
Prediction of Solid Soluble Content of Green Plum Based on Improved CatBoost



Abstract
:1. Introduction
2. Materials and Methods
2.1. Spectrum Data Collection
2.1.1. Sample Sources
2.1.2. Hardware Composition of Hyperspectral Acquisition Device
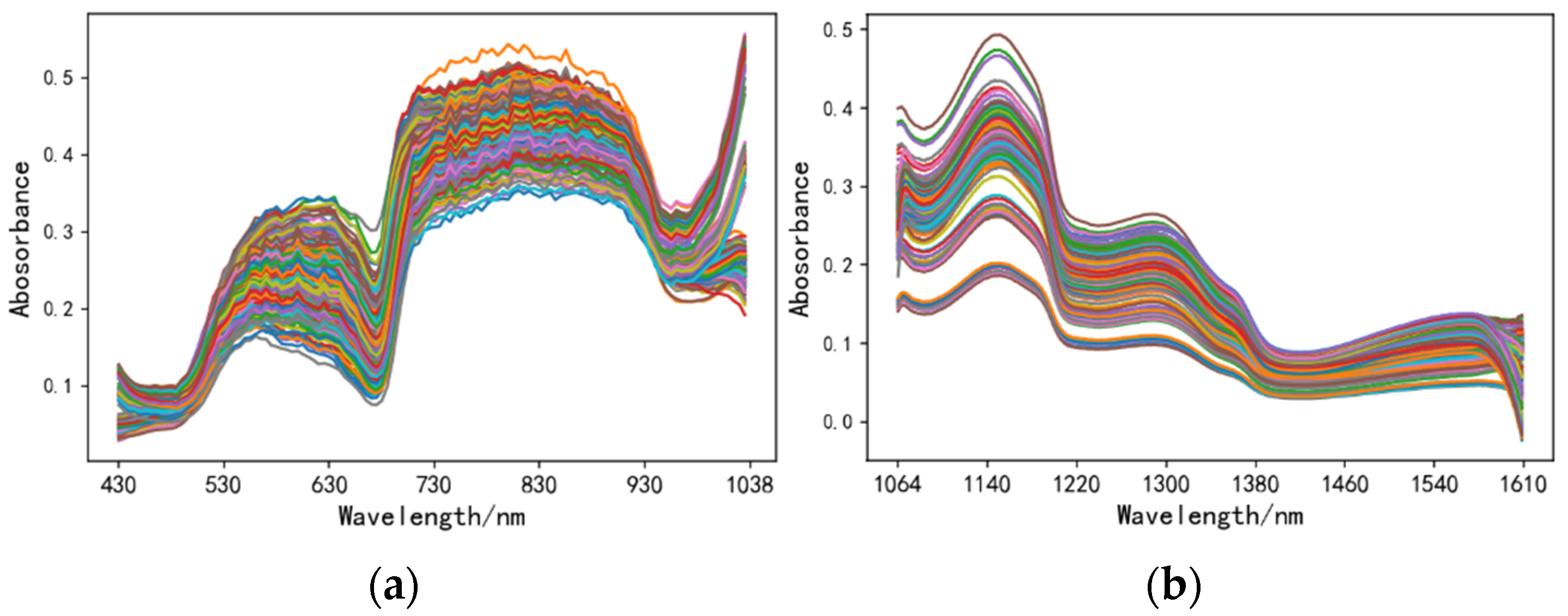
2.2. Preprocessing of Spectral Data
2.3. Improved Random Forest Feature Extraction Based on Induced Random Selection
- (1)
- Measure the importance of features
- (2)
- K-means clustering for feature classification
- (3)
- Proportional sampling
3. BO-CatBoost Model Based on Bayesian Optimization Algorithm
- (1)
- Initialize the Bayesian optimization algorithm point set and the maximum number of iterations N;
- (2)
- Based on the current set of points, build the Gaussian process proxy function;
- (3)
- Based on the proxy function, maximize the acquisition function to obtain the next evaluation point;
- (4)
- Obtain the evaluation point xt function value f(xt), add it to the evaluation point set;
- (5)
- Termination condition determination: if the number of iterations meets the default criteria, stop searching or return to step 2 for further search;
- (6)
- After iteration, obtain the optimal BO-CatBoost parameters, and use the optimal parameters to study and model the training data;
- (7)
- Finally, test the model with the test set, output the evaluation result.
