
A Comparative Study of Statistical Techniques for Prediction of Meteorological and Oceanographic Conditions: An Application in Sea Spray Icing


Abstract
:1. Introduction
2. Methods
2.1. Bayesian Inference
Gaussian Data-Generating Process
- : mean of the data-generating process;
- : known variance of the data-generating process;
- : hyper-parameters of Gaussian prior distribution;
- : sample mean;
- : hyper-parameters of Gaussian posterior distribution;
- : parameters of Gaussian predictive distribution.
2.2. Sequential Importance Sampling
2.2.1. Sequential Importance Sampling for Markov Processes
2.3. Markov Chain Monte Carlo
2.3.1. The Metropolis–Hastings Algorithm
2.3.2. Convergence Diagnostic
2.4. Proposed Models
2.4.1. Proposed Bayesian Approach
2.4.2. Proposed Sequential Importance Sampling Algorithm
| Algorithm 1 Proposed sequential importance sampling (SIS) for prediction of meteorological and oceanographic conditions. |
|
2.4.3. Proposed Markov Chain Monte Carlo Algorithm
| Algorithm 2 Proposed Markov chain Monte Carlo (MCMC) for prediction of meteorological and oceanographic conditions. |
|
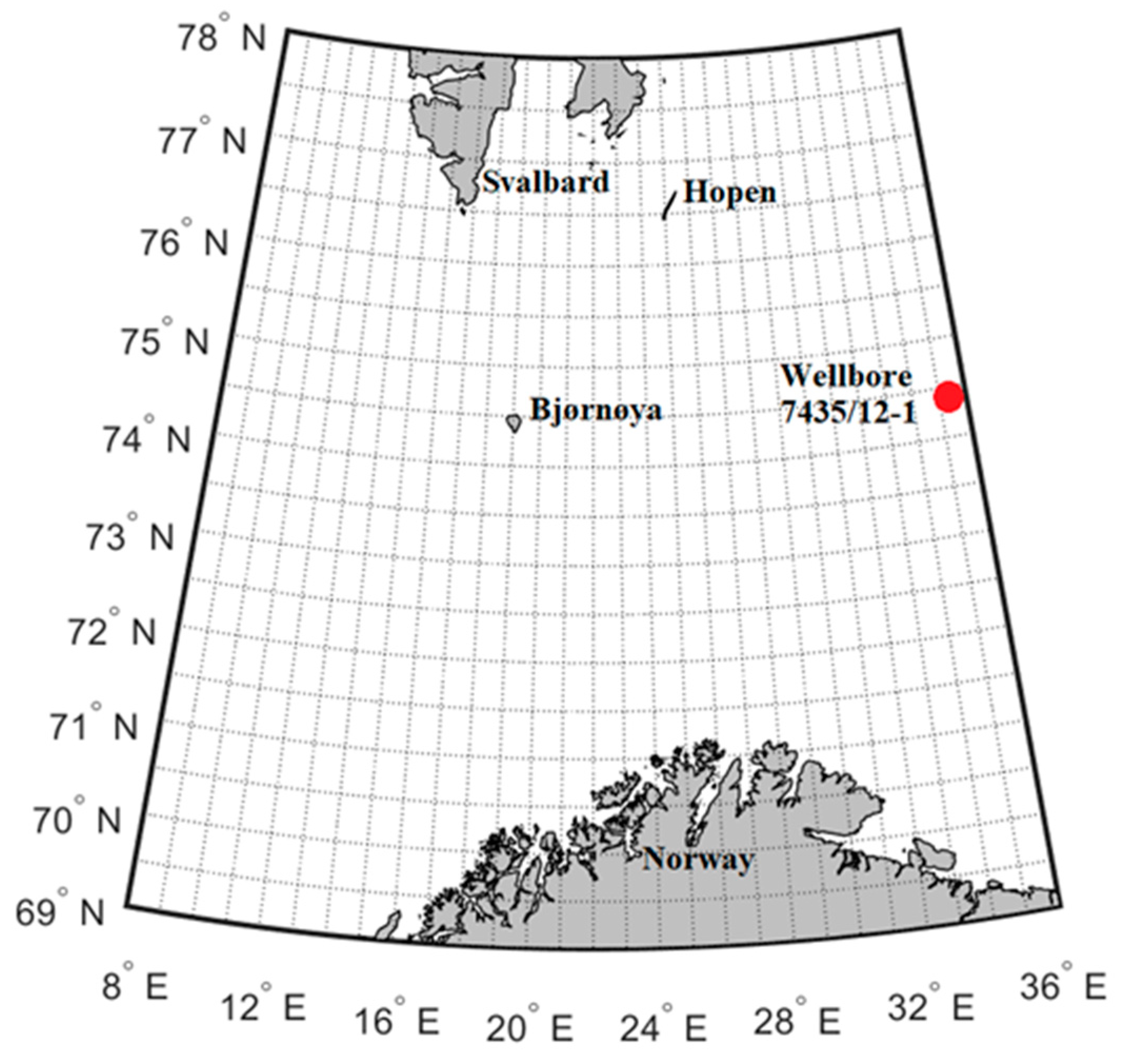
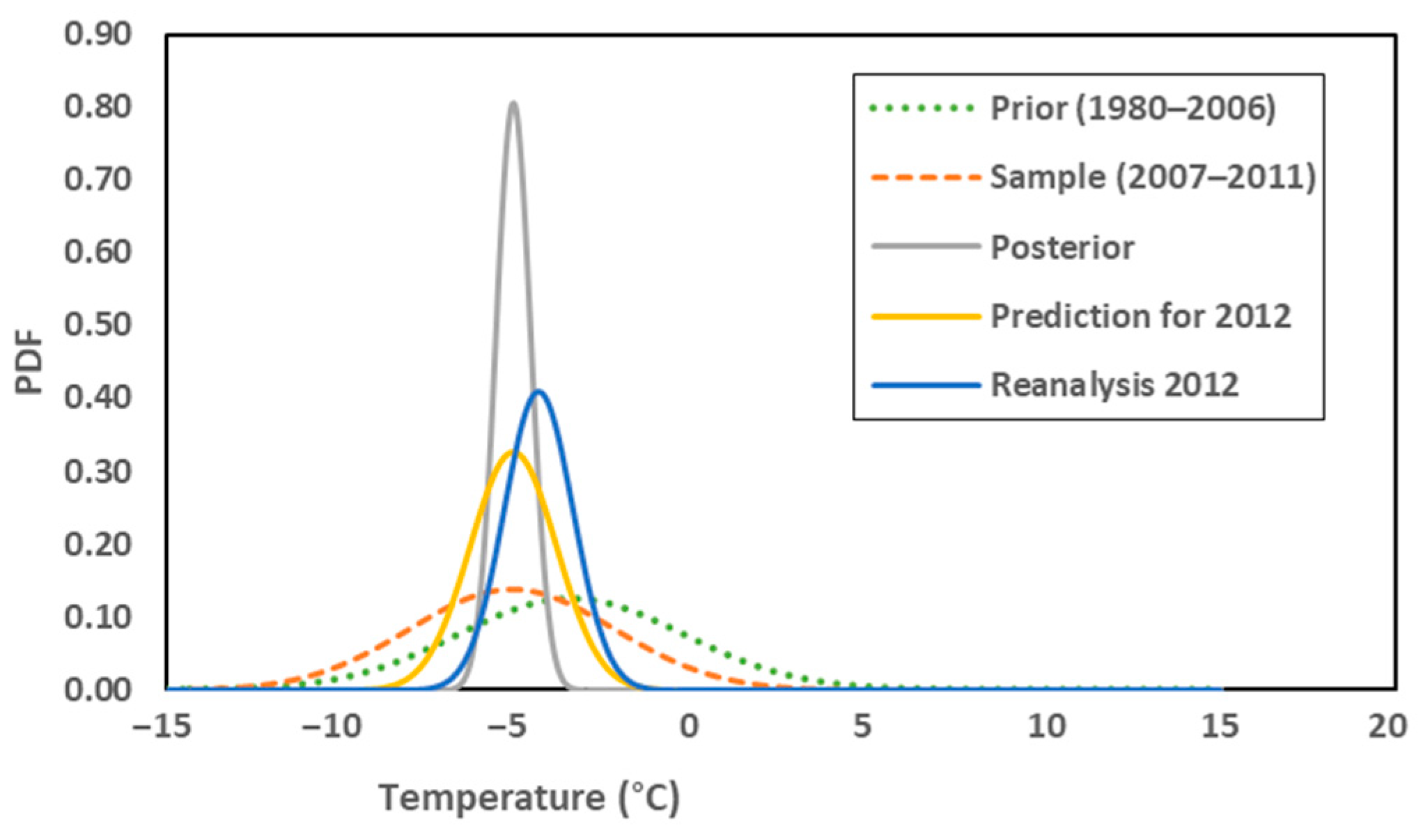
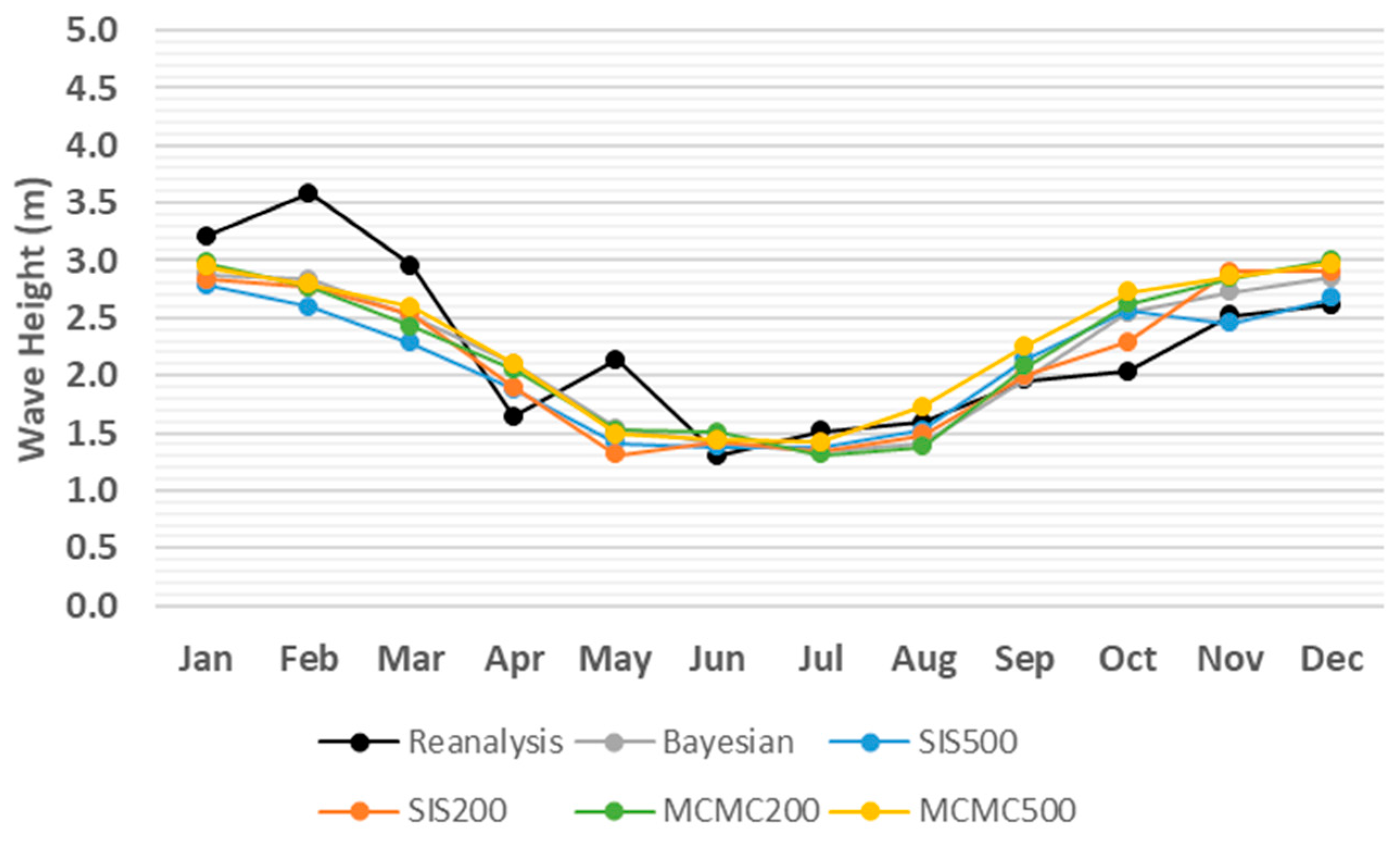
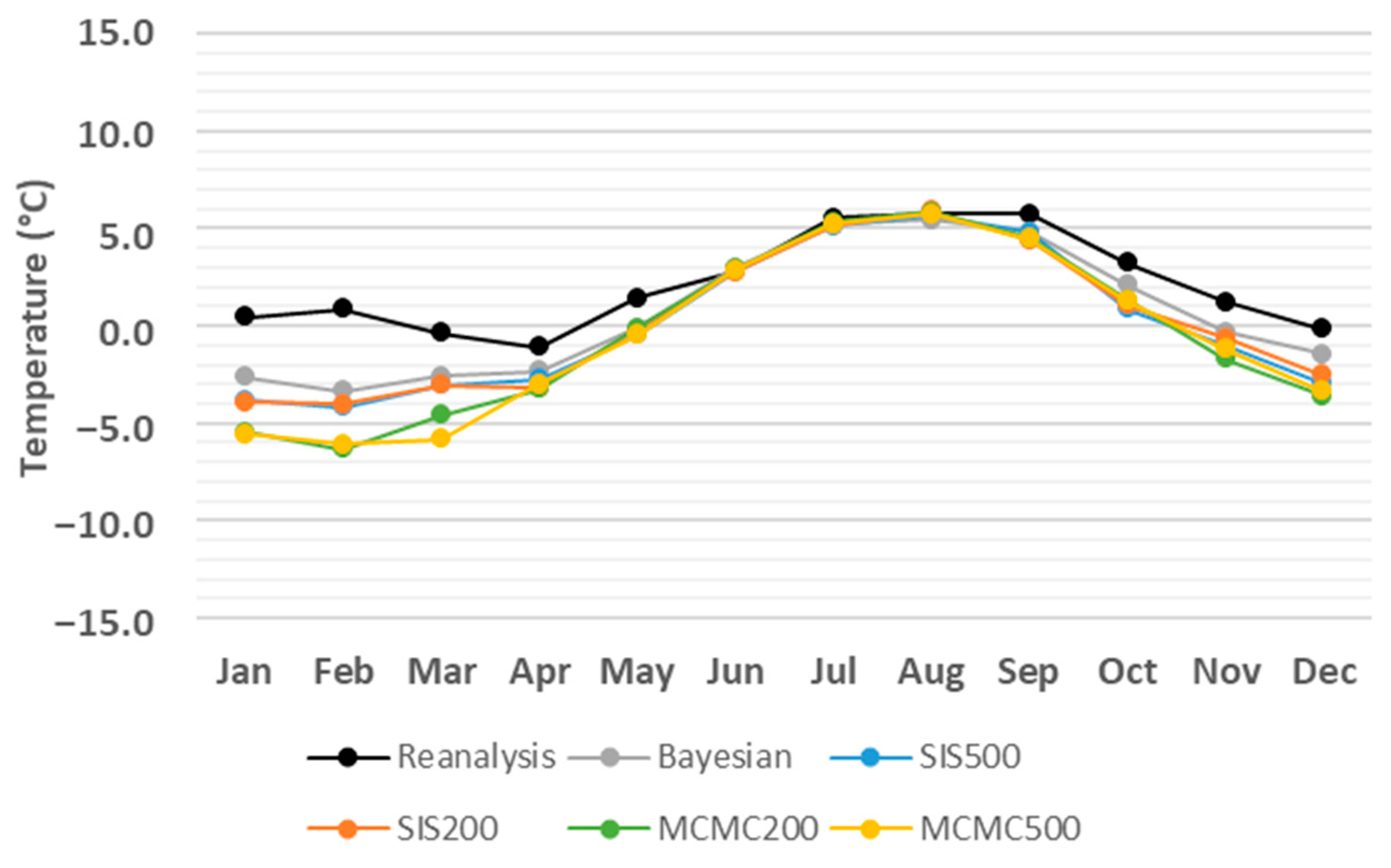
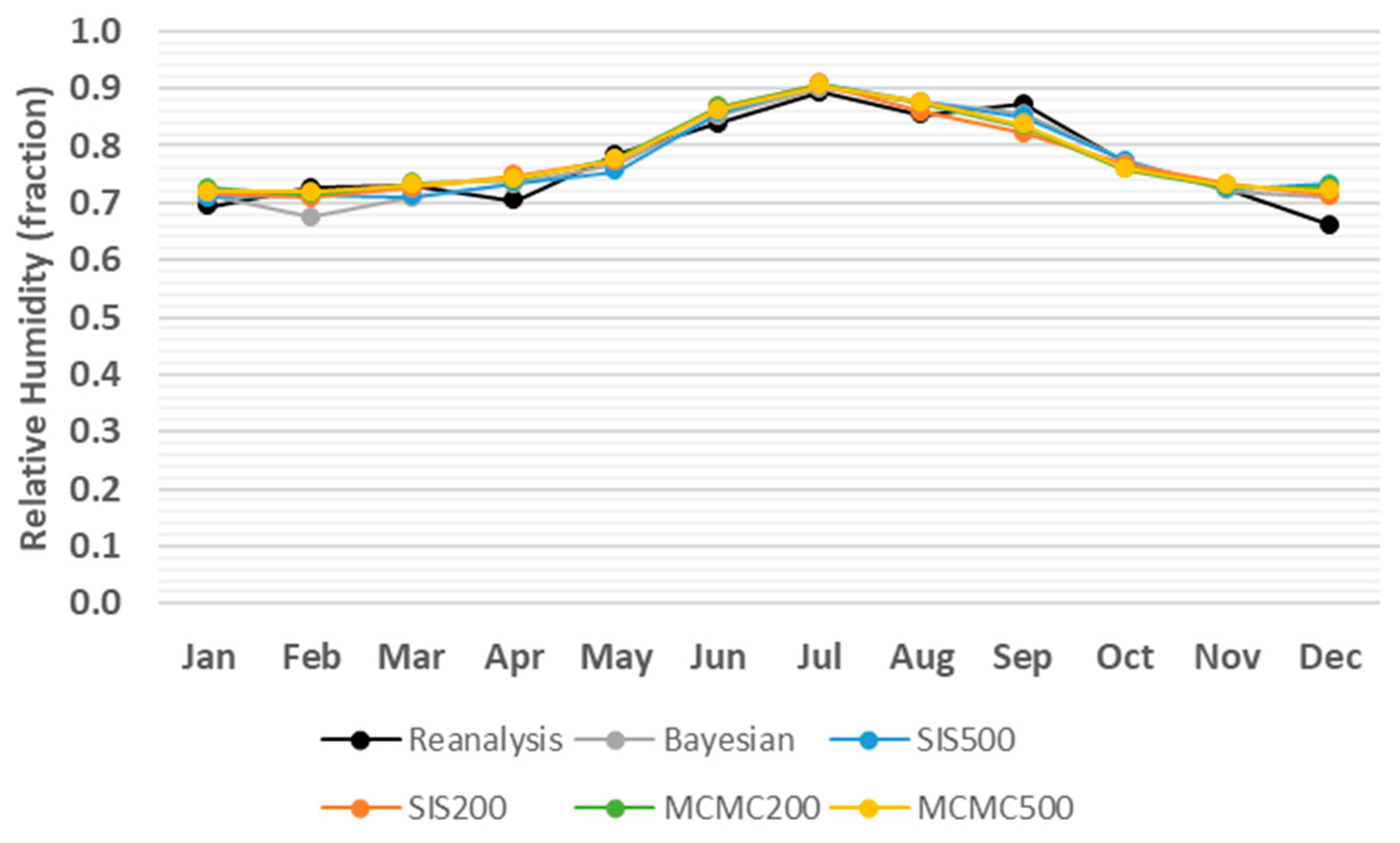
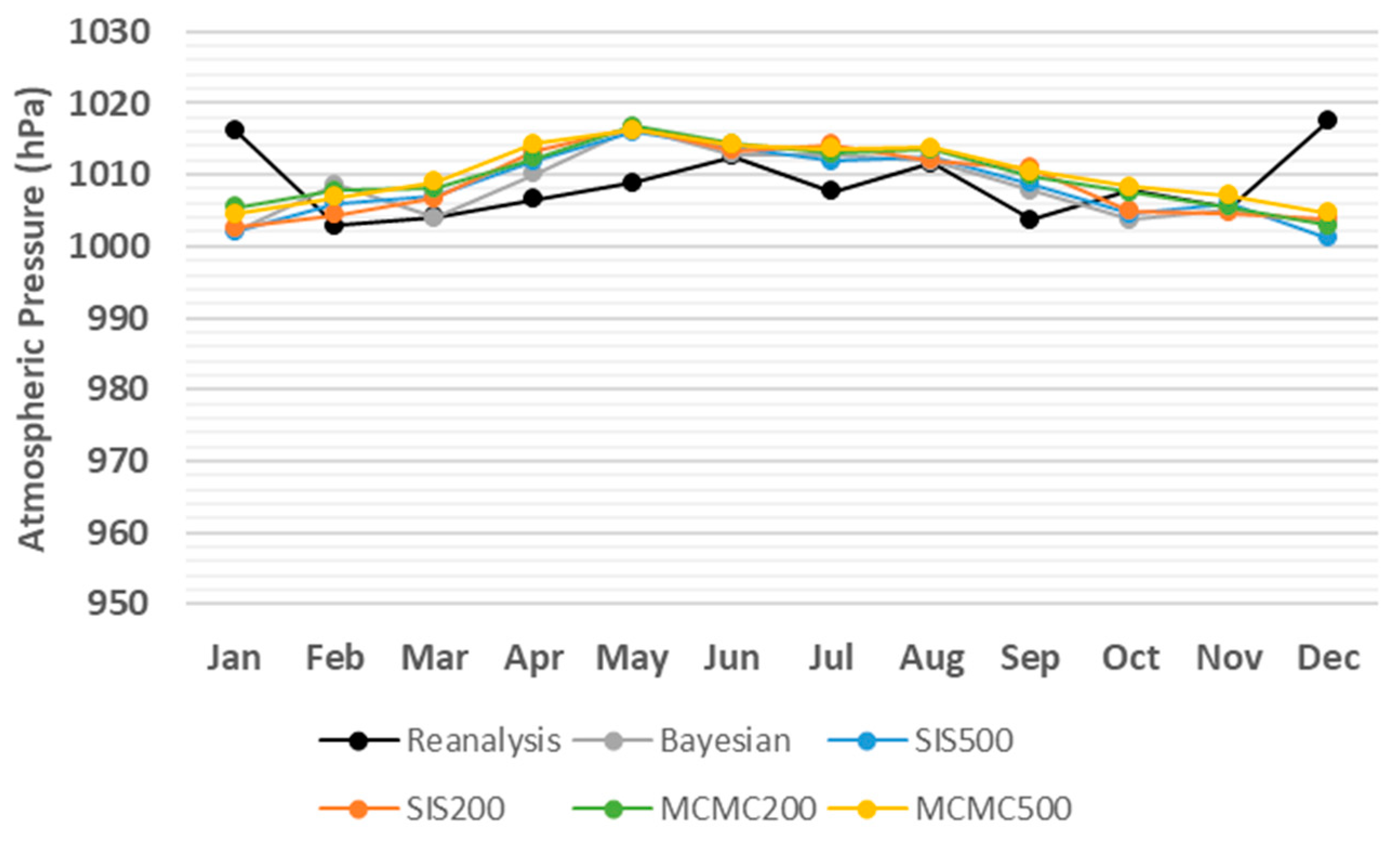
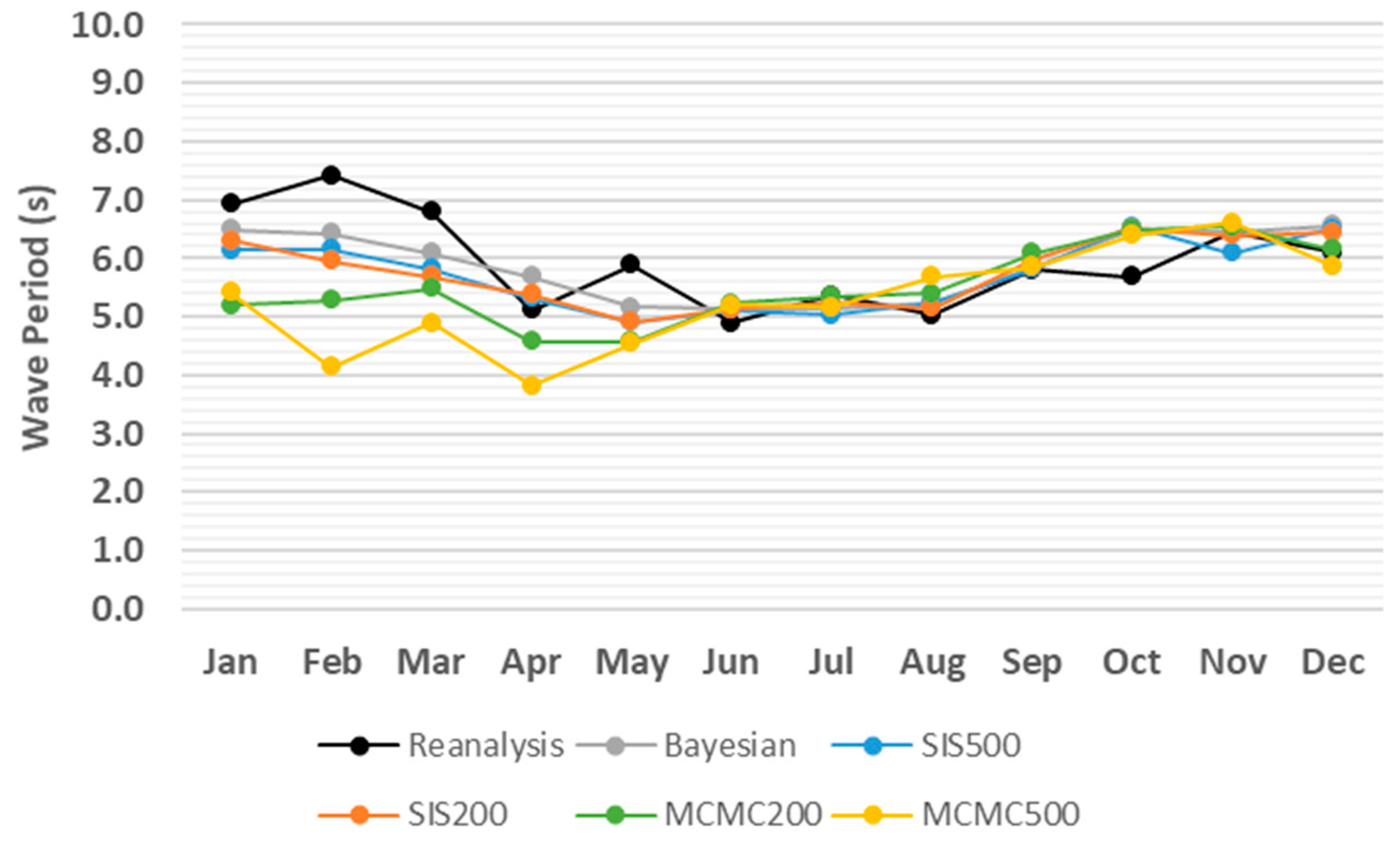
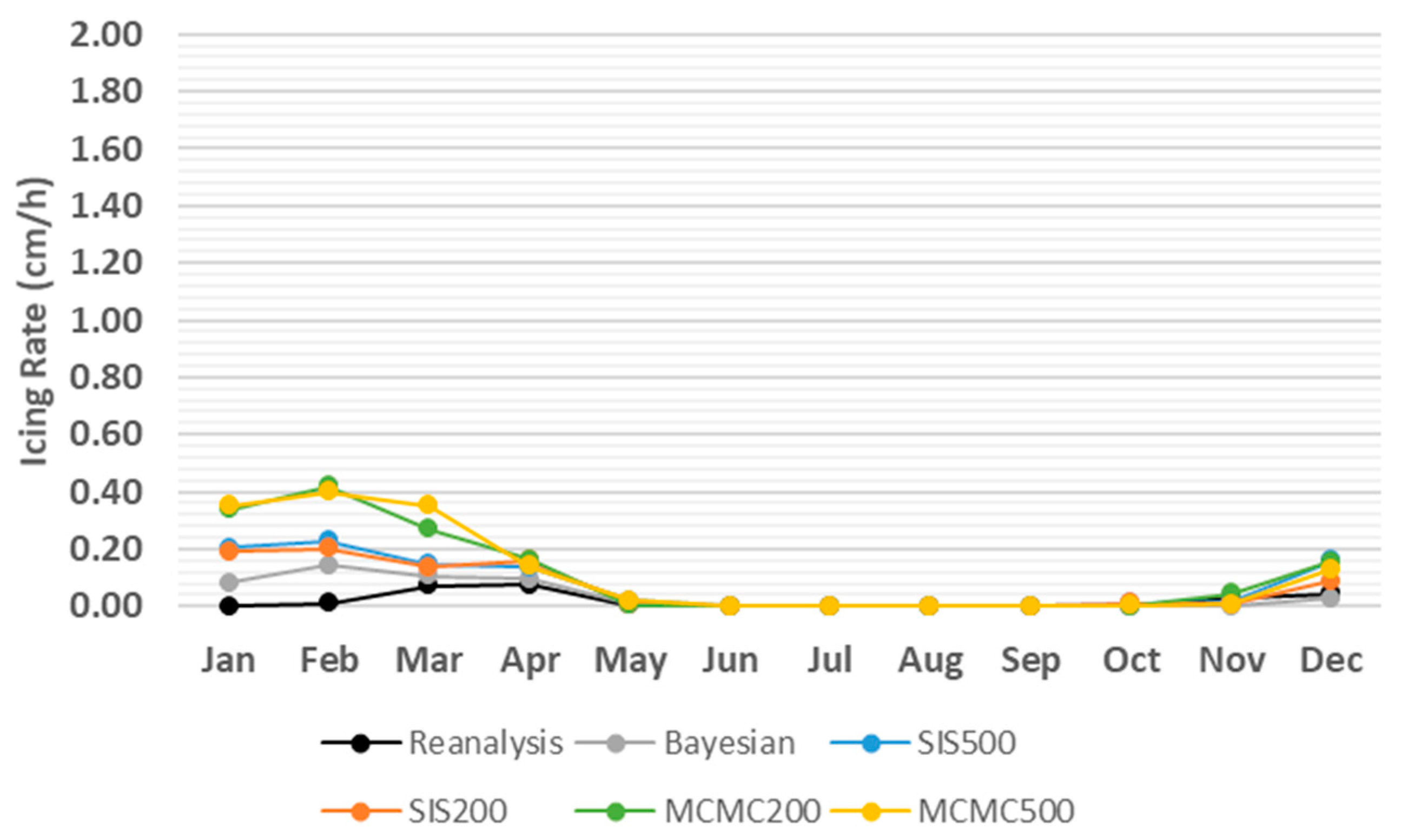
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| List of Acronyms. | |
| Acronym | Meaning |
| AAD | Average Absolute Deviation |
| ACO | Ant Colony Optimization |
| CV | Coefficient of Variation |
| DOE | Design of Experiments |
| IS | Importance Sampling |
| MCDM | Multi-Criteria Decision-Making |
| MCMC | Markov Chain Monte Carlo |
