
An Estimation of Ship Collision Risk Based on Relevance Vector Machine



Abstract
:1. Introduction
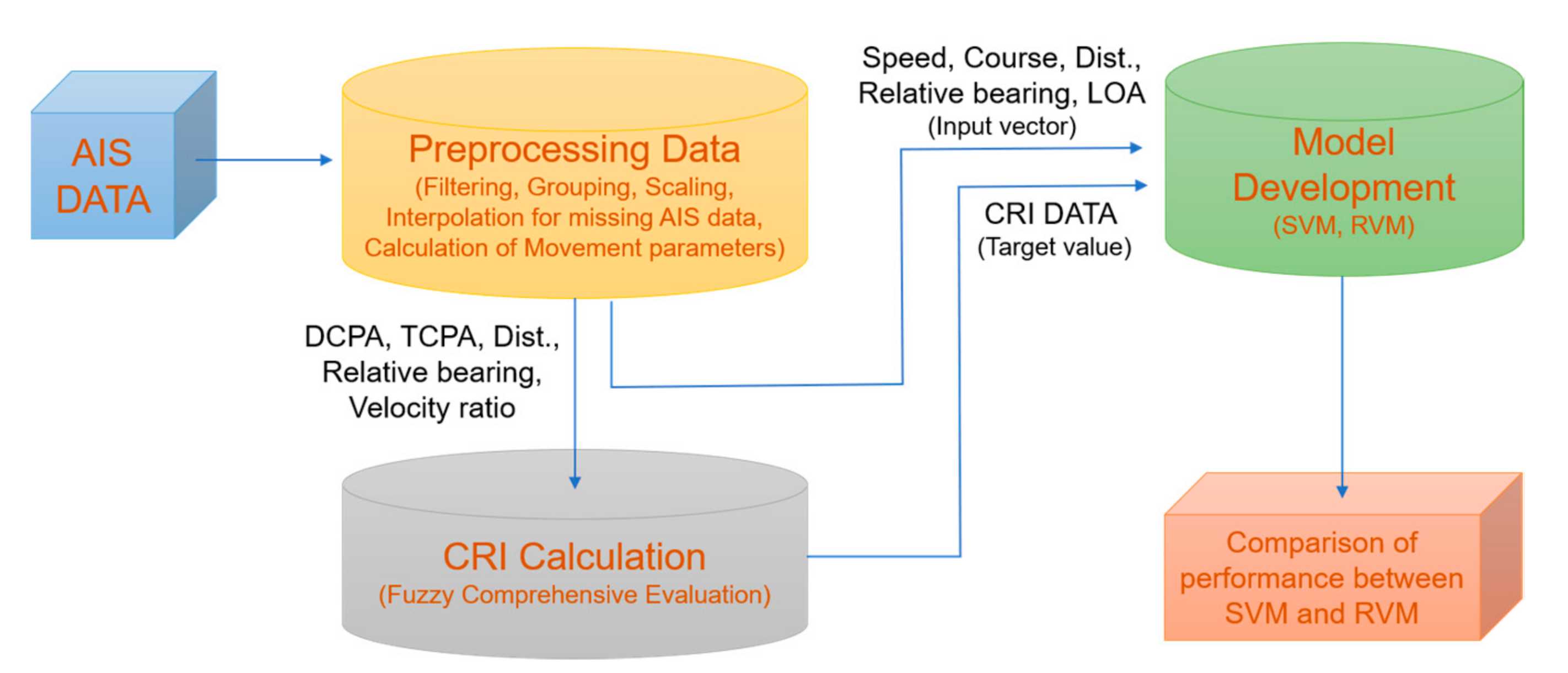
2. Methodology
2.1. Preprocessing AIS Data
2.2. CRI Calculation
2.3. Model Development
2.3.1. SVM Regression
2.3.2. RVM Regression
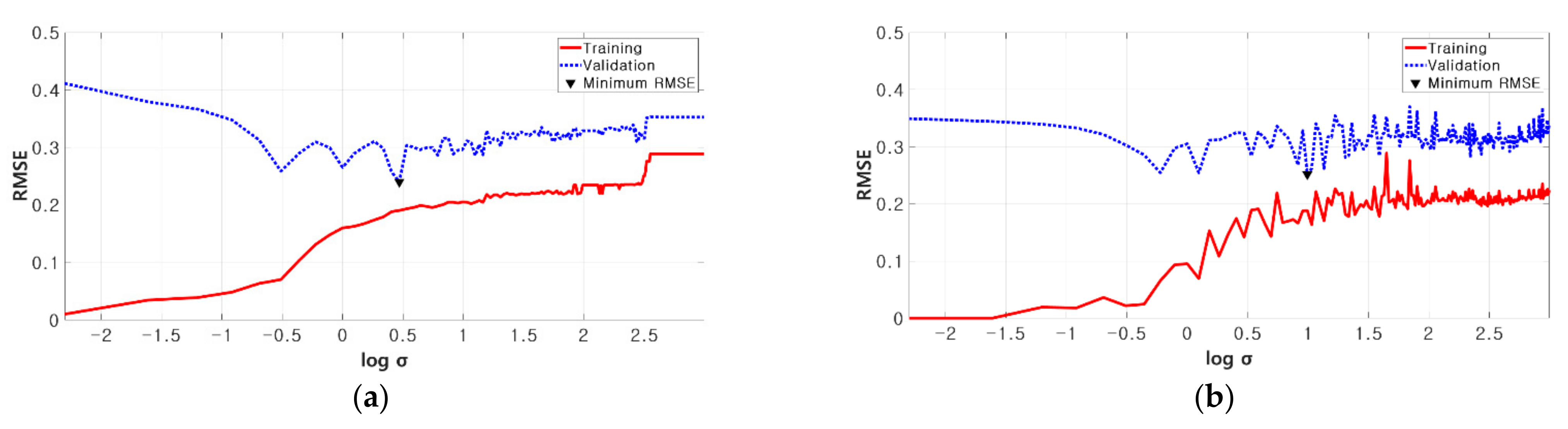
2.4. Parameter Optimization
3. Simulations and Results
3.1. Data Collection
3.2. Results of Model Development
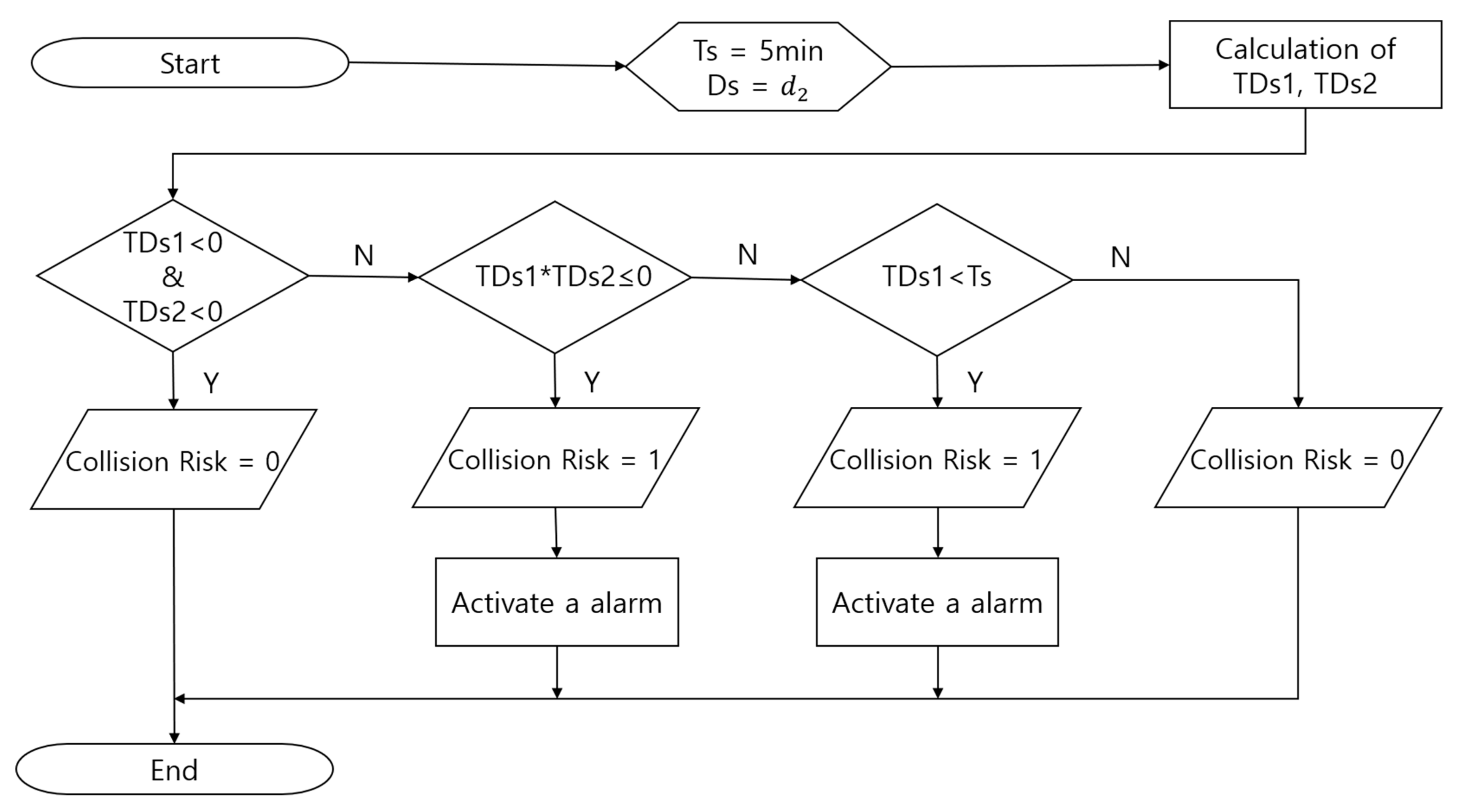
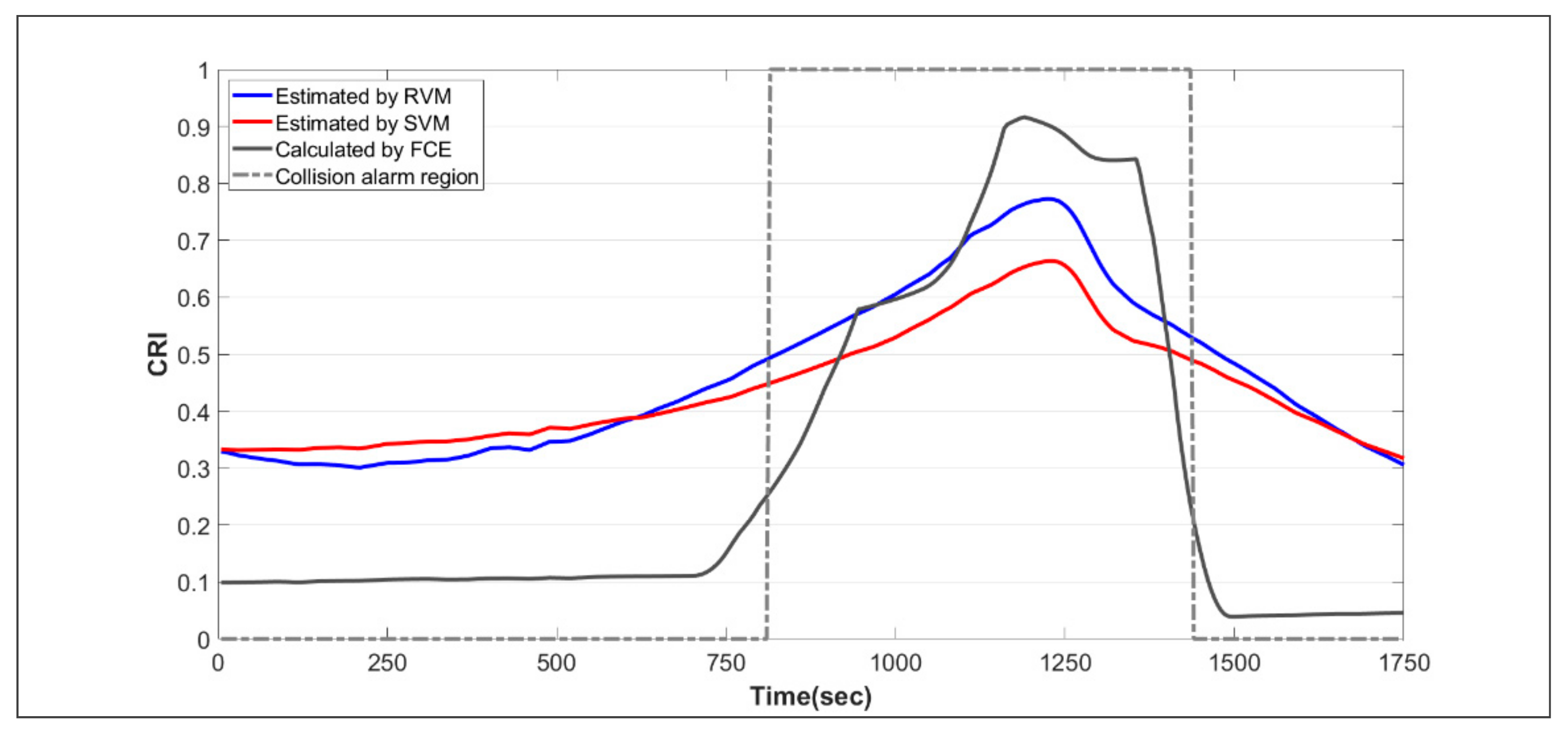
3.3. Model Validation
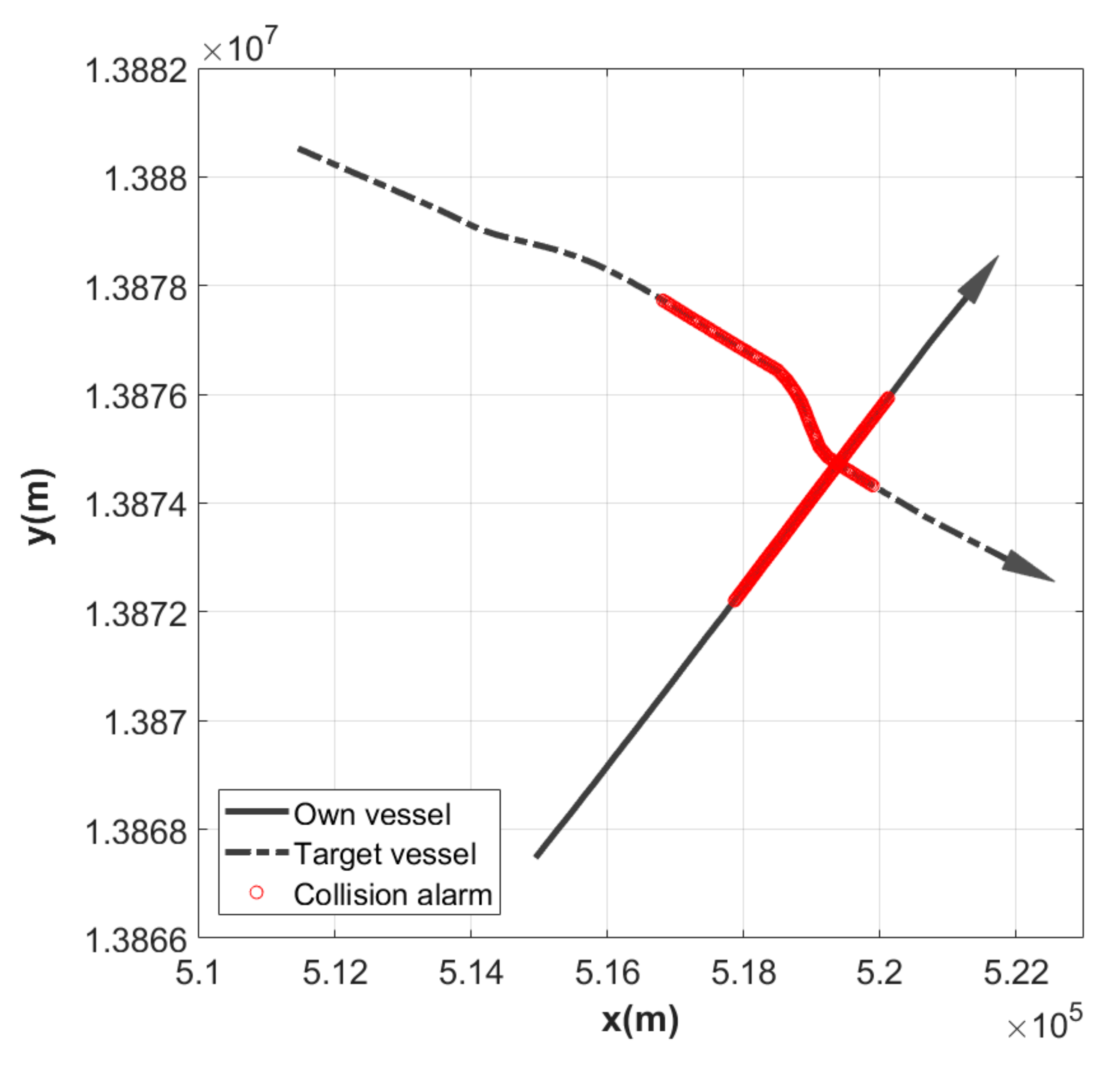
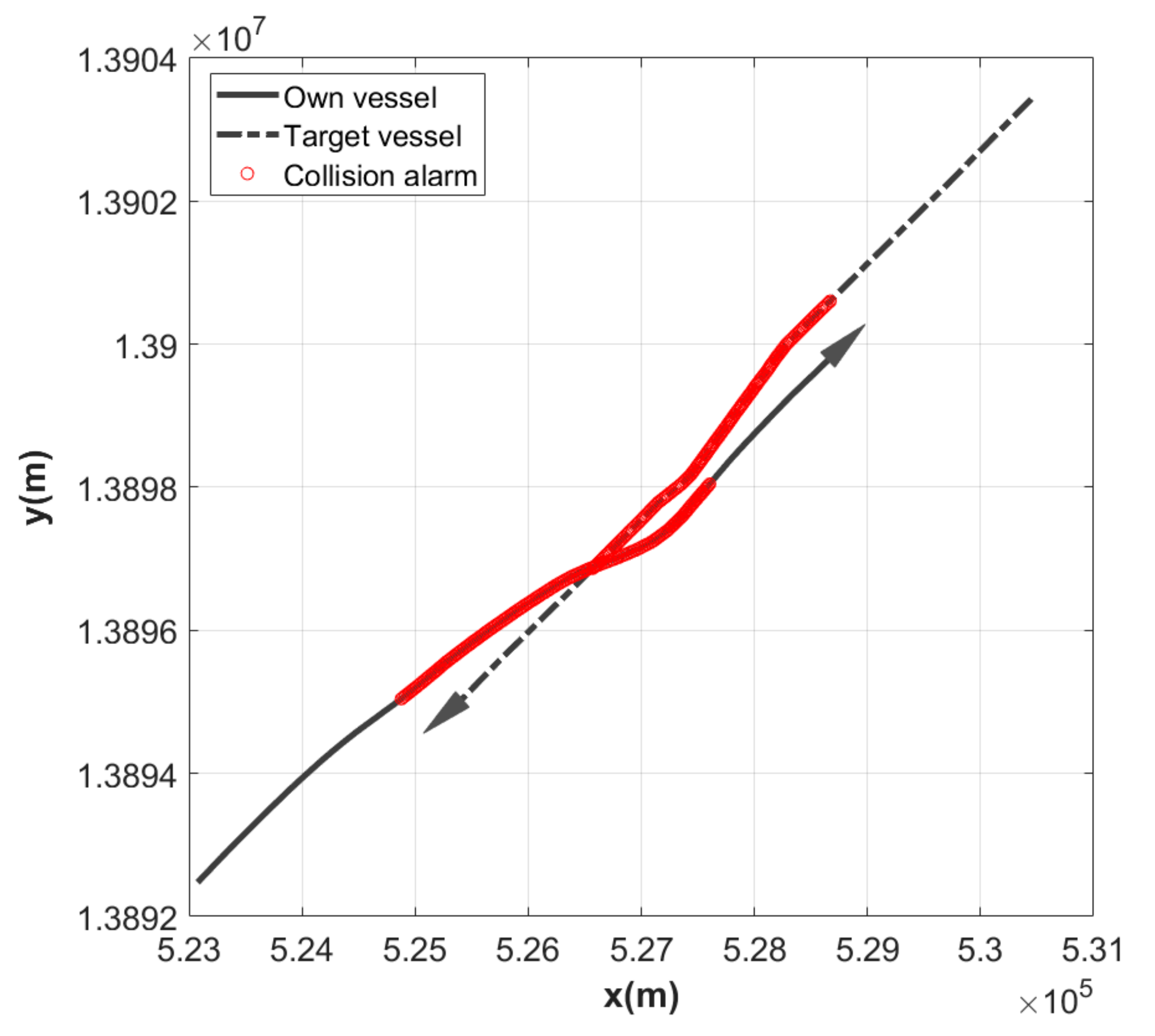
3.4. Results of Simulations
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IMO (International Maritime Organization). COLREGS—International Regulations for Preventing Collisions at Sea. In Convention on the International Regulations for Preventing Collisions at Sea; IMO (International Maritime Organization): London, UK, 1972; pp. 1–74. [Google Scholar]