4. Results and Discussion
4.1. Model Training and Result Analysis
4.1.1. Comparison of SSC Prediction Results with Different Pre-Processing Methods and Feature Extraction Combination Algorithms
4.1.2. Comparison of SSC Prediction Results of Different Machine Learning Regression Models
5. Conclusions
- (1)
- MSC + IRS-RF was used to preprocess the VIS-NIR spectral band and select the characteristic wavelength. The BO-CatBoost model based on Bayesian optimization algorithm outperformed PLSR, XGBoost, and CatBoost regression models in SSC prediction, with R2P of 0.957, which was 3.1% higher than the traditional PLSR.
- (2)
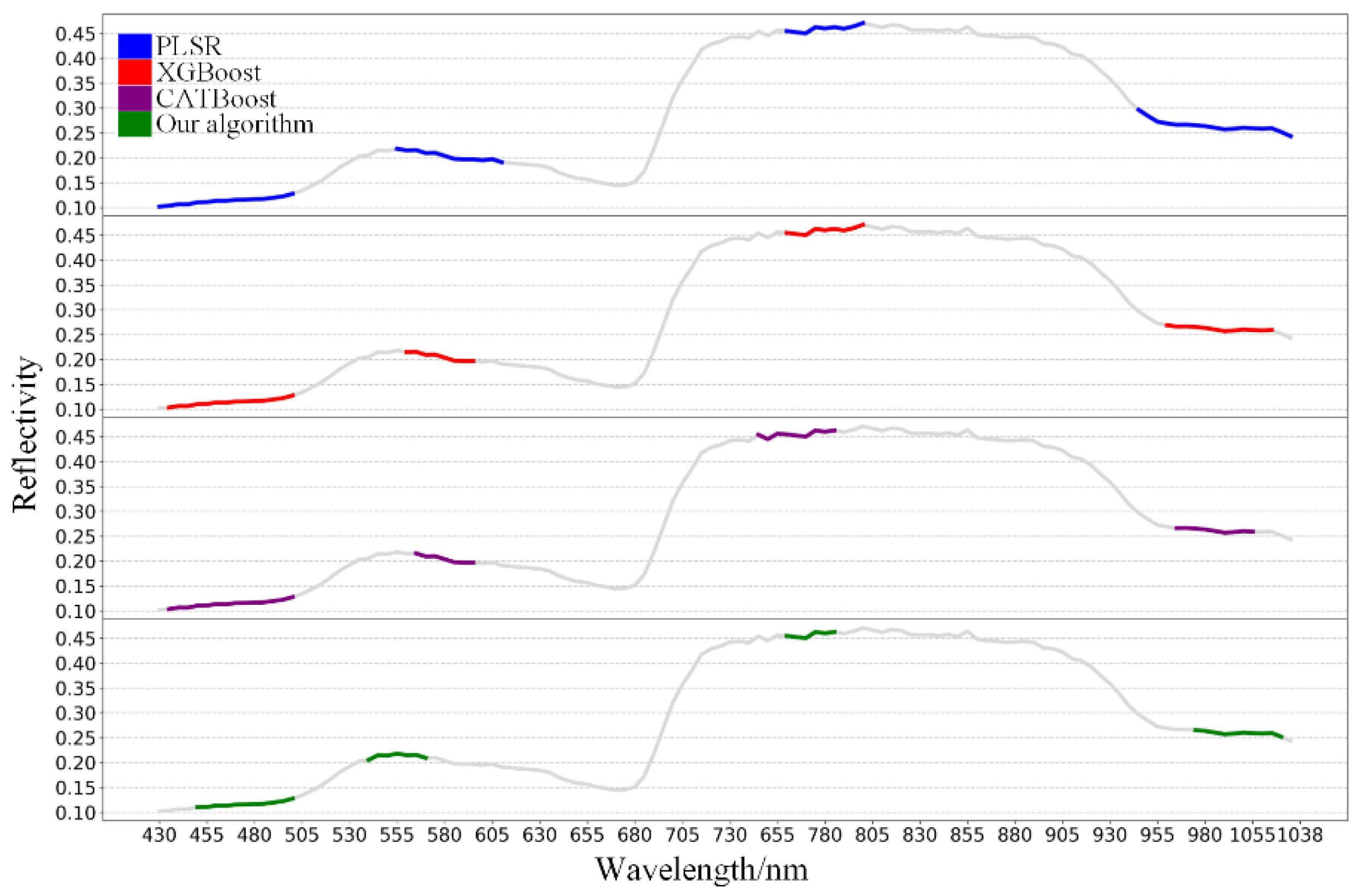
- Based on the MSC + IRS-RF + BO-CatBoost model proposed in this article, when predicting SSC values, the four selected feature band dimensions were the lowest, only 31, all less than PLSR, XGBoost, and CatBoost’s 53, 43, and 39. The selected band ranges were 452–498, 538–566, 756–782, and 982–1032.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, L.; Wang, S.; Tian, A.; Liu, T.; Benjakul, S.; Xiao, G.; Ying, X.; Zhang, Y.; Ma, L. Characteristic volatile compounds, fatty acids and minor bioactive components in oils from green plum seed by HS-GC-IMS, GC-MS and HPLC. Food Chem. X 2023, 17, 100530. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Ju, R.; Ma, F.; Qian, J.; Yan, J.; Li, S.; Li, Z. Moisture variation analysis of the green plum during the drying process based on low-field nuclear magnetic resonance. J. Food Sci. 2021, 86, 5137–5147. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Wang, H.; Liu, Y.; Liu, Y.; Zhang, X.; Fei, Y. Prediction of Soluble Solids Content in Green Plum by Using a Sparse Autoencoder. Appl. Sci. 2020, 10, 3769. [Google Scholar] [CrossRef]
- Saridaş, M.A.; Kafkas, E.; Zarifikhosroshahi, M.; Bozhaydar, O.; Kargi, S.P. Quality traits of green plums (Prunus cerasifera Ehrh.) at different maturity stages. Turk. J. Agric. For. 2016, 40, 655–663. [Google Scholar] [CrossRef]
- Luo, W.; Tappi, S.; Wang, C.; Yu, Y.; Zhu, S.; Rocculi, P. Study and optimization of high hydrostatic pressure (HHP) to improve mass transfer and quality characteristics of candied green plums (Prunus mume). J. Food Process. Preserv. 2018, 42, e13769. [Google Scholar] [CrossRef]
