
Impacts of Discretization and Numerical Propagation on the Ability to Follow Challenging Square Wave Commands


Abstract
:1. Introduction
1.1. Learning Teachniques
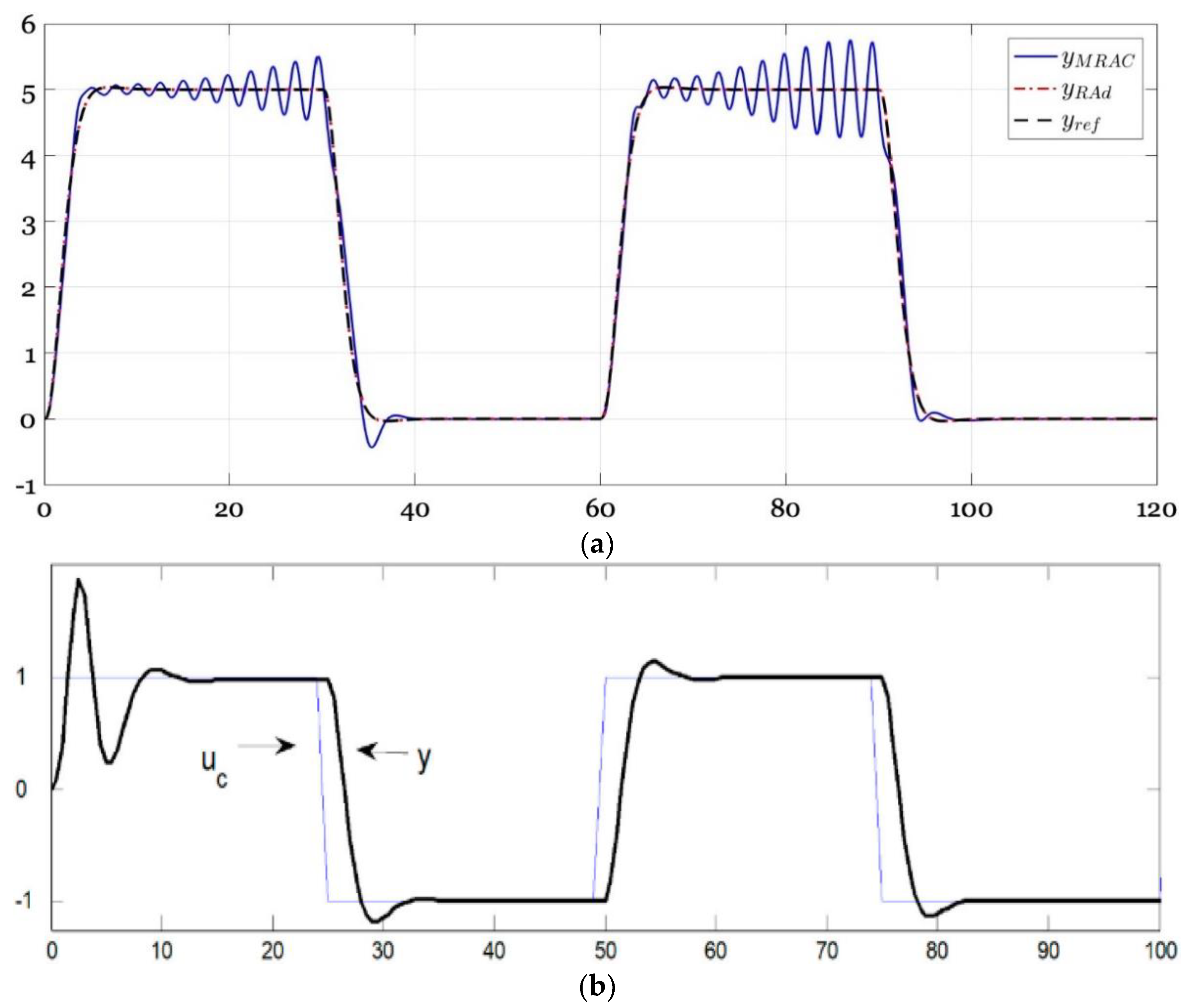
1.2. Adaptive Techniques as Benchmarks for Comparison
1.3. Proposed Novelties
2. Materials and Methods
2.1. Discretized Process Truth Model for DC Motor
2.2. Model-Following Self Tuner
2.3. Deterministic Artificial Intelligence
3. Results
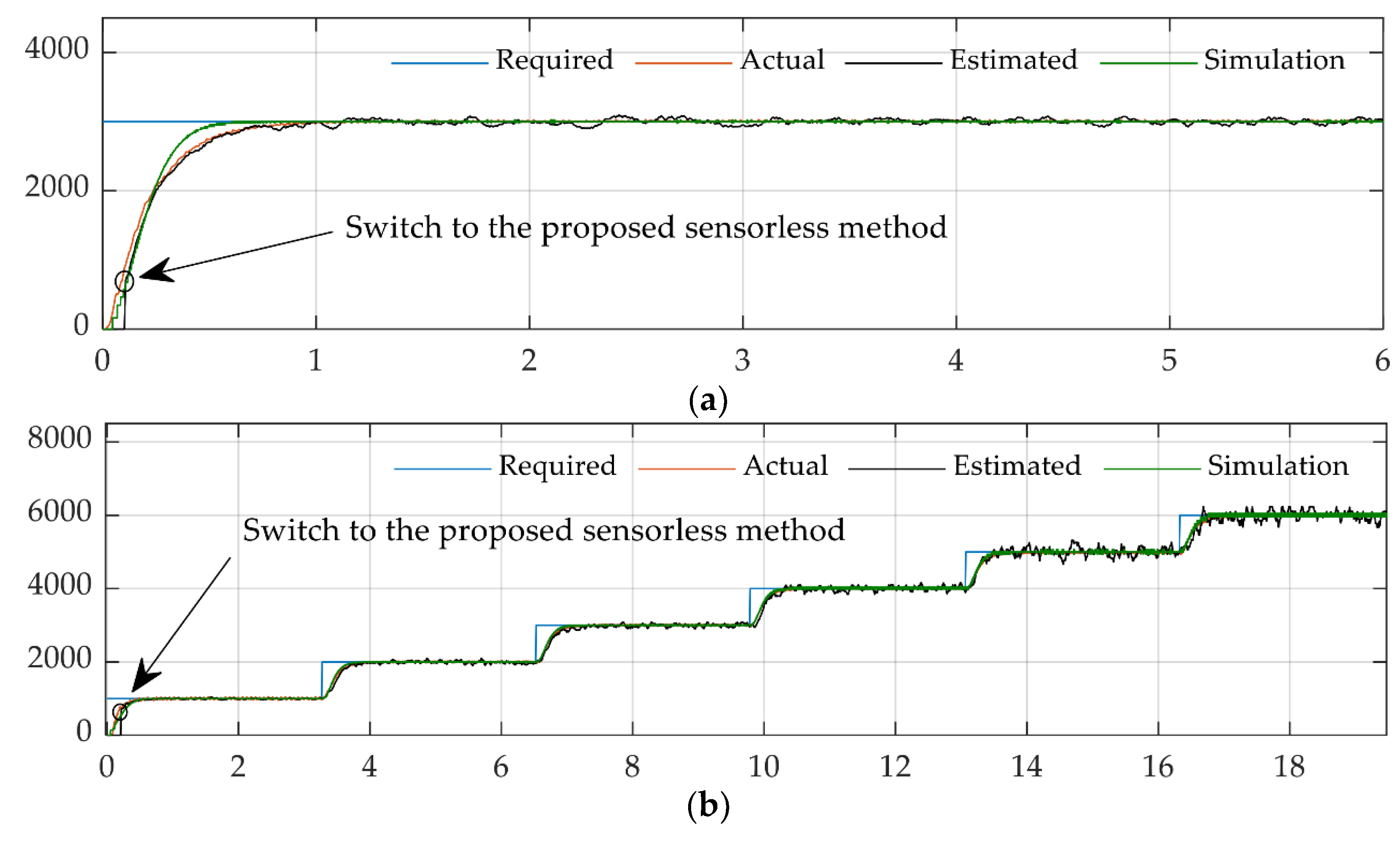
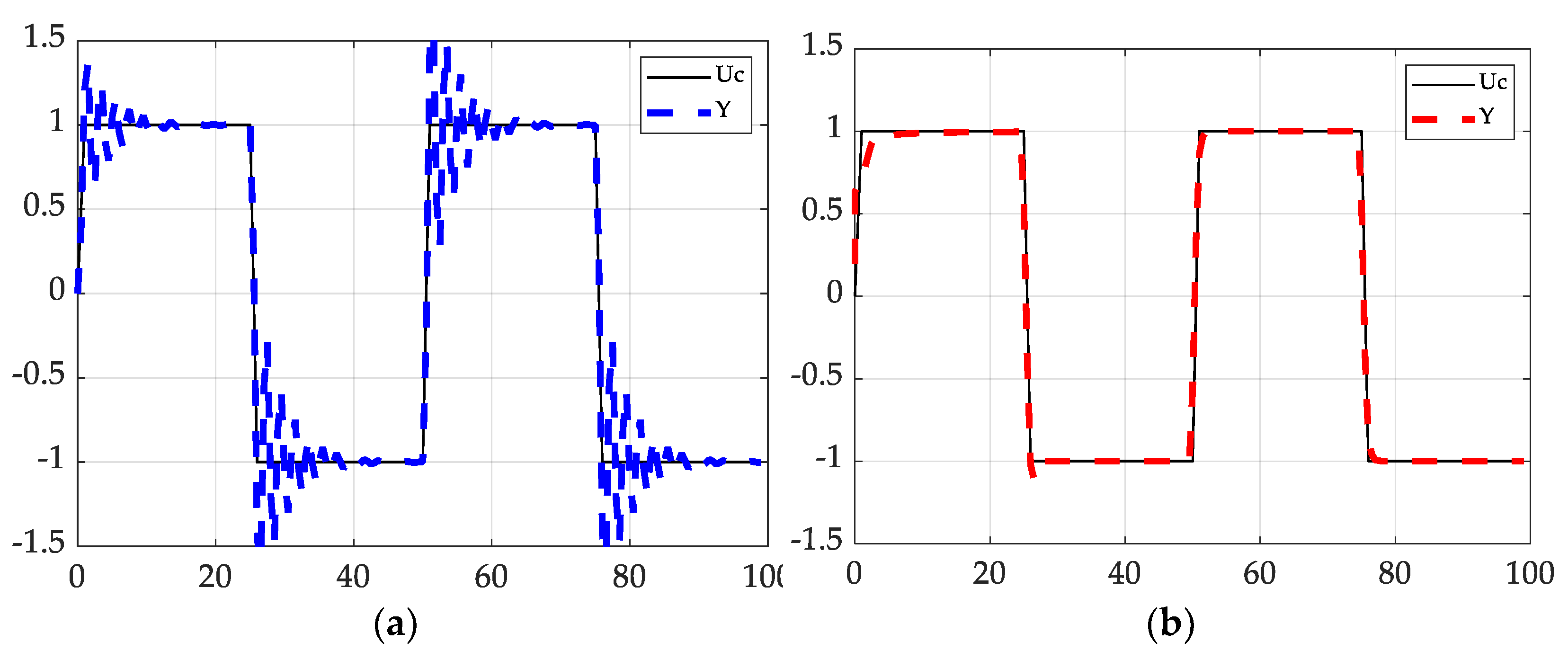
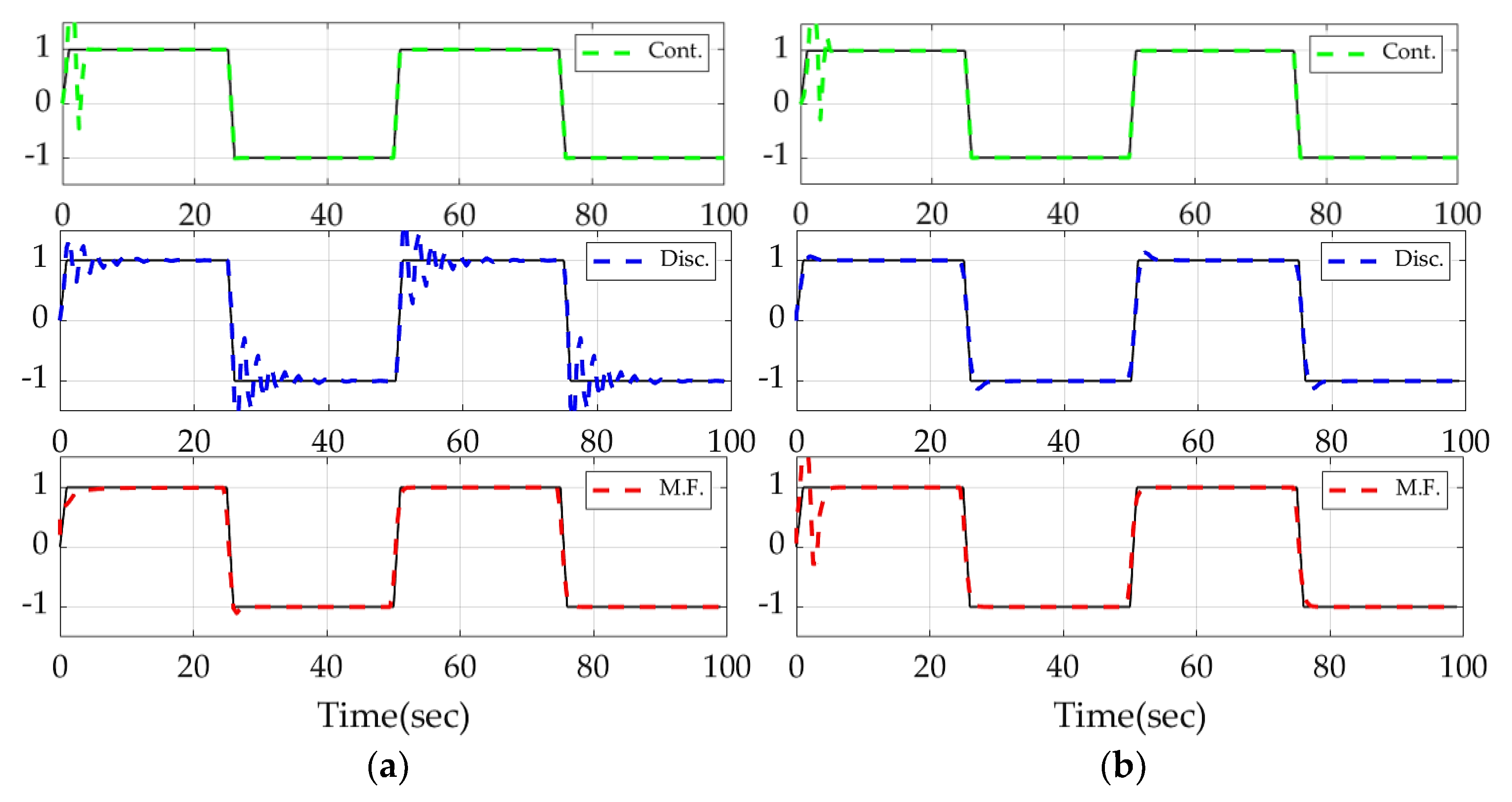
3.1. Comparison of Discrete Deterministic Artificial Intelligence and Model-Following Approach
3.2. Comparison of Discrete D.A.I. and Continuous D.A.I.
4. Discussion
Future Research Recommendations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Discrete D.A.I.
- clear all; clc; close all;
- %% DISCRETIZATION
- % B=[0 0.1065 0.0902];A=poly([1.1 0.8]);
- % Gs = tf(B,A);
- % a1=0;a2=0;b0=0.1;b1=0.2; %Shah’s
- Bp=[0 0 1];Ap=[1 1 0];Gs=tf(Bp,Ap); %Create continuous time transfer function
- Ts=0.5; Hd=c2d(Gs,Ts,‘matched’); % Transform continuous system to discrete system
- B = Hd.Numerator{1}; A = Hd.Denominator{1};
- b0=0.1; b1=0.1; a0=0.1; a1=0.01; a2=0.01;
- %% RLS
- Am=poly([0.2+0.2j 0.2-0.2j]);Bm=[0 0.1065 0.0902];