| MCMC200 | Markov Chain Monte Carlo with 200 iterations |
| MCMC500 | Markov Chain Monte Carlo with 500 iterations |
| MCS | Monte Carlo Simulation |
| MINCOG | Marine-Icing model for the Norwegian COast Guard |
| MLE | Maximum Likelihood Estimation |
| NORA10 | NOrwegian ReAnalysis 10 km |
| NSR | Northern Sea Route |
| RAMS | Reliability, Availability, Maintainability, and Safety |
| Probability Density Function | |
| RAMS | Reliability, Availability, Maintainability, and Safety |
| SIR | Sampling Importance Resampling |
| SIS | Sequential Importance Sampling |
| SIS200 | Sequential Importance Sampling with 200 iterations |
| SIS500 | Sequential Importance Sampling with 500 iterations |
| SMC | Sequential Monte Carlo |
| List of Symbols. | |
| Symbol | Meaning |
| The parameters of the Weibull distribution | |
| A positive value, which is needed to shift the data in Weibull estimation; since the Weibull distribution does not support non-positive values. | |
| CV for the last drawn samples in the MCMC algorithm iterations | |
| A threshold for CV | |
| The number of days in a year, which adopts the values 365 and 366 for normal and leap years, respectively. | |
| The daily mean of the parameter at time in year . Here, ‘time’ is referring to ‘day’. | |
| Deviation of from its value at time ‘’ in year . Here, ‘time’ is referring to ‘day’. | |
| The expected value of | |
| The expected value of a quantity of interest, , with respect to | |
| A target density | |
| Prior distribution of the parameter | |
| Posterior distribution of the parameter given the data | |
| The likelihood function of the data in hand, given the parameter | |
| Target density of a discrete-time sequential random variable at time | |
| Proposal density or envelope for | |
| Proposal density or envelope for | |
