1. Introduction
The arable industry is a small sector within the New Zealand farming system, primarily aimed at supplying the domestic requirements for cereals used in the milling, brewing and animal feed industries, and herbage seed production [
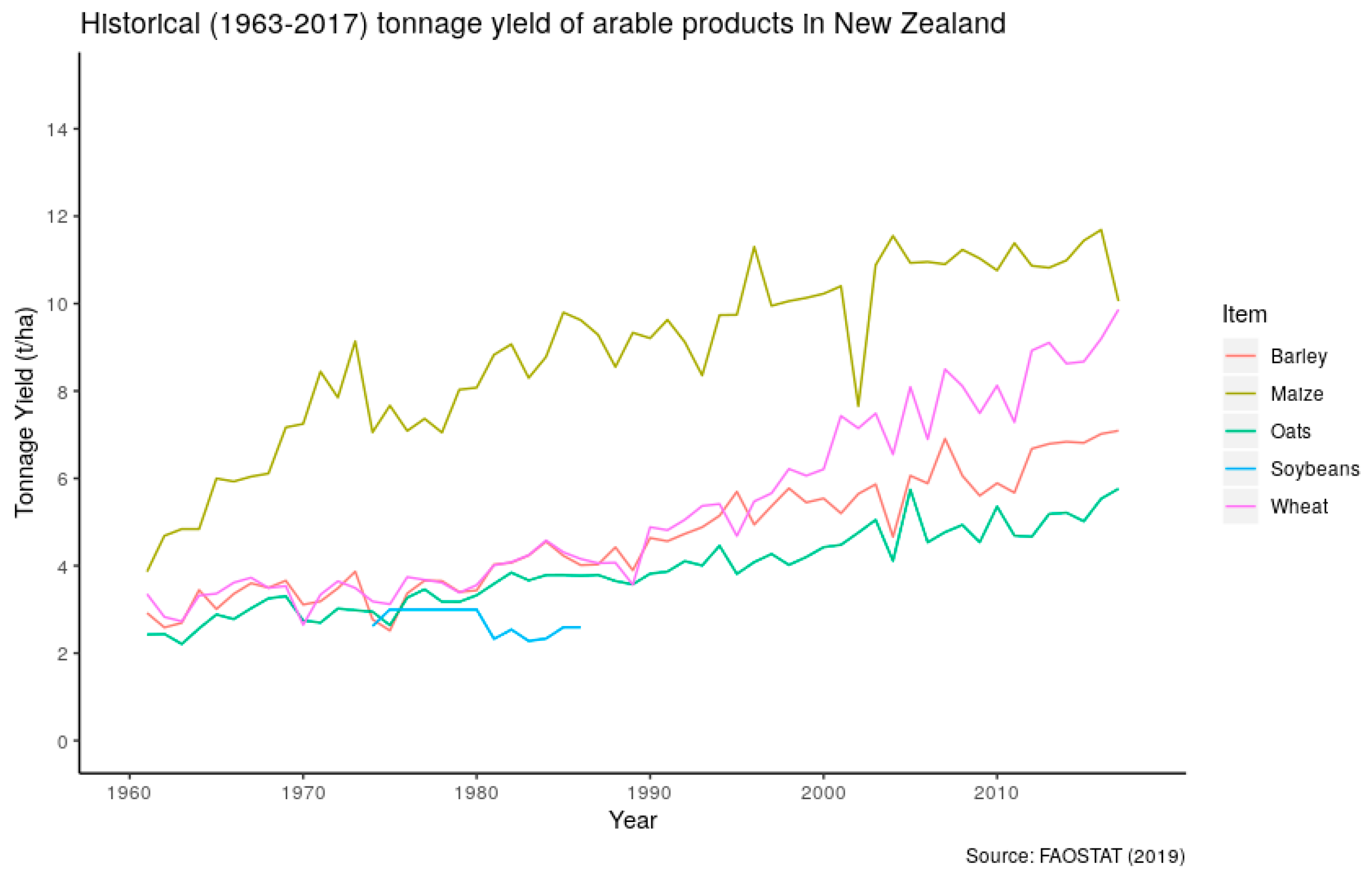
1]. Maize is a major arable crop grown in New Zealand, producing grain for human or animal consumption, as well as silage as supplementary feed to livestock. It also tends to produce higher yields per hectare compared to other arable products such as wheat and barley, as seen in
Figure 1. The Foundation for Arable Research (FAR) is the research organization for the arable sector. This research is funded by FAR, as they are looking for a way to utilize the historical data from precision farming technologies such as combine yield monitors and soil EC sensors to inform crop management decisions such as variable rate seeding and nitrogen applications.