- am0=Am(1);am1=Am(2);am2=Am(3);a0=0;
- Rmat=[];
- factor = 25;
- % Reference
- T_ref = 25; t_max = 100; time = 0:0.5:t_max; nt = length(time);
- % slew stuff
- Tslew = 1; Uc = zeros(length(nt));
- for j=1:nt
- % pos or neg
- if mod(time(j),2*T_ref)<T_ref
- pn = 1;
- else
- pn =-1;
- end
- % slew
- if mod(time(j),T_ref)<Tslew
- Uc(j)=pn*-1*sin(pi/2+pi/Tslew*mod(time(j),T_ref));
- else
- Uc(j)=pn;
- end
- % initial slew special case
- if time(j)<Tslew
- Uc(j)=1/2*-1*sin(pi/2+pi/Tslew*mod(time(j),T_ref))+1/2;
- end
- end
- n=4;lambda=1.0;
- nzeros=2;time=zeros(1,nzeros);Y=zeros(1,nzeros);Ym=zeros(1,nzeros);
- U=ones(1,nzeros);Uc=[zeros(1,nzeros),Uc];
- Noise = 0;
- P=[100 0 0 0;0 100 0 0;0 0 1 0;0 0 0 1]; THETA_hat(:,1)=[-a1 -a2 b0 b1]’;beta=[];
- alpha = 0.5; gamma = 1.2;
- for i=1:201
- phi=[]; t=i+nzeros; time(t)=i;
- Y(t)=[-A(2) -A(3) B(2) B(3)]*[Y(t-1) Y(t-2) U(t-1) U(t-2)]’;
- Ym(t)=[-Am(2) -Am(3) Bm(2) Bm(3)]*[Ym(t-1) Ym(t-2) Uc(t-1) Uc(t-2)]’;
- BETA=(Am(1)+Am(2)+Am(3))/(b0+b1); beta=[beta BETA];
- %RLS implementation
- phi=[Y(t-1) Y(t-2) U(t-1) U(t-2)]’; K=P*phi*1/(lambda+phi’*P*phi); P=P-P*phi*inv(1+phi’*P*phi)*phi’*P/lambda; %RLS-EF
- error(i)=Y(t)-phi’*THETA_hat(:,i); THETA_hat(:,i+1)=THETA_hat(:,i)+K*error(i);