| An arbitrary function | |
| Indices for hyper-parameters | |
| H0 | The null hypothesis in the Anderson-Darling test of hypothesis |
| H1 | The alternative hypothesis in the Anderson-Darling test of hypothesis |
| Subscript index for samples; | |
| The weighted average of all drawn samples until iteration for , using IS weights | |
| Subscript index as iteration counter of algorithms; | |
| Center of the bin in the kernel density estimation | |
| Number of iterations of an algorithm | |
| MCMC estimation for at time | |
| Sample size | |
| p | The parameter of Binomial distribution |
| Possible values (i.e. state space) for the parameter in the SIS algorithm at time in year . Here, ‘time’ is referring to ‘day’. The values are based on the historical deviations from the daily mean of the parameter in the previous day. | |
| Sample standard deviation of | |
| Set of for all years; | |
| SIS estimation for at time | |
| Superscript index for the time in a discrete-time sequential process. Without loss of generality, ‘time’ is referring to ‘day’ in this study. | |
| IS weight for in a Markov process | |
| IS weight for in a Markov process for a drawn sample in iteration | |
| IS weight for a drawn sample in iteration | |
| IS weight for | |
| IS weight for in iteration | |
| Set of from iterations of SIS algorithm; | |
| The available data on the dataset | |
| The ith sample of | |
| Unobserved data of the random variable in the future | |
| A sample for | |
| Sample mean | |
| A random variable | |
| A discrete-time sequential random variable at time | |
| A discrete-time stochastic process representing the entire history of the sequence of a random variable | |
| A sample for | |
| The ith sample for | |
| Superscript index for years; | |