- Caporaso, N.; Whitworth, M.B.; Fisk, I.D. Protein content prediction in single wheat kernels using hyperspectral imaging. Food Chem. 2018, 240, 32–42. [Google Scholar] [CrossRef]
- Liu, Z.; He, Y.; Cen, H.; Lu, R. Deep feature representation with stacked sparse auto-encoder and convolutional neural network for hyperspectral imaging-based detection of cucumber defects. Trans. Asabe 2018, 61, 425–436. [Google Scholar] [CrossRef]
- Fan, Y.; Zhang, C.; Liu, Z.; Qiu, Z.; He, Y. Cost-sensitive stacked sparse auto-encoder models to detect striped stem borer infestation on rice based on hyperspectral imaging. Knowl. Based Syst. 2019, 168, 49–58. [Google Scholar] [CrossRef]
- Satorres Martinez, S.; Martinez Gila, D.; Beyaz, A.; Gomez Ortega, J.; Gamez Garcia, J. A computer vision approach based on endocarp features for the identification of olive cultivars. Comput. Electron. Agric. 2018, 154, 341–346. [Google Scholar] [CrossRef]
- Xie, C.; Zhu, H.Y.; Fei, Y.Q. Deep coordinate attention network for single image super-resolution. Iet Image Process. 2022, 16, 273–284. [Google Scholar] [CrossRef]
- Ma, T.; Xia, Y.; Inagaki, T.; Tsuchikawa, S. Rapid and nondestructive evaluation of soluble solids content (SSC) and firmness in apple using Vis-NIR spatially resolved spectroscopy. Postharvest Biol. Technol. 2020, 173, 111417. [Google Scholar] [CrossRef]
- Yu, X.; Lu, H.; Wu, D. Development of deep learning method for predicting firmness and soluble solid content of postharvest Korla fragrant pear using Vis-NIR hyperspectral reflectance imaging. Postharvest Biol. Technol. 2018, 141, 39–49. [Google Scholar] [CrossRef]
- Zhang, C.; Shi, Y.; Wei, Z.; Wang, R.; Li, T.; Wang, Y.; Zhao, X.; Gu, X. Hyperspectral estimation of the soluble solid content of intact netted melons decomposed by continuous wavelet transform. Front. Phys. 2022, 10, 1034982. [Google Scholar] [CrossRef]
- Saha, D.; Senthilkumar, T.; Sharma, S.; Singh, C.B.; Manickavasagan, A. Application of near-infrared hyperspectral imaging coupled with chemometrics for rapid and non-destructive prediction of protein content in single chickpea seed. J. Food Compos. Anal. 2023, 115, 104938. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Liu, W.; Yang, J.; Chen, Y.; Zheng, L. Non-destructive detection of dicyandiamide in infant formula powder using multi-spectral imaging coupled with chemometrics. J. Sci. Food Agric. 2017, 97, 2094–2099. [Google Scholar] [CrossRef] [PubMed]