- a1=-THETA_hat(1,i+1);a2=-THETA_hat(2,i+1);b0=THETA_hat(3,i+1);b1=THETA_hat(4,i+1);
- Af(:,i)=[1 a1 a2]’; Bf(:,i)=[b0 b1]’;
- % Determine R,S, & T for CONTROLLER
- r1=(b1/b0)+(b1^2-am1*b0*b1+am2*b0^2)*(-b1+a0*b0)/(b0*(b1^2-a1*b0*b1+a2*b0^2));
- s0=b1*(a0*am1-a2-am1*a1+a1^2+am2-a1*a0)/(b1^2-a1*b0*b1+a2*b0^2)+b0*(am1*a2-a1*a2-a0*am2+a0*a2)/(b1^2-a1*b0*b1+a2*b0^2);
- s1=b1*(a1*a2-am1*a2+a0*am2-a0*a2)/(b1^2-a1*b0*b1+a2*b0^2)+b0*(a2*am2-a2^2-a0*am2*a1+a0*a2*am1)/(b1^2-a1*b0*b1+a2*b0^2);
- R=[1 r1];S=[s0 s1];T=BETA*[1 a0];
- Rmat=[Rmat r1];
- %calculate control signal
- U(t)=[T(1) T(2) -R(2) -S(1) -S(2)]*[Uc(t) Uc(t-1) U(t-1) Y(t) Y(t-1)]’;
- U(t)=1.3*[T(1) T(2) -R(2) -S(1) -S(2)]*[Uc(t) Uc(t-1) U(t-1) Y(t) Y(t-1)]’;% Arbitrarily increased to duplicate text
- end
- %% DAI
- %Create command signal, Uc based on Example 3.5 plots…square wave with 50 sec period
- t_max = 200;
- THETA_hat(:,1)=[-a1 -a2 b0 b1]’;
- n = length(THETA_hat);
- % Sigma=1/25; Noise=Sigma*randn(nt,1);
- % Noise = 0;
- nzeros=2;
- Y_true=zeros(1,nzeros);Ym=zeros(1,nzeros);U=zeros(1,nzeros);
- P=[100 0 0 0;0 100 0 0;0 0 1 0;0 0 0 1];
- lambda = 1;
- eb = Y_true(1) - Uc(1);
- err = 0;
- kp = 2.0;
- kd = 6.0;
- hatvec = zeros(4,1);
- for i=1:t_max+1 %Loop through the output data Y(t)
- t=i+nzeros;
- de = err-eb;
- u = kp*err + kd*de;