| Number of years from the dataset that are used for estimation | |
| Subscript index for bins in the kernel density estimation | |
| Acceptance probability in the Metropolis-Hastings algorithm | |
| Generic parameter that is supposed to be estimated | |
| A drawn sample for parameter , which might be accepted or rejected | |
| An accepted sample for parameter in iteration | |
| The parameter of Poisson distribution | |
| Mean of the data-generating process | |
| Hyper-parameters of Gaussian prior distribution | |
| Hyper-parameters of Gaussian posterior distribution | |
| Parameters of Gaussian predictive distribution | |
| Parameters of reanalysis values in 2012 | |
| The known variance of the data-generating process | |
References
- Sevastyanov, D.V. Arctic Tourism in the Barents Sea region: Current Situation and Boundaries of the Possible. Arct. North 2020, 39, 26–36. [Google Scholar] [CrossRef]
- Ryerson, C.C. Ice protection of offshore platforms. Cold Reg. Sci. Technol. 2011, 65, 97–110. [Google Scholar] [CrossRef]
- Dehghani-Sanij, A.R.; Dehghani, S.R.; Naterer, G.F.; Muzychka, Y.S. Sea spray icing phenomena on marine vessels and offshore structures: Review and formulation. Ocean Eng. 2017, 132, 25–39. [Google Scholar] [CrossRef]
- Heinrich, H. Industrial Accident Prevention: A Scientific Approach, 3rd ed.; McGraw Hill: New York, NY, USA, 1950. [Google Scholar]
- Chatterton, M.; Cook, J.C. The Effects of Icing on Commercial Fishing Vessels; Worcester Polytechnic Institute: Worcester, UK, 2008. [Google Scholar]
- Barabadi, A.; Garmabaki, A.; Zaki, R. Designing for performability: An icing risk index for Arctic offshore. Cold Reg. Sci. Technol. 2016, 124, 77–86. [Google Scholar] [CrossRef]
- Rashid, T.; Khawaja, H.A.; Edvardsen, K. Review of marine icing and anti-/de-icing systems. J. Mar. Eng. Technol. 2016, 15, 79–87. [Google Scholar] [CrossRef]
