
Deep Learning-Based Maritime Environment Segmentation for Unmanned Surface Vehicles Using Superpixel Algorithms


Abstract
:1. Introduction
1.1. Background and Motivation
1.2. Contributions
- A superpixel segmentation model called Simple Linear Iterative Clustering (SLIC), has been innovatively integrated with a deep neural network in this paper to improve the segmentation accuracy, especially for obstacle edge detection in maritime environments.
- Enriched cross validations based on three different maritime datasets are conducted with the results proving that the proposed SLIC enabled model has a strong capability in understanding the semantics of the environment.
- Obstacle detection performances are validated using a series of practical maritime datasets with the results showing that a high obstacle detection accuracy can be achieved when using the segmentation generated by the proposed network.
2. Related Work
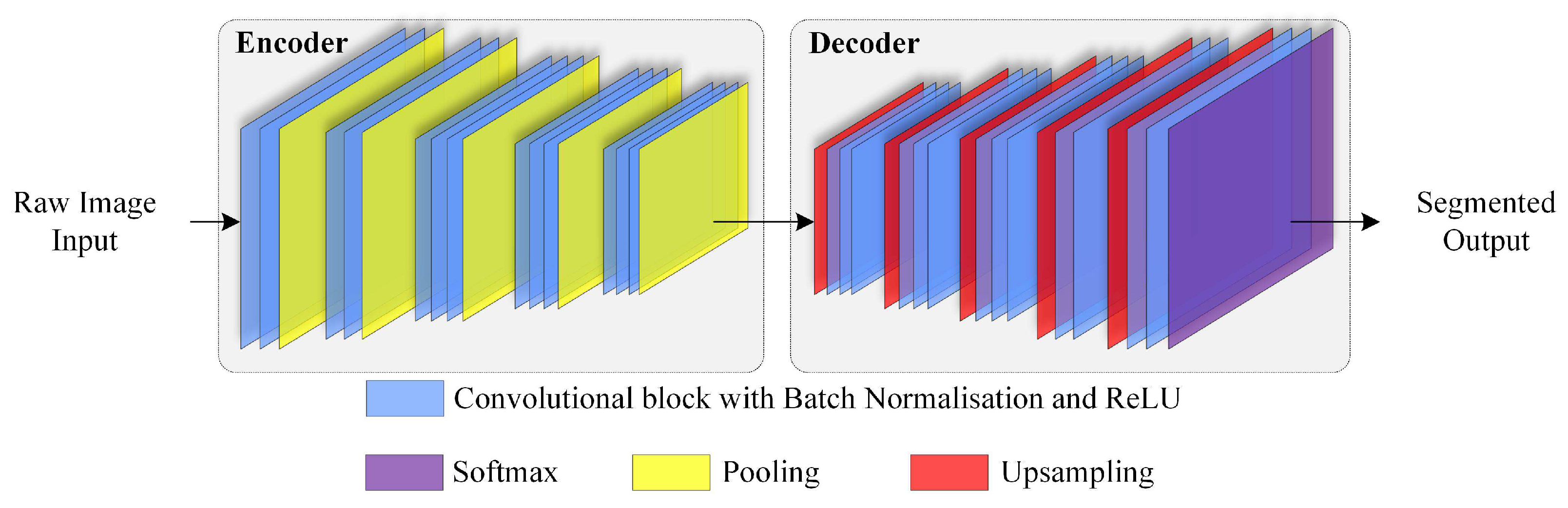
2.1. Image Semantic Segmentation Networks
2.2. Superpixel Algorithms
2.3. Deep Learning-Based Segmentation for USVs
- When dealing with datasets containing a large number of samples with diverse features, current deep convolutional neural network approaches are still ineffective.
- Although superpixel segmentation techniques are frequently used in image preprocessing to discover edge characteristics in images, they are rarely used in marine semantic segmentation tasks due to their inability to segment semantically.
- Despite the fact that many studies have used deep learning approaches to solve the segmentation problem of marine semantic datasets, there has been little discussion of the differences between deep convolutional neural networks with different depths in learning marine semantic features.