- U(t-1)= u;
- Y_true(t)=[Y_true(t-1) Y_true(t-2) U(t-1) U(t-2)]*[-A(2) -A(3) B(2) B(3)]’;
- phid = [Y_true(t) -Y_true(t-1) Y_true(t-2) -U(t-2)];
- newest = phid\u;
- hatvec(:,i) = newest;
- eb = err;
- %disp(t);
- err = Uc(t)-Y_true(t);
- end
- %% PLOT
- tspan = linspace(0,100,201);
- tspan = [zeros(1,2) tspan];
- figure(1); %DAI
- plot(tspan(1:201),Uc(1:201),‘k-’,‘LineWidth’,1); hold on; plot(tspan(1:201),Y_true(2:202),‘b--’,‘LineWidth’,3); hold off
- xlabel(’Time(sec)’); legend(‘Uc’,‘Y’,‘fontsize’,11);
- set(gca,‘fontsize’,16); set(gca,‘fontname’,‘Palatino Linotype’); xlim([0 max(time)]); grid;
- % p=plot(tspan,Uc(1:203),‘-’,tspan,Y,‘-’); p(2).LineWidth = 2; legend(‘Uc’,‘Y’,‘fontsize’,11); %DAI
- axis([0 100,-1.5 1.5]);
- figure(2); %RLS estimation
- plot(tspan(1:201),Uc(1:201),‘k-’,‘LineWidth’,1); hold on; plot(tspan(1:201),Y(3:203),‘r--’,‘LineWidth’,3); hold off
- xlabel(’Time(sec)’); legend(‘Uc’,‘Y’,‘fontsize’,11);
- set(gca,‘fontsize’,16); set(gca,‘fontname’,‘Palatino Linotype’); xlim([0 max(time)]); grid;
- axis([0 100,-1.5 1.5]);
- DAI_err_mean = mean(abs(Uc(1:201)-Y_true(2:202)))
- DAI_err_std = std(abs(Uc(1:201)-Y_true(2:202)))
- RLS_err_mean = mean(abs(Uc(1:201)-Y(3:203)))
- RLS_err_std = std(abs(Uc(1:201)-Y(3:203)))
Appendix A.2. Continuous D.A.I.