The practice of precision farming in the New Zealand (NZ) arable sector began in the early 1990s. Since then, there has been wide-scale uptake of precision farming tools such as guidance systems and variable-rate irrigation. However, the commercial uptake of variable rate application (VRA) (which has the potential to improve farming efficiency) has been limited due to the lack of available information to estimate yield response [
2].
With the increasing availability of regularly captured spatial data and publicly-available satellite imagery and climatic records, there is potential to use this information to inform farm management decisions. However, appropriate spatial analysis techniques are still limited for this type of application. Progress has been made on delineating potential management zones (MZs) within-paddocks to represent similar yield-limiting factors based on a variety of spatial information (e.g., historical yield data, geo-referenced aerial photographs, soil and topography features) using spatial classification techniques [
2,
3,
4]. From this, a different rate of an input (e.g., fertilizer, seeding rate) can be applied to each MZ. However, it is difficult to quantify spatial yield and temporal variability without understanding yield potential and crop response to specific variables (e.g., climate, soil type, management practices) [
5,
6].
Other studies have attempted to use statistical modelling techniques to understand the relationship between crop yield potential and measured soil and site parameters using large, spatial, multivariate datasets. Correlation and other linear techniques (e.g., multiple linear regression [MLR] models) have been used in many previous studies to explore the relationship between crop or soil properties and the data derived from precision farming tools [
7,
8,
9]. It can also provide insight into the linkages between precision farming data and crop yield spatial variability [
5,
10,
11]. However, linear regression models assume that the relationships between the dependent and independent variables are linear. More accurate results have been reported with more complex machine learning techniques such as artificial neural networks on predicting crop yields [
5,
10,
12].
Liu, et al. [
13] used a feed-forward, back-propagation neural network (BPNN) model for predicting maize yield based on soil factors (e.g., soil pH, phosphorus, potassium, organic matter), management factors (nitrogen fertilizer), and monthly rainfall as inputs in their BPNN. The BPNN was able to model the interaction between rainfall and the rate of applied nitrogen fertilizer. It also predicted maize yields with 80% accuracy. Drummond, et al. [
10] used three different algorithms (stepwise MLR, projection pursuit regression, BPNN) for predicting maize and soybean yield, with a number of soil fertility/topography variables (e.g., soil phosphorus, magnesium, potassium, pH, organic matter, topsoil depth). However, the back-propagation neural networks are computationally expensive and time consuming for handling large datasets. However, intensive soil testing is expensive. In cropping situations in New Zealand grid sampling is rarely undertaken at points less than one value per hectare.
The Cubist regression model is primarily used in remote sensing studies for handling large datasets [
14,
15]. Cubist is a rule-based decision tree algorithm, modified from Ross Quinlan’s M5 model tree [
16,
17] and introduced to the R statistical software by Max Kuhn in the R development group [
18]. As distinct from other types of regression trees such as the Classification and Regression Trees (CART) program (where values are predicted at their leaves), the Cubist model produces a set of rules (“if-then” statements) and each rule contains multivariate linear regression models at the terminal leaves. A specific set of predictor variables will then choose an actual prediction model based on the rule that best fits the predictors [
18,
19]. Promising results have been reported when predicting continuous variables [
14,
15].
This paper aims to examine the use of statistical modelling techniques on precision farming data for estimating within-paddock maize-grain yield potential. The aspects looked into are:
The uses of precision farming data including yield monitor data, spatial yield data, seeding density, high-precision elevation and soil EC;
The uses of multispectral satellite imagery (NASA’s Landsat-8 and Sentinel-2 ESA’s missions) in crop management at the sub-paddock scale;
The uses of statistical modelling techniques (stepwise MLR, Cubist regression and a feed-forward neural network) to predict within-paddock maize-grain yield potential;
Agronomic interpretation and management implications.