- Samuelsen, E.M.; Edvardsen, K.; Graversen, R.G. Modelled and observed sea-spray icing in Arctic-Norwegian waters. Cold Reg. Sci. Technol. 2017, 134, 54–81. [Google Scholar] [CrossRef] [Green Version]
- Mertins, H.O. Icing on fishing vessels due to spray. Mar. Obs. 1968, 38, 128–130. [Google Scholar]
- Stallabrass, J.R. Trawler Icing: A Compilation of Work Done at N.R.C.; Mechanical Engineering Report MD-56; National Research Conseil: Ottawa, ON, Canada, 1980. [Google Scholar]
- Sultana, K.R.; Dehghani, S.R.; Pope, K.; Muzychka, Y.S. A review of numerical modelling techniques for marine icing applications. Cold Reg. Sci. Technol. 2018, 145, 40–51. [Google Scholar] [CrossRef]
- Kulyakhtin, A.; Tsarau, A. A time-dependent model of marine icing with application of computational fluid dynamics. Cold Reg. Sci. Technol. 2014, 104–105, 33–44. [Google Scholar] [CrossRef] [Green Version]
- Horjen, I. Numerical Modelling of Time-Dependent Marine Icing, Anti-Icing and De-Icing; Norges Tekniske Høgskole (NTH): Trondheim, Norway, 1960. [Google Scholar]
- Horjen, I. Numerical modeling of two-dimensional sea spray icing on vessel-mounted cylinders. Cold Reg. Sci. Technol. 2013, 93, 20–35. [Google Scholar] [CrossRef]
- Forest, T.; Lozowski, E.; Gagnon, R.E. Estimating Marine Icing on Offshore Structures Using RIGICE04. In Proceedings of the 11th International Workshop on Atmospheric Icing of Structures, Montreal, PQ, Canada, 12–16 June 2005; National Research Council Canada: Montreal, QC, Canada, 2005; pp. 12–16. [Google Scholar]
- Samuelsen, E.M. Ship-icing prediction methods applied in operational weather forecasting. Q. J. R. Meteorol. Soc. 2017, 144, 13–33. [Google Scholar] [CrossRef]