- clear all;clc;close all;
- % Enter Given Plant parameters
- for k=1:2
- Bp=[0 0 1];Ap=[1 1 0];Gs=tf(Bp,Ap); %Create continuous time transfer function
- Ts=[0.5 0.27]; Hz=c2d(Gs,Ts(k),‘matched’); % Transform continuous system to discrete system
- B = Hz.Numerator{1}; A = Hz.Denominator{1};
- % Initial estimates of plant parameters for undetermined system from example 3.5
- b0=0.1; b1=0.1; a0=0.1; a1=0.01; a2=0.01;
- % Reference
- T_ref = 25; t_max = 100; time = 0:Ts:t_max; nt = length(time);
- % slew stuff
- Tslew = 1; Yd = zeros(length(nt));
- for i=1:nt
- % pos or neg
- if mod(time(i),2*T_ref)<T_ref
- pn = 1;
- else
- pn =-1;
- end
- % slew
- if mod(time(i),T_ref)<Tslew
- Yd(i)=pn*-1*sin(pi/2+pi/Tslew*mod(time(i),T_ref));
- else
- Yd(i)=pn;
- end
- % initial slew special case
- if time(i)<Tslew
- Yd(i)=1/2*-1*sin(pi/2+pi/Tslew*mod(time(i),T_ref))+1/2;
- end
- end
- THETA_hat(:,1)=[-a1 -a2 b0 b1]’;
- n = length(THETA_hat);
- Sigma=1/12*0; Noise=Sigma*randn(nt,1);
- nzeros=2;Y=zeros(1,nzeros);Y_true=zeros(1,nzeros);
- Ym=zeros(1,nzeros);U=zeros(1,nzeros);Yd=[zeros(1,nzeros),Yd];
- P=[100 0 0 0;0 100 0 0;0 0 1 0;0 0 0 1];
- lambda = 1;
- for i=1:nt-1
- t=i+nzeros;
- % Update Dynamics
- Y_true(t)=[Y(t-1) Y(t-2) U(t-1) U(t-2)]*[-A(2) -A(3) B(2) B(3)]’;
- Y(t)=Y_true(t)+Noise(i);
- phi=[Y(t-1) Y(t-2) U(t-1) U(t-2)]’;
- K=P*phi*1/(lambda+phi’*P*phi);
- P=P-P*phi/(1+phi’*P*phi)*phi’*P/lambda;
- innov_err(i)=Y(t)-phi’*THETA_hat(:,i);
- THETA_hat(:,i+1)=THETA_hat(:,i)+K*innov_err(i);
- a1=-THETA_hat(1,i+1);a2=-THETA_hat(2,i+1);b0=THETA_hat(3,i+1);b1=THETA_hat(4,i+1);% THETA=[-a1 -a2 b0 b1];
- % Calculate Model control, U(t) optimally
- U(t)=[Yd(t+1) Y(t) Y(t-1) U(t-1)]*[1 a1 a2 -b0]’/b1;
- end
- Y_true(end+1)=Y_true(end);
- FS = 2;
- time = [-(nzeros-1)*Ts:Ts:0 time];
- figure (k)
- plot(time,Yd,‘k-’,‘LineWidth’,1); hold on;
- h1 = plot(time,Y_true,‘g--’,‘LineWidth’,2); axis([0 100,-1.5 1.5]); hold off; grid;
- if k==1
- legend(h1,‘T_s = 0.50s’,‘fontsize’,11); xlabel(’Time(sec)’); set(gca,‘fontsize’,16); set(gca,‘fontname’,‘Palatino Linotype’);
- else
- legend(h1,‘T_s = 0.27s’,‘fontsize’,11); xlabel(’Time(sec)’); set(gca,‘fontsize’,16); set(gca,‘fontname’,‘Palatino Linotype’);
- end
- end
Appendix A.3. D.A.I. All
- clear all;clc;close all;
- %% DISCRETIZATION
- % B=[0 0.1065 0.0902];A=poly([1.1 0.8]);
- % Gs = tf(B,A);
- % a1=0;a2=0;b0=0.1;b1=0.2; %Shah’s
- Bp=[0 0 1];Ap=[1 1 0];Gs=tf(Bp,Ap); %Create continuous time transfer function
- Ts=0.5; Hd=c2d(Gs,Ts,‘matched’); % Transform continuous system to discrete system
- B = Hd.Numerator{1}; A = Hd.Denominator{1};
- b0=0.1; b1=0.1; a0=0.1; a1=0.01; a2=0.01;
- %% RLS
- Am=poly([0.2+0.2j 0.2-0.2j]);Bm=[0 0.1065 0.0902];
- am0=Am(1);am1=Am(2);am2=Am(3);a0=0;
- Rmat=[];
- factor = 25;
- % Reference
- T_ref = 25; t_max = 100; time = 0:0.5:t_max; nt = length(time);
- % slew stuff
- Tslew = 1; Uc = zeros(length(nt));
- for j=1:nt
- % pos or neg
- if mod(time(j),2*T_ref)<T_ref
- pn = 1;
- else
- pn =-1;
- end
- % slew
- if mod(time(j),T_ref)<Tslew
- Uc(j)=pn*-1*sin(pi/2+pi/Tslew*mod(time(j),T_ref));
- else
- Uc(j)=pn;
- end
- % initial slew special case
- if time(j)<Tslew
- Uc(j)=1/2*-1*sin(pi/2+pi/Tslew*mod(time(j),T_ref))+1/2;
- end
- end
- n=4;lambda=1.0;
- nzeros=2;time=zeros(1,nzeros);Y=zeros(1,nzeros);Ym=zeros(1,nzeros);
- U=ones(1,nzeros);Uc=[zeros(1,nzeros),Uc];
- Noise = 0;
- P=[100 0 0 0;0 100 0 0;0 0 1 0;0 0 0 1]; THETA_hat(:,1)=[-a1 -a2 b0 b1]’;beta=[];
- alpha = 0.5; gamma = 1.2;
- for i=1:201
- phi=[]; t=i+nzeros; time(t)=i;
- Y(t)=[-A(2) -A(3) B(2) B(3)]*[Y(t-1) Y(t-2) U(t-1) U(t-2)]’;
- Ym(t)=[-Am(2) -Am(3) Bm(2) Bm(3)]*[Ym(t-1) Ym(t-2) Uc(t-1) Uc(t-2)]’;
- BETA=(Am(1)+Am(2)+Am(3))/(b0+b1); beta=[beta BETA];
- %RLS implementation