The modelling output could be embedded into a GIS software program as a decision-making tool. It is hypothesized that such a modelling approach can help farmers modify crop management practices to maximize yield and minimize costs. Once the functional relationship between within-paddock yield potential and complementary variables is established, it should be possible to provide a more accurate management prescription to be uploaded to a variable-rate implement (e.g., liquid fertilizer applicator), enabling variable rates of an input (e.g., nitrogen fertilizer) to be applied automatically across the paddock based on the “input-response” function. This work suggests an approach which may be taken to develop within field crop management statistical algorithms.
4. Discussion
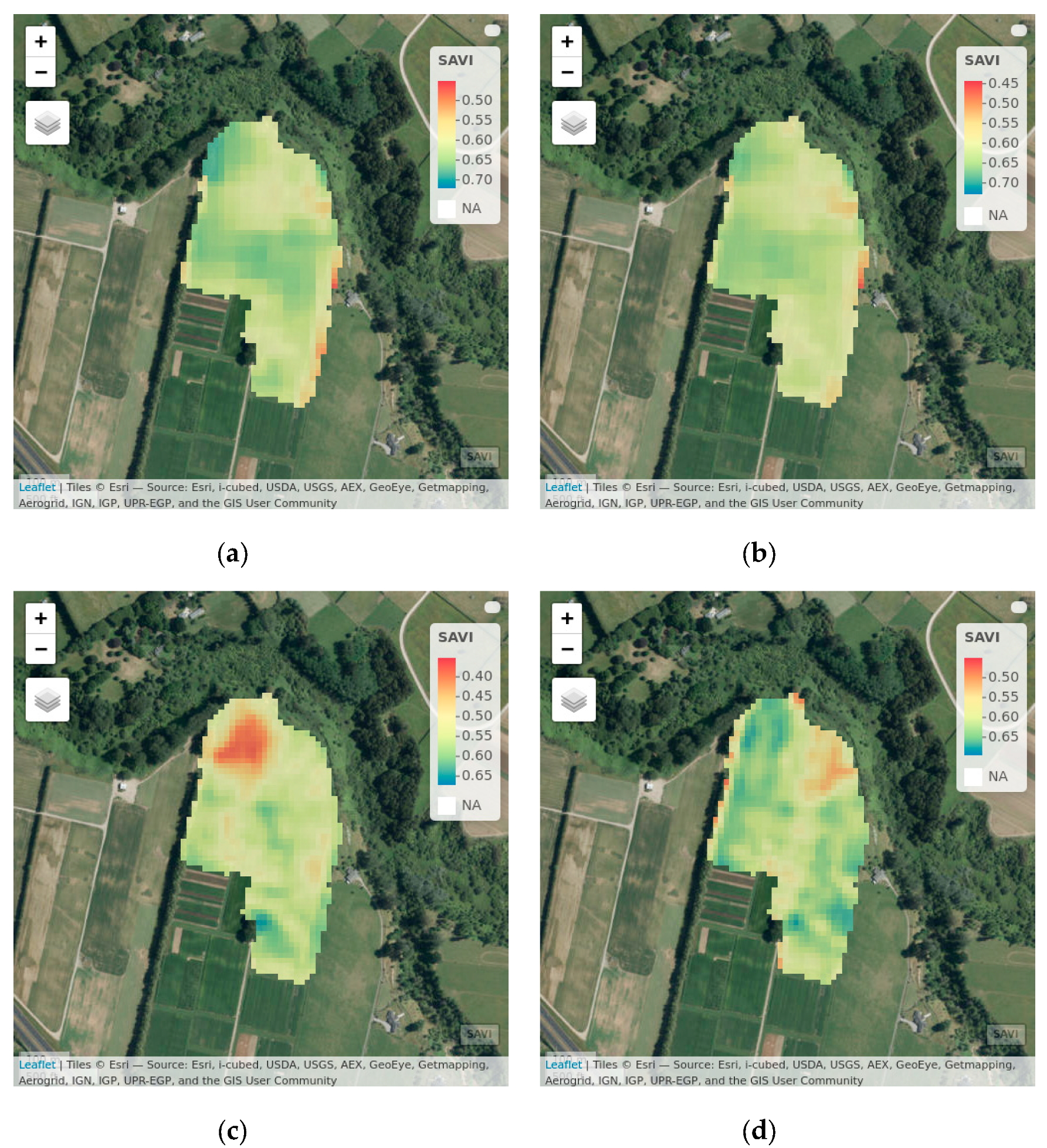
The SAVI images captured in February were the most influential predictor in the MLR models for both sites in this limited data capture, producing the highest estimated coefficient (2.628 for site 1 and 3.998 for site 2, respectively). This supports Chang, et al. [
50]. Their study estimated the maize yield variability for two 65-ha fields using multispectral and multi-date reflectance data measured by a digital camera mounted on an airplane and the IKONOS satellite. MLR and principal component regression were used. The models were able to explain 40%–60% of the yield variations. The methods used would also rank other factors such as meteorological data when moisture deficit is evident with some soil textures. The results from this study suggest the crop reflectance data can be used for mapping spatial maize yield variability in paddock before harvest. In our study, however, we were unable to acquire consistent multi-date data from the Landsat-8 and Sentinel-2 satellites at each growth stage for crop management in New Zealand due to cloud coverage at the point of capturing the images. The crop growth can be influenced by environmental conditions (e.g., the weather pattern of years, planting time, and time of the first onset), which makes it difficult to model yield if satellite images are not available for different growing stages. However, if a particular date in a particular year when the onset of grain filling is known (often shortly after max leaf area and beginning of senescence), an image can be obtained using a UAV (unmanned aerial vehicle) around this time frame to provide a good indication of final grain yield. This is also the point when decisions can be made to scout pests and diseases from the UAV image, and then apply patch spraying to improve yield or quality.