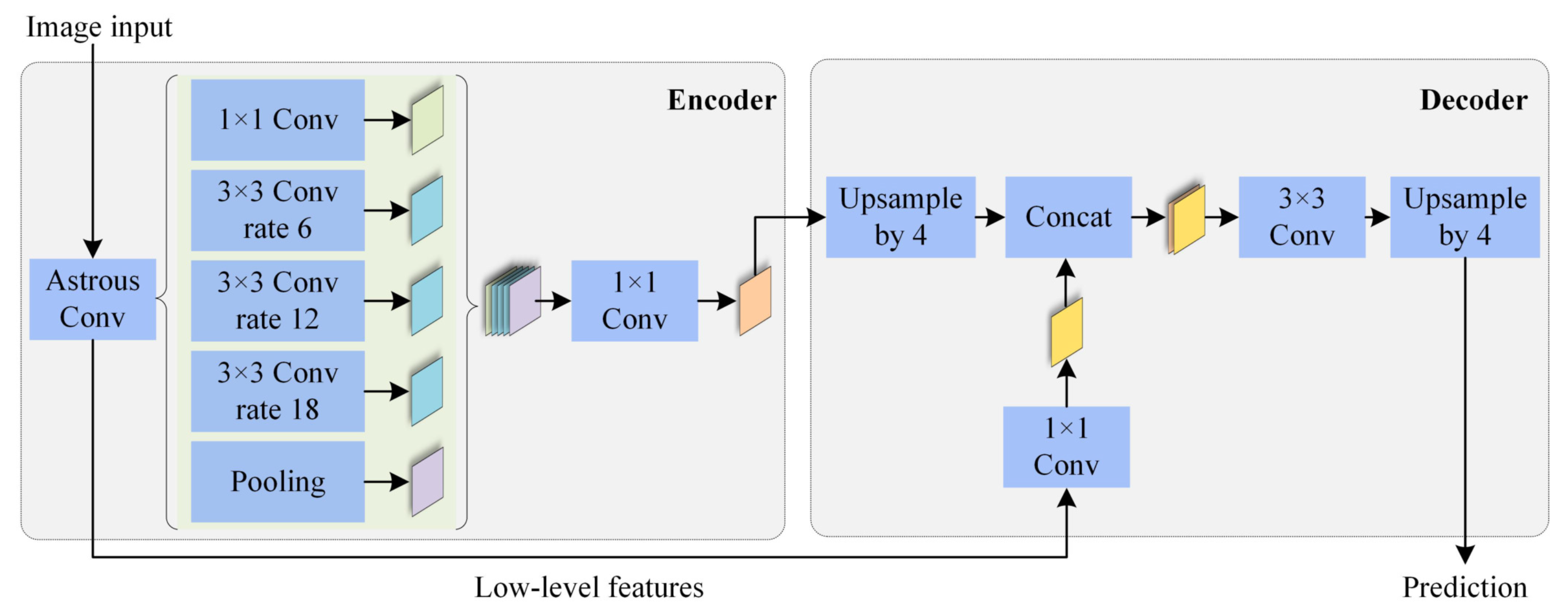
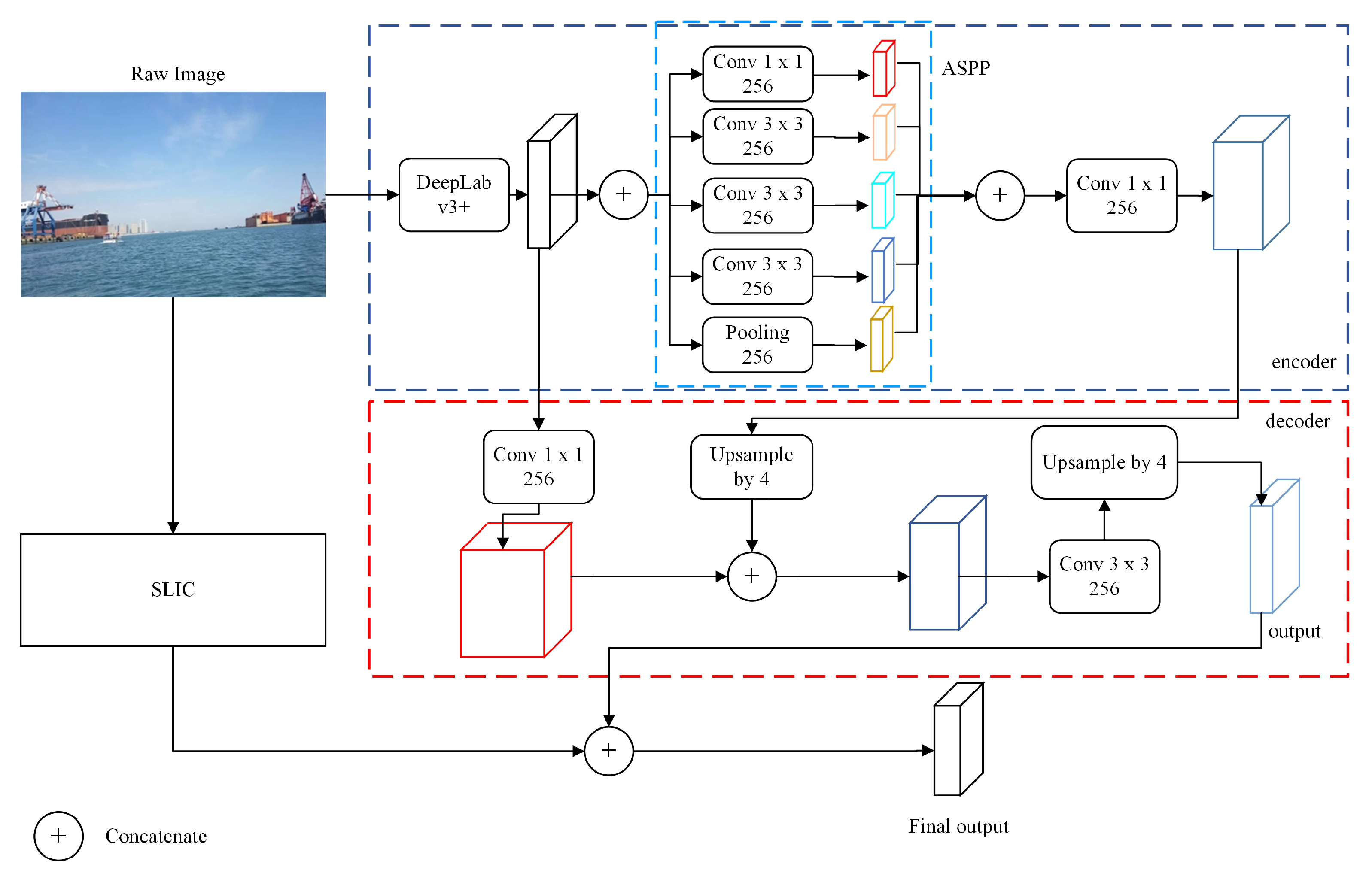
3. Method
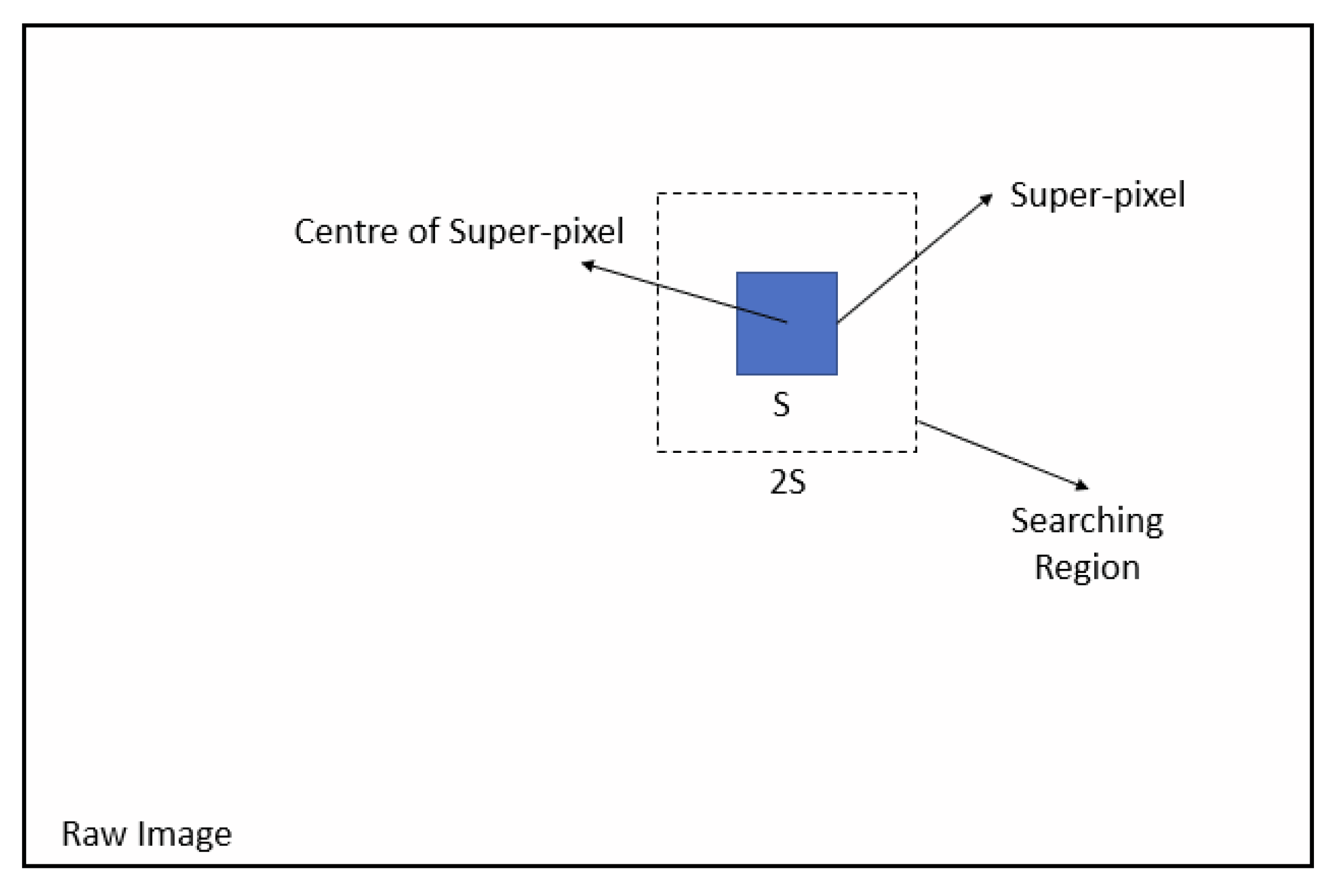
3.1. Simple Linear Iterative Clustering Algorithm
3.2. Structure of the SLIC Enabled Segmentation Model
3.3. Network Implementation
3.4. Trade-Off: Compactness and Accuracy of Superpixel Segmentation
4. Experiments and Results
4.1. Dataset and Evaluation Metrics
4.2. Data Augmentation and Training Setups
4.3. SLIC Algorithm Results
4.4. Comparisons with Original DeepLab v3+ Network
4.5. Quantitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manley, J.E. Unmanned Surface Vehicles, 15 Years of Development; OCEANS 2008; IEEE: Quebec City, QC, Canada, 2008; pp. 1–4. [Google Scholar]