- phi=[Y(t-1) Y(t-2) U(t-1) U(t-2)]’; K=P*phi*1/(lambda+phi’*P*phi); P=P-P*phi*inv(1+phi’*P*phi)*phi’*P/lambda; %RLS-EF
- error(i)=Y(t)-phi’*THETA_hat(:,i); THETA_hat(:,i+1)=THETA_hat(:,i)+K*error(i);
- a1=-THETA_hat(1,i+1);a2=-THETA_hat(2,i+1);b0=THETA_hat(3,i+1);b1=THETA_hat(4,i+1);
- Af(:,i)=[1 a1 a2]’; Bf(:,i)=[b0 b1]’;
- % Determine R,S, & T for CONTROLLER
- r1=(b1/b0)+(b1^2-am1*b0*b1+am2*b0^2)*(-b1+a0*b0)/(b0*(b1^2-a1*b0*b1+a2*b0^2));
- s0=b1*(a0*am1-a2-am1*a1+a1^2+am2-a1*a0)/(b1^2-a1*b0*b1+a2*b0^2)+b0*(am1*a2-a1*a2-a0*am2+a0*a2)/(b1^2-a1*b0*b1+a2*b0^2);
- s1=b1*(a1*a2-am1*a2+a0*am2-a0*a2)/(b1^2-a1*b0*b1+a2*b0^2)+b0*(a2*am2-a2^2-a0*am2*a1+a0*a2*am1)/(b1^2-a1*b0*b1+a2*b0^2);
- R=[1 r1];S=[s0 s1];T=BETA*[1 a0];
- Rmat=[Rmat r1];
- %calculate control signal
- U(t)=[T(1) T(2) -R(2) -S(1) -S(2)]*[Uc(t) Uc(t-1) U(t-1) Y(t) Y(t-1)]’;
- U(t)=1.3*[T(1) T(2) -R(2) -S(1) -S(2)]*[Uc(t) Uc(t-1) U(t-1) Y(t) Y(t-1)]’;% Arbitrarily increased to duplicate text
- end
- %% DAI
- %Create command signal, Uc based on Example 3.5 plots…square wave with 50 sec period
- t_max = 200;
- THETA_hat(:,1)=[-a1 -a2 b0 b1]’;
- n = length(THETA_hat);
- % Sigma=1/25; Noise=Sigma*randn(nt,1);
- % Noise = 0;
- nzeros=2;
- Y_true=zeros(1,nzeros);Ym=zeros(1,nzeros);U=zeros(1,nzeros);
- P=[100 0 0 0;0 100 0 0;0 0 1 0;0 0 0 1];
- lambda = 1;
- eb = Y_true(1) - Uc(1);
- err = 0;
- kp = 2.0;
- kd = 6.0;
- hatvec = zeros(4,1);
- for i=1:t_max+1 %Loop through the output data Y(t)
- t=i+nzeros;
- de = err-eb;
- u = kp*err + kd*de;
- U(t-1) = u;
- Y_true(t)=[Y_true(t-1) Y_true(t-2) U(t-1) U(t-2)]*[-A(2) -A(3) B(2) B(3)]’;
- phid = [Y_true(t) -Y_true(t-1) Y_true(t-2) -U(t-2)];
- newest = phid\u;
- hatvec(:,i) = newest;
- eb = err;
- %disp(t);
- err = Uc(t)-Y_true(t);
- end
- %% PLOT
- tspan = linspace(0,100,201);
- tspan = [zeros(1,2) tspan];
- figure(1); %DAI
- plot(tspan(1:201),Uc(1:201),‘k-’,‘LineWidth’,1); hold on; plot(tspan(1:201),Y_true(2:202),‘b--’,‘LineWidth’,3); hold off
- xlabel(’Time(sec)’); legend(‘Uc’,‘Y’,‘fontsize’,11);
- set(gca,‘fontsize’,16); set(gca,‘fontname’,‘Palatino Linotype’); xlim([0 max(time)]); grid;
- % p=plot(tspan,Uc(1:203),‘-’,tspan,Y,‘-’); p(2).LineWidth = 2; legend(‘Uc’,‘Y’,‘fontsize’,11); %DAI
- axis([0 100,-1.5 1.5]);
- figure(2); %RLS estimation
- plot(tspan(1:201),Uc(1:201),‘k-’,‘LineWidth’,1); hold on; plot(tspan(1:201),Y(3:203),‘r--’,‘LineWidth’,3); hold off
- xlabel(’Time(sec)’); legend(‘Uc’,‘Y’,‘fontsize’,11);
- set(gca,‘fontsize’,16); set(gca,‘fontname’,‘Palatino Linotype’); xlim([0 max(time)]); grid;
- axis([0 100,-1.5 1.5]);
- DAI_err_mean = mean(abs(Uc(1:201)-Y_true(2:202)))
- DAI_err_std = std(abs(Uc(1:201)-Y_true(2:202)))
- RLS_err_mean = mean(abs(Uc(1:201)-Y(3:203)))
- RLS_err_std = std(abs(Uc(1:201)-Y(3:203)))
References
- Harker, T. Department of the Navy Unmanned Campaign Framework, 16 March 2021. Available online: https://www.navy.mil/Portals/1/Strategic/20210315%20Unmanned%20Campaign_Final_LowRes.pdf?ver=LtCZ-BPlWki6vCBTdgtDMA%3D%3D (accessed on 24 January 2022).
- See, H.A. Coordinated Guidance Strategy for Multiple USVs during Maritime Interdiction Operations. Master’s Thesis, Naval Postgraduate School, Monterey, CA, USA, September 2017. Photo Is Figure 7 Taken from 2014 NASA Website, Wolf, M. Autonomy and Situational Awareness for UMS. Available online: https://www-robotics.jpl.nasa.gov/tasks/showBrowseImage.cfm?TaskID=271&tdaID=700075 (accessed on 6 January 2022).
- NOAA Image Use Policy. Available online: https://www.omao.noaa.gov/find/media/images/image-licensing-usage-info (accessed on 24 December 2021).
- What Is an AUV. NOAA Ocean Exploration National Oceanic and Atmospheric Administration, U.S. Department of Commerce. Available online: https://oceanexplorer.noaa.gov/facts/auv.html (accessed on 24 December 2021).