- KMST (Korean Maritime Safety Tribunal). 2020 Annual Report of Marine Accident Statistics. Available online: https://www.kmst.go.kr (accessed on 10 March 2020).
- Gang, L.; Wang, Y.; Sun, Y.; Zhou, L.; Zhang, M. Estimation of vessel collision risk index based on support vector machine. Adv. Mech. Eng. 2016, 8, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Ahn, J.H.; Rhee, K.P.; You, Y.J. A study on the collision avoidance of a ship using neural networks and fuzzy logic. Appl. Ocean Res. 2012, 37, 162–173. [Google Scholar] [CrossRef]
- Li, C.; Li, W.; Ning, J. Calculation of Ship Collision Risk Index Based on Adaptive Fuzzy Neural Network; Atlantis Press: Paris, France, 2018. [Google Scholar]
- Kearon, J. Computer program for collision avoidance and track keeping. In Proceedings of the International Conference on Mathematics Aspects of Marine Traffic; Academic Press: London, UK, 1977; pp. 229–242. [Google Scholar]
- Imazu, H.; Koyama, T. The Determination of Collision Avoidance Action. J. Jpn. Inst. Navig. 1984, 70, 31–37. [Google Scholar] [CrossRef] [Green Version]
- Zec, D. An Algorithm for a Real-Time Detection of Encounter Situations. J. Navig. 1996, 49, 121–126. [Google Scholar] [CrossRef] [Green Version]
- Chin, H.C.; Debnath, A.K. Modeling perceived collision risk in port water navigation. Saf. Sci. 2009, 47, 1410–1416. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Meng, X.; Wang, N. Intelligent evaluation system of ship management. Mar. Navig. Saf. Sea Transp. 2009, 4, 787–790. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, W.; Shi, P. A real-time collision avoidance learning system for Unmanned Surface Vessels. Neurocomputing 2016, 182, 255–266. [Google Scholar] [CrossRef]
- Li, B.; Pang, F.W. An approach of vessel collision risk assessment based on the D-S evidence theory. Ocean Eng. 2013, 74, 16–21. [Google Scholar] [CrossRef]
- Zadeh, L.A. Simple View of the Dempster-Shafer Theory of Evidence and Its Implication for the Rule of Combination. AI Mag. 1986, 7, 85–90. [Google Scholar]