- Younas, S.; Liu, C.; Qu, H.; Mao, Y.; Liu, W.; Wei, L.; Yan, L.; Zheng, L. Multispectral imaging for predicting the water status in mushroom during hot-air dehydration. J. Food Sci. 2020, 85, 903–909. [Google Scholar] [CrossRef]
- Chakravartula, S.S.N.; Cevoli, C.; Balestra, F.; Fabbri, A.; Dalla Rosa, M. Evaluation of drying of edible coating on bread using NIR spectroscopy. J. Food Eng. 2019, 240, 29–37. [Google Scholar] [CrossRef]
- Beskopylny, A.N.; Stel’makh, S.A.; Shcherban, E.M.; Mailyan, L.R.; Meskhi, B.; Razveeva, I.; Chernil’nik, A.; Beskopylny, N. Concrete strength prediction using machine learning methods CatBoost, k-Nearest Neighbors, Support Vector Regression. Appl. Sci. 2022, 12, 10864. [Google Scholar] [CrossRef]
- Ogar, V.; Hussain, S.; Gamage, K. Transmission line fault classification of multi-dataset using CatBoost classifier. Signals 2022, 3, 468–482. [Google Scholar] [CrossRef]
- Guadagno, C.R.; Millar, D.; Lai, R.; Mackay, D.S.; Pleban, J.R.; McClung, C.R.; Weinig, C.; Wang, D.R.; Ewers, B.E. Use of transcriptomic data to inform biophysical models via Bayesian networks. Ecol. Model. 2020, 429, 109086. [Google Scholar] [CrossRef]
- Sandra, M.; Jose, M.A.; José, B.; Sergio, C.; Pau, T.; Nuria, A. Ripeness monitoring of two cultivars of nectarine using VIS-NIR hyperspectral reflectance imaging. J. Food Eng. 2017, 214, 29–39. [Google Scholar]
- Yang, Y.; Huang, W.; Zhao, C.; Tian, X.; Fan, S.; Wang, Q.; Li, J. Online soluble solids content (SSC) assessment of multi-variety tomatoes using Vis/NIRS diffuse transmission. Infrared Phys. Technol. 2022, 125, 104312. [Google Scholar] [CrossRef]
- Zhang, D.; Yang, Y.; Chen, G.; Tian, X.; Wang, Z.; Fan, S.; Xin, Z. Nondestructive evaluation of soluble solids content in tomato with different stage by using Vis/NIR technology and multivariate algorithms. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 248, 119139. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Set | Number of Samples | Minimum Value | Maximum Value | Average Value |