- Sulzberger, G.; Bono, J.; Manley, R.; Clem, T.; Vaizer, L.; Holtzapple, R. Hunting sea mines with UUV-based magnetic and electro-optic sensors. In Proceedings of the OCEANS 2009, Biloxi, MS, USA, 26–29 October 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Huntsberger, T.; Woodward, G. Intelligent autonomy for unmanned surface and underwater vehicles. In Proceedings of the MTS/IEEE OCEANS’11, Waikoloa, HI, USA, 19–22 September 2011. [Google Scholar] [CrossRef]
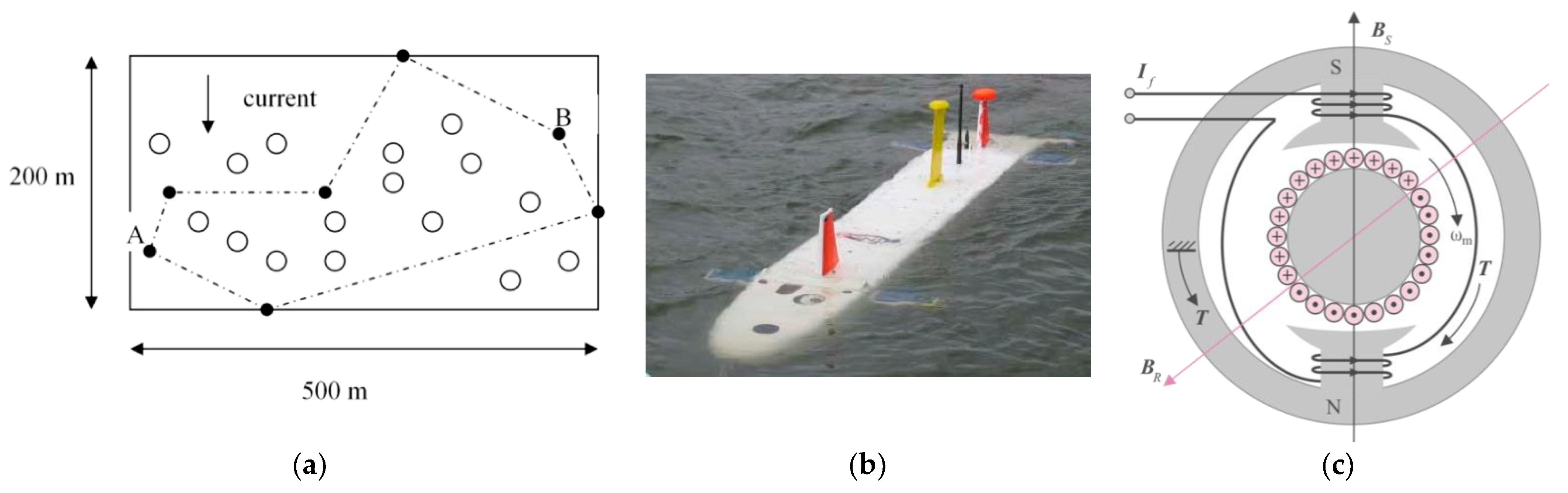
- Sands, T.; Bollino, K.; Kaminer, I.; Healey, A. Autonomous Minimum Safe Distance Maintenance from Submersed Obstacles in Ocean Currents. J. Mar. Sci. Eng. 2018, 6, 98. [Google Scholar] [CrossRef] [Green Version]
- Slotine, J.; Weiping, L. Applied Nonlinear Control; Prentice Hall: Englewood Cliffs, NJ, USA, 1991. [Google Scholar]
- Slotine, J.; Benedetto, M. Hamiltonian adaptive control on spacecraft. IEEE Trans. Autom. Control 1990, 35, 848–852. [Google Scholar] [CrossRef]
- Fossen, T. Comments on “Hamiltonian Adaptive Control of Spacecraft”. IEEE Trans. Autom. Control 1993, 38, 671–672. [Google Scholar] [CrossRef]
- Sands, T.; Kim, J.J.; Agrawal, B.N. Improved Hamiltonian adaptive control of spacecraft. In Proceedings of the IEEE Aerospace, Big Sky, MT, USA, 7–14 March 2009; IEEE Publishing: Piscataway, NJ, USA, 2009; pp. 1–10. [Google Scholar]
- Smeresky, B.; Rizzo, A.; Sands, T. Optimal Learning and Self-Awareness Versus PDI. Algorithms 2020, 13, 23. [Google Scholar] [CrossRef] [Green Version]
- Sands, T. Development of deterministic artificial intelligence for unmanned underwater vehicles (UUV). J. Mar. Sci. Eng. 2020, 8, 578. [Google Scholar] [CrossRef]
- Fossen, T. Guidance and Control of Ocean Vehicles; John Wiley & Sons Inc.: Chichester, UK, 1994. [Google Scholar]
- Fossen, T. Handbook of Marine Craft Hydrodynamics and Motion Control, 2nd ed.; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2021; ISBN 978-1-119-57505-4. [Google Scholar]
- Available online: https://site.ieee.org/ias-idc/2019/01/29/prof-bob-lorenz-passed-away/ (accessed on 25 January 2022).
- Zhang, L.; Fan, Y.; Cui, R.; Lorenz, R.; Cheng, M. Fault-Tolerant Direct Torque Control of Five-Phase FTFSCW-IPM Motor Based on Analogous Three-phase SVPWM for Electric Vehicle Applications. IEEE Trans. Veh. Technol. 2018, 67, 910–919. [Google Scholar] [CrossRef]
- Apoorva, A.; Erato, D.; Lorenz, R. Enabling Driving Cycle Loss Reduction in Variable Flux PMSMs Via Closed-Loop Magnetization State Control. IEEE Trans. Ind. Appl. 2018, 54, 3350–3359. [Google Scholar] [CrossRef]
- Flieh, H.; Lorenz, R.; Totoki, E.; Yamaguchi, S.; Nakamura, Y. Investigation of Different Servo Motor Designs for Servo Cycle Operations and Loss Minimizing Control Performance. IEEE Trans. Ind. Appl. 2018, 54, 5791–5801. [Google Scholar] [CrossRef]
- Flieh, H.; Lorenz, R.; Totoki, E.; Yamaguchi, S.; Nakamura, Y. Dynamic Loss Minimizing Control of a Permanent Magnet Servomotor Operating Even at the Voltage Limit When Using Deadbeat-Direct Torque and Flux Control. IEEE Trans. Ind. Appl. 2019, 3, 2710–2720. [Google Scholar] [CrossRef]
- Flieh, H.; Slininger, T.; Lorenz, R.; Totoki, E. Self-Sensing via Flux Injection with Rapid Servo Dynamics Including a Smooth Transition to Back-EMF Tracking Self-Sensing. IEEE Trans. Ind. Appl. 2020, 56, 2673–2684. [Google Scholar] [CrossRef]
- Sands, T. Virtual sensoring of motion using Pontryagin’s treatment of Hamiltonian systems. Sensors 2021, 21, 4603. [Google Scholar] [CrossRef]
- Sands, T. Comparison and Interpretation Methods for Predictive Control of Mechanics. Algorithms 2019, 12, 232. [Google Scholar] [CrossRef] [Green Version]
- Vidlak, M.; Gorel, L.; Makys, P.; Stano, M. Sensorless Speed Control of Brushed DC Motor Based at New Current Ripple Component Signal Processing. Energies 2021, 14, 5359. [Google Scholar] [CrossRef]
- Banda, G.; Kolli, S.G. An Intelligent Adaptive Neural Network Controller for a Direct Torque Controlled eCAR Propulsion System. World Electr. Veh. J. 2021, 12, 44. [Google Scholar] [CrossRef]
- Sands, T. Control of DC Motors to Guide Unmanned Underwater Vehicles. Appl. Sci. 2021, 11, 2144. [Google Scholar] [CrossRef]
- Shah, R.; Sands, T. Comparing Methods of DC Motor Control for UUVs. Appl. Sci. 2021, 11, 4972. [Google Scholar] [CrossRef]