Soil organic matter (OM) was the second most influential predictor in the MLR models for site 1. Soil OM provides nutrients and habitat to micro-organisms living in the soil. It also binds soil particles into aggregates and improves the water holding capacity of the soil [
51]. Our model suggested that a 1% increase in soil OM may result in a 1.72 t/ha increase in maize-grain yield for the site.
The average temperature (1–14 September) had a significant positive influence on maize-grain yield for site 1. Temperature and solar radiation are key factors that determine the potential production of maize. Maize has a base temperature (the minimum temperature a plant requires to assimilate carbon dioxide through photosynthesis) range from 8–10 °C. Maize is ideally sown in early to mid-October in the northern North Island region of New Zealand once the soil temperature has increased to above 10°C [
31]. A warmer soil temperature in spring is favorable for seed germination and seedling emergence. Our model suggested that an increase of 1 degree Celsius in the average temperature from September 1 may increase yield by 1.18 t/ha. With information on the soil temperature in September, the model may inform the optimal seeding rate to apply.
Soil EC deep has a positive influence on yield. For site 1, Soil EC shallow was highly correlated with soil EC deep (
r = 0.9) and was removed due to multicollinearity. A higher soil EC value often indicates finer textured soil and higher soil water holding capacity [
52]. Kitchen, et al. [
5] studied the relationship of soil EC and topographic features (elevation, slope and curvature) to grain yield for three contrasting soil-crop systems in the US. Their MLR models explained 1%-30% of the yield variation. The prediction was improved by adding the topographic features to the model. In our study, the correlations between soil EC/elevation and yield in the multiple years were very weak (
r = 0.1). This may be related to the spatial resolution (10 m) of the data. In the study by Kitchen, et al. [
5], kriging was applied to interpolate soil EC/elevation into 10-m grid, which reduced the variations and the size of the dataset to be modelled. Our study did not interpolate the spatial data because there were missing data points in different parts of the paddock from year to year. In the study by Blackmore, et al. [
53], they also noted that the results of spatial yield prediction may be related to the spatial resolution of the predictors, as coarse spatial points tended to lose details from the resulting maps.