- Reistad, M.; Breivik, Ø.; Haakenstad, H.; Aarnes, O.J.; Furevik, B.; Bidlot, J.R. A high-resolution hindcast of wind and waves for the North Sea, the Norwegian Sea, and the Barents Sea. J. Geophys. Res. Oceans 2011, 116, C05019. [Google Scholar] [CrossRef] [Green Version]
- Little, R.J. Calibrated Bayes: A Bayes/Frequentist Roadmap. Am. Stat. 2006, 60, 213–223. [Google Scholar] [CrossRef]
- Wilks, D. Statistical Methods in the Atmospheric Sciences, 3rd ed.; Academic Press: Cambridge, MA, USA, 2011; Volume 3. [Google Scholar]
- Park, M.H.; Ju, M.; Kim, J.Y. Bayesian approach in estimating flood waste generation: A case study in South Korea. J. Environ. Manag. 2020, 265, 110552. [Google Scholar] [CrossRef]
- Robert, C.; Casella, G. A Short History of Markov Chain Monte Carlo: Subjective Recollections from Incomplete Data. Stat. Sci. 2012, 26, 102–115. [Google Scholar] [CrossRef]
- Zio, E. The Monte Carlo Simulation Method for System Reliability and Risk Analysis; Springer: London, UK, 2013. [Google Scholar] [CrossRef]
- Epstein, E.S. Statistical Inference and Prediction in Climatology: A Bayesian Approach; Meteorological Monographs, American Meteorological Society: Boston, MA, USA, 1985; Volume 20. [Google Scholar]
- Lee, P.M. Bayesian Statistics, an Introduction, 2nd ed.; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Barjouei, A.S.; Naseri, M.; Ræder, T.B.; Samuelsen, E.M. Simulation of Atmospheric and Oceanographic Parameters for Spray Icing Prediction. In Proceedings of the 30th Conference Anniversary of the International Society of Offshore and Polar Engineers, Shanghai, China, 11–16 October 2020; ISOPE: Mountain View, CA, USA, 2020; ISOPE-I-20-1256; pp. 750–1256. Available online: https://onepetro.org/ISOPEIOPEC/proceedings-abstract/ISOPE20/All-ISOPE20/ISOPE-I20-1256/446378 (accessed on 20 April 2021).