- Voorbraak, F. On the justification of Dempster’s rule of combination. Artif. Intell. 1991, 48, 171–197. [Google Scholar] [CrossRef] [Green Version]
- Tipping, M.E. The relevance vector machine. In Proceedings of the Advances in Neural Information Processing Systems; Solla, S.A., Leen, T.K., Müller, K.-R., Eds.; MIT Press: Cambridge, MA, USA, 2000; Volume 12, pp. 653–658. [Google Scholar]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.H.; Wu, C.J. The construction of the collision risk factor model. J. Ningbo Univ. 2004, 17, 61–65. [Google Scholar]
- Ren, Y.; Mou, J.; Yan, Q.; Zhang, F. Study on assessing dynamic risk of ship collision. In Proceedings of the ICTIS 2011: Multimodal Approach to Sustained Transportation System Development: Information, Technology, Implementation, Wuhan, China, 30 June–2 July 2011; pp. 2751–2757. [Google Scholar]
- IMO (International Maritime Organization). Adoption of New and Amended Performance Standards for Navigational Equipment; IMO (International Maritime Organization): London, UK, 1998; Volume 86, pp. 13–16. [Google Scholar]
- Lenart, A.S. Analysis of Collision Threat Parameters and Criteria. J. Navig. 2015, 68, 887–896. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Jeong, J. Assessment of Ship Collision Risk in Coastal Waters by Fuzzy Comprehensive Evaluation. J. Korean Inst. Intell. Syst. 2020, 30, 325–330. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the Analytic Hierarchy Process. Int. J. Serv. Sci. 2008, 1, 83–98. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, M.; Zhang, S.; Wang, X. A novel method for risk assessment and simulation of collision avoidance for vessels based on AIS. Algorithms 2018, 11, 204. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Vapnik, V. Estimation of Dependences Based on Empirical Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006; ISBN 0387342397. [Google Scholar]
