of Block Scheduled Transactions | Number of Transaction Concurrency | Number of Transaction Integration |
|---|---|---|---|---|
| Kokoris-Kogias et al. [28] | Stored data | 10 | 10 | 1 |
| Xu et al. [47] | Stored data hash | 10 | 10 | 1 |
| Authors’ method | Stored block data | 1 | 1 | 10 |
| Experimental Scheme | Number of Transactions | TPS for Data Writing | TPS for Data Query | Time of Data Writing | Time of Data Query |
|---|---|---|---|---|---|
| Traditional scheme | m | n | q | ||
| Authors’ method | m | n | q |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Li, Q.; Yi, W.; Xiong, H. Agricultural IoT Data Storage Optimization and Information Security Method Based on Blockchain. Agriculture 2023, 13, 274. https://doi.org/10.3390/agriculture13020274
Zhao Y, Li Q, Yi W, Xiong H. Agricultural IoT Data Storage Optimization and Information Security Method Based on Blockchain. Agriculture. 2023; 13(2):274. https://doi.org/10.3390/agriculture13020274
Chicago/Turabian StyleZhao, Yingding, Qiude Li, Wenlong Yi, and Huanliang Xiong. 2023. "Agricultural IoT Data Storage Optimization and Information Security Method Based on Blockchain" Agriculture 13, no. 2: 274. https://doi.org/10.3390/agriculture13020274
APA StyleZhao, Y., Li, Q., Yi, W., & Xiong, H. (2023). Agricultural IoT Data Storage Optimization and Information Security Method Based on Blockchain. Agriculture, 13(2), 274. https://doi.org/10.3390/agriculture13020274