|---|---|---|---|---|
| Training set | 221 | 5.8 | 13.1 | 9.7263 |
| Test set | 55 | 5.8 | 12.4 | 9.7033 |
| Name | Parameters |
|---|---|
| System | Windows 10 × 64 |
| CPU | Inter I9 [email protected] GHz |
| GPU | Nvidia GeForce RTX 2080 Ti (11 G) |
| Environment configuration | PyCharm + Pytorch 1.7.1 + Python 3.7.7 Cuda 10.2 + cudnn 7.6.5 + tensorboardX 2.1 |
| Bands | Preprocessing + Characteristic Wavelength Combination Algorithm | RMSEC | MAEC | R2C | RMSEP | MAEP | R2P |
|---|---|---|---|---|---|---|---|
| VIS-NIR Spectral Band | MSC + CCM | 0.401 | 0.323 | 0.909 | 0.420 | 0.339 | 0.901 |
| MSC + SPA | 0.369 | 0.305 | 0.925 | 0.378 | 0.316 | 0.920 | |
| MSC + CARS | 0.605 | 0.479 | 0.827 | 0.614 | 0.490 | 0.814 | |
| MSC + RF | 0.418 | 0.321 | 0.918 | 0.428 | 0.327 | 0.914 | |
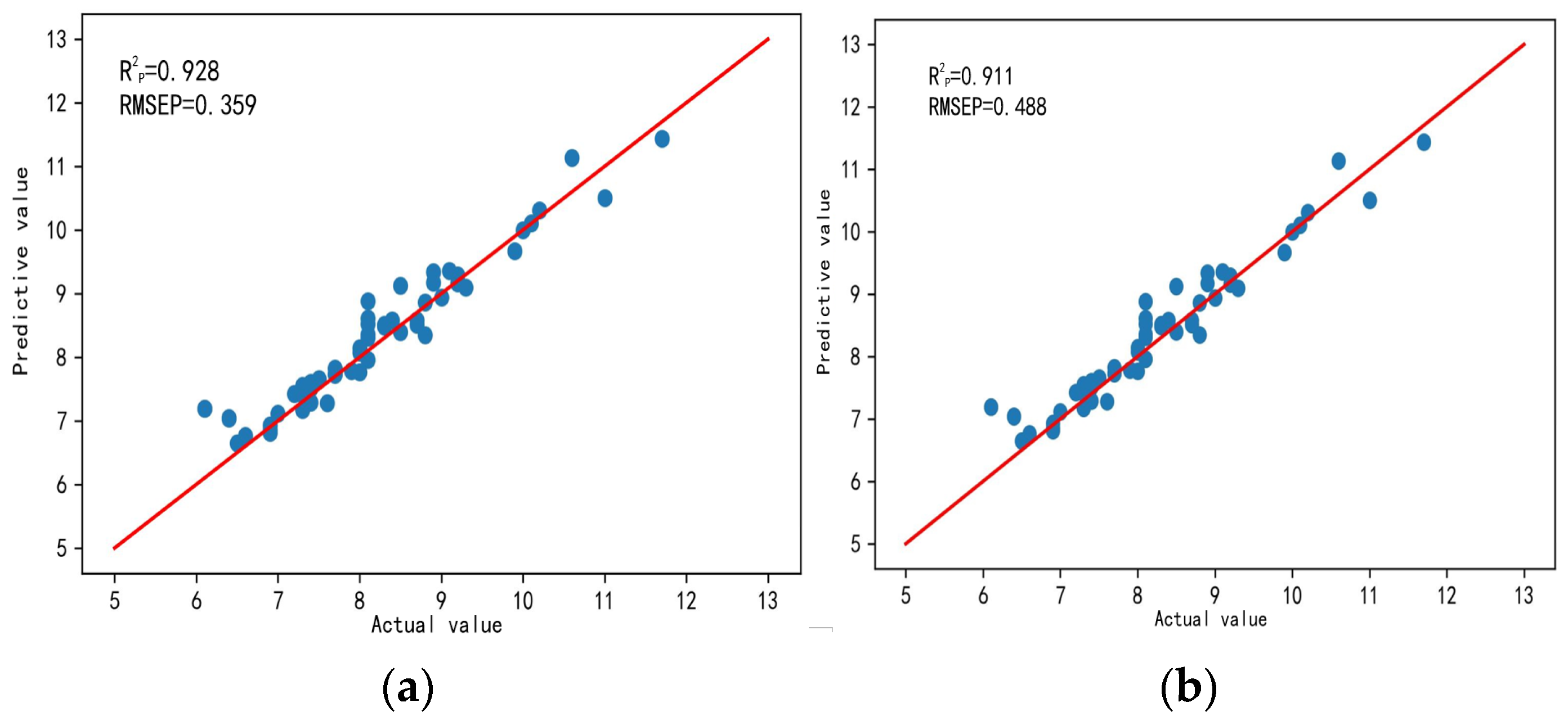
| MSC + our algorithm | 0.341 | 0.255 | 0.933 | 0.359 | 0.261 | 0.928 | |
| S–G + CCM | 0.376 | 0.276 | 0.912 | 0.380 | 0.288 | 0.902 | |
| S–G + SPA | 0.391 | 0.303 | 0.894 | 0.405 | 0.319 | 0.889 | |
| S–G + CARS | 0.614 | 0.465 | 0.738 | 0.639 | 0.475 | 0.723 | |
| S–G + RF | 0.607 | 0.447 | 0.759 | 0.611 | 0.458 | 0.747 | |
| S–G + our algorithm | 0.456 | 0.258 | 0.916 | 0.467 | 0.268 | 0.905 | |
| SW-NIR Spectral Band | MSC + CCM | 0.562 | 0.451 | 0.839 | 0.572 | 0.455 | 0.827 |
| MSC + SPA | 0.531 | 0.408 | 0.871 | 0.543 | 0.423 | 0.851 | |
| MSC + CARS | 0.752 | 0.599 | 0.798 | 0.786 | 0.615 | 0.785 | |
| MSC + RF | 0.661 | 0.402 | 0.822 | 0.670 | 0.410 | 0.805 | |
| MSC + our algorithm | 0.473 | 0.257 | 0.925 | 0.488 | 0.266 | 0.911 | |
| S–G + CCM | 0.637 | 0.461 | 0.732 | 0.649 | 0.480 | 0.715 | |
| S–G + SPA | 0.457 | 0.321 | 0.873 | 0.462 | 0.334 | 0.855 | |
| S–G + CARS | 0.552 | 0.359 | 0.790 | 0.569 | 0.371 | 0.781 | |
| S–G + RF | 0.718 | 0.525 | 0.652 | 0.738 | 0.544 | 0.631 | |
| S–G + our algorithm | 0.490 | 0.301 | 0.903 | 0.495 | 0.304 | 0.892 |
| Algorithms | Bands | Characteristic Band Group Wavelength (nm) | Dimension | RMSEP | MAEP | R2P | |||
|---|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | ||||||
| CCM | VIS-NIR Spectral Band | 430–488 | 636–666 | 702–925 | 968–1038 | 79 | 0.420 | 0.339 | 0.901 |