- Prasad, D.K. Object Detection in a Maritime Environment: Performance Evaluation of Background Subtraction Methods. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1787–1802. [Google Scholar] [CrossRef]
- Sinisterra, A.J.; Dhanak, M.R.; von Ellenrieder, K. Stereo Vision-Based Target Tracking System for an USV; 2014 Oceans-St. John’s; IEEE: Quebec City, QC, Canada, 2014; pp. 1–7. [Google Scholar]
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar]
- Kristan, M.; Kenk, V.S.; Kovačič, S.; Perš, J. Fast image-based obstacle detection from unmanned surface vehicles. IEEE Trans. Cybern. 2015, 46, 641–654. [Google Scholar] [CrossRef] [Green Version]
- Halterman, R.; Bruch, M. Velodyne HDL-64E lidar for unmanned surface vehicle obstacle detection. Unmanned Systems Technology XII. Int. Soc. Opt. Photonics 2010, 7692, 76920D. [Google Scholar]
- Han, J.; Cho, Y.; Kim, J. Coastal SLAM with marine radar for USV operation in GPS-restricted situations. IEEE J. Ocean. Eng. 2019, 44, 300–309. [Google Scholar] [CrossRef]
- Niemeyer, M.; Arandjelović, O. Automatic semantic labelling of images by their content using non-parametric Bayesian machine learning and image search using synthetically generated image collages. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 160–168. [Google Scholar]
- Haralick, R.M.; Shapiro, L.G. Image segmentation techniques. Comput. Vis. Graph. Image Process. 1985, 29, 100–132. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Swizterland, 2015; pp. 234–241. Available online: https://arxiv.org/pdf/1505.04597.pdf (accessed on 1 October 2021).