For Site 1, elevation, accumulated rainfall (29 May–12 June), and the average temperature (31 October–14 November) have negative impacts on the yield. For Site 2, elevation and rainfall (14 May–29 May) have negative influences on yield (
Table 5). It was noted that the period of meteorological data such as rainfall and temperature may be too short (15 days) for studying their impacts on yield. However, there was no guideline on which interval to use, as different intervals were used previously such as a 15-day interval during the plant reproductive phase [
10], or a monthly interval [
13]. Elevation influences water movement and soil wetness potential in the paddock. Higher elevated soil may be more susceptible to nutrient runoff and erosion during rainfall events [
54,
55] and is likely to dry out earlier. The MLR model suggests that an increase of 1 m in elevation can cause a decrease of 1.04 t/ha in yield. There may also be other stronger influences (e.g., soil type) on the productivity. Based on our observation during a field visit in November, 2018 (as shown in
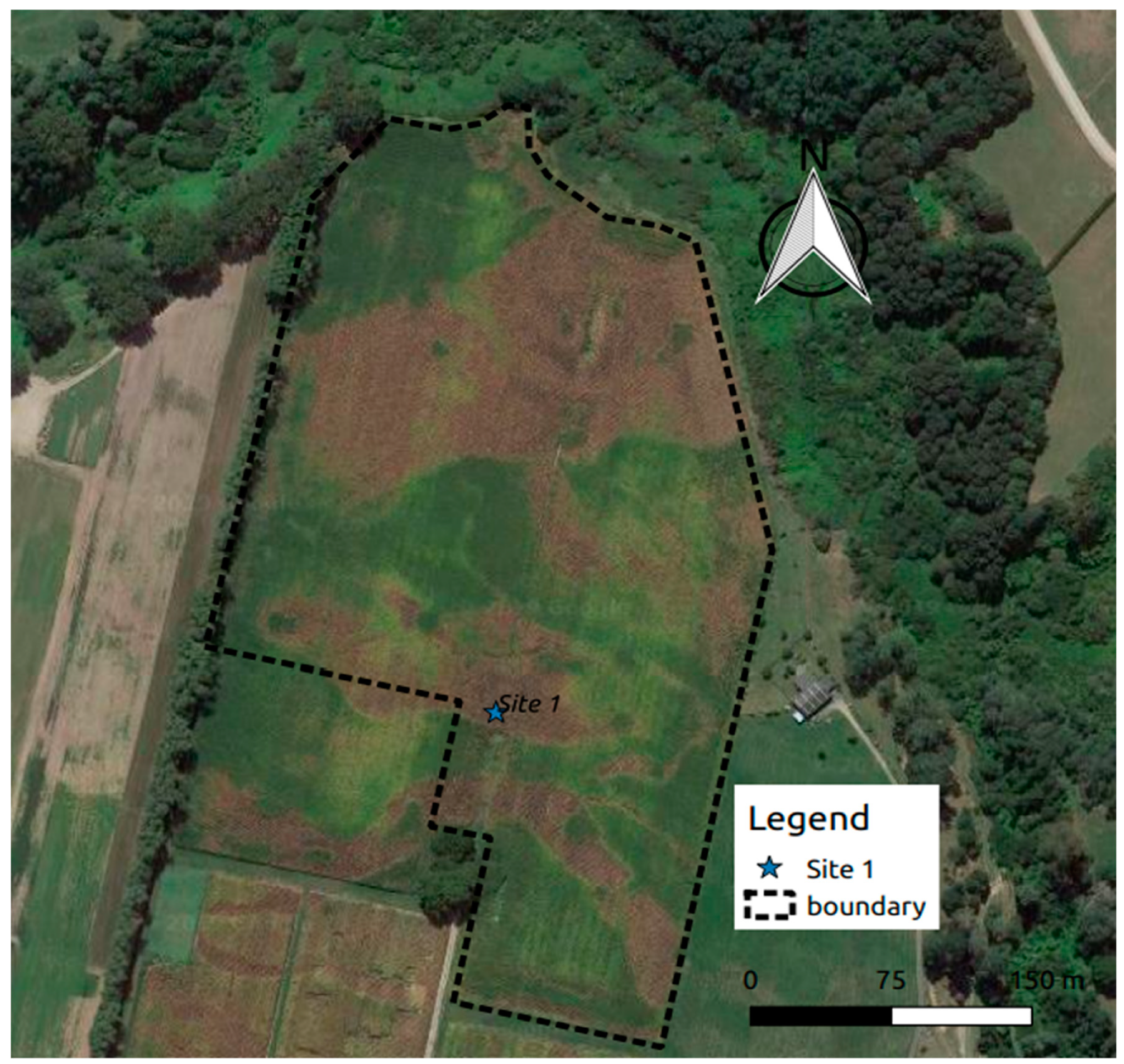
Figure 13), it was hypothesized that the soil texture variations may have influenced the drainage and the performance of the seedling crop, differed within the paddock. Target sampling was undertaken with core samples taken at 0–90 cm depth and we are currently undertaking soil particle size analysis in the laboratory to examine this hypothesis.