- Vapnik, V.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Ministry of Oceans and Fisheries Statistics of Vessels Arrival and Departure at Major Port of Korea. Available online: http://www.mof.go.kr (accessed on 8 January 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Year | Busan | Ulsan | Gwangyang | Incheon | Pyeongtaek |
|---|---|---|---|---|---|---|
| No. of vessel entry/ departure | 2014 | 95,378 | 51,565 | 46,746 | 35,363 | 18,591 |
| 2015 | 98,087 | 51,525 | 48,229 | 37,560 | 19,383 | |
| 2016 | 100,197 | 50,495 | 52,263 | 37,407 | 19,924 | |
| 2017 | 99,687 | 48,182 | 51,269 | 36,215 | 19,442 | |
| 2018 | 94,816 | 46,664 | 48,225 | 31,351 | 18,829 | |
| Total | 488,165 | 248,431 | 246,732 | 177,896 | 96,169 | |
| No. of marine accidents | 2014 | 45 | 25 | 6 | 14 | 1 |
| 2015 | 66 | 58 | 11 | 22 | 5 | |
| 2016 | 85 | 47 | 13 | 37 | 11 | |
| 2017 | 52 | 52 | 27 | 22 | 10 | |
| 2018 | 19 | 30 | 16 | 43 | 20 | |
| Total | 267 | 212 | 73 | 138 | 47 |
| Method | Elapsed Time (min) | SVs/RVs | MAE | RMSE | |
|---|---|---|---|---|---|
| SVM | 2.7 | 8.73 | 634 | 0.2349 | 0.2518 |
| RVM | 1.6 | 0.14 | 129 | 0.2145 | 0.2401 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Jeong, J.-S. An Estimation of Ship Collision Risk Based on Relevance Vector Machine. J. Mar. Sci. Eng. 2021, 9, 538. https://doi.org/10.3390/jmse9050538
Park J, Jeong J-S. An Estimation of Ship Collision Risk Based on Relevance Vector Machine. Journal of Marine Science and Engineering. 2021; 9(5):538. https://doi.org/10.3390/jmse9050538
Chicago/Turabian StylePark, Jinwan, and Jung-Sik Jeong. 2021. "An Estimation of Ship Collision Risk Based on Relevance Vector Machine" Journal of Marine Science and Engineering 9, no. 5: 538. https://doi.org/10.3390/jmse9050538
APA StylePark, J., & Jeong, J. -S. (2021). An Estimation of Ship Collision Risk Based on Relevance Vector Machine. Journal of Marine Science and Engineering, 9(5), 538. https://doi.org/10.3390/jmse9050538