- Ridgeway, G.; Madigan, D. A Sequential Monte Carlo Method for Bayesian Analysis of Massive Datasets. Data Min. Knowl. Discov. 2003, 7, 301–319. [Google Scholar] [CrossRef] [PubMed]
- Givens, G.H.; Hoeting, J.A. Computational Statistics, 2nd ed.; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2013. [Google Scholar] [CrossRef]
- Rubin, D.B. Comment. J. Am. Stat. 1987, 82, 543–546. [Google Scholar] [CrossRef]
- Rubin, D.B. Using the SIR algorithm to simulate posterior distributions. In Bayesian Statistics 3; Bernardo, J.M., DeGroot, M.H., Lindley, D.V., Smith, A.F., Eds.; John Wiley & Sons Inc.: Oxford, UK, 1988; pp. 395–402. [Google Scholar]
- Liu, J.S.; Chen, R. Sequential Monte Carlo Methods for Dynamic Systems. J. Am. Stat. Assoc. 1988, 93, 1032–1044. [Google Scholar] [CrossRef]
- Barbu, A.; Zhu, S.C. Sequential Monte Carlo. In Monte Carlo Methods; Springer: Singapore, 2020; pp. 19–48. [Google Scholar] [CrossRef]
- Brooks, S.P.; Roberts, G.O. Convergence assessment techniques for Markov chain Monte Carlo. Stat. Comput. 1998, 8, 319–335. [Google Scholar] [CrossRef]
- Tierney, L. Markov Chains for Exploring Posterior Distributions. Ann. Stat. 1994, 22, 1701–1762. [Google Scholar] [CrossRef]
- Cowles, M.K.; Carlin, B.P. Markov Chain Monte Carlo Convergence Diagnostics: A Comparative Review. J. Am. Stat. Assoc. 1996, 91, 883–904. [Google Scholar] [CrossRef]
- Norwegian Petroleum Directorate. Available online: https://factpages.npd.no/en (accessed on 4 May 2020).
- Anderson, T.W.; Darling, D.A. Asymptotic theory of certain ‘goodness-of-fit’ criteria based on stochastic processes. Ann. Math. Stat. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- MATLAB. MATLAB and Simulink; 9.8.0.1396136 (R2020a); The MathWorks Inc.: Natick, MA, USA, 2020; Available online: https://es.mathworks.com/products/matlab/ (accessed on 14 April 2020).
- Smith, G. Essential Statistics, Regression, and Econometrics, 2nd ed.; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar] [CrossRef]
- Naseri, M.; Samuelsen, E.M. Unprecedented Vessel-Icing Climatology Based on Spray-Icing Modelling and Reanalysis Data: A Risk-Based Decision-Making Input for Arctic Offshore Industries. Atmosphere 2019, 10, 197. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Mu, Y.; Zhang, X.; Jia, X. Polar tourism and environment change: Opportunity, impact and adaptation. Polar Sci. 2020, 25, 100544. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Number of Days in Year Which H0 Cannot Be Rejected | Percentage of Days in Year Which H0 Cannot Be Rejected |
|---|---|---|
| Wave height | 245 | 67% |
| Wind speed | 330 | 90% |
| Temperature | 257 | 70% |
| Relative humidity | 284 | 78% |
| Atmospheric pressure | 346 | 95% |
| Wave period | 180 | 49% |
| Parameter | Value |
|---|---|
| 1.12 | |
| (−3.49, 10.29) | |
| (−5.20, 8.52) | |
| (−5.16, 0.25) | |
| (−5.16, 1.50) | |
| (−4.44, 0.95) |
| Month | Bayesian | SIS200 2 | SIS500 3 | MCMC200 4 | MCMC500 5 |
|---|---|---|---|---|---|
| Jan | 1.00 | 1.03 | 0.94 | 0.99 | 0.97 |
| Feb | 0.97 | 1.19 | 1.25 | 1.00 | 0.97 |
| Mar | 0.89 | 0.96 | 1.12 | 0.97 | 0.84 |
| Apr | 0.65 | 0.74 | 0.63 | 0.67 | 0.70 |
| May | 0.98 | 1.10 | 1.04 | 0.95 | 0.95 |
| Jun | 0.54 | 0.62 | 0.52 | 0.66 | 0.53 |
| Jul | 0.42 | 0.38 | 0.46 | 0.47 | 0.52 |
| Aug | 0.54 | 0.56 | 0.59 | 0.56 | 0.74 |
| Sep | 0.82 | 0.83 | 1.02 | 0.89 | 1.07 |
| Oct | 0.99 | 0.94 | 1.17 | 1.15 | 1.22 |
| Nov | 0.66 | 0.84 | 0.75 | 0.78 | 0.83 |
| Dec | 1.03 | 1.48 | 1.37 | 1.15 | 1.09 |
| Month | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Jan | 3.39 | 3.37 | 3.31 | 3.76 | 3.52 |
| Feb | 2.39 | 2.23 | 2.31 | 2.29 | 2.38 |
| Mar | 2.69 | 3.14 | 2.92 | 2.77 | 2.89 |
| Apr | 1.99 | 2.07 | 2.65 | 1.92 | 2.18 |
| May | 2.77 | 2.50 | 2.84 | 2.60 | 2.54 |
| Jun | 2.33 | 2.49 | 2.49 | 2.22 | 2.14 |
| Jul | 1.56 | 1.86 | 1.90 | 1.65 | 1.53 |
| Aug | 2.48 | 2.51 | 2.60 | 2.35 | 2.62 |
| Sep | 2.90 | 3.62 | 3.23 | 3.01 | 3.00 |
| Oct | 2.85 | 3.18 | 4.10 | 3.22 | 3.07 |
| Nov | 2.63 | 3.13 | 3.48 | 2.43 | 2.59 |
| Dec | 2.83 | 3.61 | 3.64 | 2.94 | 2.91 |
| Month | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Jan | 3.13 | 4.36 | 4.29 | 5.95 | 5.99 |
| Feb | 4.25 | 4.88 | 5.16 | 7.25 | 6.94 |
| Mar | 2.76 | 3.19 | 3.16 | 4.49 | 5.57 |
| Apr | 1.83 | 2.58 | 2.26 | 2.40 | 2.18 |