- Åström, K.; Wittenmark, B. Adaptive Control; Addison-Wesley: Boston, FL, USA, 1995. [Google Scholar]
- Chen, J.; Wang, J.; Wang, W. Robust Adaptive Control for Nonlinear Aircraft System with Uncertainties. Appl. Sci. 2020, 10, 4270. [Google Scholar] [CrossRef]
- Cezayirli, A.; Ciliz, M. Multiple model based adaptive control of a DC motor under load changes. In Proceedings of the IEEE International Conference on Mechatronics, Istanbul, Turkey, 5 June 2004; pp. 328–333. [Google Scholar] [CrossRef]
- Sri Gowri, K.; Reddy, T.B.; Sai Babu, C. Direct torque control of induction motor based on advanced discontinuous PWM algorithm for reduced current ripple. Electr. Eng. 2010, 92, 245–255. [Google Scholar] [CrossRef]
- Bernat, J.; Stepien, S. The adaptive speed controller for the BLDC motor using MRAC technique. IFAC Proc. Vol. 2011, 44, 4143–4148. [Google Scholar] [CrossRef] [Green Version]
- Rathaiah, M.; Reddy, R.; Anjaneyulu, K. Design of Optimum Adaptive Control for DC Motor. Int. J. Electr. Eng. 2014, 7, 353–366. [Google Scholar]
- Haghi, P.; Ariyur, K. Adaptive First Order Nonlinear Systems Using Extremum Seeking. In Proceedings of the 50th Annual Allerton Conference on Communication Control, Monticello, IL, USA, 1–5 October 2012; pp. 1510–1516. [Google Scholar]
- Sands, T. Nonlinear-Adaptive Mathematical System Identification. Computation 2017, 5, 47. [Google Scholar] [CrossRef] [Green Version]
- Isidori, A.; Byrnes, C. Output Regulation of Nonlinear Systems. IEEE Trans. Autom. Control 1990, 35, 131–140. [Google Scholar] [CrossRef]
- Cheng, D.; Tarn, T.; Spurgeon, S. On the Design of Output Regulators for Nonlinear Systems. Syst. Control. Lett. 2001, 43, 167–179. [Google Scholar] [CrossRef]
- Khalil, H. Nonlinear Systems; Prentice Hall: Englewood Cliffs, NJ, USA, 1996. [Google Scholar]
- Wang, D.; Huang, J. Solving the Discrete-time Output Regulation Problem with Taylor series Method. In Proceedings of the Chinese Control Conference, Hongkong China, 6–8 December 2000. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Step-Size [s] | Error Mean | Error Standard Deviation |
|---|---|---|---|
| D.A.I. | 0.50 | 0.0956 | 0.1632 |
| M.F. | 0.50 | 0.0278 | 0.0918 |
| D.A.I. | 0.27 | 0.0175 | 0.0545 |
| M.F. | 0.27 | 0.0471 | 0.1745 |
| Type | Step-Size [s] | Error Mean | Error Std. |
|---|---|---|---|
| Discrete | 0.50 | 0.0956 | 0.1632 |
| Continuous | 0.50 | 0.0223 | 0.1654 |
| Discrete | 0.27 | 0.0175 | 0.0545 |
| Continuous | 0.27 | 0.0169 | 0.1397 |
| Discretization Method | Step-Size [s] | Error Mean | Error Standard Deviation |
|---|---|---|---|
| Matched | 0.50 | 0.0956 (0%) | 0.1632 (0%) |
| ZOH | 0.50 | 0.0730 (−24%) | 0.1317 (−19%) |
| Tustin FOH | 0.50 0.50 | 0.0204 (−79%) 0.0141 (−85%) | 0.0525 (−68%) 0.0330 (−80%) |
| Method | Step-Size [s] | Error Mean | Error Standard Deviation |
|---|---|---|---|
| D.A.I. | 0.50 | 0% | 0% |
| M.F. | 0.50 | −71% | −44% |
| D.A.I. | 0.27 | −82% | −67% |
| M.F. | 0.27 | −51% | 7% |
| Method | Step-Size [s] | Error Mean | Error Standard Deviation |
|---|---|---|---|
| Discrete | 0.50 | 0% | 0% |
| Continuous | 0.50 | −77% | 1% |
| Discrete | 0.27 | −82% | −67% |
| Continuous | 0.27 | −82% | −14% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koo, S.M.; Travis, H.; Sands, T. Impacts of Discretization and Numerical Propagation on the Ability to Follow Challenging Square Wave Commands. J. Mar. Sci. Eng. 2022, 10, 419. https://doi.org/10.3390/jmse10030419
Koo SM, Travis H, Sands T. Impacts of Discretization and Numerical Propagation on the Ability to Follow Challenging Square Wave Commands. Journal of Marine Science and Engineering. 2022; 10(3):419. https://doi.org/10.3390/jmse10030419
Chicago/Turabian StyleKoo, Sung Mo, Henry Travis, and Timothy Sands. 2022. "Impacts of Discretization and Numerical Propagation on the Ability to Follow Challenging Square Wave Commands" Journal of Marine Science and Engineering 10, no. 3: 419. https://doi.org/10.3390/jmse10030419
APA StyleKoo, S. M., Travis, H., & Sands, T. (2022). Impacts of Discretization and Numerical Propagation on the Ability to Follow Challenging Square Wave Commands. Journal of Marine Science and Engineering, 10(3), 419. https://doi.org/10.3390/jmse10030419