| SPA | 440–524 | 596–646 | 707–846 | 957–1038 | 74 | 0.378 | 0.316 | 0.920 | |
| CARS | 450–542 | 596–646 | 707–867 | 957–1038 | 80 | 0.614 | 0.490 | 0.814 | |
| RF | 430–483 | 631–656 | 707–925 | 973–1038 | 75 | 0.428 | 0.327 | 0.914 | |
| Ours | 430–498 | 552–608 | 756–798 | 952–1038 | 53 | 0.359 | 0.261 | 0.928 | |
| CCM | SW-NIR Spectral Band | 1167–1239 | 1253–1358 | 1489–1573 | 1601–1610 | 159 | 0.572 | 0.455 | 0.827 |
| SPA | 1066–1150 | 1165–1333 | 1367–1467 | 1518–1568 | 236 | 0.543 | 0.423 | 0.851 | |
| CARS | 1068–1149 | 1159–1353 | 1363–1476 | 1576–1610 | 248 | 0.786 | 0.615 | 0.785 | |
| RF | 1024–1150 | 1164–1350 | 1507–1568 | 1591–1610 | 231 | 0.670 | 0.410 | 0.805 | |
| Ours | 1182–1226 | 1281–1345 | 1526–1573 | 1595–1610 | 100 | 0.488 | 0.266 | 0.911 | |
| Regression Model | Characteristic Band Group Wavelength (nm) | Dimension | RMSEP | MAEP | R2P | |||
|---|---|---|---|---|---|---|---|---|
| Group 1 | Group 2 | Group 3 | Group 4 | |||||
| PLSR | 430–498 | 552–608 | 756–798 | 952–1038 | 53 | 0.359 | 0.261 | 0.928 |
| XGBoost | 432–498 | 556–592 | 756–798 | 966–1028 | 43 | 0.403 | 0.191 | 0.927 |
| CatBoost | 432–498 | 562–592 | 742–786 | 972–1018 | 39 | 0.365 | 0.231 | 0.942 |
| Ours | 452–498 | 538–566 | 756–782 | 982–1032 | 31 | 0.252 | 0.189 | 0.957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhou, C.; Sun, Q.; Liu, Y.; Yang, Y.; Zhuang, Z. Prediction of Solid Soluble Content of Green Plum Based on Improved CatBoost. Agriculture 2023, 13, 1122. https://doi.org/10.3390/agriculture13061122
Zhang X, Zhou C, Sun Q, Liu Y, Yang Y, Zhuang Z. Prediction of Solid Soluble Content of Green Plum Based on Improved CatBoost. Agriculture. 2023; 13(6):1122. https://doi.org/10.3390/agriculture13061122
Chicago/Turabian StyleZhang, Xiao, Chenxin Zhou, Qi Sun, Ying Liu, Yutu Yang, and Zilong Zhuang. 2023. "Prediction of Solid Soluble Content of Green Plum Based on Improved CatBoost" Agriculture 13, no. 6: 1122. https://doi.org/10.3390/agriculture13061122
APA StyleZhang, X., Zhou, C., Sun, Q., Liu, Y., Yang, Y., & Zhuang, Z. (2023). Prediction of Solid Soluble Content of Green Plum Based on Improved CatBoost. Agriculture, 13(6), 1122. https://doi.org/10.3390/agriculture13061122