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Malik, R. Learning a classification model for segmentation. In Proceedings of the Proceedings Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 10–17. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Moore, A.P.; Prince, S.J.; Warrell, J.; Mohammed, U.; Jones, G. Superpixel lattices. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 705–718. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Ren, C.Y.; Reid, I. gSLIC: A Real-Time Implementation of SLIC Superpixel Segmentation; Technical Report; University of Oxford, Department of Engineering: Oxford, UK, 2011; pp. 1–6. [Google Scholar]
- Lucchi, A.; Li, Y.; Smith, K.; Fua, P. Structured image segmentation using kernelized features. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 400–413. [Google Scholar]
- Thompson, D.; Coyle, E.; Brown, J. Efficient LiDAR-based object segmentation and mapping for maritime environments. IEEE J. Ocean. Eng. 2019, 44, 352–362. [Google Scholar] [CrossRef]
- Papadopoulos, G.; Kurniawati, H.; Shariff, A.S.B.M.; Wong, L.J.; Patrikalakis, N.M. 3D-surface reconstruction for partially submerged marine structures using an autonomous surface vehicle. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and SystemsE, San Francisco, CA, USA, 25–30 September 2011; pp. 3551–3557. [Google Scholar]
- Nita, C.; Vandewal, M. CNN-based object detection and segmentation for maritime domain awareness. Artificial Intelligence and Machine Learning in Defense Applications II. Int. Soc. Opt. Photonics 2020, 11543, 1154306. [Google Scholar]
- Liu, Y.; Zhang, M.h.; Xu, P.; Guo, Z.W. SAR ship detection using sea-land segmentation-based convolutional neural network. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Bousetouane, F.; Morris, B. Fast CNN surveillance pipeline for fine-grained vessel classification and detection in maritime scenarios. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 242–248. [Google Scholar]
- Cruz, G.; Bernardino, A. Aerial detection in maritime scenarios using convolutional neural networks. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Lecce, Italy, 24–27 October 2016; pp. 373–384. [Google Scholar]
- Bloisi, D.D.; Previtali, F.; Pennisi, A.; Nardi, D.; Fiorini, M. Enhancing automatic maritime surveillance systems with visual information. IEEE Trans. Intell. Transp. Syst. 2016, 18, 824–833. [Google Scholar] [CrossRef] [Green Version]
- Loomans, M.J.; de With, P.H.; Wijnhoven, R.G. Robust automatic ship tracking in harbours using active cameras. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 4117–4121. [Google Scholar]
- Bovcon, B.; Kristan, M. WaSR—A Water Segmentation and Refinement Maritime Obstacle Detection Network. IEEE Trans. Cybern. 2021, 1–14. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Y.; Achuthan, K. WODIS: Water Obstacle Detection Network Based on Image Segmentation for Autonomous Surface Vehicles in Maritime Environments. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Elkhateeb, E.; Soliman, H.; Atwan, A.; Elmogy, M.; Kwak, K.S.; Mekky, N. A Novel Coarse-to-Fine Sea-Land Segmentation Technique Based on Superpixel Fuzzy C-Means Clustering and Modified Chan-Vese Model. IEEE Access 2021, 9, 53902–53919. [Google Scholar] [CrossRef]