| May | 1.68 | 1.85 | 2.17 | 1.64 | 1.98 |
| Jun | 0.63 | 0.64 | 0.76 | 0.67 | 0.57 |
| Jul | 0.75 | 0.84 | 0.71 | 0.80 | 0.76 |
| Aug | 0.85 | 0.83 | 0.97 | 0.89 | 0.78 |
| Sep | 1.33 | 1.83 | 1.25 | 1.43 | 1.42 |
| Oct | 1.41 | 2.44 | 2.46 | 2.07 | 2.12 |
| Nov | 2.34 | 2.75 | 3.02 | 3.38 | 3.04 |
| Dec | 2.12 | 3.31 | 3.44 | 3.55 | 3.49 |
| Month | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Jan | 5.31 | 5.59 | 5.20 | 5.82 | 6.02 |
| Feb | 9.54 | 9.34 | 9.33 | 8.21 | 8.25 |
| Mar | 5.94 | 7.53 | 7.49 | 6.28 | 5.16 |
| Apr | 9.72 | 10.39 | 9.59 | 9.94 | 9.65 |
| May | 8.22 | 8.82 | 8.57 | 8.60 | 8.54 |
| Jun | 5.54 | 5.41 | 5.25 | 4.96 | 4.88 |
| Jul | 6.48 | 5.98 | 7.34 | 6.36 | 6.36 |
| Aug | 6.55 | 6.14 | 7.52 | 5.95 | 5.99 |
| Sep | 8.81 | 10.47 | 9.22 | 9.63 | 9.75 |
| Oct | 6.46 | 8.41 | 9.76 | 6.19 | 6.21 |
| Nov | 9.98 | 13.56 | 11.86 | 11.59 | 11.29 |
| Dec | 6.97 | 9.38 | 8.16 | 8.97 | 7.67 |
| Month | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Jan | 14.20 | 14.09 | 15.64 | 13.07 | 14.57 |
| Feb | 17.13 | 15.96 | 16.92 | 16.46 | 16.86 |
| Mar | 10.58 | 12.53 | 12.60 | 11.55 | 12.91 |
| Apr | 9.35 | 12.01 | 9.41 | 8.40 | 10.38 |
| May | 9.80 | 11.05 | 9.92 | 10.46 | 9.95 |
| Jun | 4.40 | 5.05 | 4.20 | 4.84 | 4.88 |
| Jul | 7.07 | 8.74 | 7.66 | 7.45 | 7.76 |
| Aug | 7.62 | 8.29 | 6.44 | 7.46 | 6.84 |
| Sep | 8.79 | 9.35 | 10.88 | 10.40 | 9.69 |
| Oct | 8.46 | 8.41 | 12.09 | 8.68 | 7.70 |
| Nov | 12.85 | 12.20 | 14.82 | 12.36 | 12.79 |
| Dec | 16.90 | 17.16 | 18.81 | 17.05 | 16.12 |
| Month | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Jan | 1.06 | 1.14 | 1.08 | 2.00 | 1.82 |
| Feb | 1.14 | 1.59 | 1.38 | 2.33 | 3.38 |
| Mar | 0.99 | 1.40 | 1.20 | 1.52 | 2.16 |
| Apr | 0.78 | 0.81 | 0.80 | 1.34 | 1.61 |
| May | 1.03 | 1.36 | 1.29 | 1.47 | 1.56 |
| Jun | 0.63 | 1.03 | 0.77 | 0.70 | 0.67 |
| Jul | 0.70 | 0.97 | 0.79 | 0.84 | 0.71 |
| Aug | 0.60 | 0.62 | 0.70 | 0.71 | 0.96 |
| Sep | 0.64 | 0.63 | 0.88 | 0.89 | 0.61 |
| Oct | 0.98 | 1.22 | 1.06 | 1.13 | 1.01 |
| Nov | 0.63 | 0.98 | 1.13 | 0.83 | 0.73 |
| Dec | 0.89 | 1.01 | 1.25 | 1.28 | 1.47 |
| Month | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Jan | 0.08 | 0.19 | 0.20 | 0.34 | 0.35 |
| Feb | 0.13 | 0.19 | 0.22 | 0.41 | 0.39 |
| Mar | 0.08 | 0.12 | 0.12 | 0.22 | 0.29 |
| Apr | 0.07 | 0.12 | 0.10 | 0.10 | 0.09 |
| May | 0.00 | 0.00 | 0.02 | 0.01 | 0.02 |
| Jun | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Jul | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Aug | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Sep | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Oct | 0.00 | 0.01 | 0.01 | 0.00 | 0.00 |
| Nov | 0.03 | 0.04 | 0.04 | 0.07 | 0.04 |
| Dec | 0.06 | 0.11 | 0.16 | 0.14 | 0.14 |
| Location | Bayesian | SIS200 | SIS500 | MCMC200 | MCMC500 |
|---|---|---|---|---|---|
| Coordinates (74.07° N, 35.81° E) | 00:00:01 | 00:00:05 | 00:00:22 | 00:00:12 | 00:00:19 |
| Entire area | 00:04:41 | 00:44:29 | 02:00:03 | 01:28:28 | 02:22:14 |
| t-test Parameter | 30 Years | 32 Years |
|---|---|---|
| Mean | 2.68 | 2.61 |
| Variance | 4.32 | 3.80 |
| Observations | 365 | 365 |
| df | 725 | - |
| t Stat | 0.45 | - |
| p-value | 0.65 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shojaei Barjouei, A.; Naseri, M. A Comparative Study of Statistical Techniques for Prediction of Meteorological and Oceanographic Conditions: An Application in Sea Spray Icing. J. Mar. Sci. Eng. 2021, 9, 539. https://doi.org/10.3390/jmse9050539
Shojaei Barjouei A, Naseri M. A Comparative Study of Statistical Techniques for Prediction of Meteorological and Oceanographic Conditions: An Application in Sea Spray Icing. Journal of Marine Science and Engineering. 2021; 9(5):539. https://doi.org/10.3390/jmse9050539
Chicago/Turabian StyleShojaei Barjouei, Abolfazl, and Masoud Naseri. 2021. "A Comparative Study of Statistical Techniques for Prediction of Meteorological and Oceanographic Conditions: An Application in Sea Spray Icing" Journal of Marine Science and Engineering 9, no. 5: 539. https://doi.org/10.3390/jmse9050539
APA StyleShojaei Barjouei, A., & Naseri, M. (2021). A Comparative Study of Statistical Techniques for Prediction of Meteorological and Oceanographic Conditions: An Application in Sea Spray Icing. Journal of Marine Science and Engineering, 9(5), 539. https://doi.org/10.3390/jmse9050539