Our results are consistent with Drummond, et al. [
10]. The authors predicted maize and soybean yield on three sites in the US state of Missouri (ranging from 13 to 36 ha in size) using a feed-forward, back-propagation neural network (BPNN) model with a number of soil fertility parameters (e.g., soil pH, OM, phosphorus, calcium, magnesium, potassium) and topographic inputs (e.g., elevation, slope). The BPNN model generally provided better statistical predictions in the multiple year analysis than the other two models (MLR and projection pursuit regression). However, in the leave-one-site-year analysis, high prediction errors were produced for the individual site-year due to severe overfitting. The authors concluded that a much larger set of climatologically unique site–years would be required for these models to be used in a predictive manner. However, it is uncertain about the minimum number of years data required to produce a reasonable prediction of spatial yield. Even with additional years of yield data in the models, it is still challenging to acquire spatial data consistently for the task. For example, the precision planting data was only available after 2016, and the Sentinel-2 data was only available after 2015. The results may be distorted with additional years of yield data in the leave-out-one-year analysis if the consistency of historical management actions and yield data quality are not guaranteed.
Future research should perhaps focus on the use of crop reflectance sensors acquiring data at regular intervals to determine how predicted yield changes with the vegetation indices, and use this information to tailor the rates of input during crop growth such as applying nitrogen (N) fertilizer at the V5 stage (5th leaf vegetative stage when the tassel is initiated) of maize. This idea has been exploited by a number of commercial crop sensors such as Crop Circle™ (Holland Scientific), OptRx™ (Ag Leader) and GreenSeeker
® (Trimble Navigation Limited), which calculate N-rates and apply N fertilizer automatically across the paddock by scanning crop canopy [
56]. Satellite imagery in our study is perhaps more useful in other arable systems such as outdoor vegetables and wheat. For arable farmers who grow high protein wheat, a mid-season N application may improve the areas that might require more N and thus move the product to the premium range. The application of statistical modelling techniques can then overcome the limitations of yield monitor data or protein sensor [
57] and provide the opportunity to improve production before harvest.
5. Conclusions
This paper examined several statistical models (stepwise MLR, Cubist regression and a feed-forward neural network) for predicting maize-grain yield potential at the sub-paddock scale using precision farming data including yield monitor data, spatial yield data, seeding density, high-precision elevation and soil EC, as well as publicly-free multispectral satellite imagery (NASA’s Landsat-8 and Sentinel-2 ESA’s missions). The results showed that among other statistical models, the Cubist model produced the best statistical performance for this limited data set.
Although the data is limited, this work demonstrates that there is potential to integrate statistical modelling techniques and spatiotemporal data for site-specific crop management. However, given the model responses, yield data for additional years, and inclusion of further relevant variables (e.g., soil fertility, soil texture) may improve the model. This should be possible when more data sets become available. Once the value proposition of calibrating yield monitors and collecting and storing the data is understood, then the opportunity to embed a yield model in GIS software for consultants to use to advise clients may be possible.
Data consistency is a potential problem in the acquisition of useful satellite imagery at an appropriate growth stage for crop management in New Zealand due to cloud coverage. Nevertheless, UAVs (unmanned aerial vehicles) are increasingly being used in agricultural applications, and may offer alternatives to currently available satellite imagery by providing more relevant scales of data capture and the ability to capture information at more appropriate times of year. Whilst acquiring better data to improve the model might remain a challenge in the near future, the application of the approach used in this study offers advantages over techniques that use spatial data collected from intensive and expensive grid sampling. The minimal costs associated with the approach employed in this study are thus more likely to be of commercial interest to New Zealand farmers. By predicting within-paddock yield potential, this study provided a statistical basis for delineating management zones for precision crop management decisions.
In the future, we will incorporate the models into on-farm GIS software and evaluate the financial viability of the management information through on-farm trials.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}