- Pappas, O.A.; Achim, A.M.; Bull, D.R. Superpixel-guided CFAR detection of ships at sea in SAR imagery. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1647–1651. [Google Scholar]
- Pappas, O.; Achim, A.; Bull, D. Superpixel-level CFAR detectors for ship detection in SAR imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1397–1401. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Ming, D.; Lv, X. Superpixel based land cover classification of VHR satellite image combining multi-scale CNN and scale parameter estimation. Earth Sci. Inform. 2019, 12, 341–363. [Google Scholar] [CrossRef]
- Schanda, J. Colorimetry: Understanding the CIE System; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bovcon, B.; Muhovič, J.; Perš, J.; Kristan, M. The mastr1325 dataset for training deep usv obstacle detection models. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 3431–3438. [Google Scholar]
- Choromanska, A.; Henaff, M.; Mathieu, M.; Arous, G.B.; LeCun, Y. The loss surfaces of multilayer networks. In Artificial Intelligence and Statistics; 2015; pp. 192–204. Available online: https://proceedings.mlr.press/v38/choromanska15.html (accessed on 2 June 2021).
- Bovcon, B.; Perš, J.; Kristan, M. Stereo obstacle detection for unmanned surface vehicles by IMU-assisted semantic segmentation. Robot. Auton. Syst. 2018, 104, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Li, H.; Luo, J.; Xie, S.; Sun, Y. Efficient obstacle detection based on prior estimation network and spatially constrained mixture model for unmanned surface vehicles. J. Field Robot. 2021, 38, 212–228. [Google Scholar] [CrossRef]
- Thoma, M. A survey of semantic segmentation. arXiv 2016, arXiv:1602.06541. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Drives | Parameters |
|---|---|
| CPU-inference | i7-10875H 2.3 GHz |
| GPU | Nvidia Tesla V100 |
| Deep Learning Network API | Pytorch 1.9 |
| Compile Language | Python |
| Image size | |
| Training epochs | 50 |
| Optimiser | Adam |
| Learning rate | |
| Batch size | 2 |
| Training images | 1221 |
| Validation images | 324 |
| Model | Time (s) | (%) |
|---|---|---|
| DeepLab v3+_Xception | 1.2301 | 85.5 |
| DeepLab v3+_ResNet101 | 0.6725 | 89.1 |
| DeepLab v3+_Xception + SLIC | 1.7865 | 85.9 |
| DeepLab v3+_ResNet101 + SLIC | 1.1256 | 90.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, H.; Chen, X.; Zhang, R.; Wu, P.; Li, X.; Liu, Y. Deep Learning-Based Maritime Environment Segmentation for Unmanned Surface Vehicles Using Superpixel Algorithms. J. Mar. Sci. Eng. 2021, 9, 1329. https://doi.org/10.3390/jmse9121329
Xue H, Chen X, Zhang R, Wu P, Li X, Liu Y. Deep Learning-Based Maritime Environment Segmentation for Unmanned Surface Vehicles Using Superpixel Algorithms. Journal of Marine Science and Engineering. 2021; 9(12):1329. https://doi.org/10.3390/jmse9121329
Chicago/Turabian StyleXue, Haolin, Xiang Chen, Ruo Zhang, Peng Wu, Xudong Li, and Yuanchang Liu. 2021. "Deep Learning-Based Maritime Environment Segmentation for Unmanned Surface Vehicles Using Superpixel Algorithms" Journal of Marine Science and Engineering 9, no. 12: 1329. https://doi.org/10.3390/jmse9121329
APA StyleXue, H., Chen, X., Zhang, R., Wu, P., Li, X., & Liu, Y. (2021). Deep Learning-Based Maritime Environment Segmentation for Unmanned Surface Vehicles Using Superpixel Algorithms. Journal of Marine Science and Engineering, 9(12), 1329. https://doi.org/10.3390/jmse9121329